
Unikanie pułapek związanych z automatycznie wbudowanym kodem
Opublikowany: 2022-03-10 Wstawianie to proces umieszczania zawartości plików bezpośrednio w dokumencie HTML: pliki CSS mogą być wstawiane do elementu style , a pliki JavaScript mogą być wstawiane do elementu script :
<style> /* CSS contents here */ </style> <script> /* JS contents here */ </script>Dzięki wydrukowaniu kodu znajdującego się już w danych wyjściowych HTML, wstawianie pozwala uniknąć żądań blokujących renderowanie i wykonuje kod przed renderowaniem strony. W związku z tym jest przydatny do poprawy postrzeganej wydajności witryny (tj. czasu potrzebnego, aby strona stała się użyteczna). Na przykład możemy użyć bufora danych dostarczanych natychmiast po załadowaniu witryny (około 14 kb) do wbudowanej krytyczne style, w tym style zawartości strony widocznej na ekranie (tak jak zostało to zrobione w poprzedniej witrynie Smashing Magazine) oraz rozmiary czcionek oraz szerokości i wysokości układu, aby uniknąć niestabilnego ponownego renderowania układu po dostarczeniu pozostałych danych .
Jednak gdy jest przesadzony, wbudowany kod może również mieć negatywny wpływ na wydajność witryny: ponieważ kod nie może być buforowany, ta sama zawartość jest wielokrotnie wysyłana do klienta i nie może być wstępnie buforowana przez Service Workers lub buforowane i dostępne z sieci dostarczania treści. Ponadto skrypty wbudowane są uważane za niebezpieczne podczas wdrażania polityki bezpieczeństwa treści (CSP). Następnie rozsądną strategią jest wbudowanie tych krytycznych części CSS i JS, które sprawiają, że witryna ładuje się szybciej, ale w inny sposób unika się ich w jak największym stopniu.
W celu uniknięcia tworzenia wstawek, w tym artykule zbadamy, jak przekonwertować kod wbudowany w zasoby statyczne: Zamiast drukować kod w wyniku HTML, zapisujemy go na dysku (w efekcie tworzymy plik statyczny) i dodajemy odpowiedni <script> lub <link> , aby załadować plik.
Zacznijmy!
Zalecana literatura : Bezpieczeństwo WordPress jako proces
Kiedy unikać inliningu?
Nie ma magicznej recepty na ustalenie, czy jakiś kod musi być wbudowany, czy nie, jednak może być całkiem oczywiste, kiedy jakiś kod nie może być wbudowany: kiedy obejmuje duży fragment kodu i kiedy nie jest potrzebny od razu.
Na przykład witryny WordPress wbudowane w szablony JavaScript do renderowania Menedżera multimediów (dostępnego na stronie Biblioteki multimediów w /wp-admin/upload.php ), wyświetlając znaczną ilość kodu:
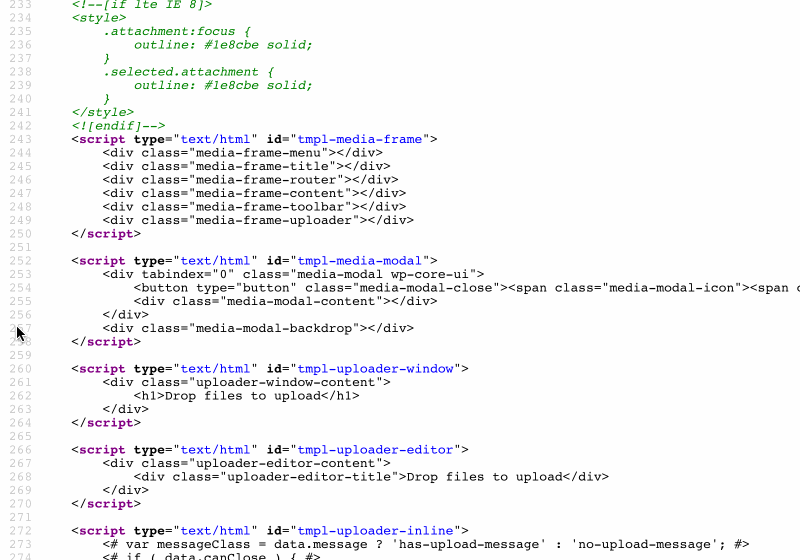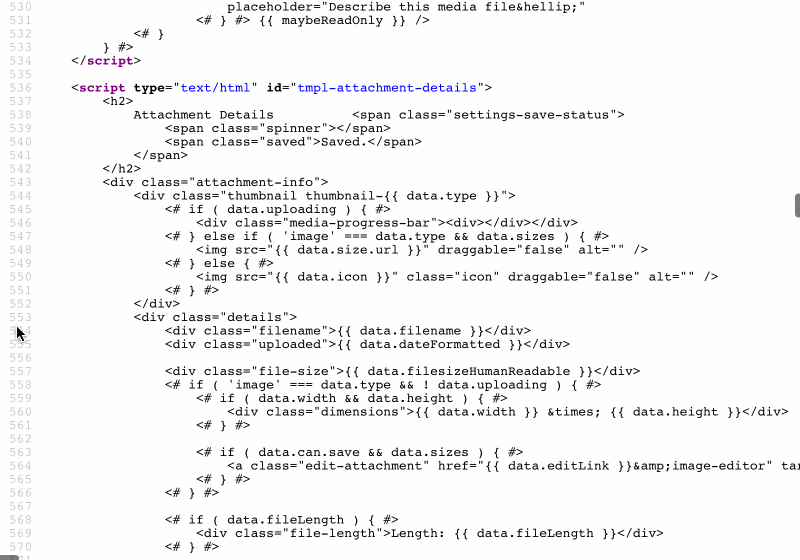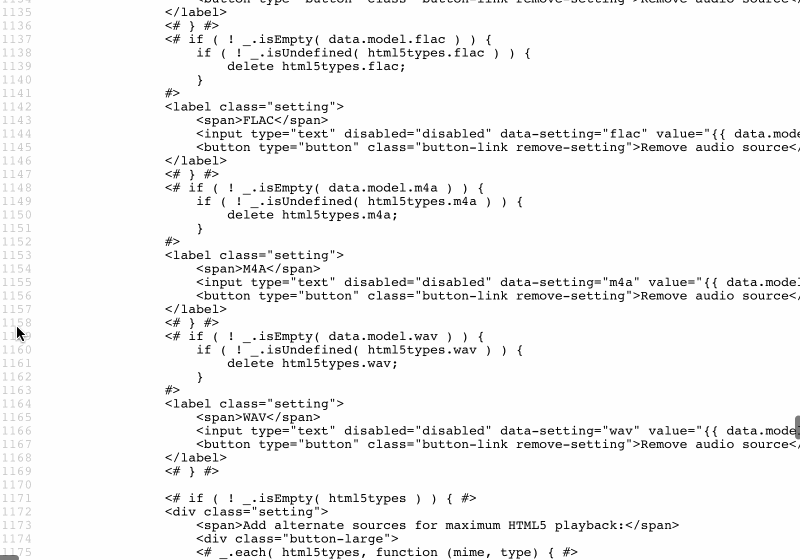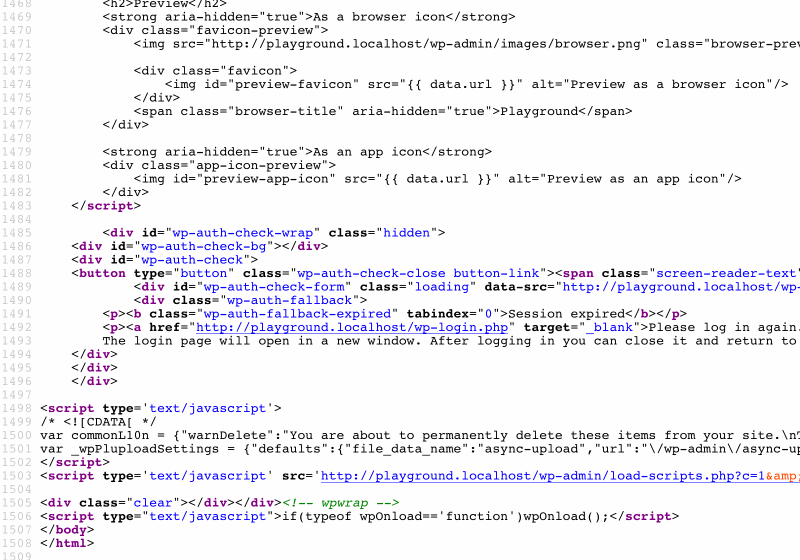
Zajmując całe 43 KB, rozmiar tego fragmentu kodu nie jest bez znaczenia, a ponieważ znajduje się na dole strony, nie jest potrzebny od razu. W związku z tym sensowne byłoby udostępnianie tego kodu za pomocą zasobów statycznych lub drukowanie go wewnątrz danych wyjściowych HTML.
Zobaczmy dalej, jak przekształcić kod wbudowany w zasoby statyczne.
Uruchamianie tworzenia plików statycznych
Jeśli zawartość (ta, która ma być wbudowana) pochodzi z pliku statycznego, nie ma wiele do zrobienia poza po prostu zażądaniem tego pliku statycznego zamiast wstawiania kodu.
Jednak w przypadku kodu dynamicznego musimy zaplanować jak/kiedy wygenerować plik statyczny z jego zawartością. Na przykład, jeśli witryna oferuje opcje konfiguracyjne (takie jak zmiana schematu kolorów lub obrazu tła), kiedy należy wygenerować plik zawierający nowe wartości? Mamy następujące możliwości tworzenia plików statycznych z kodu dynamicznego:
- Na prośbę
Kiedy użytkownik uzyskuje dostęp do treści po raz pierwszy. - Przy zmianie
Gdy zmieniło się źródło kodu dynamicznego (np. wartość konfiguracyjna).
Rozważmy najpierw na żądanie. Gdy użytkownik wchodzi na stronę po raz pierwszy, powiedzmy przez /index.html , plik statyczny (np header-colors.css ) jeszcze nie istnieje, więc musi zostać wtedy wygenerowany. Sekwencja wydarzeń jest następująca:
- Użytkownik żąda
/index.html; - Podczas przetwarzania żądania serwer sprawdza, czy istnieje plik
header-colors.css. Ponieważ tak nie jest, uzyskuje kod źródłowy i generuje plik na dysku; - Zwraca odpowiedź do klienta, w tym tag
<link rel="stylesheet" type="text/css" href="/staticfiles/header-colors.css"> - Przeglądarka pobiera wszystkie zasoby zawarte na stronie, w tym
header-colors.css; - Do tego czasu ten plik istnieje, więc jest obsługiwany.
Jednak kolejność wydarzeń może być również inna, prowadząc do niezadowalającego wyniku. Na przykład:
- Użytkownik żąda
/index.html; - Ten plik jest już buforowany przez przeglądarkę (lub inny serwer proxy lub przez Service Workers), więc żądanie nigdy nie jest wysyłane do serwera;
- Przeglądarka pobiera wszystkie zasoby zawarte na stronie, w tym
header-colors.css. Obraz ten nie jest jednak buforowany w przeglądarce, więc żądanie jest wysyłane do serwera; - Serwer nie wygenerował jeszcze
header-colors.css(np. został właśnie zrestartowany); - Zwróci 404.
Alternatywnie, możemy wygenerować header-colors.css nie podczas żądania /index.html , ale podczas żądania samego /header-colors.css . Ponieważ jednak ten plik początkowo nie istnieje, żądanie jest już traktowane jako 404. Mimo że moglibyśmy się obejść, zmieniając nagłówki, aby zmienić kod stanu na 200 i zwracając zawartość obrazu, to jest okropny sposób robienia rzeczy, więc nie będziemy rozważać takiej możliwości (jesteśmy znacznie lepsi niż to!)
Pozostaje tylko jedna opcja: wygenerowanie pliku statycznego po zmianie jego źródła.
Tworzenie pliku statycznego po zmianie źródła
Zwróć uwagę, że możemy tworzyć kod dynamiczny zarówno ze źródeł zależnych od użytkownika, jak i od strony. Na przykład, jeśli motyw umożliwia zmianę obrazu tła witryny, a ta opcja jest skonfigurowana przez administratora witryny, plik statyczny można wygenerować w ramach procesu wdrażania. Z drugiej strony, jeśli witryna umożliwia użytkownikom zmianę obrazu tła dla swoich profili, plik statyczny musi zostać wygenerowany w czasie wykonywania.
W skrócie mamy te dwa przypadki:
- Konfiguracja użytkownika
Proces musi zostać uruchomiony, gdy użytkownik zaktualizuje konfigurację. - Konfiguracja witryny
Proces musi zostać uruchomiony, gdy administrator zaktualizuje konfigurację witryny lub przed wdrożeniem witryny.
Gdybyśmy rozważyli te dwa przypadki niezależnie, dla #2 moglibyśmy zaprojektować proces na dowolnym stosie technologicznym, jaki chcieliśmy. Nie chcemy jednak wdrażać dwóch różnych rozwiązań, ale unikalne rozwiązanie, które poradzi sobie w obu przypadkach. A ponieważ z punktu 1 proces generowania pliku statycznego musi być uruchamiany w działającej witrynie, konieczne jest zaprojektowanie tego procesu na tym samym stosie technologicznym, na którym działa witryna.
Podczas projektowania procesu nasz kod będzie musiał poradzić sobie z określonymi okolicznościami zarówno #1, jak i #2:
- Wersjonowanie
Dostęp do pliku statycznego należy uzyskać za pomocą parametru „wersja”, aby unieważnić poprzedni plik po utworzeniu nowego pliku statycznego. Podczas gdy #2 może po prostu mieć taką samą wersję jak witryna, #1 musi używać wersji dynamicznej dla każdego użytkownika, prawdopodobnie zapisanej w bazie danych. - Lokalizacja wygenerowanego pliku
#2 generuje unikalny plik statyczny dla całej witryny (np/staticfiles/header-colors.css), natomiast #1 tworzy plik statyczny dla każdego użytkownika (np./staticfiles/users/leo/header-colors.css). - Poruszające wydarzenie
Podczas gdy w przypadku nr 1 plik statyczny musi zostać wykonany w czasie wykonywania, w przypadku nr 2 można go również wykonać jako część procesu budowania w naszym środowisku pomostowym. - Wdrażanie i dystrybucja
Pliki statyczne w punkcie 2 można bezproblemowo zintegrować z pakietem wdrożeniowym witryny, nie stwarzając żadnych problemów; Jednak pliki statyczne w #1 nie mogą, więc proces musi zająć się dodatkowymi problemami, takimi jak wiele serwerów za systemem równoważenia obciążenia (czy pliki statyczne zostaną utworzone tylko na 1 serwerze, czy na wszystkich z nich i jak?).
Zaprojektujmy i zaimplementujmy dalej proces. Aby każdy plik statyczny został wygenerowany, musimy stworzyć obiekt zawierający metadane pliku, obliczyć jego zawartość ze źródeł dynamicznych, a na koniec zapisać plik statyczny na dysku. Jako przykład użycia, aby poprowadzić poniższe wyjaśnienia, wygenerujemy następujące pliki statyczne:
-
header-colors.css, z pewnym stylem z wartości zapisanych w bazie danych -
welcomeuser-data.js, zawierający obiekt JSON z danymi użytkownika pod jakąś zmienną:window.welcomeUserData = {name: "Leo"};.
Poniżej opiszę proces generowania plików statycznych dla WordPressa, dla których musimy oprzeć stos o funkcje PHP i WordPressa. Funkcję generowania plików statycznych przed wdrożeniem można uruchomić, ładując specjalną stronę wykonującą [create_static_files] , jak opisałem w poprzednim artykule.
Dalsze polecane lektury : Tworzenie pracownika usług: studium przypadku
Reprezentowanie pliku jako obiektu
Musimy wymodelować plik jako obiekt PHP ze wszystkimi odpowiadającymi mu właściwościami, abyśmy mogli zarówno zapisać plik na dysku w określonej lokalizacji (np. w /staticfiles/ lub /staticfiles/users/leo/ ), jak i wiedzieć, jak zażądać plik konsekwentnie. W tym celu tworzymy interfejs Resource zwracający zarówno metadane pliku (nazwa pliku, katalog, typ: „css” lub „js”, wersję oraz zależności od innych zasobów), jak i jego zawartość.
interface Resource { function get_filename(); function get_dir(); function get_type(); function get_version(); function get_dependencies(); function get_content(); } Aby kod był utrzymywalny i reużywalny, kierujemy się zasadami SOLID, dla których ustalamy schemat dziedziczenia obiektów dla zasobów, aby stopniowo dodawać właściwości, zaczynając od abstrakcyjnej klasy ResourceBase , z której będą dziedziczyć wszystkie nasze implementacje Resource:
abstract class ResourceBase implements Resource { function get_dependencies() { // By default, a file has no dependencies return array(); } }Podążając za SOLID, tworzymy podklasy, gdy właściwości się różnią. Jak wspomniano wcześniej, lokalizacja wygenerowanego pliku statycznego i żądane wersje będą się różnić w zależności od tego, czy plik dotyczy konfiguracji użytkownika lub witryny:
abstract class UserResourceBase extends ResourceBase { function get_dir() { // A different file and folder for each user $user = wp_get_current_user(); return "/staticfiles/users/{$user->user_login}/"; } function get_version() { // Save the resource version for the user under her meta data. // When the file is regenerated, must execute `update_user_meta` to increase the version number $user_id = get_current_user_id(); $meta_key = "resource_version_".$this->get_filename(); return get_user_meta($user_id, $meta_key, true); } } abstract class SiteResourceBase extends ResourceBase { function get_dir() { // All files are placed in the same folder return "/staticfiles/"; } function get_version() { // Same versioning as the site, assumed defined under a constant return SITE_VERSION; } } Wreszcie, na ostatnim poziomie, implementujemy obiekty dla plików, które chcemy wygenerować, dodając nazwę pliku, typ pliku i kod dynamiczny za pomocą funkcji get_content :
class HeaderColorsSiteResource extends SiteResourceBase { function get_filename() { return "header-colors"; } function get_type() { return "css"; } function get_content() { return sprintf( " .site-title a { color: #%s; } ", esc_attr(get_header_textcolor()) ); } } class WelcomeUserDataUserResource extends UserResourceBase { function get_filename() { return "welcomeuser-data"; } function get_type() { return "js"; } function get_content() { $user = wp_get_current_user(); return sprintf( "window.welcomeUserData = %s;", json_encode( array( "name" => $user->display_name ) ) ); } }Dzięki temu zamodelowaliśmy plik jako obiekt PHP. Następnie musimy go zapisać na dysku.
Zapisywanie pliku statycznego na dysku
Zapisywanie pliku na dysku można łatwo wykonać dzięki natywnym funkcjom zapewnianym przez język. W przypadku PHP jest to realizowane za pomocą funkcji fwrite . Dodatkowo tworzymy klasę narzędziową ResourceUtils z funkcjami podającymi bezwzględną ścieżkę do pliku na dysku, a także jego ścieżkę względem katalogu głównego strony:

class ResourceUtils { protected static function get_file_relative_path($fileObject) { return $fileObject->get_dir().$fileObject->get_filename().".".$fileObject->get_type(); } static function get_file_path($fileObject) { // Notice that we must add constant WP_CONTENT_DIR to make the path absolute when saving the file return WP_CONTENT_DIR.self::get_file_relative_path($fileObject); } } class ResourceGenerator { static function save($fileObject) { $file_path = ResourceUtils::get_file_path($fileObject); $handle = fopen($file_path, "wb"); $numbytes = fwrite($handle, $fileObject->get_content()); fclose($handle); } } Następnie, gdy źródło ulegnie zmianie i plik statyczny musi zostać ponownie wygenerowany, wykonujemy ResourceGenerator::save przekazując jako parametr obiekt reprezentujący plik. Poniższy kod regeneruje i zapisuje na dysku pliki „header-colors.css” i „welcomeuser-data.js”:
// When need to regenerate header-colors.css, execute: ResourceGenerator::save(new HeaderColorsSiteResource()); // When need to regenerate welcomeuser-data.js, execute: ResourceGenerator::save(new WelcomeUserDataUserResource()); Gdy już istnieją, możemy kolejkować pliki do załadowania za pomocą <script> i <link> .
Kolejkowanie plików statycznych
Kolejkowanie plików statycznych nie różni się niczym od kolejkowania dowolnego zasobu w WordPress: poprzez funkcje wp_enqueue_script i wp_enqueue_style . Następnie po prostu iterujemy wszystkie instancje obiektów i używamy jednego lub drugiego haka w zależności od ich wartości get_type() będącej albo "js" albo "css" .
Najpierw dodajemy funkcje narzędziowe, aby podać adres URL pliku i wskazać typ będący JS lub CSS:
class ResourceUtils { // Continued from above... static function get_file_url($fileObject) { // Add the site URL before the file path return get_site_url().self::get_file_relative_path($fileObject); } static function is_css($fileObject) { return $fileObject->get_type() == "css"; } static function is_js($fileObject) { return $fileObject->get_type() == "js"; } } Wystąpienie klasy ResourceEnqueuer będzie zawierać wszystkie pliki, które należy załadować; po wywołaniu jego funkcje enqueue_scripts i enqueue_styles kolejkowanie, wykonując odpowiednie funkcje WordPressa (odpowiednio wp_enqueue_script i wp_enqueue_style ):
class ResourceEnqueuer { protected $fileObjects; function __construct($fileObjects) { $this->fileObjects = $fileObjects; } protected function get_file_properties($fileObject) { $handle = $fileObject->get_filename(); $url = ResourceUtils::get_file_url($fileObject); $dependencies = $fileObject->get_dependencies(); $version = $fileObject->get_version(); return array($handle, $url, $dependencies, $version); } function enqueue_scripts() { $jsFileObjects = array_map(array(ResourceUtils::class, 'is_js'), $this->fileObjects); foreach ($jsFileObjects as $fileObject) { list($handle, $url, $dependencies, $version) = $this->get_file_properties($fileObject); wp_register_script($handle, $url, $dependencies, $version); wp_enqueue_script($handle); } } function enqueue_styles() { $cssFileObjects = array_map(array(ResourceUtils::class, 'is_css'), $this->fileObjects); foreach ($cssFileObjects as $fileObject) { list($handle, $url, $dependencies, $version) = $this->get_file_properties($fileObject); wp_register_style($handle, $url, $dependencies, $version); wp_enqueue_style($handle); } } } Na koniec tworzymy instancję obiektu klasy ResourceEnqueuer z listą obiektów PHP reprezentujących każdy plik i dodajemy zaczep WordPress do wykonania kolejkowania:
// Initialize with the corresponding object instances for each file to enqueue $fileEnqueuer = new ResourceEnqueuer( array( new HeaderColorsSiteResource(), new WelcomeUserDataUserResource() ) ); // Add the WordPress hooks to enqueue the resources add_action('wp_enqueue_scripts', array($fileEnqueuer, 'enqueue_scripts')); add_action('wp_print_styles', array($fileEnqueuer, 'enqueue_styles'));To wszystko: po umieszczeniu w kolejce pliki statyczne będą wymagane podczas ładowania witryny w kliencie. Udało nam się uniknąć drukowania kodu wbudowanego i ładowania zasobów statycznych.
Następnie możemy zastosować kilka ulepszeń w celu dodatkowego zwiększenia wydajności.
Zalecana lektura : Wprowadzenie do automatycznego testowania wtyczek WordPress za pomocą PHPUnit
Grupowanie plików razem
Mimo że protokół HTTP/2 ograniczył potrzebę łączenia plików, nadal przyspiesza działanie witryny, ponieważ kompresja plików (np. za pomocą GZip) będzie bardziej efektywna, a przeglądarki (takie jak Chrome) mają większe narzuty na przetwarzanie wielu zasobów .
Do tej pory zamodelowaliśmy plik jako obiekt PHP, co pozwala nam traktować ten obiekt jako dane wejściowe do innych procesów. W szczególności możemy powtórzyć ten sam proces, aby połączyć wszystkie pliki tego samego typu razem i udostępnić dołączoną wersję zamiast wszystkich niezależnych plików. W tym celu tworzymy funkcję get_content , która po prostu wyodrębnia zawartość z każdego zasobu w $fileObjects i drukuje ją ponownie, tworząc agregację całej zawartości ze wszystkich zasobów:
abstract class SiteBundleBase extends SiteResourceBase { protected $fileObjects; function __construct($fileObjects) { $this->fileObjects = $fileObjects; } function get_content() { $content = ""; foreach ($this->fileObjects as $fileObject) { $content .= $fileObject->get_content().PHP_EOL; } return $content; } } Możemy połączyć wszystkie pliki razem w plik bundled-styles.css , tworząc klasę dla tego pliku:
class StylesSiteBundle extends SiteBundleBase { function get_filename() { return "bundled-styles"; } function get_type() { return "css"; } } Na koniec po prostu umieszczamy w kolejce te dołączone pliki, jak poprzednio, zamiast wszystkich niezależnych zasobów. Dla CSS tworzymy pakiet zawierający pliki header-colors.css , background-image.css i font-sizes.css , dla których po prostu tworzymy instancję StylesSiteBundle z obiektem PHP dla każdego z tych plików (i podobnie możemy stworzyć JS plik pakietu):
$fileObjects = array( // CSS new HeaderColorsSiteResource(), new BackgroundImageSiteResource(), new FontSizesSiteResource(), // JS new WelcomeUserDataUserResource(), new UserShoppingItemsUserResource() ); $cssFileObjects = array_map(array(ResourceUtils::class, 'is_css'), $fileObjects); $jsFileObjects = array_map(array(ResourceUtils::class, 'is_js'), $fileObjects); // Use this definition of $fileEnqueuer instead of the previous one $fileEnqueuer = new ResourceEnqueuer( array( new StylesSiteBundle($cssFileObjects), new ScriptsSiteBundle($jsFileObjects) ) );Otóż to. Teraz będziemy żądać tylko jednego pliku JS i jednego pliku CSS zamiast wielu.
Ostateczna poprawa postrzeganej wydajności polega na ustaleniu priorytetów zasobów poprzez opóźnienie ładowania tych zasobów, które nie są potrzebne natychmiast. Zajmijmy się tym dalej.
async / defer Atrybuty dla zasobów JS
Możemy dodać atrybuty async i defer do tagu <script> , aby zmienić czas pobierania, analizowania i wykonywania pliku JavaScript, aby nadać priorytet krytycznemu JavaScriptowi i przesyłać wszystko, co nie jest krytyczne, tak późno, jak to możliwe, zmniejszając w ten sposób pozorne ładowanie witryny czas.
Aby zaimplementować tę funkcję, zgodnie z zasadami SOLID, powinniśmy stworzyć nowy interfejs JSResource (który dziedziczy po Resource ) zawierający funkcje is_async i is_defer . Jednak to zamknęłoby drzwi do tagów <style> ostatecznie wspierających również te atrybuty. Tak więc, mając na uwadze adaptacyjność, przyjmujemy bardziej otwarte podejście: po prostu dodajemy ogólną metodę get_attributes do interfejsu Resource , aby zachować elastyczność w dodawaniu do dowolnego atrybutu (albo już istniejących, albo jeszcze nie wynalezionych) dla obu <script> i <link> tagi:
interface Resource { // Continued from above... function get_attributes(); } abstract class ResourceBase implements Resource { // Continued from above... function get_attributes() { // By default, no extra attributes return ''; } } WordPress nie oferuje łatwego sposobu na dodanie dodatkowych atrybutów do umieszczonych w kolejce zasobów, więc robimy to w dość chytry sposób, dodając zaczep, który zastępuje ciąg znaków wewnątrz tagu za pomocą funkcji add_script_tag_attributes :
class ResourceEnqueuerUtils { protected static tag_attributes = array(); static function add_tag_attributes($handle, $attributes) { self::tag_attributes[$handle] = $attributes; } static function add_script_tag_attributes($tag, $handle, $src) { if ($attributes = self::tag_attributes[$handle]) { $tag = str_replace( " src='${src}'>", " src='${src}' ".$attributes.">", $tag ); } return $tag; } } // Initize by connecting to the WordPress hook add_filter( 'script_loader_tag', array(ResourceEnqueuerUtils::class, 'add_script_tag_attributes'), PHP_INT_MAX, 3 );Atrybuty dla zasobu dodajemy podczas tworzenia odpowiedniej instancji obiektu:
abstract class ResourceBase implements Resource { // Continued from above... function __construct() { ResourceEnqueuerUtils::add_tag_attributes($this->get_filename(), $this->get_attributes()); } } Wreszcie, jeśli zasób welcomeuser-data.js nie musi być wykonywany natychmiast, możemy ustawić go jako defer :
class WelcomeUserDataUserResource extends UserResourceBase { // Continued from above... function get_attributes() { return "defer='defer'"; } }Ponieważ jest ładowany jako odroczony, skrypt zostanie załadowany później, przenosząc punkt w czasie, w którym użytkownik może wejść w interakcję z witryną. Jeśli chodzi o wzrost wydajności, wszyscy jesteśmy już gotowi!
Pozostaje jeszcze jeden problem do rozwiązania, zanim będziemy mogli się zrelaksować: co się dzieje, gdy witryna jest hostowana na wielu serwerach?
Radzenie sobie z wieloma serwerami za Load Balancer
Jeśli nasza strona jest hostowana na kilku stronach za load balancerem, a plik zależny od konfiguracji użytkownika jest regenerowany, serwer obsługujący żądanie musi w jakiś sposób przesłać zregenerowany plik statyczny na wszystkie inne serwery; w przeciwnym razie inne serwery będą od tego momentu udostępniać przestarzałą wersję tego pliku. Jak to robimy? Komunikacja między serwerami jest nie tylko skomplikowana, ale może ostatecznie okazać się niewykonalna: Co się stanie, jeśli witryna będzie działać na setkach serwerów z różnych regionów? Oczywiście to nie jest opcja.
Rozwiązanie, które wymyśliłem, polega na dodaniu poziomu niebezpośredniości: zamiast żądać plików statycznych z adresu URL witryny, są one żądane z lokalizacji w chmurze, na przykład z zasobnika AWS S3. Następnie, po zregenerowaniu pliku, serwer natychmiast prześle nowy plik do S3 i obsłuży go stamtąd. Implementacja tego rozwiązania została wyjaśniona w moim poprzednim artykule Udostępnianie danych między wieloma serwerami za pośrednictwem AWS S3.
Wniosek
W tym artykule uznaliśmy, że wstawianie kodu JS i CSS nie zawsze jest idealne, ponieważ kod musi być wielokrotnie wysyłany do klienta, co może mieć wpływ na wydajność, jeśli ilość kodu jest znaczna. Jako przykład widzieliśmy, jak WordPress ładuje 43 KB skryptów do drukowania Media Managera, które są czystymi szablonami JavaScript i mogą być doskonale załadowane jako zasoby statyczne.
Dlatego opracowaliśmy sposób na przyspieszenie strony internetowej poprzez przekształcenie dynamicznego kodu inline JS i CSS w zasoby statyczne, co może usprawnić buforowanie na kilku poziomach (w kliencie, Service Workers, CDN), pozwala na dalsze łączenie wszystkich plików w jedną całość w jeden zasób JS/CSS, aby poprawić współczynnik kompresji danych wyjściowych (np. przez GZip) i uniknąć obciążenia przeglądarek związanych z przetwarzaniem kilku zasobów jednocześnie (np. w Chrome), a dodatkowo umożliwia dodawanie atrybutów async lub defer do tagu <script> , aby przyspieszyć interaktywność użytkownika, poprawiając w ten sposób pozorny czas ładowania witryny.
Korzystnym efektem ubocznym jest podzielenie kodu na zasoby statyczne, dzięki czemu kod jest bardziej czytelny, radząc sobie z jednostkami kodu zamiast dużymi blobami HTML, co może prowadzić do lepszego utrzymania projektu.
Opracowane przez nas rozwiązanie zostało wykonane w PHP i zawiera kilka specyficznych fragmentów kodu dla WordPressa, jednak sam kod jest niezwykle prosty, zaledwie kilka interfejsów definiujących właściwości i obiekty implementujące te właściwości zgodnie z zasadami SOLID oraz funkcję zapisywania plik na dysk. To prawie wszystko. Efekt końcowy jest czysty i kompaktowy, prosty do odtworzenia dla dowolnego innego języka i platformy oraz łatwy do wprowadzenia do istniejącego projektu — zapewniając łatwy wzrost wydajności.