
Utrzymywanie szybkości Node.js: narzędzia, techniki i wskazówki dotyczące tworzenia wysokowydajnych serwerów Node.js
Opublikowany: 2022-03-10Jeśli budowałeś coś w Node.js wystarczająco długo, to bez wątpienia doświadczyłeś bólu związanego z nieoczekiwanymi problemami z szybkością. JavaScript jest językiem zdarzeń, asynchronicznym. To może utrudnić rozumowanie dotyczące wydajności , co stanie się oczywiste. Rosnąca popularność Node.js ujawniła potrzebę narzędzi, technik i myślenia dostosowanych do ograniczeń JavaScript po stronie serwera.
Jeśli chodzi o wydajność, to, co działa w przeglądarce, niekoniecznie pasuje do Node.js. Jak więc upewnić się, że implementacja Node.js jest szybka i odpowiednia do celu? Przejdźmy przez praktyczny przykład.
Narzędzia
Node to bardzo wszechstronna platforma, ale jedną z dominujących aplikacji jest tworzenie procesów sieciowych. Skoncentrujemy się na profilowaniu najczęstszych z nich: serwerów WWW HTTP.
Będziemy potrzebować narzędzia, które może wysadzić serwer wieloma żądaniami, jednocześnie mierząc wydajność. Na przykład możemy użyć AutoCannon:
npm install -g autocannonInne dobre narzędzia do benchmarkingu HTTP to Apache Bench (ab) i wrk2, ale AutoCannon jest napisany w Node, zapewnia podobną (a czasami większą) presję obciążenia i jest bardzo łatwy do zainstalowania w systemach Windows, Linux i Mac OS X.
Po ustaleniu podstawowego pomiaru wydajności, jeśli uznamy, że nasz proces może być szybszy, będziemy potrzebować sposobu na zdiagnozowanie problemów z procesem. Świetnym narzędziem do diagnozowania różnych problemów z wydajnością jest Node Clinic, które można również zainstalować z npm:
npm install -g clinicTo faktycznie instaluje zestaw narzędzi. Będziemy używać Clinic Doctor i Clinic Flame (opakowanie około 0x).
Uwaga : W tym praktycznym przykładzie będziemy potrzebować węzła 8.11.2 lub nowszego.
Kod
Nasz przykładowy przypadek to prosty serwer REST z pojedynczym zasobem: duży ładunek JSON uwidoczniony jako trasa GET w /seed/v1 . Serwer to folder app , który składa się z pliku package.json (w zależności od restify 7.1.0 ), pliku index.js i pliku util.js.
Plik index.js dla naszego serwera wygląda tak:
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) Ten serwer jest reprezentatywny dla typowego przypadku serwowania zawartości dynamicznej z pamięci podręcznej klienta. Osiąga się to za pomocą oprogramowania pośredniczącego etagger , które oblicza nagłówek ETag dla najnowszego stanu zawartości.
Plik util.js zawiera elementy implementacyjne, które byłyby powszechnie używane w takim scenariuszu, funkcję do pobierania odpowiedniej treści z zaplecza, oprogramowanie pośredniczące etag oraz funkcję znacznika czasu, która dostarcza znaczniki czasu z minuty na minutę:
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }W żadnym wypadku nie traktuj tego kodu jako przykładu najlepszych praktyk! W tym pliku jest wiele zapachów kodu, ale zlokalizujemy je podczas pomiaru i profilowania aplikacji.
Aby uzyskać pełne źródło dla naszego punktu startowego, powolny serwer można znaleźć tutaj.
Profilowy
Do profilowania potrzebujemy dwóch terminali, jednego do uruchomienia aplikacji, a drugiego do testowania obciążenia.
W jednym terminalu, w ramach app , możemy uruchomić folder:
node index.jsW innym terminalu możemy to sprofilować tak:
autocannon -c100 localhost:3000/seed/v1Spowoduje to otwarcie 100 jednoczesnych połączeń i bombardowanie serwera żądaniami przez dziesięć sekund.
Wyniki powinny być podobne do następujących (Test 10s biegania @ https://localhost:3000/seed/v1 — 100 połączeń):
| Stat | Średnia | Stdev | Maks. |
|---|---|---|---|
| Opóźnienie (ms) | 3086,81 | 1725.2 | 5554 |
| Żądanie/s | 23,1 | 19.18 | 65 |
| Bajty/s | 237,98 kB | 197,7 kB | 688,13 kB |
Wyniki będą się różnić w zależności od maszyny. Jednak biorąc pod uwagę, że serwer Node.js „Hello World” jest w stanie z łatwością obsłużyć trzydzieści tysięcy żądań na sekundę na maszynie, która wygenerowała te wyniki, 23 żądania na sekundę ze średnim opóźnieniem przekraczającym 3 sekundy są ponure.
Diagnozowanie
Odkrywanie problematycznego obszaru
Możemy zdiagnozować aplikację jednym poleceniem, dzięki poleceniu Clinic Doctor –on-port. W folderze app uruchamiamy:
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsSpowoduje to utworzenie pliku HTML, który zostanie automatycznie otwarty w naszej przeglądarce po zakończeniu profilowania.
Wyniki powinny wyglądać mniej więcej tak:
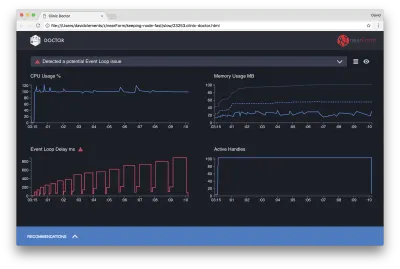
Doktor mówi nam, że prawdopodobnie mieliśmy problem z pętlą zdarzeń.
Wraz z komunikatem w górnej części interfejsu widzimy również, że wykres pętli zdarzeń jest czerwony i pokazuje stale rosnące opóźnienie. Zanim zagłębimy się w to, co to oznacza, najpierw zrozummy, jaki wpływ ma zdiagnozowany problem na inne wskaźniki.
Widzimy, że procesor stale osiąga lub przekracza 100%, ponieważ proces ciężko pracuje, aby przetworzyć żądania w kolejce. Silnik JavaScript Node (V8) faktycznie używa w tym przypadku dwóch rdzeni procesora, ponieważ maszyna jest wielordzeniowa, a V8 używa dwóch wątków. Jeden dla pętli wydarzeń, a drugi dla zbierania śmieci. Kiedy widzimy, że procesor w niektórych przypadkach osiąga 120%, proces gromadzi obiekty związane z obsłużonymi żądaniami.
Widzimy to skorelowane na wykresie pamięci. Linia ciągła na wykresie Pamięć to metryka Wykorzystana sterta. Za każdym razem, gdy występuje skok w procesorze, widzimy spadek w wierszu Używana sterta, co pokazuje, że pamięć jest zwalniana.
Opóźnienie pętli zdarzeń nie ma wpływu na aktywne uchwyty. Aktywny uchwyt to obiekt, który reprezentuje we/wy (np. gniazdo lub uchwyt pliku) lub zegar (np. setInterval ). Poleciliśmy AutoCannon otworzyć 100 połączeń ( -c100 ). Aktywne uchwyty pozostają niezmienną liczbą 103. Pozostałe trzy to uchwyty STDOUT, STDERR i uchwyt dla samego serwera.
Jeśli klikniemy panel Rekomendacje u dołu ekranu, powinniśmy zobaczyć coś takiego:
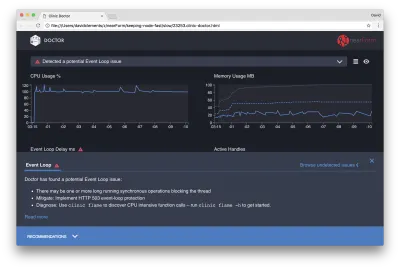
Łagodzenie krótkoterminowe
Analiza głównych przyczyn poważnych problemów z wydajnością może zająć trochę czasu. W przypadku projektu wdrożonego na żywo warto dodać ochronę przed przeciążeniem serwerów lub usług. Ideą ochrony przed przeciążeniem jest monitorowanie opóźnienia pętli zdarzeń (między innymi) i reagowanie komunikatem „503 Usługa niedostępna” w przypadku przekroczenia progu. Pozwala to systemowi równoważenia obciążenia na przełączanie awaryjne do innych instancji lub w najgorszym przypadku oznacza, że użytkownicy będą musieli odświeżyć. Moduł ochrony przed przeciążeniem może zapewnić to przy minimalnym obciążeniu dla Express, Koa i Restify. Struktura Hapi ma ustawienie konfiguracji ładowania, które zapewnia taką samą ochronę.
Zrozumienie obszaru problemu
Jak wyjaśnia krótkie wyjaśnienie w Clinic Doctor, jeśli pętla zdarzeń jest opóźniona do obserwowanego przez nas poziomu, jest bardzo prawdopodobne, że jedna lub więcej funkcji „blokuje” pętlę zdarzeń.
W przypadku Node.js szczególnie ważne jest rozpoznanie tej podstawowej cechy JavaScript: zdarzenia asynchroniczne nie mogą wystąpić, dopóki aktualnie wykonywany kod nie zostanie zakończony.
Dlatego setTimeout nie może być precyzyjny.
Na przykład spróbuj uruchomić następujące polecenie w DevTools przeglądarki lub Node REPL:
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() Wynikowy pomiar czasu nigdy nie będzie wynosił 100ms. Prawdopodobnie będzie to zakres od 150ms do 250ms. setTimeout zaplanował operację asynchroniczną ( console.timeEnd ), ale aktualnie wykonywany kod nie został jeszcze ukończony; są jeszcze dwie linie. Aktualnie wykonywany kod jest znany jako bieżący „tick”. Aby tik się zakończył, Math.random musi zostać wywołane dziesięć milionów razy. Jeśli zajmie to 100 ms, całkowity czas przed upływem limitu czasu wyniesie 200 ms (plus czas potrzebny funkcji setTimeout na zakolejkowanie limitu czasu, zwykle kilka milisekund).
W kontekście po stronie serwera, jeśli operacja w bieżącym takcie zajmuje dużo czasu, nie można obsłużyć żądań, a pobieranie danych nie może nastąpić, ponieważ kod asynchroniczny nie zostanie wykonany, dopóki bieżący takt nie zostanie zakończony. Oznacza to, że kosztowny obliczeniowo kod spowolni wszystkie interakcje z serwerem. Dlatego zaleca się rozdzielenie pracy wymagającej dużej ilości zasobów na oddzielne procesy i wywoływanie ich z serwera głównego, co pozwoli uniknąć przypadków, w których na rzadko używanej, ale drogiej trasie spowalnia działanie innych często używanych, ale niedrogich tras.
Przykładowy serwer zawiera kod, który blokuje pętlę zdarzeń, więc następnym krokiem jest zlokalizowanie tego kodu.
Analizowanie
Jednym ze sposobów szybkiego zidentyfikowania słabo działającego kodu jest utworzenie i przeanalizowanie wykresu płomienia. Wykres płomienia przedstawia wywołania funkcji jako bloki leżące jeden na drugim — nie w czasie, ale łącznie. Powodem, dla którego nazywa się go „wykresem płomienia”, jest to, że zazwyczaj używa schematu kolorów od pomarańczowego do czerwonego, gdzie im bardziej czerwony blok jest „gorętszy” funkcja, co oznacza, że bardziej prawdopodobne jest, że blokuje pętlę zdarzeń. Przechwytywanie danych dla wykresu płomienia odbywa się poprzez próbkowanie procesora — co oznacza, że wykonywana jest migawka aktualnie wykonywanej funkcji i jej stosu. Ciepło jest określane przez procent czasu podczas profilowania, w którym dana funkcja znajduje się na szczycie stosu (np. funkcja aktualnie wykonywana) dla każdej próbki. Jeśli nie jest to ostatnia funkcja, która została kiedykolwiek wywołana na tym stosie, prawdopodobnie blokuje pętlę zdarzeń.
Użyjmy clinic flame do wygenerowania wykresu płomienia przykładowej aplikacji:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsWynik powinien otworzyć się w naszej przeglądarce z czymś podobnym do następującego:
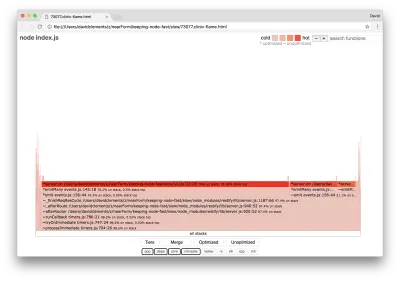
Szerokość bloku reprezentuje całkowity czas poświęcony na procesor. Można zaobserwować trzy główne stosy, które zajmują najwięcej czasu, z których wszystkie wyróżniają server.on jako najgorętszą funkcję. W rzeczywistości wszystkie trzy stosy są takie same. Różnią się one, ponieważ podczas profilowania funkcje zoptymalizowane i niezoptymalizowane są traktowane jako osobne ramki wywołań. Funkcje poprzedzone * są optymalizowane przez silnik JavaScript, a te poprzedzone znakiem ~ są niezoptymalizowane. Jeśli zoptymalizowany stan nie jest dla nas ważny, możemy jeszcze bardziej uprościć wykres, naciskając przycisk Scal. Powinno to prowadzić do widoku podobnego do następującego:
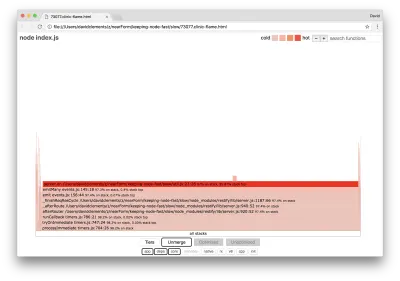
Od samego początku możemy wywnioskować, że obraźliwy kod znajduje się w pliku util.js kodu aplikacji.
Powolna funkcja jest również obsługą zdarzeń: funkcje prowadzące do funkcji są częścią podstawowego modułu events , a server.on jest nazwą rezerwową anonimowej funkcji dostarczanej jako funkcja obsługi zdarzeń. Widzimy również, że ten kod nie znajduje się w tym samym tiku, co kod, który faktycznie obsługuje żądanie. Gdyby tak było, na stosie znalazłyby się funkcje z podstawowych modułów http , net i stream .
Takie podstawowe funkcje można znaleźć poprzez rozwinięcie innych, znacznie mniejszych części wykresu płomienia. Na przykład spróbuj użyć danych wejściowych wyszukiwania w prawym górnym rogu interfejsu użytkownika, aby wyszukać send (nazwę zarówno wewnętrznej metody restify , jak i http ). Powinien znajdować się po prawej stronie wykresu (funkcje są posortowane alfabetycznie):
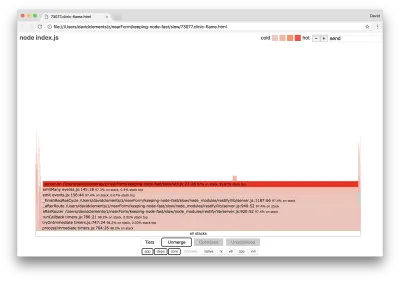
Zwróć uwagę, jak stosunkowo małe są wszystkie rzeczywiste bloki obsługi HTTP.

Możemy kliknąć jeden z bloków podświetlonych na niebiesko, które rozwiną się, aby pokazać funkcje takie jak writeHead i write w pliku http_outgoing.js (część biblioteki http Node core):
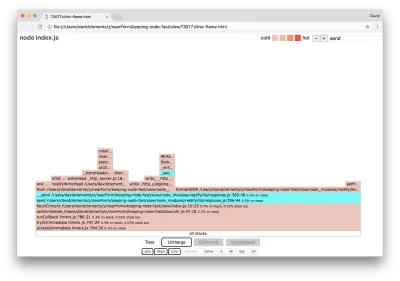
Możemy kliknąć wszystkie stosy , aby powrócić do głównego widoku.
Kluczowym punktem tutaj jest to, że chociaż funkcja server.on nie znajduje się w tym samym tiku, co rzeczywisty kod obsługi żądań, nadal wpływa na ogólną wydajność serwera, opóźniając wykonanie kodu, który w przeciwnym razie byłby wydajny.
Debugowanie
Z wykresu płomienia wiemy, że problematyczną funkcją jest handler zdarzeń przekazany do server.on w pliku util.js.
Spójrzmy:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) Powszechnie wiadomo, że kryptografia bywa droga, podobnie jak serializacja ( JSON.stringify ), ale dlaczego nie pojawiają się na wykresie płomienia? Te operacje znajdują się w przechwyconych próbkach, ale są ukryte za filtrem cpp . Jeśli naciśniemy przycisk cpp , powinniśmy zobaczyć coś takiego:
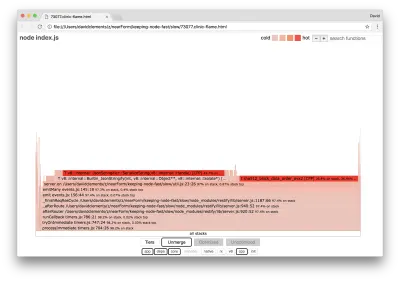
Wewnętrzne instrukcje V8 dotyczące zarówno serializacji, jak i kryptografii są teraz wyświetlane jako najgorętsze stosy i zajmują większość czasu. Metoda JSON.stringify bezpośrednio wywołuje kod C++; dlatego nie widzimy funkcji JavaScript. W przypadku kryptografii funkcje takie jak createHash i update znajdują się w danych, ale są one albo wbudowane (co oznacza, że znikają w widoku scalonym), albo są zbyt małe do renderowania.
Kiedy już zaczniemy myśleć o kodzie w funkcji etagger , szybko może się okazać, że jest on kiepsko zaprojektowany. Dlaczego pobieramy instancję server z kontekstu funkcji? Dużo się dzieje, czy to wszystko jest konieczne? W implementacji nie ma również obsługi nagłówka If-None-Match , co zmniejszyłoby część obciążenia w niektórych rzeczywistych scenariuszach, ponieważ klienci wysyłaliby tylko żądanie nagłówka w celu określenia świeżości.
Zignorujmy na razie wszystkie te punkty i zweryfikujmy stwierdzenie, że rzeczywista praca wykonywana w server.on jest rzeczywiście wąskim gardłem. Można to osiągnąć poprzez ustawienie kodu server.on na pustą funkcję i wygenerowanie nowego flamegrafa.
Zmień funkcję etagger na następującą:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } Funkcja nasłuchiwania zdarzeń przekazana do server.on jest teraz no-op.
Uruchommy ponownie clinic flame :
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsPowinno to dać wykres płomienia podobny do następującego:
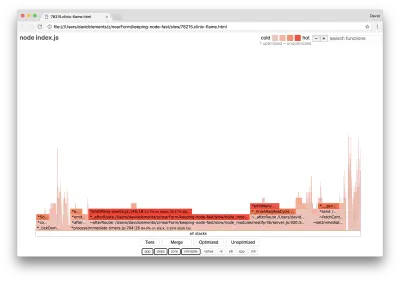
Wygląda to lepiej i powinniśmy zauważyć wzrost liczby żądań na sekundę. Ale dlaczego kod emitujący zdarzenie jest tak gorący? Spodziewalibyśmy się, że w tym momencie kod przetwarzania HTTP zajmie większość czasu procesora, ponieważ w zdarzeniu server.on nic się nie wykonuje.
Ten rodzaj wąskiego gardła jest spowodowany tym, że funkcja jest wykonywana częściej niż powinna.
Wskazówką może być następujący podejrzany kod w górnej części util.js :
require('events').defaultMaxListeners = Infinity Usuńmy tę linię i rozpocznijmy nasz proces z --trace-warnings :
node --trace-warnings index.jsJeśli profilujemy za pomocą AutoCannona w innym terminalu, to tak:
autocannon -c100 localhost:3000/seed/v1Nasz proces wygeneruje coś podobnego do:
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Node informuje nas, że do obiektu serwera jest dołączanych wiele zdarzeń. Jest to dziwne, ponieważ istnieje wartość logiczna, która sprawdza, czy zdarzenie zostało dołączone, a następnie zwraca wcześnie, co zasadniczo powoduje, że attachAfterEvent nie wykonuje operacji po dołączeniu pierwszego zdarzenia.
Przyjrzyjmy się funkcji attachAfterEvent :
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } Kontrola warunkowa jest błędna! Sprawdza, czy attachAfterEvent jest true zamiast afterEventAttached . Oznacza to, że przy każdym żądaniu do instancji server dołączane jest nowe zdarzenie, a po każdym żądaniu uruchamiane są wszystkie wcześniej dołączone zdarzenia. Ups!
Optymalizacja
Teraz, gdy odkryliśmy obszary problemowe, zobaczmy, czy możemy przyspieszyć serwer.
Nisko wiszący owoc
Wstawmy kod odbiornika server.on z powrotem (zamiast pustej funkcji) i użyjmy poprawnej nazwy logicznej w sprawdzaniu warunkowym. Nasza funkcja etagger wygląda następująco:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }Teraz sprawdzamy naszą poprawkę, ponownie profilując. Uruchom serwer w jednym terminalu:
node index.jsNastępnie profil z AutoCannon:
autocannon -c100 localhost:3000/seed/v1 Powinniśmy zobaczyć wyniki gdzieś w zakresie 200-krotnej poprawy (test Running 10s @ https://localhost:3000/seed/v1 — 100 połączeń):
| Stat | Średnia | Stdev | Maks. |
|---|---|---|---|
| Opóźnienie (ms) | 19.47 | 4.29 | 103 |
| Żądanie/s | 5011.11 | 506,2 | 5487 |
| Bajty/s | 51,8 MB | 5,45 MB | 58,72 MB |
Ważne jest, aby zrównoważyć potencjalną redukcję kosztów serwera z kosztami rozwoju. Musimy określić, w naszych własnych kontekstach sytuacyjnych, jak daleko musimy posunąć się w optymalizacji projektu. W przeciwnym razie może być zbyt łatwo włożyć 80% wysiłku w 20% ulepszeń prędkości. Czy ograniczenia projektu to uzasadniają?
W niektórych sytuacjach właściwe może być osiągnięcie 200-krotnej poprawy za pomocą nisko wiszącego owocu i nazwanie tego dniem. W innych możemy chcieć, aby nasza implementacja była tak szybka, jak to tylko możliwe. To naprawdę zależy od priorytetów projektu.
Jednym ze sposobów kontrolowania wydatków na zasoby jest wyznaczenie celu. Na przykład 10-krotna poprawa lub 4000 żądań na sekundę. Oparcie tego na potrzebach biznesowych ma największy sens. Na przykład, jeśli koszty serwerów przekraczają budżet o 100%, możemy ustawić cel w postaci dwukrotnej poprawy.
Idąc dalej
Jeśli stworzymy nowy wykres płomienia naszego serwera, powinniśmy zobaczyć coś podobnego do następującego:
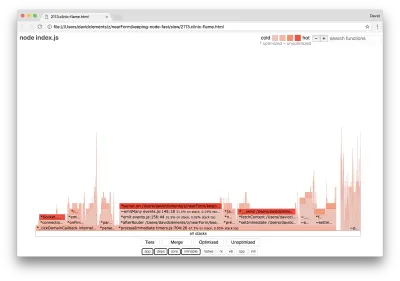
Wąskim gardłem nadal jest detektor zdarzeń, który podczas profilowania nadal zajmuje jedną trzecią czasu procesora (szerokość wynosi około jednej trzeciej całego wykresu).
Jakie dodatkowe korzyści można osiągnąć i czy warto wprowadzić zmiany (wraz z ich zakłóceniami)?
Dzięki zoptymalizowanej implementacji, która jest jednak nieco bardziej ograniczona, można osiągnąć następujące charakterystyki wydajności (test 10 s. @ https://localhost:3000/seed/v1 — 10 połączeń):
| Stat | Średnia | Stdev | Maks. |
|---|---|---|---|
| Opóźnienie (ms) | 0,64 | 0,86 | 17 |
| Żądanie/s | 8330,91 | 757,63 | 8991 |
| Bajty/s | 84,17 MB | 7,64 MB | 92,27 MB |
Chociaż poprawa 1,6x jest znacząca, można twierdzić, że wysiłek, zmiany i zakłócenia kodu niezbędne do stworzenia tego ulepszenia są uzasadnione w zależności od sytuacji. Zwłaszcza w porównaniu z 200-krotną poprawą oryginalnej implementacji z jedną poprawką błędu.
Aby osiągnąć to ulepszenie, użyto tej samej iteracyjnej techniki profilowania, generowania płomienia, analizowania, debugowania i optymalizacji, aby dotrzeć do ostatecznego zoptymalizowanego serwera, którego kod można znaleźć tutaj.
Ostateczne zmiany, aby osiągnąć 8000 wymagań/s, to:
- Nie twórz obiektów, a następnie serializuj, skompiluj bezpośrednio ciąg JSON;
- Użyj czegoś unikalnego w treści, aby zdefiniować Etag, zamiast tworzyć hash;
- Nie mieszaj adresu URL, użyj go bezpośrednio jako klucza.
Te zmiany są nieco bardziej skomplikowane, nieco bardziej zakłócają podstawę kodu i sprawiają, że oprogramowanie pośredniczące etagger jest nieco mniej elastyczne, ponieważ obciąża trasę, aby zapewnić wartość Etag . Ale osiąga dodatkowe 3000 żądań na sekundę na maszynie do profilowania.
Rzućmy okiem na wykres płomienia dla tych ostatnich ulepszeń:
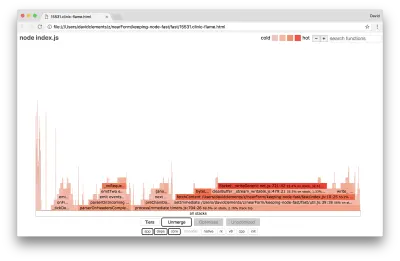
Najgorętsza część wykresu płomienia jest częścią rdzenia węzła w module net . To jest idealne.
Zapobieganie problemom z wydajnością
Na zakończenie przedstawiamy kilka sugestii dotyczących sposobów zapobiegania problemom z wydajnością przed ich wdrożeniem.
Używanie narzędzi wydajnościowych jako nieformalnych punktów kontrolnych podczas opracowywania może odfiltrować błędy wydajności, zanim trafią one do produkcji. Zaleca się, aby AutoCannon i Clinic (lub ich odpowiedniki) stały się częścią codziennych narzędzi programistycznych.
Kupując w ramach frameworka, dowiedz się, jakie są jego zasady dotyczące wydajności. Jeśli struktura nie określa priorytetów wydajności, ważne jest, aby sprawdzić, czy jest to zgodne z praktykami infrastrukturalnymi i celami biznesowymi. Na przykład Restify wyraźnie (od czasu wydania wersji 7) zainwestowało w poprawę wydajności biblioteki. Jeśli jednak niski koszt i wysoka prędkość są absolutnym priorytetem, rozważ Fastify, które zostało zmierzone jako 17% szybsze przez współtwórcę Restify.
Uważaj na inne opcje, które mają duży wpływ na bibliotekę — szczególnie rozważ rejestrowanie. Gdy programiści rozwiązują problemy, mogą zdecydować się na dodanie dodatkowych danych wyjściowych dziennika, aby pomóc w debugowaniu powiązanych problemów w przyszłości. Jeśli używany jest niesprawny rejestrator, może to z czasem zdusić wydajność, podobnie jak w bajce o gotującej się żabie. Logger pino jest najszybszym loggerem JSON rozdzielanym znakami nowej linii dostępnym dla Node.js.
Na koniec zawsze pamiętaj, że pętla zdarzeń jest zasobem udostępnionym. Serwer Node.js jest ostatecznie ograniczony przez najwolniejszą logikę na najgorętszej ścieżce.