
Rozpocznij pracę z węzłem: wprowadzenie do API, HTTP i ES6+ JavaScript
Opublikowany: 2022-03-10Prawdopodobnie słyszałeś, że Node.js jest „asynchronicznym środowiskiem wykonawczym JavaScript zbudowanym na silniku JavaScript V8 w przeglądarce Chrome” i że „używa opartego na zdarzeniach, nieblokującego modelu we/wy, który czyni go lekkim i wydajnym”. Ale dla niektórych nie jest to najlepsze wyjaśnienie.
Czym jest Węzeł w pierwszej kolejności? Co dokładnie oznacza, że Node jest „asynchroniczny” i czym różni się to od „synchronicznego”? Co właściwie oznacza „sterowany zdarzeniami” i „nieblokujący” i jak Node pasuje do szerszego obrazu aplikacji, sieci internetowych i serwerów?
Postaramy się odpowiedzieć na wszystkie te pytania i nie tylko w tej serii, gdy przyjrzymy się dogłębnie wewnętrznemu działaniu Node, poznamy protokół przesyłania hipertekstu, interfejsy API i JSON oraz zbudujemy nasz własny interfejs API półki na książki z wykorzystaniem MongoDB, Express, Lodash, Mocha i Kierownice.
Co to jest Node.js
Węzeł to tylko środowisko lub środowisko wykonawcze, w którym można uruchamiać normalny JavaScript (z niewielkimi różnicami) poza przeglądarką. Możemy go używać do tworzenia aplikacji desktopowych (z frameworkami takimi jak Electron), pisania serwerów internetowych lub aplikacji i nie tylko.
Blokujące/nieblokujące i synchroniczne/asynchroniczne
Załóżmy, że wykonujemy wywołanie bazy danych, aby pobrać właściwości dotyczące użytkownika. To wywołanie zajmie trochę czasu, a jeśli żądanie „blokuje”, oznacza to, że zablokuje wykonanie naszego programu, dopóki wywołanie nie zostanie zakończone. W tym przypadku wykonaliśmy żądanie „synchroniczne”, ponieważ ostatecznie zablokowało to wątek.
Tak więc operacja synchroniczna blokuje proces lub wątek do momentu zakończenia tej operacji, pozostawiając wątek w „stanie oczekiwania”. Z drugiej strony operacja asynchroniczna nie blokuje . Pozwala na kontynuowanie wykonywania wątku niezależnie od czasu potrzebnego na zakończenie operacji lub wyniku, z którym się kończy, a żadna część wątku nie przechodzi w stan oczekiwania w żadnym momencie.
Spójrzmy na inny przykład wywołania synchronicznego , które blokuje wątek. Załóżmy, że tworzymy aplikację, która porównuje wyniki dwóch interfejsów Weather API, aby znaleźć ich procentową różnicę temperatur. W sposób blokujący wywołujemy Weather API One i czekamy na wynik. Gdy otrzymamy wynik, wywołujemy Weather API Two i czekamy na jego wynik. Nie martw się w tym momencie, jeśli nie znasz interfejsów API. Omówimy je w następnej sekcji. Na razie pomyśl o interfejsie API jako o medium, za pośrednictwem którego dwa komputery mogą się ze sobą komunikować.
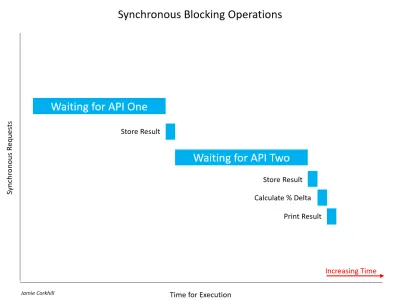
Pozwolę sobie zauważyć, że ważne jest, aby pamiętać, że nie wszystkie wywołania synchroniczne są koniecznie blokujące. Jeśli operacja synchroniczna może zakończyć się bez blokowania wątku lub powodowania stanu oczekiwania, oznacza to, że nie była blokowana. W większości przypadków wywołania synchroniczne będą blokowane, a czas ich wykonania będzie zależał od wielu czynników, takich jak szybkość serwerów API, szybkość pobierania połączenia internetowego użytkownika końcowego itp.
W przypadku powyższego obrazka musieliśmy trochę poczekać na pobranie pierwszych wyników z API One. Następnie musieliśmy czekać równie długo na odpowiedź od API Two. Podczas oczekiwania na obie odpowiedzi użytkownik zauważyłby, że nasza aplikacja zawiesiła się — interfejs użytkownika dosłownie się zawiesił — a to byłoby złe dla User Experience.
W przypadku połączenia nieblokującego mielibyśmy coś takiego:

Widać wyraźnie, o ile szybciej zakończyliśmy egzekucję. Zamiast czekać na API One, a potem czekać na API Two, moglibyśmy poczekać, aż oba z nich zakończą się w tym samym czasie i osiągnąć nasze wyniki prawie o 50% szybciej. Zauważ, że kiedy wywołaliśmy API One i zaczęliśmy czekać na jego odpowiedź, wywołaliśmy również API Two i zaczęliśmy czekać na jego odpowiedź w tym samym czasie, co One.
W tym momencie, zanim przejdziemy do bardziej konkretnych i namacalnych przykładów, należy wspomnieć, że dla ułatwienia termin „Synchroniczny” jest ogólnie skracany do „Synchroniczny”, a termin „Asynchroniczny” jest ogólnie skracany do „Async”. Zobaczysz ten zapis używany w nazwach metod/funkcji.
Funkcje zwrotne
Być może zastanawiasz się, „jeśli możemy obsłużyć połączenie asynchronicznie, skąd mamy wiedzieć, kiedy połączenie zostało zakończone i otrzymaliśmy odpowiedź?” Ogólnie rzecz biorąc, przekazujemy jako argument do naszej metody asynchronicznej funkcję zwrotną, a ta metoda „oddzwoni” do tej funkcji w późniejszym czasie z odpowiedzią. Używam tutaj funkcji ES5, ale później zaktualizujemy do standardów ES6.
function asyncAddFunction(a, b, callback) { callback(a + b); //This callback is the one passed in to the function call below. } asyncAddFunction(2, 4, function(sum) { //Here we have the sum, 2 + 4 = 6. }); Taka funkcja jest nazywana „Funkcją wyższego rzędu”, ponieważ przyjmuje funkcję (nasz callback) jako argument. Alternatywnie funkcja wywołania zwrotnego może przyjąć obiekt błędu i obiekt odpowiedzi jako argumenty i przedstawić je po zakończeniu funkcji asynchronicznej. Zobaczymy to później w programie Express. Kiedy asyncAddFunction(...) , zauważysz, że dostarczyliśmy funkcję wywołania zwrotnego dla parametru wywołania zwrotnego z definicji metody. Ta funkcja jest funkcją anonimową (nie ma nazwy) i jest napisana przy użyciu składni wyrażeń . Z drugiej strony definicja metody jest instrukcją funkcyjną. Nie jest anonimowy, ponieważ faktycznie ma nazwę (czyli „asyncAddFunction”).
Niektórzy mogą zauważyć zamieszanie, ponieważ w definicji metody podajemy nazwę, która jest „oddzwonieniem”. Jednak funkcja anonimowa przekazana jako trzeci parametr do asyncAddFunction(...) nie zna nazwy, więc pozostaje anonimowa. Nie możemy również wykonać tej funkcji później według nazwy, musielibyśmy ponownie przejść przez funkcję wywołania asynchronicznego, aby ją uruchomić.
Jako przykład wywołania synchronicznego możemy użyć metody Node.js readFileSync(...) . Ponownie przejdziemy do ES6+ później.
var fs = require('fs'); var data = fs.readFileSync('/example.txt'); // The thread will be blocked here until complete.Gdybyśmy robili to asynchronicznie, przekazalibyśmy funkcję zwrotną, która zostanie uruchomiona po zakończeniu operacji asynchronicznej.
var fs = require('fs'); var data = fs.readFile('/example.txt', function(err, data) { //Move on, this will fire when ready. if(err) return console.log('Error: ', err); console.log('Data: ', data); // Assume var data is defined above. }); // Keep executing below, don't wait on the data. Jeśli nigdy wcześniej nie widziałeś return używanego w ten sposób, mówimy po prostu, aby zatrzymać wykonywanie funkcji, więc nie wypisujemy obiektu danych, jeśli zdefiniowany jest obiekt błędu. Mogliśmy również po prostu umieścić instrukcję log w klauzuli else .
Podobnie jak w przypadku naszego asyncAddFunction(...) , kod za fs.readFile(...) następująco:
function readFile(path, callback) { // Behind the scenes code to read a file stream. // The data variable is defined up here. callback(undefined, data); //Or, callback(err, undefined); }Pozwól nam spojrzeć na ostatnią implementację wywołania funkcji asynchronicznej. Pomoże to utrwalić ideę, że funkcje zwrotne będą uruchamiane w późniejszym czasie i pomoże nam zrozumieć wykonanie typowego programu Node.js.
setTimeout(function() { // ... }, 1000); Metoda setTimeout(...) przyjmuje funkcję zwrotną dla pierwszego parametru, która zostanie wywołana po wystąpieniu liczby milisekund określonej jako drugi argument.
Spójrzmy na bardziej złożony przykład:
console.log('Initiated program.'); setTimeout(function() { console.log('3000 ms (3 sec) have passed.'); }, 3000); setTimeout(function() { console.log('0 ms (0 sec) have passed.'); }, 0); setTimeout(function() { console.log('1000 ms (1 sec) has passed.'); }, 1000); console.log('Terminated program');Wynik jaki otrzymujemy to:
Initiated program. Terminated program. 0 ms (0 sec) have passed. 1000 ms (1 sec) has passed. 3000 ms (3 sec) have passed. Widać, że pierwsza instrukcja dziennika działa zgodnie z oczekiwaniami. Natychmiast ostatnia instrukcja dziennika jest wypisywana na ekranie, ponieważ dzieje się to przed upływem 0 sekund po drugim setTimeout(...) . Natychmiast po tym wykonywane są druga, trzecia i pierwsza metoda setTimeout(...) .
Gdyby Node.js nie był nieblokujący, zobaczylibyśmy pierwszą instrukcję log, poczekali 3 sekundy, aby zobaczyć następną, natychmiast zobaczylibyśmy trzecią (0-sekundowy setTimeout(...) , a potem musielibyśmy poczekać jeszcze jedną drugi, aby zobaczyć ostatnie dwie instrukcje dziennika. Nieblokujący charakter węzła powoduje, że wszystkie liczniki zaczynają odliczać od momentu wykonania programu, a nie kolejności, w jakiej są wpisywane.Możesz zajrzeć do interfejsów API węzła, Callstack i Event Loop, aby uzyskać więcej informacji o tym, jak Node działa pod maską.
Ważne jest, aby pamiętać, że tylko dlatego, że widzisz funkcję zwrotną, niekoniecznie oznacza to, że w kodzie jest wywołanie asynchroniczne. Nazwaliśmy asyncAddFunction(…) powyżej „async”, ponieważ zakładamy, że operacja wymaga czasu — na przykład wykonanie połączenia z serwerem. W rzeczywistości proces dodawania dwóch liczb nie jest asynchroniczny, więc byłby to przykład użycia funkcji zwrotnej w sposób, który w rzeczywistości nie blokuje wątku.
Obietnice ponad oddzwonieniami
Wywołania zwrotne mogą szybko stać się bałaganem w JavaScript, zwłaszcza wiele zagnieżdżonych wywołań zwrotnych. Jesteśmy zaznajomieni z przekazywaniem wywołania zwrotnego jako argumentu do funkcji, ale Obietnice pozwalają nam dołączyć lub dołączyć wywołanie zwrotne do obiektu zwróconego z funkcji. Umożliwiłoby nam to obsługę wielu wywołań asynchronicznych w bardziej elegancki sposób.
Jako przykład, załóżmy, że wykonujemy wywołanie API, a nasza funkcja, nie tak unikatowo nazwana ' makeAPICall(...) ', przyjmuje adres URL i wywołanie zwrotne.
Nasza funkcja makeAPICall(...) byłaby zdefiniowana jako
function makeAPICall(path, callback) { // Attempt to make API call to path argument. // ... callback(undefined, res); // Or, callback(err, undefined); depending upon the API's response. }i nazwalibyśmy to:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); // ... }); Gdybyśmy chcieli wykonać kolejne wywołanie API przy użyciu odpowiedzi z pierwszego, musielibyśmy zagnieździć oba wywołania zwrotne. Załóżmy, że muszę wstrzyknąć właściwość userName z obiektu res1 do ścieżki drugiego wywołania API. Mielibyśmy:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); makeAPICall('/newExample/' + res1.userName, function(err2, res2) { if(err2) return console.log('Error: ', err2); console.log(res2); }); }); Uwaga : Metoda ES6+ do wstrzykiwania właściwości res1.userName zamiast łączenia ciągów polega na użyciu „ciągów szablonów”. W ten sposób zamiast umieszczać nasz ciąg w cudzysłowie ( ' , lub " ), użyjemy znaku backticks ( ` ) znajdującego się pod klawiszem Escape na klawiaturze. Następnie użyjemy notacji ${} do osadzenia dowolnego wyrażenia JS wewnątrz Na koniec nasza wcześniejsza ścieżka wyglądałaby następująco: /newExample/${res.UserName} , otoczona znakami wstecznymi.
Widać wyraźnie, że ta metoda zagnieżdżania wywołań zwrotnych może szybko stać się dość nieelegancka, tak zwana „JavaScript Pyramid of Doom”. Wskakujmy, gdybyśmy używali obietnic, a nie wywołań zwrotnych, moglibyśmy przerobić nasz kod z pierwszego przykładu w taki sposób:
makeAPICall('/example').then(function(res) { // Success callback. // ... }, function(err) { // Failure callback. console.log('Error:', err); }); Pierwszym argumentem funkcji then() jest nasze wywołanie zwrotne odnoszące się do sukcesu, a drugim argumentem wywołanie zwrotne niepowodzenia. Alternatywnie, moglibyśmy stracić drugi argument do .then() i zamiast tego wywołać .catch() . Argumenty .then() są opcjonalne, a wywołanie .catch() byłoby równoważne .then(successCallback, null) .
Używając .catch() , mamy:
makeAPICall('/example').then(function(res) { // Success callback. // ... }).catch(function(err) { // Failure Callback console.log('Error: ', err); });Możemy również zrestrukturyzować to pod kątem czytelności:
makeAPICall('/example') .then(function(res) { // ... }) .catch(function(err) { console.log('Error: ', err); }); Należy zauważyć, że nie możemy po prostu dołączyć wywołania .then() do dowolnej funkcji i oczekiwać, że zadziała. Wywoływana przez nas funkcja musi faktycznie zwrócić obietnicę, obietnicę, która uruchomi .then() po zakończeniu operacji asynchronicznej. W tym przypadku makeAPICall(...) zrobi swoje, uruchamiając blok then() lub catch() po zakończeniu.
Aby makeAPICall(...) Promise, przypisujemy funkcję do zmiennej, gdzie ta funkcja jest konstruktorem Promise. Obietnice mogą być spełnione lub odrzucone , gdzie spełnione oznacza, że czynność odnosząca się do obietnicy zakończyła się pomyślnie, a odrzucona – odwrotnie. Gdy obietnica zostanie spełniona lub odrzucona, mówimy, że została uregulowana i czekając na jej uregulowanie, być może podczas połączenia asynchronicznego, mówimy, że obietnica jest w toku .
Konstruktor Promise przyjmuje jedną funkcję zwrotną jako argument, który otrzymuje dwa parametry — resolve i reject , które wywołamy w późniejszym czasie, aby wywołać pomyślne wywołanie zwrotne w .then() lub niepowodzenie .then() wywołanie zwrotne lub .catch() , jeśli podano.
Oto przykład, jak to wygląda:
var examplePromise = new Promise(function(resolve, reject) { // Do whatever we are going to do and then make the appropiate call below: resolve('Happy!'); // — Everything worked. reject('Sad!'); // — We noticed that something went wrong. }):Następnie możemy użyć:
examplePromise.then(/* Both callback functions in here */); // Or, the success callback in .then() and the failure callback in .catch(). Zauważ jednak, że examplePromise nie może przyjmować żadnych argumentów. Ten rodzaj łamie cel, więc zamiast tego możemy odwzajemnić obietnicę.
function makeAPICall(path) { return new Promise(function(resolve, reject) { // Make our async API call here. if (/* All is good */) return resolve(res); //res is the response, would be defined above. else return reject(err); //err is error, would be defined above. }); } Obietnice naprawdę lśnią, aby poprawić strukturę, a następnie elegancję naszego kodu dzięki koncepcji „Promise Chaining”. Umożliwiłoby nam to zwrócenie nowej obietnicy wewnątrz klauzuli .then() , dzięki czemu moglibyśmy dołączyć drugą .then() później, która uruchomiłaby odpowiednie wywołanie zwrotne z drugiej obietnicy.
Refaktoryzacja naszego powyższego wywołania adresu URL multi API za pomocą Promises, otrzymujemy:
makeAPICall('/example').then(function(res) { // First response callback. Fires on success to '/example' call. return makeAPICall(`/newExample/${res.UserName}`); // Returning new call allows for Promise Chaining. }, function(err) { // First failure callback. Fires if there is a failure calling with '/example'. console.log('Error:', err); }).then(function(res) { // Second response callback. Fires on success to returned '/newExample/...' call. console.log(res); }, function(err) { // Second failure callback. Fire if there is a failure calling with '/newExample/...' console.log('Error:', err); }); Zauważ, że najpierw wywołujemy makeAPICall('/example') . To zwraca obietnicę, więc dołączamy .then() . Wewnątrz tego then() , zwracamy nowe wywołanie makeAPICall(...) , które samo w sobie, jak widzieliśmy wcześniej, zwraca obietnicę, pozwalając nam połączyć nowe .then() po pierwszym.
Tak jak powyżej, możemy zmienić strukturę tego, aby uzyskać czytelność i usunąć wywołania zwrotne niepowodzenia dla ogólnej klauzuli catch() all. Następnie możemy postępować zgodnie z zasadą DRY (Nie powtarzaj się) i wystarczy zaimplementować obsługę błędów tylko raz.
makeAPICall('/example') .then(function(res) { // Like earlier, fires with success and response from '/example'. return makeAPICall(`/newExample/${res.UserName}`); // Returning here lets us chain on a new .then(). }) .then(function(res) { // Like earlier, fires with success and response from '/newExample'. console.log(res); }) .catch(function(err) { // Generic catch all method. Fires if there is an err with either earlier call. console.log('Error: ', err); }); Zauważ, że wywołania zwrotne sukcesu i niepowodzenia w .then() uruchamiane tylko dla statusu pojedynczej Promise, której odpowiada .then() . Jednak blok catch przechwyci wszelkie błędy, które zostaną wywołane w dowolnym z .then() s.
ES6 Const kontra Let
We wszystkich naszych przykładach używaliśmy funkcji ES5 i starego słowa kluczowego var . Mimo że miliony wierszy kodu nadal są uruchamiane przy użyciu tych metod ES5, warto zaktualizować do obecnych standardów ES6+, a my dokonamy refaktoryzacji części naszego kodu powyżej. Zacznijmy od const i let .
Możesz być przyzwyczajony do deklarowania zmiennej za pomocą słowa kluczowego var :
var pi = 3.14;Dzięki standardom ES6+ możemy to zrobić
let pi = 3.14;lub
const pi = 3.14; gdzie const oznacza „stałą” — wartość, której nie można później przypisać. (Z wyjątkiem właściwości obiektu — omówimy to wkrótce. Ponadto zmienne zadeklarowane jako const nie są niezmienne, jest tylko odniesienie do zmiennej.)
W starym JavaScript blokować zakresy, takie jak te w if , while , {} . for , itp. nie wpłynęły w żaden sposób na var , a to jest zupełnie inne niż w przypadku bardziej statycznych języków, takich jak Java czy C++. Oznacza to, że zakresem var jest cała otaczająca funkcja — i może to być globalna (jeśli jest umieszczona poza funkcją) lub lokalna (jeśli jest umieszczona w funkcji). Aby to zademonstrować, zobacz następujący przykład:
function myFunction() { var num = 5; console.log(num); // 5 console.log('--'); for(var i = 0; i < 10; i++) { var num = i; console.log(num); //num becomes 0 — 9 } console.log('--'); console.log(num); // 9 console.log(i); // 10 } myFunction();Wyjście:
5 --- 0 1 2 3 ... 7 8 9 --- 9 10 Należy zauważyć, że zdefiniowanie nowej var num wewnątrz zakresu for ma bezpośredni wpływ na var num poza i powyżej for . Dzieje się tak, ponieważ zasięg var jest zawsze zakresem funkcji otaczającej, a nie bloku.
Ponownie, domyślnie var i wewnątrz for() domyślnie odpowiada zakresowi myFunction , więc możemy uzyskać dostęp do i poza pętlą i uzyskać 10.
Pod względem przypisywania wartości do zmiennych let jest równoważny var , po prostu let ma zasięg blokowy, więc anomalie, które wystąpiły z var powyżej, nie wystąpią.
function myFunction() { let num = 5; console.log(num); // 5 for(let i = 0; i < 10; i++) { let num = i; console.log('--'); console.log(num); // num becomes 0 — 9 } console.log('--'); console.log(num); // 5 console.log(i); // undefined, ReferenceError } Patrząc na słowo kluczowe const , widać, że otrzymujemy błąd, jeśli spróbujemy go ponownie przypisać:
const c = 299792458; // Fact: The constant "c" is the speed of light in a vacuum in meters per second. c = 10; // TypeError: Assignment to constant variable. Sprawy stają się interesujące, gdy do obiektu przypiszemy zmienną const :
const myObject = { name: 'Jane Doe' }; // This is illegal: TypeError: Assignment to constant variable. myObject = { name: 'John Doe' }; // This is legal. console.log(myObject.name) -> John Doe myObject.name = 'John Doe'; Jak widać, niezmienne jest tylko odwołanie w pamięci do obiektu przypisanego do obiektu const , a nie sama wartość.
ES6 Funkcje strzałek
Możesz być przyzwyczajony do tworzenia takiej funkcji:
function printHelloWorld() { console.log('Hello, World!'); }Z funkcjami strzałek wyglądałoby to tak:
const printHelloWorld = () => { console.log('Hello, World!'); };Załóżmy, że mamy prostą funkcję, która zwraca kwadrat liczby:
const squareNumber = (x) => { return x * x; } squareNumber(5); // We can call an arrow function like an ES5 functions. Returns 25.Widać, że podobnie jak w przypadku funkcji ES5, możemy przyjmować argumenty z nawiasami, możemy używać normalnych instrukcji return i możemy wywołać funkcję tak jak każdą inną.
Należy zauważyć, że chociaż nawiasy są wymagane, jeśli nasza funkcja nie przyjmuje żadnych argumentów (jak w przypadku printHelloWorld() powyżej), możemy usunąć nawiasy, jeśli przyjmuje tylko jeden, więc nasza wcześniejsza definicja metody squareNumber() może zostać przepisana jako:
const squareNumber = x => { // Notice we have dropped the parentheses for we only take in one argument. return x * x; }To, czy zdecydujesz się umieścić pojedynczy argument w nawiasach, czy nie, jest kwestią osobistego gustu i prawdopodobnie zobaczysz, że programiści używają obu metod.
Na koniec, jeśli chcemy niejawnie zwrócić tylko jedno wyrażenie, jak w przypadku squareNumber(...) powyżej, możemy umieścić instrukcję return zgodnie z sygnaturą metody:
const squareNumber = x => x * x;To znaczy,
const test = (a, b, c) => expressionjest taki sam jak
const test = (a, b, c) => { return expression }Zauważ, że kiedy używasz powyższego skrótu do niejawnego zwracania obiektu, rzeczy stają się niejasne. Co powstrzymuje JavaScript przed przekonaniem, że nawiasy, w których musimy umieścić nasz obiekt, nie są treścią naszej funkcji? Aby to obejść, owijamy nawiasy kwadratowe obiektu w nawiasy. To wyraźnie informuje JavaScript, że rzeczywiście zwracamy obiekt, a nie tylko definiujemy ciało.
const test = () => ({ pi: 3.14 }); // Spaces between brackets are a formality to make the code look cleaner.Aby pomóc utrwalić koncepcję funkcji ES6, przerobimy część naszego wcześniejszego kodu, co pozwoli nam porównać różnice między obiema notacjami.
asyncAddFunction(...) , z góry, może być refaktoryzowany z:
function asyncAddFunction(a, b, callback){ callback(a + b); }do:
const aysncAddFunction = (a, b, callback) => { callback(a + b); };a nawet do:
const aysncAddFunction = (a, b, callback) => callback(a + b); // This will return callback(a + b).Podczas wywoływania funkcji możemy przekazać funkcję strzałki w wywołaniu zwrotnym:
asyncAddFunction(10, 12, sum => { // No parentheses because we only take one argument. console.log(sum); }Nietrudno zauważyć, jak ta metoda poprawia czytelność kodu. Aby pokazać tylko jeden przypadek, możemy skorzystać z naszego starego przykładu opartego na ES5 Promise i zrefaktoryzować go tak, aby używał funkcji strzałek.
makeAPICall('/example') .then(res => makeAPICall(`/newExample/${res.UserName}`)) .then(res => console.log(res)) .catch(err => console.log('Error: ', err)); Teraz są pewne zastrzeżenia dotyczące funkcji strzałek. Po pierwsze, nie wiążą this słowa kluczowego. Załóżmy, że mam następujący obiekt:
const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Możesz oczekiwać, że wywołanie Person.greeting() zwróci „Cześć. Nazywam się John Doe. Zamiast tego otrzymujemy: „Cześć. Moje imię jest nieokreślone”. Dzieje się tak, ponieważ funkcje strzałek nie mają this , więc próba użycia this wewnątrz funkcji strzałki domyślnie przyjmuje wartość this w zakresie otaczającym, a otaczającym zakresem obiektu Person jest window , w przeglądarce lub module.exports w Węzeł.
Aby to udowodnić, jeśli ponownie użyjemy tego samego obiektu, ale ustawimy właściwość name globalnego this na coś w rodzaju „Jane Doe”, wtedy this.name w funkcji strzałki zwróci „Jane Doe”, ponieważ globalne this znajduje się w obejmujący zakres lub jest obiektem nadrzędnym obiektu Person .
this.name = 'Jane Doe'; const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting(); // Hi. My name is Jane DoeJest to znane jako „Scoping leksykalny” i możemy go obejść, używając tak zwanej „krótkiej składni”, w której tracimy dwukropek i strzałkę, aby zrefaktoryzować nasz obiekt jako taki:
const Person = { name: 'John Doe', greeting() { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting() //Hi. My name is John Doe.Klasy ES6
Chociaż JavaScript nigdy nie obsługiwał klas, zawsze można je emulować za pomocą obiektów takich jak powyżej. EcmaScript 6 zapewnia obsługę klas korzystających z class i new słów kluczowych:
class Person { constructor(name) { this.name = name; } greeting() { console.log(`Hi. My name is ${this.name}.`); } } const person = new Person('John'); person.greeting(); // Hi. My name is John. Funkcja konstruktora jest wywoływana automatycznie po użyciu słowa kluczowego new , do którego możemy przekazać argumenty, aby wstępnie skonfigurować obiekt. Powinno to być znane każdemu czytelnikowi, który ma doświadczenie z bardziej statycznymi, obiektowymi językami programowania, takimi jak Java, C++ i C#.
Nie wchodząc zbyt szczegółowo w koncepcje OOP, innym takim paradygmatem jest „dziedziczenie”, które polega na umożliwieniu jednej klasie dziedziczenia po innej. Na przykład klasa o nazwie Car będzie bardzo ogólna — będzie zawierać takie metody, jak „stop”, „start” itp., których potrzebują wszystkie samochody. Podzbiór klasy o nazwie SportsCar , może zatem dziedziczyć podstawowe operacje z Car i zastępować wszystko, czego potrzebuje. Taką klasę możemy określić następująco:
class Car { constructor(licensePlateNumber) { this.licensePlateNumber = licensePlateNumber; } start() {} stop() {} getLicensePlate() { return this.licensePlateNumber; } // … } class SportsCar extends Car { constructor(engineRevCount, licensePlateNumber) { super(licensePlateNumber); // Pass licensePlateNumber up to the parent class. this.engineRevCount = engineRevCount; } start() { super.start(); } stop() { super.stop(); } getLicensePlate() { return super.getLicensePlate(); } getEngineRevCount() { return this.engineRevCount; } } Widać wyraźnie, że słowo kluczowe super umożliwia nam dostęp do właściwości i metod z klasy nadrzędnej, czyli super.
Zdarzenia JavaScript
Zdarzenie to akcja, na którą masz możliwość zareagowania. Załóżmy, że tworzysz formularz logowania do swojej aplikacji. Gdy użytkownik naciśnie przycisk „prześlij”, możesz zareagować na to zdarzenie za pomocą „obsługi zdarzeń” w kodzie — zazwyczaj funkcji. Kiedy ta funkcja jest zdefiniowana jako obsługa zdarzeń, mówimy, że „rejestrujemy obsługę zdarzeń”. Program obsługi zdarzeń dla kliknięcia przycisku przesyłania prawdopodobnie sprawdzi formatowanie danych wejściowych dostarczonych przez użytkownika, oczyści je, aby zapobiec takim atakom, jak wstrzykiwanie SQL lub Cross Site Scripting (należy pamiętać,że żaden kod po stronie klienta nie może być brany pod uwagę Zawsze oczyszczaj dane na serwerze — nigdy nie ufaj niczemu z przeglądarki), a następnie sprawdź, czy ta kombinacja nazwy użytkownika i hasła nie istnieje w bazie danych, aby uwierzytelnić użytkownika i podać mu token.
Ponieważ jest to artykuł o węźle, skupimy się na modelu zdarzeń węzła.
Możemy użyć modułu events z Node, aby emitować i reagować na określone zdarzenia. Każdy obiekt, który emituje zdarzenie, jest instancją klasy EventEmitter .
Możemy wyemitować zdarzenie, wywołując metodę emit emit() i nasłuchiwać tego zdarzenia za pomocą metody on() , z których obie są udostępniane przez klasę EventEmitter .
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); Gdy myEmitter jest teraz instancją klasy EventEmitter , możemy uzyskać dostęp do emit emit() i on() :
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', () => { console.log('The "someEvent" event was fired (emitted)'); }); myEmitter.emit('someEvent'); // This will call the callback function above. Drugim parametrem myEmitter.on() jest funkcja zwrotna, która zostanie uruchomiona, gdy zdarzenie zostanie wyemitowane — jest to procedura obsługi zdarzenia. Pierwszym parametrem jest nazwa zdarzenia, która może być dowolna, chociaż zalecana jest konwencja nazewnictwa camelCase.
Dodatkowo moduł obsługi zdarzeń może przyjmować dowolną liczbę argumentów, które są przekazywane w momencie emisji zdarzenia:
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', (data) => { console.log(`The "someEvent" event was fired (emitted) with data: ${data}`); }); myEmitter.emit('someEvent', 'This is the data payload'); Używając dziedziczenia, możemy udostępnić metody emit emit() i on() z 'EventEmitter' dowolnej klasie. Odbywa się to poprzez utworzenie klasy Node.js i użycie zastrzeżonego słowa kluczowego extends do dziedziczenia właściwości dostępnych w EventEmitter :
const EventEmitter = require('events'); class MyEmitter extends EventEmitter { // This is my class. I can emit events from a MyEmitter object. } Załóżmy, że budujemy program powiadamiania o kolizjach pojazdów, który odbiera dane z żyroskopów, akcelerometrów i manometrów na kadłubie samochodu. Kiedy pojazd zderzy się z obiektem, te zewnętrzne czujniki wykryją awarię, wykonując funkcję collide(...) i przekazując do niej zagregowane dane z czujnika jako ładny obiekt JavaScript. Ta funkcja wyemituje zdarzenie collision , powiadamiając dostawcę o awarii.

const EventEmitter = require('events'); class Vehicle extends EventEmitter { collide(collisionStatistics) { this.emit('collision', collisionStatistics) } } const myVehicle = new Vehicle(); myVehicle.on('collision', collisionStatistics => { console.log('WARNING! Vehicle Impact Detected: ', collisionStatistics); notifyVendor(collisionStatistics); }); myVehicle.collide({ ... }); Jest to zawiły przykład, ponieważ moglibyśmy po prostu umieścić kod w procedurze obsługi zdarzeń w funkcji kolizji klasy, ale pokazuje on, jak mimo to działa model zdarzeń węzła. Zwróć uwagę, że niektóre samouczki pokażą metodę util.inherits() pozwalającą obiektowi na emitowanie zdarzeń. Zostało to przestarzałe na rzecz klas ES6 i extends .
Menedżer pakietów węzłów
Podczas programowania w Node i JavaScript dość często słyszy się o npm . Npm to menedżer pakietów, który właśnie to robi — umożliwia pobieranie pakietów innych firm, które rozwiązują typowe problemy w JavaScript. Istnieją również inne rozwiązania, takie jak Yarn, Npx, Grunt i Bower, ale w tej sekcji skupimy się tylko na npm i sposobach instalowania zależności dla aplikacji za pomocą prostego interfejsu wiersza poleceń (CLI).
Zacznijmy prosto, z npm . Odwiedź stronę główną NpmJS, aby wyświetlić wszystkie pakiety dostępne w NPM. Po uruchomieniu nowego projektu, który będzie zależał od pakietów NPM, będziesz musiał uruchomić npm init za pośrednictwem terminala w katalogu głównym projektu. Zostaniesz poproszony o serię pytań, które posłużą do utworzenia pliku package.json . Ten plik przechowuje wszystkie zależności — moduły, od których zależy działanie aplikacji, skrypty — wstępnie zdefiniowane polecenia terminala do uruchamiania testów, budowania projektu, uruchamiania serwera programistycznego itp. i nie tylko.
Aby zainstalować pakiet, po prostu uruchom npm install [package-name] --save . Flaga save zapewni, że pakiet i jego wersja zostaną zarejestrowane w pliku package.json . Od wersji 5 npm zależności są zapisywane domyślnie, więc --save można pominąć. Zauważysz również nowy folder node_modules , zawierający kod dla właśnie zainstalowanego pakietu. Można to również skrócić do npm i [package-name] . Jako pomocna uwaga, folder node_modules nigdy nie powinien być dołączany do repozytorium GitHub ze względu na jego rozmiar. Za każdym razem, gdy klonujesz repozytorium z GitHub (lub dowolnego innego systemu zarządzania wersjami), pamiętaj, aby uruchomić polecenie npm install , aby wyjść i pobrać wszystkie pakiety zdefiniowane w pliku package.json , automatycznie tworząc katalog node_modules . Możesz także zainstalować pakiet w określonej wersji: npm i [package-name]@1.10.1 --save .
Usuwanie pakietu jest podobne do instalowania: npm remove [package-name] .
Możesz także zainstalować pakiet globalnie. Ten pakiet będzie dostępny we wszystkich projektach, nie tylko w tym, nad którym pracujesz. Robisz to za pomocą flagi -g po npm i [package-name] . Jest to powszechnie używane w przypadku interfejsów wiersza polecenia, takich jak Google Firebase i Heroku. Pomimo łatwości, jaką przedstawia ta metoda, generalnie uważa się za złą praktykę instalowanie pakietów globalnie, ponieważ nie są one zapisywane w pliku package.json , a jeśli inny programista spróbuje użyć twojego projektu, nie osiągną wszystkich wymaganych zależności od npm install .
API i JSON
Interfejsy API są bardzo powszechnym paradygmatem w programowaniu i nawet jeśli dopiero zaczynasz karierę jako programista, interfejsy API i ich wykorzystanie, zwłaszcza w programowaniu internetowym i mobilnym, będą prawdopodobnie pojawiać się częściej niż nie.
API to interfejs programowania aplikacji i jest to w zasadzie metoda, dzięki której dwa oddzielone systemy mogą komunikować się ze sobą. Mówiąc bardziej technicznie, API umożliwia systemowi lub programowi komputerowemu (zwykle serwerowi) odbieranie żądań i wysyłanie odpowiednich odpowiedzi (do klienta, zwanego również hostem).
Załóżmy, że tworzysz aplikację pogodową. Potrzebujesz sposobu na geokodowanie adresu użytkownika na szerokość i długość geograficzną, a następnie sposób na uzyskanie aktualnej lub prognozowanej pogody w tej konkretnej lokalizacji.
As a developer, you want to focus on building your app and monetizing it, not putting the infrastructure in place to geocode addresses or placing weather stations in every city.
Luckily for you, companies like Google and OpenWeatherMap have already put that infrastructure in place, you just need a way to talk to it — that is where the API comes in. While, as of now, we have developed a very abstract and ambiguous definition of the API, bear with me. We'll be getting to tangible examples soon.
Now, it costs money for companies to develop, maintain, and secure that aforementioned infrastructure, and so it is common for corporations to sell you access to their API. This is done with that is known as an API key, a unique alphanumeric identifier associating you, the developer, with the API. Every time you ask the API to send you data, you pass along your API key. The server can then authenticate you and keep track of how many API calls you are making, and you will be charged appropriately. The API key also permits Rate-Limiting or API Call Throttling (a method of throttling the number of API calls in a certain timeframe as to not overwhelm the server, preventing DOS attacks — Denial of Service). Most companies, however, will provide a free quota, giving you, as an example, 25,000 free API calls a day before charging you.
Up to this point, we have established that an API is a method by which two computer programs can communicate with each other. If a server is storing data, such as a website, and your browser makes a request to download the code for that site, that was the API in action.
Let us look at a more tangible example, and then we'll look at a more real-world, technical one. Suppose you are eating out at a restaurant for dinner. You are equivalent to the client, sitting at the table, and the chef in the back is equivalent to the server.
Since you will never directly talk to the chef, there is no way for him/her to receive your request (for what order you would like to make) or for him/her to provide you with your meal once you order it. We need someone in the middle. In this case, it's the waiter, analogous to the API. The API provides a medium with which you (the client) may talk to the server (the chef), as well as a set of rules for how that communication should be made (the menu — one meal is allowed two sides, etc.)
Now, how do you actually talk to the API (the waiter)? You might speak English, but the chef might speak Spanish. Is the waiter expected to know both languages to translate? What if a third person comes in who only speaks Mandarin? What then? Well, all clients and servers have to agree to speak a common language, and in computer programming, that language is JSON, pronounced JAY-sun, and it stands for JavaScript Object Notation.
At this point, we don't quite know what JSON looks like. It's not a computer programming language, it's just, well, a language, like English or Spanish, that everyone (everyone being computers) understands on a guaranteed basis. It's guaranteed because it's a standard, notably RFC 8259 , the JavaScript Object Notation (JSON) Data Interchange Format by the Internet Engineering Task Force (IETF).
Even without formal knowledge of what JSON actually is and what it looks like (we'll see in an upcoming article in this series), we can go ahead introduce a technical example operating on the Internet today that employs APIs and JSON. APIs and JSON are not just something you can choose to use, it's not equivalent to one out of a thousand JavaScript frameworks you can pick to do the same thing. It is THE standard for data exchange on the web.
Suppose you are building a travel website that compares prices for aircraft, rental car, and hotel ticket prices. Let us walk through, step-by-step, on a high level, how we would build such an application. Of course, we need our User Interface, the front-end, but that is out of scope for this article.
We want to provide our users with the lowest price booking method. Well, that means we need to somehow attain all possible booking prices, and then compare all of the elements in that set (perhaps we store them in an array) to find the smallest element (known as the infimum in mathematics.)
How will we get this data? Well, suppose all of the booking sites have a database full of prices. Those sites will provide an API, which exposes the data in those databases for use by you. You will call each API for each site to attain all possible booking prices, store them in your own array, find the lowest or minimum element of that array, and then provide the price and booking link to your user. We'll ask the API to query its database for the price in JSON, and it will respond with said price in JSON to us. We can then use, or parse, that accordingly. We have to parse it because APIs will return JSON as a string, not the actual JavaScript data type of JSON. This might not make sense now, and that's okay. We'll be covering it more in a future article.
Also, note that just because something is called an API does not necessarily mean it operates on the web and sends and receives JSON. The Java API, for example, is just the list of classes, packages, and interfaces that are part of the Java Development Kit (JDK), providing programming functionality to the programmer.
Dobra. We know we can talk to a program running on a server by way of an Application Programming Interface, and we know that the common language with which we do this is known as JSON. But in the web development and networking world, everything has a protocol. What do we actually do to make an API call, and what does that look like code-wise? That's where HTTP Requests enter the picture, the HyperText Transfer Protocol, defining how messages are formatted and transmitted across the Internet. Once we have an understanding of HTTP (and HTTP verbs, you'll see that in the next section), we can look into actual JavaScript frameworks and methods (like fetch() ) offered by the JavaScript API (similar to the Java API), that actually allow us to make API calls.
HTTP And HTTP Requests
HTTP is the HyperText Transfer Protocol. It is the underlying protocol that determines how messages are formatted as they are transmitted and received across the web. Let's think about what happens when, for example, you attempt to load the home page of Smashing Magazine in your web browser.
You type the website URL (Uniform Resource Locator) in the URL bar, where the DNS server (Domain Name Server, out of scope for this article) resolves the URL into the appropriate IP Address. The browser makes a request, called a GET Request, to the Web Server to, well, GET the underlying HTML behind the site. The Web Server will respond with a message such as “OK”, and then will go ahead and send the HTML down to the browser where it will be parsed and rendered accordingly.
There are a few things to note here. First, the GET Request, and then the “OK” response. Suppose you have a specific database, and you want to write an API to expose that database to your users. Suppose the database contains books the user wants to read (as it will in a future article in this series). Then there are four fundamental operations your user may want to perform on this database, that is, Create a record, Read a record, Update a record, or Delete a record, known collectively as CRUD operations.
Let's look at the Read operation for a moment. Without incorrectly assimilating or conflating the notion of a web server and a database, that Read operation is very similar to your web browser attempting to get the site from the server, just as to read a record is to get the record from the database.
Jest to znane jako żądanie HTTP. Wysyłasz żądanie do jakiegoś serwera, aby uzyskać jakieś dane, i jako takie żądanie jest odpowiednio nazwane „GET”, a wielkie litery są standardowym sposobem oznaczania takich żądań.
A co z częścią CRUD dotyczącą tworzenia? Cóż, kiedy mówimy o żądaniach HTTP, jest to znane jako żądanie POST. Tak jak możesz opublikować wiadomość na platformie mediów społecznościowych, możesz również opublikować nowy rekord w bazie danych.
Aktualizacja CRUD pozwala nam użyć żądania PUT lub PATCH w celu aktualizacji zasobu. PUT HTTP utworzy nowy rekord lub zaktualizuje/zastąpi stary.
Przyjrzyjmy się temu nieco bardziej szczegółowo, a potem przejdziemy do PATCH.
Interfejs API zazwyczaj działa poprzez wysyłanie żądań HTTP do określonych tras w adresie URL. Załóżmy, że tworzymy API do komunikacji z bazą danych zawierającą listę książek użytkownika. Wtedy możemy zobaczyć te książki pod adresem URL .../books . Żądanie POST do .../books spowoduje utworzenie nowej książki z określonymi przez Ciebie właściwościami (identyfikator myślenia, tytuł, numer ISBN, autor, dane publikacji itp.) na ścieżce .../books . Nie ma znaczenia, jaka jest podstawowa struktura danych, która przechowuje wszystkie książki w .../books w tej chwili. Zależy nam tylko na tym, aby interfejs API udostępniał ten punkt końcowy (dostępny za pośrednictwem trasy) w celu manipulowania danymi. Poprzednie zdanie było kluczowe: Żądanie POST tworzy nową książkę na trasie ...books/ . Różnica między PUT i POST polega więc na tym, że PUT utworzy nową książkę (tak jak w przypadku POST), jeśli taka książka nie istnieje, lub zastąpi istniejącą książkę , jeśli książka już istnieje w wyżej wymienionej strukturze danych.
Załóżmy, że każda książka ma następujące właściwości: id, tytuł, ISBN, autor, hasRead (wartość logiczna).
Następnie, aby dodać nową książkę, jak widzieliśmy wcześniej, wyślij żądanie POST do .../books . Gdybyśmy chcieli całkowicie zaktualizować lub wymienić książkę, złożylibyśmy żądanie PUT do .../books/id , gdzie id jest identyfikatorem książki, którą chcemy zastąpić.
Podczas gdy PUT całkowicie zastępuje istniejącą książkę, PATCH aktualizuje coś, co ma związek z konkretną książką, być może modyfikując właściwość logiczną hasRead , którą zdefiniowaliśmy powyżej — więc złożymy żądanie PATCH do …/books/id , wysyłając nowe dane.
W tej chwili może być trudno zrozumieć znaczenie tego, ponieważ do tej pory ustaliliśmy wszystko teoretycznie, ale nie widzieliśmy żadnego namacalnego kodu, który faktycznie wysyła żądanie HTTP. Jednak wkrótce do tego dojdziemy, omawiając GET w tym artykule, a resztę w przyszłym artykule.
Jest jeszcze jedna podstawowa operacja CRUD i nazywa się ona Usuń. Jak można się spodziewać, nazwa takiego żądania HTTP to „DELETE” i działa podobnie jak PATCH, wymagając podania identyfikatora książki w trasie.
Do tej pory dowiedzieliśmy się zatem, że trasy to określone adresy URL, do których wysyłasz żądanie HTTP, a punkty końcowe to funkcje udostępniane przez API, które robią coś z danymi, które udostępnia. Oznacza to, że punkt końcowy to funkcja języka programowania zlokalizowana na drugim końcu trasy i wykonująca określone żądanie HTTP. Dowiedzieliśmy się również, że istnieją takie terminy, jak POST, GET, PUT, PATCH, DELETE i inne (znane jako czasowniki HTTP), które w rzeczywistości określają żądania kierowane do interfejsu API. Podobnie jak JSON, te metody żądania HTTP są standardami internetowymi zdefiniowanymi przez Internet Engineering Task Force (IETF), w szczególności RFC 7231, sekcja czwarta: Metody żądania i RFC 5789, sekcja druga: Metoda łaty, gdzie RFC jest akronimem Prośba o komentarze.
Możemy więc wysłać żądanie GET do adresu URL .../books/id , gdzie przekazany identyfikator jest znany jako parametr. Możemy wysłać żądanie POST, PUT lub PATCH do .../books , aby utworzyć zasób lub do .../books/id , aby zmodyfikować/zamienić/zaktualizować zasób. Możemy również wysłać żądanie DELETE do .../books/id , aby usunąć konkretną książkę.
Pełną listę metod żądań HTTP można znaleźć tutaj.
Należy również pamiętać, że po wykonaniu żądania HTTP otrzymamy odpowiedź. Konkretna odpowiedź zależy od tego, w jaki sposób budujemy API, ale zawsze powinieneś otrzymać kod statusu. Wcześniej powiedzieliśmy, że gdy Twoja przeglądarka zażąda kodu HTML z serwera internetowego, odpowie „OK”. Jest to znane jako kod stanu HTTP, a dokładniej HTTP 200 OK. Kod statusu określa po prostu, jak zakończyła się operacja lub akcja określona w punkcie końcowym (pamiętaj, że to nasza funkcja, która wykonuje całą pracę). Kody stanu HTTP są wysyłane z powrotem przez serwer, a prawdopodobnie jest ich wiele, takich jak 404 Not Found (nie można znaleźć zasobu lub pliku, byłoby to jak wysłanie żądania GET do .../books/id , jeśli taki identyfikator nie istnieje.)
Pełną listę kodów stanu HTTP można znaleźć tutaj.
MongoDB
MongoDB to nierelacyjna baza danych NoSQL podobna do bazy danych czasu rzeczywistego Firebase. Będziesz komunikować się z bazą danych za pośrednictwem pakietu Node, takiego jak MongoDB Native Driver lub Mongoose.
W MongoDB dane są przechowywane w formacie JSON, który różni się od relacyjnych baz danych, takich jak MySQL, PostgreSQL czy SQLite. Obie są nazywane bazami danych, z tabelami SQL zwanymi kolekcjami, wierszami tabel SQL zwanymi dokumentami i kolumnami tabel SQL zwanymi polami.
Bazy danych MongoDB użyjemy w nadchodzącym artykule z tej serii, podczas tworzenia naszego pierwszego interfejsu Bookshelf API. Podstawowe operacje CRUD wymienione powyżej mogą być wykonywane na bazie danych MongoDB.
Zaleca się przeczytanie MongoDB Docs, aby dowiedzieć się, jak utworzyć działającą bazę danych w klastrze Atlas i wykonywać na niej operacje CRUD za pomocą natywnego sterownika MongoDB. W kolejnym artykule z tej serii dowiemy się, jak skonfigurować lokalną bazę danych oraz produkcyjną bazę danych w chmurze.
Budowanie aplikacji węzła wiersza poleceń
Podczas tworzenia aplikacji zobaczysz, że wielu autorów zrzuca całą bazę kodu na początku artykułu, a następnie próbuje wyjaśnić każdą linijkę. W tym tekście przyjmę inne podejście. Wyjaśnię mój kod linijka po linijce, tworząc aplikację na bieżąco. Nie będę się przejmował modułowością ani wydajnością, nie podzielę bazy kodu na osobne pliki, nie będę przestrzegał zasady DRY ani nie będę próbował uczynić kodu wielokrotnego użytku. Kiedy tylko się uczysz, przydatne jest, aby wszystko było tak proste, jak to tylko możliwe, i to jest podejście, które tutaj przyjmę.
Powiedzmy jasno, co budujemy. Nie będziemy zajmować się wprowadzaniem danych przez użytkownika, więc nie będziemy korzystać z pakietów takich jak Yargs. Nie będziemy też budować własnego API. Pojawi się to w kolejnym artykule z tej serii, kiedy będziemy korzystać z Express Web Application Framework. Podejmuję to podejście, aby nie łączyć Node.js z potęgą Express i API, tak jak robi to większość samouczków. Zamiast tego przedstawię jedną (z wielu) metodę wywoływania i odbierania danych z zewnętrznego interfejsu API, który wykorzystuje bibliotekę JavaScript innej firmy. API, które będziemy wywoływać, to Weather API, do którego uzyskamy dostęp z Node i zrzucimy dane wyjściowe do terminala, być może z pewnym formatowaniem, znanym jako „ładne drukowanie”. Omówię cały proces, w tym konfigurację API i uzyskanie klucza API, którego kroki zapewniają prawidłowe wyniki od stycznia 2019 r.
W tym projekcie będziemy używać OpenWeatherMap API, więc aby rozpocząć, przejdź do strony rejestracji OpenWeatherMap i utwórz konto za pomocą formularza. Po zalogowaniu znajdź pozycję menu API Keys na stronie pulpitu nawigacyjnego (znajduje się tutaj). Jeśli właśnie utworzyłeś konto, będziesz musiał wybrać nazwę dla swojego klucza API i nacisnąć „Generuj”. Zanim nowy klucz API zacznie działać i powiązać go z kontem, może minąć co najmniej 2 godziny.
Zanim zaczniemy tworzyć aplikację, odwiedzimy dokumentację API, aby dowiedzieć się, jak sformatować nasz klucz API. W tym projekcie będziemy określać kod pocztowy i kod kraju, aby uzyskać informacje o pogodzie w tej lokalizacji.
Z dokumentacji widzimy, że metodą, za pomocą której to robimy, jest podanie następującego adresu URL:
api.openweathermap.org/data/2.5/weather?zip={zip code},{country code}Do którego możemy wprowadzić dane:
api.openweathermap.org/data/2.5/weather?zip=94040,usTeraz, zanim będziemy mogli faktycznie uzyskać odpowiednie dane z tego interfejsu API, musimy podać nasz nowy klucz API jako parametr zapytania:
api.openweathermap.org/data/2.5/weather?zip=94040,us&appid={YOUR_API_KEY} Na razie skopiuj ten adres URL do nowej karty w przeglądarce internetowej, zastępując symbol zastępczy {YOUR_API_KEY} kluczem API uzyskanym wcześniej podczas rejestracji konta.
Tekst, który widzisz, to w rzeczywistości JSON — uzgodniony język sieci, jak omówiono wcześniej.
Aby dokładniej to sprawdzić, naciśnij Ctrl + Shift + I w Google Chrome, aby otworzyć narzędzia dla programistów Chrome, a następnie przejdź do karty Sieć. Obecnie nie powinno tu być żadnych danych.
Aby faktycznie monitorować dane sieciowe, odśwież stronę i obserwuj, jak karta jest wypełniona przydatnymi informacjami. Kliknij pierwszy link, jak pokazano na obrazku poniżej.
Po kliknięciu tego linku możemy wyświetlić szczegółowe informacje HTTP, takie jak nagłówki. Nagłówki są wysyłane w odpowiedzi z API (możesz również, w niektórych przypadkach, wysłać własne nagłówki do API lub możesz nawet stworzyć własne niestandardowe nagłówki (często z prefiksem x- ), które zostaną odesłane podczas budowania własnego API ) i zawierają tylko dodatkowe informacje, których może potrzebować klient lub serwer.
W tym przypadku widać, że wykonaliśmy żądanie HTTP GET do interfejsu API, a on odpowiedział komunikatem HTTP Status 200 OK. Możesz również zobaczyć, że odesłane dane były w formacie JSON, jak wymieniono w sekcji „Nagłówki odpowiedzi”.
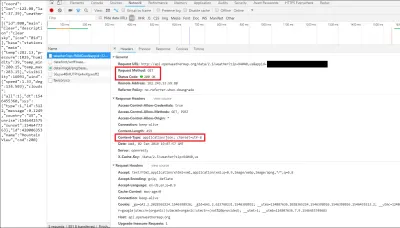
Jeśli klikniesz kartę podglądu, możesz faktycznie wyświetlić JSON jako obiekt JavaScript. Wersja tekstowa, którą widzisz w przeglądarce, jest ciągiem, ponieważ JSON jest zawsze przesyłany i odbierany w sieci jako ciąg. Dlatego musimy przeanalizować JSON w naszym kodzie, aby uzyskać bardziej czytelny format — w tym przypadku (i prawie w każdym przypadku) — obiekt JavaScript.
Możesz także użyć rozszerzenia Google Chrome „Widok JSON”, aby zrobić to automatycznie.
Aby rozpocząć tworzenie naszej aplikacji, otworzę terminal i stworzę nowy katalog główny, a następnie przeprowadzę do niego cd . W środku utworzę nowy plik app.js , uruchomię npm init , aby wygenerować plik package.json z ustawieniami domyślnymi, a następnie otworzę Visual Studio Code.
mkdir command-line-weather-app && cd command-line-weather-app touch app.js npm init code . Następnie pobiorę Axios, zweryfikuję, że został dodany do mojego pliku package.json i zauważę, że folder node_modules został pomyślnie utworzony.
W przeglądarce widać, że ręcznie wykonaliśmy żądanie GET, ręcznie wpisując odpowiedni adres URL w pasku adresu URL. Axios jest tym, co pozwoli mi to zrobić w Node.
Od teraz cały poniższy kod będzie znajdować się w pliku app.js , każdy fragment zostanie umieszczony jeden po drugim.
Pierwszą rzeczą, którą zrobię, będzie wymaganie pakietu Axios, który zainstalowaliśmy wcześniej
const axios = require('axios'); Mamy teraz dostęp do Axios i możemy wysyłać odpowiednie żądania HTTP za pośrednictwem stałej axios .
Generalnie nasze wywołania API będą dynamiczne — w tym przypadku możemy chcieć wstawić do naszego adresu URL różne kody pocztowe i kody krajów. Dlatego utworzę stałe zmienne dla każdej części adresu URL, a następnie połączę je z ciągami szablonów ES6. Po pierwsze, mamy część naszego adresu URL, która nigdy się nie zmieni, a także nasz klucz API:
const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; Przypiszę też nasz kod pocztowy i kod kraju. Ponieważ nie oczekujemy danych wejściowych użytkownika i raczej ciężko kodujemy dane, ustawię je również na stałe, chociaż w wielu przypadkach bardziej przydatne będzie użycie let .
const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us';Teraz musimy połączyć te zmienne w jeden adres URL, do którego możemy użyć Axios, aby wykonać żądania GET do:
const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Oto zawartość naszego pliku app.js do tego momentu:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Wszystko, co pozostało do zrobienia, to faktyczne użycie axios do wykonania żądania GET do tego adresu URL. W tym celu użyjemy metody get(url) dostarczonej przez axios .
axios.get(ENTIRE_API_URL) axios.get(...) faktycznie zwraca Promise, a funkcja wywołania zwrotnego sukcesu przyjmie argument odpowiedzi, który pozwoli nam uzyskać dostęp do odpowiedzi z API — to samo, co widziałeś w przeglądarce. Dodam również klauzulę .catch() , aby wyłapać wszelkie błędy.
axios.get(ENTIRE_API_URL) .then(response => console.log(response)) .catch(error => console.log('Error', error)); Jeśli teraz uruchomimy ten kod z node app.js w terminalu, będziesz mógł zobaczyć pełną odpowiedź, którą otrzymamy. Załóżmy jednak, że chcesz tylko zobaczyć temperaturę dla tego kodu pocztowego — wtedy większość danych w odpowiedzi nie jest dla Ciebie przydatna. Axios faktycznie zwraca odpowiedź z API w obiekcie danych, który jest właściwością odpowiedzi. Oznacza to, że odpowiedź z serwera faktycznie znajduje się w response.data , więc zamiast tego wypiszmy to w funkcji zwrotnej: console.log(response.data) .
Teraz powiedzieliśmy, że serwery internetowe zawsze traktują JSON jako ciąg i to prawda. Możesz jednak zauważyć, że response.data jest już obiektem (widoczne po uruchomieniu console.log(typeof response.data) ) — nie musieliśmy parsować go za pomocą JSON.parse() . To dlatego, że Axios już zajmuje się tym za nas za kulisami.
Dane wyjściowe w terminalu z uruchomienia console.log(response.data) można sformatować — „ładnie wydrukowane” — uruchamiając console.log(JSON.stringify(response.data, undefined, 2)) . JSON.stringify() konwertuje obiekt JSON na ciąg znaków i przyjmuje obiekt, filtr oraz liczbę znaków, według których ma być wykonywane wcięcie podczas drukowania. Możesz zobaczyć odpowiedź, którą zapewnia:
{ "coord": { "lon": -118.24, "lat": 33.97 }, "weather": [ { "id": 800, "main": "Clear", "description": "clear sky", "icon": "01d" } ], "base": "stations", "main": { "temp": 288.21, "pressure": 1022, "humidity": 15, "temp_min": 286.15, "temp_max": 289.75 }, "visibility": 16093, "wind": { "speed": 2.1, "deg": 110 }, "clouds": { "all": 1 }, "dt": 1546459080, "sys": { "type": 1, "id": 4361, "message": 0.0072, "country": "US", "sunrise": 1546441120, "sunset": 1546476978 }, "id": 420003677, "name": "Lynwood", "cod": 200 } Teraz wyraźnie widać, że szukana przez nas temperatura znajduje się we właściwości main obiektu response.data , więc możemy uzyskać do niej dostęp, wywołując response.data.main.temp . Przyjrzyjmy się dotychczasowemu kodowi naszej aplikacji:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => console.log(response.data.main.temp)) .catch(error => console.log('Error', error));Temperatura, którą otrzymujemy, jest w rzeczywistości w kelwinach, która jest skalą temperatury powszechnie używaną w fizyce, chemii i termodynamice, ponieważ zapewnia punkt „zera absolutnego”, który jest temperaturą, w której cały ruch termiczny wszystkich wewnętrznych cząstki ustają. Musimy tylko przekonwertować to na stopnie Fahrenheita lub Celsjusza za pomocą poniższych formuł:
F = K * 9/5 - 459,67
C = K - 273,15
Zaktualizujmy nasze skuteczne wywołanie zwrotne, aby wydrukować nowe dane z tą konwersją. Dodamy również odpowiednie zdanie dla celów User Experience:
axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error)); Nawiasy wokół zmiennej message nie są wymagane, po prostu wyglądają ładnie — podobnie jak podczas pracy z JSX w React. Ukośniki odwrotne uniemożliwiają formatowanie nowej linii ciągu szablonu, a prototypowa metoda replace() String usuwa białe znaki za pomocą wyrażeń regularnych (RegEx). Prototypowe metody toFixed() Number zaokrąglają liczbę zmiennoprzecinkową do określonej liczby miejsc dziesiętnych — w tym przypadku do dwóch.
Dzięki temu nasz ostateczny app.js wygląda następująco:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error));Wniosek
Z tego artykułu dowiedzieliśmy się wiele o tym, jak działa Node, od różnic między żądaniami synchronicznymi i asynchronicznymi, przez funkcje wywołań zwrotnych, po nowe funkcje ES6, zdarzenia, menedżery pakietów, API, JSON i HyperText Transfer Protocol, nierelacyjne bazy danych , a nawet zbudowaliśmy własną aplikację wiersza poleceń, wykorzystując większość tej nowo znalezionej wiedzy.
W przyszłych artykułach z tej serii przyjrzymy się dogłębnie interfejsom API stosu wywołań, pętli zdarzeń i węzłów, porozmawiamy o współużytkowaniu zasobów między źródłami (CORS) i zbudujemy pełny Stack Bookshelf API wykorzystujący bazy danych, punkty końcowe, uwierzytelnianie użytkowników, tokeny, renderowanie szablonów po stronie serwera i nie tylko.
Stąd zacznij budować własne aplikacje Node, przeczytaj dokumentację Node, wyjdź i znajdź ciekawe API lub Node Modules i zaimplementuj je samodzielnie. Świat jest Twoją ostrygą, a Ty masz na wyciągnięcie ręki dostęp do największej sieci wiedzy na świecie — Internetu. Użyj go na swoją korzyść.
Dalsze czytanie na SmashingMag:
- Zrozumienie i korzystanie z interfejsów API REST
- Nowe funkcje JavaScript, które zmienią sposób pisania Regex
- Utrzymywanie szybkości Node.js: narzędzia, techniki i wskazówki dotyczące tworzenia wysokowydajnych serwerów Node.js
- Tworzenie prostego chatbota AI z Web Speech API i Node.js