
Naucz się algorytmu naiwnego Bayesa do uczenia maszynowego [z przykładami]
Opublikowany: 2021-02-25Spis treści
Wstęp
W matematyce i programowaniu niektóre z najprostszych rozwiązań są zwykle najpotężniejsze. Klasycznym przykładem tego stwierdzenia jest naiwny algorytm Bayesa. Nawet przy silnym i szybkim postępie i rozwoju w dziedzinie uczenia maszynowego, ten algorytm Naive Bayes nadal jest jednym z najczęściej używanych i wydajnych algorytmów. Naiwny algorytm Bayesa znajduje zastosowanie w różnych problemach, w tym w zadaniach klasyfikacyjnych i problemach przetwarzania języka naturalnego (NLP).
Hipoteza matematyczna twierdzenia Bayesa służy jako podstawowa koncepcja tego naiwnego algorytmu Bayesa. W tym artykule omówimy podstawy twierdzenia Bayesa, naiwnego algorytmu Bayesa wraz z jego implementacją w Pythonie z przykładowym problemem w czasie rzeczywistym. Wraz z nimi przyjrzymy się również niektórym zaletom i wadom algorytmu Naive Bayes w porównaniu z jego konkurentami.
Podstawy prawdopodobieństwa
Zanim podejmiemy próbę zrozumienia twierdzenia Bayesa i naiwnego algorytmu Bayesa, odświeżmy naszą dotychczasową wiedzę o podstawy prawdopodobieństwa.
Jak wszyscy wiemy z definicji, przy danym zdarzeniu A prawdopodobieństwo wystąpienia tego zdarzenia jest dane przez P(A). W prawdopodobieństwie dwa zdarzenia A i B są określane jako zdarzenia niezależne, jeśli wystąpienie zdarzenia A nie zmienia prawdopodobieństwa wystąpienia zdarzenia B i na odwrót. Z drugiej strony, jeśli jedno zdarzenie zmienia prawdopodobieństwo drugiego, to są one określane jako zdarzenia zależne.
Zapoznajmy się z nowym terminem zwanym prawdopodobieństwem warunkowym . W matematyce prawdopodobieństwo warunkowe dla dwóch zdarzeń A i B podane przez P (A| B) definiuje się jako prawdopodobieństwo wystąpienia zdarzenia A, biorąc pod uwagę, że zdarzenie B już zaszło. W zależności od relacji między dwoma zdarzeniami A i B, czy są one zależne czy niezależne, prawdopodobieństwo warunkowe oblicza się na dwa sposoby.
- Prawdopodobieństwo warunkowe dwóch zdarzeń zależnych A i B jest dane przez P (A| B) = P (A i B) / P (B)
- Wyrażenie na warunkowe prawdopodobieństwo dwóch niezależnych zdarzeń A i B jest podane przez: P (A| B) = P (A)
Znając matematykę stojącą za prawdopodobieństwem i prawdopodobieństwem warunkowym, przejdźmy teraz do twierdzenia Bayesa.

Twierdzenie Bayesa
W statystyce i teorii prawdopodobieństwa do określenia warunkowego prawdopodobieństwa zdarzeń używa się twierdzenia Bayesa, znanego również jako reguła Bayesa. Innymi słowy, twierdzenie Bayesa opisuje prawdopodobieństwo zdarzenia na podstawie wcześniejszej wiedzy o warunkach, które mogą mieć znaczenie dla zdarzenia.
Aby to zrozumieć w prostszy sposób, weźmy pod uwagę, że musimy wiedzieć, że prawdopodobieństwo, iż cena domu jest bardzo wysoka. Jeśli wiemy o innych parametrach, takich jak obecność w pobliżu szkół, sklepów medycznych i szpitali, możemy dokonać dokładniejszej oceny tego samego. Dokładnie to wykonuje twierdzenie Bayesa.
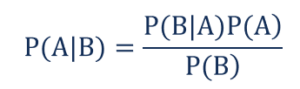
Tak, że
- P(A|B) – warunkowe prawdopodobieństwo wystąpienia zdarzenia A, dane zdarzenie B wystąpiło, znane również jako prawdopodobieństwo a posteriori .
- P(B|A) – warunkowe prawdopodobieństwo wystąpienia zdarzenia B, dane zdarzenie A zaistniało, znane również jako prawdopodobieństwo prawdopodobieństwa .
- P(A) – prawdopodobieństwo wystąpienia zdarzenia A, znane również jako prawdopodobieństwo wcześniejsze.
- P(B) – prawdopodobieństwo wystąpienia zdarzenia B, znane również jako prawdopodobieństwo krańcowe.
Załóżmy, że mamy prosty problem z uczeniem maszynowym z „n” zmiennymi niezależnymi, a zmienna zależna, która jest wynikiem jest wartością logiczną (prawda lub fałsz). Załóżmy, że niezależne atrybuty mają charakter kategoryczny, rozważmy w tym przykładzie 2 kategorie. Dlatego na podstawie tych danych musimy obliczyć wartość prawdopodobieństwa prawdopodobieństwa, P(B|A).
Dlatego obserwując powyższe, stwierdzamy, że musimy obliczyć 2*(2^ n -1 ) parametry, aby nauczyć się tego modelu uczenia maszynowego. Podobnie, jeśli mamy 30 niezależnych atrybutów logicznych, całkowita liczba parametrów do obliczenia będzie bliska 3 miliardów, co jest niezwykle wysokim kosztem obliczeniowym.
Ta trudność w budowaniu modelu uczenia maszynowego z twierdzeniem Bayesa doprowadziła do narodzin i rozwoju algorytmu naiwnego Bayesa.
Naiwny algorytm Bayesa
Aby być praktycznym, wspomniana wyżej złożoność twierdzenia Bayesa musi zostać zredukowana. Jest to dokładnie osiągane w naiwnym algorytmie Bayesa poprzez przyjęcie kilku założeń. Przyjęte założenia są takie, że każda funkcja wnosi niezależny i równy wkład w wynik.
Naiwny algorytm Bayesa jest algorytmem uczenia nadzorowanego i opiera się na twierdzeniu Bayesa, które jest używane głównie do rozwiązywania problemów klasyfikacyjnych. Jest to jeden z najprostszych i najdokładniejszych klasyfikatorów, który buduje modele uczenia maszynowego w celu szybkiego przewidywania. Matematycznie jest klasyfikatorem probabilistycznym, ponieważ dokonuje przewidywań za pomocą funkcji prawdopodobieństwa zdarzeń.
Przykładowy problem
Aby zrozumieć logikę stojącą za założeniami, przejdźmy przez prosty zestaw danych, aby uzyskać lepszą intuicję.
| Kolor | Rodzaj | Pochodzenie | Kradzież? |
| Czarny | Sedan | Importowany | TAk |
| Czarny | SUV | Importowany | Nie |
| Czarny | Sedan | Domowy | TAk |
| Czarny | Sedan | Importowany | Nie |
| brązowy | SUV | Domowy | TAk |
| brązowy | SUV | Domowy | Nie |
| brązowy | Sedan | Importowany | Nie |
| brązowy | SUV | Importowany | TAk |
| brązowy | Sedan | Domowy | Nie |
Z powyższego zestawu danych możemy wyprowadzić koncepcje dwóch założeń, które zdefiniowaliśmy dla powyższego algorytmu naiwnego Bayesa.
- Pierwszym założeniem jest to, że wszystkie cechy są od siebie niezależne. Tutaj widzimy, że każdy atrybut jest niezależny, na przykład kolor „Czerwony” jest niezależny od typu i pochodzenia samochodu.
- Następnie każdej funkcji należy nadać jednakową wagę. Podobnie, sama wiedza o typie i pochodzeniu samochodu nie jest wystarczająca, aby przewidzieć wynik problemu. W związku z tym żadna ze zmiennych nie jest nieistotna, a zatem wszystkie w równym stopniu przyczyniają się do wyniku.
Podsumowując, A i B są warunkowo niezależne przy danym C wtedy i tylko wtedy, gdy przy wiedzy, że C występuje, wiedza o tym, czy występuje A, nie dostarcza informacji o prawdopodobieństwie wystąpienia B, a wiedza o tym, czy występuje B, nie dostarcza informacji na temat prawdopodobieństwo wystąpienia A. Z tych założeń składa się algorytm Bayesa – Naive . Stąd nazwa Naive Bayes Algorithm.
Stąd dla powyższego problemu twierdzenie Bayesa można przepisać jako –
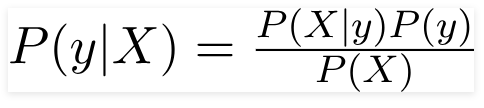
Tak, że
- Niezależny wektor cech, X = (x 1 , x 2 , x 3 ……x n ) reprezentujący cechy takie jak kolor, typ i pochodzenie samochodu.
- Zmienna wyjściowa y ma tylko dwa wyniki Tak lub Nie.
Stąd, podstawiając powyższe wartości, otrzymujemy Naive Bayes Formula jako,
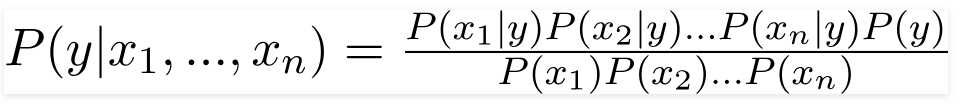
Aby obliczyć prawdopodobieństwo a posteriori P(y|X), musimy stworzyć tabelę częstotliwości dla każdego atrybutu na podstawie danych wyjściowych. Następnie przekształcamy tabele częstości w tabele prawdopodobieństwa, po czym w końcu używamy naiwnego równania Bayesa do obliczenia prawdopodobieństwa a posteriori dla każdej klasy. Jako wynik predykcji wybierana jest klasa o najwyższym prawdopodobieństwie a posteriori. Poniżej znajdują się tabele częstotliwości i prawdopodobieństwa dla wszystkich trzech predyktorów.
Tabela częstości występowania kolorów Tabela prawdopodobieństwa kolorów
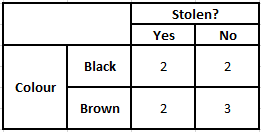
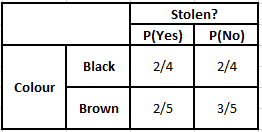
Tabela częstości typu Tabela prawdopodobieństwa typu
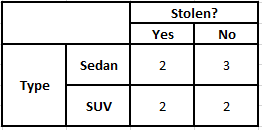
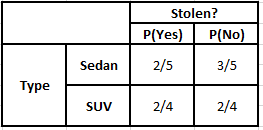

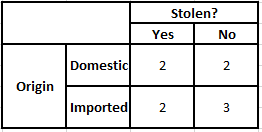
Tabela częstości pochodzenia Tabela prawdopodobieństwa pochodzenia
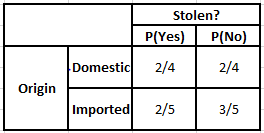
Rozważmy przypadek, w którym musimy obliczyć prawdopodobieństwa a posteriori dla podanych poniżej warunków –
| Kolor | Rodzaj | Pochodzenie |
| brązowy | SUV | Importowany |
Zatem z powyższego wzoru możemy obliczyć prawdopodobieństwa a posteriori, jak pokazano poniżej:
P(Tak | X) = P(Brązowy | Tak) * P(SUV | Tak) * P(Importowane | Tak) * P(Tak)
= 2/5 * 2/4 * 2/5 * 1
= 0,08
P(Nie | X) = P(Brązowy | Nie) * P(SUV | Nie) * P(Importowane | Nie) * P(Nie)
= 3/5 * 2/4 * 3/5 * 1
= 0,18
Z obliczonych powyżej wartości, ponieważ prawdopodobieństwo a posteriori dla Nie jest większe niż Tak (0,18>0,08), można wywnioskować, że samochód o Kolorze Brązowym, typ SUV importowanego pochodzenia jest sklasyfikowany jako „Nie”. Dzięki temu samochód nie jest kradziony.
Implementacja w Pythonie
Teraz, gdy zrozumieliśmy matematykę stojącą za algorytmem Naive Bayes, a także zwizualizowaliśmy go na przykładzie, przejdźmy przez jego kod uczenia maszynowego w języku Python.
Powiązane: Naiwny klasyfikator Bayesa
Analiza problemu
Aby zaimplementować program Naive Bayes Classification w Machine Learning za pomocą Pythona, będziemy używać bardzo znanego „Iris Flower Dataset”. Zestaw danych kwiatu tęczówki lub zestaw danych tęczówki Fishera to wielowymiarowy zestaw danych wprowadzony przez brytyjskiego statystyka, eugenika i biologa Ronalda Fishera w 1998 roku. Jest to bardzo mały i podstawowy zestaw danych, który składa się z bardzo mniej danych liczbowych zawierających informacje o 3 klasach kwiatów należących do gatunku Iris, które są –
- Irys Setosa
- Iris Versicolor
- Irys Wirginica
Istnieje 50 próbek każdego z trzech gatunków , co daje łączny zestaw danych składający się ze 150 wierszy. 4 atrybuty (lub) niezależne zmienne używane w tym zbiorze danych to:
- długość kielicha w cm
- szerokość działki w cm
- długość płatka w cm
- szerokość płatka w cm
Zmienną zależną jest „ gatunek ” kwiatu, który jest identyfikowany przez powyższe cztery atrybuty.
Krok 1 – Importowanie bibliotek
Jak zawsze, podstawowym krokiem w budowaniu dowolnego modelu uczenia maszynowego będzie zaimportowanie odpowiednich bibliotek. W tym celu załadujemy biblioteki NumPy, Mathplotlib i Pandas do wstępnego przetwarzania danych.
importuj numer jako np
importuj matplotlib.pyplot jako plt
importuj pandy jako PD
Krok 2 – Ładowanie zbioru danych
Zestaw danych kwiatu tęczówki, który ma być używany do uczenia klasyfikatora Naive Bayes, należy załadować do ramki danych Pandas DataFrame. 4 zmienne niezależne należy przypisać do zmiennej X, a ostateczna zmienna gatunku wyjściowego zostanie przypisana do y.
dataset = pd.read_csv(' https://raw.githubusercontent.com/mk-gurucharan/Classification/master/IrisDataset.csv' )X = dataset.iloc[:,:4].values
y = zbiór danych['gatunek'].valuesdataset.head(5)>>
sepal_length sepal_width petal_length petal_width gatunki
5,1 3,5 1,4 0,2 setosa
4,9 3,0 1,4 0,2 setosa
4,7 3,2 1,3 0,2 setosa
4,6 3,1 1,5 0,2 setosa
5,0 3,6 1,4 0,2 setosa
Krok 3 – Podział zbioru danych na zbiór treningowy i zbiór testowy
Po załadowaniu zbioru danych i zmiennych kolejnym krokiem jest przygotowanie zmiennych, które przejdą proces uczenia. W tym kroku musimy podzielić zmienne X i y na treningowe i testowe zbiory danych. W tym celu przypiszemy losowo 80% danych do zbioru uczącego, który będzie używany do celów uczących, a pozostałe 20% danych jako zbioru testowego, na którym wytrenowany klasyfikator Naive Bayes będzie testowany pod kątem dokładności.
ze sklearn.model_selection importuj train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0,2)
Krok 4 – Skalowanie funkcji
Chociaż jest to dodatkowy proces do tego małego zestawu danych, dodaję go, abyś mógł go użyć w większym zestawie danych. W ten sposób dane w zbiorach uczącym i testowym są skalowane w dół do zakresu wartości od 0 do 1. Zmniejsza to koszt obliczeniowy.
ze sklearn.preprocessing import StandardScaler
sc = Standardowy skaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Krok 5 – Uczenie modelu Naive Bayes Classification na zestawie uczącym
W tym kroku importujemy klasę Naive Bayes z biblioteki sklearn. Do tego modelu używamy modelu Gaussa, istnieje kilka innych modeli, takich jak Bernoulli, Kategoryczny i Wielomianowy. W ten sposób X_train i y_train są dopasowywane do zmiennej klasyfikatora do celów szkoleniowych.
z sklearn.naive_bayes import GaussianNB
klasyfikator = GaussianNB()
classifier.fit(X_train, y_train)
Krok 6 – Przewidywanie wyników zestawu testowego –
Przewidujemy klasę gatunku dla zbioru testowego przy użyciu wytrenowanego modelu i porównujemy go z wartościami rzeczywistymi klasy gatunku.
y_pred = klasyfikator.predict(X_test)
df = pd.DataFrame({'Wartości rzeczywiste':y_test, 'Wartości przewidywane':y_pred})
df>>
Rzeczywiste wartości Przewidywane wartości
setosa setosa
setosa setosa
wirginica wirginica
versicolor versicolor
setosa setosa
setosa setosa
… … … … …
dziewica versicolor
wirginica wirginica
setosa setosa
setosa setosa
versicolor versicolor
versicolor versicolor
W powyższym porównaniu widzimy, że istnieje jedna nieprawidłowa przepowiednia, która przewidziała Versicolor zamiast virginica.
Krok 7 – Macierz pomyłek i dokładność
Ponieważ mamy do czynienia z Klasyfikacją, najlepszym sposobem oceny naszego modelu klasyfikatora jest wydrukowanie Macierzy Pomyłek wraz z jej dokładnością na zbiorze testowym.
ze sklearn.metrics importuj pomyłkę_macierzy
cm = pomyłka_matrix(y_test, y_pred)z importu sklearn.metrics dokładność_wyniku
drukuj („Dokładność :”, wynik_dokładności(y_test, y_pred))
cm>> Dokładność: 0.9666666666666667
>>tablica([[14, 0, 0],
[ 0, 7, 0],
[ 0, 1, 8]])
Wniosek
Dlatego w tym artykule omówiliśmy podstawy algorytmu naiwnego Bayesa, zrozumieliśmy matematykę stojącą za klasyfikacją wraz z ręcznie rozwiązanym przykładem. Na koniec wdrożyliśmy kod uczenia maszynowego, aby rozwiązać popularny zbiór danych za pomocą algorytmu Naive Bayes Classification.
Jeśli chcesz dowiedzieć się więcej o sztucznej inteligencji, uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadań, Status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
W jaki sposób prawdopodobieństwo jest pomocne w uczeniu maszynowym?
Być może będziemy musieli podejmować decyzje na podstawie częściowych lub niepełnych informacji w rzeczywistych scenariuszach. Prawdopodobieństwo pomaga nam określić ilościowo niepewności w takich systemach i zarządzać ryzykiem dla zadania. Tradycyjna metoda działa tylko dla deterministycznych wyników dla określonych działań, ale zawsze istnieje pewien zakres niepewności w każdym modelu predykcyjnym. Ta niepewność może pochodzić z wielu parametrów z danych wejściowych, takich jak szum w danych. Również poglądy bayesowskie z twierdzeń prawdopodobieństwa mogą pomóc w rozpoznawaniu wzorców na podstawie danych wejściowych. W tym celu prawdopodobieństwo wykorzystuje koncepcję oszacowania maksymalnego prawdopodobieństwa, a zatem jest pomocne w uzyskiwaniu odpowiednich wyników.
Jaki jest pożytek z Matrycy Pomyłek?
Macierz pomyłek to macierz 2x2 używana do interpretacji wydajności modelu klasyfikacji. Aby to zadziałało, muszą być znane prawdziwe wartości danych wejściowych, więc nie mogą być reprezentowane dla danych bez etykiet. Składa się z liczby wyników fałszywie dodatnich (FP), prawdziwie dodatnich (TP), fałszywie ujemnych (FN) i prawdziwie ujemnych (TN). Prognozy są klasyfikowane do tych klas przy użyciu liczby ze zbioru uczącego i zbioru testowego. Pomaga nam wizualizować przydatne parametry, takie jak dokładność, precyzja, przypomnienie i szczegółowość. Jest stosunkowo łatwy do zrozumienia i daje jasny obraz algorytmu.
Jakie są rodzaje modelu Naive Bayes?
Wszystkie typy są oparte głównie na twierdzeniu Bayesa. Model Naive Bayes generalnie ma trzy typy: Gaussa, Bernoulliego i Wielomianowy. Gaussian Naive Bayes wspomaga ciągłe wartości parametrów wejściowych i zakłada, że wszystkie klasy danych wejściowych są równomiernie rozłożone. Naiwny Bayes Bernoulliego to model oparty na zdarzeniach, w którym cechy danych są niezależne i prezentowane w wartościach logicznych. Multinomial Naive Bayes jest również oparty na modelu opartym na zdarzeniach. Posiada cechy danych w postaci wektorowej, która reprezentuje odpowiednie częstotliwości na podstawie występowania zdarzeń.