
7 najczęściej używanych algorytmów uczenia maszynowego w Pythonie, o których powinieneś wiedzieć
Opublikowany: 2021-03-04Uczenie maszynowe to gałąź sztucznej inteligencji (AI), która zajmuje się algorytmami komputerowymi używanymi na dowolnych danych. Koncentruje się na automatycznym uczeniu się na podstawie wprowadzanych do niego danych i daje nam wyniki, za każdym razem poprawiając poprzednie przewidywania.
Spis treści
Najlepsze algorytmy uczenia maszynowego używane w Pythonie
Poniżej znajdują się niektóre z najlepszych algorytmów uczenia maszynowego używanych w Pythonie, wraz z fragmentami kodu pokazuje ich implementację i wizualizacje granic klasyfikacji.
1. Regresja liniowa
Regresja liniowa jest jedną z najczęściej stosowanych technik nadzorowanego uczenia maszynowego. Jak sama nazwa wskazuje, ta regresja próbuje modelować związek między dwiema zmiennymi przy użyciu równania liniowego i dopasowywać tę linię do obserwowanych danych. Ta technika służy do szacowania rzeczywistych wartości ciągłych, takich jak całkowita sprzedaż lub koszt domów.
Linia najlepszego dopasowania jest również nazywana linią regresji. Daje to następujące równanie:
Y = a*X + b
gdzie Y to zmienna zależna, a to nachylenie, X to zmienna niezależna, a b to wartość przecięcia. Współczynniki a i b są wyprowadzane przez minimalizację kwadratu różnicy tej odległości między różnymi punktami danych i równania linii regresji.

# syntetyczny zbiór danych dla prostej regresji
ze sklearn.datasets importuj make_regression
pl.figura()
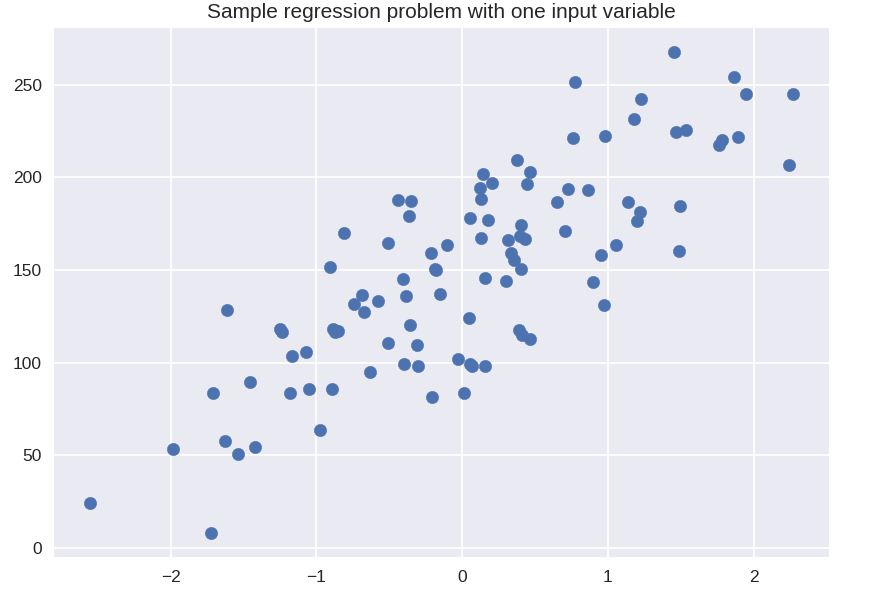
plt.title( 'Przykładowy problem z regresją z jedną zmienną wejściową' )
X_R1, y_R1 = make_regression( n_samples = 100, n_features = 1, n_informative = 1, bias = 150,0, noise = 30, random_state = 0 )
plt.scatter( X_R1, y_R1, znacznik = 'o', s = 50 )
plt.pokaż()
from sklearn.linear_model import LinearRegression
X_train, X_test, y_train, y_test = train_test_split( X_R1, y_R1,
stan_losowy = 0 )
linreg = LinearRegression().fit( X_train, y_train )
print( 'współczynnik modelu liniowego (w): {}'.format( linreg.coef_ ) )
print( 'przecięcie modelu liniowego (b): {:.3f}'z.format( linreg.intercept_ ) )
print( 'Wynik R-kwadrat (trening): {:.3f}'.format( linreg.score( X_train, y_train )) )
print( 'Wynik R-kwadrat (test): {:.3f}'.format( linreg.score( X_test, y_test ) ) )
Wyjście
współczynnik modelu liniowego (w): [ 45,71]
przecięcie modelu liniowego (b): 148.446
Wynik R-kwadrat (trening): 0,679
Wynik R-kwadrat (test): 0,492
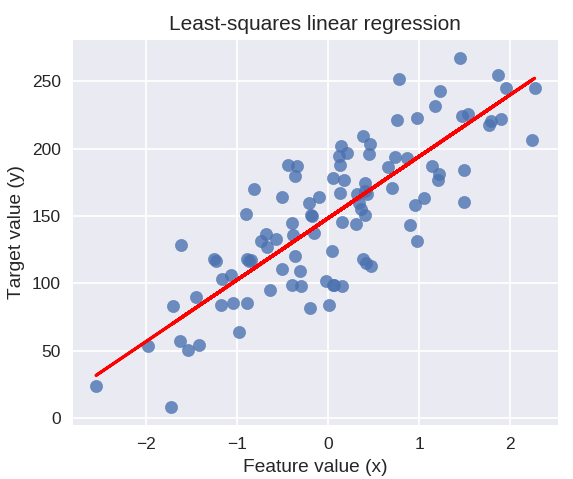
Poniższy kod narysuje dopasowaną linię regresji na wykresie naszych punktów danych.
plt.figure( wielkość fig = ( 5, 4 ) )
plt.scatter( X_R1, y_R1, znacznik = 'o', s = 50, alfa = 0,8 )
plt.plot( X_R1, linreg.coef_ * X_R1 + linreg.intercept_, 'r-' )
plt.title( 'Regresja liniowa najmniejszych kwadratów' )
plt.xlabel( 'Wartość funkcji (x)' )
plt.ylabel( 'Wartość docelowa (y)' )
plt.pokaż()
Przygotowanie wspólnego zbioru danych do eksploracji technik klasyfikacji
Poniższe dane zostaną użyte do pokazania różnych algorytmów klasyfikacji, które są najczęściej używane w uczeniu maszynowym w Pythonie.
Zbiór danych grzybów UCI jest przechowywany w mushrooms.csv.
%notplotlib notatnik
importuj pandy jako PD
importuj numer jako np
importuj matplotlib.pyplot jako plt
ze sklearn.decomposition import PCA
ze sklearn.model_selection importuj train_test_split
df = pd.read_csv( 'tylko do odczytu/grzyby.csv' )
df2 = pd.get_dummies( df )
df3 = df2.próbka( frac = 0.08 )
X = df3.iloc[:, 2:]
y = df3.iloc[:, 1]
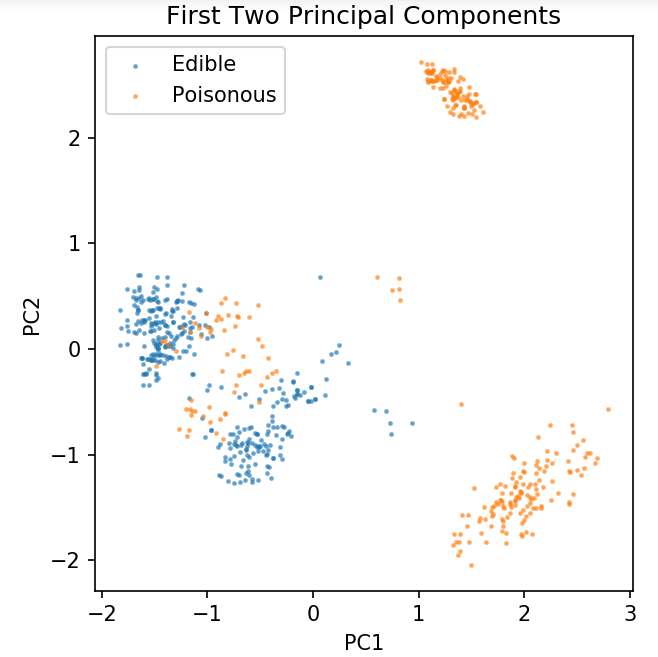
pca = PCA( n_komponentów = 2 ).fit_transform( X )
X_train, X_test, y_train, y_test = train_test_split( pca, y, random_state = 0 )
liczba.plt( dpi = 120 )
plt.scatter( pca[y.values == 0, 0], pca[y.values == 0, 1], alpha = 0.5, label = 'Jadalne', s = 2 )
plt.scatter( pca[y.values == 1, 0], pca[y.values == 1, 1], alpha = 0.5, label = 'Trujące', s = 2 )
plt.legenda()
plt.title( 'Zbiór danych grzybów\nPierwsze dwa główne składniki' )
plt.xlabel( 'PC1' )
plt.ylabel( 'PC2' )
plt.gca().set_aspect( 'równe' )
Użyjemy funkcji zdefiniowanej poniżej, aby uzyskać granice decyzji różnych klasyfikatorów, których użyjemy w zbiorze danych grzybów.
def plot_grzybowy_granica( X, y, dopasowany_model ):
plt.figure( rozmiar fig = (9,8, 5), dpi = 100 )
for i, plot_type in enumerate( ['Granica decyzji', 'Prawdopodobieństwo decyzji'] ):
plt.podwykres( 1, 2, i + 1 )
mesh_step_size = 0,01 # rozmiar kroku w siatce
x_min, x_max = X[:, 0].min() – 0,1, X[:, 0].max() + 0,1
y_min, y_max = X[:, 1].min() – .1, X[:, 1].max() + .1
xx, yy = np.meshgrid( np.arange( x_min, x_max, mesh_step_size ), np.arange(y_min, y_max, mesh_step_size ))
jeśli ja == 0:
Z = dopasowany_model.predict( np.c_[xx.ravel(), yy.ravel()] )
w przeciwnym razie:
próbować:
Z = dopasowany_model.predict_proba( np.c_[xx.ravel(), yy.ravel()] )[:, 1]
oprócz:
plt.text( 0.4, 0.5, 'Prawdopodobieństwo niedostępne', horizontalalignment = 'center', verticalalignment = 'center', transform = plt.gca().transAxes, fontsize = 12 )
oś.pl( 'wył' )
zepsuć
Z = Z.przekształć( xx.kształt )
plt.scatter( X[y.values == 0, 0], X[y.values == 0, 1], alfa = 0,4, label = 'Jadalne', s = 5 )
plt.scatter( X[y.values == 1, 0], X[y.values == 1, 1], alfa = 0,4, label = 'Trujące', s = 5 )
plt.imshow( Z, interpolation = 'nearest', cmap = 'RdYlBu_r', alpha = 0.15, extend = ( x_min, x_max, y_min, y_max ), origin = 'lower' )
plt.title( typ_druku + '\n' + str( dopasowany_model ).split( '(' )[0] + ' Dokładność testu: ' + str( np.round( dopasowany_model.score( X, y ), 5 ) ) )
plt.gca().set_aspect( 'równe' );
plt.tight_layout()
plt.subplots_adjust( góra = 0,9, dół = 0,08, wspace = 0,02 )
2. Regresja logistyczna
W przeciwieństwie do regresji liniowej, regresja logistyczna zajmuje się estymacją wartości dyskretnych (wartości binarne 0/1, prawda/fałsz, tak/nie). Ta technika jest również nazywana regresją logitową. Dzieje się tak, ponieważ przewiduje prawdopodobieństwo zdarzenia za pomocą funkcji logit do trenowania danych. Jego wartość zawsze mieści się w przedziale od 0 do 1 (ponieważ oblicza prawdopodobieństwo).
Logarytm szans wyników jest skonstruowany jako liniowa kombinacja zmiennej predykcyjnej w następujący sposób:
szanse = p / (1 – p) = prawdopodobieństwo wystąpienia zdarzenia lub prawdopodobieństwo, że zdarzenie nie wystąpi
ln( kursy ) = ln( p / (1 – p))
logit( p ) = ln( p / (1 – p) ) = b0 + b1X1 + b2X2 + b3X3 + … + bkXk
gdzie p jest prawdopodobieństwem obecności cechy.
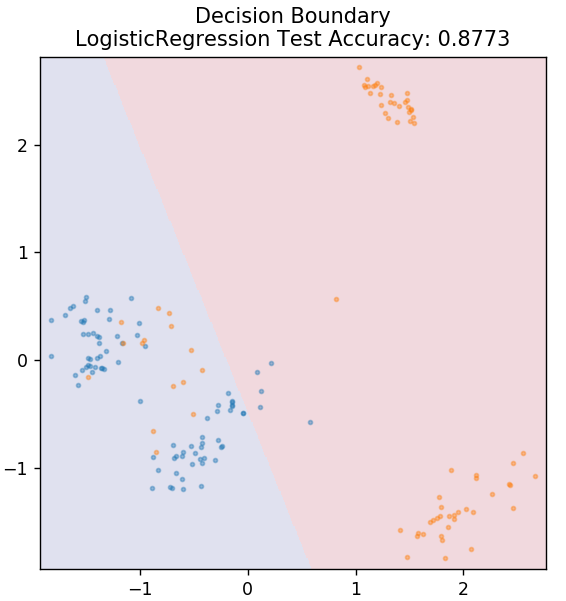
ze sklearn.linear_model import LogisticRegression
model =Regresja Logistyczna()
model.fit( X_train, y_train )
działka_grzybowa_granica( X_test, y_test, model )
Uzyskaj certyfikat sztucznej inteligencji online z najlepszych światowych uniwersytetów — studiów magisterskich, programów podyplomowych dla kadry kierowniczej i zaawansowanego programu certyfikacji w zakresie uczenia się maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
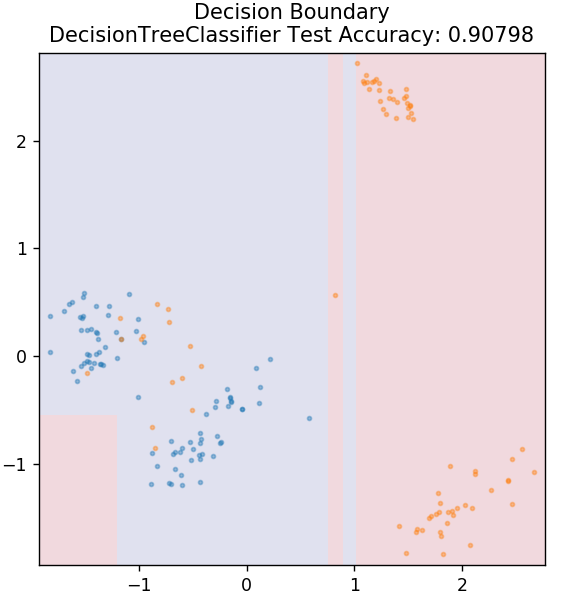
3. Drzewo decyzyjne
Jest to bardzo popularny algorytm, którego można użyć do klasyfikacji zarówno ciągłych, jak i dyskretnych zmiennych danych. Na każdym kroku dane są dzielone na więcej niż jeden jednorodny zestaw w oparciu o pewien atrybut/warunki podziału.

ze sklearn.tree importuj DecisionTreeClassifier
model = DecisionTreeClassifier( max_depth = 3 )
model.fit( X_train, y_train )
działka_grzybowa_granica( X_test, y_test, model )
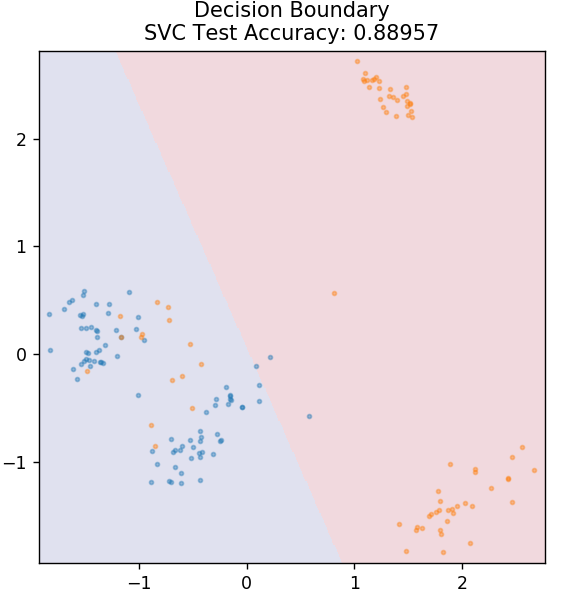
4. SVM
SVM to skrót od Support Vector Machines. Tutaj podstawową ideą jest klasyfikacja punktów danych za pomocą hiperpłaszczyzn do separacji. Celem jest znalezienie takiej hiperpłaszczyzny, która ma maksymalną odległość (lub margines) między punktami danych obu klas lub kategorii.
Samolot dobieramy w taki sposób, aby w przyszłości z największą pewnością zadbać o klasyfikację nieznanych punktów. SVM są powszechnie używane, ponieważ zapewniają wysoką dokładność, a jednocześnie zajmują mniej mocy obliczeniowej. Maszyny SVM mogą być również używane do problemów z regresją.
z sklearn.svm import SVC
model = SVC( jądro = 'liniowy' )
model.fit( X_train, y_train )
działka_grzybowa_granica( X_test, y_test, model )
Zamówienie: Projekty Pythona na GitHub
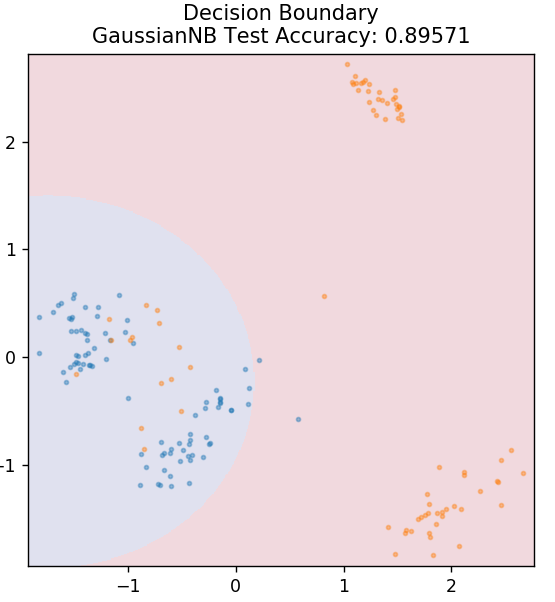
5. Naiwny Bayes
Jak sama nazwa wskazuje, algorytm Naive Bayes jest nadzorowanym algorytmem uczenia opartym na twierdzeniu Bayesa . Twierdzenie Bayesa wykorzystuje prawdopodobieństwa warunkowe, aby podać prawdopodobieństwo zdarzenia w oparciu o określoną wiedzę.
Gdzie, 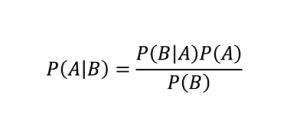
P (A | B): Warunkowe prawdopodobieństwo wystąpienia zdarzenia A, biorąc pod uwagę, że zdarzenie B już zaszło. (Zwane także prawdopodobieństwem a posteriori)
P(A): Prawdopodobieństwo zdarzenia A.
P(B): Prawdopodobieństwo zdarzenia B.
P (B | A): Warunkowe prawdopodobieństwo wystąpienia zdarzenia B, biorąc pod uwagę, że zdarzenie A już zaszło.
Pytasz, dlaczego ten algorytm nazywa się Naive? Dzieje się tak, ponieważ zakłada, że wszystkie wystąpienia zdarzeń są od siebie niezależne. Tak więc każda funkcja osobno definiuje klasę, do której należy punkt danych, bez żadnych zależności między sobą. Naive Bayes to najlepszy wybór do kategoryzacji tekstu. Sprawdzi się wystarczająco dobrze nawet z niewielką ilością danych treningowych.
z sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit( X_train, y_train )
działka_grzybowa_granica( X_test, y_test, model )
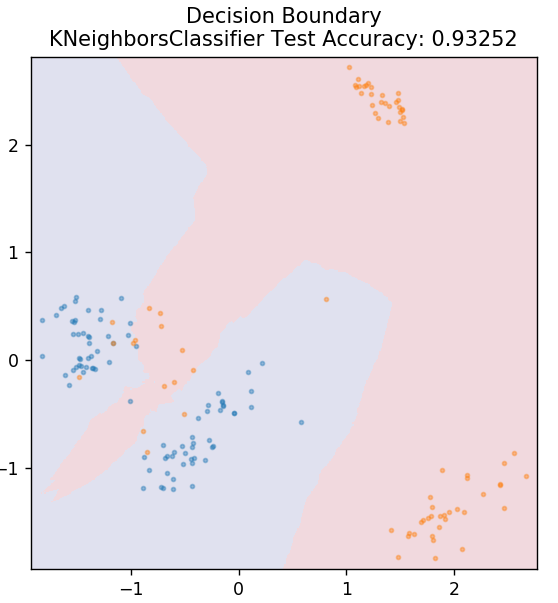
5. KNN
KNN oznacza K-Nearest Neighbours. Jest to bardzo szeroko stosowany algorytm uczenia nadzorowanego, który klasyfikuje dane testowe zgodnie z ich podobieństwami do wcześniej sklasyfikowanych danych treningowych. KNN nie klasyfikuje wszystkich punktów danych podczas treningu. Zamiast tego po prostu przechowuje zestaw danych, a gdy otrzymuje nowe dane, klasyfikuje te punkty danych na podstawie ich podobieństw. Robi to, obliczając odległość euklidesową liczby K najbliższych sąsiadów (tutaj, n_neighbors ) tego punktu danych.
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier( n_sąsiedzi = 20 )
model.fit( X_train, y_train )
działka_grzybowa_granica( X_test, y_test, model )
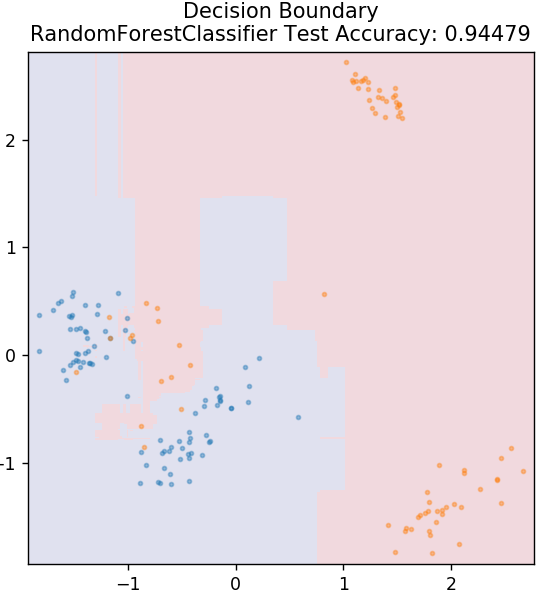
6. Losowy las
Las losowy to bardzo prosty i zróżnicowany algorytm uczenia maszynowego, który wykorzystuje technikę uczenia nadzorowanego. Jak można się domyślić po nazwie, losowy las składa się z dużej liczby drzew decyzyjnych, działających jak zespół. Każde drzewo decyzyjne określi klasę wyjściową punktów danych, a klasa większości zostanie wybrana jako końcowy wynik modelu. Pomysł polega na tym, że więcej drzew pracujących na tych samych danych będzie mieć dokładniejsze wyniki niż pojedyncze drzewa.
z sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit( X_train, y_train )
działka_grzybowa_granica( X_test, y_test, model )
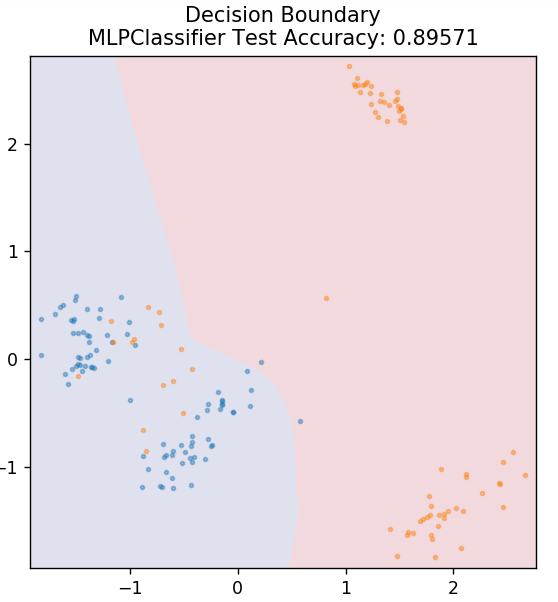
7. Perceptron wielowarstwowy
Perceptron wielowarstwowy (lub MLP) to bardzo fascynujący algorytm należący do gałęzi głębokiego uczenia. Dokładniej, należy do klasy sztucznych sieci neuronowych ze sprzężeniem do przodu (ANN). MLP tworzy sieć wielu perceptronów z co najmniej trzema warstwami: warstwą wejściową, warstwą wyjściową i warstwą ukrytą. MLP są w stanie rozróżnić dane, które można nieliniowo oddzielić.
Każdy neuron w warstwach ukrytych wykorzystuje funkcję aktywacji, aby przejść do następnej warstwy. Tutaj algorytm propagacji wstecznej jest używany do faktycznego dostrojenia parametrów, a tym samym do trenowania sieci neuronowej. Może być używany głównie do prostych problemów regresji.
ze sklearn.neural_network import MLPClassifier
model = MLPClassifier()
model.fit( X_train, y_train )
działka_grzybowa_granica( X_test, y_test, model )
Przeczytaj także: Pomysły i tematy projektów Pythona
Wniosek
Możemy stwierdzić, że różne algorytmy uczenia maszynowego dają różne granice decyzyjne, a zatem różne wyniki dokładności w klasyfikacji tego samego zbioru danych.
Nie ma możliwości zadeklarowania dowolnego algorytmu jako najlepszego algorytmu dla wszystkich rodzajów danych w ogóle. Uczenie maszynowe wymaga rygorystycznych prób i błędów dla różnych algorytmów, aby określić, co działa najlepiej dla każdego zestawu danych z osobna. Lista algorytmów ML oczywiście nie kończy się tutaj. Istnieje ogromna liczba innych technik, które czekają na odkrycie w bibliotece Pythona Scikit-Learn. Śmiało i trenuj swoje zbiory danych przy użyciu wszystkich tych elementów i baw się dobrze!
Jeśli chcesz dowiedzieć się więcej o drzewach decyzyjnych, uczeniu maszynowym, zapoznaj się z programem Executive PG w zakresie uczenia maszynowego i sztucznej inteligencji IIIT-B i upGrad, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadania, status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Jakie są główne założenia regresji liniowej?
Istnieją 4 podstawowe założenia regresji liniowej: liniowość, homoskedastyczność, niezależność i normalność. Liniowość oznacza, że związek między zmienną niezależną (X) a średnią zmiennej zależnej (Y) jest uważany za liniowy, gdy stosujemy regresję liniową. Homoskedastyczność oznacza, że wariancja błędów punktów resztowych wykresu jest zakładana jako stała. Niezależność odnosi się do wszystkich obserwacji z danych wejściowych, które należy uznać za niezależne od siebie. Normalność oznacza, że rozkład danych wejściowych może być jednorodny lub niejednorodny, ale zakłada się, że jest on równomiernie rozłożony w przypadku regresji liniowej.
Jakie są różnice między drzewem decyzyjnym a losowym lasem?
Drzewo decyzyjne wdraża swój proces decyzyjny, wykorzystując strukturę podobną do drzewa, która reprezentuje możliwe wyniki dla określonych działań. Las losowy wykorzystuje pakiet takich drzew decyzyjnych do analizy danych. Dzięki temu procesowi więcej danych zostanie wykorzystanych przez losowy las, ale pomaga to zapobiegać nadmiernemu dopasowaniu i zapewnia dokładne wyniki. W algorytmie drzewa decyzyjnego istnieje pewien zakres nadmiernego dopasowania, które może dawać mniej dokładne wyniki. Drzewo decyzyjne jest łatwe do interpretacji, ponieważ wymaga mniej obliczeń, podczas gdy losowy las jest trudny do interpretacji ze względu na złożone analizy.
Jakie są standardowe biblioteki używane do algorytmów uczenia maszynowego w Pythonie?
Python zastąpił prawie wszystkie inne języki w uczeniu maszynowym dzięki dostępności ogromnej liczby bibliotek i prostych reguł składniowych. Istnieje wiele bibliotek Pythona do uczenia maszynowego, takich jak Numpy, Scipy, Scikit-learn, Theono, TensorFlow, PyTorch, Matplotlib, Keras, Pandas itp. Korzystanie z funkcji z tych bibliotek pozwala zaoszczędzić mnóstwo czasu na pisanie algorytmów dla każdego zadania; procesy są mniej czasochłonne i zapewniają efektywne wyniki. Biblioteki te mają zastosowania, takie jak przetwarzanie macierzy, problemy z optymalizacją, eksploracja danych, analiza statystyczna, obliczenia z wykorzystaniem tensorów, wykrywanie obiektów, sieci neuronowe i wiele innych.