
Mieszanie namacalnych i niematerialnych: projektowanie interfejsów multimodalnych za pomocą Adobe XD
Opublikowany: 2022-03-10(Ten artykuł jest sponsorowany przez firmę Adobe.) Interfejsy użytkownika ewoluują. Interfejsy głosowe stanowią wyzwanie dla długiej dominacji graficznych interfejsów użytkownika i szybko stają się powszechną częścią naszego codziennego życia. Znaczący postęp w automatycznym rozpoznawaniu mowy (APS) i przetwarzaniu języka naturalnego (NLP) oraz imponująca baza konsumentów (miliony urządzeń mobilnych z wbudowanymi asystentami głosowymi) wpłynęły na szybki rozwój i przyjęcie interfejsu głosowego.
Produkty wykorzystujące głos jako podstawowy interfejs stają się coraz bardziej popularne. W samych Stanach 47,3 mln dorosłych ma dostęp do inteligentnego głośnika (to jedna piąta dorosłej populacji USA), a liczba ta rośnie. Jednak interfejsy głosowe mają przed sobą świetlaną przyszłość nie tylko w użytku osobistym i domowym. Gdy ludzie przyzwyczają się do interfejsów głosowych, będą oczekiwać ich również w kontekście biznesowym. Wyobraź sobie, że wkrótce będziesz mógł uruchomić projektor w sali konferencyjnej, mówiąc coś w stylu „Pokaż moją prezentację”.
Oczywiste jest, że komunikacja człowiek-maszyna szybko się rozszerza, obejmując zarówno interakcję pisemną, jak i ustną. Ale czy to oznacza, że przyszłe interfejsy będą wyłącznie głosowe? Pomimo pewnych przedstawień science-fiction, głos nie zastąpi całkowicie graficznych interfejsów użytkownika. Zamiast tego otrzymamy synergię głosu, obrazu i gestów w nowym formacie interfejsu: wielomodalnym interfejsie obsługującym głos.
W tym artykule:
- poznaj koncepcję interfejsu głosowego i przejrzyj różne typy interfejsów głosowych;
- dowiedz się, dlaczego obsługiwane głosem, multimodalne interfejsy użytkownika będą preferowanym interfejsem użytkownika;
- zobacz, jak możesz zbudować multimodalny interfejs użytkownika za pomocą Adobe XD.
Stan interfejsów użytkownika głosowego (VUI)
Zanim zagłębimy się w szczegóły głosowych interfejsów użytkownika, musimy zdefiniować, czym jest wprowadzanie głosowe. Wprowadzanie głosowe to interakcja człowiek-komputer, w której użytkownik wypowiada polecenia zamiast je pisać. Piękno wprowadzania głosowego polega na tym, że jest to bardziej naturalna interakcja dla ludzi — użytkownicy nie są ograniczeni do określonej składni podczas interakcji z systemem; mogą ustrukturyzować swój wkład na wiele różnych sposobów, tak jak robiliby to w ludzkiej rozmowie.
Głosowe interfejsy użytkownika przynoszą użytkownikom następujące korzyści:
- Mniejszy koszt interakcji
Chociaż korzystanie z interfejsu obsługującego głos wiąże się z kosztami interakcji, ten koszt jest (teoretycznie) mniejszy niż koszt nauki nowego GUI. - Sterowanie bez użycia rąk
VUI świetnie sprawdzają się, gdy ręce użytkownika są zajęte — na przykład podczas jazdy, gotowania lub ćwiczeń. - Prędkość
Głos jest doskonały, gdy zadawanie pytania jest szybsze niż wpisywanie go i czytanie wyników. Na przykład, używając głosu w samochodzie, szybciej jest powiedzieć miejsce do systemu nawigacyjnego, niż wpisać lokalizację na ekranie dotykowym. - Emocje i osobowość
Nawet gdy słyszymy głos, ale nie widzimy obrazu mówiącego, możemy sobie wyobrazić mówiącego w naszej głowie. Daje to możliwość zwiększenia zaangażowania użytkowników. - Dostępność
Użytkownicy niedowidzący i użytkownicy z niepełnosprawnością ruchową mogą używać głosu do interakcji z systemem.
Trzy rodzaje interfejsów obsługujących głos
W zależności od tego, jak używany jest głos, może to być jeden z następujących typów interfejsów.
Agenci głosowi na urządzeniach z pierwszym ekranem
Apple Siri i Asystent Google to najlepsze przykłady agentów głosowych. W takich systemach głos działa bardziej jak ulepszenie istniejącego GUI. W wielu przypadkach agent działa jako pierwszy krok w podróży użytkownika: użytkownik uruchamia agenta głosowego i wydaje polecenie za pomocą głosu, podczas gdy wszystkie inne interakcje są wykonywane za pomocą ekranu dotykowego. Na przykład, gdy zadasz Siri pytanie, otrzymasz odpowiedzi w formacie listy i musisz wejść w interakcję z tą listą. W rezultacie doświadczenie użytkownika staje się fragmentaryczne — używamy głosu do zainicjowania interakcji, a następnie przechodzimy na dotyk, aby ją kontynuować.
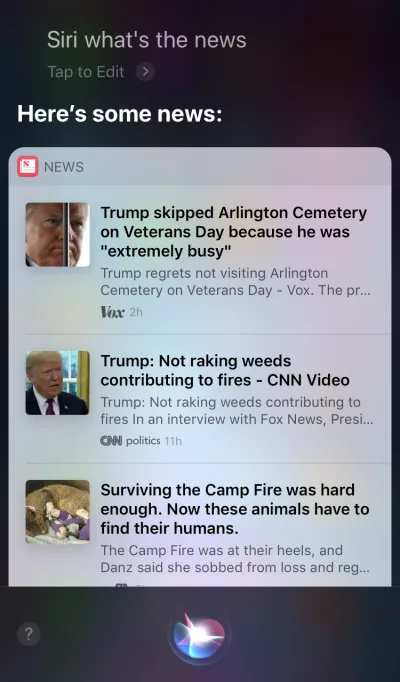
Urządzenia tylko głosowe
Te urządzenia nie mają wyświetlaczy wizualnych; użytkownicy polegają na dźwięku zarówno na wejściu, jak i wyjściu. Inteligentne głośniki Amazon Echo i Google Home to najlepsze przykłady produktów w tej kategorii. Brak wyświetlacza wizualnego jest istotnym ograniczeniem zdolności urządzenia do przekazywania użytkownikowi informacji i opcji. W rezultacie większość ludzi używa tych urządzeń do wykonywania prostych zadań, takich jak odtwarzanie muzyki i uzyskiwanie odpowiedzi na proste pytania.

Urządzenia Voice-First
W przypadku systemów głosowych, urządzenie akceptuje dane wprowadzane przez użytkownika przede wszystkim za pomocą poleceń głosowych, ale ma również zintegrowany wyświetlacz ekranowy. Oznacza to, że głos jest podstawowym interfejsem użytkownika, ale nie jedynym. Stare powiedzenie „Obraz jest wart tysiąca słów” nadal obowiązuje w nowoczesnych systemach głosowych. Ludzki mózg ma niesamowite zdolności przetwarzania obrazu — możemy szybciej zrozumieć złożone informacje, gdy widzimy je wizualnie. W porównaniu do urządzeń głosowych, urządzenia głosowe umożliwiają użytkownikom dostęp do większej ilości informacji i znacznie ułatwiają wykonywanie wielu zadań.
Amazon Echo Show to doskonały przykład urządzenia, które wykorzystuje system głosowy. Informacje wizualne są stopniowo włączane jako część całościowego systemu — ekran nie jest ładowany ikonami aplikacji; system zachęca raczej użytkowników do wypróbowania różnych poleceń głosowych (sugerując polecenia werbalne, takie jak „Spróbuj 'Alexa, pokaż mi pogodę o 17:00'”). Ekran znacznie ułatwia nawet typowe zadania, takie jak sprawdzanie przepisu podczas gotowania — użytkownicy nie muszą uważnie słuchać i przechowywać wszystkie informacje w głowie; kiedy potrzebują informacji, po prostu patrzą na ekran.

Przedstawiamy interfejsy multimodalne
Jeśli chodzi o używanie głosu w projektowaniu interfejsu użytkownika, nie myśl o głosie jako o czymś, z czego możesz korzystać samodzielnie. Urządzenia takie jak Amazon Echo Show zawierają ekran, ale wykorzystują głos jako podstawową metodę wprowadzania, co zapewnia bardziej holistyczne wrażenia użytkownika. To pierwszy krok w kierunku nowej generacji interfejsów użytkownika: interfejsów multimodalnych.
Interfejs multimodalny to interfejs, który łączy głos, dotyk, dźwięk i różne rodzaje efektów wizualnych w jednym, płynnym interfejsie użytkownika. Amazon Echo Show to doskonały przykład urządzenia, które w pełni wykorzystuje wielomodalny interfejs głosowy. Kiedy użytkownicy wchodzą w interakcję z Show, wysyłają żądania tak samo, jak w przypadku urządzenia głosowego; jednak odpowiedź, którą otrzymają, będzie prawdopodobnie multimodalna, zawierająca zarówno odpowiedzi głosowe, jak i wizualne.
Produkty multimodalne są bardziej złożone niż produkty, które opierają się wyłącznie na wizualizacji lub tylko na głosie. Dlaczego w ogóle ktoś miałby tworzyć interfejs multimodalny? Aby odpowiedzieć na to pytanie, musimy cofnąć się i zobaczyć, jak ludzie postrzegają otaczające ich środowisko. Ludzie mają pięć zmysłów, a połączenie naszych współdziałających zmysłów to sposób, w jaki postrzegamy rzeczy. Na przykład nasze zmysły współpracują ze sobą, gdy słuchamy muzyki na koncercie na żywo. Usuń jeden zmysł (na przykład słuch), a doświadczenie nabierze zupełnie innego kontekstu.

Zbyt długo myśleliśmy, że wrażenia użytkownika to wyłącznie projekt wizualny lub gestykulacyjny. Czas zmienić to myślenie. Projektowanie multimodalne to sposób na myślenie i projektowanie dla doświadczeń, które łączą ze sobą nasze zdolności sensoryczne.
Interfejsy multimodalne wydają się bardziej ludzkim sposobem komunikowania się użytkownika i maszyny. Otwierają nowe możliwości głębszych interakcji. A dzisiaj znacznie łatwiej jest projektować interfejsy multimodalne, ponieważ znikają ograniczenia techniczne, które w przeszłości ograniczały interakcje z produktami.
Różnica między graficznym interfejsem użytkownika a interfejsem multimodalnym
Kluczową różnicą jest to, że interfejsy multimodalne, takie jak Amazon Echo Show, synchronizują interfejsy głosowe i wizualne. W rezultacie, kiedy projektujemy doświadczenie, głos i wizualizacje nie są już niezależnymi częściami; są integralną częścią doświadczenia zapewnianego przez system.
Kanał wizualny i głosowy: kiedy używać każdego
Ważne jest, aby myśleć o głosie i obrazach jako kanałach wejściowych i wyjściowych. Każdy kanał ma swoje mocne i słabe strony.
Zacznijmy od wizualizacji. Oczywiste jest, że niektóre informacje są po prostu łatwiejsze do zrozumienia, gdy je widzimy, niż gdy je słyszymy. Wizualizacje działają lepiej, gdy trzeba zapewnić:
- długie listy opcji (czytanie długiej listy zajmie dużo czasu i będzie trudne do naśladowania);
- informacje z dużą ilością danych (takie jak diagramy i wykresy);
- informacje o produktach (np. produkty w sklepach internetowych; najprawdopodobniej przed zakupem chciałbyś zobaczyć produkt) i porównanie produktów (podobnie jak przy długiej liście opcji, ciężko byłoby podać wszystkie informacje wyłącznie głosem) .
W przypadku niektórych informacji możemy jednak z łatwością polegać na komunikacji werbalnej. Głos może być odpowiedni w następujących przypadkach:
- komendy użytkownika (głos to wydajna metoda wprowadzania, umożliwiająca użytkownikom szybkie wydawanie komend systemowi i pominięcie złożonych menu nawigacyjnych);
- proste instrukcje dla użytkownika (na przykład rutynowa kontrola recepty);
- ostrzeżenia i powiadomienia (na przykład ostrzeżenie dźwiękowe połączone z powiadomieniami głosowymi podczas jazdy).
Chociaż jest to kilka typowych przypadków połączenia wizualnego i głosowego, ważne jest, aby wiedzieć, że nie możemy ich oddzielić od siebie. Możemy stworzyć lepsze wrażenia użytkownika tylko wtedy, gdy zarówno głos, jak i grafika współpracują ze sobą. Załóżmy na przykład, że chcemy kupić nową parę butów. Moglibyśmy użyć głosu, aby zażądać od systemu „Pokaż mi buty New Balance”. System przetworzy Twoje żądanie i wizualnie dostarczy informacje o produkcie (łatwiejszy sposób na porównanie butów).
Co musisz wiedzieć, aby zaprojektować interfejsy multimodalne z obsługą głosową
Głos to jedno z najbardziej ekscytujących wyzwań dla projektantów UX. Pomimo nowości, podstawowe zasady projektowania wielomodalnego interfejsu głosowego są takie same, jak te, których używamy do tworzenia projektów wizualnych. Projektanci powinni dbać o swoich użytkowników. Powinny dążyć do zmniejszenia tarcia dla użytkownika poprzez skuteczne rozwiązywanie jego problemów i priorytetowo traktować jasność, aby wybory użytkownika były jasne.
Ale istnieją również pewne unikalne zasady projektowania interfejsów multimodalnych.
Upewnij się, że rozwiążesz właściwy problem
Design powinien rozwiązywać problemy. Ale ważne jest, aby rozwiązać właściwe problemy; w przeciwnym razie możesz poświęcić dużo czasu na tworzenie środowiska, które nie przyniesie użytkownikom dużej wartości. Dlatego upewnij się, że koncentrujesz się na rozwiązaniu właściwego problemu. Interakcje głosowe powinny mieć sens dla użytkownika; użytkownicy powinni mieć ważny powód, by używać głosu zamiast innych metod interakcji (takich jak klikanie lub stukanie). Dlatego podczas tworzenia nowego produktu — jeszcze przed rozpoczęciem projektowania — niezbędne jest przeprowadzenie badań użytkowników i ustalenie, czy głos poprawi UX.
Zacznij od stworzenia mapy podróży użytkownika. Przeanalizuj mapę podróży i znajdź miejsca, w których włączenie głosu jako kanału byłoby korzystne dla UX.
- Znajdź miejsca w podróży, w których użytkownicy mogą napotkać tarcia i frustrację. Czy użycie głosu zmniejszyłoby tarcie?
- Pomyśl o kontekście użytkownika. Czy głos będzie działał w określonym kontekście?
- Zastanów się, co jest wyjątkowo możliwe dzięki głosowi. Pamiętaj o wyjątkowych zaletach używania głosu, takich jak interakcja bez użycia rąk i oczu. Czy głos może dodać wartość do doświadczenia?
Twórz przepływy konwersacji
Idealnie, projektowane interfejsy powinny wymagać zerowych kosztów interakcji: użytkownicy powinni być w stanie zaspokoić swoje potrzeby bez poświęcania dodatkowego czasu na naukę interakcji z systemem. Dzieje się tak tylko wtedy, gdy interakcja głosowa przypomina prawdziwą rozmowę, a nie dialog systemowy opakowany w format poleceń głosowych. Podstawowa zasada dobrego interfejsu użytkownika jest prosta: komputery powinny dostosowywać się do ludzi, a nie odwrotnie.
Ludzie rzadko prowadzą płaskie, linearne rozmowy (rozmowy trwające tylko jedną turę). Dlatego, aby interakcja z systemem przypominała rozmowę na żywo, projektanci powinni skupić się na tworzeniu przepływów konwersacyjnych. Każdy przepływ konwersacji składa się z dialogów — ścieżek, które występują między systemem a użytkownikiem. Każde okno dialogowe zawierałoby monity systemu i możliwe odpowiedzi użytkownika.
Przepływ konwersacyjny można przedstawić w formie diagramu przepływu. Każdy przepływ powinien koncentrować się na jednym konkretnym przypadku użycia (na przykład ustawienie budzika za pomocą systemu). W przypadku większości okien dialogowych w przepływie ważne jest, aby wziąć pod uwagę ścieżki błędów, gdy coś pójdzie nie tak.
Każde polecenie głosowe użytkownika składa się z trzech kluczowych elementów: intencji, wypowiedzi i slotu.
- Intencja jest celem interakcji użytkownika z systemem obsługującym głos.
Intencja to tylko fantazyjny sposób na zdefiniowanie celu kryjącego się za zestawem słów. Każda interakcja z systemem przynosi użytkownikowi pewną użyteczność. Niezależnie od tego, czy jest to informacja, czy działanie, narzędzie jest zamierzone. Zrozumienie intencji użytkownika jest kluczową częścią interfejsów obsługujących głos. Kiedy projektujemy VUI, nie zawsze wiemy na pewno, jakie są intencje użytkownika, ale możemy je odgadnąć z dużą dokładnością. - Wypowiedź to sposób, w jaki użytkownik formułuje swoją prośbę.
Zwykle użytkownicy mają więcej niż jeden sposób formułowania polecenia głosowego. Na przykład możemy ustawić budzik, mówiąc „Ustaw budzik na 8 rano”, „Budzik jutro o 8 rano” lub nawet „Muszę wstać o 8 rano”. Projektanci muszą wziąć pod uwagę każdą możliwą odmianę wypowiedzi. - Gniazda to zmienne, których użytkownicy używają w poleceniu. Czasami użytkownicy muszą podać w żądaniu dodatkowe informacje. W naszym przykładzie budzika „8 rano” to szczelina.
Nie wkładaj słów w usta użytkownika
Ludzie wiedzą, jak rozmawiać. Nie próbuj uczyć ich poleceń. Unikaj wyrażeń typu „Aby wysłać termin spotkania, musisz powiedzieć „Kalendarz, spotkania, utwórz nowe spotkanie”. Jeśli musisz wyjaśnić polecenia, musisz przemyśleć sposób, w jaki projektujesz system. Zawsze staraj się rozmawiać w języku naturalnym i staraj się dostosować do różnych stylów mówienia).
Dąż do spójności
Musisz osiągnąć spójność języka i głosu w różnych kontekstach. Spójność pomoże w budowaniu znajomości w interakcjach.
Zawsze przekaż opinię
Widoczność stanu systemu jest jedną z podstawowych zasad dobrego projektowania GUI. System powinien zawsze informować użytkowników o tym, co się dzieje, poprzez odpowiednią informację zwrotną w rozsądnym czasie. Ta sama zasada dotyczy projektowania VUI.
- Poinformuj użytkownika, że system nasłuchuje.
Pokaż wizualne wskaźniki, gdy urządzenie nasłuchuje lub przetwarza żądanie użytkownika. Bez informacji zwrotnej użytkownik może tylko zgadywać, czy system coś robi. Dlatego nawet urządzenia tylko głosowe, takie jak Amazon Echo i Google Home, dają nam ładne wizualne informacje zwrotne (migające światła), gdy słuchają lub szukają odpowiedzi. - Zapewnij markery konwersacyjne.
Znaczniki konwersacji informują użytkownika, na jakim etapie rozmowy się znajduje. - Potwierdź zakończenie zadania.
Na przykład, gdy użytkownicy pytają system inteligentnego domu z obsługą głosową „Wyłącz światła w garażu”, system powinien poinformować użytkownika, że polecenie zostało wykonane pomyślnie. Bez potwierdzenia użytkownicy będą musieli wejść do garażu i sprawdzić oświetlenie. Jest to sprzeczne z celem systemu inteligentnego domu, jakim jest ułatwienie życia użytkownikowi.
Unikaj długich zdań
Projektując system z obsługą głosu, należy wziąć pod uwagę sposób, w jaki przekazujesz informacje użytkownikom. Stosunkowo łatwo jest przytłoczyć użytkowników zbyt dużą ilością informacji, używając długich zdań. Po pierwsze, użytkownicy nie mogą zachować wielu informacji w pamięci krótkotrwałej, więc mogą łatwo zapomnieć o niektórych ważnych informacjach. Ponadto dźwięk jest wolnym medium — większość ludzi czyta znacznie szybciej niż słucha.
Szanuj czas swojego użytkownika; nie czytaj długich monologów audio. Kiedy projektujesz odpowiedź, im mniej słów użyjesz, tym lepiej. Pamiętaj jednak, że nadal musisz podać wystarczającą ilość informacji, aby użytkownik mógł wykonać swoje zadanie. Dlatego jeśli nie możesz streścić odpowiedzi w kilku słowach, zamiast tego wyświetl ją na ekranie.

Podaj kolejne kroki sekwencyjnie
Użytkownicy mogą być przytłoczeni nie tylko długimi zdaniami, ale także liczbą opcji na raz. Niezwykle ważne jest rozbicie procesu interakcji z systemem obsługującym głos na kawałki wielkości jednego kęsa. Ogranicz liczbę wyborów, które użytkownik ma w danym momencie i upewnij się, że wie, co robić w każdej chwili.
Projektując złożony system głosowy z wieloma funkcjami, możesz skorzystać z techniki progresywnego ujawniania: Przedstaw tylko opcje lub informacje niezbędne do wykonania zadania.
Miej silną strategię radzenia sobie z błędami
Oczywiście system powinien przede wszystkim zapobiegać występowaniu błędów. Ale bez względu na to, jak dobry jest Twój system głosowy, zawsze powinieneś projektować scenariusz, w którym system nie rozumie użytkownika. Twoim obowiązkiem jest zaprojektowanie takich przypadków.
Oto kilka praktycznych wskazówek dotyczących tworzenia strategii:
- Nie obwiniaj użytkownika.
W rozmowie nie ma błędów. Staraj się unikać odpowiedzi typu „Twoja odpowiedź jest nieprawidłowa”. - Zapewnij przepływy odzyskiwania błędów.
Zapewnij możliwość przechodzenia w tę i z powrotem w rozmowie, a nawet wyjścia z systemu bez utraty ważnych informacji. Zapisz stan użytkownika w podróży, aby mógł ponownie nawiązać kontakt z systemem od samego początku. - Pozwól użytkownikom odtwarzać informacje.
Zapewnij opcję, aby system powtórzył pytanie lub odpowiedź. Może to być przydatne w przypadku złożonych pytań lub odpowiedzi, w których użytkownikowi trudno byłoby zapisać wszystkie informacje w pamięci roboczej. - Podaj sformułowanie stop.
W niektórych przypadkach użytkownik nie będzie zainteresowany słuchaniem opcji i będzie chciał, aby system przestał o niej mówić. Stopniowanie powinno im w tym pomóc. - Z wdziękiem obchodź się z nieoczekiwanymi wypowiedziami.
Bez względu na to, ile zainwestujesz w projekt systemu, będą sytuacje, w których system nie zrozumie użytkownika. Ważne jest, aby z wdziękiem zajmować się takimi przypadkami. Nie bój się, aby system przyznał się do braku zrozumienia. System powinien komunikować to, co zrozumiał i udzielać pomocnych podpowiedzi. - Korzystaj z analiz, aby ulepszyć swoją strategię błędów.
Analytics może pomóc w zidentyfikowaniu niewłaściwych zwrotów i błędnych interpretacji.
Śledź kontekst
Upewnij się, że system rozumie kontekst danych wprowadzonych przez użytkownika. Na przykład, gdy ktoś mówi, że chce zarezerwować lot do San Francisco w przyszłym tygodniu, może odwoływać się do „to” lub „miasto” podczas rozmowy. System powinien zapamiętać to, co zostało powiedziane i być w stanie dopasować to do nowo otrzymanych informacji.
Dowiedz się więcej o swoich użytkownikach, aby tworzyć bardziej zaawansowane interakcje
System obsługujący głos staje się bardziej wyrafinowany, gdy wykorzystuje dodatkowe informacje (takie jak kontekst użytkownika lub zachowanie w przeszłości), aby zrozumieć, czego chce użytkownik. Technika ta nazywana jest inteligentną interpretacją i wymaga, aby system aktywnie poznawał użytkownika i był w stanie odpowiednio dostosować jego zachowanie. Ta wiedza pomoże systemowi udzielać odpowiedzi nawet na złożone pytania, np. „Jaki prezent kupić na urodziny żony?”
Nadaj swojemu VUI osobowość
Każdy system obsługujący głos ma emocjonalny wpływ na użytkownika, niezależnie od tego, czy planujesz to, czy nie. Ludzie kojarzą głos raczej z ludźmi niż z maszynami. Według badań Speak Easy Global Edition 74% stałych użytkowników technologii głosowych oczekuje, że marki będą miały unikalne głosy i osobowości w swoich produktach obsługujących głos. Możliwe jest zbudowanie empatii poprzez osobowość i osiągnięcie wyższego poziomu zaangażowania użytkownika.
Postaraj się odzwierciedlić swoją wyjątkową markę i tożsamość w głosie i tonie, który prezentujesz. Skonstruuj personę swojego agenta obsługującego głos i polegaj na tej personie podczas tworzenia okien dialogowych.
Budować zaufanie
Gdy użytkownicy nie ufają systemowi, nie mają motywacji do korzystania z niego. Dlatego budowanie zaufania jest wymogiem projektowania produktu. Dwa czynniki mają istotny wpływ na poziom zbudowanego zaufania: możliwości systemu i prawidłowy wynik.
Budowanie zaufania zaczyna się od ustalenia oczekiwań użytkowników. Tradycyjne GUI zawierają wiele szczegółów wizualnych, które pomagają użytkownikowi zrozumieć, do czego zdolny jest system. Dzięki systemowi z obsługą głosu projektanci mają mniej narzędzi, na których mogą polegać. Mimo to ważne jest, aby system był naturalnie wykrywalny; użytkownik powinien zrozumieć, co jest, a co nie jest możliwe w systemie. Dlatego system obsługujący głos może wymagać wprowadzenia użytkownika, w którym mówi o tym, co system może zrobić lub co wie. Podczas projektowania onboardingu postaraj się podać sensowne przykłady, aby ludzie wiedzieli, co może zrobić (przykłady działają lepiej niż instrukcje).
Jeśli chodzi o prawidłowe wyniki, ludzie wiedzą, że systemy głosowe są niedoskonałe. Gdy system dostarcza odpowiedzi, niektórzy użytkownicy mogą wątpić, czy odpowiedź jest prawidłowa. dzieje się tak, ponieważ użytkownicy nie mają żadnych informacji o tym, czy ich żądanie zostało poprawnie zrozumiane lub jakiego algorytmu użyto do znalezienia odpowiedzi. Aby zapobiec problemom z zaufaniem, użyj ekranu do potwierdzania dowodów — wyświetl oryginalne zapytanie na ekranie — i podaj kilka kluczowych informacji o algorytmie. Na przykład, gdy użytkownik zapyta „Pokaż mi pięć najlepszych filmów 2018 roku”, system może powiedzieć „Oto pięć najlepszych filmów 2018 roku według kas w USA”.
Nie ignoruj bezpieczeństwa i prywatności danych
W przeciwieństwie do urządzeń mobilnych, które należą do osoby, urządzenia głosowe zwykle przynależą do miejsca, na przykład kuchni. Zwykle w tej samej lokalizacji znajduje się więcej niż jedna osoba. Wyobraź sobie, że ktoś inny może wchodzić w interakcję z systemem, który ma dostęp do wszystkich Twoich danych osobowych. Niektóre systemy VUI, takie jak Amazon Alexa, Google Assistant i Apple Siri, potrafią rozpoznawać poszczególne głosy, co dodaje systemowi warstwę bezpieczeństwa. Nie gwarantuje to jednak, że system będzie w stanie rozpoznać użytkowników na podstawie ich unikalnego podpisu głosowego w 100% przypadków.
Rozpoznawanie głosu stale się poprawia iw najbliższej przyszłości naśladowanie głosu będzie trudne lub prawie niemożliwe. Jednak w obecnej rzeczywistości bardzo ważne jest zapewnienie dodatkowej warstwy uwierzytelniania, aby upewnić użytkownika, że jego dane są bezpieczne. Jeśli projektujesz aplikację, która działa z danymi wrażliwymi, takimi jak informacje o stanie zdrowia lub dane bankowe, możesz uwzględnić dodatkowy etap uwierzytelniania, taki jak hasło, odcisk palca lub rozpoznawanie twarzy.
Przeprowadź testy użyteczności
Testowanie użyteczności jest obowiązkowym wymogiem dla każdego systemu. Testuj wcześnie, test często powinien być podstawową zasadą procesu projektowania. Zbierz dane z badań użytkowników na wczesnym etapie i powtórz swoje projekty. Jednak testowanie interfejsów multimodalnych ma swoją specyfikę. Oto dwie fazy, które należy wziąć pod uwagę:
- Faza ideacji
Przetestuj swoje przykładowe okna dialogowe. Poćwicz czytanie na głos przykładowych dialogów. Po przeprowadzeniu konwersacji nagraj obie strony rozmowy (wypowiedzi użytkownika i odpowiedzi systemu) i odsłuchaj nagranie, aby zrozumieć, czy brzmią naturalnie. - Wczesne etapy rozwoju produktu (testowanie z prototypami lo-fi)
Testy Wizard of Oz dobrze nadają się do testowania interfejsów konwersacyjnych. Testy Wizard of Oz to rodzaj testów, w których uczestnik wchodzi w interakcję z systemem, który jego zdaniem jest obsługiwany przez komputer, ale w rzeczywistości jest obsługiwany przez człowieka. Uczestnik testu formułuje zapytanie, a po drugiej stronie odpowiada prawdziwa osoba. Ta metoda ma swoją nazwę od książki The Wonderful Wizard of Oz autorstwa Franka Bauma. W książce zwykły człowiek chowa się za zasłoną, udając potężnego czarodzieja. Ten test pozwala na zmapowanie każdego możliwego scenariusza interakcji i w rezultacie stworzenie bardziej naturalnych interakcji. Say Wizard to świetne narzędzie, które pomoże Ci uruchomić test interfejsu głosowego Wizard of Oz w systemie macOS. - Późniejsze etapy rozwoju produktu (testy z prototypami hi-fi)
W testach użyteczności graficznych interfejsów użytkownika często prosimy użytkowników o głośne mówienie podczas interakcji z systemem. W przypadku systemu z obsługą głosu nie zawsze jest to możliwe, ponieważ system będzie słuchał tej narracji. Dlatego może lepiej obserwować interakcje użytkownika z systemem, niż prosić go o głośne wypowiadanie się.
Jak stworzyć interfejs multimodalny za pomocą Adobe XD
Teraz, gdy już dobrze rozumiesz, czym jest interfejs multimodalny i o jakich zasadach należy pamiętać podczas ich projektowania, możemy omówić, jak zrobić prototyp interfejsu multimodalnego.
Prototypowanie to podstawowa część procesu projektowania. Możliwość wcielenia pomysłu w życie i podzielenia się nim z innymi jest niezwykle ważna. Do tej pory projektanci, którzy chcieli włączyć głos w prototypowanie, mieli niewiele narzędzi, na których mogliby polegać, z których najpotężniejszym był schemat blokowy. Wyobrażenie sobie interakcji użytkownika z systemem wymagało dużej wyobraźni od osoby patrzącej na schemat blokowy. Dzięki Adobe XD projektanci mają teraz dostęp do medium głosowego i mogą go używać w swoich prototypach. XD płynnie łączy prototypowanie ekranu i głosu w jednej aplikacji.
Nowe doświadczenia, ten sam proces
Chociaż głos jest zupełnie innym medium niż wizualny, proces prototypowania głosu w Adobe XD jest prawie taki sam, jak tworzenie prototypów dla GUI. Zespół Adobe XD integruje głos w sposób naturalny i intuicyjny dla każdego projektanta. Projektanci mogą używać wyzwalaczy głosowych i odtwarzania mowy do interakcji z prototypami:
- Wyzwalacze głosowe rozpoczynają interakcję, gdy użytkownik wypowiada określone słowo lub frazę (wypowiedź).
- Odtwarzanie mowy daje projektantom dostęp do mechanizmu zamiany tekstu na mowę. XD wypowiada słowa i zdania zdefiniowane przez projektanta. Odtwarzanie mowy może być wykorzystywane do wielu różnych celów. Na przykład może działać jako potwierdzenie (aby uspokoić użytkowników) lub jako wskazówka (aby użytkownicy wiedzieli, co dalej).
Wspaniałą rzeczą w XD jest to, że nie zmusza Cię do poznawania złożoności każdej platformy głosowej.
Dosyć słów — zobaczmy, jak to działa w akcji. We wszystkich przykładach, które zobaczysz poniżej, użyłem obszarów roboczych utworzonych za pomocą zestawu Adobe XD UI dla Amazon Alexa (jest to link do pobrania zestawu). Zestaw zawiera wszystkie style i komponenty potrzebne do tworzenia doświadczeń dla Amazon Alexa.
Załóżmy, że mamy następujące obszary robocze:
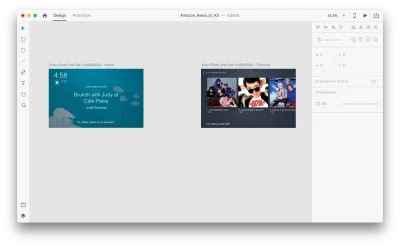
Przejdźmy do trybu prototypowania, aby dodać kilka interakcji głosowych. Zaczniemy od wyzwalaczy głosowych. Wraz z wyzwalaczami, takimi jak dotknięcie i przeciągnięcie, możemy teraz używać głosu jako wyzwalacza. Do wyzwalaczy głosowych możemy użyć dowolnych warstw, o ile mają one uchwyt prowadzący do innego obszaru roboczego. Połączmy razem obszary robocze.
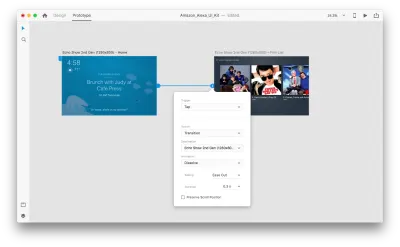
Gdy to zrobimy, znajdziemy nową opcję „Głos” pod „Wyzwalaczem”. Po wybraniu tej opcji zobaczymy pole „Polecenie”, którego możemy użyć do wprowadzenia wypowiedzi — tego właśnie nasłuchuje XD. Użytkownicy będą musieli wypowiedzieć to polecenie, aby aktywować wyzwalacz.
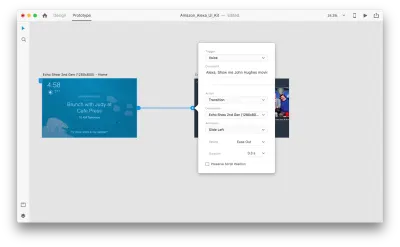
To wszystko! Zdefiniowaliśmy naszą pierwszą interakcję głosową. Teraz użytkownicy mogą coś powiedzieć, a prototyp odpowie na to. Ale możemy uczynić tę interakcję znacznie bardziej wydajną, dodając odtwarzanie mowy. Jak wspomniałem wcześniej, odtwarzanie mowy pozwala systemowi wypowiadać pewne słowa.
Wybierz cały drugi obszar roboczy i kliknij niebieski uchwyt. Wybierz wyzwalacz „Czas” z opóźnieniem i ustaw go na 0,2s. Pod akcją znajdziesz „Odtwarzanie mowy”. Napiszemy, co mówi nam wirtualna asystentka.
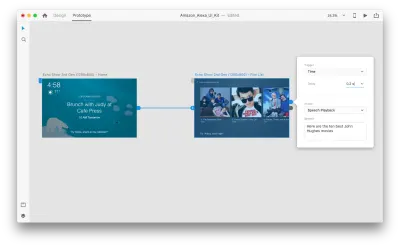
Jesteśmy gotowi do przetestowania naszego prototypu. Wybierz pierwszy obszar roboczy, a kliknięcie przycisku odtwarzania w prawym górnym rogu otworzy okno podglądu. Podczas interakcji z prototypowaniem głosu upewnij się, że mikrofon jest włączony. Następnie przytrzymaj spację, aby wypowiedzieć polecenie głosowe. To wejście wyzwala następną akcję w prototypie.
Użyj funkcji Auto-Animate, aby uczynić doświadczenie bardziej dynamicznym
Animacja przynosi wiele korzyści w projektowaniu interfejsu użytkownika. Służy jasnym celom funkcjonalnym, takim jak:
- komunikowanie relacji przestrzennych między obiektami (Skąd pochodzi obiekt? Czy te obiekty są ze sobą powiązane?);
- afordancja komunikacyjna (Co mogę zrobić dalej?)
Jednak cele funkcjonalne to nie jedyne korzyści płynące z animacji; animacja sprawia również, że doświadczenie jest bardziej żywe i dynamiczne. Dlatego animacje UI powinny być naturalną częścią interfejsów multimodalnych.
Dzięki funkcji „Auto-Animate” dostępnej w Adobe XD znacznie łatwiej jest tworzyć prototypy z wciągającymi animowanymi przejściami. Adobe XD wykonuje całą ciężką pracę za Ciebie, więc nie musisz się tym martwić. Wszystko, co musisz zrobić, aby utworzyć animowane przejście między dwoma obszarami roboczymi, to po prostu zduplikować obszar roboczy, zmodyfikować właściwości obiektu w klonie (właściwości takie jak rozmiar, położenie i obrót) i zastosować akcję Auto-Animacja. XD automatycznie animuje różnice we właściwościach między każdym obszarem roboczym.
Zobaczmy, jak to działa w naszym projekcie. Załóżmy, że mamy istniejącą listę zakupów w Amazon Echo Show i chcemy dodać nowy obiekt do listy za pomocą głosu. Zduplikuj następujący obszar roboczy:
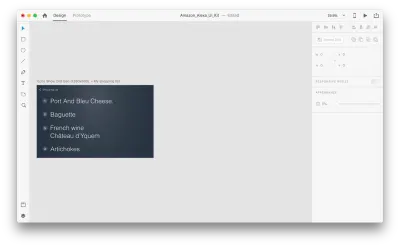
Wprowadźmy kilka zmian w układzie: Dodaj nowy obiekt. Nie jesteśmy tu ograniczeni, więc możemy łatwo modyfikować dowolne właściwości, takie jak atrybuty tekstu, kolor, krycie, położenie obiektu — w zasadzie wszelkie zmiany, które wprowadzimy, XD będzie animował między nimi.
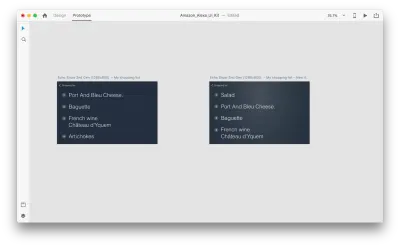
Gdy połączysz ze sobą dwa obszary robocze w trybie prototypu za pomocą funkcji Auto-Animate w „Działaniu”, XD automatycznie animuje różnice we właściwościach między każdym obszarem roboczym.
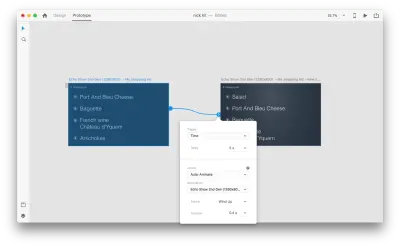
A oto jak interakcja będzie wyglądać dla użytkowników:

Jedna kluczowa rzecz, o której należy wspomnieć: zachowaj takie same nazwy wszystkich warstw; w przeciwnym razie Adobe XD nie będzie w stanie zastosować automatycznej animacji.
Wniosek
Jesteśmy u zarania rewolucji interfejsu użytkownika. Nowa generacja interfejsów — interfejsy multimodalne — nie tylko zapewni użytkownikom więcej możliwości, ale także zmieni sposób interakcji użytkowników z systemami. We will probably still have displays, but we won't need keyboards to interact with the systems.
At the same time, the fundamental requirements for designing multimodal interfaces won't be much different from those of designing modern interfaces. Designers will need to keep the interaction simple; focus on the user and their needs; design, prototype, test and iterate.
And the great thing is that you don't need to wait to start designing for this new generation of interfaces. You can start today.
Ten artykuł jest częścią serii projektów UX sponsorowanych przez firmę Adobe. Narzędzie Adobe XD zostało stworzone z myślą o szybkim i płynnym procesie projektowania UX, ponieważ pozwala szybciej przejść od pomysłu do prototypu. Projektuj, prototypuj i udostępniaj — wszystko w jednej aplikacji. Możesz zapoznać się z bardziej inspirującymi projektami stworzonymi za pomocą Adobe XD w serwisie Behance, a także zapisać się do biuletynu Adobe Experience Design, aby być na bieżąco i otrzymywać informacje o najnowszych trendach i spostrzeżeniach dotyczących projektowania UX/UI.