
Samouczek uczenia maszynowego: Naucz się ML od podstaw
Opublikowany: 2022-02-17Wdrażanie rozwiązań sztucznej inteligencji (AI) i uczenia maszynowego (ML) nadal przyspiesza różne procesy biznesowe , a poprawa doświadczenia klienta jest najczęstszym przypadkiem użycia.
Dziś uczenie maszynowe ma szerokie zastosowanie, a większość z nich to technologie, z którymi spotykamy się na co dzień. Na przykład Netflix lub podobne platformy OTT wykorzystują uczenie maszynowe do personalizowania sugestii dla każdego użytkownika. Jeśli więc użytkownik często ogląda thrillery kryminalne lub szuka tego samego, system rekomendacji oparty na platformie ML zacznie sugerować więcej filmów z podobnego gatunku. Podobnie Facebook i Instagram personalizują kanał użytkownika na podstawie postów, z którymi często wchodzą w interakcję.
W tym samouczku dotyczącym uczenia maszynowego w Pythonie omówimy podstawy uczenia maszynowego. Dołączyliśmy również krótki samouczek głębokiego uczenia się, aby przedstawić tę koncepcję początkującym.
Spis treści
Co to jest uczenie maszynowe?
Termin „uczenie maszynowe” został ukuty w 1959 roku przez Arthura Samuela, pioniera w grach komputerowych i sztucznej inteligencji.
Uczenie maszynowe to podzbiór sztucznej inteligencji. Opiera się na założeniu, że oprogramowanie (programy) może uczyć się na podstawie danych, rozszyfrowywać wzorce i podejmować decyzje przy minimalnej ingerencji człowieka. Innymi słowy, ML to obszar nauk obliczeniowych, który umożliwia użytkownikowi wprowadzanie ogromnej ilości danych do algorytmu, a system analizuje i podejmuje decyzje oparte na danych na podstawie danych wejściowych. Dlatego algorytmy ML nie opierają się na z góry określonym modelu, a zamiast tego bezpośrednio „uczą się” informacji z wprowadzonych danych.
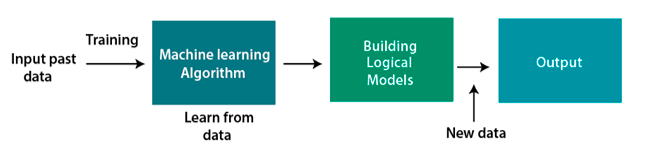
Źródło

Oto uproszczony przykład –
Jak napisać program, który identyfikuje kwiaty na podstawie koloru, kształtu płatka lub innych właściwości? Chociaż najbardziej oczywistym sposobem byłoby wprowadzenie podstawowych zasad identyfikacji, takie podejście nie sprawi, że idealne zasady będą miały zastosowanie we wszystkich przypadkach. Jednak uczenie maszynowe wymaga bardziej praktycznej i solidnej strategii i zamiast tworzyć z góry określone reguły, trenuje system, dostarczając mu dane (obrazy) różnych kwiatów. Tak więc następnym razem, gdy systemowi pokaże się różę i słonecznik, można je sklasyfikować na podstawie wcześniejszych doświadczeń.
Przeczytaj , jak nauczyć się uczenia maszynowego – krok po kroku
Rodzaje uczenia maszynowego
Klasyfikacja uczenia maszynowego opiera się na tym, jak algorytm uczy się dokładniej przewidywać wyniki. Tak więc istnieją trzy podstawowe podejścia do uczenia maszynowego: uczenie nadzorowane, uczenie nienadzorowane i uczenie się ze wzmocnieniem.
Nadzorowana nauka
W nadzorowanym uczeniu maszynowym algorytmy są dostarczane z oznaczonymi danymi treningowymi. Ponadto użytkownik definiuje zmienne, które ma oceniać algorytm; zmienne docelowe to zmienne, które chcemy przewidzieć, a cechy to zmienne, które pomagają nam przewidzieć cel. To raczej tak, że pokazujemy algorytmowi obraz ryby i mówimy „to jest ryba”, a potem pokazujemy żabę i wskazujemy, że to żaba. Następnie, gdy algorytm zostanie wyszkolony na wystarczającej liczbie danych o rybach i żabach, nauczy się je rozróżniać.
Nauka nienadzorowana
Nienadzorowane uczenie maszynowe obejmuje algorytmy, które uczą się na podstawie nieoznaczonych danych szkoleniowych. Tak więc istnieją tylko cechy (zmienne wejściowe), a nie zmienne docelowe. Problemy z uczeniem się nienadzorowanym obejmują grupowanie, w którym zmienne wejściowe o tej samej charakterystyce są grupowane i kojarzone w celu odszyfrowania znaczących relacji w zbiorze danych. Przykładem grupowania jest grupowanie ludzi w osoby palące i niepalące. Wręcz przeciwnie, odkrycie, że klienci korzystający ze smartfonów będą kupować również pokrowce na telefon, jest skojarzeniem.
Nauka wzmacniania
Uczenie się przez wzmacnianie to technika oparta na plikach danych, w której modele uczenia maszynowego uczą się podejmować szereg decyzji na podstawie informacji zwrotnych, które otrzymują za swoje działania. Za każde dobre działanie maszyna otrzymuje pozytywną informację zwrotną, a za każdą złą – karę lub negatywną informację zwrotną. Tak więc, w przeciwieństwie do nadzorowanego uczenia maszynowego, wzmocniony model automatycznie uczy się, używając informacji zwrotnych zamiast jakichkolwiek oznaczonych danych.
Przeczytaj także, co to jest uczenie maszynowe i dlaczego ma to znaczenie
Dlaczego warto używać Pythona do uczenia maszynowego?
Projekty uczenia maszynowego różnią się od tradycyjnych projektów oprogramowania tym, że te pierwsze obejmują różne zestawy umiejętności, stosy technologii i głębokie badania. Dlatego wdrożenie udanego projektu uczenia maszynowego wymaga języka programowania, który jest stabilny, elastyczny i oferuje niezawodne narzędzia. Python oferuje wszystko, więc najczęściej widzimy projekty uczenia maszynowego oparte na Pythonie.
Niezależność od platformy
Popularność Pythona w dużej mierze wynika z faktu, że jest to język niezależny od platformy i jest obsługiwany przez większość platform, w tym Windows, macOS i Linux. Dzięki temu programiści mogą tworzyć samodzielne programy wykonywalne na jednej platformie i dystrybuować je do innych systemów operacyjnych bez konieczności korzystania z interpretera Pythona. Dlatego modele uczenia maszynowego stają się łatwiejsze w zarządzaniu i tańsze.

Prostota i elastyczność
Za każdym modelem uczenia maszynowego kryją się złożone algorytmy i przepływy pracy, które mogą być onieśmielające i przytłaczające dla użytkowników. Jednak zwięzły i czytelny kod Pythona pozwala programistom skupić się na modelu uczenia maszynowego zamiast martwić się o szczegóły techniczne języka. Co więcej, Python jest łatwy do nauczenia i może obsługiwać skomplikowane zadania uczenia maszynowego, co skutkuje szybkim tworzeniem i testowaniem prototypów.
Szeroki wybór frameworków i bibliotek
Python oferuje szeroki wybór frameworków i bibliotek, które znacznie skracają czas programowania. Takie biblioteki mają wstępnie napisane kody, których programiści używają do wykonywania ogólnych zadań programistycznych. Repertuar narzędzi programowych Pythona obejmuje Scikit-learn, TensorFlow i Keras do uczenia maszynowego, Pandas do ogólnej analizy danych, NumPy i SciPy do analizy danych i obliczeń naukowych, Seaborn do wizualizacji danych i wiele innych.
Naucz się również wstępnego przetwarzania danych w uczeniu maszynowym: 7 łatwych kroków do wykonania
Kroki wdrażania projektu uczenia maszynowego w języku Python
Jeśli nie masz doświadczenia w uczeniu maszynowym, najlepszym sposobem na pogodzenie się z projektem jest spisanie kluczowych kroków, które musisz wykonać. Gdy już masz kroki, możesz użyć ich jako szablonu dla kolejnych zestawów danych, wypełniając luki i modyfikując przepływ pracy, przechodząc do zaawansowanych etapów.
Oto omówienie implementacji projektu uczenia maszynowego w Pythonie:
- Zdefiniuj problem.
- Zainstaluj Pythona i SciPy.
- Załaduj zestaw danych.
- Podsumuj zbiór danych.
- Wizualizuj zbiór danych.
- Oceń algorytmy.
- Prognozować.
- Przedstaw wyniki.
Co to jest sieć głębokiego uczenia się?
Sieci głębokiego uczenia lub głębokie sieci neuronowe (DNN) to gałąź uczenia maszynowego oparta na imitacji ludzkiego mózgu. DNN obejmują jednostki, które łączą wiele wejść w celu wytworzenia jednego wyjścia. Są one analogiczne do neuronów biologicznych, które odbierają wiele sygnałów przez synapsy i wysyłają pojedynczy strumień potencjału czynnościowego w dół swojego neuronu.
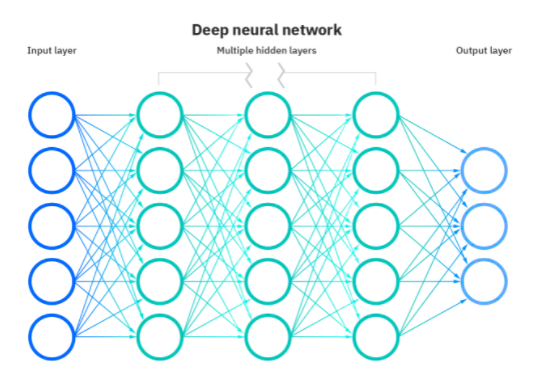
Źródło
W sieci neuronowej funkcjonalność podobną do mózgu osiąga się poprzez warstwy węzłów składające się z warstwy wejściowej, jednej lub wielu warstw ukrytych oraz warstwy wyjściowej. Każdy sztuczny neuron lub węzeł ma powiązany próg i wagę i łączy się z innym. Gdy wyjście jednego węzła przekracza zdefiniowaną wartość progową, jest on aktywowany i przesyła dane do następnej warstwy w sieci.
DNN polegają na danych uczących, aby uczyć się i dostosowywać swoją dokładność w miarę upływu czasu. Stanowią solidne narzędzia sztucznej inteligencji, umożliwiające klasyfikację danych i grupowanie przy dużych prędkościach. Dwie z najczęstszych dziedzin zastosowań głębokich sieci neuronowych to rozpoznawanie obrazów i rozpoznawanie mowy.
Droga naprzód
Czy to odblokowywanie smartfona za pomocą Face ID, przeglądanie filmów, czy wyszukiwanie losowego tematu w Google, współcześni, napędzani cyfrowo konsumenci wymagają lepszych rekomendacji i lepszej personalizacji. Bez względu na branżę lub domenę sztuczna inteligencja odgrywa i nadal odgrywa znaczącą rolę w zwiększaniu komfortu użytkowania. Dodaj do tego, prostota i wszechstronność Pythona sprawiły, że tworzenie, wdrażanie i utrzymanie projektów AI jest wygodne i wydajne na różnych platformach.
Ucz się kursu ML z najlepszych światowych uniwersytetów. Zdobywaj programy Masters, Executive PGP lub Advanced Certificate Programy, aby przyspieszyć swoją karierę.
Jeśli uważasz, że ten samouczek dotyczący uczenia maszynowego w języku Python dla początkujących jest interesujący, zagłębij się głębiej w ten temat z tytułem Master of Science in Machine Learning & AI . Ten program online jest przeznaczony dla pracujących profesjonalistów, którzy chcą nauczyć się zaawansowanych umiejętności sztucznej inteligencji, takich jak NLP, głębokie uczenie, uczenie wzmacniające i inne.
Najważniejsze informacje o kursie:
- Stopień magistra z LJMU
- Wykonawczy PGP z IIIT Bangalore
- 750+ godzin treści
- 40+ sesji na żywo
- 12+ studiów przypadku i projektów
- 11 zadań kodowania
- Szczegółowe omówienie 20 narzędzi, języków i bibliotek
- Pomoc w karierze 360 stopni
1. Czy Python jest dobry do uczenia maszynowego?
Python to jeden z najlepszych języków programowania do wdrażania modeli uczenia maszynowego. Python przemawia zarówno do programistów, jak i początkujących ze względu na swoją prostotę, elastyczność i łagodną krzywą uczenia się. Co więcej, Python jest niezależny od platformy i ma dostęp do bibliotek i frameworków, które przyspieszają i ułatwiają budowanie i testowanie modeli uczenia maszynowego.
2. Czy uczenie maszynowe w Pythonie jest trudne?
Ze względu na powszechną popularność Pythona jako języka programowania ogólnego przeznaczenia i jego zastosowanie w uczeniu maszynowym i obliczeniach naukowych, znalezienie samouczka dotyczącego uczenia maszynowego w Pythonie jest dość łatwe. Poza tym łagodna krzywa uczenia się Pythona, czytelny i precyzyjny kod sprawia, że jest to język programowania przyjazny dla początkujących.
3. Czy sztuczna inteligencja i uczenie maszynowe to to samo?
Chociaż terminy AI i machine learning są często używane zamiennie, nie są one tym samym. Sztuczna inteligencja (AI) to ogólny termin określający gałąź informatyki zajmującą się maszynami zdolnymi do wykonywania zadań zwykle wykonywanych przez ludzi. Jednak uczenie maszynowe to podzbiór sztucznej inteligencji, w którym maszyny są zasilane danymi i szkolone w podejmowaniu decyzji na podstawie danych wejściowych.