
15 pytań i odpowiedzi dotyczących uczenia maszynowego na rok 2022
Opublikowany: 2021-01-08Czy jesteś kimś, kto chce odnieść sukces w uczeniu maszynowym? Jeśli tak, to świetnie dla Ciebie!
Ale najpierw musisz przygotować się na przełamanie lodów – wywiad z ML.
Ponieważ proces przygotowania do rozmowy kwalifikacyjnej może być przytłaczający, zdecydowaliśmy się wkroczyć – oto wyselekcjonowana lista 15 najczęściej zadawanych pytań w rozmowach dotyczących uczenia maszynowego!
- Jaka jest różnica między uczeniem głębokim a uczeniem maszynowym?
Podczas gdy uczenie maszynowe obejmuje zastosowanie i wykorzystanie zaawansowanych algorytmów do analizowania danych, odkrywania ukrytych wzorców w danych i uczenia się na ich podstawie, a na koniec zastosowania wyuczonych spostrzeżeń do podejmowania świadomych decyzji biznesowych. Jeśli chodzi o uczenie głębokie, jest to podzbiór uczenia maszynowego, który obejmuje wykorzystanie sztucznych sieci neuronowych, które czerpią inspirację ze struktury sieci neuronowej ludzkiego mózgu. Głębokie uczenie jest szeroko stosowane w wykrywaniu funkcji.
- Zdefiniuj – precyzja i przypomnienie.
Precyzja lub Dodatnia Wartość Predykcyjna mierzy lub dokładniej przewiduje liczbę prawdziwych wyników pozytywnych deklarowanych przez model w porównaniu z liczbą pozytywów, które faktycznie deklaruje.
Wskaźnik przypomnienia lub prawdziwie pozytywnych wyników odnosi się do liczby pozytywów stwierdzonych przez model w porównaniu z rzeczywistą liczbą pozytywów obecnych w danych.

Dołącz do kursu uczenia maszynowego online z najlepszych uniwersytetów na świecie — studiów magisterskich, programów podyplomowych dla kadry kierowniczej i zaawansowanego programu certyfikacji w zakresie uczenia maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
- Wyjaśnij pojęcia „stronniczość” i „wariancja”. '
Podczas procesu uczenia oczekiwany błąd algorytmu uczenia się jest generalnie klasyfikowany lub rozkładany na dwie części – błąd systematyczny i wariancję. Podczas gdy „bias” jest sytuacją błędu spowodowaną zastosowaniem prostych założeń w algorytmie uczącym się, „wariancja” oznacza błąd spowodowany złożonością tego algorytmu uczenia się w analizie danych. Bias mierzy bliskość średniego klasyfikatora utworzonego przez algorytm uczący się do funkcji docelowej, a wariancja mierzy stopień zmienności predykcji algorytmu uczącego dla różnych zestawów danych uczących.
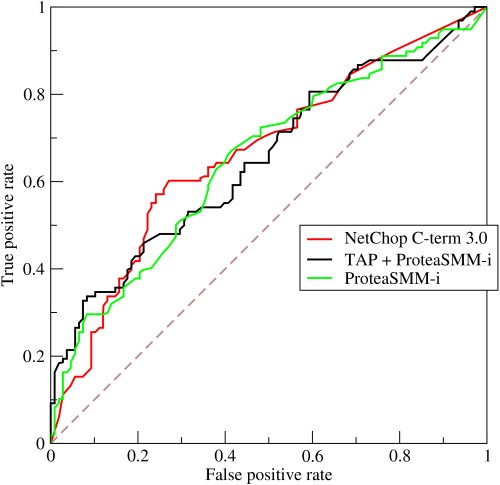
- Jak działa krzywa ROC?
Krzywa ROC lub charakterystyka pracy odbiornika jest graficzną reprezentacją zmienności między wskaźnikami prawdziwie dodatnich i fałszywie dodatnich przy różnych progach. Jest to podstawowe narzędzie do oceny testów diagnostycznych i jest często używane jako reprezentacja kompromisu między czułością modelu (prawdziwie dodatnie) a prawdopodobieństwem wyzwolenia fałszywych alarmów (fałszywie dodatnie).
Źródło
- Krzywa przedstawia kompromis między czułością a swoistością – jeśli czułość wzrośnie, swoistość zmniejszy się.
- Jeśli krzywa graniczy bardziej w kierunku lewej osi i górnej części przestrzeni ROC, test jest zwykle dokładniejszy. Jeśli jednak krzywa zbliża się do 45-stopniowej przekątnej przestrzeni ROC, test jest mniej dokładny lub wiarygodny.
- Nachylenie linii stycznej w punkcie odcięcia wskazuje współczynnik wiarygodności (LR) dla tej konkretnej wartości testu.
- Obszar pod krzywą mierzy dokładność testu.
- Wyjaśnij różnicę między błędami typu 1 i typu 2?
Błąd typu 1 to błąd fałszywie pozytywny, który „twierdzi”, że incydent miał miejsce, gdy w rzeczywistości nic się nie wydarzyło. Najlepszym przykładem błędu fałszywie pozytywnego jest fałszywy alarm pożarowy – alarm zaczyna dzwonić, gdy nie ma pożaru. W przeciwieństwie do tego, błąd typu 2 jest błędem fałszywie ujemnym, który „twierdzi”, że nic się nie wydarzyło, gdy coś na pewno się wydarzyło. Byłoby błędem typu 2 powiedzieć ciężarnej kobiecie, że nie nosi dziecka.
- Dlaczego Bayes jest określany jako „Naive Bayes”?
Naive Bayes jest określany jako „naiwny”, ponieważ chociaż ma wiele praktycznych zastosowań, opiera się na założeniu, którego nie można znaleźć w rzeczywistych danych – wszystkie cechy w zbiorze danych są kluczowe, niezależne i równe. W podejściu naiwnym Bayesa prawdopodobieństwo warunkowe jest obliczane jako czysty iloczyn prawdopodobieństw poszczególnych składowych, co implikuje całkowitą niezależność cech. Niestety, to założenie nigdy nie może zostać spełnione w realnym scenariuszu.
- Co oznacza termin „przesadne dopasowanie”? Czy możesz tego uniknąć? Jeśli tak to jak?
Zwykle podczas procesu uczenia model jest zasilany dużą ilością danych. W trakcie procesu dane zaczynają się uczyć nawet na podstawie niedokładnych informacji i szumu obecnych w przykładowym zestawie danych. Stwarza to negatywny wpływ na wydajność modelu na nowych danych, co oznacza, że model nie może dokładnie klasyfikować nowych wystąpień/danych poza tymi z zestawu uczącego. Jest to znane jako Overfitting.
Tak, można uniknąć nadmiernego dopasowania. Oto jak:
- Zbierz więcej danych (z różnych źródeł), aby trenować model z różnymi próbkami.
- Zastosuj metody grupowania (na przykład Random Forest), które wykorzystują podejście baggingowe, aby zminimalizować zmienność prognoz, zestawiając wyniki wielu drzew decyzyjnych w różnych jednostkach zbioru danych.
- Upewnij się, że używasz technik weryfikacji krzyżowej.
- Wymień dwie metody używane do kalibracji w uczeniu nadzorowanym.
Dwie metody kalibracji w Supervised Learning to – Kalibracja Platta i Regresja Izotoniczna. Obie te metody są specjalnie zaprojektowane do klasyfikacji binarnej.

- Dlaczego przycinasz drzewo decyzyjne?
Drzewa decyzyjne należy przycinać, aby pozbyć się gałęzi o słabych zdolnościach przewidywania. Pomaga to zminimalizować iloraz złożoności modelu drzewa decyzyjnego i zoptymalizować jego dokładność predykcyjną. Przycinanie można wykonać od góry do dołu lub od dołu do góry. Zmniejszone przycinanie błędów, przycinanie złożoności kosztów, przycinanie przycinania błędów i minimalizacja błędów to niektóre z najczęściej używanych metod przycinania drzewa decyzyjnego.
- Co oznacza wynik F1?
Mówiąc prościej, wynik F1 jest miarą wydajności modelu – średnia precyzji i pamięci modelu, przy czym wyniki bliskie 1 oznaczają najlepsze, a te bliskie 0 są najgorsze. Wynik F1 można wykorzystać w testach klasyfikacyjnych, które nie przywiązują wagi do prawdziwych wyników negatywnych.
- Rozróżnij algorytm generatywny i dyskryminacyjny.
Podczas gdy algorytm generatywny uczy się kategorii danych, algorytm dyskryminacyjny uczy się rozróżniania między różnymi kategoriami danych. Jeśli chodzi o zadania klasyfikacyjne, modele dyskryminacyjne zazwyczaj wyprzedzają modele generatywne.
- Co to jest uczenie zespołowe?
Ensemble Learning wykorzystuje kombinację algorytmów uczenia się w celu optymalizacji predykcyjnej wydajności modeli. W tej metodzie wiele modeli, takich jak klasyfikatory lub eksperci, jest zarówno strategicznie generowanych, jak i łączonych, aby zapobiec nadmiernemu dopasowaniu w modelach. Jest używany głównie do udoskonalenia przewidywania, klasyfikacji, aproksymacji funkcji, wydajności itp. modelu.
- Zdefiniuj „Sztuczkę jądra”.
Metoda Kernel Trick polega na użyciu funkcji jądra, które mogą działać w wielowymiarowej i niejawnej przestrzeni cech bez konieczności jawnego obliczania współrzędnych punktów w tym wymiarze. Funkcje jądra obliczają iloczyny wewnętrzne między obrazami wszystkich par danych obecnych w przestrzeni funkcji. Ta procedura jest tańsza obliczeniowo w porównaniu z jawnym obliczeniem współrzędnych i jest znana jako sztuczka jądra.
- Jak postępować z brakującymi lub uszkodzonymi danymi w zestawie danych?
Aby znaleźć brakujące/uszkodzone dane w zestawie danych, należy albo usunąć wiersze i kolumny, albo zastąpić je innymi wartościami. Biblioteka Pandas ma dwie świetne metody znajdowania brakujących/uszkodzonych danych – isnull() i dropna(). Obie te funkcje zostały specjalnie zaprojektowane, aby pomóc Ci znaleźć wiersze/kolumny danych z brakującymi/uszkodzonymi danymi i usunąć te wartości.
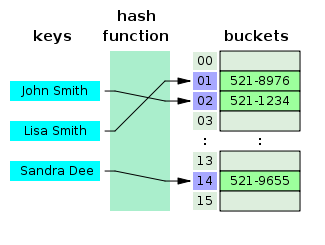
- Co to jest tablica mieszająca?
Tablica mieszająca to struktura danych, która tworzy tablicę asocjacyjną, w której klucz jest mapowany na określone wartości za pomocą funkcji mieszającej. Tabele haszujące są najczęściej używane w indeksowaniu baz danych.
Źródło
Ta lista pytań ma na celu jedynie wprowadzenie w podstawy uczenia maszynowego i szczerze mówiąc, te dwadzieścia pytań to tylko kropla w morzu. Uczenie maszynowe rozwija się, gdy mówimy, i dlatego z czasem pojawią się nowe koncepcje. Kluczem do przeprowadzenia rozmów kwalifikacyjnych jest więc ciągłe pragnienie nauki i podnoszenia umiejętności. Więc zacznij i plądruj Internet, czytaj czasopisma, dołączaj do społeczności internetowych, bierz udział w konferencjach i seminariach ML – jest tak wiele sposobów na naukę.
Aby wejść do dużej organizacji, niezbędny jest certyfikat renomowanej instytucji. Zapoznaj się z programem Executive PG IIIT-B w zakresie uczenia maszynowego i sztucznej inteligencji i uzyskaj pomoc w pracy od najlepszych firm zajmujących się ML i sztuczną inteligencją.
Jakie są ograniczenia uczenia zespołowego?
Podejścia zespołowe mogą pomóc w zmniejszeniu wariancji i opracowaniu bardziej niezawodnych modeli. Istnieją jednak pewne wady korzystania z technik zespołowych, takie jak brak możliwości wyjaśnienia i wydajności. Ponadto należy pamiętać, że skuteczność zespołów wynika z ich zdolności do agregowania wielu modeli, które koncentrują się na różnych aspektach zagadnienia. Mają jednak dłuższy okres prognozy, ponieważ możesz potrzebować prognoz z setek modeli. Nawet jeśli mają lepsze prognozy, wzrost dokładności może nie być tego wart.
Ile czasu potrzeba na naukę uczenia maszynowego?
Jeśli chodzi o uczenie maszynowe, złożone technologie wykorzystywane do tego samego mogą łatwo przestraszyć ludzi. Jednak zrozumienie go krok po kroku nie jest trudne. Wcześniejsze doświadczenie w statystyce, zaawansowanej matematyce itd. z pewnością pomoże ci w szybkim zrozumieniu wszystkich pojęć. Jednakże, ponieważ wykształcenie i umiejętności różnią się w zależności od osoby, jedna osoba może nauczyć się ML w ciągu trzech tygodni, podczas gdy inna może potrzebować roku.
W jaki sposób uczenie maszynowe jest wykorzystywane w naszym codziennym życiu?
Gmail kategoryzuje e-maile jako niezbędne, sortując je jako Główne, Promocje, Społeczności i Aktualizacje za pomocą uczenia maszynowego. Firmy wykorzystują sieci neuronowe do wykrywania nieuczciwych transakcji na podstawie danych, takich jak najnowsza częstotliwość transakcji, kwota transakcji i typ sprzedawcy. Wykrywacze plagiatu wykorzystują również uczenie maszynowe. Jeśli chodzi o inżynierię ML, ukończenie jej zajmuje około sześciu miesięcy.