
Klasyfikator KNN do uczenia maszynowego: wszystko, co musisz wiedzieć
Opublikowany: 2021-09-28Pamiętasz czasy, kiedy sztuczna inteligencja (AI) była tylko koncepcją ograniczoną do powieści i filmów science fiction? Cóż, dzięki postępowi technologicznemu sztuczna inteligencja jest czymś, z czym żyjemy na co dzień. Od Alexy i Siri, które są na nasze zawołanie i wzywają do platform OTT „ręcznie wybierających” filmy, które chcielibyśmy obejrzeć, sztuczna inteligencja stała się prawie na porządku dziennym i jest tutaj, aby powiedzieć w dającej się przewidzieć przyszłości.
To wszystko jest możliwe dzięki zaawansowanym algorytmom ML. Dzisiaj porozmawiamy o jednym z takich użytecznych algorytmów ML, klasyfikatorze K-NN.
Jako gałąź sztucznej inteligencji i informatyki, uczenie maszynowe wykorzystuje dane i algorytmy do naśladowania ludzkiego zrozumienia, jednocześnie stopniowo poprawiając dokładność algorytmów. Uczenie maszynowe obejmuje uczenie algorytmów w celu przewidywania lub klasyfikacji i wydobywania kluczowych spostrzeżeń, które napędzają podejmowanie strategicznych decyzji w firmach i aplikacjach.
Algorytm KNN (k-nearest near) jest podstawowym nadzorowanym algorytmem uczenia maszynowego używanym do rozwiązywania regresji i klasyfikacji problemów. Zanurzmy się więc, aby dowiedzieć się więcej o klasyfikatorze K-NN.
Spis treści
Nadzorowane a nienadzorowane uczenie maszynowe
Uczenie nadzorowane i nienadzorowane to dwa podstawowe podejścia do nauki o danych i ważne jest, aby poznać różnicę, zanim przejdziemy do szczegółów KNN.
Uczenie nadzorowane to podejście do uczenia maszynowego, które wykorzystuje oznaczone zestawy danych do przewidywania wyników. Takie zbiory danych mają na celu „nadzorowanie” lub szkolenie algorytmów w przewidywaniu wyników lub dokładnej klasyfikacji danych. W związku z tym oznakowane dane wejściowe i wyjściowe umożliwiają modelowi uczenie się w czasie, jednocześnie poprawiając jego dokładność.

Uczenie nadzorowane obejmuje dwa rodzaje problemów – klasyfikację i regresję. W problemach z klasyfikacją algorytmy przydzielają dane testowe do odrębnych kategorii, takich jak oddzielanie kotów od psów.
Znaczącym przykładem z życia może być klasyfikowanie wiadomości spamowych w folderze innym niż Twoja skrzynka odbiorcza. Z drugiej strony metoda regresji nadzorowanego uczenia się uczy algorytmy zrozumienia relacji między zmiennymi niezależnymi i zależnymi. Wykorzystuje różne punkty danych do przewidywania wartości liczbowych, takich jak prognozowanie przychodów ze sprzedaży dla firmy.
Natomiast uczenie nienadzorowane wykorzystuje algorytmy uczenia maszynowego do analizy i grupowania nieoznakowanych zbiorów danych. W związku z tym nie ma potrzeby interwencji człowieka („nienadzorowanej”), aby algorytmy identyfikowały ukryte wzorce w danych.
Modele uczenia się nienadzorowanego mają trzy główne zastosowania – asocjację, grupowanie i redukcję wymiarowości. Nie będziemy jednak wchodzić w szczegóły, ponieważ wykracza to poza nasz zakres dyskusji.
K-Najbliższy sąsiad (KNN)
Algorytm K-Nearest Neighbor lub KNN to algorytm uczenia maszynowego oparty na modelu uczenia nadzorowanego. Algorytm K-NN działa przy założeniu, że podobne rzeczy istnieją blisko siebie. W związku z tym algorytm K-NN wykorzystuje podobieństwo cech między nowymi punktami danych a punktami w zbiorze uczącym (dostępne przypadki) do przewidywania wartości nowych punktów danych. Zasadniczo algorytm K-NN przypisuje wartość do ostatniego punktu danych na podstawie tego, jak bardzo przypomina on punkty w zbiorze uczącym. Algorytm K-NN znajduje zastosowanie zarówno w problemach klasyfikacyjnych, jak i regresyjnych, ale jest używany głównie w problemach klasyfikacyjnych.
Oto przykład, jak zrozumieć klasyfikator K-NN.

Źródło
Na powyższym obrazku wartością wejściową jest stworzenie podobne do kota i psa. Chcemy jednak zaklasyfikować go albo do kota, albo do psa. Do tej klasyfikacji możemy więc użyć algorytmu K-NN. Model K-NN znajdzie podobieństwa między nowym zbiorem danych (dane wejściowe) a dostępnymi obrazami kotów i psów (zestaw danych treningowych). Następnie model umieści nowy punkt danych w kategorii kota lub psa w oparciu o najbardziej podobne cechy.
Podobnie kategoria A (zielone kropki) i kategoria B (pomarańczowe kropki) mają powyższy przykład graficzny. Mamy również nowy punkt danych (niebieska kropka), który będzie należeć do jednej z kategorii. Możemy rozwiązać ten problem klasyfikacji za pomocą algorytmu K-NN i zidentyfikować nową kategorię punktów danych.
Definiowanie właściwości algorytmu K-NN
Następujące dwie właściwości najlepiej definiują algorytm K-NN:
- Jest to algorytm z leniwym uczeniem się, ponieważ zamiast natychmiastowego uczenia się ze zbioru uczącego, algorytm K-NN przechowuje zbiór danych i pociągi ze zbioru danych w momencie klasyfikacji.
- K-NN jest również algorytmem nieparametrycznym , co oznacza, że nie przyjmuje żadnych założeń dotyczących danych bazowych.
Działanie algorytmu K-NN
Przyjrzyjmy się teraz następującym krokom, aby zrozumieć, jak działa algorytm K-NN.
Krok 1: Załaduj dane treningowe i testowe.
Krok 2: Wybierz najbliższe punkty danych, czyli wartość K.
Krok 3: Oblicz odległość K liczby sąsiadów (odległość między każdym wierszem danych uczących i danych testowych). Do obliczania odległości najczęściej stosuje się metodę euklidesową.
Krok 4: Weź K najbliższych sąsiadów na podstawie obliczonej odległości euklidesowej.
Krok 5: Wśród najbliższych K sąsiadów policz liczbę punktów danych w każdej kategorii.
Krok 6: Przydziel nowe punkty danych do tej kategorii, dla której liczba sąsiadów jest maksymalna.
Krok 7: Koniec. Model jest już gotowy.
Dołącz do kursów dotyczących sztucznej inteligencji online z najlepszych światowych uniwersytetów — studiów magisterskich, programów podyplomowych dla kadry kierowniczej oraz zaawansowanego programu certyfikacji w zakresie uczenia maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
Wybór wartości K
K jest parametrem krytycznym w algorytmie K-NN. Dlatego musimy pamiętać o kilku punktach, zanim zdecydujemy o wartości K.
Korzystanie z krzywych błędów jest powszechną metodą określania wartości K. Poniższy obraz przedstawia krzywe błędów dla różnych wartości K dla danych testowych i treningowych.


Źródło
W powyższym przykładzie graficznym błąd pociągu wynosi zero przy K = 1 w danych treningowych, ponieważ najbliższym sąsiadem tego punktu jest ten punkt. Jednak błąd testowy jest wysoki nawet przy niskich wartościach K. Nazywa się to dużą wariancją lub nadmiernym dopasowaniem danych. Błąd testu zmniejsza się, gdy zwiększamy wartość K. Ale po pewnej wartości K widzimy, że błąd testu ponownie wzrasta, co nazywamy odchyleniem lub niedopasowaniem. Zatem błąd danych testowych jest początkowo wysoki ze względu na wariancję, następnie obniża się i stabilizuje, a przy dalszym wzroście wartości K błąd testowy ponownie wzrasta z powodu obciążenia.
Dlatego wartość K, przy której błąd testu stabilizuje się i jest niski, przyjmuje się za optymalną wartość K. Biorąc pod uwagę powyższą krzywą błędu, K=8 jest wartością optymalną.
Przykład zrozumienia działania algorytmu K-NN
Rozważmy zestaw danych, który został wykreślony w następujący sposób:

Źródło
Powiedzmy, że jest nowy punkt danych (czarna kropka) w (60,60), który musimy zaklasyfikować do fioletowej lub czerwonej klasy. Użyjemy K=3, co oznacza, że nowy punkt danych znajdzie trzy najbliższe punkty danych, dwa w klasie czerwonej i jeden w klasie fioletowej.
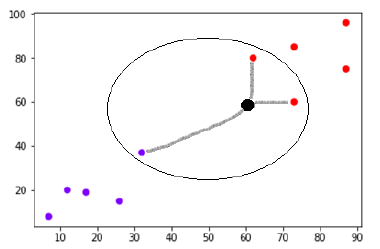
Źródło
Najbliższych sąsiadów określa się, obliczając odległość euklidesową między dwoma punktami. Oto ilustracja pokazująca, jak wykonuje się obliczenia.

Źródło
Teraz, ponieważ dwóch (z trzech) najbliższych sąsiadów nowego punktu danych (czarna kropka) leży w klasie czerwonej, nowy punkt danych zostanie również przypisany do klasy czerwonej.
Dołącz do kursu uczenia maszynowego online z najlepszych uniwersytetów na świecie — studiów magisterskich, programów podyplomowych dla kadry kierowniczej i zaawansowanego programu certyfikacji w zakresie uczenia maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
K-NN jako klasyfikator (implementacja w Pythonie)
Teraz, gdy mamy uproszczone wyjaśnienie algorytmu K-NN, przejdźmy przez implementację algorytmu K-NN w Pythonie. Skupimy się tylko na Klasyfikatorze K-NN.
Krok 1: Zaimportuj niezbędne pakiety Pythona.

Źródło
Krok 2: Pobierz zestaw danych tęczówki z repozytorium uczenia maszynowego UCI. Jego łącze internetowe to „https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data”
Krok 3: Przypisz nazwy kolumn do zestawu danych.

Źródło
Krok 4: Odczytaj zbiór danych do Pandas DataFrame.

Źródło
Krok 5: Wstępne przetwarzanie danych odbywa się za pomocą następujących wierszy skryptu.

Źródło
Krok 6: Podziel zbiór danych na podział testowy i treningowy. Poniższy kod podzieli zbiór danych na 40% danych testowych i 60% danych treningowych.

Źródło
Krok 7: Skalowanie danych odbywa się w następujący sposób:

Źródło
Krok 8: Wytrenuj model przy użyciu klasy sklearn KNeighborsClassifier.

Źródło
Krok 9: Dokonaj prognozy za pomocą następującego skryptu:

Źródło
Krok 10: Wydrukuj wyniki.

Źródło
Wyjście:

Źródło
Co następne? Zarejestruj się w Advanced Certificate Program in Machine Learning od IIT Madras i upGrad
Załóżmy, że chcesz zostać wykwalifikowanym analitykiem danych lub specjalistą ds. uczenia maszynowego. W takim razie Advanced Certification Course in Machine Learning and Cloud od IIT Madras i upGrad jest właśnie dla Ciebie!
12-miesięczny program online jest specjalnie zaprojektowany dla pracujących profesjonalistów, którzy chcą opanować koncepcje uczenia maszynowego, przetwarzania Big Data, zarządzania danymi, hurtowni danych, chmury i wdrażania modeli uczenia maszynowego.
Oto kilka najważniejszych informacji o kursie, aby lepiej zorientować się, co oferuje program:
- Globalnie akceptowany prestiżowy certyfikat IIT Madras
- 500+ godzin nauki, ponad 20 studiów przypadków i projektów, ponad 25 sesji mentoringu branżowego, ponad 8 zadań z zakresu kodowania
- Kompleksowa obsługa 7 języków programowania i narzędzi
- 4 tygodnie projektu zwieńczenia przemysłu
- Praktyczne warsztaty praktyczne
- Sieci peer-to-peer offline
Zarejestruj się już dziś, aby dowiedzieć się więcej o programie!
Wniosek
Z czasem Big Data wciąż się rozwija, a sztuczna inteligencja coraz bardziej wplata się w nasze życie. W rezultacie istnieje gwałtowny wzrost zapotrzebowania na specjalistów zajmujących się analizą danych, którzy mogą wykorzystać moc modeli uczenia maszynowego do gromadzenia wglądu w dane i ulepszania krytycznych procesów biznesowych oraz, ogólnie, naszego świata. Bez wątpienia dziedzina sztucznej inteligencji i uczenia maszynowego wygląda naprawdę obiecująco. Dzięki upGrad możesz mieć pewność, że Twoja kariera w uczeniu maszynowym i chmurze będzie satysfakcjonująca!
Dlaczego K-NN jest dobrym klasyfikatorem?
Główną zaletą K-NN nad innymi algorytmami uczenia maszynowego jest to, że możemy wygodnie używać K-NN do klasyfikacji wieloklasowej. Zatem K-NN jest najlepszym algorytmem, jeśli musimy sklasyfikować dane w więcej niż dwóch kategoriach lub jeśli dane zawierają więcej niż dwie etykiety. Poza tym jest idealny do danych nieliniowych i ma stosunkowo wysoką dokładność.
Jakie jest ograniczenie algorytmu K-NN?
Algorytm K-NN działa poprzez obliczenie odległości między punktami danych. W związku z tym jest dość oczywiste, że jest to stosunkowo bardziej czasochłonny algorytm i w niektórych przypadkach klasyfikacja zajmie więcej czasu. Dlatego najlepiej nie używać zbyt wielu punktów danych podczas korzystania z K-NN do klasyfikacji wieloklasowej. Inne ograniczenia obejmują dużą pojemność pamięci i wrażliwość na nieistotne funkcje.
Jakie są rzeczywiste zastosowania K-NN?
K-NN ma kilka rzeczywistych przypadków użycia w uczeniu maszynowym, takich jak wykrywanie pisma ręcznego, rozpoznawanie mowy, rozpoznawanie wideo i rozpoznawanie obrazów. W bankowości K-NN służy do przewidywania, czy dana osoba kwalifikuje się do pożyczki na podstawie tego, czy ma cechy podobne do osób niewypłacalnych. W polityce K-NN może być używany do klasyfikowania potencjalnych wyborców do różnych klas, takich jak „zagłosuje na partię X” lub „zagłosuje na partię Y” itp.