
Przedstawiamy API oparte na komponentach
Opublikowany: 2022-03-10Ten artykuł został zaktualizowany 31 stycznia 2019 r. w odpowiedzi na opinie czytelników. Autor dodał do interfejsu API opartego na komponentach funkcje zapytań niestandardowych i opisuje, jak to działa .
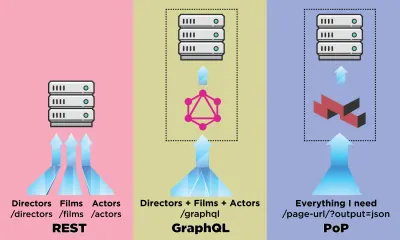
API to kanał komunikacji aplikacji, który ładuje dane z serwera. W świecie interfejsów API REST jest bardziej ustaloną metodologią, ale ostatnio został przyćmiony przez GraphQL, który oferuje istotną przewagę nad REST. Podczas gdy REST wymaga wielu żądań HTTP w celu pobrania zestawu danych w celu renderowania komponentu, GraphQL może wysyłać zapytania i pobierać takie dane w jednym żądaniu, a odpowiedź będzie dokładnie taka, jaka jest wymagana, bez nadmiernego lub niedostatecznego pobierania danych, jak to zwykle ma miejsce w ODPOCZYNEK.
W tym artykule opiszę inny sposób pobierania danych, który zaprojektowałem i nazwałem „PoP” (tutaj open source), który rozwija ideę pobierania danych dla kilku podmiotów w jednym żądaniu wprowadzonym przez GraphQL i pobiera je krok dalej, tj. podczas gdy REST pobiera dane dla jednego zasobu, a GraphQL pobiera dane dla wszystkich zasobów w jednym komponencie, API oparte na komponentach może pobierać dane dla wszystkich zasobów ze wszystkich komponentów na jednej stronie.
Korzystanie z API opartego na komponentach ma największy sens, gdy sama strona jest budowana z komponentów, czyli gdy strona składa się iteracyjnie z komponentów owijających inne komponenty, aż na samej górze otrzymamy pojedynczy komponent reprezentujący stronę. Na przykład strona pokazana na poniższym obrazku jest zbudowana z komponentów, które są obrysowane kwadratami:
Interfejs API oparty na komponentach jest w stanie wysłać pojedyncze żądanie do serwera, żądając danych dla wszystkich zasobów w każdym komponencie (jak również dla wszystkich komponentów na stronie), co jest osiągane przez utrzymywanie relacji między komponentami w samą strukturę API.
Ta struktura oferuje między innymi następujące korzyści:
- Strona z wieloma komponentami wywoła tylko jedno żądanie zamiast wielu;
- Dane współdzielone przez komponenty można pobrać tylko raz z bazy danych i wydrukować tylko raz w odpowiedzi;
- Może znacznie zmniejszyć — a nawet całkowicie wyeliminować — potrzebę przechowywania danych.
Omówimy je szczegółowo w całym artykule, ale najpierw przyjrzyjmy się, czym właściwie są komponenty i jak możemy zbudować witrynę opartą na takich komponentach, a na koniec sprawdźmy, jak działa API oparte na komponentach.
Zalecana literatura : GraphQL Primer: Dlaczego potrzebujemy nowego rodzaju API
Budowanie witryny za pomocą komponentów
Komponent to po prostu zestaw fragmentów kodu HTML, JavaScript i CSS połączonych razem, aby stworzyć autonomiczną jednostkę. Może to następnie owijać inne komponenty, tworząc bardziej złożone struktury, a także być otoczone innymi komponentami. Komponent ma swoje przeznaczenie, które może być bardzo proste (takie jak link lub przycisk) do czegoś bardzo skomplikowanego (takiego jak karuzela lub narzędzie do przesyłania obrazów metodą „przeciągnij i upuść”). Komponenty są najbardziej przydatne, gdy są ogólne i umożliwiają dostosowywanie poprzez wstrzykiwane właściwości (lub „rekwizyty”), dzięki czemu mogą służyć szerokiej gamie przypadków użycia. W skrajnym przypadku sama witryna staje się elementem składowym.
Termin „komponent” jest często używany w odniesieniu zarówno do funkcjonalności, jak i designu. Na przykład jeśli chodzi o funkcjonalność, frameworki JavaScript takie jak React czy Vue pozwalają na tworzenie komponentów po stronie klienta, które są w stanie samodzielnie się renderować (np. po pobraniu przez API wymaganych danych) i za pomocą rekwizytów ustawiać wartości konfiguracyjne na swoich opakowane komponenty, umożliwiające ponowne wykorzystanie kodu. Jeśli chodzi o projektowanie, Bootstrap ustandaryzował wygląd i sposób działania witryn internetowych poprzez swoją bibliotekę komponentów front-endowych i stało się zdrowym trendem dla zespołów do tworzenia systemów projektowania w celu utrzymania swoich witryn internetowych, co pozwala różnym członkom zespołu (projektantom i programistom, ale także marketerzy i sprzedawcy), aby mówić jednolitym językiem i wyrażać spójną tożsamość.
Komponentowanie witryny jest zatem bardzo rozsądnym sposobem na sprawienie, by witryna stała się łatwiejsza w utrzymaniu. Witryny korzystające z frameworków JavaScript, takich jak React i Vue, są już oparte na komponentach (przynajmniej po stronie klienta). Korzystanie z biblioteki komponentów, takiej jak Bootstrap, niekoniecznie powoduje, że witryna będzie oparta na komponentach (może to być duża plama HTML), jednak zawiera koncepcję elementów wielokrotnego użytku dla interfejsu użytkownika.
Jeśli witryna jest dużą plamą HTML, abyśmy mogli ją skomponować, musimy podzielić układ na serię powtarzających się wzorców, dla których musimy zidentyfikować i skatalogować sekcje na stronie na podstawie ich podobieństwa funkcjonalności i stylów, a następnie rozbić te sekcje w dół na warstwy, tak szczegółowe, jak to możliwe, starając się, aby każda warstwa była skoncentrowana na jednym celu lub działaniu, a także próbując dopasować wspólne warstwy w różnych sekcjach.
Uwaga : „Atomowy projekt” Brada Frosta to świetna metodologia identyfikacji tych powszechnych wzorców i budowania systemu projektowania wielokrotnego użytku.
Dlatego budowanie witryny z komponentów przypomina zabawę z LEGO. Każdy składnik jest albo atomową funkcjonalnością, kompozycją innych składników, albo kombinacją tych dwóch.
Jak pokazano poniżej, podstawowy komponent (awatar) jest iteracyjnie składany z innych komponentów, aż do uzyskania strony internetowej u góry:

Specyfikacja API opartego na komponentach
W przypadku zaprojektowanego przeze mnie API opartego na komponentach, komponent nazywa się „modułem”, więc od teraz terminy „komponent” i „moduł” będą używane zamiennie.
Relacja wszystkich modułów owijających się nawzajem, od najwyższego modułu do ostatniego poziomu, nazywana jest „hierarchią komponentów”. Ta relacja może być wyrażona za pomocą tablicy asocjacyjnej (tablicy klucza => właściwości) po stronie serwera, w której każdy moduł określa swoją nazwę jako atrybut klucza, a jego wewnętrzne moduły pod modules właściwości . Interfejs API po prostu koduje tę tablicę jako obiekt JSON do wykorzystania:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }Relacja między modułami jest definiowana w sposób ściśle odgórny: moduł otacza inne moduły i wie, kim one są, ale nie wie — i nie obchodzi go — które moduły go otaczają.
Na przykład w powyższym kodzie JSON module module-level1 wie, że opakowuje moduły module-level11 i module-level12 , a przechodnie wie również, że module-level121 ; ale module module-level11 nie obchodzi, kto go opakowuje, w konsekwencji nie jest świadomy module-level1 .
Mając strukturę opartą na komponentach, możemy teraz dodać rzeczywiste informacje wymagane przez każdy moduł, które są podzielone na kategorie (takie jak wartości konfiguracyjne i inne właściwości) i dane (takie jak identyfikatory odpytywanych obiektów bazy danych i inne właściwości). i umieszczone odpowiednio pod wpisami modulesettings i moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } Następnie API doda dane obiektu bazy danych. Te informacje nie są umieszczane w każdym module, ale we wspólnej sekcji zwanej databases , aby uniknąć duplikowania informacji, gdy dwa lub więcej różnych modułów pobiera te same obiekty z bazy danych.
Ponadto interfejs API reprezentuje dane obiektu bazy danych w sposób relacyjny, aby uniknąć duplikowania informacji, gdy dwa lub więcej różnych obiektów bazy danych jest powiązanych ze wspólnym obiektem (na przykład dwa posty mające tego samego autora). Innymi słowy, dane obiektu bazy danych są znormalizowane.
Zalecana literatura : Tworzenie bezserwerowego formularza kontaktowego dla Twojej witryny statycznej
Struktura jest słownikiem, po pierwsze zorganizowanym pod każdy typ obiektu, a po drugie ID obiektu, z którego możemy uzyskać właściwości obiektu:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }Ten obiekt JSON jest już odpowiedzią z interfejsu API opartego na komponentach. Jego format jest specyfikacją samą w sobie: tak długo, jak serwer zwraca odpowiedź JSON w wymaganym formacie, klient może korzystać z interfejsu API niezależnie od sposobu jego implementacji. Dlatego API można zaimplementować w dowolnym języku (co jest jedną z największych zalet GraphQL: bycie specyfikacją, a nie rzeczywistą implementacją, umożliwiło udostępnienie go w wielu językach).
Uwaga : W nadchodzącym artykule opiszę moją implementację API opartego na komponentach w PHP (które jest dostępne w repozytorium).
Przykład odpowiedzi API
Na przykład poniższa odpowiedź API zawiera hierarchię komponentów z dwoma modułami, page => post-feed , gdzie moduł post-feed pobiera posty na blogu. Proszę zwrócić uwagę na następujące kwestie:
- Każdy moduł wie, które obiekty są odpytywane z właściwości
dbobjectids(identyfikatory4i9dla postów na blogu) - Każdy moduł zna typ obiektu dla swoich odpytywanych obiektów z właściwości
dbkeys(dane każdego wpisu znajdują się podposts, a dane autora wpisu odpowiadające autorowi o identyfikatorze podanym we właściwościauthorwpisu znajdują się podusers) - Ponieważ dane obiektu bazy danych są relacyjne,
authorwłaściwości zawiera identyfikator obiektu autora, zamiast bezpośrednio drukować dane autora.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }Różnice w pobieraniu danych z interfejsów API opartych na zasobach, schematach i komponentach
Zobaczmy, jak interfejs API oparty na składnikach, taki jak PoP, porównuje się podczas pobierania danych z interfejsem API opartym na zasobach, takim jak REST, oraz interfejsem API opartym na schemacie, takim jak GraphQL.
Załóżmy, że IMDB ma stronę z dwoma komponentami, które muszą pobrać dane: „Reżyser polecany” (pokazuje opis George'a Lucasa i listę jego filmów) oraz „Filmy polecane dla Ciebie” (pokazują filmy takie jak Gwiezdne wojny: część I — Mroczne widmo i Terminator ). Może to wyglądać tak:
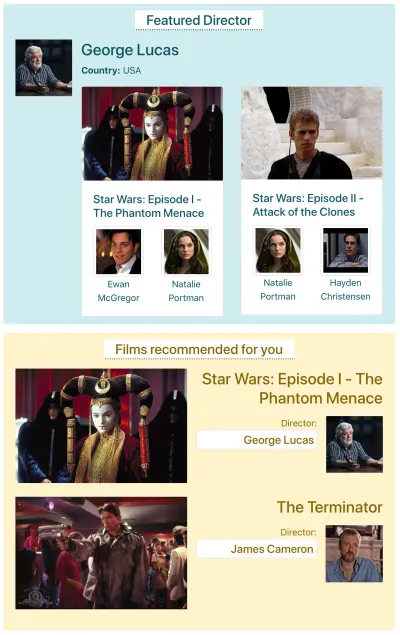
Zobaczmy, ile żądań jest potrzebnych do pobrania danych za pomocą każdej metody API. W tym przykładzie komponent „Wyróżniony reżyser” daje jeden wynik („George Lucas”), z którego pobiera dwa filmy ( Gwiezdne wojny: Część I — Mroczne widmo i Gwiezdne wojny: Część II — Atak klonów ) oraz dla każdego filmu po dwóch aktorów („Ewan McGregor” i „Natalie Portman” dla pierwszego filmu oraz „Natalie Portman” i „Hayden Christensen” dla drugiego filmu). Komponent „Filmy polecane dla Ciebie” przynosi dwa wyniki ( Gwiezdne wojny: część I — Mroczne widmo i Terminator ), a następnie pobiera ich reżyserów (odpowiednio „George Lucas” i „James Cameron”).
Używając REST do renderowania komponentu featured-director , możemy potrzebować następujących 7 żądań (liczba ta może się różnić w zależności od tego, ile danych dostarcza każdy punkt końcowy, tj. ile over-fetching zostało zaimplementowane):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL umożliwia, poprzez silnie typizowane schematy, pobranie wszystkich wymaganych danych w jednym żądaniu na komponent. Zapytanie o pobranie danych przez GraphQL dla komponentu featuredDirector wygląda tak (po zaimplementowaniu odpowiedniego schematu):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }I daje następującą odpowiedź:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }Zapytanie o komponent „Films Recommended for you” daje następującą odpowiedź:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP wyśle tylko jedno żądanie, aby pobrać wszystkie dane dla wszystkich komponentów na stronie i znormalizować wyniki. Wywoływany punkt końcowy jest po prostu taki sam jak adres URL, dla którego potrzebujemy uzyskać dane, wystarczy dodać dodatkowy parametr output=json , aby wskazać, że należy pobrać dane w formacie JSON zamiast drukować je jako HTML:
GET - /url-of-the-page/?output=json Zakładając, że struktura modułu ma górny moduł o nazwie page zawierający moduły featured-director i films-recommended-for-you , które również mają podmoduły, takie jak:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"Pojedyncza zwrócona odpowiedź JSON będzie wyglądać tak:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }Przeanalizujmy, jak te trzy metody porównują się ze sobą pod względem szybkości i ilości pobieranych danych.
Prędkość
Dzięki REST, konieczność pobrania 7 żądań tylko w celu wyrenderowania jednego komponentu może być bardzo powolna, głównie w przypadku mobilnych i niestabilnych połączeń danych. Stąd przeskok z REST do GraphQL jest bardzo szybki, ponieważ jesteśmy w stanie wyrenderować komponent za pomocą tylko jednego żądania.
PoP, ponieważ może pobrać wszystkie dane dla wielu komponentów w jednym żądaniu, będzie szybszy przy renderowaniu wielu komponentów jednocześnie; jednak najprawdopodobniej nie ma takiej potrzeby. Wyrenderowanie komponentów w kolejności (tak jak pojawiają się na stronie) jest już dobrą praktyką, a dla tych komponentów, które pojawiają się pod zakładką, z pewnością nie ma pośpiechu z ich renderowaniem. W związku z tym zarówno interfejsy API oparte na schemacie, jak i na komponentach są już całkiem dobre i wyraźnie lepsze od interfejsu API opartego na zasobach.
Ilość danych
Na każde żądanie dane w odpowiedzi GraphQL mogą zostać zduplikowane: aktorka „Natalie Portman” jest pobierana dwukrotnie w odpowiedzi z pierwszego komponentu, a biorąc pod uwagę wspólne wyjście dla dwóch komponentów, możemy również znaleźć wspólne dane, takie jak film Gwiezdne wojny: część I — Mroczne widmo .
Z drugiej strony PoP normalizuje dane bazy danych i drukuje je tylko raz, jednak ponosi narzut związany z drukowaniem struktury modułu. W związku z tym, w zależności od konkretnego żądania zawierającego zduplikowane dane lub nie, interfejs API oparty na schemacie lub interfejs API oparty na komponentach będzie miał mniejszy rozmiar.
Podsumowując, interfejs API oparty na schemacie, taki jak GraphQL i interfejs API oparty na komponentach, taki jak PoP, są podobnie dobre pod względem wydajności i lepsze od interfejsu API opartego na zasobach, takiego jak REST.
Zalecana literatura : Zrozumienie i korzystanie z interfejsów API REST
Szczególne właściwości API opartego na komponentach
Jeśli interfejs API oparty na komponentach niekoniecznie jest lepszy pod względem wydajności niż interfejs API oparty na schemacie, możesz się zastanawiać, co chcę osiągnąć dzięki temu artykułowi?
W tej sekcji postaram się przekonać, że takie API ma niesamowity potencjał, dostarczając kilka funkcji, które są bardzo pożądane, co czyni je poważnym pretendentem w świecie API. Poniżej opisuję i demonstruję każdą z jego wyjątkowych, wspaniałych funkcji.
Dane do pobrania z bazy danych można wywnioskować z hierarchii komponentów
Kiedy moduł wyświetla właściwość z obiektu DB, moduł może nie wiedzieć lub nie obchodzić, jaki to obiekt; zależy mu tylko na określeniu, jakie właściwości z wczytanego obiektu są wymagane.
Rozważmy na przykład obrazek poniżej. Moduł ładuje obiekt z bazy danych (w tym przypadku pojedynczy post), a następnie jego moduły podrzędne pokażą pewne właściwości obiektu, takie jak title i content :
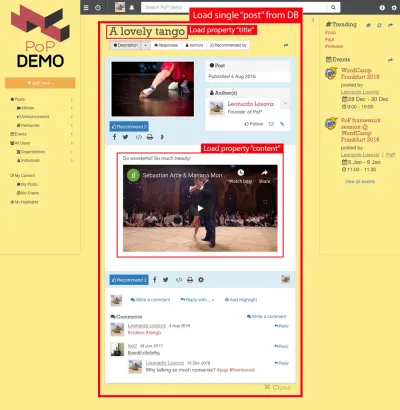
Stąd, wzdłuż hierarchii komponentów, moduły „dataloading” będą odpowiedzialne za ładowanie odpytywanych obiektów (w tym przypadku moduł ładujący pojedynczy post), a jego moduły potomne będą określać, jakie właściwości z obiektu DB są wymagane ( title i content , w tym przypadku).
Pobranie wszystkich wymaganych właściwości obiektu DB może odbywać się automatycznie, przechodząc przez hierarchię komponentów: zaczynając od modułu ładowania danych, iterujemy wszystkie jego moduły potomne aż do osiągnięcia nowego modułu ładowania danych lub do końca drzewa; na każdym poziomie uzyskujemy wszystkie wymagane właściwości, a następnie łączymy wszystkie właściwości razem i odpytujemy je z bazy danych, wszystkie tylko raz.
W poniższej strukturze moduł single-post pobiera wyniki z bazy danych (post z identyfikatorem 37), a podmoduły post-title i post-content definiują właściwości, które mają zostać załadowane dla odpytywanego obiektu DB (odpowiednio title i content ); submoduły post-layout i fetch-next-post-button nie wymagają żadnych pól danych.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"Zapytanie do wykonania jest obliczane automatycznie z hierarchii komponentów i ich wymaganych pól danych, zawierających wszystkie właściwości wymagane przez wszystkie moduły i ich podmoduły:
SELECT title, content FROM posts WHERE id = 37 Pobierając właściwości do pobrania bezpośrednio z modułów, zapytanie będzie automatycznie aktualizowane po każdej zmianie hierarchii komponentów. Jeśli na przykład dodamy podmoduł post-thumbnail , który wymaga thumbnail pola danych :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"Następnie zapytanie jest automatycznie aktualizowane w celu pobrania dodatkowej właściwości:
SELECT title, content, thumbnail FROM posts WHERE id = 37Ponieważ ustaliliśmy, że dane obiektów bazy danych mają być pobierane w sposób relacyjny, możemy również zastosować tę strategię między relacjami między samymi obiektami bazy danych.
Rozważ poniższy obraz: Zaczynając od post typu obiekt i przechodząc w dół hierarchii komponentów, będziemy musieli zmienić typ obiektu DB na user i comment , odpowiadający odpowiednio autorowi wpisu i każdemu z komentarzy, a następnie dla każdego komentarz, musi ponownie zmienić typ obiektu na user odpowiadającego autorowi komentarza.
Przejście z obiektu bazy danych do obiektu relacyjnego (prawdopodobnie zmiana typu obiektu, jak w post => author przechodzący od post do user lub nie, jak w author => obserwujący przechodzący od user do user ) nazywam „przełączaniem domen”. ”.
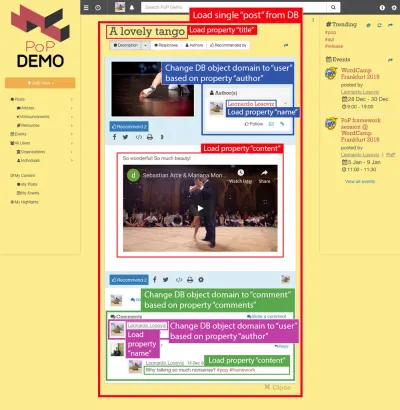
Po przejściu do nowej domeny, z tego poziomu w hierarchii komponentów w dół, wszystkie wymagane właściwości zostaną poddane nowej domenie:
-
namejest pobierana z obiektuuser(reprezentującego autora postu), -
contentjest pobierana z obiektucomment(reprezentującego każdy komentarz do posta), -
namejest pobierana z obiektuuser(reprezentującego autora każdego komentarza).
Przechodząc przez hierarchię komponentów, API wie, kiedy przechodzi do nowej domeny i odpowiednio aktualizuje zapytanie, aby pobrać obiekt relacyjny.
Na przykład, jeśli potrzebujemy pokazać dane od autora postu, post-author ze stosem podmodułu zmieni domenę na tym poziomie z post na odpowiedniego user , a od tego poziomu w dół obiekt DB załadowany do kontekstu przekazanego do modułu jest użytkownik. Następnie podmoduły user-name i user-avatar pod post-author wczytują właściwości name i avatar pod obiektem user :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"Wynik w następującym zapytaniu:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idPodsumowując, odpowiednio konfigurując każdy moduł, nie ma potrzeby pisania zapytania w celu pobrania danych dla interfejsu API opartego na komponentach. Zapytanie jest tworzone automatycznie na podstawie samej struktury hierarchii komponentów, uzyskując, jakie obiekty muszą być ładowane przez moduły ładowania danych, pola do pobrania dla każdego załadowanego obiektu zdefiniowanego w każdym module podrzędnym oraz przełączanie domen zdefiniowane w każdym module podrzędnym.
Dodanie, usunięcie, zastąpienie lub zmiana dowolnego modułu spowoduje automatyczną aktualizację zapytania. Po wykonaniu zapytania, pobrane dane będą dokładnie tym, co jest wymagane — niczym więcej lub mniej.
Obserwacja danych i obliczanie dodatkowych właściwości
Począwszy od modułu ładowania danych w dół hierarchii komponentów, każdy moduł może obserwować zwrócone wyniki i na ich podstawie obliczać dodatkowe elementy danych lub wartości feedback , które są umieszczane w pozycji moduledata .
Na przykład moduł fetch-next-post-button może dodać właściwość wskazującą, czy jest więcej wyników do pobrania, czy nie (na podstawie tej wartości opinii, jeśli nie ma więcej wyników, przycisk zostanie wyłączony lub ukryty):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }Ukryta wiedza o wymaganych danych zmniejsza złożoność i sprawia, że koncepcja „punktu końcowego” staje się przestarzała
Jak pokazano powyżej, API oparte na komponentach może pobrać dokładnie wymagane dane, ponieważ ma model wszystkich komponentów na serwerze i jakie pola danych są wymagane przez każdy komponent. Następnie może sprawić, że znajomość wymaganych pól danych będzie ukryta.

Zaletą jest to, że określenie, jakie dane są wymagane przez komponent, może być aktualizowane tylko po stronie serwera, bez konieczności ponownego wdrażania plików JavaScript, a klient może zostać ogłupiony, po prostu prosząc serwer o dostarczenie tych danych, których potrzebuje , zmniejszając w ten sposób złożoność aplikacji po stronie klienta.
Ponadto wywołanie interfejsu API w celu pobrania danych dla wszystkich komponentów dla określonego adresu URL można wykonać po prostu przez zapytanie o ten adres URL i dodanie dodatkowego parametru output=json , aby wskazać zwracanie danych API zamiast drukowania strony. W związku z tym adres URL staje się własnym punktem końcowym lub, rozważany w inny sposób, pojęcie „punktu końcowego” staje się przestarzałe.
Pobieranie podzbiorów danych: dane mogą być pobierane dla określonych modułów, znalezione na dowolnym poziomie hierarchii komponentów
Co się stanie, jeśli nie musimy pobierać danych dla wszystkich modułów na stronie, ale po prostu dane dla konkretnego modułu, zaczynając od dowolnego poziomu hierarchii komponentów? Na przykład, jeśli moduł implementuje przewijanie w nieskończoność, podczas przewijania w dół musimy pobrać tylko nowe dane dla tego modułu, a nie dla innych modułów na stronie.
Można to osiągnąć, filtrując gałęzie hierarchii komponentów, które zostaną uwzględnione w odpowiedzi, aby uwzględnić właściwości tylko zaczynające się od określonego modułu i zignorować wszystko powyżej tego poziomu. W mojej implementacji (którą opiszę w kolejnym artykule) filtrowanie jest włączane poprzez dodanie parametru modulefilter=modulepaths do adresu URL, a wybrany moduł (lub moduły) jest wskazywany przez parametr modulepaths[] , gdzie „ścieżka modułu ” to lista modułów zaczynająca się od najwyższego modułu do konkretnego modułu (np module1 => module2 => module3 ma ścieżkę do modułu [ module1 , module2 , module3 ] i jest przekazywany jako parametr adresu URL jako module1.module2.module3 ) .
Na przykład w hierarchii komponentów poniżej każdy moduł ma wpis dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Następnie żądanie adresu URL strony internetowej z dodaniem parametrów modulefilter=modulepaths i modulepaths[]=module1.module2.module5 zwróci następującą odpowiedź:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Zasadniczo API zaczyna ładować dane zaczynając od module1 => module2 => module5 . Dlatego module6 , który wchodzi w module5 , również dostarcza swoje dane, podczas gdy module3 i module4 nie.
Ponadto możemy tworzyć niestandardowe filtry modułów, aby uwzględnić wcześniej ustalony zestaw modułów. Na przykład wywołanie strony z modulefilter=userstate może wydrukować tylko te moduły, które wymagają stanu użytkownika do renderowania ich w kliencie, takie jak moduły module3 i module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] Informacje o tym, które moduły są startowe, znajdują się w sekcji requestmeta , pod wpisem filteredmodules , jako tablica ścieżek do modułów:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }Ta funkcja pozwala na zaimplementowanie nieskomplikowanej aplikacji Single-Page, w której ramka strony jest ładowana na początkowe żądanie:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] Ale od tego momentu możemy dodać parametr modulefilter=page do wszystkich żądanych adresów URL, odfiltrowując ramkę i wprowadzając tylko zawartość strony:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] Podobnie jak w przypadku opisanych powyżej filtrów userstate i page , możemy zaimplementować dowolny niestandardowy filtr modułu i stworzyć bogate doświadczenia użytkowników.
Moduł jest własnym API
Jak pokazano powyżej, możemy filtrować odpowiedź API, aby pobrać dane z dowolnego modułu. W konsekwencji każdy moduł może współdziałać ze sobą od klienta do serwera, po prostu dodając swoją ścieżkę modułu do adresu URL strony internetowej, w której został zawarty.
Mam nadzieję, że wybaczysz moje nadmierne podekscytowanie, ale naprawdę nie mogę wystarczająco podkreślić, jak wspaniała jest ta funkcja. Tworząc komponent, nie musimy tworzyć API, które będzie razem z nim pobierać dane (REST, GraphQL lub cokolwiek w ogóle), ponieważ komponent jest już w stanie komunikować się ze sobą na serwerze i ładować własne dane — jest całkowicie autonomiczny i samoobsługowy .
Każdy moduł ładowania danych eksportuje adres URL w celu interakcji z nim pod wpisem dataloadsource z sekcji datasetmodulemeta :
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }Pobieranie danych jest oddzielone między modułami i DRY
Aby pokazać, że pobieranie danych w interfejsie API opartym na komponentach jest wysoce oddzielone i DRY ( nie powtarzaj się sam ), najpierw muszę pokazać, jak w interfejsie API opartym na schemacie, takim jak GraphQL , jest on mniej oddzielony i nie suchy.
W GraphQL zapytanie pobierające dane musi wskazywać pola danych dla komponentu, które mogą zawierać podkomponenty, a te mogą również zawierać podkomponenty i tak dalej. Następnie najwyższy komponent musi wiedzieć, jakie dane są wymagane przez każdy z jego podkomponentów, aby je pobrać.
Na przykład renderowanie składnika <FeaturedDirector> może wymagać następujących składników podrzędnych:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> W tym scenariuszu zapytanie GraphQL jest implementowane na poziomie <FeaturedDirector> . Następnie, jeśli podkomponent <Film> zostanie zaktualizowany, żądając tytułu za pomocą właściwości filmTitle zamiast title , zapytanie z komponentu <FeaturedDirector> będzie również musiało zostać zaktualizowane, aby odzwierciedlić te nowe informacje (GraphQL ma mechanizm wersjonowania, który może obsługiwać z tym problemem, ale prędzej czy później powinniśmy nadal aktualizować informacje). Powoduje to złożoność konserwacji, która może być trudna w obsłudze, gdy wewnętrzne komponenty często się zmieniają lub są produkowane przez zewnętrznych deweloperów. W związku z tym komponenty nie są od siebie całkowicie odseparowane.
Podobnie, możemy chcieć bezpośrednio wyrenderować komponent <Film> dla jakiegoś konkretnego filmu, dla którego następnie musimy również zaimplementować zapytanie GraphQL na tym poziomie, aby pobrać dane dla filmu i jego aktorów, co dodaje nadmiarowy kod: części to samo zapytanie będzie znajdować się na różnych poziomach struktury komponentów. Więc GraphQL nie jest DRY .
Ponieważ API oparte na komponentach już wie, w jaki sposób jego komponenty otaczają się nawzajem we własnej strukturze, można całkowicie uniknąć tych problemów. Po pierwsze, klient może po prostu zażądać wymaganych danych, których potrzebuje, bez względu na to, jakie są to dane; if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
Jednak w interfejsie API opartym na komponentach możemy łatwo wykorzystać relacje między modułami już opisane w interfejsie API, aby połączyć je ze sobą. Chociaż pierwotnie otrzymamy tę odpowiedź:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }Po dodaniu Instagrama otrzymamy zaktualizowaną odpowiedź:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } I tylko przez iterację wszystkich wartości w modulesettings["share-on-social-media"].modules , komponent <ShareOnSocialMedia> można uaktualnić tak, aby wyświetlał komponent <InstagramShare> bez konieczności ponownego wdrażania jakiegokolwiek pliku JavaScript. W związku z tym API obsługuje dodawanie i usuwanie modułów bez narażania kodu z innych modułów, osiągając wyższy stopień modułowości.
Natywna pamięć podręczna/magazyn danych po stronie klienta
Pobrane dane z bazy danych są znormalizowane w strukturze słownikowej i ustandaryzowane w taki sposób, że począwszy od wartości na dbobjectids , do dowolnej części danych w databases można dotrzeć po prostu podążając ścieżką do niej wskazaną przez wpisy dbkeys , niezależnie od tego, w jaki sposób były one ustrukturyzowane . W związku z tym logika organizowania danych jest już natywna dla samego interfejsu API.
Możemy skorzystać z tej sytuacji na kilka sposobów. Na przykład zwrócone dane dla każdego żądania można dodać do pamięci podręcznej po stronie klienta zawierającej wszystkie dane żądane przez użytkownika w trakcie sesji. Dzięki temu można uniknąć dodawania do aplikacji zewnętrznego magazynu danych, takiego jak Redux (mam na myśli obsługę danych, a nie innych funkcji, takich jak Undo/Redo, środowisko współpracy czy debugowanie podróży w czasie).
Ponadto struktura oparta na komponentach promuje buforowanie: hierarchia komponentów zależy nie od adresu URL, ale od tego, jakie komponenty są potrzebne w tym adresie URL. W ten sposób dwa zdarzenia w /events/1/ i /events/2/ będą współdzielić tę samą hierarchię komponentów, a informacje o tym, jakie moduły są wymagane, mogą być w nich ponownie wykorzystane. W konsekwencji wszystkie właściwości (inne niż dane bazy danych) mogą być buforowane na kliencie po pobraniu pierwszego zdarzenia i od tego momentu ponownie wykorzystywane, tak że tylko dane bazy danych dla każdego kolejnego zdarzenia muszą zostać pobrane i nic więcej.
Rozszerzalność i zmiana przeznaczenia
Sekcja databases w interfejsie API może zostać rozszerzona, umożliwiając kategoryzację informacji w niestandardowych podsekcjach. Domyślnie wszystkie dane obiektów bazy danych są umieszczane pod wpisem primary , jednak możemy również tworzyć niestandardowe wpisy, w których należy umieścić określone właściwości obiektu DB.
Na przykład, jeśli opisany wcześniej komponent „Films Recommended for you” wyświetla listę znajomych zalogowanego użytkownika, którzy obejrzeli ten film, pod właściwością friendsWhoWatchedFilm w obiekcie DB film , ponieważ ta wartość będzie się zmieniać w zależności od zalogowanego user następnie zapisujemy tę właściwość pod wpisem userstate , więc gdy użytkownik się wyloguje, usuwamy tylko tę gałąź z buforowanej bazy danych na kliencie, ale wszystkie primary dane nadal pozostają:
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }Ponadto, do pewnego momentu, struktura odpowiedzi API może zostać zmieniona. W szczególności wyniki bazy danych mogą być drukowane w innej strukturze danych, takiej jak tablica zamiast domyślnego słownika.
Na przykład, jeśli typ obiektu jest tylko jeden (np. films ), można go sformatować jako tablicę, która zostanie przekazana bezpośrednio do komponentu typeahead:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]Wsparcie dla programowania zorientowanego aspektowo
Oprócz pobierania danych API oparte na komponentach może również publikować dane, takie jak tworzenie posta lub dodawanie komentarza, oraz wykonywać wszelkiego rodzaju operacje, takie jak logowanie lub wylogowywanie użytkownika, wysyłanie wiadomości e-mail, logowanie, analityka, i tak dalej. Nie ma ograniczeń: dowolna funkcjonalność dostarczana przez bazowy CMS może być wywołana przez moduł — na dowolnym poziomie.
Wzdłuż hierarchii komponentów możemy dodać dowolną liczbę modułów, a każdy moduł może wykonać swoją własną operację. Dlatego nie wszystkie operacje muszą być koniecznie związane z oczekiwaną akcją żądania, jak podczas wykonywania operacji POST, PUT lub DELETE w REST lub wysyłania mutacji w GraphQL, ale można je dodać, aby zapewnić dodatkowe funkcje, takie jak wysyłanie wiadomości e-mail do administratora, gdy użytkownik tworzy nowy post.
Tak więc, definiując hierarchię komponentów za pomocą wstrzykiwania zależności lub plików konfiguracyjnych, można powiedzieć, że interfejs API obsługuje programowanie zorientowane na aspekty, „paradygmat programowania, którego celem jest zwiększenie modułowości poprzez umożliwienie oddzielenia przekrojowych problemów”.
Zalecana literatura : Ochrona witryny za pomocą zasad dotyczących funkcji
Rozszerzona ochrona
Nazwy modułów niekoniecznie są stałe podczas drukowania na wyjściu, ale można je skracać, zniekształcać, zmieniać losowo lub (w skrócie) zmieniać w dowolny sposób. Chociaż pierwotnie planowano skrócić dane wyjściowe interfejsu API (tak, aby nazwy modułów carousel-featured-posts lub drag-and-drop-user-images mogły być skrócone do podstawowej notacji 64, takiej jak a1 , a2 itd., dla środowiska produkcyjnego ), ta funkcja pozwala często zmieniać nazwy modułów w odpowiedzi z API ze względów bezpieczeństwa.
Na przykład nazwy wejściowe są domyślnie nazywane jako odpowiadające im moduły; następnie moduły o nazwie username i password , które mają być renderowane w kliencie odpowiednio jako <input type="text" name="{input_name}"> i <input type="password" name="{input_name}"> , można ustawić różne losowe wartości dla ich nazw danych wejściowych (takich jak zwH8DSeG i QBG7m6EF dzisiaj oraz c3oMLBjo i c46oVgN6 jutro), co utrudnia spamerom i botom atakowanie witryny.
Wszechstronność dzięki alternatywnym modelom
Zagnieżdżanie modułów pozwala na rozgałęzienie do innego modułu w celu dodania kompatybilności z konkretnym medium lub technologią lub zmianę stylu lub funkcjonalności, a następnie powrót do oryginalnej gałęzi.
Załóżmy na przykład, że strona internetowa ma następującą strukturę:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" W tym przypadku chcielibyśmy, aby strona działała również dla AMP, jednak moduły module2 , module4 i module5 nie są kompatybilne z AMP. Możemy rozgałęziać te moduły na podobne, zgodne z AMP moduły module2AMP , module4AMP i module5AMP , po czym ładujemy oryginalną hierarchię komponentów, więc wtedy tylko te trzy moduły są zastępowane (i nic więcej):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"To sprawia, że dość łatwo jest generować różne dane wyjściowe z jednej bazy kodu, dodając widełki tylko tu i tam, gdy jest to potrzebne, i zawsze ograniczone do poszczególnych modułów.
Czas demonstracji
Kod implementujący interfejs API, jak wyjaśniono w tym artykule, jest dostępny w tym repozytorium typu open source.
Wdrożyłem API PoP pod https://nextapi.getpop.org w celach demonstracyjnych. Strona działa na WordPressie, więc permalinki URL są typowe dla WordPressa. Jak wspomniano wcześniej, poprzez dodanie do nich parametru output=json , te adresy URL stają się ich własnymi punktami końcowymi API.
Witryna jest obsługiwana przez tę samą bazę danych z witryny Demo PoP, więc wizualizację hierarchii komponentów i pobranych danych można wykonać, wysyłając zapytanie o ten sam adres URL w tej innej witrynie (np. odwiedzając https://demo.getpop.org/u/leo/ wyjaśnia dane z https://nextapi.getpop.org/u/leo/?output=json ).
Poniższe linki przedstawiają interfejs API w przypadkach opisanych wcześniej:
- Strona główna, pojedynczy post, autor, lista postów i lista użytkowników.
- Zdarzenie filtrujące z określonego modułu.
- Znacznik, moduły filtrujące, które wymagają stanu użytkownika i filtrowania, aby pobrać tylko stronę z aplikacji jednostronicowej.
- Tablica lokalizacji, które można wprowadzić do wpisu.
- Alternatywne modele strony „Kim jesteśmy”: Normalne, do druku, do osadzenia.
- Zmiana nazw modułów: oryginalne vs zniekształcone.
- Informacje o filtrowaniu: tylko ustawienia modułu, dane modułu plus dane bazy danych.
Wniosek
Dobre API to odskocznia do tworzenia niezawodnych, łatwych w utrzymaniu i wydajnych aplikacji. W tym artykule opisałem koncepcje napędzające API oparte na komponentach, które moim zdaniem jest całkiem dobrym API i mam nadzieję, że Was również przekonałem.
Jak dotąd projektowanie i wdrażanie API obejmowało kilka iteracji i trwało ponad pięć lat — i nie jest jeszcze w pełni gotowe. Jest jednak w całkiem przyzwoitym stanie, nie gotowy do produkcji, ale jako stabilna alfa. Obecnie wciąż nad tym pracuję; praca nad zdefiniowaniem otwartej specyfikacji, implementacja dodatkowych warstw (np. rendering) oraz pisanie dokumentacji.
W kolejnym artykule opiszę, jak działa moja implementacja API. Do tego czasu, jeśli masz jakieś przemyślenia na ten temat – niezależnie od tego, czy są pozytywne, czy negatywne – chętnie przeczytam Twoje komentarze poniżej.
Aktualizacja (31 stycznia): Niestandardowe możliwości zapytań
Alain Schlesser skomentował, że interfejs API, który nie może być odpytywany przez klienta, jest bezwartościowy, co prowadzi nas z powrotem do SOAP, ponieważ jako taki nie może konkurować ani z REST, ani z GraphQL. Po kilkudniowym zastanowieniu się nad jego komentarzem musiałem przyznać, że ma rację. Jednak zamiast odrzucać API oparte na komponentach jako przedsięwzięcie oparte na dobrych intencjach, ale jeszcze nie do końca, zrobiłem coś znacznie lepszego: musiałem zaimplementować dla niego możliwość niestandardowego zapytania. I działa jak urok!
W poniższych łączach dane dotyczące zasobu lub kolekcji zasobów są pobierane, jak zwykle odbywa się za pośrednictwem REST. Jednak za pomocą fields parametrów możemy również określić, jakie konkretne dane należy pobrać dla każdego zasobu, unikając nadmiernego lub niedoboru danych:
- Pojedynczy post i zbiór postów z dodawaniem
fields=title,content,datetime - Użytkownik i zbiór użytkowników dodających
fields=name,username,description
Powyższe linki demonstrują pobieranie danych tylko dla zapytanych zasobów. A co z ich związkami? Załóżmy na przykład, że chcemy pobrać listę postów z polami "title" i "content" , komentarze do każdego posta z polami "content" i "date" oraz autora każdego komentarza z polami "name" i "url" . Aby to osiągnąć w GraphQL, zaimplementowalibyśmy następujące zapytanie:
query { post { title content comments { content date author { name url } } } } W celu zaimplementowania API opartego na komponentach przetłumaczyłem zapytanie na odpowiadające mu wyrażenie „składnia z kropką”, które można następnie podać za pomocą fields parametrów . Przy zapytaniu o zasób „post” ta wartość to:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url Lub można to uprościć, używając | aby pogrupować wszystkie pola zastosowane do tego samego zasobu:
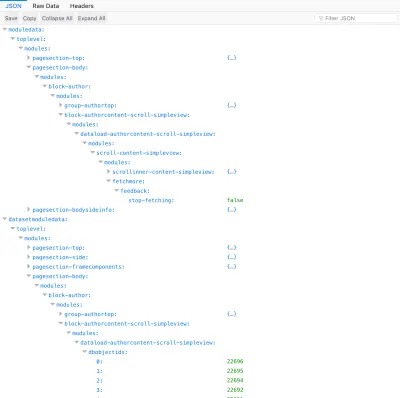
fields=title|content,comments.content|date,comments.author.name|urlWykonując to zapytanie na pojedynczym poście uzyskujemy dokładnie wymagane dane dla wszystkich zaangażowanych zasobów:
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } Dlatego możemy wysyłać zapytania do zasobów w sposób REST i określać zapytania oparte na schemacie w sposób GraphQL, a uzyskamy dokładnie to, co jest wymagane, bez nadmiernego lub niedoboru danych i normalizacji danych w bazie danych, aby żadne dane nie były duplikowane. Korzystnie, zapytanie może zawierać dowolną liczbę relacji, głęboko zagnieżdżonych, a te są rozwiązywane z czasem złożoności liniowej: najgorszy przypadek O(n+m), gdzie n to liczba węzłów, które przełączają domenę (w tym przypadku 2: comments i comments.author ), a m to liczba pobranych wyników (w tym przypadku 5: 1 post + 2 komentarze + 2 użytkowników) oraz średni przypadek O(n). (Jest to bardziej wydajne niż GraphQL, który ma wielomianowy czas złożoności O(n^c) i cierpi z powodu wydłużania czasu wykonywania wraz ze wzrostem głębokości poziomu).
Wreszcie, ten interfejs API może również stosować modyfikatory podczas zapytań o dane, na przykład w celu filtrowania pobieranych zasobów, na przykład za pomocą GraphQL. Aby to osiągnąć, API po prostu znajduje się na górze aplikacji i może wygodnie korzystać z jej funkcjonalności, więc nie ma potrzeby wymyślania koła na nowo. Na przykład dodanie parametrów filter=posts&searchfor=internet spowoduje odfiltrowanie wszystkich postów zawierających "internet" ze zbioru postów.
Wdrożenie tej nowej funkcji zostanie opisane w nadchodzącym artykule.