
Konwersja obrazu na tekst za pomocą React i Tesseract.js (OCR)
Opublikowany: 2022-03-10Dane są podstawą każdej aplikacji, ponieważ głównym celem aplikacji jest rozwiązywanie ludzkich problemów. Aby rozwiązać ludzkie problemy, konieczne jest posiadanie pewnych informacji na ich temat.
Takie informacje są przedstawiane jako dane, zwłaszcza poprzez obliczenia. W sieci dane są gromadzone głównie w postaci tekstów, obrazów, filmów i wielu innych. Czasami obrazy zawierają niezbędne teksty, które mają zostać przetworzone w określonym celu. Te obrazy były w większości przetwarzane ręcznie, ponieważ nie było możliwości ich programowego przetworzenia.
Brak możliwości wyodrębnienia tekstu z obrazów był ograniczeniem przetwarzania danych, którego doświadczyłem na własnej skórze w mojej ostatniej firmie. Musieliśmy przetworzyć zeskanowane karty podarunkowe i musieliśmy to zrobić ręcznie , ponieważ nie mogliśmy wyodrębnić tekstu z obrazów.
W firmie istniał dział „Operacje”, który odpowiadał za ręczne potwierdzanie kart podarunkowych i uznawanie kont użytkowników. Chociaż mieliśmy stronę internetową, przez którą użytkownicy łączyli się z nami, przetwarzanie kart podarunkowych odbywało się ręcznie za kulisami.
W tamtym czasie nasza strona była zbudowana głównie z PHP (Laravel) dla backendu oraz JavaScript (jQuery i Vue) dla frontendu. Nasz stos techniczny był wystarczająco dobry, aby pracować z Tesseract.js, pod warunkiem, że problem został uznany przez kierownictwo za ważny.
Chciałem rozwiązać problem, ale nie było to konieczne, sądząc z punktu widzenia biznesu lub kierownictwa. Po odejściu z firmy postanowiłem zrobić rozeznanie i spróbować znaleźć możliwe rozwiązania. W końcu odkryłem OCR.
Co to jest OCR?
OCR to skrót od „Optical Character Recognition” lub „Optical Character Reader”. Służy do wyodrębniania tekstów z obrazów.
Ewolucję OCR można przypisać kilku wynalazkom, ale Optophone, „Gismo”, płaski skaner CCD, Newton MessagePad i Tesseract to główne wynalazki, które przenoszą rozpoznawanie postaci na inny poziom użyteczności.
Dlaczego więc używać OCR? Cóż, optyczne rozpoznawanie znaków rozwiązuje wiele problemów, z których jeden skłonił mnie do napisania tego artykułu. Zdałem sobie sprawę, że możliwość wyodrębnienia tekstów z obrazu daje wiele możliwości, takich jak:
- Rozporządzenie
Każda organizacja z jakichś powodów musi regulować działania użytkowników. Regulacja może służyć do ochrony praw użytkowników i zabezpieczenia ich przed groźbami lub oszustwami.
Wyodrębnianie tekstów z obrazu umożliwia organizacji przetwarzanie informacji tekstowych na obrazie w celu regulacji, zwłaszcza gdy obrazy są dostarczane przez niektórych użytkowników.
Na przykład regulacja liczby tekstów na obrazach wykorzystywanych w reklamach, podobna do Facebooka, może zostać osiągnięta za pomocą OCR. Ukrywanie poufnych treści na Twitterze jest również możliwe dzięki OCR. - Możliwość wyszukiwania
Wyszukiwanie to jedna z najczęstszych czynności, zwłaszcza w Internecie. Algorytmy wyszukiwania opierają się głównie na manipulowaniu tekstami. Dzięki optycznemu rozpoznawaniu znaków możliwe jest rozpoznawanie znaków na obrazach i używanie ich do dostarczania użytkownikom odpowiednich wyników. Krótko mówiąc, obrazy i filmy można teraz przeszukiwać za pomocą OCR. - Dostępność
Posiadanie tekstów na obrazach zawsze było wyzwaniem dla dostępności i jest praktyczną zasadą, aby mieć niewiele tekstów na obrazie. Dzięki OCR czytniki ekranu mogą mieć dostęp do tekstów na obrazach, aby zapewnić użytkownikom niezbędne wrażenia. - Automatyzacja Przetwarzania Danych Przetwarzanie danych jest w większości zautomatyzowane dla skali. Posiadanie tekstów na obrazach jest ograniczeniem w przetwarzaniu danych, ponieważ teksty nie mogą być przetwarzane inaczej niż ręcznie. Optyczne rozpoznawanie znaków (OCR) umożliwia programowe wyodrębnianie tekstów na obrazach, zapewniając automatyzację przetwarzania danych, zwłaszcza gdy ma to związek z przetwarzaniem tekstów na obrazach.
- Digitalizacja materiałów drukowanych
Wszystko staje się cyfrowe i wciąż jest wiele dokumentów do zdigitalizowania. Czeki, certyfikaty i inne dokumenty fizyczne można teraz zdigitalizować za pomocą optycznego rozpoznawania znaków.
Poznanie wszystkich powyższych zastosowań pogłębiło moje zainteresowania, dlatego postanowiłem pójść dalej i zadać pytanie:
„Jak mogę korzystać z OCR w sieci, zwłaszcza w aplikacji React?”
To pytanie zaprowadziło mnie do Tesseract.js.
Co to jest Tesseract.js?
Tesseract.js to biblioteka JavaScript, która kompiluje oryginalny Tesseract z C do JavaScript WebAssembly, dzięki czemu OCR jest dostępny w przeglądarce. Silnik Tesseract.js został pierwotnie napisany w ASM.js, a później został przeniesiony do WebAssembly, ale ASM.js nadal służy jako kopia zapasowa w niektórych przypadkach, gdy WebAssembly nie jest obsługiwany.
Jak podano na stronie Tesseract.js, obsługuje ponad 100 języków , automatyczną orientację tekstu i wykrywanie skryptów, prosty interfejs do czytania akapitów, słów i ramek ograniczających znaki.
Tesseract to mechanizm optycznego rozpoznawania znaków dla różnych systemów operacyjnych. Jest to darmowe oprogramowanie, wydane na licencji Apache. Hewlett-Packard opracował Tesseract jako oprogramowanie własnościowe w latach 80. XX wieku. Został wydany jako open source w 2005 roku, a jego rozwój jest sponsorowany przez Google od 2006 roku.
Najnowsza wersja Tesseract, wersja 4, została wydana w październiku 2018 roku i zawiera nowy silnik OCR, który wykorzystuje system sieci neuronowej oparty na pamięci Long Short-Term Memory (LSTM) i ma zapewniać dokładniejsze wyniki.
Zrozumienie interfejsów API Tesseract
Aby naprawdę zrozumieć, jak działa Tesseract, musimy rozbić niektóre jego interfejsy API i ich komponenty. Zgodnie z dokumentacją Tesseract.js istnieją dwa sposoby podejścia do korzystania z niego. Poniżej pierwsze podejście i jego podział:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } Metoda recognize przyjmuje obraz jako swój pierwszy argument, język (który może być wielokrotny) jako drugi argument i { logger: m => console.log(me) } jako ostatni argument. Format obrazu obsługiwany przez Tesseract to jpg, png, bmp i pbm, które mogą być dostarczane tylko jako elementy (img, wideo lub płótno), obiekt pliku ( <input> ), obiekt blob, ścieżka lub adres URL obrazu i obraz zakodowany w base64 . (Przeczytaj tutaj, aby uzyskać więcej informacji o wszystkich formatach obrazów, które obsługuje Tesseract.)
Język jest dostarczany jako ciąg, taki jak eng . Znak + może być używany do łączenia kilku języków, jak w eng+chi_tra . Argument języka służy do określenia wyszkolonych danych językowych, które mają być używane w przetwarzaniu obrazów.
Uwaga : wszystkie dostępne języki i ich kody znajdziesz tutaj.
{ logger: m => console.log(m) } jest bardzo przydatny do uzyskania informacji o postępie przetwarzania obrazu. Właściwość rejestratora przyjmuje funkcję, która będzie wywoływana wielokrotnie, gdy Tesseract przetwarza obraz. Parametrem funkcji rejestratora powinien być obiekt z workerId , jobId , status i progress :
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress to liczba z zakresu od 0 do 1, która w procentach pokazuje postęp procesu rozpoznawania obrazu.
Tesseract automatycznie generuje obiekt jako parametr funkcji rejestratora, ale może być również zasilany ręcznie. Ponieważ ma miejsce proces rozpoznawania, właściwości obiektu logger są aktualizowane za każdym razem, gdy funkcja jest wywoływana . Może więc służyć do wyświetlania paska postępu konwersji, zmiany jakiejś części aplikacji lub do osiągnięcia pożądanego rezultatu.
result w powyższym kodzie jest wynikiem procesu rozpoznawania obrazu. Każda z właściwości result ma właściwość bbox jako współrzędne x/y ich obwiedni.
Oto właściwości obiektu result , ich znaczenie lub zastosowania:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: Cały rozpoznany tekst jako ciąg. -
lines: tablica każdego rozpoznanego wiersza po wierszu tekstu. -
words: tablica każdego rozpoznanego słowa. -
symbols: tablica każdego rozpoznanego znaku. -
paragraphs: tablica każdego rozpoznanego akapitu. W dalszej części tego artykułu omówimy „zaufanie”.
Tesseract może być również używany bardziej imperatywnie, jak w:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();To podejście jest związane z pierwszym podejściem, ale z różnymi implementacjami.
createWorker(options) tworzy proces potomny sieci Web lub proces potomny węzła, który tworzy proces roboczy Tesseract. Pracownik pomaga skonfigurować silnik Tesseract OCR. Metoda load() ładuje podstawowe skrypty Tesseract, loadLanguage() ładuje dowolny dostarczony do niej język jako ciąg znaków, initialize() upewnia się, że Tesseract jest w pełni gotowy do użycia, a następnie do przetworzenia dostarczonego obrazu używana jest metoda rozpoznawania. Metoda Termin() zatrzymuje proces roboczy i czyści wszystko.
Uwaga : więcej informacji znajdziesz w dokumentacji interfejsów API Tesseracta.
Teraz musimy coś zbudować, aby naprawdę zobaczyć, jak skuteczny jest Tesseract.js.
Co zbudujemy?
Zamierzamy zbudować ekstraktor PIN karty podarunkowej, ponieważ wydobywanie PIN z karty podarunkowej było problemem, który doprowadził do tej przygody z pisaniem.
Zbudujemy prostą aplikację, która wyciągnie PIN ze zeskanowanej karty podarunkowej . Kiedy postanowiłem zbudować prosty ekstraktor szpilek do kart podarunkowych, przeprowadzę Cię przez niektóre z wyzwań, z jakimi się zmierzyłem, rozwiązania, które dostarczyłem, i moje wnioski oparte na moim doświadczeniu.
- Przejdź do kodu źródłowego →
Poniżej znajduje się obraz, którego użyjemy do testowania, ponieważ ma pewne realistyczne właściwości, które są możliwe w prawdziwym świecie.

Wyodrębnimy z karty AQUX-QWMB6L-R6JAU . Więc zacznijmy.
Instalacja React i Tesseract
Jest pytanie, na które należy zwrócić uwagę przed instalacją Reacta i Tesseract.js, a dlaczego używać Reacta z Tesseractem? Praktycznie możemy używać Tesseracta z Vanilla JavaScript, dowolnymi bibliotekami JavaScript lub frameworkami typu React, Vue i Angular.
Korzystanie z Reacta w tym przypadku jest osobistą preferencją. Początkowo chciałem użyć Vue, ale zdecydowałem się na React, ponieważ React jest mi bardziej znany niż Vue.
Teraz przejdźmy do instalacji.
Aby zainstalować React z create-react-app, musisz uruchomić poniższy kod:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jslub
npm install tesseract.jsZdecydowałem się na włóczkę, aby zainstalować Tesseract.js, ponieważ nie mogłem zainstalować Tesseract z npm, ale włóczka wykonała pracę bez stresu. Możesz użyć npm, ale sądząc z mojego doświadczenia, polecam zainstalować Tesseract z włóczką.
Teraz zacznijmy nasz serwer programistyczny, uruchamiając poniższy kod:
yarn startlub
npm startPo uruchomieniu przędzy start lub npm start domyślna przeglądarka powinna otworzyć stronę, która wygląda jak poniżej:

Możesz także przejść do localhost:3000 w przeglądarce, pod warunkiem, że strona nie zostanie uruchomiona automatycznie.
Po zainstalowaniu Reacta i Tesseract.js, co dalej?
Konfigurowanie formularza przesyłania
W tym przypadku dostosujemy stronę główną (App.js), którą właśnie oglądaliśmy w przeglądarce, aby zawierała potrzebny nam formularz:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App Część powyższego kodu, która w tym momencie wymaga naszej uwagi, to funkcja handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } W funkcji URL.createObjectURL pobiera wybrany plik przez event.target.files[0] i tworzy referencyjny adres URL, którego można używać ze znacznikami HTML, takimi jak img, audio i wideo. Użyliśmy setImagePath , aby dodać adres URL do stanu. Teraz adres URL jest teraz dostępny za pomocą imagePath .
<img src={imagePath} className="App-logo" alt="image"/> Ustawiamy atrybut src obrazu na {imagePath} , aby wyświetlić podgląd w przeglądarce przed przetworzeniem.
Konwertowanie wybranych obrazów na teksty
Ponieważ złapaliśmy ścieżkę do wybranego obrazu, możemy przekazać ścieżkę obrazu do Tesseract.js, aby wyodrębnić z niego teksty.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default AppDodajemy funkcję „handleClick” do „App.js i zawiera ona Tesseract.js API, która pobiera ścieżkę do wybranego obrazu. Tesseract.js przyjmuje „imagePath”, „język”, „obiekt ustawień”.
Poniższy przycisk jest dodawany do formularza, aby wywołać „handClick”, co powoduje konwersję obrazu na tekst po każdym kliknięciu przycisku.
<button onClick={handleClick} style={{height:50}}> convert to text</button>Gdy przetwarzanie się powiedzie, uzyskujemy dostęp zarówno do „zaufania”, jak i „tekstu” z wyniku. Następnie do stanu dodajemy „text” za pomocą „setText(text)”.
Dodając do <p> {text} </p> , wyświetlamy wyodrębniony tekst.
Oczywiste jest, że „tekst” jest wydobywany z obrazu, ale czym jest pewność?
Zaufanie pokazuje, jak dokładna jest konwersja. Poziom ufności wynosi od 1 do 100. 1 oznacza najgorszy, a 100 oznacza najlepszą pod względem dokładności. Może być również używany do określenia, czy wyodrębniony tekst powinien zostać uznany za dokładny, czy nie.
Następnie pojawia się pytanie, jakie czynniki mogą wpłynąć na wynik ufności lub dokładność całej konwersji? Wpływają na to głównie trzy główne czynniki — jakość i charakter używanego dokumentu, jakość skanu utworzonego z dokumentu oraz możliwości przetwarzania silnika Tesseract.
Teraz dodajmy poniższy kod do „App.css”, aby nieco wystylizować aplikację.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }Oto wynik mojego pierwszego testu :
Wynik w Firefoksie
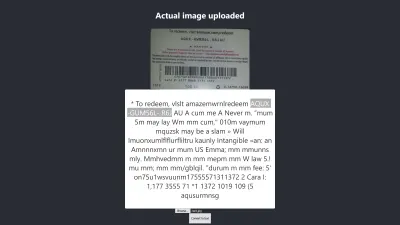
Poziom ufności powyższego wyniku to 64. Warto zauważyć, że obraz karty podarunkowej ma ciemny kolor i zdecydowanie wpływa to na otrzymany wynik.

Jeśli przyjrzysz się bliżej powyższemu obrazkowi, zobaczysz, że pinezka z karty jest prawie dokładna w wyodrębnionym tekście. Nie jest to dokładne, ponieważ karta podarunkowa nie jest do końca jasna.
Zaczekaj! Jak to będzie wyglądać w Chrome?
Wynik w Chrome
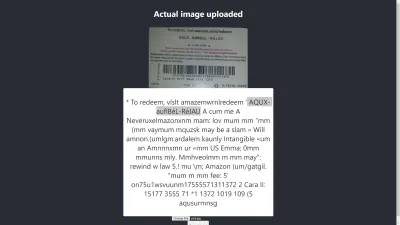
Ach! W Chrome wynik jest jeszcze gorszy. Ale dlaczego wynik w Chrome różni się od Mozilla Firefox? Różne przeglądarki w różny sposób obsługują obrazy i ich profile kolorów. Oznacza to, że obraz może być renderowany w różny sposób w zależności od przeglądarki . Dostarczanie wstępnie wyrenderowanych danych image.data do Tesseract prawdopodobnie da różne wyniki w różnych przeglądarkach, ponieważ różne image.data są dostarczane do Tesseract w zależności od używanej przeglądarki. Wstępne przetwarzanie obrazu, jak zobaczymy w dalszej części tego artykułu, pomoże osiągnąć spójny wynik.
Musimy być bardziej dokładni, aby mieć pewność, że otrzymujemy lub przekazujemy właściwe informacje. Musimy więc posunąć się nieco dalej.
Spróbujmy więcej, aby zobaczyć, czy w końcu uda nam się osiągnąć cel.
Testowanie pod kątem dokładności
Istnieje wiele czynników, które wpływają na konwersję obrazu na tekst za pomocą Tesseract.js. Większość z tych czynników zależy od charakteru obrazu, który chcemy przetworzyć, a reszta zależy od tego, jak silnik Tesseract radzi sobie z konwersją.
Wewnętrznie Tesseract wstępnie przetwarza obrazy przed właściwą konwersją OCR, ale nie zawsze daje dokładne wyniki.
Jako rozwiązanie możemy wstępnie przetworzyć obrazy w celu uzyskania dokładnych konwersji. Możemy zbinaryzować, odwrócić, poszerzyć, pochylić lub przeskalować obraz, aby wstępnie przetworzyć go dla Tesseract.js.
Wstępne przetwarzanie obrazu to samo w sobie dużo pracy lub rozległe pole. Na szczęście P5.js zapewnia wszystkie techniki wstępnego przetwarzania obrazu, których chcemy użyć. Zamiast wymyślać koło na nowo lub korzystać z całej biblioteki tylko dlatego, że chcemy wykorzystać jej niewielką część, skopiowałem te, których potrzebujemy. Wszystkie techniki wstępnego przetwarzania obrazu są zawarte w preprocess.js.
Co to jest Binaryzacja?
Binaryzacja to konwersja pikseli obrazu na czerń lub biel. Chcemy zbinaryzować poprzednią kartę podarunkową, aby sprawdzić, czy dokładność będzie lepsza, czy nie.
Wcześniej wyodrębniliśmy niektóre teksty z karty podarunkowej, ale docelowy kod PIN nie był tak dokładny, jak oczekiwaliśmy. Dlatego istnieje potrzeba znalezienia innego sposobu na uzyskanie dokładnego wyniku.
Teraz chcemy zbinaryzować kartę podarunkową , czyli przekonwertować jej piksele na czarno-białe, abyśmy mogli zobaczyć, czy można osiągnąć lepszy poziom dokładności, czy nie.
Poniższe funkcje zostaną użyte do binaryzacji i są zawarte w osobnym pliku o nazwie preprocess.js.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageCo robi powyższy kod?
Wprowadzamy płótno do przechowywania danych obrazu, aby zastosować niektóre filtry, wstępnie przetworzyć obraz przed przekazaniem go do Tesseract w celu konwersji.
Pierwsza funkcja preprocessImage znajduje się w preprocess.js i przygotowuje kanwę do użycia, pobierając jej piksele. Funkcja thresholdFilter binarizuje obraz, konwertując jego piksele na kolor czarny lub biały .
Zadzwońmy do preprocessImage , aby sprawdzić, czy tekst wyodrębniony z poprzedniej karty podarunkowej może być dokładniejszy.
Zanim zaktualizujemy App.js, kod powinien teraz wyglądać tak:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default AppNajpierw musimy zaimportować „preprocessImage” z „preprocess.js” z poniższym kodem:
import preprocessImage from './preprocess'; Następnie do formularza dodajemy tag canvas. Ustawiamy atrybut ref tagów canvas i img odpowiednio na { canvasRef } i { imageRef } . Odnośniki służą do uzyskiwania dostępu do kanwy i obrazu z komponentu App. Otrzymujemy zarówno płótno, jak i obraz za pomocą „useRef”, jak w:
const canvasRef = useRef(null); const imageRef = useRef(null);W tej części kodu łączymy obraz z płótnem, ponieważ możemy wstępnie przetworzyć płótno tylko w JavaScript. Następnie konwertujemy go na adres URL danych z „jpeg” jako formatem obrazu.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");„dataUrl” jest przekazywany do Tesseract jako obraz do przetworzenia.
Sprawdźmy teraz, czy wyodrębniony tekst będzie dokładniejszy.
Test #2

Powyższy obrazek pokazuje wynik w Firefoksie. Jest oczywiste, że ciemna część obrazu została zmieniona na białą, ale wstępne przetwarzanie obrazu nie prowadzi do dokładniejszego wyniku. Jest jeszcze gorzej.
Pierwsza konwersja ma tylko dwa nieprawidłowe znaki, ale ta ma cztery nieprawidłowe znaki. Próbowałem nawet zmienić poziom progu, ale bezskutecznie. Lepszego wyniku nie uzyskujemy nie dlatego, że binaryzacja jest zła, ale dlatego, że binaryzacja obrazu nie poprawia natury obrazu w sposób odpowiedni dla silnika Tesseract.
Sprawdźmy, jak to też wygląda w Chrome:

Otrzymujemy ten sam wynik.
Po uzyskaniu gorszego wyniku poprzez binaryzację obrazu, należy sprawdzić inne techniki przetwarzania obrazu, aby sprawdzić, czy możemy rozwiązać problem, czy nie. Więc spróbujemy teraz dylatacji, inwersji i rozmycia.
Po prostu pobierzmy kod dla każdej z technik z P5.js użytych w tym artykule. Dodamy techniki przetwarzania obrazu do preprocess.js i będziemy z nich korzystać po kolei. Konieczne jest zrozumienie każdej z technik wstępnego przetwarzania obrazu, których chcemy użyć przed ich użyciem, dlatego najpierw je omówimy.
Co to jest dylatacja?
Dylatacja to dodawanie pikseli do granic obiektów na obrazie, aby uczynić go szerszym, większym lub bardziej otwartym. Technika „rozszerzenia” służy do wstępnego przetwarzania naszych obrazów w celu zwiększenia jasności obiektów na obrazach. Potrzebujemy funkcji rozszerzającej obrazy za pomocą JavaScript, więc fragment kodu rozszerzający obraz jest dodawany do preprocess.js.
Co to jest rozmycie?
Rozmycie to wygładzenie kolorów obrazu poprzez zmniejszenie jego ostrości. Czasami obrazy mają małe kropki/łatki. Aby usunąć te łatki, możemy rozmazać obrazy. Fragment kodu służący do rozmycia obrazu jest zawarty w preprocess.js.
Co to jest inwersja?
Inwersja zmienia jasne obszary obrazu na ciemny kolor, a ciemne obszary na jasny kolor. Na przykład, jeśli obraz ma czarne tło i biały pierwszy plan, możemy go odwrócić tak, aby jego tło było białe, a pierwszy plan czarny. Dodaliśmy również fragment kodu, aby odwrócić obraz do preprocess.js.
Po dodaniu dilate , invertColors i blurARGB do „preprocess.js”, możemy teraz używać ich do wstępnego przetwarzania obrazów. Aby z nich skorzystać, musimy zaktualizować początkową funkcję „preprocessImage” w preprocess.js:
preprocessImage(...) wygląda teraz tak:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } W preprocessImage powyżej stosujemy cztery techniki przetwarzania wstępnego do obrazu: blurARGB() , aby usunąć kropki z obrazu, dilate() , aby zwiększyć jasność obrazu, invertColors() , aby przełączyć kolor pierwszego planu i tła obrazu oraz thresholdFilter() , aby przekonwertować obraz na czarno-biały, który jest bardziej odpowiedni dla konwersji Tesseract.
Funkcja thresholdFilter() przyjmuje jako parametry image.data i level . level jest używany do ustawienia, jak biały lub czarny powinien być obraz. Ustaliliśmy thresholdFilter filtra i promień blurRGB metodą prób i błędów, ponieważ nie jesteśmy pewni, jak biały, ciemny lub gładki powinien być obraz, aby Tesseract mógł uzyskać doskonały wynik.
Test nr 3
Oto nowy wynik po zastosowaniu czterech technik:

Powyższy obrazek przedstawia wynik, który otrzymujemy zarówno w przeglądarce Chrome, jak i Firefox.
Ups! Wynik jest straszny.
Zamiast używać wszystkich czterech technik, dlaczego po prostu nie użyjemy dwóch z nich na raz?
Tak! Możemy po prostu użyć technik invertColors i thresholdFilter , aby przekonwertować obraz na czarno-biały i zamienić pierwszy plan i tło obrazu. Ale skąd wiemy, jakie i jakie techniki połączyć? Wiemy, co połączyć, w zależności od charakteru obrazu, który chcemy wstępnie przetworzyć.
Na przykład obraz cyfrowy musi zostać przekonwertowany na czarno-biały, a obraz z plamami musi zostać zamazany, aby usunąć kropki/łatki. Naprawdę ważne jest zrozumienie, do czego służy każda z technik.
Aby użyć invertColors i thresholdFilter , musimy zakomentować zarówno blurARGB , jak i dilate w preprocessImage :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }Test #4
Oto nowy wynik:

Wynik jest nadal gorszy niż bez wstępnego przetwarzania. Po dostosowaniu każdej z technik do tego konkretnego obrazu i kilku innych obrazów, doszedłem do wniosku, że obrazy o innej naturze wymagają różnych technik obróbki wstępnej.
Krótko mówiąc, użycie Tesseract.js bez wstępnego przetwarzania obrazu dało najlepszy wynik dla powyższej karty podarunkowej. Wszystkie inne eksperymenty z wstępnym przetwarzaniem obrazu przyniosły mniej dokładne wyniki.
Sprawa
Początkowo chciałem wyodrębnić kod PIN z dowolnej karty podarunkowej Amazon, ale nie mogłem tego osiągnąć, ponieważ nie ma sensu dopasowywać niespójnego kodu PIN, aby uzyskać spójny wynik. Chociaż możliwe jest przetworzenie obrazu w celu uzyskania dokładnego kodu PIN, takie wstępne przetwarzanie będzie niespójne do czasu, gdy zostanie użyty inny obraz o innym charakterze.
Najlepszy wyprodukowany wynik
Poniższy obraz przedstawia najlepsze wyniki eksperymentów.
Test nr 5

Teksty na obrazie i te wyodrębnione są całkowicie takie same. Konwersja ma 100% dokładność. Próbowałem odtworzyć wynik, ale udało mi się go odtworzyć tylko przy użyciu obrazów o podobnym charakterze.
Obserwacje i lekcje
- Niektóre obrazy, które nie są wstępnie przetworzone, mogą dawać różne wyniki w różnych przeglądarkach . To twierdzenie jest widoczne w pierwszym teście. Wynik w Firefoksie różni się od tego w Chrome. Jednak wstępne przetwarzanie obrazów pomaga uzyskać spójny wynik w innych testach.
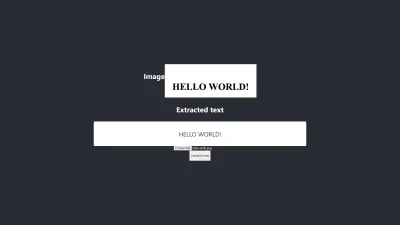
- Czarny kolor na białym tle daje łatwe do opanowania rezultaty. Poniższy obraz jest przykładem dokładnego wyniku bez wstępnego przetwarzania . Udało mi się również uzyskać ten sam poziom dokładności poprzez wstępne przetwarzanie obrazu, ale wymagało to wielu korekt, które były niepotrzebne.
Konwersja jest w 100% dokładna.
- Tekst o dużym rozmiarze czcionki jest zwykle dokładniejszy.
- Czcionki z zakrzywionymi krawędziami często mylą Tesseract. Najlepszy wynik osiągnąłem, używając Arial (czcionka).
- OCR nie jest obecnie wystarczająco dobry, aby zautomatyzować konwersję obrazu na tekst, zwłaszcza gdy wymagany jest poziom dokładności przekraczający 80%. Można go jednak użyć, aby ręczne przetwarzanie tekstów na obrazach było mniej stresujące , dzięki wyodrębnieniu tekstów do ręcznej korekty.
- OCR nie jest obecnie wystarczająco dobry, aby przekazywać przydatne informacje do czytników ekranu w celu ułatwienia dostępu . Dostarczanie niedokładnych informacji do czytnika ekranu może łatwo wprowadzić w błąd lub rozpraszać użytkowników.
- OCR jest bardzo obiecujący, ponieważ sieci neuronowe umożliwiają naukę i doskonalenie. Głębokie uczenie sprawi, że OCR zmieni zasady gry w niedalekiej przyszłości .
- Pewne podejmowanie decyzji. Ocena zaufania może służyć do podejmowania decyzji, które mogą mieć duży wpływ na nasze aplikacje. Wynik ufności może być wykorzystany do określenia, czy zaakceptować lub odrzucić wynik. Z mojego doświadczenia i eksperymentu zdałem sobie sprawę, że jakikolwiek wynik zaufania poniżej 90 nie jest tak naprawdę przydatny. Jeśli potrzebuję tylko wyodrębnić kilka pinezek z tekstu, spodziewam się, że wynik zaufania wynosi od 75 do 100, a wszystko poniżej 75 zostanie odrzucone .
W przypadku, gdy mam do czynienia z tekstami bez potrzeby wyodrębniania jakiejkolwiek ich części, na pewno zaakceptuję ocenę zaufania od 90 do 100, ale odrzucę każdy wynik poniżej tego. Na przykład oczekiwana jest dokładność 90 i więcej, jeśli chcę zdigitalizować dokumenty, takie jak czeki, historyczny projekt lub zawsze, gdy potrzebna jest dokładna kopia. Ale wynik od 75 do 90 jest akceptowalny, gdy dokładna kopia nie jest ważna, na przykład uzyskanie kodu PIN z karty podarunkowej. Krótko mówiąc, ocena zaufania pomaga w podejmowaniu decyzji , które mają wpływ na nasze aplikacje.
Wniosek
Biorąc pod uwagę ograniczenia przetwarzania danych spowodowane tekstami na obrazach i związane z tym wady, optyczne rozpoznawanie znaków (OCR) jest przydatną technologią do przyjęcia. Chociaż OCR ma swoje ograniczenia, jest bardzo obiecujący ze względu na wykorzystanie sieci neuronowych.
Z biegiem czasu OCR pokona większość swoich ograniczeń za pomocą głębokiego uczenia się, ale wcześniej podejścia przedstawione w tym artykule można wykorzystać do radzenia sobie z wyodrębnianiem tekstu z obrazów, przynajmniej w celu zmniejszenia trudności i strat związanych z ręcznym przetwarzanie — zwłaszcza z biznesowego punktu widzenia.
Teraz Twoja kolej, aby wypróbować OCR, aby wyodrębnić teksty z obrazów. Powodzenia!
Dalsza lektura
- P5.js
- Wstępne przetwarzanie w OCR
- Poprawa jakości produkcji
- Używanie JavaScript do wstępnego przetwarzania obrazów dla OCR
- OCR w przeglądarce z Tesseract.js
- Krótka historia optycznego rozpoznawania znaków
- Przyszłość OCR to głębokie uczenie
- Oś czasu optycznego rozpoznawania znaków