
Klasyfikacja obrazów w CNN: wszystko, co musisz wiedzieć
Opublikowany: 2021-02-25Spis treści
Wstęp
Czy podczas przeglądania kanału na Facebooku zastanawiałeś się kiedyś, w jaki sposób ludzie na zdjęciu grupowym są automatycznie oznaczani przez oprogramowanie Facebooka? Za każdym interaktywnym interfejsem użytkownika Facebooka, który widzisz, kryje się złożony i silny algorytm, który służy do rozpoznawania i oznaczania każdego zdjęcia przesłanego przez nas na platformę mediów społecznościowych. Z każdym naszym zdjęciem pomagamy tylko w poprawie wydajności algorytmu. Tak, klasyfikacja obrazów jest jednym z najczęściej używanych algorytmów, w którym widzimy zastosowanie sztucznej inteligencji.
W ostatnim czasie Convolutional Neural Networks (CNN) stał się jednym z najsilniejszych orędowników Deep Learning. Jednym z popularnych zastosowań tych sieci splotowych jest klasyfikacja obrazów. W tym samouczku omówimy podstawy splotowych sieci neuronowych, zobaczymy różne warstwy zaangażowane w budowanie modelu CNN i na koniec zwizualizujemy przykład zadania klasyfikacji obrazów.
Klasyfikacja obrazu
Zanim przejdziemy do szczegółów głębokiego uczenia i splotowych sieci neuronowych, zapoznajmy się z podstawami klasyfikacji obrazów. Ogólnie rzecz biorąc, klasyfikacja obrazu jest definiowana jako zadanie, w którym podajemy obraz jako dane wejściowe do modelu zbudowanego przy użyciu określonego algorytmu, który wyprowadza klasę lub prawdopodobieństwo klasy, do której należy obraz. Ten proces, w którym przypisujemy obraz do konkretnej klasy, nazywa się uczeniem nadzorowanym.
Istnieje ogromna różnica między tym, jak widzimy obraz, a tym, jak maszyna (komputer) widzi ten sam obraz. Dla nas jesteśmy w stanie zwizualizować obraz i scharakteryzować go na podstawie koloru i rozmiaru. Z drugiej strony maszyna widzi tylko liczby. Widoczne liczby to piksele.
Każdy piksel ma wartość od 0 do 255. W związku z tym przy tych danych liczbowych maszyna wymaga pewnych etapów wstępnego przetwarzania w celu uzyskania określonych wzorów lub cech, które odróżniają jeden obraz od drugiego. Splotowe sieci neuronowe pomagają nam budować algorytmy, które są w stanie wyprowadzić określony wzór z obrazów.
To, co widzimy, a to, co widzi komputer
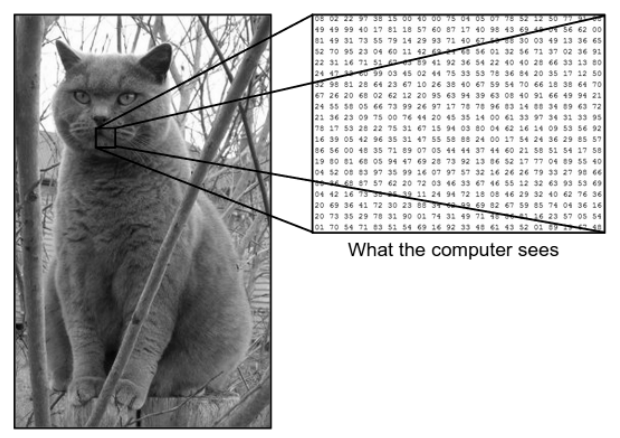 Źródło – różnica między komputerem a ludzkim okiem
Źródło – różnica między komputerem a ludzkim okiem

Głębokie uczenie do klasyfikacji obrazów
Teraz, gdy zrozumieliśmy, czym jest klasyfikacja obrazów, zobaczmy teraz, jak możemy ją wdrożyć za pomocą sztucznej inteligencji. W tym celu wykorzystujemy popularne metody Deep Learning. Głębokie uczenie to podzbiór sztucznej inteligencji, który wykorzystuje duże zestawy danych obrazu do rozpoznawania i wyprowadzania wzorców z różnych obrazów w celu rozróżnienia różnych klas obecnych w zestawie danych obrazu.
Głównym wyzwaniem, przed którym stoi Deep Learning, jest to, że w przypadku ogromnej bazy danych zajmuje to bardzo dużo czasu i wiąże się z wysokimi kosztami obliczeniowymi. Jednak splotowe sieci neuronowe, które są rodzajem algorytmu Deep Learning, dobrze rozwiązują ten problem.
Konwolucyjne sieci neuronowe
W uczeniu głębokim, splotowe sieci neuronowe są klasą głębokich sieci neuronowych, które są najczęściej używane w obrazowaniu wizualnym. Stanowią specjalną architekturę sztucznych sieci neuronowych (ANN), zaproponowaną w 1998 roku przez Yanna LeCunna. Splotowe sieci neuronowe składają się z dwóch części.
Pierwsza część składa się z warstw splotowych i warstw zbiorczych, w których odbywa się główny proces ekstrakcji cech. W drugiej części warstwy Fully Connected i Dense wykonują kilka nieliniowych przekształceń na wyodrębnionych elementach i działają jako część klasyfikatora. Dowiedz się CNN do klasyfikacji obrazów.
Rozważ powyższy przykład obrazu przedstawiający to, co widzi człowiek i maszyna. Jak widzimy, komputer widzi szereg pikseli. Na przykład, jeśli rozmiar obrazu to 500×500, to rozmiar tablicy będzie wynosił 500x500x3. Tutaj 500 oznacza każdą wysokość i szerokość, 3 oznacza kanał RGB, w którym każdy kanał koloru jest reprezentowany przez oddzielną tablicę. Intensywność pikseli waha się od 0 do 255.
Teraz w przypadku klasyfikacji obrazów komputer będzie szukał funkcji na poziomie podstawowym. Według nas, ludzi, tymi podstawowymi cechami kota są uszy, nos i wąsy. W przypadku komputera te podstawowe funkcje to krzywizny i granice. W ten sposób, korzystając z kilku różnych warstw, takich jak warstwy splotowe i warstwy zbiorcze, komputer wyodrębnia z obrazów elementy z poziomu podstawowego.
W modelu Convolutional Neural Network istnieje kilka rodzajów warstw, takich jak:
- Warstwa wejściowa
- Warstwa splotowa
- Warstwa puli
- W pełni połączona warstwa
- Warstwa wyjściowa
- Funkcje aktywacji
Przeanalizujmy pokrótce każdą z warstw, zanim przejdziemy do jej zastosowania w klasyfikacji obrazów.
Warstwa wejściowa
Z nazwy rozumiemy, że jest to warstwa, w której obraz wejściowy zostanie wprowadzony do modelu CNN. W zależności od naszych wymagań możemy zmienić kształt obrazu do różnych rozmiarów, takich jak (28,28,3)
Warstwa splotowa
Następnie pojawia się najważniejsza warstwa, która składa się z filtra (zwanego również jądrem) o ustalonym rozmiarze. Operacja matematyczna Convolution odbywa się między obrazem wejściowym a filtrem. Jest to etap, w którym większość podstawowych cech, takich jak ostre krawędzie i krzywe, jest wyodrębnianych z obrazu, dlatego ta warstwa jest również znana jako warstwa ekstrakcji cech.
Warstwa puli
Po wykonaniu operacji convolution wykonujemy operację Pooling. Jest to również znane jako próbkowanie w dół, gdzie objętość przestrzenna obrazu jest zmniejszona. Na przykład, jeśli wykonamy operację łączenia z krokiem 2 na obrazie o wymiarach 28×28, to rozmiar obrazu zmniejszony do 14×14, zostanie zmniejszony do połowy swojego oryginalnego rozmiaru.
W pełni połączona warstwa
Warstwa w pełni połączona (FC) jest umieszczana tuż przed końcowym wynikiem klasyfikacji modelu CNN. Warstwy te służą do spłaszczania wyników przed klasyfikacją. Obejmuje kilka błędów systematycznych, wag i neuronów. Dołączenie warstwy FC przed klasyfikacją daje N-wymiarowy wektor, gdzie N jest liczbą klas, z których model musi wybrać klasę.
Warstwa wyjściowa
Wreszcie warstwa wyjściowa składa się z etykiety, która jest w większości zakodowana przy użyciu metody kodowania one-hot.
Funkcja aktywacji
Te funkcje aktywacji stanowią rdzeń każdego modelu splotowej sieci neuronowej. Funkcje te służą do określania wyjścia sieci neuronowej. Krótko mówiąc, określa, czy dany neuron powinien być aktywowany („odpalony”), czy nie. Są to zwykle funkcje nieliniowe, które są wykonywane na sygnałach wejściowych. Ten przekształcony wynik jest następnie wysyłany jako dane wejściowe do następnej warstwy neuronów. Istnieje kilka funkcji aktywacji, takich jak Sigmoid, ReLU, Leaky ReLU, TanH i Softmax.
Podstawowa architektura CNN
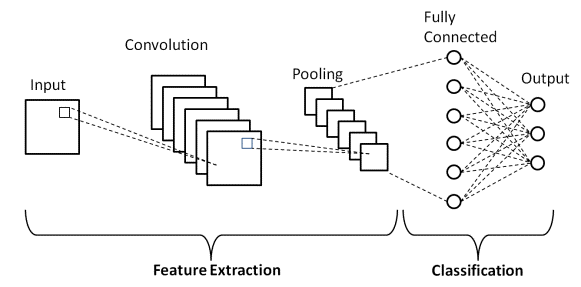
Źródło : podstawowa architektura CNN
Jak zdefiniowano wcześniej, powyższy diagram jest podstawową architekturą modelu Convolutional Neural Network. Teraz, gdy jesteśmy już gotowi z podstawami klasyfikacji obrazów i CNN, przejdźmy teraz do jej zastosowania z problemem czasu rzeczywistego. Dowiedz się więcej o podstawowej architekturze CNN.
Implementacja splotowych sieci neuronowych
Teraz, gdy zrozumieliśmy podstawy klasyfikacji obrazów i splotowych sieci neuronowych, zwizualizujmy jej implementację w TensorFlow/Keras z kodowaniem w Pythonie. W tym celu zbudujemy prosty model konwolucyjnej sieci neuronowej z podstawową architekturą LeNet, wytrenujemy model na zbiorze uczącym i zbiorze testowym, a na koniec uzyskamy dokładność modelu na danych zbioru testowego.
Zestaw problemów
W tym artykule do budowania i trenowania modelu konwolucyjnej sieci neuronowej będziemy używać słynnego zbioru danych Fashion MNIST. MNIST to skrót od Modified National Institute of Standards and Technology. Fashion-MNIST to zbiór danych obrazów artykułów Zalando — składający się z zestawu treningowego 60 000 przykładów i zestawu testowego 10 000 przykładów. Każdy przykład to obraz w skali szarości 28×28, powiązany z etykietą z 10 klas.

Każdy przykład szkolenia i testu jest przypisany do jednej z następujących etykiet:
0 – T-shirt/top
1 – Spodnie
2 – Sweter
3 – Sukienka
4 – Płaszcz
5 – Sandał
6 – Koszula
7 – Trampki
8 – Torba
9 – Botki
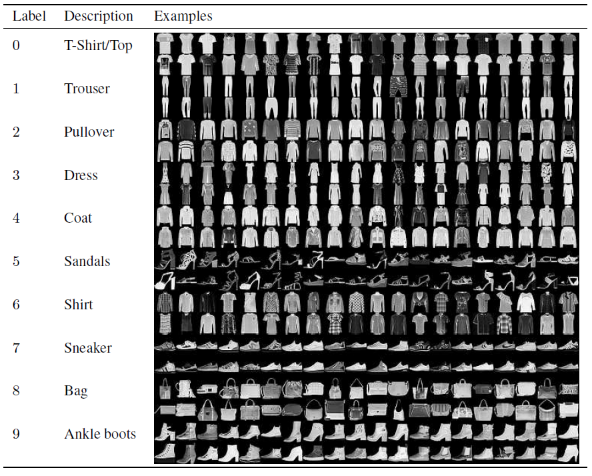
Źródło : Fashion MNIST Dataset Images
Kod programu
Krok 1 – Importowanie bibliotek
Pierwszym krokiem do zbudowania dowolnego modelu Deep Learning jest zaimportowanie bibliotek niezbędnych dla programu. W naszym przykładzie, ponieważ używamy frameworka TensorFlow, zaimportujemy bibliotekę Keras, a także inne ważne biblioteki, takie jak number do obliczeń i matplotlib do wykreślania wykresów.
#TensorFlow – Importowanie bibliotek
importuj numer jako np
importuj matplotlib.pyplot jako plt
%matplotlib wbudowany
importuj tensorflow jako tf
z importu tensorflow Keras
Krok 2 – Pobieranie i dzielenie zbioru danych
Po zaimportowaniu bibliotek następnym krokiem jest pobranie zestawu danych i podzielenie zestawu danych Fashion MNIST na odpowiednie 60 000 danych treningowych i 10 000 danych testowych. Na szczęście Keras udostępnia nam predefiniowaną funkcję do importowania zestawu danych Fashion MNIST i możemy podzielić je w następnym wierszu za pomocą prostego wiersza kodu, który jest zrozumiały dla siebie.
#TensorFlow – Pobieranie i dzielenie zbioru danych
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
Krok 3 – Wizualizacja danych
Ponieważ zestaw danych jest pobierany wraz z obrazami i odpowiadającymi im etykietami, aby był bardziej zrozumiały dla użytkownika, zawsze zaleca się przeglądanie danych, abyśmy mogli zrozumieć typ danych, z którymi mamy do czynienia podczas budowania neuronu splotowego Model sieci odpowiednio. Tutaj, za pomocą tego prostego bloku kodu podanego poniżej, zwizualizujemy pierwsze 3 obrazy zestawu danych treningowych, który jest losowo mieszany.
#TensorFlow – Wizualizacja danych
def imshowTensorFlow(img):
plt.imshow(img, cmap='szary')
print("Etykieta:", img[0])
imshowTensorFlow(train_images_tf[0])
Etykieta: 9 Etykieta: 0 Etykieta: 3


Powyższe zdjęcie i ich etykiety można zweryfikować za pomocą etykiet, które są podane w szczegółach zestawu danych Fashion MNIST powyżej. Z tego wnioskujemy, że nasz obraz danych jest obrazem w skali szarości o wysokości 28 pikseli i szerokości 28 pikseli.
W związku z tym model można zbudować z rozmiarem wejściowym (28,28,1), gdzie 1 oznacza obraz w skali szarości.
Krok 4 – Budowanie modelu
Jak wspomniano powyżej, w tym artykule będziemy budować prostą Convolutional Neural Network z architekturą LeNet. LeNet to splotowa struktura sieci neuronowej zaproponowana przez Yanna LeCuna i in. w 1989 roku. Ogólnie rzecz biorąc, LeNet odnosi się do LeNet-5 i jest prostą Konwolucyjną siecią neuronową.
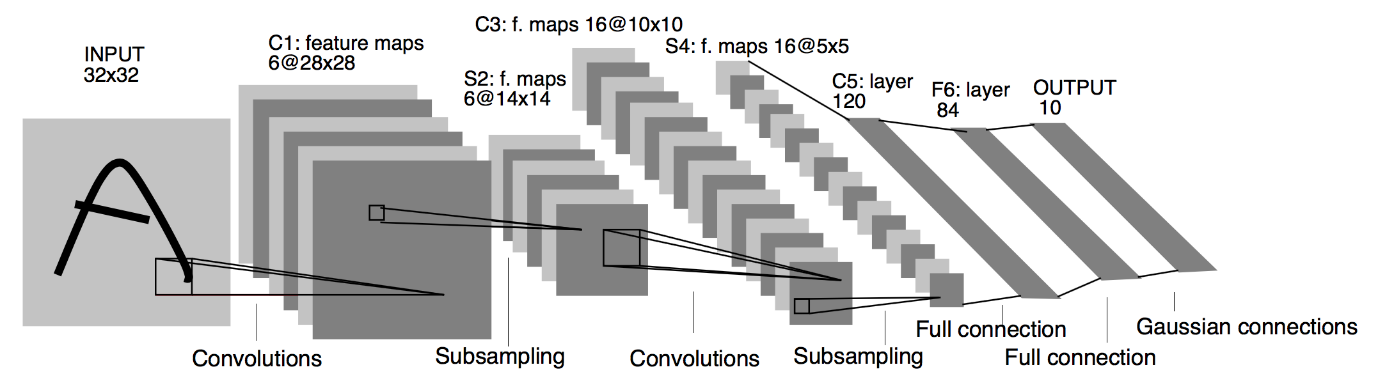
Źródło : Architektura LeNet
Z powyższego diagramu architektury modelu LeNet CNN widzimy, że istnieje 5+2 warstw. Pierwsza i druga warstwa to warstwa konwolucyjna, po której następuje warstwa zbiorcza. Ponownie, trzecia i czwarta warstwa składają się z warstwy splotowej i warstwy zbiorczej. W wyniku tych operacji rozmiar obrazu wejściowego z 28×28 zmniejsza się do 7×7.
Piąta warstwa modelu LeNet to warstwa w pełni połączona, która spłaszcza wyniki poprzedniej warstwy. Po dwóch warstwach Dense, ostateczna warstwa wyjściowa modelu CNN składa się z funkcji aktywacji Softmax z 10 jednostkami. Funkcja Softmax przewiduje prawdopodobieństwo klasy dla każdej z 10 klas zestawu danych Fashion MNIST.
#TensorFlow – Budowanie modelu
model = keras.Sekwencyjny([
keras.layers.Conv2D(input_shape=(28,28,1), filters=6, kernel_size=5, strides=1, padding=”same”, aktywacja=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, kroki=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, padding=”same”, aktywacja=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, kroki=2),
keras.warstwy.Flatten(),
keras.layers.Dense(120, aktywacja=tf.nn.relu),
keras.layers.Dense(84, aktywacja=tf.nn.relu),
keras.layers.Dense(10, aktywacja=tf.nn.softmax)
])
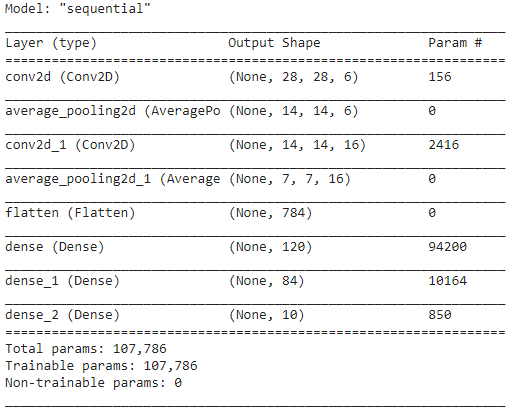
Krok 5 – Podsumowanie modelu
Po sfinalizowaniu warstw modelu LeNet możemy przystąpić do kompilacji modelu i obejrzenia podsumowanej wersji zaprojektowanego modelu CNN.
#TensorFlow – Podsumowanie modelu
model.compile(loss=keras.losses.categorical_crossentropy,
optymalizator='adam',
metryki=['acc'])
model.podsumowanie()
W tym przypadku, ponieważ końcowy wynik ma więcej niż 2 klasy (10 klas), używamy kategorycznej entropii krzyżowej jako funkcji straty i Adama Optimizera do zbudowanego modelu. Podsumowanie modelu podano poniżej.
Krok 6 – Trening modelki
Wreszcie dochodzimy do części, w której rozpoczynamy proces uczenia modelu LeNet CNN. Po pierwsze, przekształcamy uczący zbiór danych i normalizujemy go do mniejszych wartości, dzieląc przez 255,0 w celu zmniejszenia kosztów obliczeniowych. Następnie etykiety szkoleniowe są konwertowane z wektora klasy liczb całkowitych na binarną macierz klas. Na przykład etykieta 3 jest konwertowana na [0, 0, 0, 1, 0, 0, 0, 0, 0]
#TensorFlow – Trening modelki
train_images_tensorflow = (train_images_tf / 255.0).reshape(train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
Pod koniec treningu po 30 epokach uzyskujemy ostateczną dokładność i stratę treningu jako,
Epoka 30/30
1875/1875 [==============================] – 4s 2ms/krok – strata: 0,0421 – wg: 0,9850
Dokładność szkolenia: 98.294997215271 %
Utrata szkolenia: 0.04584110900759697
Krok 7 – Przewidywanie wyników
Wreszcie, gdy zakończymy proces uczenia modelu CNN, dopasujemy ten sam model do zestawu danych testowych i przewidzimy dokładność 10 000 obrazów testowych.
#TensorFlow – porównywanie wyników
prognozy = model.predict(test_images_tensorflow)
poprawny = 0
for i, pred in enumerate(prognozy):
if np.argmax(pred) == test_labels_tf[i]:
poprawnie += 1
print('Dokładność testu modelu na {} obrazach testowych: {}% z TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0]))
Wynik, który otrzymujemy, to:
Dokładność testu modelu na 10000 obrazach testowych: 90,67% z TensorFlow
Na tym kończymy program budowania Modelu Klasyfikacji Obrazów za pomocą Konwolucyjnych Sieci Neuronowych.
Przeczytaj także: Pomysły na projekty uczenia maszynowego
Wniosek
Dlatego w tym samouczku dotyczącym wdrażania klasyfikacji obrazów w CNN zrozumieliśmy podstawowe pojęcia związane z klasyfikacją obrazów, splotowymi sieciami neuronowymi wraz z ich implementacją w języku programowania Python za pomocą frameworka TensorFlow.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom IIIT-B i upGrad's PG Diploma in Machine Learning & AI, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, IIIT- Status absolwenta B, ponad 5 praktycznych, praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Który model CNN jest uważany za najbardziej optymalny do klasyfikacji obrazów?
Najlepszym modelem CNN do klasyfikacji obrazów jest VGG-16, co oznacza Very Deep Convolutional Networks for Large-Scale Image Recognition. VGG, który został zaprojektowany jako głęboki CNN, przewyższa wartości bazowe w szerokim zakresie zadań i zestawów danych poza ImageNet. Cechą wyróżniającą model jest to, że podczas jego tworzenia więcej uwagi poświęcono wprowadzeniu doskonałych warstw splotu, niż skupieniu się na dodawaniu dużej liczby hiperparametrów. Ma w sumie 16 warstw, 5 bloków, a każdy blok ma maksymalną warstwę puli, co czyni go dość dużą siecią.
Jakie są wady używania modeli CNN do klasyfikacji obrazów?
Jeśli chodzi o klasyfikację obrazów, modele CNN odnoszą duży sukces. Istnieje jednak kilka wad korzystania z CNN. Jeśli obraz, który ma zostać zidentyfikowany, jest pochylony lub obrócony, model CNN ma problemy z dokładną identyfikacją obrazu. Gdy CNN wizualizuje obrazy, nie ma wewnętrznych reprezentacji komponentów i ich połączeń część-całość. Co więcej, jeśli stosowany model CNN obejmuje wiele warstw splotowych, proces klasyfikacji zajmie dużo czasu.
Dlaczego w przypadku danych obrazu jako danych wejściowych preferuje się stosowanie modelu CNN niż ANN?
Łącząc filtry lub przekształcenia, CNN może nauczyć się wielu warstw reprezentacji cech dla każdego obrazu dostarczonego jako dane wejściowe. Overfitting jest zmniejszony, ponieważ liczba parametrów sieci do uczenia się w CNN jest znacznie mniejsza niż w wielowarstwowych sieciach neuronowych. Podczas korzystania z SSN sieci neuronowe mogą uczyć się reprezentacji pojedynczej cechy obrazu, ale w przypadku złożonych obrazów SNN nie zapewni lepszych wizualizacji ani klasyfikacji, ponieważ nie może nauczyć się zależności pikseli istniejących w obrazach wejściowych.