
HTTP/3: Praktyczne opcje wdrażania (część 3)
Opublikowany: 2022-03-10Witam i witam w ostatniej części tej trzyczęściowej serii poświęconej nowym protokołom HTTP/3 i QUIC! Jeśli po poprzednich dwóch częściach — historii HTTP/3 i podstawowych koncepcjach oraz funkcjach wydajności HTTP/3 — jesteś przekonany, że rozpoczęcie korzystania z nowych protokołów jest dobrym pomysłem (a powinieneś!), to ten ostatni fragment zawiera wszystkie musisz wiedzieć, aby zacząć!
Najpierw omówimy, jakie zmiany należy wprowadzić na swoich stronach i zasobach, aby optymalnie korzystać z nowych protokołów (to najłatwiejsza część). Następnie przyjrzymy się, jak skonfigurować serwery i klientów (jest to trudna część, chyba że korzystasz z sieci dostarczania treści (CDN)). Na koniec zobaczymy, jakich narzędzi możesz użyć do oceny wpływu nowych protokołów na wydajność (jest to prawie niemożliwa część, przynajmniej na razie).
- Część 1: Historia HTTP/3 i podstawowe koncepcje
Ten artykuł jest skierowany do osób, które nie znają protokołu HTTP/3 i protokołów w ogóle, i omawia głównie podstawy. - Część 2: Funkcje wydajności HTTP/3
Ten jest bardziej dogłębny i techniczny. Tutaj mogą zacząć osoby, które już znają podstawy. - Część 3: Praktyczne opcje wdrażania HTTP/3
Ten trzeci artykuł z serii wyjaśnia wyzwania związane z samodzielnym wdrażaniem i testowaniem HTTP/3. Opisuje również, jak i czy powinieneś zmienić swoje strony internetowe i zasoby.
Zmiany na stronach i zasobach
Zacznijmy od dobrych wiadomości: jeśli korzystasz już z HTTP/2, prawdopodobnie nie będziesz musiał niczego zmieniać na swoich stronach lub zasobach po przejściu na HTTP/3! . Dzieje się tak, ponieważ, jak wyjaśniliśmy w części 1 i 2, HTTP/3 jest bardziej podobny do HTTP/2-over-QUIC, a funkcje wysokiego poziomu obu wersji pozostały takie same. W związku z tym wszelkie zmiany lub optymalizacje wprowadzone dla HTTP/2 będą nadal działać dla HTTP/3 i na odwrót.
Jeśli jednak nadal korzystasz z HTTP/1.1 lub zapomniałeś o przejściu na HTTP/2 lub nigdy nie zmieniałeś rzeczy dla HTTP/2, możesz się zastanawiać, jakie były te zmiany i dlaczego były potrzebne. Jednak nawet dzisiaj trudno byłoby znaleźć dobry artykuł, który zawierałby szczegółowe informacje o najlepszych praktykach. Dzieje się tak, ponieważ, jak wspomniałem we wstępie do części 1, większość wczesnych treści HTTP/2 była zbyt optymistycznie nastawiona do tego, jak dobrze będzie działać w praktyce, a niektóre z nich, szczerze mówiąc, zawierały poważne błędy i złe rady. Niestety, wiele z tych dezinformacji przetrwało do dziś. To jedna z moich głównych motywacji do pisania tej serii na HTTP/3, aby zapobiec powtórzeniu się tego.
Najlepszym wszechstronnym źródłem niuansów HTTP/2, jakie mogę w tej chwili polecić, jest książka Barry Pollarda HTTP/2 w działaniu . Jednak ponieważ jest to płatny zasób i nie chcę, abyś zgadywał tutaj, wymieniłem kilka głównych punktów poniżej, wraz z ich związkiem z HTTP/3:
1. Pojedyncze połączenie
Największą różnicą między HTTP/1.1 i HTTP/2 było przełączenie z 6 do 30 równoległych połączeń TCP na jedno podstawowe połączenie TCP. Omówiliśmy nieco w części 2, w jaki sposób pojedyncze połączenie może nadal być tak szybkie, jak wiele połączeń, ponieważ kontrola przeciążenia może powodować większą lub wcześniejszą utratę pakietów przy większej liczbie połączeń (co niweczy korzyści ich zagregowanego szybszego startu). HTTP/3 kontynuuje to podejście, ale „tylko” przełącza się z jednego TCP na jedno połączenie QUIC. Ta różnica sama w sobie nie robi zbyt wiele (głównie zmniejsza obciążenie po stronie serwera), ale prowadzi do większości poniższych punktów.
2. Dzielenie serwerów na fragmenty i łączenie połączeń
Przejście na konfigurację pojedynczego połączenia było dość trudne w praktyce, ponieważ wiele stron zostało podzielonych na różne nazwy hostów, a nawet serwery (takie jak img1.example.com i img2.example.com ). Wynikało to z faktu, że przeglądarki otwierały tylko do sześciu połączeń dla każdej indywidualnej nazwy hosta, więc wielokrotne pozwalały na więcej połączeń! Bez zmian w tej konfiguracji HTTP/1.1 protokół HTTP/2 nadal otwierałby wiele połączeń, zmniejszając skuteczność innych funkcji, takich jak ustalanie priorytetów (patrz poniżej).
W związku z tym pierwotnym zaleceniem było cofnięcie shardingu serwera i jak największa konsolidacja zasobów na jednym serwerze. HTTP/2 zapewniał nawet funkcję ułatwiającą przejście z konfiguracji HTTP/1.1, zwaną łączeniem połączeń. Z grubsza mówiąc, jeśli dwie nazwy hostów prowadzą do tego samego adresu IP serwera (przy użyciu DNS) i używają podobnego certyfikatu TLS, przeglądarka może ponownie użyć jednego połączenia, nawet w przypadku dwóch nazw hostów .
W praktyce łączenie połączeń może być trudne do uzyskania, np. z powodu kilku subtelnych problemów z bezpieczeństwem związanych z CORS. Nawet jeśli skonfigurujesz go prawidłowo, nadal możesz łatwo skończyć z dwoma oddzielnymi połączeniami. Chodzi o to, że nie zawsze jest źle . Po pierwsze, ze względu na źle zaimplementowane ustalanie priorytetów i multipleksowanie (patrz poniżej), pojedyncze połączenie może z łatwością być wolniejsze niż korzystanie z dwóch lub więcej. Po drugie, używanie zbyt wielu połączeń może spowodować wczesną utratę pakietów z powodu konkurencyjnych kontrolerów przeciążenia. Użycie tylko kilku (ale wciąż więcej niż jednego) może jednak ładnie zrównoważyć wzrost przeciążenia z lepszą wydajnością, szczególnie w szybkich sieciach. Z tych powodów uważam, że odrobina shardingu jest nadal dobrym pomysłem (powiedzmy, dwa do czterech połączeń), nawet przy HTTP/2. W rzeczywistości myślę, że większość nowoczesnych konfiguratorów HTTP/2 działa tak samo dobrze, jak one, ponieważ wciąż mają kilka dodatkowych połączeń lub obciążenia stron trzecich na swojej krytycznej ścieżce.
3. Łączenie zasobów i inlining
W HTTP/1.1 możesz mieć tylko jeden aktywny zasób na połączenie, co prowadzi do blokowania nagłówka wiersza (HoL) na poziomie HTTP. Ponieważ liczba połączeń była ograniczona do nędznych 6 do 30, łączenie zasobów (gdzie mniejsze podzasoby są łączone w jeden większy zasób) było od dawna najlepszą praktyką. Nadal widzimy to dzisiaj w pakietach, takich jak Webpack. Podobnie zasoby były często umieszczane w innych zasobach (na przykład krytyczny CSS był wbudowany w HTML).
Jednak w przypadku HTTP/2 pojedyncze połączenie multipleksuje zasoby, dzięki czemu możesz mieć o wiele więcej zaległych żądań plików (innymi słowy, pojedyncze żądanie nie zajmuje już jednego z kilku cennych połączeń). Pierwotnie interpretowano to jako „ Nie musimy już łączyć naszych zasobów w pakiety ani dołączać do nich zasobów HTTP/2 ”. To podejście było reklamowane jako lepsze dla szczegółowego buforowania, ponieważ każdy podzasób mógł być buforowany indywidualnie, a pełny pakiet nie musiał być ponownie pobierany, jeśli jeden z nich uległ zmianie. To prawda, ale tylko w stosunkowo ograniczonym zakresie.
Na przykład możesz zmniejszyć wydajność kompresji, ponieważ działa to lepiej przy większej ilości danych. Ponadto każde dodatkowe żądanie lub plik wiąże się z nieodłącznym obciążeniem, ponieważ musi je obsłużyć przeglądarka i serwer. Koszty te mogą sumować się do, powiedzmy, setek małych plików w porównaniu z kilkoma dużymi. W naszych wczesnych testach zauważyłem poważnie malejące zwroty przy około 40 plikach. Chociaż te liczby są teraz prawdopodobnie nieco wyższe, żądania plików nadal nie są tak tanie w HTTP/2, jak pierwotnie przewidywano . Wreszcie brak wstawiania zasobów wiąże się z dodatkowym kosztem opóźnienia, ponieważ należy zażądać pliku. To, w połączeniu z problemami z ustalaniem priorytetów i wypychaniem serwerów (patrz poniżej), oznacza, że nawet dzisiaj lepiej jest wprowadzić niektóre krytyczne CSS. Może kiedyś propozycja Resource Bundles w tym pomoże, ale jeszcze nie teraz.
Wszystko to oczywiście dotyczy również HTTP/3. Mimo to, czytałem, że ludzie twierdzą, że wiele małych plików byłoby lepszych niż QUIC, ponieważ więcej równolegle aktywnych niezależnych strumieni oznacza większe zyski z usunięcia blokowania HoL (jak omówiliśmy w części 2). Myślę, że może być w tym trochę prawdy, ale jak widzieliśmy również w części 2, jest to bardzo złożony problem z wieloma ruchomymi parametrami. Nie sądzę, aby korzyści przewyższały inne omawiane koszty, ale potrzebne są dalsze badania. (Oburzającym pomysłem byłoby, aby każdy plik miał dokładnie taki rozmiar, aby zmieścił się w pojedynczym pakiecie QUIC, całkowicie omijając blokowanie HoL. Zaakceptuję tantiemy od każdego startu, który implementuje pakiet zasobów, który to robi. ;))
4. Priorytetyzacja
Aby móc pobierać wiele plików na jednym połączeniu, musisz je jakoś zmultipleksować. Jak omówiono w części 2, w HTTP/2 to multipleksowanie jest sterowane za pomocą systemu nadawania priorytetów. Dlatego ważne jest, aby żądać jak największej liczby zasobów również na tym samym połączeniu — aby móc właściwie ustalić priorytety między sobą! Jak jednak widzieliśmy, system ten był bardzo złożony , przez co często był źle wykorzystywany i wdrażany w praktyce (patrz obrazek poniżej). To z kolei oznaczało, że niektóre inne zalecenia dotyczące protokołu HTTP/2 — takie jak ograniczone łączenie w pakiety, ponieważ żądania są tanie i zmniejszone sharding serwera w celu optymalnego wykorzystania pojedynczego połączenia (patrz wyżej) — okazały się słabsze w ćwiczyć.
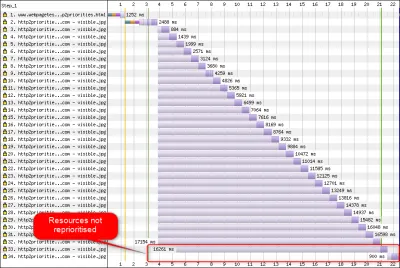
Niestety jest to coś, z czym Ty, jako przeciętny programista WWW, nie możesz wiele zrobić, ponieważ jest to głównie problem w samych przeglądarkach i serwerach. Możesz jednak spróbować złagodzić ten problem, nie używając zbyt wielu pojedynczych plików (co zmniejszy szanse na konkurencyjne priorytety) i nadal używając (ograniczonego) shardingu. Inną opcją jest użycie różnych technik wpływania na priorytety, takich jak ładowanie z opóźnieniem, async i defer JavaScript oraz wskazówki dotyczące zasobów, takie jak preload . Wewnętrznie zmieniają one głównie priorytety zasobów, tak aby zostały wysłane wcześniej lub później. Jednak te mechanizmy mogą (i cierpią) cierpieć z powodu błędów. Ponadto nie oczekuj, że uderzysz w preload wielu zasobów i przyspieszysz działanie: jeśli nagle wszystko ma wysoki priorytet, to nic nie jest! Nawet bardzo łatwo można opóźnić faktycznie krytyczne zasoby, używając takich rzeczy jak preload .
Jak wyjaśniono również w części 2, HTTP/3 zasadniczo zmienia wewnętrzne elementy tego systemu nadawania priorytetów. Mamy nadzieję , że dzięki temu będzie znacznie mniej błędów i problemów z jego praktycznym wdrożeniem, więc przynajmniej część z nich powinna zostać rozwiązana. Na razie jednak nie możemy być pewni, ponieważ niewiele serwerów i klientów HTTP/3 w pełni dziś implementuje ten system. Niemniej jednak podstawowe koncepcje ustalania priorytetów nie ulegną zmianie . Nadal nie będziesz w stanie korzystać z technik, takich jak preload , bez rzeczywistego zrozumienia, co dzieje się wewnętrznie, ponieważ nadal może to powodować niewłaściwe ustalanie priorytetów zasobów.
5. Push serwera i pierwszy lot
Serwer push umożliwia serwerowi wysyłanie danych odpowiedzi bez uprzedniego oczekiwania na żądanie od klienta. Ponownie, brzmi to świetnie w teorii i może być używane zamiast inline zasobów (patrz powyżej). Jednak, jak omówiono w części 2, wypychanie jest bardzo trudne do prawidłowego użycia ze względu na problemy z kontrolą przeciążenia, buforowaniem, ustalaniem priorytetów i buforowaniem. Ogólnie rzecz biorąc, najlepiej nie używać go do ogólnego ładowania stron internetowych , chyba że naprawdę wiesz, co robisz, a nawet wtedy prawdopodobnie byłaby to mikrooptymalizacja. Nadal wierzę, że może mieć miejsce z interfejsami API (REST), w których można przesyłać podzasoby połączone z odpowiedzią (JSON) w rozgrzanym połączeniu. Dotyczy to zarówno HTTP/2, jak i HTTP/3.
Aby nieco uogólnić, uważam, że podobne uwagi można poczynić w przypadku wznowienia sesji TLS i 0-RTT, czy to przez TCP + TLS, czy przez QUIC. Jak omówiono w części 2, 0-RTT jest podobne do serwera push (jak jest zwykle używane), ponieważ próbuje przyspieszyć pierwsze etapy ładowania strony. Oznacza to jednak, że jest on równie ograniczony w tym, co może osiągnąć w tym czasie (tym bardziej w QUIC, ze względu na obawy dotyczące bezpieczeństwa). W związku z tym mikrooptymalizacja to znowu sposób, w jaki prawdopodobnie musisz dostroić rzeczy na niskim poziomie, aby naprawdę z niej skorzystać. I pomyśleć, że kiedyś byłem bardzo podekscytowany wypróbowaniem połączenia serwera push z 0-RTT.
Co to wszystko znaczy?
Wszystko to sprowadza się do prostej zasady: zastosuj większość typowych rekomendacji HTTP/2, które można znaleźć w Internecie, ale nie przesadzaj .
Oto kilka konkretnych punktów, które dotyczą głównie zarówno HTTP/2, jak i HTTP/3:
- Podziel zasoby na około od jednego do trzech połączeń na ścieżce krytycznej (chyba że Twoi użytkownicy są głównie w sieciach o niskiej przepustowości), używając w razie potrzeby
preconnectidns-prefetch. - Grupuj zasoby podrzędne logicznie według ścieżki lub funkcji lub według częstotliwości zmian. Pięć do dziesięciu zasobów JavaScript i pięć do dziesięciu zasobów CSS na stronę powinno wystarczyć. Inline krytyczny CSS może nadal być dobrą optymalizacją.
- Oszczędnie używaj złożonych funkcji, takich jak
preload. - Użyj serwera, który prawidłowo obsługuje nadawanie priorytetów HTTP/2. W przypadku HTTP/2 polecam H2O. Apache i NGINX są w większości OK (chociaż mogłyby działać lepiej), podczas gdy Node.js należy unikać w przypadku HTTP/2. W przypadku HTTP/3 sprawy są obecnie mniej jasne (patrz poniżej).
- Upewnij się, że TLS 1.3 jest włączony na serwerze WWW HTTP/2.
Jak widać, optymalizacja stron pod kątem HTTP/3 (i HTTP/2), choć nie jest prosta, nie jest nauką rakietową. Trudniejsze będzie jednak prawidłowe skonfigurowanie serwerów, klientów i narzędzi HTTP/3.
Serwery i sieci
Jak już zapewne wiesz, QUIC i HTTP/3 to dość złożone protokoły. Wdrożenie ich od podstaw wymagałoby przeczytania (i zrozumienia!) setek stron rozłożonych na ponad siedem dokumentów. Na szczęście wiele firm od ponad pięciu lat pracuje nad implementacjami open-source QUIC i HTTP/3, więc mamy do wyboru kilka dojrzałych i stabilnych opcji.
Niektóre z najważniejszych i najbardziej stabilnych to:
| Język | Realizacja |
|---|---|
| Pyton | aioquic |
| Udać się | szybki dostęp |
| Rdza | quiche (Cloudflare), Quinn, Neqo (Mozilla) |
| C i C++ | mvfst (Facebook), MsQuic, (Microsoft), (Google), ngtcp2, LSQUIC (Litespeed), picoquic, quicly (Fastly) |
Jednak wiele (być może większość) tych implementacji zajmuje się głównie HTTP/3 i QUIC; same w sobie nie są pełnoprawnymi serwerami sieciowymi . Jeśli chodzi o typowe serwery (pomyśl NGINX, Apache, Node.js), z kilku powodów sytuacja przebiega nieco wolniej. Po pierwsze, niewielu ich programistów było związanych z HTTP/3 od samego początku, a teraz muszą nadrobić zaległości. Wielu omija to, używając jednej z wyżej wymienionych implementacji wewnętrznie jako bibliotek, ale nawet ta integracja jest trudna.
Po drugie, wiele serwerów zależy od bibliotek TLS innych firm, takich jak OpenSSL. Dzieje się tak, ponieważ TLS jest bardzo złożony i musi być bezpieczny, dlatego najlepiej jest ponownie wykorzystać istniejącą, zweryfikowaną pracę. Jednak chociaż QUIC integruje się z TLS 1.3, używa go w sposób znacznie odmienny od interakcji TLS i TCP . Oznacza to, że biblioteki TLS muszą zapewniać interfejsy API specyficzne dla QUIC, do czego ich programiści od dawna niechętnie lub powoli. Problemem jest zwłaszcza OpenSSL, który odłożył obsługę QUIC, ale jest również używany przez wiele serwerów. Ten problem stał się tak poważny, że Akamai zdecydował się uruchomić widelec OpenSSL przeznaczony dla QUIC, zwany quictls. Chociaż istnieją inne opcje i obejścia, obsługa TLS 1.3 dla QUIC nadal blokuje wiele serwerów i oczekuje się, że pozostanie tak przez jakiś czas.
Częściowa lista pełnych serwerów internetowych, z których powinieneś móc korzystać po wyjęciu z pudełka, wraz z ich aktualną obsługą HTTP/3, jest następująca:
- Apache
Wsparcie jest w tej chwili niejasne. Nic nie zostało ogłoszone. Prawdopodobnie potrzebuje również OpenSSL. (Pamiętaj, że istnieje implementacja Apache Traffic Server). - NGINX
To jest implementacja niestandardowa. Jest to stosunkowo nowe i nadal wysoce eksperymentalne. Oczekuje się, że zostanie on połączony z główną linią NGINX do końca 2021 r. Jest to stosunkowo nowe i nadal wysoce eksperymentalne. Zauważ, że istnieje łatka do uruchamiania biblioteki quiche Cloudflare również na NGINX, która prawdopodobnie jest na razie bardziej stabilna. - Node.js
Używa wewnętrznie biblioteki ngtcp2. Jest blokowany przez postęp OpenSSL, chociaż planują przejść na widelec QUIC-TLS, aby coś działało wcześniej. - IIS
Wsparcie jest w tej chwili niejasne i nic nie zostało ogłoszone. Jednak prawdopodobnie będzie używał biblioteki MsQuic wewnętrznie. - Hipercorn
To integruje aioquic z eksperymentalnym wsparciem. - Nosiciel kijów golfowych
Używa quic-go, z pełnym wsparciem. - H2O
To używa szybko, z pełnym wsparciem. - Litespeed
Używa LSQUIC, z pełnym wsparciem.
Zwróć uwagę na kilka ważnych niuansów:
- Nawet „pełne wsparcie” oznacza „tak dobre, jak jest w tej chwili”, niekoniecznie „gotowe do produkcji”. Na przykład wiele implementacji nie obsługuje jeszcze w pełni migracji połączeń, 0-RTT, push serwera lub nadawania priorytetów HTTP/3 .
- Inne niewymienione serwery, takie jak Tomcat, (o ile mi wiadomo) jeszcze nie ogłosiły.
- Spośród wymienionych serwerów internetowych tylko Litespeed, łatka NGINX Cloudflare i H2O zostały stworzone przez osoby ściśle zaangażowane w standaryzację QUIC i HTTP/3, więc najprawdopodobniej będą one działać najlepiej na wczesnym etapie.
Jak widać, krajobraz serwerów nie jest jeszcze w pełni dostępny, ale z pewnością istnieją już opcje konfiguracji serwera HTTP/3. Jednak samo uruchomienie serwera to dopiero pierwszy krok. Konfiguracja go i reszty sieci jest trudniejsza.
konfiguracja sieci
Jak wyjaśniono w części 1, QUIC działa na szczycie protokołu UDP, aby ułatwić jego wdrożenie. Oznacza to jednak przede wszystkim, że większość urządzeń sieciowych może analizować i rozumieć UDP. Niestety nie oznacza to, że UDP jest powszechnie dozwolony . Ponieważ protokół UDP jest często używany do ataków i nie jest krytyczny w codziennej pracy poza DNS, wiele (korporacyjnych) sieci i zapór sieciowych prawie całkowicie blokuje protokół. W związku z tym UDP prawdopodobnie musi być jawnie dopuszczony do/z serwerów HTTP/3 . QUIC może działać na dowolnym porcie UDP, ale spodziewaj się, że port 443 (który jest zwykle używany również dla HTTPS przez TCP) będzie najbardziej powszechny.
Jednak wielu administratorów sieci nie będzie chciało tylko zezwolić na sprzedaż hurtową UDP. Zamiast tego będą chcieli zezwolić na QUIC przez UDP. Problem polega na tym, że, jak widzieliśmy, QUIC jest prawie całkowicie zaszyfrowany. Obejmuje to metadane poziomu QUIC, takie jak numery pakietów, ale także np. sygnały wskazujące na zamknięcie połączenia. W przypadku protokołu TCP zapory aktywnie śledzą wszystkie te metadane, aby sprawdzić oczekiwane zachowanie. (Czy widzieliśmy pełne uzgadnianie przed pakietami przenoszącymi dane? Czy pakiety są zgodne z oczekiwanymi wzorcami? Ile jest otwartych połączeń?) Jak widzieliśmy w części 1, jest to dokładnie jeden z powodów, dla których TCP nie jest już praktycznie rozwijalny. Jednak ze względu na szyfrowanie QUIC zapory mogą wykonywać znacznie mniej logiki śledzenia na poziomie połączenia , a kilka bitów, które mogą sprawdzić, jest stosunkowo złożone.
W związku z tym wielu producentów zapór obecnie zaleca blokowanie QUIC do czasu, gdy będą mogli zaktualizować swoje oprogramowanie. Jednak nawet po tym wiele firm może nie chcieć na to zezwolić, ponieważ obsługa QUIC zapory zawsze będzie znacznie mniejsza niż funkcje TCP, do których są przyzwyczajeni.
Wszystko to komplikuje jeszcze bardziej funkcja migracji połączenia. Jak widzieliśmy, ta funkcja umożliwia kontynuację połączenia z nowego adresu IP bez konieczności wykonywania nowego uzgadniania, przy użyciu identyfikatorów połączeń (CID). Jednak w przypadku zapory będzie to wyglądać tak, jakby nowe połączenie było używane bez uprzedniego użycia uścisku dłoni, co może równie dobrze być atakiem wysyłającym złośliwy ruch. Zapory nie mogą po prostu korzystać z identyfikatorów QUIC CID, ponieważ zmieniają się one z czasem, aby chronić prywatność użytkowników! W związku z tym serwery będą musiały komunikować się z zaporą sieciową, co do których oczekuje się identyfikatorów CID , ale żadna z tych rzeczy jeszcze nie istnieje.
Podobne obawy dotyczą systemów równoważenia obciążenia w konfiguracjach na większą skalę. Maszyny te rozdzielają połączenia przychodzące na dużą liczbę serwerów zaplecza. Ruch dla jednego połączenia musi oczywiście być zawsze kierowany do tego samego serwera zaplecza (inne nie wiedziałyby, co z nim zrobić!). W przypadku TCP można to po prostu zrobić na podstawie 4-krotki, ponieważ to się nigdy nie zmienia. Jednak w przypadku migracji połączenia QUIC nie jest to już możliwe. Ponownie, serwery i systemy równoważenia obciążenia będą musiały w jakiś sposób uzgodnić, które identyfikatory CID wybrać, aby umożliwić deterministyczny routing . Jednak w przeciwieństwie do konfiguracji zapory istnieje już propozycja, aby to ustawić (chociaż nie jest to szeroko stosowane).
Wreszcie istnieją inne kwestie związane z bezpieczeństwem wyższego poziomu, głównie związane z atakami typu 0-RTT i rozproszoną odmową usługi (DDoS). Jak omówiono w części 2, QUIC zawiera już sporo środków łagodzących te problemy, ale najlepiej byłoby, gdyby korzystały również z dodatkowych linii obrony w sieci. Na przykład serwery proxy lub serwery brzegowe mogą blokować określone żądania 0-RTT przed dotarciem do rzeczywistych zapleczy, aby zapobiec atakom polegającym na odtwarzaniu. Alternatywnie, aby zapobiec atakom odbicia lub atakom DDoS, które wysyłają tylko pierwszy pakiet uzgadniania, a następnie przestają odpowiadać (nazywane powodzią SYN w TCP), QUIC zawiera funkcję ponawiania. Pozwala to serwerowi sprawdzić, czy jest dobrze zachowującym się klientem, bez konieczności utrzymywania w międzyczasie żadnego stanu (odpowiednik ciasteczek TCP SYN). Ten proces ponawiania najlepiej odbywa się oczywiście gdzieś przed serwerem zaplecza — na przykład w systemie równoważenia obciążenia. Ponownie jednak wymaga to dodatkowej konfiguracji i komunikacji.
To tylko najważniejsze problemy, które administratorzy sieci i systemów będą mieli z QUIC i HTTP/3. Jest ich jeszcze kilka, o niektórych z nich mówiłem. Istnieją również dwa oddzielne dokumenty towarzyszące QUIC RFC, które omawiają te kwestie i ich możliwe (częściowe) łagodzenie.
Co to wszystko znaczy?
HTTP/3 i QUIC to złożone protokoły, które opierają się na wielu wewnętrznych maszynach. Nie wszystko to jest jeszcze gotowe na czas największej oglądalności , chociaż masz już kilka opcji wdrażania nowych protokołów na swoich zapleczach. Jednak aktualizacja najbardziej znanych serwerów i podstawowych bibliotek (takich jak OpenSSL) zajmie prawdopodobnie kilka miesięcy, a nawet lat.
Nawet wtedy właściwe skonfigurowanie serwerów i innych pośredników sieciowych, tak aby protokoły mogły być używane w bezpieczny i optymalny sposób, nie będzie trywialne w konfiguracjach na większą skalę. Do prawidłowego przeprowadzenia tego przejścia potrzebny będzie dobry zespół ds. rozwoju i operacji.
W związku z tym, szczególnie na początku, prawdopodobnie najlepiej jest polegać na dużej firmie hostingowej lub CDN w celu skonfigurowania i skonfigurowania protokołów. Jak omówiono w części 2, właśnie tam QUIC i tak najprawdopodobniej się opłaci, a korzystanie z CDN jest jedną z kluczowych optymalizacji wydajności, które możesz zrobić. Osobiście poleciłbym używanie Cloudflare lub Fastly, ponieważ byli oni ściśle zaangażowani w proces standaryzacji i będą mieli dostępne najbardziej zaawansowane i dobrze dostrojone implementacje.
Klienci i QUIC Discovery
Do tej pory rozważaliśmy obsługę nowych protokołów po stronie serwera i w sieci. Jednak po stronie klienta do rozwiązania jest również kilka problemów.
Zanim do tego przejdziemy, zacznijmy od dobrych wiadomości: większość popularnych przeglądarek ma już (eksperymentalną) obsługę HTTP/3! Konkretnie, w momencie pisania tego tekstu, oto status wsparcia (patrz również caniuse.com):

- Google Chrome (wersja 91+) : domyślnie włączone.
- Mozilla Firefox (wersja 89+) : domyślnie włączona.
- Microsoft Edge (wersja 90+) : domyślnie włączone (wewnętrznie używa Chromium).
- Opera (wersja 77+) : domyślnie włączona (wewnętrznie używa Chromium).
- Apple Safari (wersja 14) : Za flagą ręczną. Zostanie włączona domyślnie w wersji 15, która jest obecnie w fazie podglądu technologii.
- Inne przeglądarki : Nie znam jeszcze żadnych sygnałów (chociaż inne przeglądarki korzystające wewnętrznie z Chromium, takie jak Brave, teoretycznie również mogą zacząć to włączać).
Zwróć uwagę na kilka niuansów:
- Większość przeglądarek jest wdrażana stopniowo, przez co nie wszyscy użytkownicy otrzymają domyślnie włączoną obsługę HTTP/3 od samego początku. Ma to na celu ograniczenie ryzyka, że pojedynczy przeoczony błąd może wpłynąć na wielu użytkowników lub że wdrożenia serwera zostaną przeciążone. W związku z tym istnieje niewielka szansa, że nawet w najnowszych wersjach przeglądarek domyślnie nie dostaniesz HTTP/3 i będziesz musiał włączyć go ręcznie.
- Podobnie jak w przypadku serwerów, obsługa HTTP/3 nie oznacza, że wszystkie funkcje zostały zaimplementowane lub są obecnie używane. W szczególności może nadal brakować 0-RTT, migracji połączenia, serwera push, dynamicznej kompresji nagłówków QPACK i priorytetyzacji HTTP/3, które mogą być wyłączone, używane oszczędnie lub słabo skonfigurowane.
- Jeśli chcesz używać HTTP/3 po stronie klienta poza przeglądarką (na przykład w swojej natywnej aplikacji), musisz zintegrować jedną z wymienionych powyżej bibliotek lub użyć cURL. Apple wkrótce wprowadzi natywną obsługę HTTP/3 i QUIC do swoich wbudowanych bibliotek sieciowych na macOS i iOS, a Microsoft dodaje QUIC do jądra systemu Windows i swojego środowiska .NET, ale podobne natywne wsparcie (według mojej wiedzy) nie zostało ogłoszony dla innych systemów, takich jak Android.
Alt-Svc
Nawet jeśli masz skonfigurowany serwer zgodny z HTTP/3 i używasz zaktualizowanej przeglądarki, możesz być zaskoczony, że HTTP/3 nie jest w rzeczywistości używany konsekwentnie . Aby zrozumieć dlaczego, załóżmy, że przez chwilę jesteś przeglądarką. Twój użytkownik poprosił Cię o przejście do example.com (witryny, której nigdy wcześniej nie odwiedzałeś), a za pomocą DNS udało Ci się ustalić adres IP. Wysyłasz jeden lub więcej pakietów QUIC handshake do tego adresu IP. Teraz kilka rzeczy może pójść nie tak:
- Serwer może nie obsługiwać QUIC.
- Jedna z pośrednich sieci lub zapory może całkowicie blokować QUIC i/lub UDP.
- Pakiety uzgadniania mogą zostać utracone podczas przesyłania.
Skąd jednak możesz wiedzieć (który) wystąpił jeden z tych problemów ? We wszystkich trzech przypadkach nigdy nie otrzymasz odpowiedzi na pakiety uzgadniania. Jedyne, co możesz zrobić, to czekać, mając nadzieję, że odpowiedź nadal może nadejść. Następnie, po pewnym czasie oczekiwania (przekroczeniu limitu czasu), możesz uznać, że rzeczywiście jest problem z HTTP/3. W tym momencie spróbujesz otworzyć połączenie TCP z serwerem, mając nadzieję, że HTTP/2 lub HTTP/1.1 zadziała.
Jak widać, tego typu podejście może spowodować poważne opóźnienia, szczególnie w początkowych latach, kiedy wiele serwerów i sieci nie obsługuje jeszcze QUIC. Prostym, ale naiwnym rozwiązaniem byłoby po prostu otwarcie połączenia QUIC i TCP w tym samym czasie, a następnie skorzystanie z tego, które uzgadnianie zakończy się jako pierwsze . Ta metoda nazywa się „wyścigami połączeń” lub „szczęśliwymi gałkami ocznymi”. Chociaż jest to z pewnością możliwe, wiąże się to ze znacznymi kosztami. Mimo że utracone połączenie jest prawie natychmiast zamykane, nadal zajmuje trochę pamięci i czasu procesora zarówno na kliencie, jak i na serwerze (szczególnie w przypadku korzystania z TLS). Oprócz tego istnieją również inne problemy związane z tą metodą, związane z sieciami IPv4 kontra IPv6 oraz wcześniej omawianymi atakami typu replay (o których bardziej szczegółowo omawiam w moim omówieniu).
W związku z tym, w przypadku QUIC i HTTP/3, przeglądarki wolą grać bezpiecznie i próbować QUIC tylko wtedy, gdy wiedzą, że serwer go obsługuje . W związku z tym przy pierwszym kontakcie z nowym serwerem przeglądarka będzie używać tylko protokołu HTTP/2 lub HTTP/1.1 przez połączenie TCP. Serwer może wtedy poinformować przeglądarkę, że obsługuje również HTTP/3 dla kolejnych połączeń. Odbywa się to poprzez ustawienie specjalnego nagłówka HTTP w odpowiedziach odsyłanych przez HTTP/2 lub HTTP/1.1. Ten nagłówek nazywa się Alt-Svc , co oznacza „usługi alternatywne”. Alt-Svc może być użyty do poinformowania przeglądarki, że dana usługa jest również osiągalna przez inny serwer (IP i/lub port), ale pozwala również na wskazanie alternatywnych protokołów. Widać to poniżej na rysunku 1.
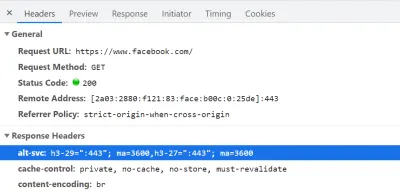
Alt-Svc , który informuje przeglądarkę, że można się z nim również połączyć przez HTTP/3 na porcie UDP 443 (jest to ważne przez 3600 sekund). Na razie nazwa protokołu to nadal h3-29 lub h3-27 (29. i 27. wersja robocza HTTP/3), ale ostatecznie stanie się to po prostu h3 (niektóre serwery, takie jak google.com , już dziś używają h3). (duży podgląd) Po otrzymaniu prawidłowego nagłówka Alt-Svc wskazującego na obsługę protokołu HTTP/3, przeglądarka zapisze go w pamięci podręcznej i od tego momentu spróbuje nawiązać połączenie QUIC. Niektórzy klienci zrobią to tak szybko, jak to możliwe (nawet podczas początkowego ładowania strony — patrz poniżej), podczas gdy inni będą czekać na zamknięcie istniejących połączeń TCP. Oznacza to, że przeglądarka będzie używać protokołu HTTP/3 dopiero po pobraniu przynajmniej kilku zasobów przez HTTP/2 lub HTTP/1.1 . Nawet wtedy to nie jest płynna żegluga. Przeglądarka wie teraz, że serwer obsługuje HTTP/3, ale to nie znaczy, że sieć pośrednia go nie zablokuje. W związku z tym wyścigi połączeń są nadal potrzebne w praktyce. Tak więc nadal możesz skończyć z HTTP/2, jeśli sieć w jakiś sposób opóźni QUIC handshake wystarczająco. Dodatkowo, jeśli połączenie QUIC nie zostanie nawiązane kilka razy z rzędu, niektóre przeglądarki umieszczą wpis pamięci podręcznej Alt-Svc na liście odrzuconych przez jakiś czas, nie próbując przez jakiś czas HTTP/3. W związku z tym pomocne może być ręczne wyczyszczenie pamięci podręcznej przeglądarki, jeśli coś działa prawidłowo, ponieważ powinno to również opróżnić powiązania Alt-Svc . Wreszcie okazało się, że Alt-Svc stwarza poważne zagrożenie bezpieczeństwa. Z tego powodu niektóre przeglądarki nakładają dodatkowe ograniczenia na przykład na to, które porty mogą być używane (w Chrome serwery HTTP/2 i HTTP/3 muszą być albo na porcie poniżej 1024, albo oba na porcie wyższym lub równym do 1024, w przeciwnym razie Alt-Svc zostanie zignorowany). Cała ta logika jest różna i ewoluuje w zależności od przeglądarek, co oznacza, że uzyskanie spójnych połączeń HTTP/3 może być trudne , co również utrudnia testowanie nowych konfiguracji.

Trwają prace nad ulepszeniem tego dwuetapowego procesuAlt-Svc. Pomysł polega na użyciu nowych rekordów DNS zwanych SVCB i HTTPS, które będą zawierać informacje podobne do tego, co jest wAlt-Svc. W związku z tym klient może odkryć, że serwer obsługuje HTTP/3 podczas kroku rozwiązywania DNS, co oznacza, że może wypróbować QUIC od pierwszego załadowania strony, zamiast najpierw przechodzić przez HTTP/2 lub HTTP/1.1. Więcej informacji na ten temat iAlt-Svcmożna znaleźć w zeszłorocznym rozdziale Web Almanac na temat HTTP/2.
Jak widać, Alt-Svc i proces wykrywania HTTP/3 dodają warstwę złożoności do i tak już wymagającego wdrożenia serwera QUIC, ponieważ:
- zawsze będziesz musiał wdrożyć serwer HTTP/3 obok serwera HTTP/2 i/lub HTTP/1.1;
- będziesz musiał skonfigurować serwery HTTP/2 i HTTP/1.1, aby ustawić prawidłowe nagłówki
Alt-Svcw ich odpowiedziach.
Chociaż powinno to być możliwe do zarządzania w konfiguracjach na poziomie produkcyjnym (ponieważ na przykład pojedyncza instancja Apache lub NGINX prawdopodobnie będzie obsługiwać wszystkie trzy wersje HTTP w tym samym czasie), może to być znacznie bardziej irytujące w (lokalnym) zestawie testowym- ups (już widzę, że zapominam dodać nagłówki Alt-Svc lub je zepsuć). Ten problem jest potęgowany przez (obecny) brak dzienników błędów przeglądarki i wskaźników DevTools, co oznacza, że ustalenie, dlaczego konfiguracja nie działa, może być trudne.
Dodatkowe problemy
Jakby tego było mało, inny problem utrudni lokalne testowanie: Chrome bardzo utrudnia korzystanie z podpisanych przez siebie certyfikatów TLS dla QUIC . Dzieje się tak, ponieważ nieoficjalne certyfikaty TLS są często używane przez firmy do odszyfrowywania ruchu TLS swoich pracowników (po to, aby na przykład zapory ogniowe skanowały ruch zaszyfrowany). Jeśli jednak firmy zaczęłyby to robić z QUIC, ponownie mielibyśmy niestandardowe implementacje middleboxa, które robią własne założenia dotyczące protokołu. Może to prowadzić do potencjalnego złamania obsługi protokołu w przyszłości, czemu właśnie staraliśmy się zapobiec, od samego początku tak intensywnie szyfrując QUIC! As such, Chrome takes a very opinionated stance on this: If you're not using an official TLS certificate (signed by a certificate authority or root certificate that is trusted by Chrome, such as Let's Encrypt), then you cannot use QUIC . This, sadly, also includes self-signed certificates, which are often used for local test set-ups.
It is still possible to bypass this with some freaky command-line flags (because the common --ignore-certificate-errors doesn't work for QUIC yet), by using per-developer certificates (although setting this up can be tedious), or by setting up the real certificate on your development PC (but this is rarely an option for big teams because you would have to share the certificate's private key with each developer). Finally, while you can install a custom root certificate, you would then also need to pass both the --origin-to-force-quic-on and --ignore-certificate-errors-spki-list flags when starting Chrome (see below). Luckily, for now, only Chrome is being so strict, and hopefully, its developers will loosen their approach over time.
If you are having problems with your QUIC set-up from inside a browser, it's best to first validate it using a tool such as cURL. cURL has excellent HTTP/3 support (you can even choose between two different underlying libraries) and also makes it easier to observe Alt-Svc caching logic.
Co to wszystko znaczy?
Next to the challenges involved with setting up HTTP/3 and QUIC on the server-side, there are also difficulties in getting browsers to use the new protocols consistently. This is due to a two-step discovery process involving the Alt-Svc HTTP header and the fact that HTTP/2 connections cannot simply be “upgraded” to HTTP/3, because the latter uses UDP.
Even if a server supports HTTP/3, however, clients (and website owners!) need to deal with the fact that intermediate networks might block UDP and/or QUIC traffic. As such, HTTP/3 will never completely replace HTTP/2 . In practice, keeping a well-tuned HTTP/2 set-up will remain necessary both for first-time visitors and visitors on non-permissive networks. Luckily, as we discussed, there shouldn't be many page-level changes between HTTP/2 and HTTP/3, so this shouldn't be a major headache.
What could become a problem, however, is testing and verifying whether you are using the correct configuration and whether the protocols are being used as expected. This is true in production, but especially in local set-ups. As such, I expect that most people will continue to run HTTP/2 (or even HTTP/1.1) development servers , switching only to HTTP/3 in a later deployment stage. Even then, however, validating protocol performance with the current generation of tools won't be easy.
Tools and Testing
As was the case with many major servers, the makers of the most popular web performance testing tools have not been keeping up with HTTP/3 from the start. Consequently, few tools have dedicated support for the new protocol as of July 2021, although they support it to a certain degree.
Latarnia Google
First, there is the Google Lighthouse tool suite. While this is an amazing tool for web performance in general, I have always found it somewhat lacking in aspects of protocol performance. This is mostly because it simulates slow networks in a relatively unrealistic way, in the browser (the same way that Chrome's DevTools handle this). While this approach is quite usable and typically “good enough” to get an idea of the impact of a slow network, testing low-level protocol differences is not realistic enough. Because the browser doesn't have direct access to the TCP stack, it still downloads the page on your normal network, and it then artificially delays the data from reaching the necessary browser logic. This means, for example, that Lighthouse emulates only delay and bandwidth, but not packet loss (which, as we've seen, is a major point where HTTP/3 could potentially differ from HTTP/2). Alternatively, Lighthouse uses a highly advanced simulation model to guesstimate the real network impact, because, for example, Google Chrome has some complex logic that tweaks several aspects of a page load if it detects a slow network. This model has, to the best of my knowledge, not been adjusted to handle IETF QUIC or HTTP/3 yet. As such, if you use Lighthouse today for the sole purpose of comparing HTTP/2 and HTTP/3 performance, then you are likely to get erroneous or oversimplified results, which could lead you to wrong conclusions about what HTTP/3 can do for your website in practice. The silver lining is that, in theory, this can be improved massively in the future, because the browser does have full access to the QUIC stack, and thus Lighthouse could add much more advanced simulations (including packet loss!) for HTTP/3 down the line. For now, though, while Lighthouse can, in theory, load pages over HTTP/3, I would recommend against it.
WebPageTest
Secondly, there is WebPageTest. This amazing project lets you load pages over real networks from real devices across the world, and it also allows you to add packet-level network emulation on top, including aspects such as packet loss! As such, WebPageTest is conceptually in a prime position to be used to compare HTTP/2 and HTTP/3 performance. However, while it can indeed already load pages over the new protocol, HTTP/3 has not yet been properly integrated into the tooling or visualizations . For example, there are currently no easy ways to force a page load over QUIC, to easily view how Alt-Svc was actually used, or even to see QUIC handshake details. In some cases, even seeing whether a response used HTTP/3 or HTTP/2 can be challenging. Still, in April, I was able to use WebPageTest to run quite a few tests on facebook.com and see HTTP/3 in action, which I'll go over now.
First, I ran a default test for facebook.com , enabling the “repeat view” option. As explained above, I would expect the first page load to use HTTP/2, which will include the Alt-Svc response header. As such, the repeat view should use HTTP/3 from the start. In Firefox version 89, this is more or less what happens. However, when looking at individual responses, we see that even during the first page load, Firefox will switch to using HTTP/3 instead of HTTP/2 ! As you can see in figure 2, this happens from the 20th resource onwards. This means that Firefox establishes a new QUIC connection as soon as it sees the Alt-Svc header, and it switches to it once it succeeds. If you scroll down to the connection view, it also seems to show that Firefox even opened two QUIC connections: one for credentialed CORS requests and one for no-CORS requests. This would be expected because, as we discussed above, even for HTTP/2 and HTTP/3, browsers will open multiple connections due to security concerns. However, because WebPageTest doesn't provide more details in this view, it's difficult to confirm without manually digging through the data. Looking at the repeat view (second visit), it starts by directly using HTTP/3 for the first request, as expected.
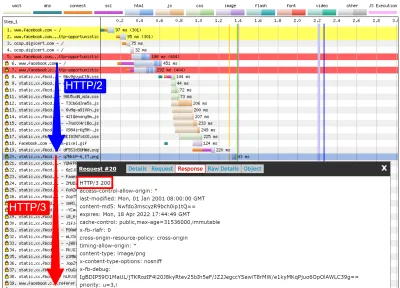
Next, for Chrome, we see similar behavior for the first page load, although here Chrome already switches on the 10th resource, much earlier than Firefox. It's a bit more unclear here whether it switches as soon as possible or only when a new connection is needed (for example, for requests with different credentials), because, unlike for Firefox, the connection view also doesn't seem to show multiple QUIC connections. For the repeat view, we see some weirder things. Unexpectedly, Chrome starts off using HTTP/2 there as well , switching to HTTP/3 only after a few requests! I performed a few more tests on other pages as well, to confirm that this is indeed consistent behaviour. This could be due to several things: It might just be Chrome's current policy, it might be that Chrome “raced” a TCP and QUIC connection and TCP won initially, or it might be that the Alt-Svc cache from the first view was unused for some reason. At this point, there is, sadly, no easy way to determine what the problem really is (and whether it can even be fixed).
Another interesting thing I noticed here is the apparent connection coalescing behavior. As discussed above, both HTTP/2 and HTTP/3 can reuse connections even if they go to other hostnames, to prevent downsides from hostname sharding. However, as shown in figure 3, WebPageTest reports that, for this Facebook load, connection coalescing is used over HTTP/3 forfacebook.comandfbcdn.net, but not over HTTP/2 (as Chrome opens a secondary connection for the second domain). I suspect this is a bug in WebPageTest, however, becausefacebook.comandfbcnd.netresolve to different IPs and, as such, can't really be coalesced.
The figure also shows that some key QUIC handshake information is missing from the current WebPageTest visualization.

Note : As we see, getting “real” HTTP/3 going can be difficult sometimes. Luckily, for Chrome specifically, we have additional options we can use to test QUIC and HTTP/3, in the form of command-line parameters.
On the bottom of WebPageTest's “Chromium” tab, I used the following command-line options:
--enable-quic --quic-version=h3-29 --origin-to-force-quic-on=www.facebook.com:443,static.xx.fbcdn.net:443 The results from this test show that this indeed forces a QUIC connection from the start, even in the first view, thus bypassing the Alt-Svc process. Interestingly, you will notice I had to pass two hostnames to --origin-to-force-quic-on . In the version where I didn't, Chrome, of course, still first opened an HTTP/2 connection to the fbcnd.net domain, even in the repeat view. As such, you'll need to manually indicate all QUIC origins in order for this to work !
We can see even from these few examples that a lot of stuff is going on with how browsers actually use HTTP/3 in practice. It seems they even switch to the new protocol during the initial page load, abandoning HTTP/2 either as soon as possible or when a new connection is needed. As such, it's difficult not only getting a full HTTP/3 load, but also getting a pure HTTP/2 load on a set-up that supports both ! Because WebPageTest doesn't show much HTTP/3 or QUIC metadata yet, figuring out what's going on can be challenging, and you can't trust the tools and visualizations at face value either.
So, if you use WebPageTest, you'll need to double-check the results to make sure which protocols were actually used. Consequently, I think this means that it's too early to really test HTTP/3 performance at this time (and especially too early to compare it to HTTP/2). This belief is strengthened by the fact that not all servers and clients have implemented all protocol features yet. Due to the fact that WebPageTest doesn't yet have easy ways of showing whether advanced aspects such as 0-RTT were used, it will be tricky to know what you're actually measuring. This is especially true for the HTTP/3 prioritization feature, which isn't implemented properly in all browsers yet and which many servers also lack full support for. Because prioritization can be a major aspect driving web performance, it would be unfair to compare HTTP/3 to HTTP/2 without making sure that at least this feature works properly (for both protocols!). This is just one aspect, though, as my research shows how big the differences between QUIC implementations can be. If you do any comparison of this sort yourself (or if you read articles that do), make 100% sure that you've checked what's actually going on .
Finally, also note that other higher-level tools (or data sets such as the amazing HTTP Archive) are often based on WebPageTest or Lighthouse (or use similar methods), so I suspect that most of my comments here will be widely applicable to most web performance tooling. Even for those tool vendors announcing HTTP/3 support in the coming months, I would be a bit skeptical and would validate that they're actually doing it correctly. For some tools, things are probably even worse, though; for example, Google's PageSpeed Insights only got HTTP/2 support this year, so I wouldn't wait for HTTP/3 arriving anytime soon.
Wireshark, qlog i qvis
Jak pokazuje powyższa dyskusja, analizowanie zachowania HTTP/3 za pomocą samego Lighthouse lub WebPageTest w tym momencie może być trudne. Na szczęście dostępne są inne narzędzia niższego poziomu, które mogą w tym pomóc. Po pierwsze, doskonałe narzędzie Wireshark ma zaawansowaną obsługę QUIC, a także może eksperymentalnie analizować HTTP/3. Pozwala to obserwować, które pakiety QUIC i HTTP/3 faktycznie przechodzą przez sieć. Jednak aby to zadziałało, musisz uzyskać klucze deszyfrujące TLS dla danego połączenia, które większość implementacji (w tym Chrome i Firefox) pozwala na wyodrębnienie za pomocą zmiennej środowiskowej SSLKEYLOGFILE . Chociaż może to być przydatne w przypadku niektórych rzeczy, naprawdę ustalenie, co się dzieje, zwłaszcza w przypadku dłuższych połączeń, może wymagać dużo pracy ręcznej. Potrzebujesz również dość zaawansowanego zrozumienia wewnętrznego działania protokołów.
Na szczęście istnieje druga opcja, qlog i qvis. qlog to format rejestrowania oparty na JSON przeznaczony specjalnie dla QUIC i HTTP/3, który jest obsługiwany przez większość implementacji QUIC. Zamiast patrzeć na pakiety przechodzące przez sieć, qlog przechwytuje te informacje bezpośrednio na kliencie i serwerze, co pozwala mu dołączyć dodatkowe informacje (na przykład szczegóły kontroli przeciążenia). Zazwyczaj można wyzwolić wyjście qlog podczas uruchamiania serwerów i klientów za pomocą zmiennej środowiskowej QLOGDIR . (Pamiętaj, że w przeglądarce Firefox musisz ustawić preferencję network.http.http3.enable_qlog . Urządzenia Apple i Safari używają zamiast tego QUIC_LOG_DIRECTORY . Chrome nie obsługuje jeszcze qlog.)
Te pliki qlog można następnie przesłać do pakietu narzędzi qvis pod adresem qvis.quictools.info. Otrzymasz tam szereg zaawansowanych interaktywnych wizualizacji, które ułatwiają interpretację ruchu QUIC i HTTP/3 . qvis obsługuje również przesyłanie przechwyconych pakietów Wireshark (pliki .pcap ) i eksperymentalnie obsługuje pliki netlog Chrome, dzięki czemu możesz również analizować zachowanie Chrome. Pełny samouczek na temat qlog i qvis wykracza poza zakres tego artykułu, ale więcej szczegółów można znaleźć w formie samouczka, w formie papierowej, a nawet w formacie talk-show. Możesz też zapytać mnie o nie bezpośrednio, ponieważ jestem głównym realizatorem qlog i qvis. ;)
Jednak nie mam złudzeń, że większość czytelników powinna kiedykolwiek używać Wireshark lub qvis, ponieważ są to dość niskopoziomowe narzędzia. Mimo to, ponieważ w tej chwili mamy kilka alternatyw, zdecydowanie odradzam szczegółowe testowanie wydajności HTTP/3 bez użycia tego typu narzędzia , aby upewnić się, że naprawdę wiesz, co się dzieje w sieci i czy to, co widzisz, jest naprawdę wyjaśnione przez przez elementy wewnętrzne protokołu, a nie przez inne czynniki.
Co to wszystko znaczy?
Jak widzieliśmy, konfiguracja i używanie HTTP/3 przez QUIC może być skomplikowaną sprawą i wiele rzeczy może pójść nie tak. Niestety, nie jest dostępne żadne dobre narzędzie ani wizualizacja, która eksponuje niezbędne szczegóły na odpowiednim poziomie abstrakcji. To sprawia, że większości programistów bardzo trudno jest ocenić potencjalne korzyści, jakie HTTP/3 może obecnie przynieść ich stronie internetowej, a nawet zweryfikować, czy ich konfiguracja działa zgodnie z oczekiwaniami.
Poleganie tylko na metrykach wysokiego poziomu jest bardzo niebezpieczne, ponieważ mogą one być wypaczone przez wiele czynników (takich jak nierealistyczna emulacja sieci, brak funkcji na klientach lub serwerach, tylko częściowe użycie HTTP/3 itp.). Nawet jeśli wszystko działało lepiej, jak widzieliśmy w części 2, różnice między HTTP/2 i HTTP/3 będą prawdopodobnie w większości przypadków stosunkowo niewielkie, co jeszcze bardziej utrudni uzyskanie niezbędnych informacji z wysokiego poziomu narzędzia bez ukierunkowanej obsługi HTTP/3.
W związku z tym radzę pozostawić pomiary wydajności HTTP/2 i HTTP/3 samemu na kilka miesięcy i skupić się na upewnieniu się, że nasze konfiguracje po stronie serwera działają zgodnie z oczekiwaniami . W tym celu najłatwiej jest użyć WebPageTest w połączeniu z parametrami wiersza poleceń Google Chrome, z opcją curl w przypadku potencjalnych problemów — jest to obecnie najbardziej spójna konfiguracja, jaką mogę znaleźć.
Wnioski i dania na wynos
Drogi czytelniku, jeśli przeczytałeś całą trzyczęściową serię i dotarłeś tutaj, pozdrawiam Cię ! Nawet jeśli przeczytałeś tylko kilka rozdziałów, dziękuję za zainteresowanie tymi nowymi i ekscytującymi protokołami. Teraz podsumuję najważniejsze wnioski z tej serii, przedstawię kilka kluczowych zaleceń na nadchodzące miesiące i rok, a na koniec udostępnię dodatkowe zasoby, jeśli chcesz dowiedzieć się więcej.
Streszczenie
Po pierwsze, w części 1 omówiliśmy, że HTTP/3 był potrzebny głównie ze względu na nowy podstawowy protokół transportowy QUIC . QUIC jest duchowym następcą TCP i integruje wszystkie najlepsze praktyki, a także TLS 1.3. Było to potrzebne głównie dlatego, że TCP, ze względu na jego wszechobecne wdrażanie i integrację w middleboxach, stał się zbyt nieelastyczny, aby mógł ewoluować. Wykorzystanie UDP przez QUIC i prawie pełne szyfrowanie oznacza, że (miejmy nadzieję) będziemy musieli aktualizować tylko punkty końcowe w przyszłości, aby dodać nowe funkcje, co powinno być łatwiejsze. QUIC dodaje jednak również kilka interesujących nowych możliwości. Po pierwsze, połączony transport i uzgadnianie kryptograficzne QUIC jest szybsze niż TCP + TLS i może dobrze wykorzystać funkcję 0-RTT. Po drugie, QUIC wie, że przenosi wiele niezależnych strumieni bajtów i może być mądrzejszy w radzeniu sobie z utratą i opóźnieniami, łagodząc problem blokowania nagłówka linii. Po trzecie, połączenia QUIC mogą przetrwać przejście użytkowników do innej sieci (tzw. migracja połączenia), oznaczając każdy pakiet identyfikatorem połączenia. Wreszcie, elastyczna struktura pakietów QUIC (wykorzystująca ramki) czyni go bardziej wydajnym, ale także bardziej elastycznym i rozszerzalnym w przyszłości. Podsumowując, jasne jest, że QUIC jest protokołem transportowym nowej generacji i będzie używany i rozszerzany przez wiele lat .
Po drugie, w części 2 przyjrzeliśmy się krytycznie tym nowym funkcjom, zwłaszcza ich wpływom na wydajność . Po pierwsze, widzieliśmy, że użycie protokołu UDP przez QUIC nie czyni go magicznie szybszym (ani wolniejszym), ponieważ QUIC używa mechanizmów kontroli przeciążenia bardzo podobnych do TCP, aby zapobiec przeciążeniu sieci. Po drugie, szybsze uzgadnianie i 0-RTT to więcej mikrooptymalizacji, ponieważ są one tak naprawdę tylko o jedną podróż szybciej niż zoptymalizowany stos TCP + TLS, a prawdziwe 0-RTT QUIC jest dodatkowo dotknięte szeregiem problemów związanych z bezpieczeństwem, które mogą ograniczać jego użyteczność. Po trzecie, migracja połączenia jest naprawdę potrzebna tylko w kilku konkretnych przypadkach i nadal oznacza resetowanie szybkości wysyłania, ponieważ kontrola przeciążenia nie wie, ile danych może obsłużyć nowa sieć. Po czwarte, skuteczność usuwania blokowania nagłówka linii przez QUIC w dużej mierze zależy od tego, w jaki sposób dane strumienia są multipleksowane i priorytetyzowane. Podejścia, które są optymalne do odzyskiwania po utracie pakietów, wydają się być szkodliwe dla ogólnych przypadków użycia wydajności ładowania stron internetowych i odwrotnie, chociaż potrzebne są dalsze badania. Po piąte, QUIC może z łatwością wysyłać pakiety wolniej niż TCP + TLS, ponieważ interfejsy API UDP są mniej dojrzałe i QUIC szyfruje każdy pakiet indywidualnie, chociaż można to w dużej mierze złagodzić w czasie. Po szóste, sam HTTP/3 tak naprawdę nie wprowadza żadnych nowych, ważnych funkcji wydajnościowych, ale głównie przerabia i upraszcza wewnętrzne funkcje znanych funkcji HTTP/2. Wreszcie, niektóre z najbardziej ekscytujących funkcji związanych z wydajnością, które umożliwia QUIC (wielościeżkowe, niewiarygodne dane, WebTransport, korekcja błędów przesyłania dalej itp.) nie są częścią podstawowych standardów QUIC i HTTP/3, ale są raczej proponowanymi rozszerzeniami, które będą wymagały jeszcze trochę czasu, aby być dostępnym. Podsumowując, oznacza to, że QUIC prawdopodobnie nie poprawi znacząco wydajności użytkowników w szybkich sieciach, ale będzie ważny głównie dla tych, którzy korzystają z wolnych i mniej stabilnych sieci .
Wreszcie, w tej części 3, przyjrzeliśmy się, jak w praktyce używać i wdrażać QUIC i HTTP/3 . Po pierwsze, zauważyliśmy, że większość najlepszych praktyk i wniosków wyciągniętych z HTTP/2 powinna zostać przeniesiona na HTTP/3. Nie ma potrzeby zmiany strategii tworzenia pakietów lub inline, ani konsolidowania lub dzielenia farmy serwerów. Serwer push nadal nie jest najlepszą funkcją do użycia, a preload ładowanie może być podobnie potężnym footgunem. Po drugie, omówiliśmy, że może minąć trochę czasu, zanim gotowe pakiety serwerów WWW zapewnią pełną obsługę HTTP/3 (częściowo z powodu problemów z obsługą biblioteki TLS), chociaż wiele opcji open source jest dostępnych dla wczesnych użytkowników i kilka głównych sieci CDN ma dojrzałą ofertę. Po trzecie, jasne jest, że większość głównych przeglądarek ma (podstawową) obsługę HTTP/3, nawet domyślnie włączoną. Istnieją jednak poważne różnice w tym, jak i kiedy w praktyce korzystają z protokołu HTTP/3 i jego nowych funkcji, więc zrozumienie ich zachowania może być trudne. Po czwarte, omówiliśmy, że pogarsza to brak wyraźnej obsługi HTTP/3 w popularnych narzędziach, takich jak Lighthouse i WebPageTest, co sprawia, że obecnie szczególnie trudno jest porównać wydajność HTTP/3 z HTTP/2 i HTTP/1.1. Podsumowując, HTTP/3 i QUIC prawdopodobnie nie są jeszcze w pełni gotowe na primetime, ale wkrótce będą .
Zalecenia
Z powyższego podsumowania może się wydawać, że przedstawiam mocne argumenty przeciwko używaniu QUIC lub HTTP/3. Jest to jednak coś zupełnie przeciwnego do punktu, o którym chcę powiedzieć.
Po pierwsze, jak omówiono pod koniec części 2, nawet jeśli „przeciętny” użytkownik może nie odnotować znacznego wzrostu wydajności (w zależności od rynku docelowego), znaczna część odbiorców prawdopodobnie odczuje imponującą poprawę . 0-RTT może zaoszczędzić tylko jedną podróż w obie strony, ale dla niektórych użytkowników może to oznaczać kilkaset milisekund. Migracja połączenia może nie zapewniać stałego szybkiego pobierania, ale z pewnością pomoże osobom próbującym pobrać ten plik PDF szybkim pociągiem. Utrata pakietów na kablu może być gwałtowna, ale łącza bezprzewodowe mogą bardziej skorzystać na usunięciu blokowania nagłówka linii przez QUIC. Co więcej, ci użytkownicy to ci, którzy zazwyczaj spotkaliby się z najgorszą wydajnością twojego produktu, a co za tym idzie, zostali przez nią najbardziej dotknięci. Jeśli zastanawiasz się, dlaczego to ma znaczenie, przeczytaj słynną anegdotę o wydajności sieciowej Chrisa Zachariasa.
Po drugie, QUIC i HTTP/3 będą z czasem tylko lepsze i szybsze . Wersja 1 skupiła się na wykonaniu podstawowego protokołu, zachowując bardziej zaawansowane funkcje wydajności na później. W związku z tym uważam, że opłaca się zacząć inwestować w protokoły już teraz, aby upewnić się, że możesz z nich korzystać i z nowych funkcji, aby uzyskać optymalny efekt, gdy staną się dostępne w dalszej kolejności. Biorąc pod uwagę złożoność protokołów i ich aspekty wdrażania, dobrze byłoby dać sobie trochę czasu na zapoznanie się z ich dziwactwami. Nawet jeśli nie chcesz jeszcze ubrudzić sobie rąk, kilku głównych dostawców CDN oferuje dojrzałą obsługę HTTP/3 „przerzuć przełącznik” (w szczególności Cloudflare i Fastly). Trudno mi znaleźć powód, aby nie wypróbowywać tego, jeśli korzystasz z CDN (co, jeśli zależy ci na wydajności, naprawdę powinieneś).
W związku z tym, chociaż nie powiedziałbym, że kluczowe jest, aby zacząć używać QUIC i HTTP/3 tak szybko, jak to możliwe, uważam, że istnieje wiele korzyści, które już można uzyskać, a będą one tylko rosły w przyszłości .
Dalsza lektura
Chociaż był to długi tekst, niestety tak naprawdę tylko zarysowuje techniczną powierzchnię złożonych protokołów, którymi są QUIC i HTTP/3.
Poniżej znajdziesz listę dodatkowych zasobów do dalszej nauki, mniej więcej w kolejności rosnącej głębi technicznej:
- „Wyjaśnienie HTTP/3”, Daniel Stenberg
Ten e-book, autorstwa twórcy cURL, podsumowuje protokół. - „HTTP/2 w akcji”, Barry Pollard
Ta doskonała, wszechstronna książka na temat HTTP/2 zawiera porady dotyczące wielokrotnego użytku oraz sekcję dotyczącą HTTP/3. - @programmingart, Twitter
Moje tweety są głównie poświęcone QUIC, HTTP/3 i ogólnie wydajności sieciowej (w tym wiadomości). Zobacz na przykład moje ostatnie wątki dotyczące funkcji QUIC. - „YouTube”, Robin Marx
Moje ponad 10 pogłębionych rozmów obejmuje różne aspekty protokołów. - „Blog Cloudlare”
To główny produkt firmy, która dodatkowo prowadzi CDN. - „Blog Fastly”
Ten blog zawiera doskonałe dyskusje na temat aspektów technicznych, osadzonych w szerszym kontekście. - QUIC, rzeczywiste RFC
Znajdziesz linki do dokumentów IETF QUIC i HTTP/3 RFC oraz innych oficjalnych rozszerzeń. - IIJ Engineers Blog: Doskonałe szczegółowe wyjaśnienia techniczne szczegółów funkcji QUIC.
- Artykuły akademickie HTTP/3 i QUIC, Robin Marx
Moje artykuły badawcze dotyczą multipleksowania strumieni i ustalania priorytetów, narzędzi i różnic w zakresie implementacji. - QUIPS, EPIQ 2018 i EPIQ 2020
Te artykuły z warsztatów akademickich zawierają dogłębne badania dotyczące bezpieczeństwa, wydajności i rozszerzeń protokołów.
Tym samym zostawiam Ci, drogi Czytelniku, miejmy nadzieję, znacznie lepsze zrozumienie tego wspaniałego nowego świata. Zawsze jestem otwarty na opinie, więc daj mi znać, co myślisz o tej serii!
- Część 1: Historia HTTP/3 i podstawowe koncepcje
Ten artykuł jest skierowany do osób, które nie znają protokołu HTTP/3 i protokołów w ogóle, i omawia głównie podstawy. - Część 2: Funkcje wydajności HTTP/3
Ten jest bardziej dogłębny i techniczny. Tutaj mogą zacząć osoby, które już znają podstawy. - Część 3: Praktyczne opcje wdrażania HTTP/3
Ten trzeci artykuł z serii wyjaśnia wyzwania związane z samodzielnym wdrażaniem i testowaniem HTTP/3. Opisuje również, jak i czy powinieneś zmienić swoje strony internetowe i zasoby.