
HTTP/3: Ulepszenia wydajności (część 2)
Opublikowany: 2022-03-10Witamy ponownie w tej serii o nowym protokole HTTP/3. W części 1 przyjrzeliśmy się, dlaczego dokładnie potrzebujemy protokołu HTTP/3 i podstawowego protokołu QUIC oraz jakie są ich główne nowe funkcje.
W tej drugiej części przyjrzymy się ulepszeniom wydajności , które QUIC i HTTP/3 wprowadzają do tabeli podczas ładowania strony internetowej. Będziemy jednak również nieco sceptycznie nastawieni do wpływu, jakiego możemy spodziewać się po tych nowych funkcjach w praktyce.
Jak zobaczymy, QUIC i HTTP/3 rzeczywiście mają ogromny potencjał wydajności sieci, ale głównie dla użytkowników w wolnych sieciach . Jeśli przeciętny użytkownik korzysta z szybkiej sieci przewodowej lub komórkowej, prawdopodobnie nie skorzysta zbytnio z nowych protokołów. Pamiętaj jednak, że nawet w krajach i regionach z zazwyczaj szybkimi łączami uplink, najwolniejszy 1% do nawet 10% Twoich odbiorców (tzw. 99. lub 90. percentyl ) wciąż może dużo zyskać. Dzieje się tak, ponieważ HTTP/3 i QUIC pomagają głównie w rozwiązywaniu nieco rzadkich, ale potencjalnie poważnych problemów, które mogą pojawić się w dzisiejszym Internecie.
Ta część jest nieco bardziej techniczna niż pierwsza, chociaż przenosi większość naprawdę głębokich rzeczy do zewnętrznych źródeł, koncentrując się na wyjaśnieniu, dlaczego te rzeczy są ważne dla przeciętnego twórcy stron internetowych.
- Część 1: Historia HTTP/3 i podstawowe koncepcje
Ten artykuł jest skierowany do osób, które nie znają protokołu HTTP/3 i protokołów w ogóle, i omawia głównie podstawy. - Część 2: Funkcje wydajności HTTP/3
Ten jest bardziej dogłębny i techniczny. Tutaj mogą zacząć osoby, które już znają podstawy. - Część 3: Praktyczne opcje wdrażania HTTP/3
Ten trzeci artykuł z serii wyjaśnia wyzwania związane z samodzielnym wdrażaniem i testowaniem HTTP/3. Opisuje również, jak i czy powinieneś zmienić swoje strony internetowe i zasoby.
Elementarz na temat szybkości
Omawianie wydajności i „szybkości” może szybko stać się skomplikowane, ponieważ wiele podstawowych aspektów przyczynia się do powolnego ładowania strony internetowej. Ponieważ mamy tutaj do czynienia z protokołami sieciowymi, przyjrzymy się głównie aspektom sieci, z których dwa są najważniejsze: opóźnienie i przepustowość.
Opóźnienie można z grubsza zdefiniować jako czas potrzebny do wysłania pakietu z punktu A (powiedzmy, klienta) do punktu B (serwera) . Jest fizycznie ograniczony przez prędkość światła lub praktycznie jak szybko sygnały mogą przemieszczać się w przewodach lub na świeżym powietrzu. Oznacza to, że opóźnienie często zależy od fizycznej, rzeczywistej odległości między A i B.
Na Ziemi oznacza to, że typowe opóźnienia są koncepcyjnie małe, od około 10 do 200 milisekund. Jest to jednak tylko jeden sposób: odpowiedzi na pakiety również muszą wrócić. Opóźnienie dwukierunkowe jest często nazywane czasem podróży w obie strony (RTT) .
Ze względu na takie funkcje, jak kontrola przeciążenia (patrz poniżej), często będziemy potrzebować kilku podróży w obie strony, aby załadować nawet pojedynczy plik. W związku z tym nawet małe opóźnienia, poniżej 50 milisekund, mogą skutkować znacznymi opóźnieniami. Jest to jeden z głównych powodów istnienia sieci dostarczania treści (CDN): umieszczają one serwery fizycznie bliżej użytkownika końcowego, aby maksymalnie zmniejszyć opóźnienia, a tym samym opóźnienia.
Przepustowość można więc z grubsza określić jako liczbę pakietów, które można wysłać w tym samym czasie . Jest to nieco trudniejsze do wytłumaczenia, ponieważ zależy to od fizycznych właściwości medium (np. wykorzystywanej częstotliwości fal radiowych), liczby użytkowników w sieci, a także urządzeń łączących różne podsieci (ponieważ zazwyczaj może przetwarzać tylko określoną liczbę pakietów na sekundę).
Często używaną metaforą jest rura służąca do transportu wody. Długość potoku to opóźnienie, a szerokość to przepustowość. W Internecie jednak zazwyczaj mamy do czynienia z długimi seriami połączonych rur , z których niektóre mogą być szersze niż inne (prowadzące do tzw. wąskich gardeł na najwęższych połączeniach). W związku z tym przepustowość od końca do końca między punktami A i B jest często ograniczona przez najwolniejsze podsekcje.
Chociaż doskonałe zrozumienie tych pojęć nie jest potrzebne w dalszej części tego postu, posiadanie wspólnej definicji wysokiego poziomu byłoby dobre. Aby uzyskać więcej informacji, polecam zapoznanie się z doskonałym rozdziałem Ilyi Grigorika na temat opóźnień i przepustowości w jego książce High Performance Browser Networking .
Kontrola przeciążenia
Jednym z aspektów wydajności jest to, jak wydajnie protokół transportowy może wykorzystać pełną (fizyczną) przepustowość sieci (tj. w przybliżeniu, ile pakietów na sekundę można wysłać lub odebrać). To z kolei wpływa na szybkość pobierania zasobów strony. Niektórzy twierdzą, że QUIC robi to znacznie lepiej niż TCP, ale to nieprawda.
Czy wiedziałeś?
Na przykład połączenie TCP nie tylko zaczyna wysyłać dane z pełną przepustowością, ponieważ może to doprowadzić do przeciążenia (lub przeciążenia) sieci. Dzieje się tak, ponieważ, jak powiedzieliśmy, każde łącze sieciowe zawiera tylko określoną ilość danych, które może (fizycznie) przetwarzać co sekundę. Daj mu więcej, a nie ma innej opcji niż odrzucenie nadmiernych pakietów, co prowadzi do utraty pakietów .
Jak omówiono w części 1, w przypadku niezawodnego protokołu, takiego jak TCP, jedynym sposobem na odzyskanie utraconych pakietów jest retransmisja nowej kopii danych, która zajmuje jedną podróż w obie strony. Utrata pakietów może poważnie wpłynąć na wydajność, zwłaszcza w sieciach o dużym opóźnieniu (powiedzmy, z ponad 50-milisekundowym czasem RTT).
Innym problemem jest to, że nie wiemy z góry, jaka będzie maksymalna przepustowość . Często zależy to od wąskiego gardła gdzieś w połączeniu typu end-to-end, ale nie możemy przewidzieć ani wiedzieć, gdzie to będzie. Internet również nie ma mechanizmów (jeszcze) do sygnalizowania przepustowości łączy z powrotem do punktów końcowych.
Dodatkowo, nawet gdybyśmy znali dostępną przepustowość fizyczną, nie oznaczałoby to, że sami moglibyśmy z niej korzystać. Kilku użytkowników jest zazwyczaj aktywnych w sieci jednocześnie, a każdy z nich potrzebuje sprawiedliwego udziału w dostępnej przepustowości.
W związku z tym połączenie nie wie, jaką przepustowość może bezpiecznie lub sprawiedliwie wykorzystać z góry, a ta przepustowość może się zmieniać, gdy użytkownicy dołączają, opuszczają i korzystają z sieci. Aby rozwiązać ten problem, TCP będzie stale próbował odkryć dostępną przepustowość w czasie, używając mechanizmu zwanego kontrolą przeciążenia .
Na początku połączenia wysyła tylko kilka pakietów (w praktyce od 10 do 100 pakietów lub około 14 do 140 KB danych) i czeka jedną podróż w obie strony, aż odbiorca odeśle potwierdzenia tych pakietów. Jeśli wszystkie zostaną potwierdzone, oznacza to, że sieć może obsłużyć tę szybkość wysyłania i możemy spróbować powtórzyć proces, ale z większą ilością danych (w praktyce szybkość wysyłania zwykle podwaja się z każdą iteracją).
W ten sposób szybkość wysyłania nadal rośnie, dopóki niektóre pakiety nie zostaną potwierdzone (co wskazuje na utratę pakietów i przeciążenie sieci). Ta pierwsza faza jest zwykle nazywana „powolnym startem”. Po wykryciu utraty pakietów TCP zmniejsza szybkość wysyłania i (po chwili) ponownie zaczyna ją zwiększać, aczkolwiek w (znacznie) mniejszych przyrostach. Ta logika redukcji, a następnie wzrostu jest powtarzana dla każdej późniejszej utraty pakietów. Ostatecznie oznacza to, że TCP będzie stale próbował osiągnąć idealny, sprawiedliwy udział w przepustowości. Mechanizm ten ilustruje rysunek 1.
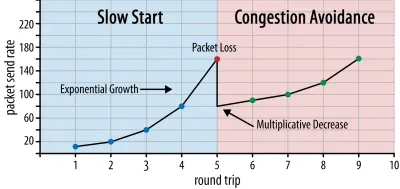
Jest to niezwykle uproszczone wyjaśnienie kontroli zatorów. W praktyce w grę wchodzi wiele innych czynników, takich jak buforowanie, wahania RTT spowodowane przeciążeniem oraz fakt, że wielu równoczesnych nadawców musi uzyskać sprawiedliwy udział w przepustowości. W związku z tym istnieje wiele różnych algorytmów kontroli przeciążenia, a wiele z nich wciąż jest wymyślanych, z których żaden nie działa optymalnie we wszystkich sytuacjach.
Chociaż kontrola przeciążenia TCP zapewnia jego niezawodność, oznacza to również, że osiągnięcie optymalnych szybkości wysyłania zajmuje trochę czasu, w zależności od RTT i rzeczywistej dostępnej przepustowości. W przypadku ładowania strony internetowej to powolne podejście może również wpływać na metryki, takie jak pierwsze wyrenderowanie treści, ponieważ tylko niewielka ilość danych (od kilkudziesięciu do kilkuset KB) może zostać przesłana w ciągu pierwszych kilku podróży w obie strony. (Być może słyszałeś zalecenie, aby Twoje krytyczne dane nie przekraczały 14 KB).
Wybranie bardziej agresywnego podejścia może zatem prowadzić do lepszych wyników w sieciach o dużej przepustowości i dużych opóźnieniach, zwłaszcza jeśli nie zależy Ci na sporadycznej utracie pakietów. W tym miejscu ponownie widziałem wiele błędnych interpretacji dotyczących działania QUIC.
Jak omówiono w części 1, QUIC teoretycznie mniej cierpi z powodu utraty pakietów (i powiązanego blokowania nagłówka linii (HOL)), ponieważ traktuje utratę pakietów w strumieniu bajtów każdego zasobu niezależnie. Ponadto QUIC działa na protokole UDP ( User Datagram Protocol ), który w przeciwieństwie do TCP nie ma wbudowanej funkcji kontroli przeciążenia; pozwala na próbę wysyłania z dowolną szybkością i nie retransmituje utraconych danych.
Doprowadziło to do wielu artykułów twierdzących, że QUIC również nie używa kontroli przeciążenia, że QUIC może zamiast tego zacząć wysyłać dane ze znacznie większą szybkością niż UDP (opierając się na usunięciu blokowania HOL, aby poradzić sobie z utratą pakietów), dlatego QUIC jest znacznie szybszy niż TCP.
W rzeczywistości nic nie może być dalsze od prawdy: QUIC faktycznie używa bardzo podobnych technik zarządzania pasmem jak TCP . Również zaczyna się od niższej szybkości wysyłania i rośnie z czasem, wykorzystując potwierdzenia jako kluczowy mechanizm pomiaru przepustowości sieci. Dzieje się tak (między innymi), ponieważ QUIC musi być niezawodny, aby być użytecznym dla czegoś takiego jak HTTP, ponieważ musi być sprawiedliwy dla innych połączeń QUIC (i TCP!) oraz ponieważ jego usuwanie blokujące HOL nie faktycznie pomagają w zapobieganiu utracie pakietów (jak zobaczymy poniżej).
Nie oznacza to jednak, że QUIC nie może być (trochę) mądrzejszy w zarządzaniu przepustowością niż TCP. Dzieje się tak głównie dlatego, że QUIC jest bardziej elastyczny i łatwiejszy do rozwijania niż TCP . Jak już powiedzieliśmy, algorytmy kontroli przeciążenia wciąż mocno ewoluują i prawdopodobnie będziemy musieli na przykład poprawić rzeczy, aby jak najlepiej wykorzystać 5G.
Jednak TCP jest zazwyczaj implementowany w jądrze systemu operacyjnego (OS), bezpiecznym i bardziej ograniczonym środowisku, które dla większości systemów operacyjnych nie jest nawet open source. W związku z tym dostrajanie logiki przeciążenia jest zwykle wykonywane tylko przez kilku wybranych programistów, a ewolucja jest powolna.
W przeciwieństwie do tego, większość implementacji QUIC jest obecnie wykonywana w „przestrzeni użytkownika” (gdzie zwykle uruchamiamy natywne aplikacje) i jest udostępniana jako open source, wyraźnie, aby zachęcić do eksperymentowania przez znacznie szerszą pulę programistów (jak już pokazano, na przykład przez Facebooka). ).
Innym konkretnym przykładem jest propozycja rozszerzenia częstotliwości opóźnionego potwierdzenia dla QUIC. Chociaż domyślnie QUIC wysyła potwierdzenie co 2 odebrane pakiety, to rozszerzenie umożliwia punktom końcowym potwierdzanie, na przykład, co 10 pakietów. Wykazano, że daje to duże korzyści w zakresie prędkości w sieciach satelitarnych i sieciach o bardzo dużej przepustowości, ponieważ zmniejsza się obciążenie związane z transmisją pakietów potwierdzeń. Dodanie takiego rozszerzenia dla TCP zajęłoby dużo czasu, aby zostało przyjęte, podczas gdy dla QUIC jest znacznie łatwiejsze do wdrożenia.
W związku z tym możemy oczekiwać, że elastyczność QUIC doprowadzi z czasem do większej liczby eksperymentów i lepszych algorytmów kontroli przeciążenia, co z kolei może być również przeniesione do TCP, aby go ulepszyć.
Czy wiedziałeś?
Oficjalny QUIC Recovery RFC 9002 określa użycie algorytmu kontroli przeciążenia NewReno. Chociaż to podejście jest solidne, jest również nieco przestarzałe i nie jest już szeroko stosowane w praktyce. Dlaczego więc jest w QUIC RFC? Pierwszym powodem jest to, że kiedy QUIC został uruchomiony, NewReno był najnowszym algorytmem kontroli przeciążenia, który sam został ustandaryzowany. Bardziej zaawansowane algorytmy, takie jak BBR i CUBIC, albo wciąż nie są ustandaryzowane, albo dopiero niedawno stały się dokumentami RFC.
Drugim powodem jest to, że NewReno to stosunkowo prosta konfiguracja. Ponieważ algorytmy wymagają kilku poprawek, aby poradzić sobie z różnicami QUIC od TCP, łatwiej jest wyjaśnić te zmiany za pomocą prostszego algorytmu. W związku z tym RFC 9002 należy czytać bardziej jako „jak dostosować algorytm kontroli przeciążenia do QUIC”, a nie „to jest rzecz, której powinieneś użyć dla QUIC”. Rzeczywiście, większość wdrożeń QUIC na poziomie produkcyjnym ma niestandardowe implementacje zarówno Cubic, jak i BBR.
Należy powtórzyć, że algorytmy kontroli przeciążenia nie są specyficzne dla TCP lub QUIC ; mogą być używane przez oba protokoły i mamy nadzieję, że postępy w QUIC w końcu trafią również do stosów TCP.
Czy wiedziałeś?
Zauważ, że obok kontroli przeciążenia jest powiązana koncepcja zwana kontrolą przepływu. Te dwie funkcje są często mylone w TCP, ponieważ obie używają „okna TCP” , chociaż w rzeczywistości istnieją dwa okna: okno przeciążenia i okno odbioru TCP. Kontrola przepływu ma jednak znacznie mniejsze znaczenie w przypadku ładowania strony internetowej, która nas interesuje, więc pominiemy ją tutaj. Więcej szczegółowych informacji jest dostępnych.
Co to wszystko znaczy?
QUIC nadal jest związany prawami fizyki i potrzebą bycia miłym dla innych nadawców w Internecie. Oznacza to, że nie będzie magicznie pobierać zasobów Twojej witryny znacznie szybciej niż TCP. Jednak elastyczność QUIC oznacza, że eksperymentowanie z nowymi algorytmami kontroli przeciążenia stanie się łatwiejsze, co w przyszłości powinno poprawić sytuację zarówno w przypadku TCP, jak i QUIC.
Konfiguracja połączenia 0-RTT
Drugi aspekt wydajności dotyczy tego, ile podróży w obie strony trwa, zanim będzie można wysłać przydatne dane HTTP (np. zasoby strony) w nowym połączeniu. Niektórzy twierdzą, że QUIC jest od dwóch do nawet trzech podróży w obie strony szybszy niż TCP + TLS, ale zobaczymy, że tak naprawdę to tylko jeden.
Czy wiedziałeś?
Jak powiedzieliśmy w części 1, połączenie zazwyczaj wykonuje jedno (TCP) lub dwa (TCP + TLS) uzgadnianie przed wymianą żądań i odpowiedzi HTTP. Te uściski dłoni wymieniają początkowe parametry, które muszą znać zarówno klient, jak i serwer, aby na przykład zaszyfrować dane.
Jak widać na rysunku 2 poniżej, każdy uścisk dłoni wymaga co najmniej jednej podróży w obie strony (TCP + TLS 1.3, (b)) i czasami dwóch (TLS 1.2 i wcześniejsze (a)). Jest to nieefektywne, ponieważ potrzebujemy co najmniej dwóch podróży w obie strony czasu oczekiwania na uzgadnianie (narzut), zanim będziemy mogli wysłać nasze pierwsze żądanie HTTP, co oznacza czekanie co najmniej trzech podróży w obie strony na pierwsze dane odpowiedzi HTTP (powracająca czerwona strzałka) w. W wolnych sieciach może to oznaczać obciążenie od 100 do 200 milisekund.
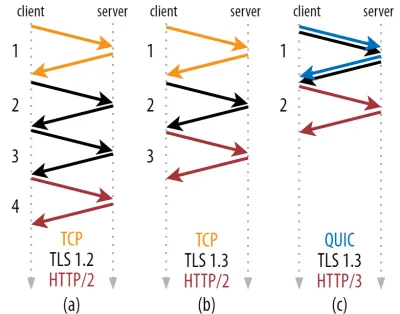
Być może zastanawiasz się, dlaczego uzgadniania TCP + TLS nie można po prostu połączyć, wykonać w tej samej podróży w obie strony. Chociaż jest to koncepcyjnie możliwe (QUIC robi dokładnie to), początkowo rzeczy nie zostały zaprojektowane w ten sposób, ponieważ musimy być w stanie używać TCP z i bez TLS na górze. Innymi słowy, TCP po prostu nie obsługuje wysyłania rzeczy innych niż TCP podczas uzgadniania. Podjęto wysiłki, aby dodać to za pomocą rozszerzenia TCP Fast Open; jednak, jak omówiono w części 1, okazało się to trudne do wdrożenia na dużą skalę.
Na szczęście QUIC został od początku zaprojektowany z myślą o TLS i jako taki łączy zarówno transport, jak i kryptograficzne uściski dłoni w jednym mechanizmie. Oznacza to, że uścisk dłoni QUIC zajmie w sumie tylko jedną podróż w obie strony, czyli o jedną podróż w obie strony mniej niż TCP + TLS 1.3 (patrz rysunek 2c powyżej).
Możesz być zdezorientowany, ponieważ prawdopodobnie czytałeś, że QUIC to dwie lub nawet trzy podróże w obie strony szybciej niż TCP, a nie tylko jedna. Dzieje się tak, ponieważ większość artykułów rozważa tylko najgorszy przypadek (TCP + TLS 1.2, (a)), nie wspominając o tym, że współczesny TCP + TLS 1.3 również „tylko” zajmuje dwie podróże w obie strony ((b) jest rzadko pokazywany). Chociaż zwiększenie prędkości podczas jednej podróży w obie strony jest fajne, nie jest to niesamowite. Zwłaszcza w szybkich sieciach (powiedzmy, mniej niż 50-milisekundowy RTT) będzie to ledwo zauważalne , chociaż wolne sieci i połączenia z odległymi serwerami przyniosą nieco większe korzyści.
Następnie możesz się zastanawiać, dlaczego w ogóle musimy czekać na uścisk dłoni. Dlaczego nie możemy wysłać żądania HTTP podczas pierwszej podróży w obie strony? Dzieje się tak głównie dlatego, że gdybyśmy to zrobili, to pierwsze żądanie zostałoby wysłane w postaci niezaszyfrowanej , możliwe do odczytania przez każdego podsłuchiwacza na przewodzie, co oczywiście nie jest dobre dla prywatności i bezpieczeństwa. W związku z tym przed wysłaniem pierwszego żądania HTTP musimy poczekać na zakończenie uzgadniania kryptograficznego. A może my?
Tutaj w praktyce stosuje się sprytną sztuczkę. Wiemy, że użytkownicy często ponownie odwiedzają strony internetowe w krótkim czasie od pierwszej wizyty. W związku z tym możemy użyć początkowego zaszyfrowanego połączenia , aby w przyszłości załadować drugie połączenie. Mówiąc najprościej, w pewnym momencie swojego życia pierwsze połączenie jest używane do bezpiecznego przekazywania nowych parametrów kryptograficznych między klientem a serwerem. Te parametry mogą następnie służyć do szyfrowania drugiego połączenia od samego początku, bez konieczności oczekiwania na zakończenie pełnego uzgadniania TLS. Takie podejście nazywa się „wznowieniem sesji” .
Pozwala to na potężną optymalizację: możemy teraz bezpiecznie wysłać nasze pierwsze żądanie HTTP wraz z uzgadnianiem QUIC/TLS, oszczędzając kolejną podróż w obie strony ! Jeśli chodzi o TLS 1.3, to skutecznie usuwa czas oczekiwania na uzgadnianie TLS. Ta metoda jest często nazywana 0-RTT (chociaż oczywiście nadal trwa jedna podróż w obie strony, aby dane odpowiedzi HTTP zaczęły napływać).
Zarówno wznowienie sesji, jak i 0-RTT to znowu rzeczy, które często błędnie wyjaśniałem jako funkcje specyficzne dla QUIC. W rzeczywistości są to w rzeczywistości funkcje TLS, które były już obecne w jakiejś formie w TLS 1.2, a teraz są w pełni rozwinięte w TLS 1.3.
Innymi słowy, jak widać na rysunku 3 poniżej, możemy uzyskać przewagę wydajnościową tych funkcji w porównaniu z TCP (a więc także HTTP/2, a nawet HTTP/1.1)! Widzimy, że nawet przy 0-RTT, QUIC jest wciąż tylko o jedną podróż szybszą niż optymalnie działający stos TCP + TLS 1.3. Twierdzenie, że QUIC jest szybszy o trzy podróże w obie strony, wynika z porównania cyfry 2 (a) z cyfrą 3 (f), co, jak widzieliśmy, nie jest naprawdę sprawiedliwe.
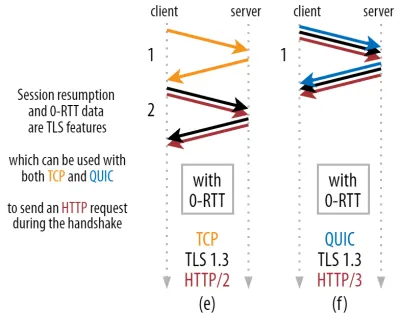
Najgorsze jest to, że podczas korzystania z 0-RTT, QUIC nie może nawet tak naprawdę wykorzystać zdobytej podróży w obie strony ze względu na bezpieczeństwo. Aby to zrozumieć, musimy zrozumieć jeden z powodów istnienia uzgadniania TCP. Po pierwsze, pozwala klientowi mieć pewność, że serwer jest rzeczywiście dostępny pod podanym adresem IP przed wysłaniem mu jakichkolwiek danych wyższej warstwy.
Po drugie, co najważniejsze, pozwala serwerowi upewnić się, że klient otwierający połączenie jest rzeczywiście tym, kim i gdzie się znajduje, zanim wyśle mu dane. Jeśli przypomnisz sobie, jak zdefiniowaliśmy połączenie z czwórką w części 1, będziesz wiedział, że klient jest identyfikowany głównie po jego adresie IP. I to jest problem: adresy IP można sfałszować !
Załóżmy, że atakujący żąda bardzo dużego pliku przez HTTP przez QUIC 0-RTT. Jednak podszywają się pod swój adres IP, przez co wygląda na to, że żądanie 0-RTT pochodzi z komputera ofiary. Pokazano to na rysunku 4 poniżej. Serwer QUIC nie ma możliwości wykrycia, czy adres IP został sfałszowany, ponieważ jest to pierwszy pakiet, który widzi od tego klienta.

Jeśli serwer po prostu zacznie wysyłać duży plik z powrotem do sfałszowanego adresu IP, może to skończyć się przeciążeniem przepustowości sieci ofiary (zwłaszcza jeśli atakujący wykonałby wiele fałszywych żądań równolegle). Zauważ, że odpowiedź QUIC zostałaby odrzucona przez ofiarę, ponieważ nie oczekuje danych przychodzących, ale to nie ma znaczenia: ich sieć nadal musi przetworzyć pakiety!
Nazywa się to odbiciem lub wzmocnieniem ataku i jest to znaczący sposób, w jaki hakerzy wykonują ataki rozproszonej odmowy usługi (DDoS). Należy zauważyć, że nie dzieje się tak, gdy używane jest połączenie 0-RTT przez TCP + TLS, właśnie dlatego, że uzgadnianie TCP musi zostać zakończone przed wysłaniem żądania 0-RTT wraz z uzgadnianiem TLS.
W związku z tym QUIC musi zachować ostrożność w odpowiadaniu na żądania 0-RTT, ograniczając ilość danych wysyłanych w odpowiedzi, dopóki klient nie zostanie zweryfikowany jako prawdziwy klient, a nie ofiara. W przypadku QUIC ta ilość danych została ustawiona na trzykrotność kwoty otrzymanej od klienta.
Innymi słowy, QUIC ma maksymalny „współczynnik wzmocnienia” wynoszący trzy, który został określony jako akceptowalny kompromis między użytecznością wydajności a ryzykiem bezpieczeństwa (szczególnie w porównaniu z niektórymi incydentami, które miały współczynnik wzmocnienia ponad 51 000 razy). Ponieważ klient zazwyczaj najpierw wysyła tylko jeden do dwóch pakietów, odpowiedź 0-RTT serwera QUIC będzie ograniczona do zaledwie 4 do 6 KB (w tym inne obciążenie QUIC i TLS!), co jest nieco mniej imponujące.
Ponadto inne problemy z bezpieczeństwem mogą prowadzić na przykład do ataków typu „powtórka”, które ograniczają typ żądań HTTP, które możesz wykonać. Na przykład Cloudflare zezwala tylko na żądania HTTP GET bez parametrów zapytania w 0-RTT. Ograniczają one jeszcze bardziej użyteczność 0-RTT.
Na szczęście QUIC ma opcje, aby to nieco poprawić. Na przykład serwer może sprawdzić, czy 0-RTT pochodzi z adresu IP, z którym wcześniej nawiązał prawidłowe połączenie. Działa to jednak tylko wtedy, gdy klient pozostaje w tej samej sieci (co ogranicza funkcję migracji połączenia QUIC). A nawet jeśli to działa, odpowiedź QUIC jest nadal ograniczona przez logikę powolnego startu kontrolera przeciążenia, o której mówiliśmy powyżej; więc nie ma dodatkowego ogromnego zwiększenia prędkości poza zapisaną jedną podróżą w obie strony.
Czy wiedziałeś?
Warto zauważyć, że trzykrotny limit wzmocnienia QUIC liczy się również dla normalnego procesu uzgadniania innego niż 0 RTT na rysunku 2c. Może to stanowić problem, jeśli na przykład certyfikat TLS serwera jest zbyt duży, aby zmieścić się w 4 do 6 KB. W takim przypadku musiałby zostać podzielony, a druga porcja musiałaby czekać na wysłanie drugiej podróży w obie strony (po potwierdzeniu nadejścia kilku pierwszych pakietów, co wskazuje, że adres IP klienta nie został sfałszowany). W takim przypadku uścisk dłoni QUIC może nadal zakończyć się dwoma podróżami w obie strony , równymi TCP + TLS! Dlatego dla QUIC techniki takie jak kompresja certyfikatów będą szczególnie ważne.
Czy wiedziałeś?
Możliwe, że niektóre zaawansowane konfiguracje są w stanie złagodzić te problemy na tyle, aby uczynić 0-RTT bardziej użytecznym. Na przykład serwer mógł zapamiętać przepustowość, jaką klient miał do dyspozycji ostatnim razem, gdy był widziany, co czyniło go mniej ograniczonym przez powolny start kontroli przeciążenia w celu ponownego połączenia (nie sfałszowanych) klientów. Zostało to zbadane w środowisku akademickim, a nawet w QUIC zaproponowano rozszerzenie, aby to zrobić. Kilka firm już robi tego typu rzeczy, aby przyspieszyć TCP.
Inną opcją byłoby wysłanie przez klientów więcej niż jednego lub dwóch pakietów (na przykład wysłanie 7 dodatkowych pakietów z dopełnieniem), więc trzykrotny limit przekłada się na bardziej interesującą odpowiedź od 12 do 14 KB, nawet po migracji połączenia. Pisałem o tym w jednym z moich artykułów.
Wreszcie (niewłaściwie zachowujące się) serwery QUIC mogą również celowo zwiększyć trzykrotny limit, jeśli uważają, że jest to w jakiś sposób bezpieczne lub jeśli nie przejmują się potencjalnymi problemami z bezpieczeństwem (w końcu nie ma na to żadnej policji protokołu).
Co to wszystko znaczy?
Szybsza konfiguracja połączenia QUIC z 0-RTT to naprawdę bardziej mikrooptymalizacja niż rewolucyjna nowa funkcja. W porównaniu z najnowocześniejszą konfiguracją TCP + TLS 1.3 zaoszczędziłoby to maksymalnie jedną podróż w obie strony. Ilość danych, które faktycznie można przesłać w pierwszej podróży w obie strony, jest dodatkowo ograniczona szeregiem względów bezpieczeństwa.
W związku z tym ta funkcja zabłyśnie, jeśli Twoi użytkownicy są w sieciach o bardzo dużych opóźnieniach (np. sieci satelitarne z RTT przekraczającymi 200 milisekund) lub jeśli zazwyczaj nie wysyłasz dużo danych. Niektóre przykłady tych ostatnich to silnie buforowane witryny internetowe, a także aplikacje jednostronicowe, które okresowo pobierają małe aktualizacje za pośrednictwem interfejsów API i innych protokołów, takich jak DNS-over-QUIC. Jednym z powodów, dla których Google widział bardzo dobre wyniki 0-RTT dla QUIC, było to, że przetestował je na już mocno zoptymalizowanej stronie wyszukiwania, gdzie odpowiedzi na zapytania są dość małe.
W innych przypadkach zyskasz w najlepszym razie tylko kilkadziesiąt milisekund , a nawet mniej, jeśli już korzystasz z CDN (co powinieneś robić, jeśli zależy ci na wydajności!).
Migracja połączenia
Trzecia funkcja zwiększająca wydajność sprawia, że QUIC jest szybszy podczas przesyłania między sieciami, utrzymując istniejące połączenia w stanie nienaruszonym . Chociaż to rzeczywiście działa, tego rodzaju zmiany sieci nie zdarzają się zbyt często, a połączenia nadal muszą zresetować swoje stawki wysyłania.
Jak omówiono w części 1, identyfikatory połączeń (CID) firmy QUIC umożliwiają migrację połączeń podczas przełączania sieci . Zilustrowaliśmy to na przykładzie klienta przechodzącego z sieci Wi-Fi na 4G podczas pobierania dużego pliku. W przypadku protokołu TCP może być konieczne przerwanie tego pobierania, podczas gdy w przypadku QUIC może być kontynuowane.
Najpierw jednak zastanów się, jak często tego typu scenariusze faktycznie się zdarzają. Możesz pomyśleć, że dzieje się tak również podczas przemieszczania się między punktami dostępu Wi-Fi w budynku lub między wieżami komórkowymi podczas podróży. Jednak w tych konfiguracjach (jeśli są one wykonane poprawnie) urządzenie zazwyczaj zachowuje swój adres IP w stanie nienaruszonym, ponieważ przejście między bezprzewodowymi stacjami bazowymi odbywa się w niższej warstwie protokołu. W związku z tym występuje tylko wtedy, gdy poruszasz się między zupełnie różnymi sieciami , co, powiedziałbym, nie zdarza się zbyt często.
Po drugie, możemy zapytać, czy działa to również w innych przypadkach użycia oprócz pobierania dużych plików oraz wideokonferencji na żywo i przesyłania strumieniowego. Jeśli ładujesz stronę internetową dokładnie w momencie przełączania sieci, może być konieczne ponowne zażądanie niektórych (późniejszych) zasobów.
Jednak ładowanie strony zwykle zajmuje kilka sekund, więc zbieganie się z przełącznikiem sieciowym również nie będzie zbyt częste. Ponadto w przypadkach użycia, w których jest to pilna sprawa, zwykle stosowane są już inne środki łagodzące . Na przykład serwery oferujące pobieranie dużych plików mogą obsługiwać żądania zakresu HTTP, aby umożliwić ponowne pobieranie.
Ponieważ zazwyczaj występuje pewien czas nakładania się między odłączeniem sieci 1 a udostępnieniem sieci 2, aplikacje wideo mogą otwierać wiele połączeń (po jednym na sieć), synchronizując je, zanim stara sieć całkowicie zniknie. Użytkownik nadal zauważy zmianę, ale nie spowoduje to całkowitego porzucenia kanału wideo.
Po trzecie, nie ma gwarancji, że nowa sieć będzie miała taką samą przepustowość jak stara. W związku z tym, mimo że połączenie koncepcyjne jest nienaruszone, serwer QUIC nie może po prostu wysyłać danych z dużą prędkością. Zamiast tego, aby uniknąć przeciążenia nowej sieci, musi ona zresetować (lub przynajmniej obniżyć) szybkość wysyłania i rozpocząć ponownie w fazie wolnego startu kontrolera przeciążenia.
Ponieważ ta początkowa szybkość wysyłania jest zwykle zbyt niska, aby naprawdę obsługiwać takie rzeczy, jak przesyłanie strumieniowe wideo, zauważysz pewną utratę jakości lub czkawkę, nawet na QUIC. W pewnym sensie migracja połączenia polega bardziej na zapobieganiu zmianom kontekstu połączenia i narzutom na serwerze niż na poprawie wydajności.
Czy wiedziałeś?
Zwróć uwagę, że jak omówiono powyżej dla 0-RTT, możemy opracować kilka zaawansowanych technik usprawniających migrację połączeń. Na przykład, możemy ponownie spróbować zapamiętać, jaka przepustowość była dostępna w danej sieci ostatnim razem i spróbować przyspieszyć do tego poziomu dla nowej migracji. Ponadto moglibyśmy sobie wyobrazić nie tylko przełączanie się między sieciami, ale używanie obu jednocześnie. Ta koncepcja nazywa się wielościeżkowa i omówimy ją bardziej szczegółowo poniżej.
Do tej pory mówiliśmy głównie o aktywnej migracji połączeń, w której użytkownicy przemieszczają się między różnymi sieciami. Zdarzają się jednak również przypadki pasywnej migracji połączeń, gdy dana sieć sama zmienia parametry. Dobrym tego przykładem jest ponowne wiązanie translacji adresów sieciowych (NAT). Chociaż pełne omówienie NAT jest poza zakresem tego artykułu, oznacza to głównie, że numery portów połączenia mogą się zmienić w dowolnym momencie, bez ostrzeżenia. Zdarza się to również znacznie częściej w przypadku UDP niż TCP w większości routerów.
Jeśli tak się stanie, QUIC CID nie zmieni się, a większość implementacji zakłada, że użytkownik nadal znajduje się w tej samej sieci fizycznej, a zatem nie zresetuje okna przeciążenia ani innych parametrów. QUIC zawiera również niektóre funkcje, takie jak PING i wskaźniki limitu czasu, aby temu zapobiec, ponieważ zwykle ma to miejsce w przypadku długich połączeń bezczynnych.
W części 1 omówiliśmy, że QUIC nie używa tylko jednego CID ze względów bezpieczeństwa. Zamiast tego zmienia identyfikatory CID podczas wykonywania aktywnej migracji. W praktyce jest to jeszcze bardziej skomplikowane, ponieważ zarówno klient, jak i serwer mają oddzielne listy CID (nazywane CID źródłowym i docelowym w QUIC RFC). Ilustruje to rysunek 5 poniżej.
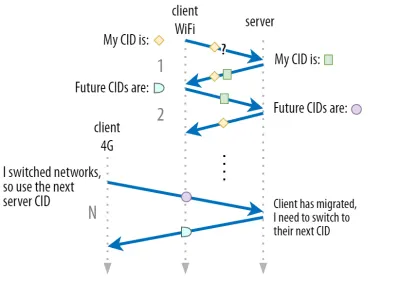
Ma to na celu umożliwienie każdemu punktowi końcowemu wyboru własnego formatu i zawartości CID , co z kolei ma kluczowe znaczenie dla umożliwienia zaawansowanej logiki routingu i równoważenia obciążenia. Dzięki migracji połączenia systemy równoważenia obciążenia nie mogą już patrzeć na 4 krotkę, aby zidentyfikować połączenie i wysłać je do właściwego serwera zaplecza. Jeśli jednak wszystkie połączenia QUIC miałyby używać losowych identyfikatorów CID, znacznie zwiększyłoby to wymagania dotyczące pamięci w systemie równoważenia obciążenia, ponieważ musiałby przechowywać mapowania identyfikatorów CID na serwery zaplecza. Ponadto nadal nie działałoby to w przypadku migracji połączenia, ponieważ identyfikatory CID zmieniają się na nowe wartości losowe.
W związku z tym ważne jest, aby serwery zaplecza QUIC wdrożone za modułem równoważenia obciążenia miały przewidywalny format swoich identyfikatorów CID, dzięki czemu moduł równoważenia obciążenia może uzyskać prawidłowy serwer zaplecza z identyfikatora CID, nawet po migracji. Niektóre możliwości wykonania tego są opisane w proponowanym dokumencie IETF. Aby było to możliwe, serwery muszą mieć możliwość wyboru własnego CID, co nie byłoby możliwe, gdyby inicjator połączenia (którym dla QUIC jest zawsze klient) wybrał CID. Dlatego w QUIC istnieje podział na identyfikatory CID klienta i serwera.

Co to wszystko znaczy?
Dlatego migracja połączenia jest funkcją sytuacyjną. Na przykład wstępne testy przeprowadzone przez Google pokazują niewielką poprawę procentową w przypadku jej użycia. Wiele implementacji QUIC nie zawiera jeszcze tej funkcji. Nawet te, które to robią, zazwyczaj ograniczają się do klientów i aplikacji mobilnych, a nie ich odpowiedników na komputery stacjonarne. Niektórzy uważają nawet, że ta funkcja nie jest potrzebna, ponieważ otwarcie nowego połączenia z 0-RTT powinno w większości przypadków mieć podobne właściwości wydajnościowe.
Mimo to, w zależności od przypadku użycia lub profilu użytkownika, może to mieć duży wpływ. Jeśli Twoja witryna lub aplikacja jest najczęściej używana w ruchu (np. Uber lub Mapy Google), prawdopodobnie odniesiesz większe korzyści niż w przypadku, gdy Twoi użytkownicy zwykle siedzą za biurkiem. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
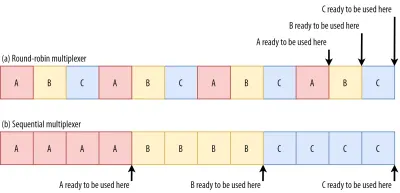
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
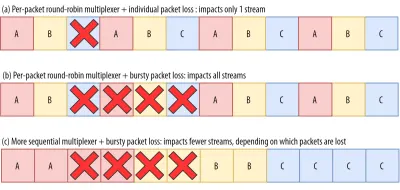
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
Co to wszystko znaczy?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
Wydajność UDP i TLS
Piąty aspekt wydajności QUIC i HTTP/3 dotyczy tego, jak wydajnie i wydajnie mogą faktycznie tworzyć i wysyłać pakiety w sieci. Zobaczymy, że użycie UDP i silnego szyfrowania przez QUIC może sprawić, że będzie on nieco wolniejszy niż TCP (ale sytuacja się poprawia).
Po pierwsze, omówiliśmy już, że użycie UDP przez QUIC było bardziej związane z elastycznością i możliwością wdrażania niż z wydajnością. Świadczy o tym jeszcze bardziej fakt, że do niedawna wysyłanie pakietów QUIC przez UDP było zwykle znacznie wolniejsze niż wysyłanie pakietów TCP. Wynika to częściowo z tego, gdzie i jak te protokoły są zazwyczaj implementowane (patrz rysunek 9 poniżej).
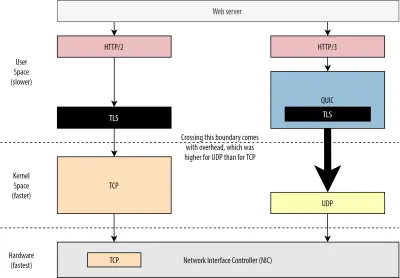
Jak omówiono powyżej, TCP i UDP są zazwyczaj implementowane bezpośrednio w szybkim jądrze systemu operacyjnego. W przeciwieństwie do tego, implementacje TLS i QUIC są w większości w wolniejszej przestrzeni użytkownika (zauważ, że nie jest to tak naprawdę potrzebne w przypadku QUIC — jest to głównie wykonywane, ponieważ jest znacznie bardziej elastyczne). To sprawia, że QUIC jest już nieco wolniejszy niż TCP.
Dodatkowo, wysyłając dane z naszego oprogramowania przestrzeni użytkownika (powiedzmy, przeglądarek i serwerów WWW), musimy przekazać te dane do jądra systemu operacyjnego , które następnie używa protokołu TCP lub UDP, aby faktycznie umieścić je w sieci. Przekazywanie tych danych odbywa się za pomocą API jądra (wywołań systemowych), co wiąże się z pewnym obciążeniem na wywołanie API. W przypadku TCP te koszty ogólne były znacznie niższe niż w przypadku UDP.
Dzieje się tak głównie dlatego, że historycznie TCP był używany znacznie częściej niż UDP. W związku z tym z biegiem czasu do implementacji TCP i interfejsów API jądra dodano wiele optymalizacji, aby zredukować do minimum koszty wysyłania i odbierania pakietów. Wiele kontrolerów interfejsu sieciowego (NIC) ma nawet wbudowane funkcje odciążania sprzętu dla protokołu TCP. UDP nie miał jednak tyle szczęścia, ponieważ jego bardziej ograniczone użycie nie uzasadniało inwestycji w dodatkowe optymalizacje. W ciągu ostatnich pięciu lat na szczęście się to zmieniło i większość systemów operacyjnych dodała również zoptymalizowane opcje dla UDP .
Po drugie, QUIC ma dużo narzutu, ponieważ szyfruje każdy pakiet indywidualnie . Jest to wolniejsze niż używanie TLS przez TCP, ponieważ można tam szyfrować pakiety porcjami (do około 16 KB lub 11 pakietów na raz), co jest bardziej wydajne. Był to świadomy kompromis dokonany w QUIC, ponieważ szyfrowanie zbiorcze może prowadzić do własnych form blokowania HoL.
W przeciwieństwie do pierwszego punktu, w którym moglibyśmy dodać dodatkowe interfejsy API, aby przyspieszyć UDP (a tym samym QUIC), tutaj QUIC zawsze będzie miał nieodłączną wadę TCP + TLS. Jednak w praktyce jest to również całkiem wykonalne dzięki, na przykład, zoptymalizowanym bibliotekom szyfrowania i sprytnym metodom, które umożliwiają masowe szyfrowanie nagłówków pakietów QUIC.
W rezultacie, chociaż najwcześniejsze wersje QUIC Google były wciąż dwa razy wolniejsze niż TCP + TLS, od tego czasu sytuacja z pewnością się poprawiła. Na przykład w ostatnich testach mocno zoptymalizowany stos QUIC Microsoftu był w stanie uzyskać 7,85 Gb/s w porównaniu do 11,85 Gb/s dla TCP + TLS w tym samym systemie (więc tutaj QUIC jest o 66% szybszy niż TCP + TLS).
Dzieje się tak w przypadku ostatnich aktualizacji systemu Windows, które przyspieszają UDP (dla pełnego porównania przepustowość UDP w tym systemie wynosiła 19,5 Gb/s). Najbardziej zoptymalizowana wersja stosu QUIC firmy Google jest obecnie o około 20% wolniejsza niż TCP + TLS. Wcześniejsze testy przeprowadzone przez Fastly na mniej zaawansowanym systemie i za pomocą kilku sztuczek wykazały nawet równą wydajność (około 450 Mb/s), pokazując, że w zależności od przypadku użycia QUIC może zdecydowanie konkurować z TCP.
Jednak nawet jeśli QUIC był dwa razy wolniejszy niż TCP + TLS, nie jest tak źle. Po pierwsze, przetwarzanie QUIC i TCP + TLS zwykle nie jest najcięższą rzeczą, jaka dzieje się na serwerze, ponieważ inna logika (powiedzmy, HTTP, buforowanie, proxy itp.) również musi zostać wykonana. W związku z tym nie będziesz potrzebować dwa razy więcej serwerów do uruchomienia QUIC (nie jest jasne, jak duży wpływ będzie to miało na prawdziwe centrum danych, ponieważ żadna z dużych firm nie opublikowała danych na ten temat).
Po drugie, wciąż istnieje wiele możliwości optymalizacji wdrożeń QUIC w przyszłości. Na przykład z biegiem czasu niektóre implementacje QUIC będą (częściowo) przenosić się do jądra systemu operacyjnego (podobnie jak TCP) lub je omijać (niektóre już to robią, takie jak MsQuic i Quant). Możemy się również spodziewać, że będzie dostępny sprzęt przeznaczony dla QUIC.
Mimo to prawdopodobnie będą pewne przypadki użycia, dla których preferowaną opcją pozostaną TCP + TLS. Na przykład Netflix zasygnalizował, że prawdopodobnie nie przejdzie na QUIC w najbliższym czasie, ponieważ mocno zainwestował w niestandardowe konfiguracje FreeBSD, aby przesyłać strumieniowo swoje filmy przez TCP + TLS.
Podobnie Facebook powiedział, że QUIC będzie prawdopodobnie używany głównie między użytkownikami końcowymi a brzegiem CDN , ale nie między centrami danych lub między węzłami brzegowymi a serwerami pochodzenia, ze względu na większe obciążenie. Ogólnie rzecz biorąc, scenariusze o bardzo dużej przepustowości prawdopodobnie nadal będą faworyzować TCP + TLS, zwłaszcza w ciągu najbliższych kilku lat.
Czy wiedziałeś?
Optymalizacja stosów sieciowych to głęboka i techniczna królicza nora, której powyższe jedynie zarysowuje powierzchnię (i pomija wiele niuansów). Jeśli jesteś wystarczająco odważny lub chcesz wiedzieć, co oznaczają terminy, takie jakGRO/GSO,SO_TXTIME, kernel bypass orazsendmmsg()irecvmmsg(), mogę polecić kilka doskonałych artykułów na temat optymalizacji QUIC przez Cloudflare i Fastly jako obszerny przewodnik po kodzie autorstwa Microsoft i szczegółową rozmowę z Cisco. Na koniec inżynier Google wygłosił bardzo interesującą przemowę na temat optymalizacji ich implementacji QUIC w czasie.
Co to wszystko znaczy?
Szczególne wykorzystanie przez QUIC protokołów UDP i TLS sprawiało, że w przeszłości był on znacznie wolniejszy niż TCP + TLS. Jednak z biegiem czasu wprowadzono kilka ulepszeń (i będą one nadal wdrażane), które nieco zmniejszyły lukę. Prawdopodobnie nie zauważysz tych rozbieżności w typowych przypadkach ładowania stron internetowych, ale mogą one przysporzyć Ci bólu głowy, jeśli będziesz utrzymywać duże farmy serwerów.
Funkcje HTTP/3
Do tej pory rozmawialiśmy głównie o nowych funkcjach wydajności w QUIC w porównaniu z TCP. A co z HTTP/3 w porównaniu z HTTP/2? Jak omówiono w części 1, HTTP/3 to tak naprawdę HTTP/2-over-QUIC i jako taki nie wprowadzono żadnych prawdziwych, dużych nowych funkcji w nowej wersji. Jest to w przeciwieństwie do przejścia z HTTP/1.1 na HTTP/2, które było znacznie większe i wprowadziło nowe funkcje, takie jak kompresja nagłówków, priorytetyzacja strumieni i push serwera. Wszystkie te funkcje są nadal dostępne w HTTP/3, ale istnieją pewne ważne różnice w sposobie ich implementacji pod maską.
Wynika to głównie z tego, jak działa usuwanie blokowania HoL przez QUIC. Jak już wspomnieliśmy, strata w strumieniu B nie oznacza już, że strumienie A i C będą musiały czekać na retransmisję B, tak jak w przypadku TCP. W związku z tym, jeśli A, B i C wysłały pakiet QUIC w tej kolejności, ich dane mogą zostać dostarczone do przeglądarki (i przetworzone przez) jako A, C, B! Innymi słowy, w przeciwieństwie do TCP, QUIC nie jest już w pełni uporządkowany w różnych strumieniach!
Jest to problem dla protokołu HTTP/2, który tak naprawdę opierał się na ścisłej kolejności TCP przy projektowaniu wielu swoich funkcji, które wykorzystują specjalne komunikaty kontrolne przeplatane fragmentami danych. W QUIC te komunikaty kontrolne mogą pojawiać się (i być stosowane) w dowolnej kolejności, potencjalnie nawet powodując, że funkcje działają odwrotnie do zamierzonego! Szczegóły techniczne są ponownie niepotrzebne w tym artykule, ale pierwsza połowa tego artykułu powinna dać wyobrażenie o tym, jak głupio to może się stać.
W związku z tym wewnętrzna mechanika i implementacja funkcji musiały ulec zmianie dla HTTP/3. Konkretnym przykładem jest kompresja nagłówków HTTP , która zmniejsza obciążenie powtarzających się dużych nagłówków HTTP (na przykład plików cookie i ciągów agenta użytkownika). W HTTP/2 zrobiono to za pomocą konfiguracji HPACK, podczas gdy w przypadku HTTP/3 zostało to przerobione na bardziej złożony QPACK. Oba systemy zapewniają tę samą funkcję (tj. kompresję nagłówków), ale w zupełnie inny sposób. Kilka doskonałych, głębokich dyskusji technicznych i diagramów na ten temat można znaleźć na blogu Litespeed.
Coś podobnego dotyczy funkcji ustalania priorytetów, która steruje logiką multipleksowania strumieniowego i którą krótko omówiliśmy powyżej. W HTTP/2 zostało to zaimplementowane przy użyciu złożonej konfiguracji „drzewa zależności”, która wyraźnie próbowała modelować wszystkie zasoby strony i ich wzajemne powiązania (więcej informacji można znaleźć w dyskusji „The Ultimate Guide to HTTP Resource Prioritization”). Używanie tego systemu bezpośrednio przez QUIC prowadziłoby do potencjalnie bardzo błędnych układów drzewa, ponieważ dodanie każdego zasobu do drzewa byłoby osobnym komunikatem kontrolnym.
Dodatkowo to podejście okazało się niepotrzebnie skomplikowane, co doprowadziło do wielu błędów implementacji i nieefektywności oraz słabej wydajności na wielu serwerach. Oba problemy doprowadziły do przeprojektowania systemu priorytetów dla HTTP/3 w znacznie prostszy sposób. Ta prostsza konfiguracja sprawia, że niektóre zaawansowane scenariusze są trudne lub niemożliwe do wyegzekwowania (na przykład proxy ruchu z wielu klientów w jednym połączeniu), ale nadal udostępnia szeroki zakres opcji optymalizacji ładowania stron internetowych.
Chociaż, ponownie, te dwa podejścia zapewniają tę samą podstawową funkcję (kierowanie multipleksowaniem strumienia), istnieje nadzieja, że łatwiejsza konfiguracja HTTP/3 spowoduje mniej błędów w implementacji.
Wreszcie jest serwer push . Ta funkcja umożliwia serwerowi wysyłanie odpowiedzi HTTP bez wcześniejszego oczekiwania na wyraźne żądanie. Teoretycznie może to zapewnić doskonały wzrost wydajności. W praktyce okazało się to jednak trudne do prawidłowego i niekonsekwentnego wdrożenia. W rezultacie prawdopodobnie zostanie nawet usunięty z Google Chrome.
Mimo to nadal jest definiowana jako funkcja w HTTP/3 (chociaż niewiele implementacji ją obsługuje). Chociaż jego wewnętrzne działanie nie zmieniło się tak bardzo, jak poprzednie dwie funkcje, również został przystosowany do obejścia niedeterministycznego porządkowania QUIC. Niestety, to niewiele pomoże rozwiązać niektóre z jego długotrwałych problemów.
Co to wszystko znaczy?
Jak powiedzieliśmy wcześniej, większość potencjału HTTP/3 pochodzi z bazowego QUIC, a nie z samego HTTP/3. Chociaż wewnętrzna implementacja protokołu bardzo różni się od HTTP/2, jego funkcje wydajności na wysokim poziomie oraz sposób, w jaki mogą i powinny być używane, pozostały takie same.
Przyszłe zmiany, na które należy zwrócić uwagę
W tej serii regularnie podkreślałem, że szybsza ewolucja i większa elastyczność to podstawowe aspekty QUIC (i, co za tym idzie, HTTP/3). W związku z tym nie powinno dziwić, że ludzie już pracują nad nowymi rozszerzeniami i aplikacjami protokołów. Poniżej wymieniono główne z nich, które prawdopodobnie napotkasz gdzieś w dalszej części linii:
Korekcja błędów w przód
Celem tej techniki jest, ponownie, poprawa odporności QUIC na utratę pakietów . Robi to, wysyłając nadmiarowe kopie danych (choć sprytnie zakodowane i skompresowane, aby nie były tak duże). Następnie, jeśli pakiet zostanie utracony, ale nadeszły nadmiarowe dane, retransmisja nie jest już potrzebna.
Pierwotnie był to element Google QUIC (i jeden z powodów, dla których ludzie twierdzą, że QUIC jest dobry w walce z utratą pakietów), ale nie jest zawarty w standardowej wersji QUIC 1, ponieważ jego wpływ na wydajność nie został jeszcze udowodniony. Naukowcy przeprowadzają teraz z nim aktywne eksperymenty, a Ty możesz im pomóc, korzystając z aplikacji PQUIC-FEC Download Experiments.Wielościeżkowy QUIC
Omówiliśmy wcześniej migrację połączenia i sposób, w jaki może to pomóc w przejściu, powiedzmy, z Wi-Fi na sieć komórkową. Czy nie oznacza to jednak, że możemy jednocześnie korzystać z sieci Wi-Fi i sieci komórkowej? Jednoczesne korzystanie z obu sieci zapewniłoby nam większą dostępną przepustowość i zwiększoną niezawodność! To jest główna koncepcja wielościeżkowa.
Ponownie jest to coś, z czym Google eksperymentował, ale nie trafiło do wersji 1 QUIC ze względu na jego wrodzoną złożoność. Jednak od tego czasu badacze wykazali jego wysoki potencjał i może dojść do wersji QUIC 2. Należy zauważyć, że wielościeżkowy protokół TCP również istnieje, ale zajęło to prawie dziesięć lat, zanim stał się praktycznie użyteczny.Niewiarygodne dane przez QUIC i HTTP/3
Jak widzieliśmy, QUIC jest w pełni niezawodnym protokołem. Ponieważ jednak działa przez UDP, który jest zawodny, możemy dodać funkcję do QUIC, aby również wysyłać niewiarygodne dane. Zostało to nakreślone w proponowanym rozszerzeniu datagramu. Oczywiście nie chcesz używać tego do wysyłania zasobów stron internetowych, ale może to być przydatne w przypadku gier i strumieniowego przesyłania wideo na żywo. W ten sposób użytkownicy uzyskaliby wszystkie zalety UDP, ale z szyfrowaniem na poziomie QUIC i (opcjonalną) kontrolą przeciążenia.WebTransport
Przeglądarki nie udostępniają TCP ani UDP bezpośrednio w JavaScript, głównie ze względów bezpieczeństwa. Zamiast tego musimy polegać na interfejsach API na poziomie HTTP, takich jak Fetch i nieco bardziej elastycznych protokołach WebSocket i WebRTC. Najnowsza z tej serii opcji nazywa się WebTransport, która umożliwia głównie korzystanie z protokołu HTTP/3 (a co za tym idzie, QUIC) w bardziej niskopoziomowy sposób (chociaż w razie potrzeby może również wrócić do TCP i HTTP/2 ).
Co najważniejsze, będzie obejmować możliwość korzystania z niewiarygodnych danych przez HTTP/3 (patrz poprzedni punkt), co powinno znacznie ułatwić wdrażanie takich rzeczy, jak granie w przeglądarce. W przypadku normalnych wywołań API (JSON) będziesz oczywiście nadal używać Fetch, który również automatycznie zastosuje HTTP/3, jeśli to możliwe. WebTransport jest nadal przedmiotem intensywnych dyskusji, więc nie jest jeszcze jasne, jak ostatecznie będzie wyglądać. Spośród przeglądarek tylko Chromium pracuje obecnie nad publiczną implementacją weryfikacyjną.Przesyłanie strumieniowe wideo DASH i HLS
W przypadku wideo niena żywo (na przykład YouTube i Netflix) przeglądarki zazwyczaj korzystają z protokołu Dynamic Adaptive Streaming over HTTP (DASH) lub HTTP Live Streaming (HLS). Oba zasadniczo oznaczają, że kodujesz swoje filmy na mniejsze fragmenty (od 2 do 10 sekund) i różne poziomy jakości (720p, 1080p, 4K itp.).
W czasie wykonywania przeglądarka szacuje najwyższą jakość, jaką może obsłużyć Twoja sieć (lub najbardziej optymalną dla danego przypadku użycia) i żąda odpowiednich plików z serwera przez HTTP. Ponieważ przeglądarka nie ma bezpośredniego dostępu do stosu TCP (co jest zwykle implementowane w jądrze), czasami popełnia kilka błędów w tych szacunkach lub reakcja na zmieniające się warunki sieciowe zajmuje trochę czasu (prowadząc do przestojów wideo). .
Ponieważ QUIC jest zaimplementowany jako część przeglądarki, można to znacznie poprawić, dając estymatorom strumieniowym dostęp do informacji o protokole niskiego poziomu (takich jak współczynniki strat, szacunki przepustowości itp.). Inni badacze eksperymentowali również z mieszaniem wiarygodnych i niewiarygodnych danych do przesyłania strumieniowego wideo, z pewnymi obiecującymi wynikami.Protokoły inne niż HTTP/3
Ponieważ QUIC jest protokołem transportowym ogólnego przeznaczenia, możemy oczekiwać, że wiele protokołów warstwy aplikacji, które teraz działają przez TCP, będzie również uruchamianych na szczycie QUIC. Niektóre prace w toku obejmują DNS-over-QUIC, SMB-over-QUIC, a nawet SSH-over-QUIC. Ponieważ te protokoły zazwyczaj mają bardzo różne wymagania niż HTTP i ładowanie stron internetowych, ulepszenia wydajności QUIC, które omówiliśmy, mogą działać znacznie lepiej w przypadku tych protokołów.
Co to wszystko znaczy?
QUIC wersja 1 to dopiero początek . Wiele zaawansowanych funkcji zorientowanych na wydajność, z którymi Google wcześniej eksperymentował, nie znalazło się w tej pierwszej iteracji. Jednak celem jest szybka ewolucja protokołu, wprowadzanie nowych rozszerzeń i funkcji z dużą częstotliwością. W związku z tym z biegiem czasu QUIC (i HTTP/3) powinien stać się wyraźnie szybszy i bardziej elastyczny niż TCP (i HTTP/2).
Wniosek
W drugiej części serii omówiliśmy wiele różnych funkcji wydajnościowych i aspektów HTTP/3 , a zwłaszcza QUIC. Widzieliśmy, że chociaż większość z tych funkcji wydaje się mieć duży wpływ, w praktyce mogą one nie wystarczyć dla przeciętnego użytkownika w przypadku ładowania strony internetowej, które rozważaliśmy.
Na przykład widzieliśmy, że użycie UDP przez QUIC nie oznacza, że może nagle użyć większej przepustowości niż TCP, ani nie oznacza, że może szybciej pobierać zasoby. Często chwalona funkcja 0-RTT to tak naprawdę mikrooptymalizacja, która pozwala zaoszczędzić jedną podróż w obie strony, w której można wysłać około 5 KB (w najgorszym przypadku).
Usuwanie blokowania HoL nie działa dobrze, jeśli dochodzi do gwałtownej utraty pakietów lub podczas ładowania zasobów blokujących renderowanie. Migracja połączenia jest wysoce sytuacyjna, a HTTP/3 nie ma żadnych większych nowych funkcji, które mogłyby sprawić, że będzie szybszy niż HTTP/2.
W związku z tym możesz oczekiwać, że zalecę pominięcie HTTP/3 i QUIC. Po co się męczyć, prawda? Jednak zdecydowanie nie zrobię czegoś takiego! Mimo że te nowe protokoły mogą nie pomagać użytkownikom w szybkich (miejskich) sieciach, nowe funkcje z pewnością mogą mieć duży wpływ na użytkowników wysoce mobilnych i osoby korzystające z wolnych sieci.
Nawet na rynkach zachodnich, takich jak moja własna Belgia, gdzie generalnie mamy szybkie urządzenia i dostęp do szybkich sieci komórkowych, takie sytuacje mogą mieć wpływ na 1% do nawet 10% bazy użytkowników, w zależności od produktu. Przykładem może być ktoś w pociągu, który desperacko próbuje wyszukać ważne informacje w Twojej witrynie, ale musi czekać 45 sekund, aż się załadują. Z pewnością wiem, że byłem w takiej sytuacji, żałując, że ktoś nie wdrożył QUIC, aby mnie z tego wyciągnąć.
Są jednak inne kraje i regiony, w których sytuacja jest jeszcze gorsza. Tam przeciętny użytkownik może bardziej przypominać najwolniejsze 10% w Belgii, a najwolniejszy 1% może w ogóle nie zobaczyć załadowanej strony. W wielu częściach świata wydajność sieci jest problemem dostępności i integracji.
Dlatego nigdy nie powinniśmy testować naszych stron na naszym własnym sprzęcie (ale także korzystać z usługi takiej jak Webpagetest), a także dlatego zdecydowanie powinieneś wdrożyć QUIC i HTTP/3 . Zwłaszcza jeśli Twoi użytkownicy są często w ruchu lub prawdopodobnie nie mają dostępu do szybkich sieci komórkowych, te nowe protokoły mogą mieć ogromne znaczenie, nawet jeśli nie zauważysz zbyt wiele na przewodowym MacBooku Pro. Po więcej szczegółów gorąco polecam post Fastly na ten temat.
Jeśli to Cię nie przekonuje, weź pod uwagę, że QUIC i HTTP/3 będą nadal ewoluować i stawać się coraz szybsze w nadchodzących latach. Wcześniejsze doświadczenie z protokołami opłaci się w przyszłości, umożliwiając jak najszybsze czerpanie korzyści z nowych funkcji. Ponadto QUIC w tle wymusza najlepsze praktyki w zakresie bezpieczeństwa i prywatności, z których korzystają wszyscy użytkownicy na całym świecie.
W końcu przekonany? Następnie przejdź do części 3 serii, aby przeczytać o tym, jak możesz wykorzystać nowe protokoły w praktyce.
- Część 1: Historia HTTP/3 i podstawowe koncepcje
Ten artykuł jest skierowany do osób, które nie znają protokołu HTTP/3 i protokołów w ogóle, i omawia głównie podstawy. - Część 2: Funkcje wydajności HTTP/3
Ten jest bardziej dogłębny i techniczny. Tutaj mogą zacząć osoby, które już znają podstawy. - Część 3: Praktyczne opcje wdrażania HTTP/3
Ten trzeci artykuł z serii wyjaśnia wyzwania związane z samodzielnym wdrażaniem i testowaniem HTTP/3. Opisuje również, jak i czy powinieneś zmienić swoje strony internetowe i zasoby.