
Jak wdrożyć klasyfikację w uczeniu maszynowym?
Opublikowany: 2021-03-12Zastosowanie uczenia maszynowego w różnych dziedzinach wzrosło skokowo w ciągu ostatnich kilku lat i nadal tak się dzieje. Jednym z najpopularniejszych zadań modelu uczenia maszynowego jest rozpoznawanie obiektów i rozdzielanie ich na wyznaczone klasy.
Jest to metoda klasyfikacji, która jest jedną z najpopularniejszych aplikacji uczenia maszynowego. Klasyfikacja służy do rozdzielenia ogromnej ilości danych na zestaw wartości dyskretnych, które mogą być binarne, takie jak 0/1, Tak/Nie, lub wieloklasowe, takie jak zwierzęta, samochody, ptaki itp.
W poniższym artykule zrozumiemy pojęcie klasyfikacji w uczeniu maszynowym, rodzaje danych, których dotyczy, i zobaczymy niektóre z najpopularniejszych algorytmów klasyfikacji używanych w uczeniu maszynowym do klasyfikowania kilku danych.
Spis treści
Co to jest uczenie nadzorowane?
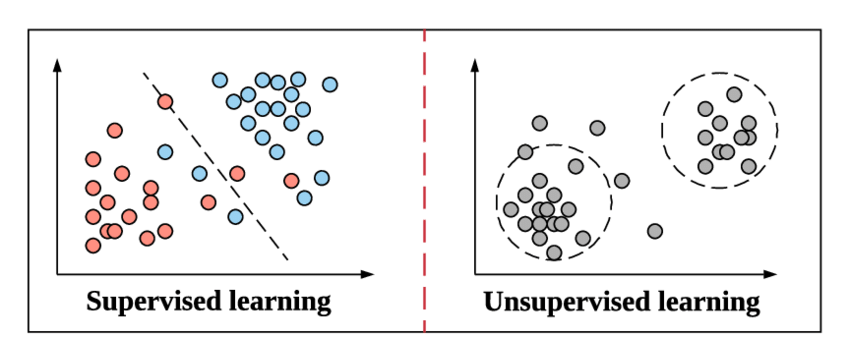
Gdy przygotowujemy się do zagłębienia się w koncepcję klasyfikacji i jej rodzaje, szybko odświeżmy się, co oznacza uczenie nadzorowane i czym różni się od innych metod uczenia się bez nadzoru w uczeniu maszynowym.
Zrozummy to, biorąc prosty przykład z naszej klasy fizyki w liceum. Załóżmy, że istnieje prosty problem związany z nową metodą. Gdybyśmy przedstawili nam pytanie, w którym musimy rozwiązać tą samą metodą, czy nie wszyscy odwołalibyśmy się do przykładowego problemu tą samą metodą i nie spróbowalibyśmy go rozwiązać. Gdy jesteśmy już pewni tej metody, nie musimy się do niej ponownie odwoływać i kontynuować jej rozwiązywanie.
Źródło

Jest to ten sam sposób, w jaki uczenie nadzorowane działa w uczeniu maszynowym. Uczy się na przykładzie. Aby było to jeszcze prostsze, w nadzorowanym uczeniu wszystkie dane są zasilane odpowiednimi etykietami, a zatem podczas procesu uczenia model uczenia maszynowego porównuje swoje dane wyjściowe dla określonych danych z prawdziwymi danymi wyjściowymi tych samych danych i próbuje zminimalizować błąd między przewidywaną i rzeczywistą wartością etykiety.
Algorytmy klasyfikacji, które omówimy w tym artykule, wykorzystują tę metodę nadzorowanego uczenia się — na przykład wykrywanie spamu i rozpoznawanie obiektów.
Nienadzorowane uczenie się to krok powyżej, w którym dane nie są zasilane z ich etykietami. Wyprowadzanie wzorców z danych i dostarczanie wyników zależy od odpowiedzialności i wydajności modelu uczenia maszynowego. Algorytmy klastrowania stosują tę nienadzorowaną metodę uczenia się.
Co to jest klasyfikacja?
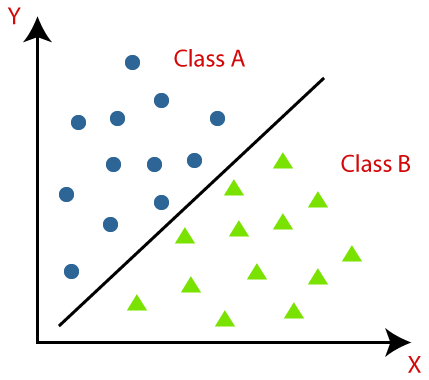
Klasyfikacja jest definiowana jako rozpoznawanie, rozumienie i grupowanie obiektów lub danych w określone klasy. Kategoryzując dane przed procesem uczenia modelu uczenia maszynowego, możemy użyć różnych algorytmów klasyfikacji do sklasyfikowania danych na kilka klas. W przeciwieństwie do regresji problem z klasyfikacją występuje, gdy zmienna wyjściowa jest kategorią, taką jak „Tak” lub „Nie”, „Choroba” lub „Brak choroby”.
W większości problemów z uczeniem maszynowym, po załadowaniu zestawu danych do programu, przed uczeniem, dzielenie zestawu danych na zestaw uczący i zestaw testowy ze stałym współczynnikiem (zwykle 70% zestaw uczący i 30% zestaw testowy). Ten proces podziału umożliwia modelowi wykonanie wstecznej propagacji błędów, w której próbuje skorygować swój błąd wartości przewidywanej względem wartości prawdziwej za pomocą kilku matematycznych przybliżeń.
Podobnie, zanim rozpoczniemy klasyfikację, tworzony jest treningowy zestaw danych. Algorytm klasyfikacji jest szkolony w tym zakresie podczas testowania zestawu danych testowych w każdej iteracji, zwanej epoką.
Źródło
Jedną z najczęstszych aplikacji algorytmów klasyfikacji jest filtrowanie wiadomości e-mail pod kątem tego, czy są one „spamem”, czy „nie spamem”. Krótko mówiąc, możemy zdefiniować klasyfikację w uczeniu maszynowym jako formę „rozpoznawania wzorców”, w której te algorytmy, które są stosowane do danych uczących, są używane do wyodrębniania kilku wzorców z danych (takich jak podobne słowa lub sekwencje liczb, nastroje itp. .).
Klasyfikacja to proces kategoryzacji danego zestawu danych na klasy; może być wykonywany zarówno na danych ustrukturyzowanych, jak i nieustrukturyzowanych. Rozpoczyna się od przewidzenia klasy danych punktów. Klasy te są również nazywane zmiennymi wyjściowymi, etykietami docelowymi itp. Kilka algorytmów ma wbudowane funkcje matematyczne w celu aproksymacji funkcji mapowania ze zmiennych punktów danych wejściowych do wyjściowej klasy docelowej. Podstawowym celem klasyfikacji jest określenie, do której klasy/kategorii będą należeć nowe dane.
Rodzaje algorytmów klasyfikacji w uczeniu maszynowym
W zależności od rodzaju danych, do których stosowane są algorytmy klasyfikacji, istnieją dwie szerokie kategorie algorytmów, modele liniowe i nieliniowe.
Modele liniowe
- Regresja logistyczna
- Maszyny wektorów nośnych (SVM)
Modele nieliniowe
- Klasyfikacja K-Najbliżsi Sąsiedzi (KNN)
- Jądro SVM
- Naiwna klasyfikacja Bayesa
- Klasyfikacja drzewa decyzyjnego
- Klasyfikacja lasów losowych
W tym artykule pokrótce omówimy koncepcję każdego z wyżej wymienionych algorytmów.
Ocena modelu klasyfikacji w uczeniu maszynowym
Zanim przejdziemy do wspomnianych powyżej koncepcji tych algorytmów, musimy zrozumieć, w jaki sposób możemy ocenić nasz model uczenia maszynowego zbudowany na podstawie tych algorytmów. Niezbędna jest ocena naszego modelu pod kątem dokładności zarówno w zbiorze uczącym, jak i zbiorze testowym.
Utrata entropii krzyżowej lub utrata dziennika
Jest to pierwszy rodzaj funkcji straty, której użyjemy do oceny wydajności klasyfikatora, którego dane wyjściowe mieszczą się w zakresie od 0 do 1. Jest to najczęściej używane w modelach klasyfikacji binarnej. Formuła Log Loss jest podana przez,
Strata dziennika = -((1 – y) * log(1 – yhat) + y * log(yhat))
Gdzie jest to wartość przewidywana, a y jest wartością rzeczywistą.
Matryca zamieszania
Macierz pomyłek to macierz NXN, gdzie N jest liczbą przewidywanych klas. Macierz pomyłek dostarcza nam macierz/tabelę jako dane wyjściowe i opisuje wydajność modelu. Składa się z wyników przewidywań w postaci macierzy, z której możemy wyprowadzić kilka metryk wydajności w celu oceny modelu klasyfikacji. Ma formę,
| Rzeczywista pozytywna | Rzeczywista negatywna | |
| Przewidywany pozytywny | Prawdziwie pozytywne | Fałszywe pozytywne |
| Przewidywany negatywny | Fałszywy negatyw | Prawdziwie negatywne |
Kilka wskaźników wydajności, które można wyprowadzić z powyższej tabeli, podano poniżej.
1.Dokładność – odsetek całkowitej liczby poprawnych prognoz.
2. Dodatnia wartość predykcyjna lub precyzja – odsetek pozytywnych przypadków, które zostały poprawnie zidentyfikowane.
3. Negatywna wartość predykcyjna – odsetek przypadków negatywnych, które zostały poprawnie zidentyfikowane.
4. Wrażliwość lub przypomnienie – odsetek rzeczywiście pozytywnych przypadków, które zostały prawidłowo zidentyfikowane.
5. Specyfika – odsetek rzeczywistych przypadków negatywnych, które zostały prawidłowo zidentyfikowane.
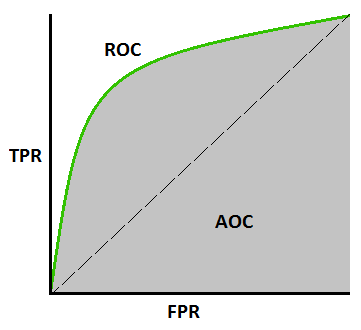
Krzywa AUC-ROC –
To kolejna ważna metryka krzywej, która ocenia dowolny model uczenia maszynowego. Krzywa ROC oznacza krzywą charakterystyki pracy odbiornika, a AUC oznacza obszar pod krzywą. Krzywa ROC jest wykreślana z TPR i FPR, gdzie TPR (współczynnik prawdziwie dodatnich) na osi Y i FPR (współczynnik wyników fałszywie dodatnich) na osi X. Pokazuje wydajność modelu klasyfikacji na różnych progach.
Źródło
1. Regresja logistyczna
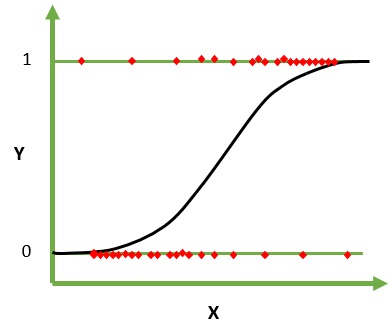
Regresja logistyczna to algorytm uczenia maszynowego do klasyfikacji. W tym algorytmie prawdopodobieństwa opisujące możliwe wyniki pojedynczego badania są modelowane za pomocą funkcji logistycznej. Zakłada, że zmienne wejściowe są liczbowe i mają rozkład Gaussa (krzywa dzwonowa).
Funkcja logistyczna, zwana także funkcją sigmoidalną, była początkowo używana przez statystyków do opisu wzrostu populacji w ekologii. Funkcja sigmoidalna to funkcja matematyczna używana do mapowania przewidywanych wartości na prawdopodobieństwa. Regresja logistyczna ma krzywą w kształcie litery S i może przyjmować wartości od 0 do 1, ale nigdy dokładnie w tych granicach.

Źródło
Regresja logistyczna służy przede wszystkim do przewidywania wyniku binarnego, takiego jak Tak/Nie i Zaliczenie/Niepowodzenie. Zmienne niezależne mogą być jakościowe lub numeryczne, ale zmienna zależna jest zawsze jakościowa. Wzór na regresję logistyczną podaje wzór,
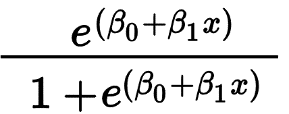
Gdzie e reprezentuje krzywą w kształcie litery S, która ma wartości od 0 do 1.
2. Wsparcie maszyn wektorowych
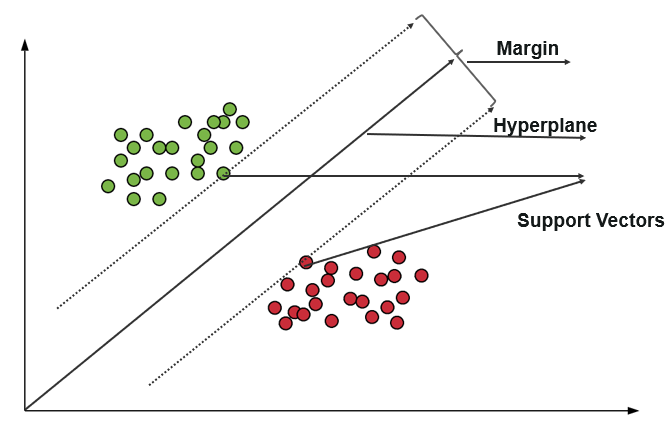
Maszyna wektorów nośnych (SVM) wykorzystuje algorytmy do trenowania i klasyfikowania danych w stopniach polaryzacji, przenosząc je w stopniu wykraczającym poza przewidywanie X/Y. W SVM linia używana do oddzielenia klas jest określana jako Hyperplane. Punkty danych po obu stronach Hyperplane najbliżej Hyperplane są nazywane wektorami pomocniczymi używanymi do wykreślania linii granicznej.
Ta maszyna wektorów nośnych w klasyfikacji reprezentuje dane uczące jako punkty danych w przestrzeni, w której wiele kategorii jest rozdzielonych na kategorie Hyperplane. Kiedy pojawia się nowy punkt, jest on klasyfikowany przez przewidywanie, do której kategorii należy i należą do określonej przestrzeni.
Źródło
Głównym celem maszyny wektorów nośnych jest maksymalizacja marginesu między dwoma wektorami nośnymi.
Dołącz do kursu ML online z najlepszych uniwersytetów na świecie — Masters, Executive Post Graduate Programs i Advanced Certificate Program w ML & AI, aby przyspieszyć swoją karierę.
3. Klasyfikacja K-Najbliżsi Sąsiedzi (KNN)
Klasyfikacja KNN jest jednym z najprostszych algorytmów Klasyfikacji, ale jest wysoce stosowana ze względu na wysoką wydajność i łatwość użycia. W tej metodzie cały zestaw danych jest początkowo przechowywany na komputerze. Następnie wybierana jest wartość – k, która reprezentuje liczbę sąsiadów. W ten sposób, kiedy nowy punkt danych jest dodawany do zbioru danych, bierze on większość głosów etykiety klasy k najbliższych sąsiadów na ten nowy punkt danych. Dzięki temu głosowaniu nowy punkt danych jest dodawany do tej konkretnej klasy z najwyższym głosem.
Źródło
4. Jądro SVM
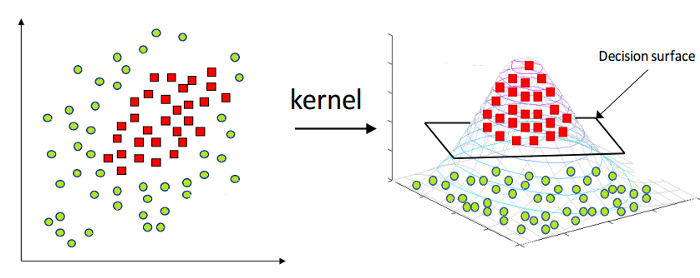
Jak wspomniano powyżej, Linear Support Vector Machine może być stosowany tylko do danych liniowych w naturze. Jednak wszystkich danych na świecie nie da się oddzielić liniowo. Dlatego musimy opracować maszynę wektorów nośnych, aby uwzględnić dane, które są również nieliniowo rozdzielone. Oto sztuczka jądra, znana również jako Kernel Support Vector Machine lub Kernel SVM.
W Kernel SVM wybieramy jądro, takie jak RBF lub jądro Gaussa. Wszystkie punkty danych są mapowane do wyższego wymiaru, gdzie stają się liniowo oddzielone. W ten sposób możemy stworzyć granicę decyzyjną między różnymi klasami zbioru danych.
Źródło
Stąd w ten sposób, korzystając z podstawowych koncepcji maszyn wektorów nośnych, możemy zaprojektować SVM jądra dla nieliniowości.
5. Naiwna klasyfikacja Bayesa
Naiwna klasyfikacja Bayesa ma swoje korzenie należące do twierdzenia Bayesa, zakładając, że wszystkie niezależne zmienne (cechy) zbioru danych są niezależne. Mają one jednakowe znaczenie w przewidywaniu wyniku. To założenie twierdzenia Bayesa daje nazwę „Naiwny”. Służy do różnych zadań, takich jak filtrowanie spamu i inne obszary klasyfikacji tekstu. Naive Bayes oblicza możliwość, czy punkt danych należy do określonej kategorii, czy nie.
Wzór klasyfikacji naiwnej Bayesa jest podany przez:
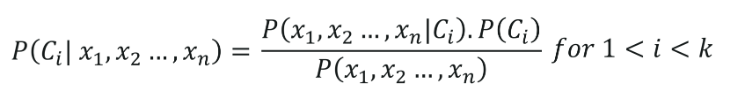
6. Klasyfikacja drzewa decyzyjnego
Drzewo decyzyjne to nadzorowany algorytm uczenia się, który doskonale nadaje się do rozwiązywania problemów klasyfikacyjnych, ponieważ może uporządkować zajęcia na precyzyjnym poziomie. Działa w formie schematu blokowego, w którym oddziela punkty danych na każdym poziomie. Ostateczna struktura wygląda jak drzewo z węzłami i liśćmi.

Źródło
Węzeł decyzyjny będzie miał co najmniej dwie gałęzie, a liść reprezentuje klasyfikację lub decyzję. W powyższym przykładzie Drzewa Decyzyjnego, zadając kilka pytań, tworzony jest schemat blokowy, który pomaga nam rozwiązać prosty problem przewidywania, czy iść na rynek, czy nie.
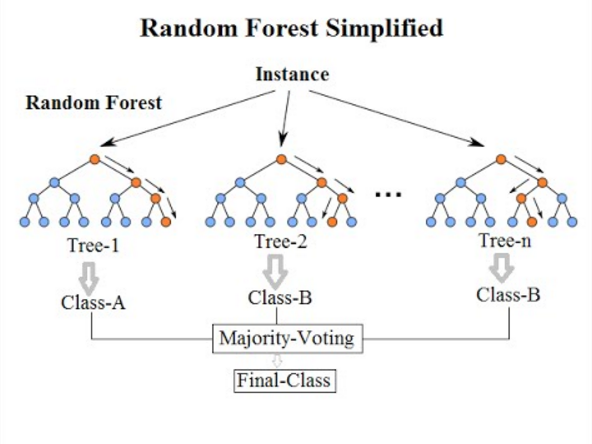
7. Losowa klasyfikacja lasów
Wracając do ostatniego algorytmu klasyfikacji z tej listy, losowy las jest tylko rozszerzeniem algorytmu drzewa decyzyjnego. Losowy las to zespołowa metoda uczenia się z wieloma drzewami decyzyjnymi. Działa w taki sam sposób jak drzewa decyzyjne.
Źródło
Algorytm losowego lasu jest rozwinięciem istniejącego algorytmu drzewa decyzyjnego, który boryka się z poważnym problemem „ przesadnego dopasowania ”. Jest również uważany za szybszy i dokładniejszy w porównaniu z algorytmem drzewa decyzyjnego.
Przeczytaj także: Pomysły i tematy projektów uczenia maszynowego
Wniosek
Dlatego w tym artykule na temat metod uczenia maszynowego do klasyfikacji zrozumieliśmy podstawy klasyfikacji i nadzorowanego uczenia się, typy i metryki oceny modeli klasyfikacji i wreszcie podsumowanie wszystkich najczęściej używanych modeli klasyfikacji uczenia maszynowego.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, zapoznaj się z programem IIIT-B i upGrad Executive PG w zakresie uczenia maszynowego i sztucznej inteligencji , który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadań, IIIT Status -B Alumni, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Q1. Jakie algorytmy są najczęściej wykorzystywane w uczeniu maszynowym?
Uczenie maszynowe wykorzystuje wiele różnych algorytmów, które można ogólnie podzielić na trzy główne rodzaje – algorytmy uczenia nadzorowanego, algorytmy uczenia nienadzorowanego i algorytmy uczenia ze wzmocnieniem. Teraz, aby zawęzić i wymienić niektóre z najczęściej używanych algorytmów, te, które należy wymienić, to regresja liniowa, regresja logistyczna, SVM, drzewa decyzyjne, algorytm losowego lasu, kNN, teoria Naive Bayesa, K-średnie, redukcja wymiarowości, i algorytmy zwiększające gradient. Algorytmy XGBoost, GBM, LightGBM i CatBoost zasługują na szczególną uwagę w algorytmach zwiększania gradientu. Algorytmy te można zastosować do rozwiązania prawie każdego problemu z danymi.
Q2. Czym jest klasyfikacja i regresja w uczeniu maszynowym?
Zarówno algorytmy klasyfikacji, jak i regresji są szeroko stosowane w uczeniu maszynowym. Istnieje jednak między nimi wiele różnic, które ostatecznie decydują o ich zastosowaniu lub przeznaczeniu. Główna różnica polega na tym, że podczas gdy algorytmy klasyfikacji są używane do klasyfikowania lub przewidywania wartości dyskretnych, takich jak mężczyzna-kobieta lub prawda-fałsz, algorytmy regresji są używane do prognozowania niedyskretnych, ciągłych wartości, takich jak wynagrodzenie, wiek, cena itp. Drzewa decyzyjne, las losowy, Kernel SVM i regresja logistyczna to jedne z najpopularniejszych algorytmów klasyfikacji, podczas gdy prosta i wielokrotna regresja liniowa, regresja wektora nośnego, regresja wielomianowa i regresja drzewa decyzyjnego to jedne z najpopularniejszych algorytmów regresji używanych w uczeniu maszynowym.
Q3. Jakie są warunki wstępne uczenia się maszynowego?
Aby zacząć od uczenia maszynowego, nie musisz być biegłym matematykiem ani doświadczonym programistą. Jednak biorąc pod uwagę ogrom tej dziedziny, może to wydawać się onieśmielające, gdy dopiero zaczynasz swoją przygodę z uczeniem maszynowym. W takich przypadkach znajomość warunków wstępnych może pomóc w płynnym rozpoczęciu. Warunki wstępne to zasadniczo podstawowe umiejętności, które musisz zdobyć, aby zrozumieć koncepcje uczenia maszynowego. Przede wszystkim upewnij się, że nauczysz się kodować w Pythonie. Kolejnym atutem będzie podstawowa znajomość statystyki i matematyki, zwłaszcza algebry liniowej i rachunku różniczkowego wielu zmiennych.