
Jak wybrać metodę wyboru funkcji do uczenia maszynowego
Opublikowany: 2021-06-22Spis treści
Wprowadzenie do wyboru funkcji
Wiele funkcji jest wykorzystywanych przez model uczenia maszynowego, z których tylko kilka z nich jest ważnych. Dokładność modelu jest zmniejszona, jeśli do uczenia modelu danych używane są niepotrzebne funkcje. Ponadto następuje wzrost złożoności modelu i spadek zdolności uogólniania, co skutkuje obciążonym modelem. Powiedzenie „czasami mniej znaczy lepiej” dobrze pasuje do koncepcji uczenia maszynowego. Z tym problemem boryka się wielu użytkowników, którym trudno jest zidentyfikować zestaw odpowiednich funkcji na podstawie swoich danych i zignorować wszystkie nieistotne zestawy funkcji. Mniej ważne cechy są określane tak, aby nie wpływały na zmienną docelową.
Dlatego jednym z ważnych procesów jest wybór funkcji w uczeniu maszynowym . Celem jest wybór najlepszego możliwego zestawu funkcji do opracowania modelu uczenia maszynowego. Wybór funkcji ma ogromny wpływ na wydajność modelu. Wraz z czyszczeniem danych, wybór funkcji powinien być pierwszym krokiem w projektowaniu modelu.
Wybór funkcji w uczeniu maszynowym można podsumować jako
- Automatyczny lub ręczny wybór tych funkcji, które mają największy wpływ na zmienną predykcji lub dane wyjściowe.
- Obecność nieistotnych cech może prowadzić do zmniejszenia dokładności modelu, ponieważ będzie on uczyć się na nieistotnych cechach.
Korzyści z wyboru funkcji
- Zmniejsza nadmierne dopasowanie danych: mniejsza liczba danych prowadzi do mniejszej nadmiarowości. Dlatego szanse na podjęcie decyzji dotyczących hałasu są mniejsze.
- Poprawia dokładność modelu: przy mniejszej szansie wprowadzenia w błąd danych zwiększa się dokładność modelu.
- Czas szkolenia jest skrócony: usunięcie nieistotnych funkcji zmniejsza złożoność algorytmu, ponieważ obecnych jest tylko mniej punktów danych. Dlatego algorytmy trenują szybciej.
- Złożoność modelu jest redukowana dzięki lepszej interpretacji danych.
Nadzorowane i nienadzorowane metody doboru cech
Głównym celem algorytmów selekcji cech jest wyselekcjonowanie zestawu najlepszych cech do opracowania modelu. Metody selekcji cech w uczeniu maszynowym można podzielić na metody nadzorowane i nienadzorowane.
- Metoda nadzorowana: metoda nadzorowana służy do wyboru cech z oznaczonych danych, a także służy do klasyfikacji odpowiednich cech. W związku z tym wzrasta wydajność tworzonych modeli.
- Metoda nienadzorowana : ta metoda wyboru elementów jest używana dla danych nieoznaczonych.
Lista metod w ramach metod nadzorowanych
Nadzorowane metody doboru cech w uczeniu maszynowym można podzielić na :

1. Metody owijania
Ten typ algorytmu wyboru cech ocenia proces działania cech na podstawie wyników algorytmu. Znany również jako algorytm zachłanny, iteracyjnie trenuje algorytm przy użyciu podzbioru funkcji. Kryteria zatrzymania są zwykle definiowane przez osobę trenującą algorytm. Dodawanie i usuwanie funkcji w modelu odbywa się na podstawie wcześniejszego uczenia modelu. W tej strategii wyszukiwania można zastosować dowolny rodzaj algorytmu uczenia. Modele są dokładniejsze w porównaniu z metodami filtracyjnymi.
Techniki stosowane w metodach Wrapper to:
- Selekcja w przód: Proces selekcji w przód to proces iteracyjny, w którym po każdej iteracji dodawane są nowe funkcje ulepszające model. Zaczyna się od pustego zestawu funkcji. Iteracja jest kontynuowana i zatrzymuje się, dopóki nie zostanie dodana funkcja, która nie poprawia wydajności modelu.
- Selekcja wsteczna/eliminacja: Proces jest procesem iteracyjnym, który rozpoczyna się od wszystkich funkcji. Po każdej iteracji ze zbioru cech początkowych usuwane są cechy o najmniejszym znaczeniu. Kryterium zatrzymania iteracji jest sytuacja, gdy wydajność modelu nie poprawia się dalej po usunięciu funkcji. Te algorytmy są zaimplementowane w pakiecie mlxtend.
- Eliminacja dwukierunkowa : Obie metody selekcji do przodu i technika eliminacji wstecznej są stosowane jednocześnie w metodzie eliminacji dwukierunkowej, aby osiągnąć jedno unikalne rozwiązanie.
- Wyczerpujący wybór cech: jest również znany jako podejście brute force do oceny podzbiorów cech. Tworzony jest zbiór możliwych podzbiorów, a dla każdego podzbioru budowany jest algorytm uczenia się. Ten podzbiór jest wybierany, którego model zapewnia najlepszą wydajność.
- Rekursywna eliminacja cech (RFE): Metoda jest określana jako zachłanna, ponieważ wybiera cechy poprzez rekurencyjne rozważanie coraz mniejszego zestawu cech. Początkowy zestaw cech jest używany do uczenia estymatora, a ich ważność jest uzyskiwana przy użyciu atrybutu feature_importance_attribute. Następnie następuje usunięcie najmniej ważnych cech, pozostawiając jedynie wymaganą liczbę cech. Algorytmy są zaimplementowane w pakiecie scikit-learn.
Rysunek 4: Przykładowy kod pokazujący technikę rekurencyjnej eliminacji cech
2. Metody wbudowane
Osadzone metody wyboru funkcji w uczeniu maszynowym mają pewną przewagę nad metodami filtrowania i opakowowania, ponieważ obejmują interakcję funkcji, a także utrzymują rozsądny koszt obliczeniowy. Techniki stosowane w metodach wbudowanych to:
- Uregulowanie: Model unika nadmiernego dopasowania danych poprzez dodanie kary do parametrów modelu. Współczynniki są dodawane z karą, w wyniku której niektóre współczynniki mają wartość zero. Dlatego te cechy, które mają współczynnik zerowy, są usuwane z zestawu cech. Podejście selekcji cech wykorzystuje Lasso (regularyzacja L1) oraz sieci elastyczne (regularyzacja L1 i L2).
- SMLR (Sparse Multinomial Logistic Regression): Algorytm implementuje rzadką regularyzację przez ARD przed (automatyczne określanie istotności) dla klasycznej wielonarodowej regresji logistycznej. Ta regularyzacja szacuje ważność każdej cechy i przycina wymiary, które nie są przydatne do przewidywania. Implementacja algorytmu odbywa się w SMLR.
- ARD (Automatic Relevance Determination Regression): Algorytm przesunie wagi współczynników w kierunku zera i jest oparty na regresji grzbietu Bayesa. Algorytm może być zaimplementowany w scikit-learn.
- Losowe znaczenie lasu: Ten algorytm wyboru cech jest agregacją określonej liczby drzew. Strategie oparte na drzewie w tym algorytmie szeregują na podstawie zwiększania zanieczyszczenia węzła lub zmniejszania zanieczyszczenia (nieczystość Giniego). Koniec drzew składa się z węzłów o najmniejszym spadku zanieczyszczeń, a początek drzew składa się z węzłów o największym spadku zanieczyszczeń. Dlatego ważne cechy można wybrać poprzez przycięcie drzewa poniżej określonego węzła.
3. Metody filtrowania
Metody są stosowane na etapach przetwarzania wstępnego. Metody te są dość szybkie i niedrogie i najlepiej sprawdzają się przy usuwaniu zduplikowanych, skorelowanych i nadmiarowych funkcji. Zamiast stosować jakiekolwiek nadzorowane metody uczenia się, znaczenie cech ocenia się na podstawie ich nieodłącznych cech. Koszt obliczeniowy algorytmu jest niższy w porównaniu do opakowujących metod selekcji cech. Jeśli jednak nie ma wystarczającej ilości danych, aby wyprowadzić statystyczną korelację między cechami, wyniki mogą być gorsze niż metody opakowujące. Dlatego algorytmy są używane na danych o dużych wymiarach, co prowadziłoby do wyższych kosztów obliczeniowych w przypadku zastosowania metod owijających.

Techniki stosowane w metodach filtrowania to :
- Wzmocnienie informacji : Wzmocnienie informacji odnosi się do ilości informacji uzyskanych z cech w celu zidentyfikowania wartości docelowej. Następnie mierzy zmniejszenie wartości entropii. Zysk informacji o każdym atrybucie jest obliczany z uwzględnieniem wartości docelowych do wyboru cech.
- Test chi-kwadrat : Metoda chi-kwadrat (X 2 ) jest zwykle używana do testowania relacji między dwiema zmiennymi kategorialnymi. Test służy do określenia, czy istnieje znacząca różnica między obserwowanymi wartościami z różnych atrybutów zbioru danych a ich wartością oczekiwaną. Hipoteza zerowa mówi, że nie ma związku między dwiema zmiennymi.
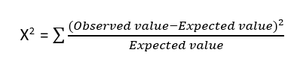
Źródło
Wzór na test chi-kwadrat
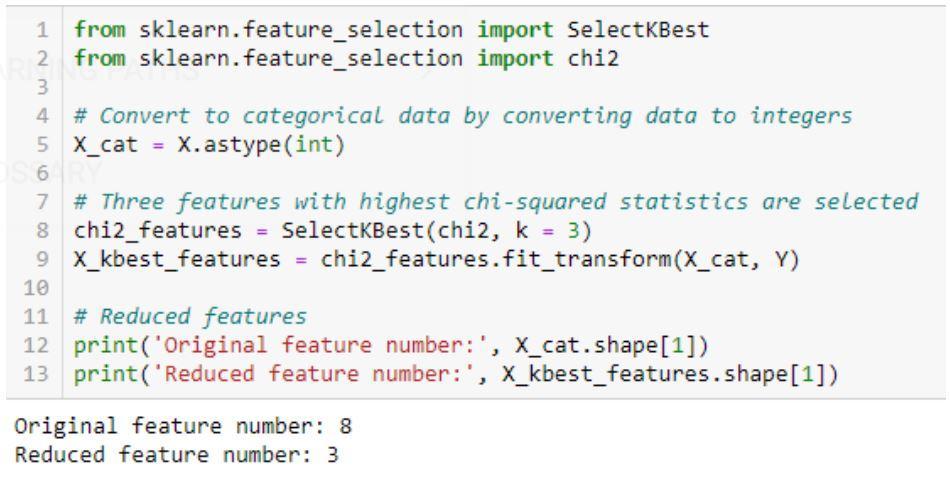
Implementacja algorytmu Chi-kwadrat: sklearn, scipy
Przykładowy kod dla testu chi-kwadrat
Źródło
- CFS (wybór cech na podstawie korelacji): Metoda polega na tym, że „ Implementacja CFS (wybór funkcji na podstawie korelacji): scikit-feature
Dołącz do internetowych kursów AI i ML z najlepszych światowych uniwersytetów – Masters, Executive Post Graduate Programs i Advanced Certificate Program w ML & AI, aby przyspieszyć swoją karierę.
- FCBF (szybki filtr oparty na korelacji): W porównaniu z wyżej wymienionymi metodami Relief i CFS, metoda FCBF jest szybsza i bardziej wydajna. Początkowo obliczenia niepewności symetrycznej są przeprowadzane dla wszystkich cech. Korzystając z tych kryteriów, funkcje są następnie sortowane, a zbędne funkcje są usuwane.
Niepewność symetryczna = zysk informacyjny x | y podzielone przez sumę ich entropii. Wdrożenie FCBF: skfeature
- Wynik Fischera: współczynnik Fischera (FIR) definiuje się jako odległość między średnimi próbki dla każdej klasy na cechę podzieloną przez ich wariancje. Każda cecha jest niezależnie wybierana zgodnie z ich punktacją w ramach kryterium Fishera. Prowadzi to do nieoptymalnego zestawu funkcji. Większy wynik Fishera oznacza lepiej wybraną funkcję.
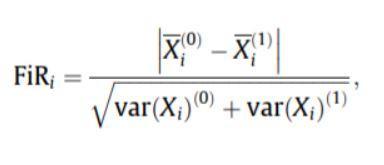
Źródło
Wzór na wynik Fischera
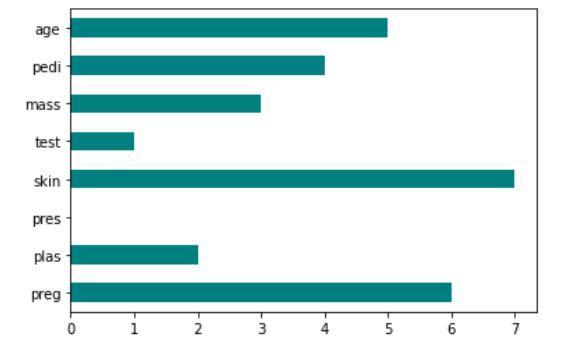
Implementacja punktacji Fishera: funkcja scikit
Wynik kodu pokazujący technikę punktacji Fishera
Źródło
Współczynnik korelacji Pearsona: Jest to miara ilościowego określenia związku między dwiema zmiennymi ciągłymi. Wartości współczynnika korelacji wahają się od -1 do 1, co określa kierunek zależności między zmiennymi.
- Próg wariancji: cechy, których wariancja nie osiąga określonego progu, są usuwane. Za pomocą tej metody usuwane są elementy o zerowej wariancji. Rozważane jest założenie, że cechy o większej wariancji prawdopodobnie będą zawierać więcej informacji.
Rysunek 15: Przykładowy kod pokazujący implementację progu wariancji
- Średnia różnica bezwzględna (MAD): Metoda oblicza średnią bezwzględną
różnica od wartości średniej.
Przykład kodu i jego wynik pokazujący implementację średniej bezwzględnej różnicy (MAD)
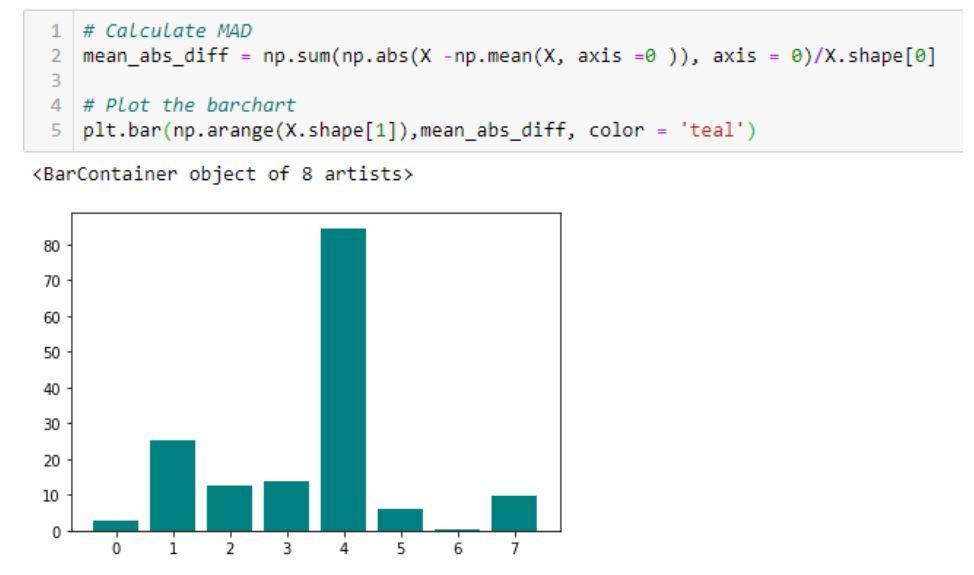
Źródło
- Współczynnik dyspersji: Współczynnik dyspersji definiuje się jako stosunek średniej arytmetycznej (AM) do średniej geometrycznej (GM) dla danej cechy. Jego wartość waha się od +1 do ∞ jako AM ≥ GM dla danej cechy.
Wyższy współczynnik dyspersji implikuje wyższą wartość Ri, a zatem bardziej odpowiednią cechę. I odwrotnie, gdy Ri jest bliskie 1, oznacza to cechę o niskim znaczeniu.
- Wzajemna zależność: Metoda służy do pomiaru wzajemnej zależności między dwiema zmiennymi. Informacje uzyskane z jednej zmiennej można wykorzystać do uzyskania informacji o drugiej zmiennej.
- Wynik Laplace'a: Dane z tej samej klasy są często blisko siebie. Wagę obiektu można ocenić na podstawie jego zdolności do zachowania lokalizacji. Dla każdej funkcji obliczany jest wynik Laplace'a. Najmniejsze wartości określają ważne wymiary. Implementacja partytury Laplace'a: scikit-feature.
Wniosek
Wybór funkcji w procesie uczenia maszynowego można podsumować jako jeden z ważnych kroków w kierunku opracowania dowolnego modelu uczenia maszynowego. Proces algorytmu wyboru cech prowadzi do zmniejszenia wymiarowości danych z usunięciem cech nieistotnych lub nieistotnych dla rozważanego modelu. Odpowiednie funkcje mogą przyspieszyć czas uczenia modeli, co skutkuje wysoką wydajnością.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, zapoznaj się z programem IIIT-B i upGrad Executive PG w zakresie uczenia maszynowego i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadań, IIIT Status -B Alumni, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Czym różni się metoda filtrowania od metody owijarki?
Metoda wrapper pomaga zmierzyć, jak przydatne są funkcje oparte na wydajności klasyfikatora. Z drugiej strony metoda filtrowania ocenia wewnętrzne cechy cech przy użyciu statystyk jednowymiarowych, a nie wydajności walidacji krzyżowej, co oznacza, że ocenia istotność cech. W rezultacie metoda opakowująca jest bardziej efektywna, ponieważ optymalizuje wydajność klasyfikatora. Jednak ze względu na powtarzające się procesy uczenia się i walidację krzyżową technika wrappera jest obliczeniowo droższa niż metoda filtrowania.
Co to jest sekwencyjny wybór do przodu w uczeniu maszynowym?
Jest to rodzaj sekwencyjnego wyboru funkcji, chociaż jest o wiele droższy niż wybór filtrów. Jest to technika zachłannego wyszukiwania, która iteracyjnie wybiera funkcje w oparciu o wydajność klasyfikatora w celu znalezienia idealnego podzbioru funkcji. Rozpoczyna się pustym podzbiorem funkcji i kontynuuje dodawanie jednej funkcji w każdej rundzie. Ta jedna funkcja jest wybierana z puli wszystkich funkcji, których nie ma w naszym podzestawie funkcji, i to ta, która zapewnia najlepszą wydajność klasyfikatora w połączeniu z innymi.
Jakie są ograniczenia używania metody filtrowania do wyboru cech?
Podejście filtrujące jest mniej kosztowne obliczeniowo niż metody wyboru opakowujących i osadzonych funkcji, ale ma pewne wady. W przypadku podejść jednowymiarowych strategia ta często ignoruje współzależność cech przy wyborze cech i ocenia każdą cechę niezależnie. W porównaniu z pozostałymi dwiema metodami wyboru funkcji może to czasami skutkować niską wydajnością obliczeniową.