
Jak moja witryna oparta na interfejsie API pomaga mi podróżować po świecie
Opublikowany: 2022-03-10(To jest post sponsorowany.) Niedawno postanowiłem przebudować swoją osobistą stronę internetową, ponieważ miała sześć lat i wyglądała – grzecznie rzecz biorąc – trochę „przestarzała”. Celem było umieszczenie informacji o sobie, bloga, listy moich ostatnich projektów pobocznych i nadchodzących wydarzeń.
Ponieważ od czasu do czasu pracuję z klientami, była jedna rzecz, z którą nie chciałem się zajmować — bazy danych ! Wcześniej budowałem strony WordPress dla wszystkich, którzy tego chcieli. Część programistyczna była dla mnie zazwyczaj zabawna, ale wydania, przenoszenie baz danych do różnych środowisk i faktyczne publikowanie zawsze były denerwujące. Tani dostawcy hostingu oferują jedynie słabe interfejsy internetowe do konfiguracji baz danych MySQL, a dostęp FTP do przesyłania plików był zawsze najgorszą częścią. Nie chciałem zajmować się tym na mojej osobistej stronie internetowej.
Tak więc wymagania, które miałem do przeprojektowania, były następujące:
- Aktualny stos technologiczny oparty na technologiach JavaScript i frontend.
- Rozwiązanie do zarządzania treścią umożliwiające edycję treści z dowolnego miejsca.
- Witryna o dobrych wynikach i szybkich wynikach.
W tym artykule chcę Wam pokazać, co zbudowałem i jak moja strona niespodziewanie okazała się moim codziennym towarzyszem.
Definiowanie modelu treści
Publikowanie rzeczy w sieci wydaje się łatwe. Wybierz system zarządzania treścią (CMS), który zapewnia edytor WYSIWYG ( W hat You See Is W hat You G et) dla każdej potrzebnej strony, a wszyscy redaktorzy mogą łatwo zarządzać treścią. To wszystko, prawda?
Po zbudowaniu kilku stron internetowych dla klientów, od małych kawiarni po rozwijające się startupy, zorientowałem się, że święty edytor WYSIWYG nie zawsze jest srebrną kulą, której wszyscy szukamy. Te interfejsy mają na celu ułatwienie tworzenia stron internetowych, ale o to chodzi:
Tworzenie stron internetowych nie jest łatwe
Aby zbudować i edytować zawartość strony internetowej bez ciągłego jej łamania, musisz mieć dogłębną wiedzę na temat HTML i przynajmniej zrozumieć odrobinę CSS. Nie jest to coś, czego można oczekiwać od swoich redaktorów.
Widziałem okropnie złożone układy zbudowane z edytorami WYSIWYG i nie mogę zacząć wymieniać wszystkich sytuacji, w których wszystko się rozpada, ponieważ system jest zbyt delikatny. Takie sytuacje prowadzą do kłótni i dyskomfortu, w których wszystkie strony obwiniają się nawzajem o coś, co było nieuniknione. Zawsze starałem się unikać takich sytuacji i tworzyć wygodne, stabilne środowisko dla redaktorów, aby uniknąć wściekłych e-maili z krzykiem „Pomocy! Wszystko jest zniszczone."
Zorganizowana zawartość pozwala zaoszczędzić trochę kłopotów
Dość szybko dowiedziałem się, że ludzie rzadko coś psują, kiedy dzielę całą potrzebną zawartość witryny na kilka części, które są ze sobą powiązane, nie myśląc o żadnej reprezentacji. W WordPressie można to osiągnąć za pomocą niestandardowych typów postów. Każdy niestandardowy typ posta może zawierać kilka właściwości z własnym, łatwym do uchwycenia polem tekstowym. Całkowicie ukryłem pojęcie myślenia na stronach .
Moim zadaniem było łączenie elementów treści i budowanie stron internetowych z tych bloków treści. Oznaczało to, że redaktorzy byli w stanie dokonać tylko niewielkich, jeśli w ogóle, zmian wizualnych na swoich stronach internetowych. Byli odpowiedzialni za treść i tylko za treść. Zmiany wizualne musiały zostać wykonane przeze mnie — nie każdy potrafił wystylizować witrynę, a my mogliśmy uniknąć delikatnego środowiska. Ta koncepcja wydawała się świetnym kompromisem i zwykle była dobrze przyjmowana.
Później odkryłem, że to, co robię, to definiowanie modelu treści. Rachel Lovinger w swoim znakomitym artykule „Content Modelling: A Master Skill” definiuje model treści w następujący sposób:
„Model treści dokumentuje wszystkie rodzaje treści, które będziesz mieć dla danego projektu. Zawiera szczegółowe definicje elementów każdego typu treści i ich wzajemnych relacji”.
Począwszy od modelowania treści, u większości klientów działało dobrze, z wyjątkiem jednego.
„Stefan, nie definiuję twojego schematu bazy danych!”
Ideą tego jednego projektu było zbudowanie ogromnej strony internetowej, która powinna wygenerować duży ruch organiczny poprzez dostarczanie mnóstwa treści — we wszystkich odmianach wyświetlanych na kilku różnych stronach i miejscach. Zorganizowałem spotkanie, aby omówić naszą strategię podejścia do tego projektu.
Chciałem zdefiniować wszystkie strony i modele treści, które powinny zostać uwzględnione. Nieważne, jaki malutki widżet lub jaki pasek boczny klient miał na myśli, chciałem, aby był jasno zdefiniowany. Moim celem było stworzenie solidnej struktury treści, która umożliwi udostępnienie edytorom łatwego w użyciu interfejsu i zapewni dane wielokrotnego użytku, aby wyświetlić je w dowolnym możliwym do pomyślenia formacie.
Okazało się, że idea tego projektu nie była zbyt jasna i nie mogłem uzyskać odpowiedzi na wszystkie moje pytania. Kierownik projektu nie rozumiał, że powinniśmy zacząć od odpowiedniego modelowania treści (nie projektowania i rozwoju). Dla niego to była tylko tona stron. Zduplikowana treść i ogromne obszary tekstowe, aby dodać ogromną ilość tekstu, nie wydawały się być problemem. W jego umyśle moje pytania dotyczące struktury były techniczne i nie powinni się nimi martwić. Krótko mówiąc, nie wykonałem projektu.
Ważne jest to, że modelowanie treści nie dotyczy baz danych.
Chodzi o to, aby Twoje treści były dostępne i odporne na przyszłość. Jeśli nie możesz określić potrzeb dotyczących treści na początku projektu, bardzo trudne, jeśli nie niemożliwe, będzie ich ponowne wykorzystanie w przyszłości.
Właściwe modelowanie treści jest kluczem do obecnych i przyszłych stron internetowych.
Treść: bezgłowy CMS
Było jasne, że chciałem również zadbać o dobre modelowanie treści dla mojej witryny. Była jednak jeszcze jedna rzecz. Nie chciałem zajmować się warstwą przechowywania, aby zbudować moją nową stronę internetową, więc zdecydowałem się na Contentful, bezgłowy CMS, nad którym (pełna uwaga!) aktualnie pracuję. „Headless” oznacza, że ta usługa oferuje interfejs sieciowy do zarządzania treścią w chmurze i zapewnia interfejs API, który zwróci moje dane w formacie JSON. Wybór tego CMS pomógł mi od razu być produktywnym, ponieważ miałem API dostępne w ciągu kilku minut i nie musiałem zajmować się żadną konfiguracją infrastruktury. Contentful zapewnia również bezpłatny plan, który jest idealny do małych projektów, takich jak moja osobista strona internetowa.
Przykładowe zapytanie, aby pobrać wszystkie posty na blogu, wygląda tak:
<a href="https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post">https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post</a>A odpowiedź w skróconej wersji wygląda tak:
{ "sys": { "type": "Array" }, "total": 7, "skip": 0, "limit": 100, "items": [ { "sys": { "space": {...}, "id": "455OEfg1KUskygWUiKwmkc", "type": "Entry", "createdAt": "2016-07-29T11:53:52.596Z", "updatedAt": "2016-11-09T21:07:19.118Z", "revision": 12, "contentType": {...}, "locale": "en-US" }, "fields": { "title": "How to React to Changing Environments Using matchMedia", "excerpt": "...", "slug": "how-to-react-to-changing-environments-using-match-media", "author": [...], "body": "...", "date": "2014-12-26T00:00+02:00", "comments": true, "externalUrl": "https://4waisenkinder.de/blog/2014/12/26/handle-environment-changes-via-window-dot-matchmedia/" }, {...}, {...}, {...}, {...}, {...}, {...} ] } }Największą zaletą Contentful jest to, że świetnie radzi sobie z modelowaniem treści, czego wymagałem. Korzystając z dostarczonego interfejsu internetowego, mogę szybko zdefiniować wszystkie potrzebne elementy treści. Definicja konkretnego modelu zawartości w Contentful jest nazywana typem zawartości. Świetną rzeczą, na którą warto zwrócić uwagę, jest możliwość modelowania relacji między elementami treści. Na przykład mogę łatwo połączyć autora z postem na blogu. Może to skutkować ustrukturyzowanymi drzewami danych, które doskonale nadają się do ponownego wykorzystania w różnych przypadkach użycia.
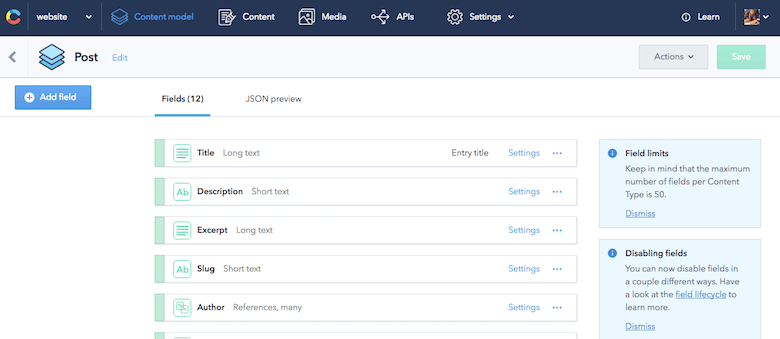
Tak więc konfiguruję swój model treści, nie myśląc o żadnych stronach, które mógłbym chcieć zbudować w przyszłości.
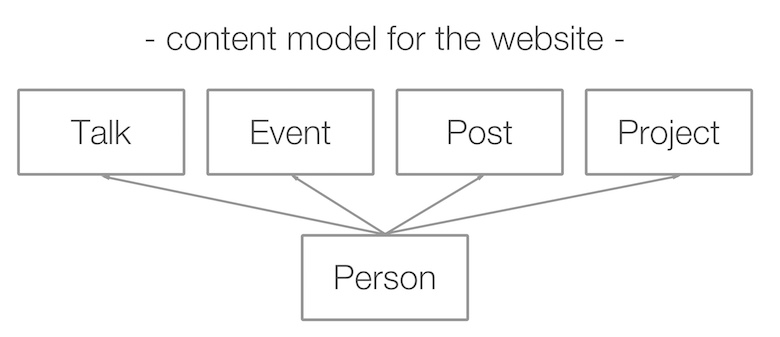
Następnym krokiem było ustalenie, co chcę zrobić z tymi danymi. Zapytałem projektanta, którego znałem, a on wymyślił stronę indeksową witryny o następującej strukturze.
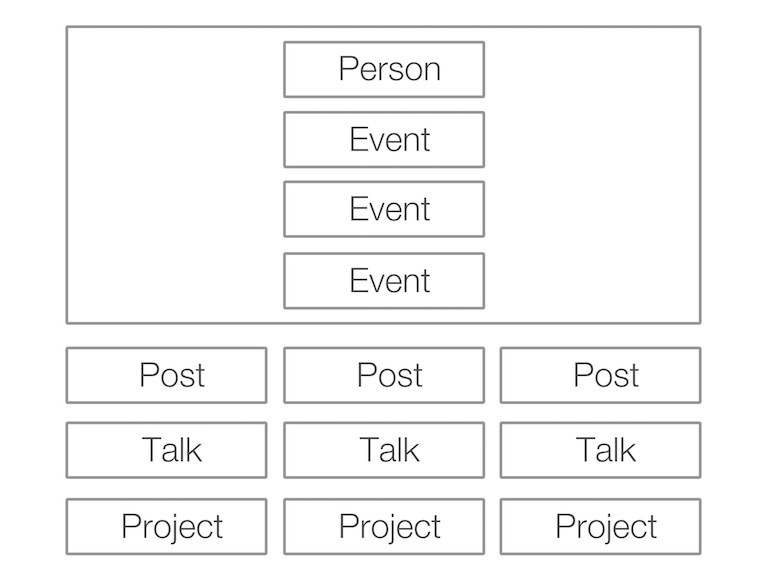
Renderowanie stron HTML za pomocą Node.js
Teraz przyszła trudna część. Do tej pory nie miałem do czynienia z pamięcią masową i bazami danych, co było dla mnie dużym osiągnięciem. Jak więc mogę zbudować swoją witrynę, gdy mam dostępne tylko API?
Moim pierwszym podejściem było podejście „zrób to sam”. Zacząłem pisać prosty skrypt Node.js, który pobierał dane i renderował z nich trochę kodu HTML.
Renderowanie wszystkich plików HTML z góry spełniło jedno z moich głównych wymagań. Statyczny HTML może być serwowany naprawdę szybko.
Przyjrzyjmy się więc skryptowi, którego użyłem.
'use strict'; const contentful = require('contentful'); const template = require('lodash.template'); const fs = require('fs'); // create contentful client with particular credentials const client = contentful.createClient({ space: 'your_space_id', accessToken: 'your_token' }); // cache templates to not read // them over and over again const TEMPLATES = { index : template(fs.readFileSync(`${__dirname}/templates/index.html`)) }; // fetch all the data Promise.all([ // get posts client.getEntries({content_type: 'content_type_post_id'}), // get events client.getEntries({content_type: 'content_type_event_id'}), // get projects client.getEntries({content_type: 'content_type_project_id'}), // get talk client.getEntries({content_type: 'content_type_talk_id'}), // get specific person client.getEntries({'sys.id': 'person_id'}) ]) .then(([posts, events, projects, talks, persons]) => { const renderedHTML = TEMPLATES.index({ posts, events, projects, talks, person : persons.items[0] }) fs.writeFileSync(`${__dirname}/build/index.html`, renderedHTML); console.log('Rendered HTML'); }) .catch(console.error); <!doctype html> <html lang="en"> <head> <!-- ... --> </head> <body> <!-- ... --> <h2>Posts</h2> <ul> <% posts.items.forEach( function( talk ) { %> <li><%- talk.fields.title %> <% }) %> </ul> <!-- ... --> </body> </html>To działało dobrze. Mogłem zbudować wybraną przeze mnie stronę internetową w całkowicie elastyczny sposób, podejmując wszystkie decyzje dotyczące struktury plików i funkcjonalności. Renderowanie różnych typów stron z zupełnie różnymi zestawami danych nie stanowiło żadnego problemu. Każdy, kto walczył z zasadami i strukturą istniejącego systemu CMS, który jest dostarczany z renderowaniem HTML, wie, że pełna swoboda może być świetną rzeczą. Zwłaszcza, gdy model danych staje się z czasem bardziej złożony i obejmuje wiele relacji — elastyczność się opłaca.
W tym skrypcie Node.js tworzony jest klient Contentful SDK, a wszystkie dane są pobierane przy użyciu metody klienta getEntries . Wszystkie dostarczone przez klienta metody są oparte na obietnicach, co ułatwia uniknięcie głęboko zagnieżdżonych wywołań zwrotnych. Do tworzenia szablonów zdecydowałem się użyć silnika szablonów Lodash. Wreszcie, do odczytu i zapisu plików, Node.js oferuje natywny moduł fs , który jest następnie używany do odczytywania szablonów i pisania renderowanego kodu HTML.
Jednak to podejście miało jedną wadę; to było bardzo gołe. Nawet gdy ta metoda była całkowicie elastyczna, wydawało się, że trzeba wymyślać koło na nowo. To, co budowałem, było w zasadzie generatorem statycznych witryn i jest ich już wiele. Czas zacząć wszystko od nowa.
Wybierasz prawdziwy generator stron statycznych
Znane generatory stron statycznych, na przykład Jekyll lub Middleman, zwykle zajmują się plikami Markdown, które będą renderowane do HTML. Pracują z nimi redaktorzy, a witryna jest budowana za pomocą polecenia CLI. Takie podejście nie spełniło jednak jednego z moich początkowych wymagań. Chciałem móc edytować witrynę, gdziekolwiek jestem, nie polegając na plikach znajdujących się na moim prywatnym komputerze.

Moim pierwszym pomysłem było wyrenderowanie tych plików Markdown za pomocą API. Chociaż to by zadziałało, nie czułem się dobrze. Renderowanie plików Markdown w celu późniejszego przekształcenia do HTML było nadal dwoma krokami, które nie zapewniały dużych korzyści w porównaniu z moim początkowym rozwiązaniem.
Na szczęście istnieją integracje Contentful, np. Metalsmith i Middleman. Zdecydowałem się na Metalsmith do tego projektu, ponieważ jest napisany w Node.js i nie chciałem wprowadzać zależności Ruby.
Metalsmith przekształca pliki z folderu źródłowego i renderuje je w folderze docelowym. Te pliki niekoniecznie muszą być plikami Markdown. Możesz go również użyć do transpilacji Sass lub optymalizacji obrazów. Nie ma ograniczeń i jest naprawdę elastyczny.
Korzystając z integracji Contentful, mogłem zdefiniować kilka plików źródłowych, które zostały wzięte jako pliki konfiguracyjne, a następnie mogłem pobrać wszystko, co potrzebne z API.
--- title: Blog contentful: content_type: content_type_id entry_filename_pattern: ${ fields.slug } entry_template: article.html order: '-fields.date' filter: include: 5 layout: blog.html description: >- Recent articles by Stefan Judis. --- Ta przykładowa konfiguracja renderuje obszar postów w blogu za pomocą nadrzędnego pliku blog.html , w tym odpowiedzi na żądanie interfejsu API, ale renderuje również kilka stron podrzędnych przy użyciu szablonu article.html . Nazwy plików dla stron podrzędnych są definiowane poprzez entry_filename_pattern .
Jak widzisz, z czymś takim mogę łatwo budować swoje strony. Ta konfiguracja działała idealnie, aby wszystkie strony były zależne od interfejsu API.
Połącz usługę ze swoim projektem
Brakowało tylko połączenia serwisu z usługą CMS i ponownego renderowania po edycji treści. Rozwiązanie tego problemu — webhooki, które możesz już znać, jeśli korzystasz z usług takich jak GitHub.
Webhook to żądania wysyłane przez oprogramowanie jako usługa do wcześniej zdefiniowanego punktu końcowego, które powiadamiają o tym, że coś się wydarzyło. Na przykład GitHub może oddzwonić, gdy ktoś otworzy żądanie ściągnięcia w jednym z Twoich repozytoriów. Jeśli chodzi o zarządzanie treścią, możemy tutaj zastosować tę samą zasadę. Za każdym razem, gdy coś dzieje się z treścią, pinguj punkt końcowy i spraw, aby określone środowisko zareagowało na to. W naszym przypadku oznaczałoby to ponowne renderowanie kodu HTML za pomocą kowalskiego.
Aby zaakceptować webhooki, wybrałem również rozwiązanie JavaScript. Wybrany przeze mnie dostawca hostingu (Uberspace) umożliwia zainstalowanie Node.js i korzystanie z JavaScript po stronie serwera.
const http = require('http'); const exec = require('child_process').exec; const server = http.createServer((req, res) => { res.setHeader('Content-Type', 'text/plain'); // check for secret header // to not open up this endpoint for everybody if (req.headers.secret === 'YOUR_SECRET') { res.end('ok'); // wait for the CDN to // invalidate the data setTimeout(() => { // execute command exec('npm start', { cwd: __dirname }, (error) => { if (error) { return console.log(error); } console.log('Rebuilt success'); }); }, 1000 * 120 ); } else { res.end('Not allowed'); } }); console.log('Started server at 8000'); server.listen(8000); Ten skrypt uruchamia prosty serwer HTTP na porcie 8000. Sprawdza przychodzące żądania pod kątem prawidłowego nagłówka, aby upewnić się, że jest to webhook od Contentful. Jeśli żądanie zostanie potwierdzone jako element webhook, predefiniowane polecenie npm start jest wykonywane w celu ponownego renderowania wszystkich stron HTML. Możesz się zastanawiać, dlaczego obowiązuje limit czasu. Jest to wymagane, aby wstrzymać działania na chwilę, dopóki dane w chmurze nie zostaną unieważnione, ponieważ przechowywane dane są obsługiwane z sieci CDN.
W zależności od środowiska ten serwer HTTP może nie być dostępny w Internecie. Moja witryna jest obsługiwana za pomocą serwera Apache, więc musiałem dodać wewnętrzną regułę przepisywania, aby serwer z uruchomionym węzłem był dostępny dla Internetu.
# add node endpoint to enable webhooks RewriteRule ^rerender/(.*) https://localhost:8000/$1 [P]API-First i uporządkowane dane: najlepsi przyjaciele na zawsze
W tym momencie byłem w stanie zarządzać wszystkimi moimi danymi w chmurze, a moja strona internetowa odpowiednio reagowałaby na zmiany.
Powtarzanie w każdym miejscu
Bycie w drodze to ważna część mojego życia, dlatego konieczne było posiadanie informacji, takich jak lokalizacja danego miejsca czy zarezerwowany hotel, na wyciągnięcie ręki – zwykle zapisane w arkuszu kalkulacyjnym Google. Teraz informacje były rozłożone w arkuszu kalkulacyjnym, kilku e-mailach, moim kalendarzu, a także na mojej stronie internetowej.
Muszę przyznać, że w swoim codziennym przepływie stworzyłem dużo duplikacji danych.
Moment uporządkowanych danych
Marzyłem o jednym źródle prawdy (najlepiej na telefonie), aby szybko zobaczyć, jakie wydarzenia się zbliżają, ale także uzyskać dodatkowe informacje o hotelach i obiektach. Wydarzenia wymienione w mojej witrynie nie zawierały w tym momencie wszystkich informacji, ale naprawdę łatwo jest dodać nowe pola do typu zawartości w Contentful. Dodałem więc potrzebne pola do typu treści „Wydarzenie”.
Umieszczenie tych informacji w CMS-ie na mojej stronie nigdy nie było moim zamiarem, ponieważ nie powinny być wyświetlane online, ale udostępnienie ich przez API uświadomiło mi, że mogę teraz robić zupełnie inne rzeczy z tymi danymi.
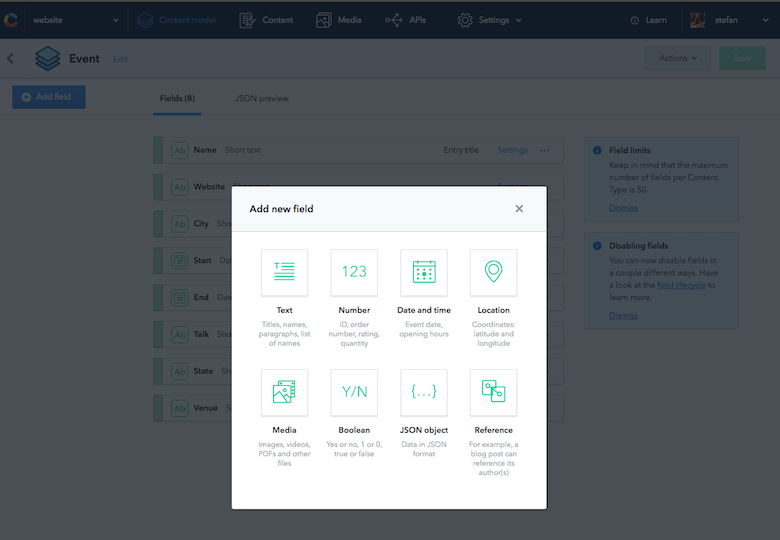
Tworzenie natywnej aplikacji za pomocą JavaScript
Tworzenie aplikacji mobilnych jest tematem od lat i istnieje kilka podejść do tego. Obecnie szczególnie gorącym tematem są progresywne aplikacje internetowe (PWA). Korzystając z Service Workers i Web App Manifest, można tworzyć kompletne środowiska przypominające aplikacje, przechodząc od ikony na ekranie głównym do zarządzanego zachowania w trybie offline przy użyciu technologii internetowych.
Jest jeden minus, o którym warto wspomnieć. Progresywne aplikacje internetowe stają się coraz popularniejsze, ale jeszcze nie do końca. Na przykład Service Workery nie są obecnie obsługiwane w Safari i jak dotąd tylko „rozważane” ze strony Apple. To było dla mnie przełomowe, ponieważ chciałem mieć również aplikację działającą w trybie offline na iPhone'ach.
Poszukałem więc alternatyw. Mój przyjaciel był naprawdę zafascynowany NativeScript i ciągle opowiadał mi o tej całkiem nowej technologii. NativeScript to framework open source do tworzenia naprawdę natywnych aplikacji mobilnych z JavaScript, więc postanowiłem spróbować.
Poznawanie NativeScript
Konfiguracja NativeScript zajmuje trochę czasu, ponieważ musisz zainstalować wiele rzeczy, aby opracować je dla natywnych środowisk mobilnych. Zostaniesz przeprowadzony przez proces instalacji podczas pierwszej instalacji narzędzia wiersza poleceń NativeScript przy użyciu npm install nativescript -g .
Następnie możesz użyć poleceń rusztowania, aby skonfigurować nowe projekty: tns create MyNewApp
Jednak nie to zrobiłem. Przeglądałem dokumentację i natknąłem się na przykładową aplikację do zarządzania zakupami zbudowaną w NativeScript. Wziąłem więc tę aplikację, dokopałem się do kodu i krok po kroku zmodyfikowałem, dopasowując do swoich potrzeb.
Nie chcę zagłębiać się zbyt głęboko w ten proces, ale zbudowanie dobrze wyglądającej listy zawierającej wszystkie potrzebne informacje nie zajęło mi dużo czasu.
NativeScript bardzo dobrze współpracuje z Angularem 2, którego tym razem nie chciałem próbować, ponieważ odkrycie samego NativeScript wydawało się wystarczająco duże. W NativeScript musisz napisać „Widoki”. Każdy widok składa się z pliku XML definiującego układ bazowy oraz opcjonalnie JavaScript i CSS. Wszystkie te są zdefiniowane w jednym folderze na widok.
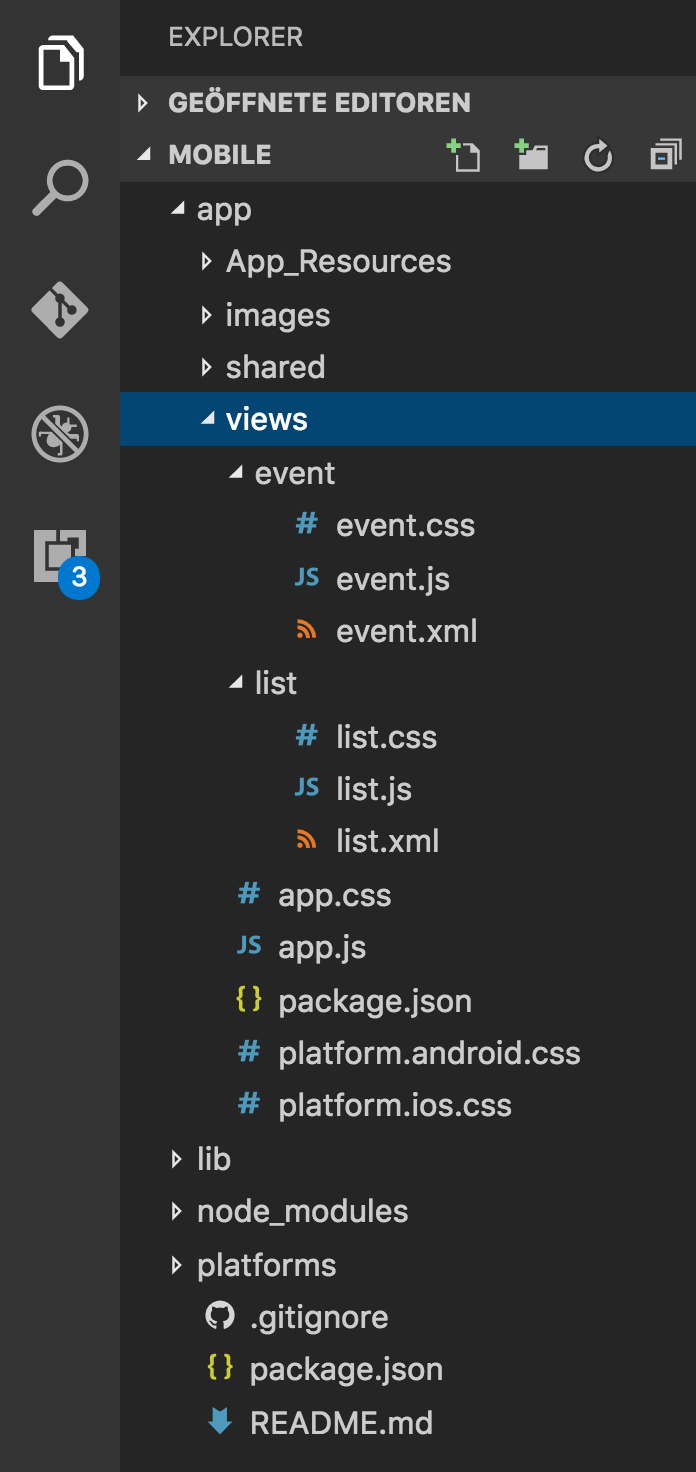
Renderowanie prostej listy można uzyskać za pomocą takiego szablonu XML:
<!-- call JavaScript function when ready --> <Page loaded="loaded"> <ActionBar title="All Travels" /> <!-- make it scrollable when going too big --> <ScrollView> <!-- iterate over the entries in context --> <ListView items="{{ entries }}"> <ListView.itemTemplate> <Label text="{{ fields.name }}" textWrap="true" class="headline"/> </ListView.itemTemplate> </ListView> </ScrollView> </Page> Pierwszą rzeczą, która się tutaj dzieje, jest zdefiniowanie elementu strony. Wewnątrz tej strony zdefiniowałem ActionBar , aby nadać mu klasyczny wygląd Androida, a także odpowiedni nagłówek. Tworzenie rzeczy dla środowisk natywnych może być czasami trochę trudne. Na przykład, aby osiągnąć działające zachowanie przewijania, musisz użyć „ScrollView”. Ostatnią rzeczą jest po prostu iteracja moich zdarzeń przy użyciu ListView . Ogólnie rzecz biorąc, wydawało się to całkiem proste!
Ale skąd pochodzą te wpisy, które są używane w widoku? Okazuje się, że istnieje wspólny obiekt kontekstu, który można do tego wykorzystać. Czytając XML dla widoku, mogłeś już zauważyć, że strona ma loaded zestaw atrybutów. Ustawiając ten atrybut, mówię widokowi, aby wywołał określoną funkcję JavaScript, gdy strona jest ładowana.
Ta funkcja JavaScript jest zdefiniowana w zależnym pliku JS. Można go udostępnić, po prostu eksportując go za pomocą exports.something . Aby dodać powiązanie danych, wszystko, co musimy zrobić, to ustawić nowy Observable we właściwości strony bindingContext . Observables w NativeScript emitują zdarzenia propertyChange , które są potrzebne do reagowania na zmiany danych w widokach, ale nie musisz się tym martwić, ponieważ działa po wyjęciu z pudełka.
const context = new Observable({ entries: null}); const fetchModule = require('fetch'); // export loaded to be called from // List.xml when everything is loaded exports.loaded = (args) => { const page = args.object; page.bindingContext = context; fetchModule.fetch( `https://cdn.contentful.com/spaces/${config.space}/entries?access_token=${config.cda.token}&content_type=event&order=fields.start`, { method: "GET", headers: { 'Content-Type': 'application/json' } } ) .then(response => response.json()) .then(response => context.set('entries', response.items)); } Ostatnią rzeczą jest pobranie danych i ustawienie ich w kontekście. Można to zrobić za pomocą modułu fetch NativeScript. Tutaj możesz zobaczyć wynik.
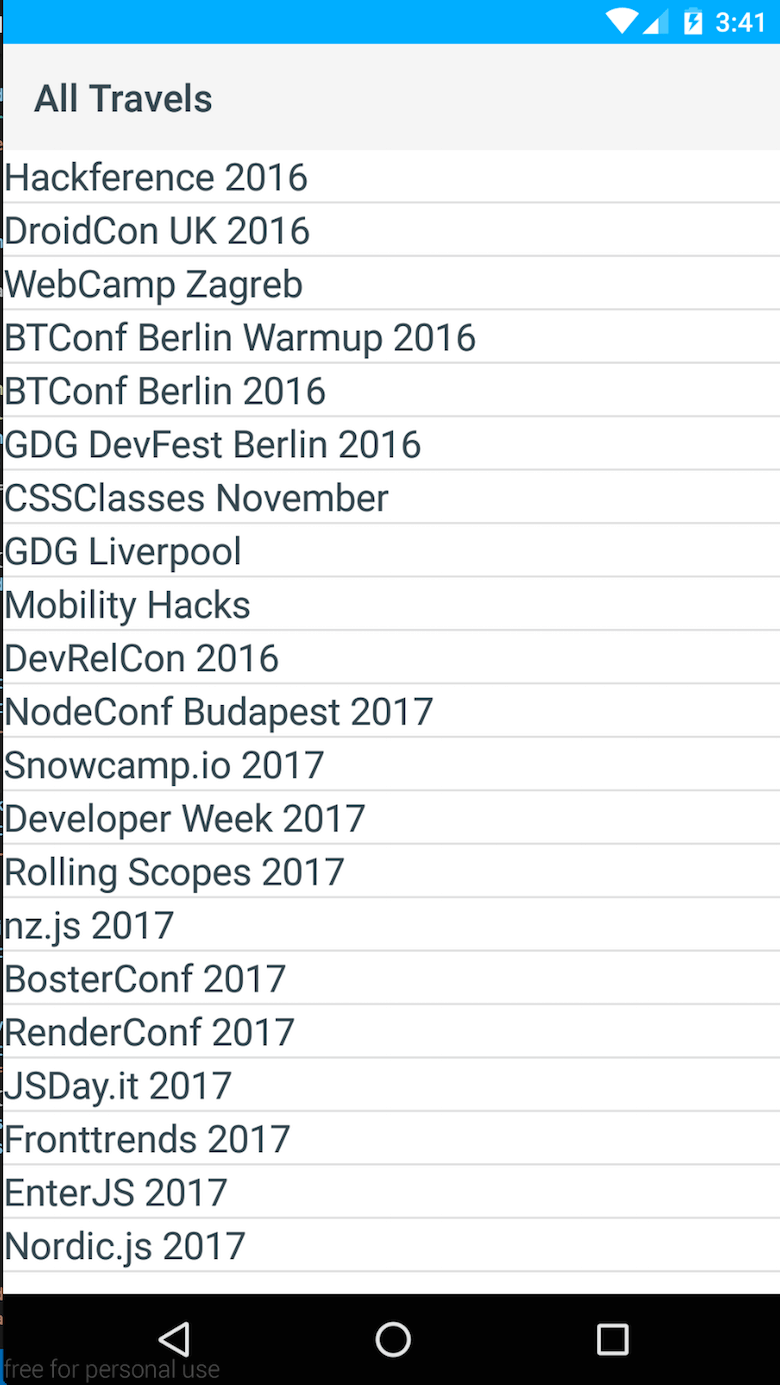
Jak więc widać — zbudowanie prostej listy przy użyciu NativeScript nie jest trudne. Później rozszerzyłem aplikację o kolejny widok, a także o dodatkową funkcjonalność umożliwiającą otwieranie podanych adresów w Mapach Google oraz widoki internetowe w celu przeglądania stron wydarzeń.
Warto tutaj zwrócić uwagę na to, że NativeScript jest wciąż całkiem nowy, co oznacza, że wtyczki znalezione na npm zwykle nie mają wielu pobrań ani gwiazdek na GitHub. Z początku mnie to irytowało, ale użyłem kilku natywnych komponentów (nativescript-floatingactionbutton, nativescript-advanced-webview i nativescript-pulltorefresh), które pomogły mi uzyskać natywne wrażenia i wszystkie działały idealnie.
Tutaj możesz zobaczyć poprawiony wynik:
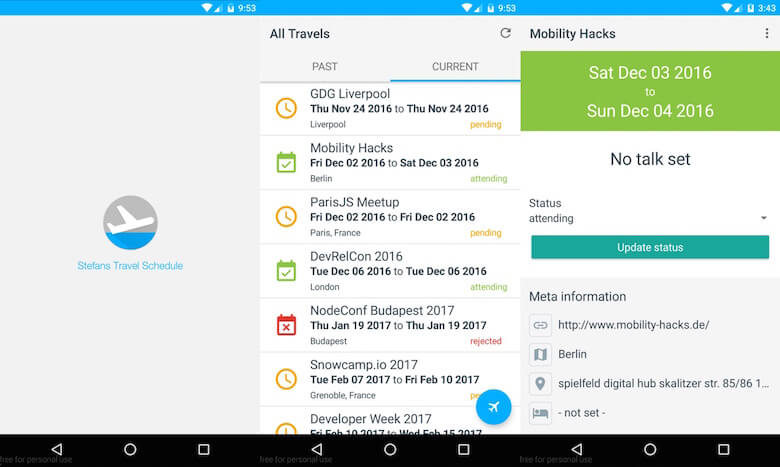
Im więcej funkcjonalności umieściłem w tej aplikacji, tym bardziej mi się podobała i tym częściej z niej korzystałem. Najlepsze jest to, że mogłem pozbyć się duplikacji danych, zarządzając wszystkimi danymi w jednym miejscu, będąc wystarczająco elastycznym, aby wyświetlać je w różnych przypadkach użycia.
Strony są wczoraj: Niech trwają uporządkowane treści!
Budowanie tej aplikacji pokazało mi po raz kolejny, że zasada posiadania danych w formacie strony to już przeszłość. Nie wiemy, dokąd trafią nasze dane — musimy być gotowi na nieograniczoną liczbę przypadków użycia.
Patrząc wstecz, osiągnąłem:
- Posiadanie systemu zarządzania treścią w chmurze
- Brak konieczności zajmowania się utrzymaniem bazy danych
- Kompletny stos technologii JavaScript
- Posiadanie wydajnej statycznej strony internetowej
- Posiadanie aplikacji na Androida, aby zawsze i wszędzie uzyskiwać dostęp do moich treści
I najważniejsza część:
Uporządkowanie i dostępność treści pomogło mi ulepszyć moje codzienne życie.
Ten przypadek użycia może w tej chwili wydawać się trywialny, ale kiedy pomyślisz o produktach, które tworzysz każdego dnia — zawsze jest więcej przypadków użycia dla Twoich treści na różnych platformach. Dzisiaj akceptujemy fakt, że urządzenia mobilne w końcu wyprzedzają stare szkolne środowiska komputerowe, ale platformy takie jak samochody, zegarki, a nawet lodówki już czekają na ich światło dzienne. Nie mogę nawet pomyśleć o przypadkach użycia, które nadejdą.
Spróbujmy więc być gotowi i umieścić ustrukturyzowaną zawartość w środku, ponieważ na końcu nie chodzi o schematy baz danych — chodzi o budowanie przyszłości.
Dalsze czytanie na SmashingMag:
- Skrobanie stron internetowych za pomocą Node.js
- Żeglowanie z Sails.js: Framework w stylu MVC dla Node.js
- 40 ikon podróży, aby urozmaicić swoje projekty
- Szczegółowe wprowadzenie do Webpack