
10 najlepszych poleceń Hadoop [z zastosowaniami]
Opublikowany: 2021-01-29W tej erze, przy ogromnych ilościach danych, konieczne staje się radzenie sobie z nimi. Dane pochodzące z organizacji z rosnącymi klientami są znacznie większe niż może przechowywać jakiekolwiek tradycyjne narzędzie do zarządzania danymi. Pozostaje nam kwestia zarządzania większymi zestawami danych, które mogą wahać się od gigabajtów do petabajtów, bez użycia jednego dużego komputera lub tradycyjnego narzędzia do zarządzania danymi.
W tym miejscu w centrum uwagi znalazła się platforma Apache Hadoop. Zanim zagłębimy się w implementację poleceń Hadoop, przyjrzyjmy się pokrótce strukturze Hadoop i jej znaczeniu.
Spis treści
Co to jest Hadoop?
Hadoop jest powszechnie używany przez duże organizacje biznesowe do rozwiązywania różnych problemów, od codziennego przechowywania dużych GB (gigabajtów) danych po operacje obliczeniowe na danych.
Hadoop, tradycyjnie definiowany jako platforma oprogramowania typu open source, używana do przechowywania danych i aplikacji przetwarzających, dość mocno wyróżnia się na tle większości tradycyjnych narzędzi do zarządzania danymi. Poprawia moc obliczeniową i zwiększa limit przechowywania danych poprzez dodanie kilku węzłów w ramach, dzięki czemu jest wysoce skalowalny. Poza tym Twoje dane i procesy aplikacji są chronione przed różnymi awariami sprzętu.
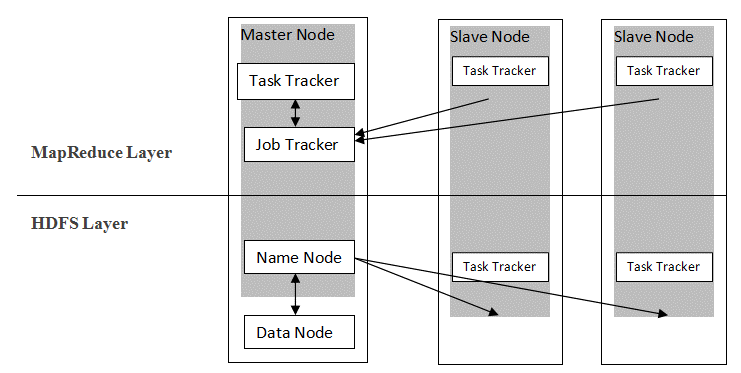
Hadoop wykorzystuje architekturę master-slave do dystrybucji i przechowywania danych przy użyciu MapReduce i HDFS. Jak pokazano na poniższym rysunku, architektura jest dostosowana w określony sposób do wykonywania operacji zarządzania danymi przy użyciu czterech głównych węzłów, a mianowicie nazwy, danych, nadrzędnego i podrzędnego. Podstawowe komponenty Hadoop są zbudowane bezpośrednio na strukturze. Pozostałe komponenty integrują się bezpośrednio z segmentami.
 Źródło
Źródło

Polecenia Hadoop
Główne cechy struktury Hadoop wykazują spójny charakter i stają się bardziej przyjazne dla użytkownika, jeśli chodzi o zarządzanie dużymi danymi dzięki nauce poleceń Hadoop. Poniżej znajduje się kilka wygodnych poleceń Hadoop, które umożliwiają wykonywanie różnych operacji, takich jak zarządzanie i przetwarzanie plików klastrów HDFS. Ta lista poleceń jest często wymagana do osiągnięcia określonych wyników procesu.
1. Hadoop Touchz
hadoop fs -touchz /katalog/nazwa pliku
To polecenie umożliwia użytkownikowi utworzenie nowego pliku w klastrze HDFS. „Katalog” w poleceniu odnosi się do nazwy katalogu, w którym użytkownik chce utworzyć nowy plik, a „nazwa pliku” oznacza nazwę nowego pliku, który zostanie utworzony po zakończeniu polecenia.
2. Polecenie testowe Hadoop
hadoop fs -test -[defsz] <ścieżka>
To konkretne polecenie służy do testowania istnienia pliku w klastrze HDFS. W razie potrzeby należy zmodyfikować znaki z „[defsz]” w poleceniu. Oto krótki opis tych postaci:
- d -> Sprawdza, czy jest to katalog, czy nie
- e -> Sprawdza, czy jest to ścieżka, czy nie
- f -> Sprawdza, czy jest to plik, czy nie
- s -> Sprawdza, czy ścieżka jest pusta, czy nie
- r -> Sprawdza istnienie ścieżki i uprawnienia do odczytu
- w -> Sprawdza istnienie ścieżki i uprawnienia do zapisu
- z -> Sprawdza rozmiar pliku
3. Polecenie tekstowe Hadoop
hadoop fs -text <src>
Polecenie tekstowe jest szczególnie przydatne do wyświetlania przydzielonego pliku zip w formacie tekstowym. Działa poprzez przetwarzanie plików źródłowych i dostarczanie ich zawartości do zwykłego zdekodowanego formatu tekstowego.

4. Hadoop Znajdź polecenie
hadoop fs -find <ścieżka> … <wyrażenie>
To polecenie jest zwykle używane do wyszukiwania plików w klastrze HDFS. Skanuje podane wyrażenie w poleceniu ze wszystkimi plikami w klastrze i wyświetla pliki pasujące do zdefiniowanego wyrażenia.
Przeczytaj: Najlepsze narzędzia Hadoop
5. Hadoop Getmerge Command
hadoop fs -getmerge <źródło> <lokalny>
Polecenie Getmerge umożliwia scalenie jednego lub wielu plików w wyznaczonym katalogu w klastrze systemu plików HDFS. Gromadzi pliki w jednym pliku znajdującym się w lokalnym systemie plików. „src” i „localdest” reprezentują znaczenie źródło-przeznaczenie i lokalny cel.
6. Polecenie liczenia Hadoop
hadoop fs -count [opcje] <ścieżka>
Równie oczywiste jak jego nazwa, polecenie Hadoop count zlicza liczbę plików i bajtów w danym katalogu. Dostępne są różne opcje, które modyfikują dane wyjściowe zgodnie z wymaganiami. Są to następujące:
- q -> przydział pokazuje limit całkowitej liczby nazw i wykorzystania miejsca
- u -> wyświetla tylko limit i wykorzystanie
- h -> podaje rozmiar pliku
- v -> wyświetla nagłówek
7. Polecenie dołączenia do pliku Hadoop
hadoop fs -appendToFile <localsrc> <docel>
Umożliwia użytkownikowi dołączenie zawartości jednego lub wielu plików do jednego pliku w określonym pliku docelowym w klastrze systemu plików HDFS. Po wykonaniu tego polecenia podane pliki źródłowe są dołączane do źródła docelowego zgodnie z podaną nazwą pliku w poleceniu.
8. Hadoop ls Command
hadoop fs -ls /ścieżka
Polecenie ls w Hadoop wyświetla listę plików/zawartości w określonym katalogu, tj. ścieżce. Po dodaniu „R” przed /path, dane wyjściowe pokażą szczegóły zawartości, takie jak nazwy, rozmiar, właściciel itd. dla każdego pliku określonego w danym katalogu.
9. Hadoop mkdir Polecenie
hadoop fs -mkdir /ścieżka/nazwa_katalogu
Unikalną cechą tego polecenia jest utworzenie katalogu w klastrze systemu plików HDFS, jeśli katalog nie istnieje. Poza tym, jeśli określony katalog jest obecny, komunikat wyjściowy pokaże błąd oznaczający istnienie katalogu.
10. Polecenie chmod Hadoop
hadoop fs -chmod [-R] <tryb> <ścieżka>
To polecenie jest używane, gdy istnieje potrzeba zmiany uprawnień dostępu do określonego pliku. Po wydaniu polecenia chmod zmieniane są uprawnienia podanego pliku. Należy jednak pamiętać, że uprawnienia zostaną zmodyfikowane, gdy właściciel pliku wykona to polecenie.
Przeczytaj także: samouczek Impala Hadoop
Wniosek
Począwszy od ważnego problemu przechowywania danych, z którym borykają się największe organizacje w dzisiejszym świecie, w tym artykule omówiono rozwiązanie problemu ograniczonego przechowywania danych przez wprowadzenie Hadoop i jego wpływ na wykonywanie operacji zarządzania danymi za pomocą poleceń Hadoop. Dla początkujących w Hadoop opisano przegląd frameworka wraz z jego komponentami i architekturą.

Po przeczytaniu tego artykułu można z łatwością poczuć się pewnie co do swojej wiedzy w aspekcie frameworka Hadoop i stosowanych w nim poleceń. Wyjątkowa certyfikacja PG w Big Data firmy upGrad: upGrad oferuje specyficzny dla branży 7,5-miesięczny program certyfikacji PG w Big Data, w którym będziesz organizować, analizować i interpretować Big Data za pomocą IIIT-Bangalore.
Zaprojektowany starannie dla pracujących profesjonalistów, pomoże uczniom zdobyć praktyczną wiedzę i ułatwi im wejście w role Big Data.
Najważniejsze punkty programu:
- Nauka odpowiednich języków i narzędzi
- Poznanie zaawansowanych koncepcji programowania rozproszonego, platform Big Data, baz danych, algorytmów i eksploracji sieci
- Akredytowany certyfikat z IIIT Bangalore
- Pomoc w zatrudnieniu, aby wchłonąć się w najlepszych korporacjach wielonarodowych
- Mentoring 1:1, aby śledzić Twoje postępy i pomagać Ci na każdym etapie
- Praca nad projektami i zadaniami na żywo
Kwalifikowalność : matematyka/inżynieria oprogramowania/statystyka/analityka
Sprawdź nasze inne kursy inżynierii oprogramowania w upGrad.