
Primer GraphQL: dlaczego potrzebujemy nowego rodzaju interfejsu API (część 1)
Opublikowany: 2022-03-10W tej serii chcę przedstawić GraphQL. Na koniec powinieneś zrozumieć nie tylko, co to jest, ale także jego pochodzenie, wady i podstawy pracy z nim. W tym pierwszym artykule, zamiast przeskakiwać do implementacji, chcę omówić, w jaki sposób i dlaczego dotarliśmy do GraphQL (i podobnych narzędzi), przyglądając się lekcjom wyciągniętym z ostatnich 60 lat tworzenia API, od RPC do teraz. W końcu, jak barwnie opisał Mark Twain, nie ma nowych pomysłów.
„Nie ma czegoś takiego jak nowy pomysł. To niemożliwe. Po prostu bierzemy wiele starych pomysłów i umieszczamy je w czymś w rodzaju mentalnego kalejdoskopu”.
— Mark Twain w „Własnej autobiografii Marka Twaina: rozdziały z The North American Review”
Ale najpierw muszę zwrócić się do słonia w pokoju. Nowe rzeczy są zawsze ekscytujące, ale mogą też być wyczerpujące. Być może słyszałeś o GraphQL i pomyślałeś sobie: „Dlaczego…” Alternatywnie, może pomyślałeś coś bardziej w stylu: „Dlaczego interesuje mnie nowy trend projektowania API? ODPOCZYNEK jest… w porządku.” To są uzasadnione pytania, więc pozwól mi wyjaśnić, dlaczego powinieneś zwrócić uwagę na to.
Wstęp
Korzyści z wprowadzenia nowych narzędzi do swojego zespołu należy porównać z jego kosztami. Jest wiele rzeczy do zmierzenia. Jest czas potrzebny na naukę, czas konwersji zajmuje rozwój funkcji, koszty utrzymania dwóch systemów. Przy tak wysokich kosztach każda nowa technologia musi być lepsza, szybsza lub bardziej wydajna . Przyrostowe ulepszenia, choć ekscytujące, po prostu nie są warte inwestycji. Rodzaje interfejsów API, o których chcę porozmawiać, w szczególności GraphQL, są moim zdaniem ogromnym krokiem naprzód i zapewniają więcej niż wystarczające korzyści, aby uzasadnić koszty.
Zamiast najpierw badać cechy, warto umieścić je w kontekście i zrozumieć, w jaki sposób powstały. Aby to zrobić, zacznę od krótkiego podsumowania historii interfejsów API.
RPC
RPC było prawdopodobnie pierwszym głównym wzorcem API, a jego początki sięgają wczesnych czasów obliczeniowych w połowie lat 60. XX wieku. W tamtych czasach komputery były tak duże i drogie, że koncepcja tworzenia aplikacji sterowanej przez API, jak o tym myślimy, była w większości tylko teoretyczna. Ograniczenia, takie jak przepustowość/opóźnienie, moc obliczeniowa, współdzielony czas obliczeniowy i fizyczna bliskość , zmuszały inżynierów do myślenia w kategoriach systemów rozproszonych, a nie usług, które eksponują dane. Od ARPANET w latach 60., aż do połowy lat 90. z takimi rzeczami jak CORBA i Java RMI, większość komputerów wchodziła ze sobą w interakcje za pomocą zdalnego wywołania procedur (RPC), który jest modelem interakcji klient-serwer, w którym klient wywołuje procedurę (lub metoda) do wykonania na zdalnym serwerze.
W RPC jest wiele fajnych rzeczy. Jego główną zasadą jest umożliwienie programiście traktowania kodu w środowisku zdalnym tak, jakby był w środowisku lokalnym, aczkolwiek znacznie wolniej i mniej niezawodnie, co zapewnia ciągłość w innych odrębnych i odmiennych systemach. Podobnie jak wiele rzeczy, które wyszły na rynek ARPANET, wyprzedził swoje czasy, ponieważ ten rodzaj ciągłości jest czymś, do czego wciąż dążymy podczas pracy z niewiarygodnymi i asynchronicznymi akcjami, takimi jak dostęp do bazy danych i wywołania usług zewnętrznych.
Przez dziesięciolecia przeprowadzono ogromną ilość badań nad tym, jak umożliwić programistom osadzenie takich zachowań asynchronicznych w typowym przepływie programu; gdyby w tym czasie były dostępne takie rzeczy jak Promises, Futures i ScheduledTasks, możliwe, że nasz krajobraz API wyglądałby inaczej.
Kolejną wielką zaletą RPC jest to, że ponieważ nie jest ono ograniczone strukturą danych, można napisać wysoce wyspecjalizowane metody dla klientów, którzy żądają i pobierają dokładnie potrzebne informacje, co może skutkować minimalnym obciążeniem sieci i mniejszymi obciążeniami.
Są jednak rzeczy, które utrudniają RPC. Po pierwsze, ciągłość wymaga kontekstu . Z założenia RPC tworzy dość duże sprzężenie między systemami lokalnymi i zdalnymi — tracisz granice między kodem lokalnym a zdalnym. W przypadku niektórych domen jest to w porządku lub nawet preferowane, jak w przypadku klienckich pakietów SDK, ale w przypadku interfejsów API, w których kod klienta nie jest dobrze rozumiany, może to być znacznie mniej elastyczne niż coś bardziej zorientowanego na dane.
Ważniejsza jest jednak możliwość rozprzestrzeniania się metod API . Teoretycznie usługa RPC udostępnia mały, przemyślany interfejs API, który może obsłużyć każde zadanie. W praktyce ogromna liczba zewnętrznych punktów końcowych może akreować bez większej struktury. Aby zapobiec nakładaniu się interfejsów API i duplikacji w miarę upływu czasu, gdy członkowie zespołu pojawiają się i odchodzą, a projekty zmieniają się, potrzeba ogromnej dyscypliny.
Prawdą jest, że z odpowiednim oprzyrządowaniem i zmianami w dokumentacji, takimi jak te, o których wspomniałem, można zarządzać, ale w swoim czasie pisania oprogramowania natknąłem się na niewiele usług autodokumentacji i zdyscyplinowanych, więc dla mnie jest to trochę trudne czerwony śledź.
MYDŁO
Kolejnym ważnym typem API, który pojawił się, był SOAP, który narodził się pod koniec lat 90. w Microsoft Research. SOAP ( S imple Object Access Protocol ) to ambitna specyfikacja protokołu do komunikacji między aplikacjami opartej na XML. Ambicją SOAP było zajęcie się niektórymi praktycznymi wadami RPC, w szczególności XML-RPC, poprzez stworzenie dobrze zorganizowanej podstawy dla złożonych usług internetowych. W efekcie oznaczało to po prostu dodanie systemu typów behawioralnych do XML. Niestety, stworzył więcej utrudnień niż rozwiązał, o czym świadczy fakt, że obecnie pisanych jest bardzo niewiele nowych punktów końcowych SOAP.
„SOAP jest tym, co większość ludzi uznałaby za umiarkowany sukces”.
— Don Box
SOAP miał kilka dobrych rzeczy, pomimo nieznośnej gadatliwości i okropnych nazw. Egzekwowalne kontrakty w WSDL i WADL (wymawiane „wizdle” i „waddle”) między klientem a serwerem gwarantowały przewidywalne, bezpieczne dla typu wyniki, a WSDL może być używany do generowania dokumentacji lub tworzenia integracji z IDE i innymi narzędziami.
Wielką rewelacją SOAP w zakresie ewolucji API było stopniowe i prawdopodobnie niezamierzone wprowadzanie wywołań bardziej zorientowanych na zasoby. Punkty końcowe SOAP pozwalają żądać danych o określonej z góry strukturze, zamiast myśleć o metodach wymaganych do wygenerowania danych (zakładając, że są napisane w ten sposób).
Najważniejszą wadą SOAP jest to, że jest tak gadatliwy; jest prawie niemożliwe do użycia bez dużej ilości narzędzi . Potrzebujesz narzędzi do pisania testów, narzędzi do sprawdzania odpowiedzi z serwera i narzędzi do analizowania wszystkich danych. Wiele starszych systemów nadal używa SOAP, ale wymóg narzędzi czyni go zbyt uciążliwym dla większości nowych projektów, a liczba bajtów potrzebnych do struktury XML sprawia, że jest to kiepski wybór do obsługi urządzeń mobilnych lub rozmownych systemów rozproszonych.
Aby uzyskać więcej informacji, warto zapoznać się ze specyfikacją SOAP oraz zaskakująco ciekawą historią SOAP od Don Box, jednego z pierwotnych członków zespołu.
ODPOCZYNEK
Wreszcie doszliśmy do wzorca projektowania API du jour: REST. REST, wprowadzony w rozprawie doktorskiej Roya Fieldinga w 2000 roku, skierował wahadło w zupełnie innym kierunku. REST jest pod wieloma względami antytezą MYDŁA, a patrzenie na nie obok siebie sprawia, że masz wrażenie, że jego rozprawa była trochę wściekłością.
SOAP używa protokołu HTTP jako niemego transportu i buduje jego strukturę w treści żądania i odpowiedzi. Z drugiej strony REST wyrzuca kontrakty klient-serwer, oprzyrządowanie, XML i nagłówki na zamówienie, zastępując je semantyką HTTPs, ponieważ zamiast tego struktura wybiera użycie czasowników HTTP w interakcji z danymi i identyfikatorami URI, które odwołują się do zasobu w pewnej hierarchii dane.
| MYDŁO | ODPOCZYNEK | |
|---|---|---|
| Czasowniki HTTP | POBIERZ, WŁÓŻ, PUBLIKUJ, ZAŁATUJ, USUŃ | |
| Format danych | XML | Cokolwiek chcesz |
| Umowy klient/serwer | Cały dzień każdego dnia! | Kto ich potrzebuje? |
| Rodzaj systemu | JavaScript ma unsigned short, prawda? | |
| adresy URL | Opisz operacje | Zasoby nazwane |
REST całkowicie i jawnie zmienia projekt API z interakcji modelowania na proste modelowanie danych domeny. Będąc w pełni zorientowanym na zasoby podczas pracy z REST API, nie musisz już wiedzieć ani dbać o to, czego potrzeba, aby pobrać dany fragment danych; nie musisz też wiedzieć nic o implementacji usług backendu.

Prostota była nie tylko dobrodziejstwem dla programistów, ale ponieważ adresy URL reprezentują stabilne informacje, można je łatwo buforować, jego bezstanowość ułatwia skalowanie w poziomie, a ponieważ modeluje dane zamiast przewidywać potrzeby konsumentów, może znacznie zmniejszyć powierzchnię interfejsów API .
REST jest świetny, a jego wszechobecność to zadziwiający sukces, ale jak wszystkie rozwiązania, które pojawiły się wcześniej, REST nie jest pozbawiony wad. Aby konkretnie omówić niektóre z jego niedociągnięć, przyjrzyjmy się podstawowemu przykładowi. Załóżmy, że musimy zbudować stronę docelową bloga, która wyświetla listę postów na blogu i nazwisko ich autora.
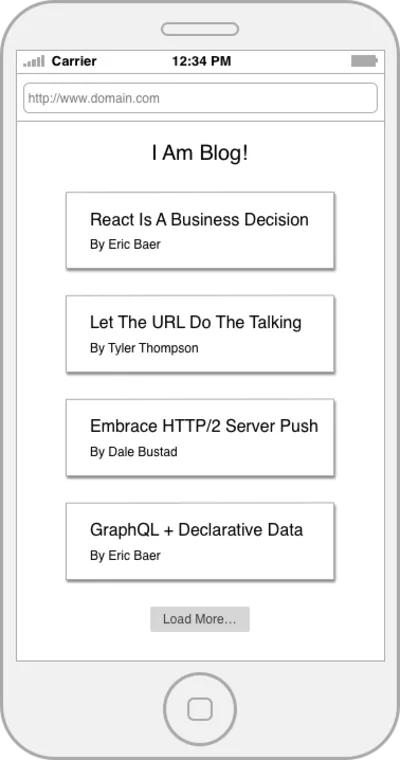
Napiszmy kod, który może pobrać dane strony głównej ze zwykłego interfejsu API REST. Zaczniemy od kilku funkcji, które otaczają nasze zasoby.
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/posts/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/authors/${authorId}`);A teraz zorganizujmy!
const getPostWithAuthor = postId => { return getPost(postId) .then(post => getAuthor(post.author)) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(postIds => { const postDetails = postIds.map(getPostWithAuthor); return Promise.all(postDetails); }) };Więc nasz kod wykona następujące czynności:
- Pobierz wszystkie posty;
- Pobierz szczegółowe informacje o każdym poście;
- Pobierz zasób autora dla każdego posta.
Fajną rzeczą jest to, że jest to dość łatwe do zrozumienia, dobrze zorganizowane, a granice pojęciowe każdego zasobu są dobrze nakreślone. Problem polega na tym, że właśnie wysłaliśmy osiem żądań sieciowych, z których wiele dzieje się szeregowo.
GET /posts GET /posts/234 GET /posts/456 GET /posts/17 GET /posts/156 GET /author/9 GET /author/4 GET /author/7 GET /author/2 Tak, możesz skrytykować ten przykład, sugerując, że interfejs API może mieć podzielony na strony punkt końcowy /posts , ale to dzieli włosy. Faktem jest, że często masz zbiór wywołań API, które zależą od siebie w celu renderowania kompletnej aplikacji lub strony.
Tworzenie klientów i serwerów REST jest z pewnością lepsze niż to, co było wcześniej, a przynajmniej bardziej idiotyczne, ale wiele się zmieniło w ciągu dwóch dekad od publikacji Fieldinga. W tym czasie wszystkie komputery były z beżowego plastiku; teraz są aluminiowe! Poważnie jednak, rok 2000 był blisko szczytu eksplozji komputerów osobistych. Każdego roku procesory podwajały prędkość, a sieci stawały się szybsze w niewiarygodnym tempie. Penetracja rynku w Internecie wyniosła około 45% i nie było dokąd pójść, ale w górę.
Następnie, około 2008 roku, komputery mobilne weszły do głównego nurtu. W przypadku urządzeń mobilnych skutecznie cofnęliśmy się o dekadę pod względem szybkości/wydajności z dnia na dzień. W 2017 roku mamy prawie 80% penetracji smartfonów w kraju i ponad 50% na świecie i nadszedł czas, aby przemyśleć niektóre z naszych założeń dotyczących projektowania API.
Słabości REST
Poniżej znajduje się krytyczne spojrzenie na REST z perspektywy programisty aplikacji klienckich, w szczególności pracującego na urządzeniach mobilnych. Interfejsy API w stylu GraphQL i GraphQL nie są nowe i nie rozwiązują problemów, które są poza zasięgiem programistów REST. Najważniejszym wkładem GraphQL jest jego zdolność do systematycznego rozwiązywania tych problemów na poziomie integracji, który nie jest łatwo dostępny gdzie indziej. Innymi słowy, jest to rozwiązanie „z bateriami”.
Główni autorzy REST, w tym Fielding, opublikowali artykuł pod koniec 2017 r. (Reflections on the REST Architectural Style i „Principled Design of the Modern Web Architecture”), w którym zastanawiali się nad dwiema dekadami REST i wieloma wzorami, które zainspirowały. Jest krótka i absolutnie warta przeczytania dla każdego, kto interesuje się projektowaniem API.
Z pewnym kontekstem historycznym i aplikacją referencyjną przyjrzyjmy się trzem głównym słabościom REST.
ODPOCZYNEK to rozmowni
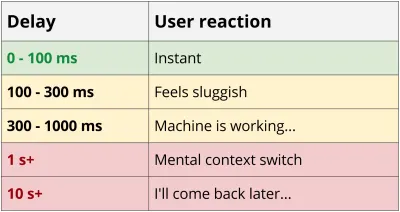
Usługi REST wydają się być co najmniej nieco „rozmowne”, ponieważ wymaga wielu podróży w obie strony między klientem a serwerem, aby uzyskać wystarczającą ilość danych do renderowania aplikacji. Ta kaskada żądań ma niszczący wpływ na wydajność, zwłaszcza na urządzeniach mobilnych. Wracając do przykładu z bloga, nawet w najlepszym scenariuszu, z nowym telefonem i niezawodną siecią z połączeniem 4G, spędziłeś prawie 0,5 sekundy na samym opóźnieniu, zanim pierwszy bajt danych zostanie pobrany.
Opóźnienie 55 ms 4G * 8 żądań = narzut 440 ms
Innym problemem związanym z usługami rozmów jest to, że w wielu przypadkach pobranie jednego dużego żądania zajmuje mniej czasu niż wielu małych. Zmniejszona wydajność małych żądań jest prawdziwa z wielu powodów, w tym powolnego startu TCP, braku kompresji nagłówków i wydajności gzip. Jeśli jesteś ciekawy, gorąco polecam przeczytanie High-Performance Browser Networking Ilyi Grigorika. Blog MaxCDN zawiera również świetny przegląd.
Ten problem nie dotyczy technicznie REST, ale HTTP, a konkretnie HTTP/1. HTTP/2 niemalże rozwiązuje problem czatowania niezależnie od stylu API i ma szerokie wsparcie w klientach, takich jak przeglądarki i natywne pakiety SDK. Niestety, po stronie API wdrażanie przebiega powoli. Wśród 10 tysięcy najlepszych stron internetowych, adopcja wynosi około 20% (i rośnie) pod koniec 2017 roku. Nawet Node.js, ku mojemu zaskoczeniu, otrzymał wsparcie HTTP/2 w wersji 8.x. Jeśli masz taką możliwość, zaktualizuj swoją infrastrukturę! Tymczasem nie zatrzymujmy się, bo to tylko jedna część równania.
Pomijając HTTP, ostatni element wyjaśniający, dlaczego gadatliwość ma znaczenie, ma związek z działaniem urządzeń mobilnych, a konkretnie ich radia. Krótko mówiąc, obsługa radia jest jedną z najbardziej obciążających baterię części telefonu, więc system operacyjny wyłącza je przy każdej okazji. Uruchomienie radia nie tylko wyczerpuje baterię, ale dodatkowo zwiększa obciążenie każdego żądania.
TMI (nadmierne pobieranie)
Kolejnym problemem związanym z usługami w stylu REST jest to, że wysyła się więcej informacji, niż jest to potrzebne. W naszym przykładzie bloga potrzebujemy tylko tytułu każdego posta i nazwiska jego autora, które stanowi tylko około 17% tego, co zostało zwrócone. To 6x strata dla bardzo prostego ładunku. W rzeczywistym interfejsie API tego rodzaju obciążenie może być ogromne. Na przykład witryny e-commerce często przedstawiają pojedynczy produkt jako tysiące wierszy JSON. Podobnie jak problem czatowania, usługi REST mogą dziś poradzić sobie z tym scenariuszem, używając „rzadkich zestawów pól”, aby warunkowo uwzględnić lub wykluczyć części danych. Niestety, obsługa tego jest niepełna, niekompletna lub problematyczna dla buforowania sieci.
Oprzyrządowanie i introspekcja
Ostatnią rzeczą, której brakuje w REST API, są mechanizmy introspekcji. Bez umowy z informacjami o typach zwrotów lub strukturze punktu końcowego nie ma możliwości niezawodnego generowania dokumentacji, tworzenia oprzyrządowania lub interakcji z danymi. W ramach REST można pracować nad rozwiązaniem tego problemu w różnym stopniu. Projekty, które w pełni implementują OpenAPI, OData lub JSON API są często czyste, dobrze określone i, w różnym stopniu, dobrze udokumentowane, ale takie backendy są rzadkie. Nawet Hypermedia, stosunkowo nisko wiszący owoc, mimo że był reklamowany na konferencjach od dziesięcioleci, nadal nie jest często robiony dobrze, jeśli w ogóle.
Wniosek
Każdy z typów API jest wadliwy, ale każdy wzorzec jest. To pisanie nie jest oceną fenomenalnych podstaw, które położyli giganci oprogramowania, a jedynie trzeźwą oceną każdego z tych wzorców, zastosowanym w ich „czystej” formie z perspektywy programisty-klienta. Mam nadzieję, że zamiast odchodzić od tego myślenia, wzorzec taki jak REST lub RPC jest zepsuty, możesz odejść od myślenia o tym, w jaki sposób każdy z nich dokonał kompromisów i obszarów, w których organizacja inżynierska może skoncentrować swoje wysiłki na ulepszeniu własnych interfejsów API .
W następnym artykule omówię GraphQL i sposób, w jaki ma on na celu rozwiązanie niektórych problemów, o których wspomniałem powyżej. Innowacja w GraphQL i podobnych narzędziach polega na ich poziomie integracji, a nie na ich implementacji. Proszę, jeśli Ty lub Twój zespół nie szukacie API „dołączonego do baterii”, zastanówcie się nad czymś takim jak nowa specyfikacja OpenAPI, która może pomóc zbudować silniejsze fundamenty już dziś!
Jeśli podobał Ci się ten artykuł (lub go nienawidziłeś) i chciałbyś przekazać mi swoją opinię, znajdź mnie na Twitterze jako @ebaerbaerbaer lub LinkedIn pod adresem ericjbaer.