
Gradientowe zejście w uczeniu maszynowym: jak to działa?
Opublikowany: 2021-01-28Spis treści
Wstęp
Jedną z najważniejszych części uczenia maszynowego jest optymalizacja jego algorytmów. Prawie wszystkie algorytmy w uczeniu maszynowym mają u swojej podstawy algorytm optymalizacji, który działa jako rdzeń algorytmu. Jak wszyscy wiemy, optymalizacja jest ostatecznym celem każdego algorytmu, nawet w przypadku rzeczywistych wydarzeń lub gdy mamy do czynienia z produktem opartym na technologii na rynku.
Obecnie istnieje wiele algorytmów optymalizacyjnych, które są wykorzystywane w kilku aplikacjach, takich jak rozpoznawanie twarzy, samochody autonomiczne, analiza rynkowa itp. Podobnie w uczeniu maszynowym takie algorytmy optymalizacji odgrywają ważną rolę. Jednym z takich szeroko stosowanych algorytmów optymalizacji jest algorytm opadania gradientu, którym zajmiemy się w tym artykule.
Co to jest zejście gradientowe?
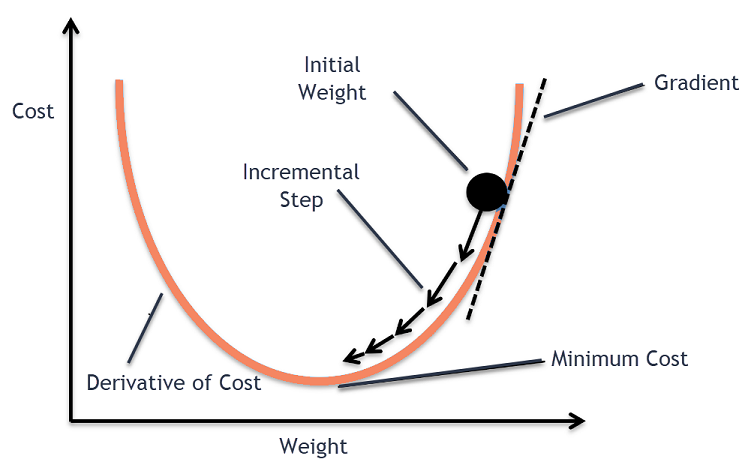
W uczeniu maszynowym algorytm Gradient Descent jest jednym z najczęściej używanych algorytmów, a jednak wprawia w osłupienie większość nowicjuszy. Matematycznie Gradient Descent to iteracyjny algorytm optymalizacji pierwszego rzędu, który służy do znajdowania lokalnego minimum funkcji różniczkowalnej. Mówiąc prościej, ten algorytm Gradient Descent jest używany do znalezienia wartości parametrów funkcji (lub współczynników), które są wykorzystywane do minimalizacji funkcji kosztu do możliwie najniższego poziomu. Funkcja kosztu służy do ilościowego określenia błędu między przewidywanymi wartościami a rzeczywistymi wartościami zbudowanego modelu uczenia maszynowego.
Intuicja ze spadkiem gradientu
Rozważ dużą miskę, w której normalnie trzymasz owoce lub jesz płatki zbożowe. Ta miska będzie funkcją kosztu (f).
Teraz losowa współrzędna na dowolnej części powierzchni czaszy będzie aktualnymi wartościami współczynników funkcji kosztu. Dno miski to najlepszy zestaw współczynników i jest to minimum funkcji.
Tutaj celem jest obliczenie różnych wartości współczynników w każdej iteracji, oszacowanie kosztu i wybranie współczynników, które mają lepszą wartość funkcji kosztu (niższa wartość). W wielu iteracjach okazałoby się, że dno misy ma najlepsze współczynniki, aby zminimalizować funkcję kosztu.

W ten sposób algorytm Gradient Descent działa tak, aby zapewnić minimalny koszt.
Dołącz do kursu uczenia maszynowego online z najlepszych uniwersytetów na świecie — studiów magisterskich, programów podyplomowych dla kadry kierowniczej i zaawansowanego programu certyfikacji w zakresie uczenia maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
Procedura opadania gradientu
Ten proces opadania gradientu rozpoczyna się od wstępnego przypisania wartości współczynnikom funkcji kosztu. Może to być wartość bliska 0 lub mała wartość losowa.
współczynnik = 0,0
Następnie koszt współczynników uzyskuje się przez zastosowanie go do funkcji kosztu i obliczenie kosztu.
koszt = f(współczynnik)
Następnie obliczana jest pochodna funkcji kosztu. Ta pochodna funkcji kosztu jest otrzymywana przez matematyczne pojęcie rachunku różniczkowego. Daje nam nachylenie funkcji w danym punkcie, w którym obliczana jest jej pochodna. To nachylenie jest potrzebne, aby wiedzieć, w którym kierunku współczynnik ma zostać przesunięty w następnej iteracji, aby uzyskać niższą wartość kosztu. Odbywa się to poprzez obserwację znaku obliczonej pochodnej.
delta = pochodna (koszt)
Gdy już wiemy, który kierunek jest w dół od obliczonej pochodnej, musimy zaktualizować wartości współczynników. W tym celu stosuje się parametr znany jako parametr uczenia się, alfa (α). Służy do kontrolowania stopnia, w jakim współczynniki mogą się zmieniać przy każdej aktualizacji.
współczynnik = współczynnik – (alfa * delta)
Źródło
W ten sposób proces ten jest powtarzany, aż koszt współczynników będzie równy 0,0 lub wystarczająco bliski zeru. To jest procedura dla algorytmu opadania gradientu.
Rodzaje algorytmów opadania gradientu
W dzisiejszych czasach istnieją trzy podstawowe typy gradientów, które są wykorzystywane w nowoczesnych algorytmach uczenia maszynowego i głębokiego uczenia. Główną różnicą między każdym z tych 3 typów jest koszt obliczeniowy i wydajność. W zależności od ilości użytych danych, złożoności czasowej i dokładności następujące są trzy typy.
- Gradient wsadowy
- Stochastyczne zejście gradientowe
- Mini-partia Gradient Descent
Gradient wsadowy
Jest to pierwsza i podstawowa wersja algorytmu Gradient Descent, w której cały zestaw danych jest używany jednocześnie do obliczenia funkcji kosztu i jej gradientu. Ponieważ cały zestaw danych jest używany za jednym razem do pojedynczej aktualizacji, obliczanie gradientu tego typu może być bardzo powolne i nie jest możliwe w przypadku zestawów danych, które są poza pojemnością pamięci urządzenia.
W związku z tym ten algorytm wsadowego opadania gradientu jest używany tylko w przypadku mniejszych zestawów danych, a gdy liczba przykładów uczących jest duża, wsadowe opadanie gradientu nie jest preferowane. Zamiast tego używane są algorytmy Stochastic i Mini Batch Gradient Descent.
Stochastyczne zejście gradientowe
Jest to inny rodzaj algorytmu zniżania gradientu, w którym w jednej iteracji przetwarzany jest tylko jeden przykład uczący. W tym przypadku pierwszym krokiem jest randomizacja całego zestawu danych treningowych. Wtedy tylko jeden przykład uczący jest używany do aktualizacji współczynników. Jest to w przeciwieństwie do Batch Gradient Descent, w którym parametry (współczynniki) są aktualizowane tylko wtedy, gdy wszystkie przykłady uczące są oceniane.

Stochastic Gradient Descent (SGD) ma tę zaletę, że ten rodzaj częstych aktualizacji zapewnia szczegółowy wskaźnik poprawy. Jednak w niektórych przypadkach może się to okazać kosztowne obliczeniowo, ponieważ przetwarza tylko jeden przykład w każdej iteracji, co może powodować bardzo dużą liczbę iteracji.
Mini-partia Gradient Descent
Jest to niedawno opracowany algorytm, który jest szybszy niż algorytmy Batch i Stochastic Gradient Descent. Jest to najbardziej preferowane, ponieważ jest połączeniem obu wspomnianych wcześniej algorytmów. W tym przypadku dzieli zestaw uczący na kilka mini-partii i wykonuje aktualizację dla każdej z tych partii po obliczeniu gradientu tej partii (jak w SGD).
Zwykle wielkość partii waha się od 30 do 500, ale nie ma ustalonego rozmiaru, ponieważ różnią się one w zależności od aplikacji. Dlatego nawet jeśli istnieje ogromny zestaw danych uczących, algorytm ten przetwarza je w mini-partiach „b”. Dzięki temu nadaje się do dużych zestawów danych z mniejszą liczbą iteracji.
Jeśli 'm' jest liczbą przykładów uczących, to jeśli b==m Mini Batch Gradient Descent będzie podobny do algorytmu Batch Gradient Descent.
Warianty opadania gradientu w uczeniu maszynowym
Na tej podstawie Gradient Descent powstało kilka innych algorytmów, które zostały na tej podstawie opracowane. Kilka z nich zostało podsumowanych poniżej.
Waniliowe zejście gradientowe
Jest to jedna z najprostszych form techniki Gradient Descent. Nazwa wanilia oznacza czystą lub bez żadnych zafałszowań. W tym przypadku podejmuje się małe kroki w kierunku minimów, obliczając gradient funkcji kosztu. Podobnie jak w powyższym algorytmie, reguła aktualizacji jest określona przez,
współczynnik = współczynnik – (alfa * delta)
Gradientowe opadanie z rozpędem
W tym przypadku algorytm jest taki, że znamy poprzednie kroki przed podjęciem następnego kroku. Odbywa się to poprzez wprowadzenie nowego terminu, który jest produktem poprzedniej aktualizacji i stałą znaną jako pęd. W tym przypadku reguła aktualizacji wagi jest podana przez,
aktualizacja = alfa * delta
prędkość = poprzednia_aktualizacja * pęd
współczynnik = współczynnik + prędkość – aktualizacja
ADAGRAD
Termin ADAGRAD oznacza adaptacyjny algorytm gradientu. Jak sama nazwa wskazuje, wykorzystuje technikę adaptacyjną do aktualizacji wag. Ten algorytm jest bardziej odpowiedni dla rzadkich danych. Optymalizacja ta zmienia swoje tempo uczenia się w zależności od częstotliwości aktualizacji parametrów podczas treningu. Na przykład parametry, które mają wyższe gradienty, mają wolniejsze tempo uczenia się, aby nie przekroczyć wartości minimalnej. Podobnie, niższe gradienty mają szybsze tempo uczenia się, aby szybciej trenować.
ADAM
Jeszcze innym algorytmem optymalizacji adaptacyjnej, który ma swoje korzenie w algorytmie Gradient Descent, jest ADAM, który jest skrótem od Adaptive Moment Estimation. Jest to połączenie algorytmów ADAGRAD i SGD z algorytmami Momentum. Jest zbudowany z algorytmu ADAGRAD i jest zbudowany dalej w dół. W uproszczeniu ADAM = ADAGRAD + Pęd.
W ten sposób istnieje kilka innych wariantów algorytmów opadania gradientu, które zostały opracowane i są rozwijane na świecie, takich jak AMGSrad, ADAMax.
Wniosek
W tym artykule zobaczyliśmy algorytm stojący za jednym z najczęściej używanych algorytmów optymalizacji w uczeniu maszynowym, algorytmami gradientu, wraz z jego rodzajami i wariantami, które zostały opracowane.
upGrad zapewnia program Executive PG w uczeniu maszynowym i sztucznej inteligencji oraz tytuł magistra w uczeniu maszynowym i sztucznej inteligencji , które mogą poprowadzić Cię w kierunku budowania kariery. Kursy te wyjaśnią potrzebę uczenia maszynowego i dalsze kroki w celu gromadzenia wiedzy w tej domenie, obejmujące różne koncepcje, od Gradient Descent w uczeniu maszynowym.
Gdzie algorytm opadania gradientu może wnieść maksymalny wkład?
Optymalizacja w ramach dowolnego algorytmu uczenia maszynowego jest przyrostowa w stosunku do czystości algorytmu. Gradient Descent Algorithm pomaga zminimalizować błędy funkcji kosztów i poprawić parametry algorytmu. Chociaż algorytm Gradient Descent jest szeroko stosowany w uczeniu maszynowym i głębokim uczeniu, jego skuteczność można określić na podstawie ilości danych, preferowanej ilości iteracji i dokładności oraz dostępnego czasu. W przypadku zestawów danych na małą skalę optymalny jest tryb Batch Gradient Descent. Stochastic Gradient Descent (SGD) okazuje się być bardziej wydajny w przypadku szczegółowych i bardziej obszernych zbiorów danych. Natomiast funkcja Mini Batch Gradient Descent służy do szybszej optymalizacji.
Jakie wyzwania stoją przed spadkiem nachylenia?
Gradient Descent jest preferowany w celu optymalizacji modeli uczenia maszynowego w celu zmniejszenia funkcji kosztów. Ma jednak również swoje wady. Załóżmy, że Gradient jest zmniejszony z powodu minimalnych funkcji wyjściowych warstw modelu. W takim przypadku iteracje nie będą tak skuteczne, ponieważ model nie zostanie w pełni przeszkolony, aktualizując swoje wagi i odchylenia. Czasami gradient błędu gromadzi mnóstwo wag i odchyleń, aby aktualizować iteracje. Jednak gradient ten staje się zbyt duży do zarządzania i nazywa się gradientem eksplodującym. Należy zająć się wymaganiami infrastrukturalnymi, bilansem tempa uczenia się, dynamiką.
Czy zejście gradientowe zawsze się zbiega?
Zbieżność ma miejsce wtedy, gdy algorytm gradientu skutecznie minimalizuje swoją funkcję kosztu do optymalnego poziomu. Gradient Descent Algorithm stara się zminimalizować funkcję kosztu poprzez parametry algorytmu. Może jednak wylądować w dowolnym z optymalnych punktów i niekoniecznie w tym, który ma globalny lub lokalny punkt optymalny. Jednym z powodów braku optymalnej zbieżności jest wielkość kroku. Większa wielkość kroku powoduje więcej oscylacji i może odbiegać od globalnego optimum. W związku z tym opadanie gradientu może nie zawsze zbiegać się na najlepszym elemencie, ale nadal kończy się na najbliższym punkcie obiektu.