
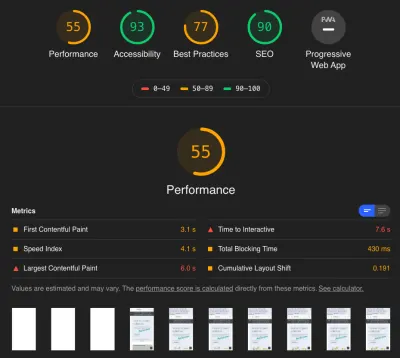
Poprawa wydajności sklepu internetowego (studium przypadku)
Opublikowany: 2022-03-10Każdy programista front-end goni tego samego świętego Graala wydajności: zielone wyniki w Google Page Speed. Zawsze doceniamy namacalne oznaki dobrze wykonanej pracy. Podobnie jak w przypadku polowania na Graala, musisz jednak zadać sobie pytanie, czy naprawdę jest to odpowiedź, której szukasz. Rzeczywista wydajność dla Twoich użytkowników i to, jak „czuje się” witryna, gdy z niej korzystasz, nie powinny być dyskontowane, nawet jeśli kosztuje to punkt lub dwa w Page Speed (w przeciwnym razie wszyscy mielibyśmy tylko pasek wyszukiwania i niestylowany tekst).
Pracuję w małej agencji cyfrowej, a mój zespół pracuje głównie nad dużymi firmowymi stronami internetowymi i sklepami — w pewnym momencie w dyskusji pojawia się szybkość strony, ale zazwyczaj do tego czasu odpowiedź brzmi, że aby naprawdę osiągnąć cokolwiek, potrzebna byłaby ogromna przeróbka, niefortunny efekt uboczny wielkości i struktury projektów w korporacjach.
Praca z jewellerybox w jej sklepie internetowym była dla nas mile widzianą zmianą tempa. Projekt polegał na aktualizacji oprogramowania sklepu do własnego systemu open-source i przerobieniu od podstaw frontendu sklepu. Projekt wykonała agencja designu i UX, która zajmowała się również prototypem HTML (w oparciu o Bootstrap 4). Stamtąd włączyliśmy go do szablonów — i tym razem mieliśmy obsesję klienta na punkcie wydajności strony internetowej.
Na początku skupiliśmy się głównie na wypuszczeniu nowego projektu, ale kiedy ponownie uruchomiliśmy witrynę, zaczęliśmy skupiać naszą uwagę na zamianie czerwonych i pomarańczowych wyników na zielone. To była wielomiesięczna podróż pełna trudnych decyzji, z wieloma dyskusjami o tym, jakie optymalizacje warto było kontynuować. Dziś strona jest znacznie szybsza i zajmuje wysokie pozycje w różnych prezentacjach i testach porównawczych. W tym artykule przedstawię niektóre prace, które wykonaliśmy i jak udało nam się osiągnąć naszą prędkość.
Sklepy internetowe są nieco inne
Zanim przejdziemy do szczegółów, porozmawiajmy przez chwilę o tym, czym sklepy internetowe różnią się od wielu innych stron internetowych (jeśli już to wiesz, spotkamy się w następnym rozdziale). Kiedy mówimy o witrynie e-commerce, główne strony, które będziesz mieć, to:
- strona główna (i strony „treści”),
- strony kategorii i wyszukiwania,
- strony ze szczegółami produktu,
- koszyk i kasa (oczywiście).
W tym artykule skupimy się na pierwszych trzech i dostosowaniu ich wydajności. Kasa to sama w sobie bestia. Będziesz tam mieć dużo dodatkowego JavaScript i logiki zaplecza do obliczania cen, a także kilka połączeń serwisowych, aby uzyskać odpowiedniego dostawcę i szacunki cen w oparciu o kraj, do którego jest wysyłana.
Jest to oczywiście dodatek do walidacji pól formularzy , które będą potrzebne do zarejestrowania adresu rozliczeniowego i wysyłkowego. Dodaj do tego drop-in dostawcy płatności i masz kilka stron, których nikt nie będzie chciał dotykać, gdy zostaną odpowiednio przetestowane i działają.
Jaka jest pierwsza rzecz, o której myślisz, kiedy wyobrażasz sobie sklep internetowy? Obrazy — wiele, wiele zdjęć produktów. Są praktycznie wszędzie i zdominują Twój projekt. Poza tym będziesz chciał pokazać wiele produktów, aby skłonić ludzi do kupowania od Ciebie — więc jest to karuzela. Ale poczekaj! Czy ludzie klikają zawarte w nim produkty? Możemy się tego dowiedzieć, umieszczając śledzenie na karuzeli. Jeśli to namierzymy, możemy to zoptymalizować! I nagle na naszych stronach pojawiły się zewnętrzne karuzele produktów oparte na sztucznej inteligencji.
Chodzi o to, że karuzela nie będzie ostatnim elementem ograniczającym szybkość, który dodasz do strony, aby zaprezentować więcej produktów w nadziei na przyciągnięcie większej sprzedaży. Oczywiście sklep potrzebuje elementów interaktywnych , czy to powiększenia obrazu produktu, kilku filmów, odliczania do dzisiejszego terminu wysyłki, czy okna czatu, aby skontaktować się z obsługą klienta.
Wszystko to jest bardzo ważne, gdy konwersje mierzysz bezpośrednio jako przychody . Co więcej, co kilka miesięcy ktoś z zespołu zauważy kilka fajnych nowych funkcji, które można dodać, więc złożoność i JavaScript zaczną się kumulować, nawet jeśli zaczynałeś z najlepszymi intencjami, aby zachować szczupłą obsługę.
I chociaż zwykle można buforować całą stronę artykułu, to samo nie dotyczy wielu stron i elementów sklepu. Niektóre są specyficzne dla użytkownika, takie jak koszyk w nagłówku lub lista życzeń, i ze względu na osobisty charakter danych nigdy nie powinny być buforowane. Dodatkowo, jeśli posiadasz towary fizyczne, masz do czynienia z inwentarzem na żywo: szczególnie w okresie świątecznym, będziesz potrzebować dokładnych i aktualnych informacji o inwentarzu; więc będziesz potrzebować bardziej złożonej strategii buforowania, która umożliwi buforowanie części strony i połączenie wszystkiego z powrotem podczas renderowania po stronie serwera.
Ale nawet w fazie planowania czekają pułapki. W fazie projektowania — a często także w fazie prototypu — będziesz pracować z precyzyjnie dopracowanymi nazwami i opisami produktów, o niemal jednolitej długości i idealnymi obrazami produktów. Wyglądają niesamowicie! Jedyny problem? W rzeczywistości informacje o produkcie mogą mieć bardzo różną długość , co może zepsuć Twój projekt. Przy kilku tysiącach produktów nie da się sprawdzić każdego z nich.
Dlatego pomaga, jeśli projektanci lub osoby przeprowadzające test prototypu z bardzo krótkimi i bardzo długimi strunami, aby upewnić się, że projekt nadal pasuje. Podobnie, posiadanie informacji pojawiających się dwukrotnie w kodzie HTML, raz na komputerze, a raz na urządzeniu mobilnym, może być dużym problemem dla sklepu — zwłaszcza jeśli są to złożone informacje, takie jak szczegóły produktu, koszyk na zakupy lub aspekty filtrów w kategorii produktów strona. Synchronizacja tych elementów jest trudna do wykonania — więc pomóż innemu programiście i nie rób tego.
Inną rzeczą, która nigdy nie powinna być przemyślana i powinna być włączona od etapu prototypu, jest dostępność. Kilka dostępnych narzędzi może pomóc Ci w podstawowych elementach, od alternatywnego tekstu dla wszystkich obrazów i ikon z funkcją, przez kontrast kolorów, po wiedzę, których atrybutów ARIA użyć, gdzie (a kiedy nie). Włączenie tego od samego początku jest o wiele łatwiejsze niż później i pozwala wszystkim cieszyć się witryną, nad którą pracujesz.
Oto wskazówka: jeśli nie widziałeś, jak ludzie używają czytnika ekranu lub nawigują za pomocą tylko klawiatury, filmy na ten temat można łatwo znaleźć w YouTube. Zmieni to twoje rozumienie tych tematów.
Powrót do wydajności: dlaczego tak ważne jest ponowne poprawienie wydajności sklepu? Oczywistą odpowiedzią jest to, że chcesz, aby ludzie kupowali od Ciebie . Istnieje kilka sposobów, na które możesz wpłynąć na to, a szybkość Twojej witryny jest duża. Badania pokazują, że każda dodatkowa sekunda czasu ładowania ma znaczący wpływ na współczynnik konwersji. Dodatkowo szybkość strony jest czynnikiem rankingowym dla wyszukiwania, a także dla Twoich reklam Google. Tak więc poprawa wydajności będzie miała wymierny wpływ na wynik finansowy.
Praktyczne rzeczy, które zrobiliśmy
Niektóre wąskie gardła wydajności są łatwe do zidentyfikowania, ale dokładna poprawa to dłuższa podróż, z wieloma zwrotami akcji. Zaczęliśmy od wszystkich zwykłych rzeczy, takich jak ponowne sprawdzenie buforowania zasobów, sprawdzenie, co możemy pobrać z wyprzedzeniem lub załadować asynchronicznie, upewniając się, że używamy HTTP/2 i TLSv1.3. Wiele z nich omówiono w pomocnym omówieniu CSS-Tricks, a Smashing Magazine oferuje świetną listę kontrolną w formacie PDF.
Najpierw najważniejsze rzeczy: rzeczy załadowane na wszystkich stronach
Porozmawiajmy o zasobach, a nie tylko CSS czy JavaScript (o których omówimy później). Zaczęliśmy od przyjrzenia się rzeczom udostępnianym na wielu ekranach, z których każdy może mieć wpływ. Dopiero potem skupiliśmy się na typach stron i problemach dla nich unikalnych. Niektóre wspólne elementy były następujące.
Ładowanie ikon
Jak na wielu stronach internetowych, w naszym projekcie używamy kilku ikon. Prototyp zawierał kilka niestandardowych ikon, które były osadzone w symbolach SVG. Były one przechowywane jako jeden duży tag svg w nagłówku HTML strony, z symbolem dla każdej ikony, który był następnie używany jako połączony svg w treści HTML. Daje to miły efekt, ponieważ udostępnia je bezpośrednio przeglądarce po załadowaniu dokumentu, ale oczywiście przeglądarka nie może ich buforować dla całej witryny.
Postanowiliśmy więc przenieść je do zewnętrznego pliku SVG i wstępnie go załadować. Dodatkowo uwzględniliśmy tylko ikony, których faktycznie używamy. W ten sposób plik może być buforowany na serwerze i w przeglądarce, a niepotrzebne pliki SVG nie będą musiały być interpretowane. Wspieramy również użycie Font Awesome na stronie (które ładujemy za pomocą JavaScript), ale ładujemy go na żądanie (dodając mały skrypt, który sprawdza, czy nie ma tagów <i> , a następnie ładując Font Awesome JavaScript, aby uzyskać dowolny SVG znalezionych ikon). Ponieważ trzymamy się własnych ikon w części strony widocznej na ekranie, możemy uruchomić cały skrypt po załadowaniu DOM.
Używamy również emoji w niektórych miejscach do tworzenia kolorowych ikon, o czym nikt z nas tak naprawdę nie myślał, ale o co poprosiła nasza redaktorka Daena i które są świetnym sposobem na pokazywanie ikon bez żadnego negatywnego wpływu na wydajność (jedynym zastrzeżeniem jest różne projekty w różnych systemach operacyjnych).
Ładowanie czcionki
Podobnie jak na wielu innych stronach internetowych, używamy czcionek internetowych do naszych potrzeb typograficznych. Projekt wymaga dwóch czcionek w treści ( Josefin Sans w dwóch grubościach), jednej dla nagłówków ( Nixie One ) i jednej dla specjalnie stylizowanego tekstu ( Moonstone Regular ). Od początku przechowywaliśmy je lokalnie, w sieci dostarczania treści (CDN) w celu zapewnienia wydajności, ale po przeczytaniu wspaniałego artykułu autorstwa Simona Hearne'a na temat unikania zmian w układzie podczas ładowania czcionek, eksperymentowaliśmy z usunięciem pogrubionej wersji i użyciem zwykłej.
W naszych testach różnica wizualna była tak niewielka, że żaden z naszych testerów nie był w stanie stwierdzić, nie widząc obu jednocześnie. Zrezygnowaliśmy więc z wagi czcionki . Pracując nad tym artykułem i przygotowując pomoc wizualną do tej sekcji, natknęliśmy się na większe różnice między przeglądarkami opartymi na Chromium na Macu i opartymi na WebKit na ekranach o wysokiej rozdzielczości (tak, złożoność!). Doprowadziło to do kolejnej rundy dyskusji na temat tego, co powinniśmy zrobić.
Po kilku tam iz powrotem zdecydowaliśmy się zachować pogrubienie i użyć -webkit-text-stroke: 0.3px , aby pomóc tym konkretnym przeglądarkom. Różnica w stosunku do rzeczywistej wagi oddzielnej czcionki jest niewielka, ale niewystarczająca dla naszego przypadku użycia, w którym prawie nie używamy czcionki pogrubionej, a jedynie garstkę słów naraz (przepraszam, miłośnicy czcionek).
Zobacz pióro [Studium przypadku z biżuterią (przykład nr 1)](https://codepen.io/smashingmag/pen/MWprwyE) autorstwa Pfenya.
Dodatkowo kilka produktów można spersonalizować grawerami . Te grawery można wykonać wieloma czcionkami, a dla niektórych oferujemy podgląd z zastosowaną czcionką. W tym celu pobieramy czcionkę na żądanie, gdy zostanie wybrana w rozwijanym selektorze czcionek. Podglądy w menu to przykładowe obrazy tego, jak wygląda czcionka. Dzięki temu nie musimy pobierać 10 lub więcej dodatkowych plików czcionek.
Wsparcie starszego typu
Pewnego dnia CSS-Tricks zaskoczył mnie artykułem „Jak favicon w 2021”. Używaliśmy każdego rozmiaru ikony dotykowej na świecie — artykuł skłonił mnie do ponownej oceny tego, czego naprawdę potrzebujemy i pokazał mi, że czasami to, co było prawdą kilka lat temu, może już nie być potrzebne. Na podstawie artykułu ograniczyliśmy nasze listy favicon i ikon dotykowych do zalecanych wersji.
Podobnie przekonwertowaliśmy czcionkę, którą mieliśmy tylko jako wersję WOFF, na WOFF2 , która jest znacznie mniejsza, i zdecydowaliśmy się zapewnić WOFF2 dla czcionek (z WOFF pozostającym jako rezerwą). I usunęliśmy dyrektywy CSS, które nie są już potrzebne.
Ładowanie leniwe i na żądanie
Kilka wskaźników koncentruje się na czasie, po którym użytkownicy mogą wejść w interakcję ze stroną. Logika podpowiada, że posiadanie mniejszej liczby elementów do załadowania oznacza, że ten punkt zostanie osiągnięty wcześniej. Aby to uwzględnić, ważne jest, aby zadać sobie pytanie, które części strony są niezbędne , a które będą potrzebne użytkownikowi dopiero później. Przeszliśmy w tej sprawie wiele debat i prób i błędów.
W tym przypadku bardzo pomogła kaskada aktywności sieciowej, podobnie jak myślenie o przepływach użytkowników. Na przykład powiększone zdjęcie produktu można wczytać przy pierwszej interakcji użytkownika ze zdjęciem produktu, a zdjęcia w stopce zwykle nie są wyświetlane w części strony widocznej na ekranie i można je załadować później. Jeśli obawiasz się spowolnień, nadal możesz pracować z zasobami pobierania z wyprzedzeniem.
Jedną z rzeczy, które zauważyliśmy bardzo wcześnie, był duży wpływ klienta czatu. To było ponad 500 KB samego JavaScriptu i chociaż niestety nie mam już wykresu, ładowanie również było powolne. Mimo że JavaScript był ustawiony na ładowanie asynchroniczne, Google uwzględniał go w pomiarach czasu do interakcji.
Nie byliśmy w stanie w pełni prześledzić, dlaczego tak się stało, ale między tym a samym rozmiarem zaczęliśmy szukać alternatyw, zamiast próbować naprawić coś, nad czym mieliśmy ograniczoną kontrolę. Przekonaliśmy Jewellerybox , aby zamiast tego wypróbował samodzielnie hostowany widżet czatu typu open source , który daje nam większą kontrolę nad tym, jak się ładuje, a także jest znacznie mniejszy. Aby jeszcze bardziej go ulepszyć, początkowo ładujemy tylko ikonę czatu; reszta zostaje załadowana, gdy klikniesz, aby ją otworzyć.
Niewidzialna karuzela innej firmy
Firma Jewellerybox chciała wypróbować usługę innej firmy, która wykorzystuje sztuczną inteligencję do poprawy personalizacji produktów w karuzeli na kilku stronach. Zdecydowaliśmy się w tym celu wywołać jego API z zaplecza, aby mieć większą kontrolę nad tym, co jest ładowane (bez dużych zależności JavaScript) i jak długo czekamy na odpowiedź od ich usługi (z pewnymi zdefiniowanymi rezerwami). Z tego powodu karuzele ładują się w taki sam sposób jak te niespersonalizowane i mogą być również buforowane za pomocą unikalnego klucza pamięci podręcznej.

Istnieje jednak wada: oznacza to, że początkowe renderowanie strony po stronie serwera może być wolniejsze, jeśli nie zostanie zapisane w pamięci podręcznej. Z tego powodu obecnie pracujemy nad alternatywnymi sposobami wstrzykiwania wyników po załadowaniu strony i najpierw renderowaniu symbolu zastępczego.
Po drugie: optymalizacja JavaScript — zacięta walka z zewnętrznymi wrogami
Karuzela przenosi nas do drugiego dużego obszaru, na którym się skupiliśmy: JavaScript. Sprawdziliśmy JavaScript, który mieliśmy, i większość pochodzi z bibliotek do różnych zadań, z bardzo małą ilością niestandardowego kodu. Zoptymalizowaliśmy kod, który sami napisaliśmy, ale oczywiście możesz zrobić tylko tyle, jeśli jest to tylko ułamek całego kodu — duże korzyści tkwią w bibliotekach.
Optymalizacja zawartości w bibliotekach lub usuwanie niepotrzebnych części to najprawdopodobniej głupia sprawa. Naprawdę nie wiesz, dlaczego są tam niektóre części, i nigdy nie będziesz w stanie uaktualnić biblioteki bez dużej ilości pracy ręcznej. Mając to na uwadze, cofnęliśmy się o krok i przyjrzeliśmy się, których bibliotek używamy i do czego ich potrzebujemy , a także zbadaliśmy dla każdej z nich, czy istnieje mniejsza lub szybsza alternatywa, która równie dobrze pasuje do naszych potrzeb.

W kilku przypadkach było! Na przykład zdecydowaliśmy się zastąpić bibliotekę suwaków Slick na GliderJS, która ma mniej funkcji, ale wszystkie te, których potrzebujemy, a ponadto jest szybsza do załadowania i ma bardziej nowoczesną obsługę CSS! Ponadto wyjęliśmy wiele samodzielnych bibliotek z głównego pliku JavaScript i zaczęliśmy ładować je na żądanie.
Ponieważ używamy Bootstrap 4, nadal uwzględniamy jQuery w projekcie, ale pracujemy nad zastąpieniem wszystkiego implementacjami natywnymi. W przypadku samego Bootstrapa istnieje wersja bootstrap.native na GitHub bez zależności jQuery, której teraz używamy. Jest mniejszy i działa szybciej. Dodatkowo generujemy dwie wersje naszego głównego pliku JavaScript: jedną bez wypełniaczy, a drugą z dołączonymi, a następnie zmieniamy wersję z nimi, gdy przeglądarka ich potrzebuje, co pozwala nam dostarczyć uproszczoną wersję główną do większości ludzi. Przetestowaliśmy usługę „wypełniania na żądanie”, ale wydajność nie spełniła naszych oczekiwań.
Ostatnia rzecz na temat jQuery. Początkowo ładowaliśmy go z naszego serwera. Widzieliśmy poprawę wydajności w naszym systemie testowym podczas ładowania go przez Google CDN, ale Page Speed Insights narzekał na wydajność (ciekawe, kto mógłby to rozwiązać), więc ponownie przetestowaliśmy hosting go samodzielnie, a w środowisku produkcyjnym było faktycznie szybsze ze względu na CDN, z którego korzystamy.
Wyciągnięta lekcja : środowisko testowe nie jest środowiskiem produkcyjnym, a poprawki jednego z nich mogą nie obowiązywać w drugim.
Po trzecie: obrazy — formaty, rozmiary i cały ten jazz
Obrazy są ogromną częścią tego, co składa się na sklep internetowy. Strona będzie miała zwykle kilkadziesiąt obrazów, zanim policzymy różne wersje dla różnych urządzeń. Witryna pudełkowa na biżuterię istnieje od prawie 10 lat, a wiele produktów jest dostępnych przez większość tego czasu, więc oryginalne zdjęcia produktów nie są jednolite pod względem rozmiaru i stylizacji, a liczba zdjęć produktów również może się różnić.
Idealnie, chcielibyśmy zaoferować responsywne obrazy dla różnych rozmiarów widoku i gęstości wyświetlania w nowoczesnych formatach, ale każda zmiana wymagań oznaczałaby wiele pracy do wykonania. Z tego powodu obecnie używamy zoptymalizowanych rozmiarów zdjęć produktów, ale nie mamy dla nich responsywnych zdjęć. Aktualizacja jest na mapie drogowej, ale nie jest trywialna. Strony treści oferują większą elastyczność, a my generujemy i używamy różnych rozmiarów oraz uwzględniamy zarówno formaty WebP, jak i rezerwowe.
Posiadanie tak wielu obrazów znacznie zwiększa początkową ładowność. Tak więc, kiedy i jak ładować obrazy stały się ogromnym tematem. Lazy-loading brzmi jak rozwiązanie, ale jeśli jest stosowany uniwersalnie, może spowolnić początkowo widoczne obrazy, zamiast ładować je bezpośrednio (a przynajmniej tak się wydaje dla użytkownika). Z tego powodu zdecydowaliśmy się na kombinację bezpośredniego ładowania kilku pierwszych i leniwego ładowania pozostałych, używając kombinacji natywnego leniwego ładowania i skryptu.
Do logo strony wykorzystujemy plik SVG, do którego dostaliśmy wstępną wersję od klienta. Logo to misterna czcionka, w której brakuje części liter, tak jakby były one w niedoskonałym nadruku wykonanym ręcznie. W dużych rozmiarach trzeba by pokazać szczegóły, ale na stronie nigdy nie używamy ich powyżej 150 na 30 pikseli. Oryginalny plik miał rozmiar 192 KB, nie był duży, ale też nie bardzo mały. Zdecydowaliśmy się pobawić SVG i zmniejszyć w nim szczegóły, i otrzymaliśmy wersję o rozmiarze 40 KB po rozpakowaniu. Nie ma żadnej wizualnej różnicy w używanych przez nas rozmiarach wyświetlaczy.

Ostatnie, ale zdecydowanie nie mniej: CSS
Krytyczny CSS
CSS ma ogromne znaczenie w raporcie Google Chrome User Experience Report (CrUX), a także w raporcie i rekomendacjach Google Page Speed Insights. Jedną z pierwszych rzeczy, które zrobiliśmy, było zdefiniowanie krytycznego kodu CSS, który ładujemy bezpośrednio do kodu HTML, aby jak najszybciej był dostępny dla przeglądarki — to twoja główna broń do walki ze zmianami układu treści (CLS). Zdecydowaliśmy się na połączenie automatycznej ekstrakcji krytycznego CSS w oparciu o prototypową stronę i mechanizm, za pomocą którego możemy zdefiniować nazwy klas do wyodrębnienia (w tym wszystkie pod-reguły). Robimy to osobno dla stylów ogólnych, stylów stron produktów i stylów kategorii, które są dodawane do odpowiednich typów stron.
Coś, czego nauczyliśmy się z tego i co spowodowało pewne błędy pomiędzy nimi, to to, że musimy uważać, aby kolejność CSS nie została przez to zmieniona. Pomiędzy różnymi osobami piszącymi kod, ktoś dodając nadpisanie później w pliku i automatyczne narzędzie wyodrębniające rzeczy, może to być bałagan.
Wyraźne wymiary przeciwko CLS
Dla mnie CLS to coś, co Google wyciągnął z kapelusza i teraz wszyscy musimy sobie z tym poradzić i otoczyć go naszymi zbiorowymi głowami. Podczas gdy wcześniej mogliśmy po prostu pozwolić kontenerom uzyskać swój rozmiar z elementów w nich zawartych, teraz ładowanie tych elementów może zepsuć rozmiar pudełka. Mając to na uwadze, użyliśmy zakładki „Wydajność” w Narzędziach dla programistów i bardzo przydatnego Generatora GIF-ów z przesunięciem układu, aby zobaczyć, które elementy powodują CLS. Stamtąd przyjrzeliśmy się nie tylko samym elementom, ale także ich rodzicom i przeanalizowaliśmy właściwości CSS, które miałyby wpływ na układ. Czasami mieliśmy szczęście — na przykład logo wymagało tylko wyraźnego ustawienia rozmiaru na urządzeniu mobilnym, aby zapobiec zmianie układu — ale innym razem walka była prawdziwa.
Wskazówka dla profesjonalistów: Czasami przesunięcie jest spowodowane nie przez element pozorny, ale przez element go poprzedzający. Aby zidentyfikować potencjalnych winowajców, skup się na właściwościach, które zmieniają rozmiar i odstępy. Podstawowe pytanie, które należy sobie zadać, brzmi: co może spowodować, że ten blok się poruszy?
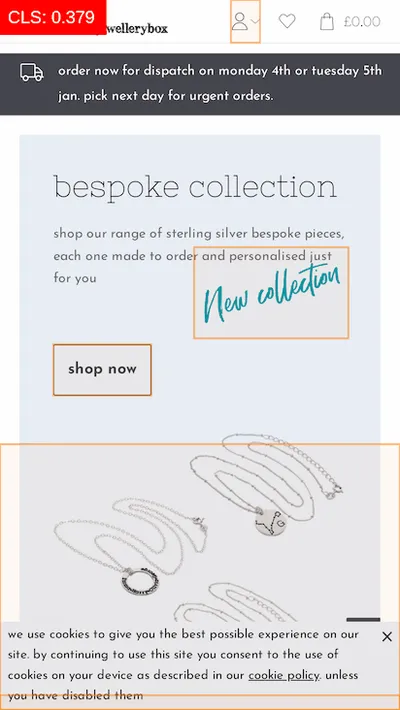
Ponieważ na stronie znajduje się tak wiele obrazów, aby zachowywały się poprawnie w CLS, również przysporzyło nam trochę pracy. Słusznie przypomina nam o tym Barry Pollard w swoim artykule „Ustawianie wysokości i szerokości obrazów jest znowu ważne”. Spędziliśmy dużo czasu na ustalaniu prawidłowych wartości szerokości i wysokości (plus proporcje) dla naszych obrazów w każdym przypadku, aby ponownie dodać je do kodu HTML. W rezultacie nie ma już zmiany układu obrazów, ponieważ przeglądarka pobiera informacje wcześnie.
Sprawa tajemniczego wyniku CLS
Po usunięciu wielu poważnych problemów z CLS w górnej części strony natrafiliśmy na przeszkodę. Czasami (nie zawsze), gdy patrzymy na Page Speed lub Lighthouse, otrzymujemy wynik CLS powyżej 0,3, ale nigdy w zakładce „Wydajność”. Generator GIFów z przesunięciem układu czasami to pokazywał, ale wyglądało na to, że cały kontener strony się porusza .
Po włączeniu dławienia sieci i procesora w końcu zobaczyliśmy to na zrzutach ekranu! Nagłówek na urządzeniu mobilnym rósł o 2 piksele ze względu na zawarte w nim elementy. Ponieważ nagłówek i tak ma stałą wysokość na urządzeniu mobilnym, zdecydowaliśmy się na prostą poprawkę i dodaliśmy do niego wyraźną wysokość — sprawa zamknięta. Kosztowało nas to jednak sporo nerwów i pokazuje, że oprzyrządowanie tutaj jest nadal bardzo nieprecyzyjne.
To nie działa — zróbmy to ponownie!
Jak wszyscy wiemy, wyniki dla urządzeń mobilnych są znacznie gorsze w przypadku Page Speed niż w przypadku komputerów stacjonarnych, a jednym z obszarów, w którym były one dla nas szczególnie złe, były strony produktów. Wynik CLS przeszedł przez dach, a strona miała również problemy z wydajnością (zrobi to kilka karuzeli, kart i elementów niebuforowanych). Co gorsza, układ strony powodował, że niektóre informacje były przetasowywane lub dodawane dwukrotnie.
Na komputerze mamy zasadniczo dwie kolumny na treść:
- Kolumna A : karuzela ze zdjęciami produktu, po której czasami pojawiają się cytaty z bloga, a następnie układ z zakładkami z informacjami o produkcie.
- Kolumna B : nazwa produktu, cena, opis i przycisk „dodaj do koszyka”.
- Wiersz C : karuzela produktów podobnych produktów.
Jednak na telefonie komórkowym najpierw musiała pojawić się karuzela zdjęć produktu, potem kolumna B, a następnie układ kart z kolumny A. W związku z tym pewne informacje zostały zduplikowane w kodzie HTML, kontrolowane przez display: none , a zamówienie było przełączane za pomocą właściwości flex: order . To zdecydowanie działa, ale nie jest dobre dla wyników CLS, ponieważ w zasadzie wszystko musi zostać zmienione.
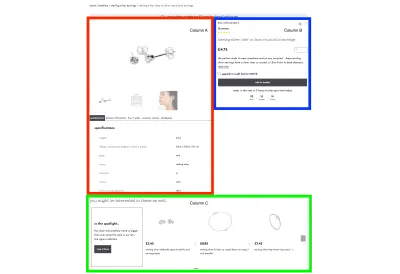
Zdecydowałem się na prosty eksperyment w CodePen: czy mógłbym osiągnąć ten sam podstawowy układ pudełek na komputerach stacjonarnych i mobilnych, przemyślając HTML i używając display: grid zamiast flexbox, i czy to pozwoliłoby mi po prostu zmienić układ obszarów siatki zgodnie z potrzebami? Krótko mówiąc, zadziałało i rozwiązało CLS, a ponadto ma tę dodatkową zaletę, że nazwa produktu pojawia się teraz w HTML znacznie szybciej niż wcześniej — dodatkowa wygrana w SEO!
Zobacz pióro [Studium przypadku pudełka z biżuterią (przykład nr 2)](https://codepen.io/smashingmag/pen/OJpzyLg) autorstwa Pfenya.
Hakowanie karuzeli dla CLS
Słowo „karuzela” pojawiło się już kilka razy – i nie bez powodu. Nie tylko zmieniliśmy używaną przez nas bibliotekę karuzeli (i zmieniliśmy sposób ładowania znajdujących się w niej obrazów), ale także musieliśmy sobie z tym poradzić w przypadku CLS, ponieważ mamy kilka stron, na których karuzela znajduje się nad krawędzią strony, a zatem może mieć duży wpływ na wyniki szybkości.
Zaczęliśmy od wczytania karuzeli później, aby skrócić czas potrzebny do interakcji , ale spowodowało to widoczne opóźnienie do momentu uruchomienia JavaScriptu i przesunięcia slajdów z jednego miejsca na drugi do jednego rzędu. Wypróbowaliśmy wiele sposobów napisania CSS, aby temu zapobiec i zachować wszystko w jednym wierszu, w tym ukrywać całą karuzelę do czasu zakończenia ładowania. Nic nie dało nam takiego rozwiązania, jakie chcielibyśmy zobaczyć odwiedzając sklep jako użytkownik.
Przepraszamy za tę krótką wypowiedź, ale naprawdę karuzele produktów i kategorii to idealna burza elastycznych elementów w responsywnym sklepie: obrazy mogą nie mieć uniwersalnej wysokości, nazwy produktów mogą obejmować wiele wierszy, a etykiety mogą być lub nie. Zasadniczo sprowadza się to do tego: nie jest możliwa stała wysokość rzędu, a także nie znasz szerokości. Dobre czasy.
Ostatecznie zdecydowaliśmy się ustawić wszystkie slajdy (oprócz pierwszego) na visibility: hidden do momentu zakończenia ładowania karuzeli, po czym dodajemy do karuzeli klasę, aby wszystkie slajdy były ponownie widoczne . To rozwiązuje problem zajmowania początkowo dodatkowej wysokości.
Dodatkowo wstępnie ustawiamy flex-shrink: 0 i flex-base: 340px dla slajdów w niepakowanym flexboksie. Powoduje to, że znajdują się one w jednym wierszu i daje przybliżoną początkową szerokość slajdów. Po rozwiązaniu tej zagadki — i tak, to był tak wielki ból głowy, jak się wydaje — dodaliśmy kilka poprawek, aby zachować miejsce na wpadanie kropek i strzał. Dzięki temu nie ma już CLS dla karuzeli!
Zobacz pióro [Studium przypadku pudełka z biżuterią (przykład nr 3)](https://codepen.io/smashingmag/pen/vYxpNEK) autorstwa Pfenyi.
Z perspektywy czasu to 20 ⁄ 20
W końcu było wiele drobnych zmian w ciągu kilku miesięcy, które poprawiły nasze wyniki i nie skończyliśmy. Pracowaliśmy głównie z dwiema osobami nad ulepszeniami front-endu, podczas gdy reszta zespołu skupiła się na ulepszaniu back-endu. Choć prawdopodobnie w ten sposób był nieco wolniejszy, zapewniło to, że nie doszło do nakładania się , a różnice w wynikach można było wyraźnie przypisać. Niektóre zasoby, które bardzo pomogły, to świetne artykuły w Smashing Magazine na temat własnych ulepszeń magazynu.
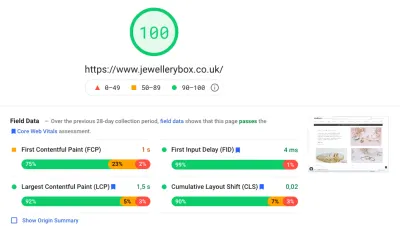
W pewnym momencie rzeczy, których powinieneś spróbować, stają się nieoczywiste, ponieważ uważasz, że nie powinny mieć wielkiego znaczenia, ale po pewnym czasie zdajesz sobie sprawę, że tak. Co więcej, ten projekt ponownie nauczył nas, jak ważne jest, aby od samego początku mieć na uwadze wydajność i metryki , od wymyślenia projektu i zakodowania prototypu po implementację w szablonach. Małe rzeczy, które zaniedbano na początku, mogą składać się na ogromne góry, na które trzeba się później wspiąć, aby je cofnąć.
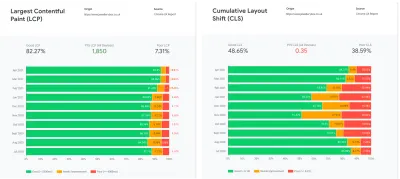
Oto niektóre z kluczowych aspektów , których się nauczyliśmy:
- Optymalizacja JavaScript nie jest tak skuteczna, jak ładowanie go na żądanie;
- Optymalizacja CSS wydaje się zdobywać więcej punktów niż optymalizacja JavaScript;
- Napisz klasy CSS z myślą o CLS i wyodrębnieniu krytycznego CSS;
- Narzędzia do wyszukiwania problemów z CLS nie są jeszcze doskonałe. Myśl nieszablonowo i sprawdź kilka narzędzi;
- Oceń każdą zintegrowaną usługę innej firmy pod kątem rozmiaru pliku i czasu wydajności. Jeśli to możliwe, odepchnij integrację czegokolwiek, co spowolniłoby wszystko;
- Regularnie testuj swoją stronę pod kątem zmian CrUX (a zwłaszcza CLS);
- Regularnie sprawdzaj, czy wszystkie dotychczasowe wpisy pomocy technicznej są nadal potrzebne.
Na naszej liście ulepszeń wciąż mamy rzeczy do wprowadzenia:
- W głównym pliku wciąż znajduje się wiele nieużywanych CSS, które można usunąć;
- Chcielibyśmy całkowicie usunąć jQuery. Będzie to oznaczać przepisanie części naszego kodu, zwłaszcza w obszarze kasy;
- Należy przeprowadzić więcej eksperymentów, jak włączyć zewnętrzne suwaki;
- Nasze wyniki punktów mobilnych mogą być lepsze. Potrzebne będą dalsze prace, zwłaszcza w przypadku urządzeń mobilnych;
- Responsywne obrazy należy dodać do wszystkich zdjęć produktów;
- Sprawdzimy strony z treścią specjalnie pod kątem ulepszeń, których mogą potrzebować, zwłaszcza w zakresie CLS;
- Elementy korzystające z wtyczki zwijania Bootstrap zostaną zastąpione natywnym tagiem
detailsHTML; - Należy zmniejszyć rozmiar DOM;
- Będziemy integrować usługę innej firmy, aby uzyskać szybsze i lepsze wyniki wyszukiwania. Będzie to związane z dużą zależnością JavaScript, którą będziemy musieli zintegrować;
- Będziemy pracować nad poprawą ułatwień dostępu, zarówno przyglądając się zautomatyzowanym narzędziom, jak i samodzielnie przeprowadzając testy z czytnikami ekranu i nawigacją za pomocą klawiatury.
Dalsze zasoby
- „Wskazówki i skróty do debugowania DevTools (Chrome, Firefox, Edge)”, Vitaly Friedman, Smashing Magazine
- „Niektóre wpisy na blogu dotyczące wydajności, które ostatnio dodałem do zakładek i przeczytałem”, Chris Coyier, CSS-Tricks
- „Dokładny przewodnik po pomiarach kluczowych wskaźników internetowych”, Barry Pollard, Smashing Magazine
- „Od semantycznego CSS do Tailwind: refaktoryzacja bazy kodu Netlify UI”, Charlie Gerard i Leslie Cohn-Wein, Netlify
- „Narzędzia audytu CSS”, Iris Lješnjanin, Smashing Magazine
- „Rzeczy, które możesz dziś zrobić dzięki CSS”, Andy Bell, Smashing Magazine
- „Jak poprawić wydajność CSS”, Milica Mihajlija, Calibre
- „Nierówność wydajności mobilnej, 2021”, Alex Russell
- „Maksymalna optymalizacja ładowania obrazów w sieci w 2021 r.” Malte Ubl
- „Pokorny
<img>element i kluczowe elementy sieci”, Addy Osmani, Smashing Magazine