
Wydajność front-endu 2021: planowanie i metryki
Opublikowany: 2022-03-10Ten przewodnik został uprzejmie poparty przez naszych przyjaciół z LogRocket, usługi, która łączy monitorowanie wydajności frontendu , odtwarzanie sesji i analizę produktów, aby pomóc Ci budować lepsze doświadczenia klientów. LogRocket śledzi kluczowe wskaźniki, m.in. DOM ukończony, czas do pierwszego bajtu, pierwsze opóźnienie wejścia, użycie procesora klienta i pamięci. Pobierz bezpłatną wersję próbną LogRocket już dziś.

Spis treści
- Przygotowanie: planowanie i metryki
Kultura wydajności, Core Web Vitals, profile wydajności, CrUX, Lighthouse, FID, TTI, CLS, urządzenia. - Wyznaczanie realistycznych celów
Budżety wydajnościowe, cele wydajnościowe, framework RAIL, budżety 170KB/30KB. - Definiowanie środowiska
Wybór frameworka, bazowy koszt wydajności, Webpack, zależności, CDN, architektura front-end, CSR, SSR, CSR + SSR, renderowanie statyczne, renderowanie wstępne, wzorzec PRPL. - Optymalizacje zasobów
Brotli, AVIF, WebP, responsywne obrazy, AV1, adaptacyjne ładowanie mediów, kompresja wideo, czcionki internetowe, czcionki Google. - Optymalizacje kompilacji
Moduły JavaScript, wzorzec modułu/nomodule, drżenie drzewa, dzielenie kodu, przenoszenie zakresu, Webpack, serwowanie różnicowe, web worker, WebAssembly, pakiety JavaScript, React, SPA, częściowe uwodnienie, import na interakcję, strony trzecie, pamięć podręczna. - Optymalizacje dostawy
Lazy loading, obserwator skrzyżowania, odroczone renderowanie i dekodowanie, krytyczne CSS, przesyłanie strumieniowe, wskazówki dotyczące zasobów, zmiany układu, pracownik serwisu. - Sieć, HTTP/2, HTTP/3
Zszywanie OCSP, certyfikaty EV/DV, pakowanie, IPv6, QUIC, HTTP/3. - Testowanie i monitorowanie
Audyt przepływu pracy, przeglądarki proxy, strona 404, monity o zgodę na pliki cookie RODO, diagnostyka wydajności CSS, dostępność. - Szybkie zwycięstwo
- Wszystko na jednej stronie
- Pobierz listę kontrolną (PDF, Apple Pages, MS Word)
- Zapisz się do naszego biuletynu e-mail, aby nie przegapić kolejnych przewodników.
Przygotowanie: planowanie i metryki
Mikrooptymalizacje doskonale nadają się do utrzymywania wydajności na właściwym torze, ale bardzo ważne jest, aby mieć na uwadze jasno określone cele — mierzalne cele, które wpłyną na wszelkie decyzje podejmowane w trakcie procesu. Istnieje kilka różnych modeli, a te omówione poniżej są dość uparte — po prostu upewnij się, że wcześniej ustaliłeś własne priorytety.
- Stwórz kulturę wydajności.
W wielu organizacjach programiści front-end dokładnie wiedzą, jakie są wspólne problemy i jakie strategie należy zastosować, aby je naprawić. Jednak dopóki nie ma ustalonego poparcia dla kultury wydajności, każda decyzja zamieni się w pole bitwy działów, rozbijając organizację na silosy. Potrzebujesz akceptacji interesariuszy biznesowych, a aby je uzyskać, musisz opracować studium przypadku lub dowód koncepcji szybkości — zwłaszcza podstawowe wskaźniki internetowe , które omówimy szczegółowo później — wskaźniki korzyści i kluczowe wskaźniki wydajności ( KPI ), na których im zależy.Na przykład, aby wydajność była bardziej namacalna, można wyeksponować wpływ wydajności na przychody, pokazując korelację między współczynnikiem konwersji i czasem w stosunku do obciążenia aplikacji, a także wydajności renderowania. Lub szybkość indeksowania robota wyszukiwania (PDF, strony 27–50).
Bez silnego powiązania między zespołami deweloperskimi/projektowymi i biznesowymi/marketingowymi wydajność nie utrzyma się na dłuższą metę. Zbadaj typowe skargi napływające do zespołu obsługi klienta i sprzedaży, przeanalizuj dane analityczne pod kątem wysokich współczynników odrzuceń i spadków konwersji. Dowiedz się, jak poprawa wydajności może pomóc w rozwiązaniu niektórych z tych typowych problemów. Dostosuj argumentację w zależności od grupy interesariuszy, z którymi rozmawiasz.
Przeprowadzaj eksperymenty skuteczności i mierz wyniki — zarówno na urządzeniach mobilnych, jak i na komputerach (na przykład za pomocą Google Analytics). Pomoże Ci stworzyć studium przypadku dostosowane do potrzeb firmy z rzeczywistymi danymi. Co więcej, korzystanie z danych ze studiów przypadków i eksperymentów opublikowanych w Statystykach WPO pomoże zwiększyć wrażliwość biznesu na to, dlaczego wydajność ma znaczenie i jaki ma to wpływ na wrażenia użytkownika i wskaźniki biznesowe. Samo stwierdzenie, że wydajność ma znaczenie, nie wystarczy — musisz także ustalić pewne mierzalne i możliwe do śledzenia cele i obserwować je w czasie.
Jak się tam dostać? W swoim przemówieniu na temat budowania wydajności w perspektywie długoterminowej Allison McKnight dzieli się obszernym studium przypadku, w jaki sposób pomogła stworzyć kulturę wydajności w Etsy (slajdy). Niedawno Tammy Everts mówił o nawykach wysoce efektywnych zespołów wydajnościowych zarówno w małych, jak i dużych organizacjach.
Prowadząc takie rozmowy w organizacjach, należy pamiętać, że podobnie jak UX to spektrum doświadczeń, wydajność sieci jest dystrybucją. Jak zauważyła Karolina Szczur, „oczekiwanie, że pojedyncza liczba będzie w stanie zapewnić ocenę, do której można aspirować, jest błędnym założeniem”. Dlatego cele wydajności muszą być szczegółowe, możliwe do śledzenia i namacalne.
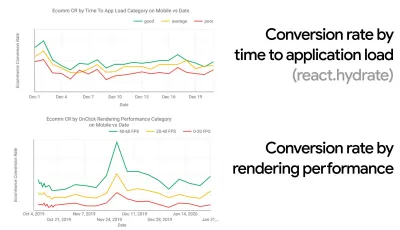
- Cel: Być co najmniej 20% szybszym od swojego najszybszego konkurenta.
Według badań psychologicznych, jeśli chcesz, aby użytkownicy czuli, że Twoja witryna jest szybsza od witryny konkurencji, musisz być co najmniej o 20% szybszy. Przeanalizuj swoich głównych konkurentów, zbierz wskaźniki ich wyników na urządzeniach mobilnych i stacjonarnych oraz ustal progi, które pomogą Ci ich wyprzedzić. Aby jednak uzyskać dokładne wyniki i cele, upewnij się, że najpierw uzyskasz dokładny obraz doświadczeń użytkowników, analizując swoje dane analityczne. Następnie możesz naśladować doświadczenie 90. percentyla podczas testowania.Aby uzyskać dobre pierwsze wrażenie na temat wyników konkurencji, możesz skorzystać z Chrome UX Report ( CrUX , gotowy zestaw danych RUM, wprowadzenie wideo autorstwa Ilyi Grigorika i szczegółowy przewodnik autorstwa Ricka Viscomiego) lub Treo, narzędzie do monitorowania RUM, które jest obsługiwany przez raport Chrome UX. Dane są zbierane od użytkowników przeglądarki Chrome, więc raporty będą dotyczyć tylko przeglądarki Chrome, ale zapewnią dość dokładny rozkład wydajności, a przede wszystkim wyniki Core Web Vitals, wśród szerokiego grona użytkowników. Zauważ, że nowe zestawy danych CrUX są publikowane w drugi wtorek każdego miesiąca .
Alternatywnie możesz również użyć:
- Narzędzie do porównywania raportów Chrome UX firmy Addy Osmani,
- Speed Scorecard (zapewnia również szacowanie wpływu na przychody),
- Porównanie testów rzeczywistych doświadczeń użytkownika lub
- SiteSpeed CI (na podstawie testów syntetycznych).
Uwaga : jeśli korzystasz z interfejsu Page Speed Insights lub Page Speed Insights API (nie, to nie jest przestarzałe!), możesz uzyskać dane o wydajności CrUX dla określonych stron zamiast tylko danych zbiorczych. Te dane mogą być znacznie bardziej przydatne do ustawiania celów skuteczności dla zasobów, takich jak „strona docelowa” lub „lista produktów”. A jeśli używasz CI do testowania budżetów, musisz upewnić się, że twoje testowane środowisko pasuje do CrUX, jeśli użyłeś CrUX do ustawienia celu ( dzięki Patrickowi Meenan! ).
Jeśli potrzebujesz pomocy, aby pokazać rozumowanie stojące za ustalaniem priorytetów szybkości, lub chcesz wizualizować spadek współczynnika konwersji lub wzrost współczynnika odrzuceń przy niższej wydajności, lub być może potrzebujesz orędowania za rozwiązaniem RUM w swojej organizacji, Sergey Chernyshev zbudował Kalkulator prędkości UX, narzędzie typu open source, które pomaga symulować dane i wizualizować je w celu osiągnięcia celu.
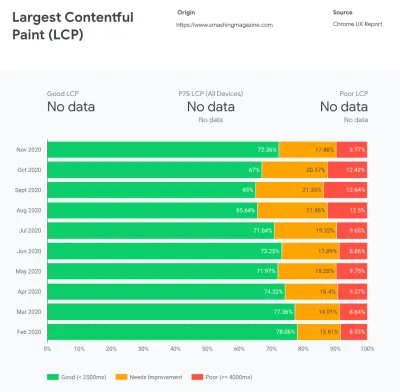
CrUX generuje przegląd rozkładów wydajności w czasie, z ruchem zbieranym od użytkowników Google Chrome. Możesz tworzyć własne w panelu Chrome UX Dashboard. (duży podgląd) 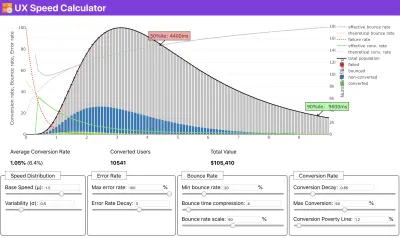
Właśnie wtedy, gdy potrzebujesz argumentów za wydajnością, aby osiągnąć cel: Kalkulator prędkości UX wizualizuje wpływ wydajności na współczynniki odrzuceń, konwersję i całkowity przychód — na podstawie rzeczywistych danych. (duży podgląd) Czasami możesz chcieć wejść nieco głębiej, łącząc dane pochodzące z CrUX z dowolnymi innymi danymi, które już musisz szybko ustalić, gdzie leżą spowolnienia, martwe punkty i nieefektywność — dla konkurencji lub dla twojego projektu. W swojej pracy Harry Roberts korzystał z arkusza kalkulacyjnego topografii Site-Speed, którego używa do rozbicia wydajności według kluczowych typów stron i śledzenia różnych kluczowych wskaźników na nich. Możesz pobrać arkusz kalkulacyjny jako Arkusze Google, Excel, dokument OpenOffice lub CSV.
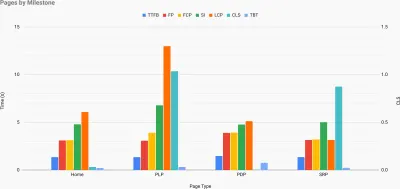
Topografia szybkości witryny z kluczowymi wskaźnikami przedstawianymi dla kluczowych stron w witrynie. (duży podgląd) A jeśli chcesz przejść na całość , możesz przeprowadzić audyt wydajności Lighthouse na każdej stronie witryny (za pośrednictwem Lightouse Parade), z wynikiem zapisanym jako CSV. Pomoże Ci to określić, które konkretnie strony (lub typy stron) konkurencji osiągają gorsze lub lepsze wyniki i na czym możesz chcieć skoncentrować swoje wysiłki. (W przypadku własnej witryny prawdopodobnie lepiej wysłać dane do punktu końcowego analizy!).

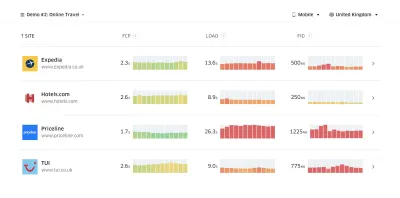
Dzięki Lighthouse Parade możesz przeprowadzić audyt wydajności Lighthouse na każdej stronie witryny, z wynikiem zapisanym jako CSV. (duży podgląd) Zbieraj dane, skonfiguruj arkusz kalkulacyjny, zmniejsz o 20% i skonfiguruj swoje cele ( budżety wydajnościowe ) w ten sposób. Teraz masz coś mierzalnego do sprawdzenia. Jeśli pamiętasz o budżecie i próbujesz wysłać tylko minimalną ładowność, aby uzyskać szybki czas na interakcję, jesteś na rozsądnej ścieżce.
Potrzebujesz zasobów, aby rozpocząć?
- Addy Osmani napisał bardzo szczegółowy opis, jak rozpocząć budżetowanie wydajnościowe, jak określić ilościowo wpływ nowych funkcji i od czego zacząć, gdy przekroczysz budżet.
- Przewodnik Lary Hogan na temat podejścia do projektów z budżetem wydajności może dostarczyć przydatnych wskazówek projektantom.
- Harry Roberts opublikował przewodnik dotyczący konfigurowania arkusza Google do wyświetlania wpływu skryptów innych firm na wydajność za pomocą mapy żądań,
- Kalkulator budżetu wydajności Jonathana Fieldinga, kalkulator budżetu perf-budget Katie Hempenius i kalorie przeglądarki mogą pomóc w tworzeniu budżetów (podziękowania dla Karoliny Szczur za ostrzeżenie).
- W wielu firmach budżety zadaniowe nie powinny być aspiracyjne, ale raczej pragmatyczne, służąc jako znak wstrzymania, aby uniknąć przekroczenia pewnego punktu. W takim przypadku możesz wybrać najgorszy punkt danych w ciągu ostatnich dwóch tygodni jako próg i przyjąć go stamtąd. Budżety wydajnościowe, pragmatycznie pokazuje strategię, aby to osiągnąć.
- Ponadto uwidocznij zarówno budżet wydajności, jak i bieżącą wydajność, konfigurując pulpity nawigacyjne z wykresami raportującymi rozmiary kompilacji. Istnieje wiele narzędzi, które pozwalają to osiągnąć: pulpit nawigacyjny SiteSpeed.io (open source), SpeedCurve i Calibre to tylko kilka z nich, a więcej narzędzi można znaleźć na perf.rocks.

Kalorie przeglądarki pomagają ustawić budżet wydajności i zmierzyć, czy strona przekracza te liczby, czy nie. (duży podgląd) Po ustaleniu budżetu, uwzględnij je w procesie kompilacji za pomocą Webpack Performance Hints and Bundlesize, Lighthouse CI, PWMetrics lub Sitespeed CI, aby wymusić budżety na żądaniach ściągnięcia i zapewnić historię wyników w komentarzach PR.
Aby udostępnić budżety wydajności całemu zespołowi, zintegruj budżety wydajności w Lighthouse za pośrednictwem Lightwallet lub użyj LHCI Action do szybkiej integracji z Github Actions. A jeśli potrzebujesz czegoś niestandardowego, możesz użyć webpagetest-charts-api, API punktów końcowych do tworzenia wykresów z wyników WebPagetest.
Świadomość wydajności nie powinna jednak pochodzić wyłącznie z budżetów wydajności. Podobnie jak Pinterest, możesz utworzyć niestandardową regułę eslint , która uniemożliwia importowanie z plików i katalogów, o których wiadomo, że zawierają duże zależności i które spowodowałyby rozdęcie pakietu. Skonfiguruj listę „bezpiecznych” pakietów, które można udostępniać całemu zespołowi.
Pomyśl także o krytycznych zadaniach klienta, które są najbardziej korzystne dla Twojej firmy. Przestudiuj, omów i zdefiniuj dopuszczalne progi czasowe dla krytycznych działań i ustal „przygotowane na UX” znaczniki czasu użytkownika, które zatwierdziła cała organizacja. W wielu przypadkach podróże użytkowników będą dotyczyć pracy wielu różnych działów, więc dostosowanie pod względem akceptowalnego harmonogramu pomoże wesprzeć lub zapobiec dyskusjom na temat wydajności w przyszłości. Upewnij się, że dodatkowe koszty dodanych zasobów i funkcji są widoczne i zrozumiałe.
Połącz wysiłki w zakresie wydajności z innymi inicjatywami technologicznymi, od nowych funkcji tworzonego produktu, przez refaktoryzację, po docieranie do nowych odbiorców na całym świecie. Tak więc za każdym razem, gdy odbywa się rozmowa o dalszym rozwoju, częścią tej rozmowy jest również wydajność. Znacznie łatwiej jest osiągnąć cele wydajnościowe, gdy baza kodu jest świeża lub właśnie jest refaktorowana.
Ponadto, jak zasugerował Patrick Meenan, warto zaplanować sekwencję ładowania i kompromisy podczas procesu projektowania. Jeśli wcześnie określisz priorytety, które części są bardziej krytyczne i określisz kolejność, w jakiej powinny się pojawiać, będziesz również wiedział, co można opóźnić. Najlepiej byłoby, gdyby ta kolejność odzwierciedlała również kolejność importów CSS i JavaScript, więc obsługa ich podczas procesu budowania będzie łatwiejsza. Zastanów się również, jakie wrażenia wizualne powinny znajdować się w stanach „pomiędzy” podczas ładowania strony (np. gdy czcionki internetowe nie zostały jeszcze załadowane).
Gdy już ustanowisz silną kulturę wydajności w swojej organizacji, postaraj się być o 20% szybszy niż poprzednie ja , aby zachować priorytety w miarę upływu czasu ( dzięki, Guy Podjarny! ). Ale weź pod uwagę różne typy i zachowania użytkowników (które Tobias Baldauf nazwał kadencją i kohortami), a także ruch botów i efekty sezonowości.
Planowanie, planowanie, planowanie. Może być kuszące, aby wcześnie przejść do kilku szybkich optymalizacji „nisko wiszących” — i może to być dobra strategia na szybkie zwycięstwa — ale bardzo trudno będzie utrzymać wydajność jako priorytet bez planowania i ustawiania realistycznego, firma -dopasowane cele wydajnościowe.
- Wybierz odpowiednie dane.
Nie wszystkie metryki są równie ważne. Sprawdź, jakie metryki mają największe znaczenie dla Twojej aplikacji: zazwyczaj będą one definiowane na podstawie tego, jak szybko możesz zacząć renderować najważniejsze piksele interfejsu i jak szybko możesz zapewnić czas reakcji wejściowej dla tych renderowanych pikseli. Ta wiedza zapewni Ci najlepszy cel optymalizacji bieżących wysiłków. Ostatecznie to nie zdarzenia ładowania lub czasy odpowiedzi serwera definiują wrażenia, ale postrzeganie tego, jak zgrabny jest interfejs .Co to znaczy? Zamiast skupiać się na czasie pełnego wczytywania strony (na przykład przez czasy onLoad i DOMContentLoaded ), nadaj priorytet ładowaniu strony, tak jak postrzegają to Twoi klienci. Oznacza to skupienie się na nieco innym zestawie wskaźników. W rzeczywistości wybór odpowiedniego wskaźnika to proces bez oczywistych zwycięzców.
Bazując na badaniach Tima Kadleca i notatkach Marcosa Iglesiasa w jego przemówieniu, tradycyjne metryki można pogrupować w kilka zestawów. Zwykle potrzebujemy ich wszystkich, aby uzyskać pełny obraz wydajności, a w konkretnym przypadku niektóre z nich będą ważniejsze od innych.
- Mierniki oparte na ilości mierzą liczbę żądań, wagę i wynik wydajności. Dobry do zgłaszania alarmów i monitorowania zmian w czasie, nie tak dobry do zrozumienia doświadczenia użytkownika.
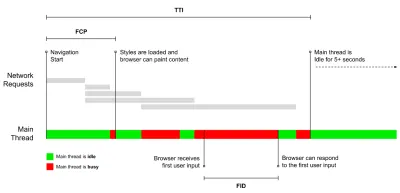
- Metryki kamieni milowych wykorzystują stany w czasie życia procesu ładowania, np. Time To First Byte i Time To Interactive . Dobry do opisywania wrażenia użytkownika i monitorowania, nie tak dobry, aby wiedzieć, co dzieje się między kamieniami milowymi.
- Metryki renderowania zapewniają oszacowanie szybkości renderowania treści (np. czas rozpoczęcia renderowania , indeks szybkości ). Dobry do mierzenia i poprawiania wydajności renderowania, ale nie tak dobry do mierzenia, kiedy pojawia się ważna treść i można z nią wchodzić w interakcję.
- Niestandardowe metryki mierzą konkretne, niestandardowe zdarzenie dla użytkownika, np. Czas do pierwszego tweeta na Twitterze i PinnerWaitTime na Pintereście. Dobry do dokładnego opisania doświadczenia użytkownika, nie tak dobry do skalowania metryk i porównywania z konkurencją.
Aby uzupełnić obraz, zwykle szukamy przydatnych danych we wszystkich tych grupach. Zazwyczaj najbardziej szczegółowe i odpowiednie są:
- Czas na interakcję (TTI)
Punkt, w którym układ się ustabilizował , widoczne są kluczowe czcionki internetowe, a główny wątek jest wystarczająco dostępny, aby obsłużyć dane wejściowe użytkownika — w zasadzie oznacza to czas, kiedy użytkownik może wchodzić w interakcję z interfejsem użytkownika. Kluczowe wskaźniki pozwalające zrozumieć, ile czasu musi czekać użytkownik, aby korzystać z witryny bez opóźnień. Boris Schapira napisał szczegółowy post o tym, jak wiarygodnie mierzyć TTI. - Opóźnienie pierwszego wejścia (FID) lub reakcja na wejście
Czas od pierwszej interakcji użytkownika z Twoją witryną do momentu, w którym przeglądarka rzeczywiście jest w stanie zareagować na tę interakcję. Bardzo dobrze uzupełnia TTI, ponieważ opisuje brakującą część obrazu: co się dzieje, gdy użytkownik faktycznie wchodzi w interakcję z witryną. Przeznaczone wyłącznie jako metryka RUM. W przeglądarce dostępna jest biblioteka JavaScript do pomiaru FID. - Największa zawartość farby (LCP)
Oznacza punkt na osi czasu ładowania strony, w którym prawdopodobnie została załadowana ważna treść strony. Założenie jest takie, że najważniejszym elementem strony jest największy widoczny w widoku użytkownika. Jeśli elementy są renderowane zarówno nad, jak i pod zakładką, tylko widoczna część jest uważana za istotną. - Całkowity czas blokowania ( TBT )
Miernik, który pomaga w ilościowym określeniu stopnia, w jakim strona nie jest interaktywna, zanim stanie się niezawodnie interaktywna (oznacza to, że główny wątek był wolny od zadań trwających ponad 50 ms ( długie zadania ) przez co najmniej 5 s). Metryka mierzy łączny czas między pierwszym malowaniem a czasem do interakcji (TTI), w którym wątek główny był blokowany na tyle długo, aby uniemożliwić reagowanie na dane wejściowe. Nic więc dziwnego, że niski TBT jest dobrym wskaźnikiem dobrej wydajności. (dzięki, Artem, Phil) - Zbiorcze przesunięcie układu ( CLS )
Wskaźnik pokazuje, jak często użytkownicy doświadczają nieoczekiwanych zmian układu (zmiany układu ) podczas uzyskiwania dostępu do witryny. Bada niestabilne elementy i ich wpływ na ogólne wrażenia. Im niższy wynik, tym lepiej. - Indeks prędkości
Mierzy, jak szybko zawartość strony jest wizualnie wypełniana; im niższy wynik, tym lepiej. Wynik indeksu prędkości jest obliczany na podstawie szybkości postępu wizualnego , ale jest to tylko wartość obliczona. Jest również wrażliwy na rozmiar widocznego obszaru, więc musisz zdefiniować szereg konfiguracji testowych, które pasują do docelowych odbiorców. Zauważ, że staje się to mniej ważne, a LCP staje się bardziej odpowiednią metryką ( dzięki, Boris, Artem! ). - Czas spędzony na procesorze
Miara, która pokazuje, jak często i jak długo główny wątek jest blokowany, pracując nad malowaniem, renderowaniem, skryptowaniem i ładowaniem. Wysoki czas procesora jest wyraźnym wskaźnikiem złego doświadczenia, tj. kiedy użytkownik odczuwa zauważalne opóźnienie między akcją a reakcją. Za pomocą WebPageTest możesz wybrać opcję „Capture Dev Tools Timeline” na karcie „Chrome”, aby ujawnić podział głównego wątku, gdy działa on na dowolnym urządzeniu za pomocą WebPageTest. - Koszty procesora na poziomie komponentów
Podobnie jak w przypadku czasu spędzonego na CPU , ta metryka, zaproponowana przez Stoyana Stefanova, bada wpływ JavaScript na CPU . Pomysł polega na użyciu liczby instrukcji procesora na komponent, aby zrozumieć jej wpływ na ogólne wrażenia, w odosobnieniu. Może być zaimplementowany przy użyciu Puppeteer i Chrome. - Wskaźnik frustracji
Podczas gdy wiele wskaźników przedstawionych powyżej wyjaśnia, kiedy ma miejsce określone zdarzenie, FrustrationIndex Tima Vereecke'a analizuje luki między wskaźnikami, zamiast patrzeć na nie indywidualnie. Analizuje kluczowe kamienie milowe postrzegane przez użytkownika końcowego, takie jak widoczny tytuł, widoczna pierwsza treść, gotowa wizualnie i strona wygląda na gotową, i oblicza wynik wskazujący poziom frustracji podczas ładowania strony. Im większa różnica, tym większa szansa, że użytkownik będzie sfrustrowany. Potencjalnie dobry KPI dla doświadczenia użytkownika. Tim opublikował szczegółowy post na temat FrustrationIndex i sposobu jego działania. - Wpływ wagi reklamy
Jeśli Twoja witryna jest uzależniona od przychodów generowanych przez reklamy, warto śledzić wagę kodu związanego z reklamą. Skrypt Paddy Ganti konstruuje dwa adresy URL (jeden normalny i jeden blokujący reklamy), monituje o wygenerowanie porównania wideo za pośrednictwem WebPageTest i zgłasza deltę. - Mierniki odchyleń
Jak zauważyli inżynierowie Wikipedii, dane o tym, jak duże są rozbieżności w twoich wynikach, mogą informować o tym, jak niezawodne są twoje instrumenty i jak dużo uwagi powinieneś zwrócić na odchylenia i wartości odstające. Duża wariancja jest wskaźnikiem korekt potrzebnych w konfiguracji. Pomaga również zrozumieć, czy niektóre strony są trudniejsze do wiarygodnego pomiaru, np. z powodu skryptów stron trzecich powodujących znaczne różnice. Dobrym pomysłem może być również śledzenie wersji przeglądarki, aby zrozumieć skoki wydajności po wprowadzeniu nowej wersji przeglądarki. - Dane niestandardowe
Niestandardowe metryki są definiowane na podstawie Twoich potrzeb biznesowych i doświadczenia klienta. Wymaga zidentyfikowania ważnych pikseli, krytycznych skryptów, niezbędnych CSS i odpowiednich zasobów oraz zmierzenia, jak szybko są dostarczane do użytkownika. W tym celu możesz monitorować Hero Rendering Times lub skorzystać z Performance API, oznaczając konkretne sygnatury czasowe dla wydarzeń, które są ważne dla Twojej firmy. Ponadto możesz zbierać niestandardowe metryki za pomocą WebPagetest, wykonując dowolny kod JavaScript na końcu testu.
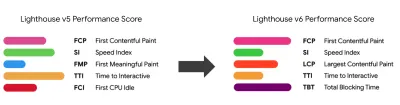
Zauważ, że pierwsza znacząca farba (FMP) nie pojawia się w powyższym przeglądzie. Kiedyś zapewniał wgląd w to, jak szybko serwer wyprowadza dane. Długi FMP zwykle wskazywał, że JavaScript blokuje główny wątek, ale może być również związany z problemami z zapleczem/serwerem. Jednak wskaźnik ten został ostatnio przestarzały, ponieważ wydaje się, że nie jest dokładny w około 20% przypadków. Został skutecznie zastąpiony przez LCP, który jest zarówno bardziej niezawodny, jak i łatwiejszy do zrozumienia. Nie jest już obsługiwany w Lighthouse. Dokładnie sprawdź najnowsze metryki i zalecenia dotyczące wydajności zorientowane na użytkownika, aby upewnić się, że jesteś na bezpiecznej stronie ( dzięki, Patrick Meenan ).

Steve Souders szczegółowo wyjaśnia wiele z tych wskaźników. Należy zauważyć, że podczas gdy czas do interakcji jest mierzony poprzez przeprowadzanie automatycznych audytów w tak zwanym środowisku laboratoryjnym , opóźnienie pierwszego wejścia reprezentuje rzeczywiste wrażenia użytkownika, przy czym faktyczni użytkownicy doświadczają zauważalnego opóźnienia. Ogólnie rzecz biorąc, dobrym pomysłem jest zawsze mierzenie i śledzenie ich obu.
W zależności od kontekstu Twojej aplikacji preferowane metryki mogą się różnić: np. w przypadku interfejsu użytkownika Netflix TV bardziej krytyczne są czas reakcji na wprowadzanie danych, użycie pamięci i TTI, a w przypadku Wikipedii ważniejsze są pierwsze/ostatnie zmiany wizualne oraz metryki czasu pracy procesora.
Uwaga : zarówno FID, jak i TTI nie uwzględniają przewijania; przewijanie może odbywać się niezależnie, ponieważ jest poza głównym wątkiem, więc w przypadku wielu witryn konsumujących treści te dane mogą być znacznie mniej ważne ( dzięki, Patrick! ).
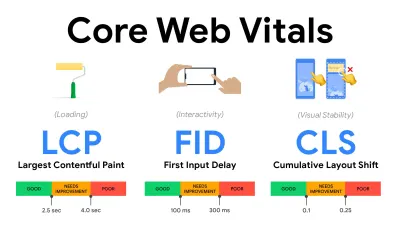
- Mierz i optymalizuj podstawowe wskaźniki internetowe .
Przez długi czas wskaźniki wydajności były dość techniczne i skupiały się na inżynierskim spojrzeniu na to, jak szybko serwery reagują i jak szybko ładują się przeglądarki. Wskaźniki zmieniały się na przestrzeni lat — próbując znaleźć sposób na uchwycenie rzeczywistego doświadczenia użytkownika, a nie czasy serwera. W maju 2020 r. Google ogłosił Core Web Vitals, zestaw nowych metryk wydajności skoncentrowanych na użytkowniku, z których każdy reprezentuje inny aspekt doświadczenia użytkownika.Dla każdego z nich Google zaleca szereg akceptowalnych celów dotyczących szybkości. Aby zaliczyć tę ocenę, co najmniej 75% wszystkich odsłon powinno przekraczać zakres Dobry . Wskaźniki te szybko zyskały popularność, a ponieważ kluczowe wskaźniki sieciowe stały się sygnałami rankingowymi dla wyszukiwarki Google w maju 2021 r. ( aktualizacja algorytmu rankingu Page Experience ), wiele firm zwróciło uwagę na swoje wyniki wydajności.
Przeanalizujmy każdy z kluczowych wskaźników internetowych, jeden po drugim, wraz z przydatnymi technikami i narzędziami do optymalizacji doświadczeń z uwzględnieniem tych wskaźników. (Warto zauważyć, że postępując zgodnie z ogólną radą w tym artykule, uzyskasz lepsze wyniki Core Web Vitals).
- Największa zawartość farby ( LCP ) < 2,5 sek.
Mierzy ładowanie strony i zgłasza czas renderowania największego bloku obrazu lub tekstu widocznego w widocznym obszarze. W związku z tym na LCP wpływa wszystko, co opóźnia renderowanie ważnych informacji — czy to powolne czasy odpowiedzi serwera, blokowanie CSS, JavaScript w locie (własne lub zewnętrzne), ładowanie czcionek internetowych, kosztowne operacje renderowania lub malowania, leniwy - załadowane obrazy, ekrany szkieletowe lub renderowanie po stronie klienta.
Aby zapewnić dobre wrażenia, LCP powinno nastąpić w ciągu 2,5 s od pierwszego rozpoczęcia ładowania strony. Oznacza to, że musimy wyrenderować pierwszą widoczną część strony tak wcześnie, jak to możliwe. Będzie to wymagało dostosowanego krytycznego kodu CSS dla każdego szablonu, uporządkowania kolejności<head>i wstępnego pobierania krytycznych zasobów (omówimy je później).Głównym powodem niskiego wyniku LCP są zwykle obrazy. Aby dostarczyć LCP w <2,5 s na Fast 3G — hostowanym na dobrze zoptymalizowanym serwerze, całkowicie statycznym bez renderowania po stronie klienta i z obrazem pochodzącym z dedykowanej sieci CDN obrazu — oznacza to, że maksymalny teoretyczny rozmiar obrazu wynosi tylko około 144 KB . Dlatego ważne są responsywne obrazy, a także wczesne wczytywanie krytycznych obrazów (za pomocą
preloadładowania ).Szybka wskazówka : aby dowiedzieć się, co jest uważane za LCP na stronie, w DevTools możesz najechać kursorem na znaczek LCP w sekcji „Czasy” w Panelu wydajności ( dzięki, Tim Kadlec !).
- Opóźnienie pierwszego wejścia ( FID ) < 100ms.
Mierzy czas reakcji interfejsu użytkownika, tj. jak długo przeglądarka była zajęta innymi zadaniami, zanim mogła zareagować na dyskretne zdarzenie wejściowe użytkownika, takie jak dotknięcie lub kliknięcie. Został zaprojektowany do przechwytywania opóźnień wynikających z zajętości głównego wątku, zwłaszcza podczas ładowania strony.
Celem jest utrzymanie się w granicach 50-100 ms dla każdej interakcji. Aby się tam dostać, musimy zidentyfikować długie zadania (blokuje główny wątek na >50ms) i je rozbić, podzielić kod na wiele części, skrócić czas wykonania JavaScript, zoptymalizować pobieranie danych, odroczyć wykonywanie skryptów przez strony trzecie , przenieś JavaScript do wątku w tle z pracownikami sieci Web i użyj progresywnego nawadniania, aby zmniejszyć koszty ponownego nawadniania w SPA.Szybka wskazówka : ogólnie rzecz biorąc, niezawodną strategią uzyskania lepszego wyniku FID jest zminimalizowanie pracy nad głównym wątkiem poprzez rozbicie większych pakietów na mniejsze i służenie tym, czego użytkownik potrzebuje, gdy tego potrzebuje, aby interakcje użytkownika nie były opóźnione . Szczegółowo omówimy to poniżej.
- Łączne przesunięcie układu ( CLS ) < 0,1.
Mierzy stabilność wizualną interfejsu użytkownika, aby zapewnić płynne i naturalne interakcje, tj. sumę wszystkich indywidualnych wyników zmian układu dla każdej nieoczekiwanej zmiany układu, która ma miejsce w trakcie życia strony. Indywidualne przesunięcie układu następuje za każdym razem, gdy element, który był już widoczny, zmienia swoje położenie na stronie. Jest oceniany na podstawie rozmiaru treści i odległości, jaką przebył.
Tak więc za każdym razem, gdy pojawia się zmiana — np. gdy czcionki rezerwowe i czcionki internetowe mają różne metryki czcionek lub reklamy, elementy osadzone lub ramki iframe pojawiają się późno, lub wymiary obrazu/wideo nie są zarezerwowane, lub późny CSS wymusza odświeżenie lub wstrzykuje zmiany przez późny JavaScript — ma wpływ na wynik CLS. Zalecaną wartością dobrego doświadczenia jest CLS < 0,1.
Warto zauważyć, że Core Web Vitals ma ewoluować w czasie, z przewidywalnym cyklem rocznym . W przypadku aktualizacji z pierwszego roku możemy spodziewać się awansu First Contentful Paint do Core Web Vitals, obniżonego progu FID i lepszej obsługi aplikacji jednostronicowych. Możemy również zaobserwować, jak reagowanie na dane wprowadzane przez użytkowników po obciążeniu przybiera na wadze, wraz z względami bezpieczeństwa, prywatności i dostępności (!).
W związku z Core Web Vitals istnieje wiele przydatnych zasobów i artykułów, z którymi warto się zapoznać:
- Web Vitals Leaderboard pozwala porównać swoje wyniki z konkurencją na telefonie komórkowym, tablecie, komputerze stacjonarnym oraz w sieciach 3G i 4G.
- Core SERP Vitals, rozszerzenie Chrome, które pokazuje Core Web Vitals z CrUX w wynikach wyszukiwania Google.
- Layout Shift GIF Generator, który wizualizuje CLS za pomocą prostego GIF-a (dostępny również z wiersza poleceń).
- Biblioteka web-vitals może zbierać i wysyłać Core Web Vitals do Google Analytics, Google Tag Manager lub dowolnego innego punktu końcowego analizy.
- Analizowanie wskaźników internetowych za pomocą WebPageTest, w którym Patrick Meenan bada, w jaki sposób WebPageTest ujawnia dane dotyczące podstawowych wskaźników internetowych.
- Optymalizacja za pomocą Core Web Vitals, 50-minutowego filmu z Addy Osmani, w którym podkreśla, jak ulepszyć Core Web Vitals w studium przypadku eCommerce.
- Zbiorcza zmiana układu w praktyce i Zbiorcza zmiana układu w świecie rzeczywistym to obszerne artykuły Nica Jansmy, które obejmują prawie wszystko na temat CLS i jego korelacji z kluczowymi wskaźnikami, takimi jak współczynnik odrzuceń, czas sesji czy wściekłość.
- Co wymusza Reflow, z przeglądem właściwości lub metod, gdy są one żądane/wywoływane w JavaScript, które powodują, że przeglądarka synchronicznie oblicza styl i układ.
- Wyzwalacze CSS pokazują, które właściwości CSS wyzwalają układ, malowanie i kompozyt.
- Naprawianie niestabilności układu to przewodnik dotyczący używania WebPageTest do identyfikowania i naprawiania problemów z niestabilnością układu.
- Kumulatywne przesunięcie układu, metryka niestabilności układu, kolejny bardzo szczegółowy przewodnik Borisa Schapira na temat CLS, jak to obliczać, jak mierzyć i jak optymalizować.
- Jak ulepszyć podstawowe wskaźniki internetowe, szczegółowy przewodnik autorstwa Simona Hearne'a dotyczący każdego z wskaźników (w tym innych wskaźników internetowych, takich jak FCP, TTI, TBT), kiedy występują i jak są mierzone.
Czy więc kluczowe wskaźniki sieciowe są ostatecznymi wskaźnikami, którymi należy się kierować ? Nie do końca. Rzeczywiście są już widoczne w większości rozwiązań i platform RUM, w tym Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (już w widoku taśmy filmowej), Newrelic, Shopify, Next.js, wszystkich narzędziach Google (PageSpeed Insights, Lighthouse + CI, Search Konsola itp.) i wiele innych.
Jednak, jak wyjaśnia Katie Sylor-Miller, niektóre z głównych problemów z Core Web Vitals to brak obsługi wielu przeglądarek, tak naprawdę nie mierzymy pełnego cyklu życia użytkownika, a ponadto trudno jest skorelować zmiany w FID i CLS z wynikami biznesowymi.
Ponieważ powinniśmy się spodziewać, że podstawowe wskaźniki internetowe będą ewoluować, rozsądne wydaje się łączenie wskaźników internetowych z niestandardowymi wskaźnikami, aby lepiej zrozumieć, na czym stoisz pod względem wydajności.
- Największa zawartość farby ( LCP ) < 2,5 sek.
- Zbierz dane na urządzeniu reprezentatywnym dla Twoich odbiorców.
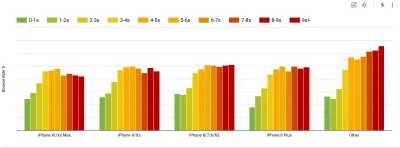
Aby zebrać dokładne dane, musimy dokładnie wybrać urządzenia do testowania. W większości firm oznacza to analizowanie i tworzenie profili użytkowników na podstawie najpopularniejszych typów urządzeń. Jednak często sama analityka nie zapewnia pełnego obrazu. Znaczna część docelowych odbiorców może opuszczać witrynę (i nie wracać) tylko dlatego, że ich doświadczenie jest zbyt wolne, a ich urządzenia prawdopodobnie nie będą z tego powodu wyświetlane jako najpopularniejsze urządzenia w analityce. Dlatego dobrym pomysłem może być dodatkowo przeprowadzenie badań na typowych urządzeniach w Twojej grupie docelowej.Według IDC na całym świecie w 2020 r. 84,8% wszystkich dostarczonych telefonów komórkowych to urządzenia z systemem Android. Przeciętny konsument aktualizuje swój telefon co 2 lata, a w USA cykl wymiany telefonu wynosi 33 miesiące. Przeciętnie najlepiej sprzedające się telefony na całym świecie kosztują mniej niż 200 USD.
Reprezentatywnym urządzeniem jest więc urządzenie z Androidem, które ma co najmniej 24 miesiące , kosztuje 200 USD lub mniej, działa na wolnym 3G, 400 ms RTT i 400 kb/s, żeby być nieco bardziej pesymistycznym. Oczywiście może to być zupełnie inne dla Twojej firmy, ale jest to wystarczająco bliskie przybliżenie większości klientów. W rzeczywistości dobrym pomysłem może być przyjrzenie się aktualnym bestsellerom Amazon na swoim rynku docelowym. ( Podziękowania dla Tima Kadleca, Henri Helvetica i Alexa Russella za wskazówki! ).
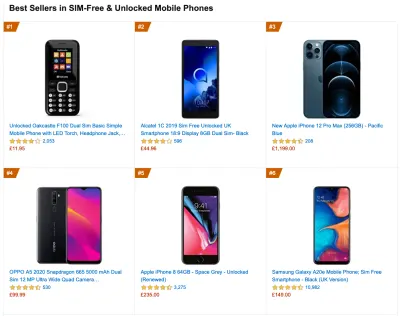
Tworząc nową witrynę lub aplikację, zawsze najpierw sprawdzaj aktualne bestsellery Amazon dla swojego rynku docelowego. (duży podgląd) Jakie zatem urządzenia testowe wybrać? Te, które dobrze pasują do zarysowanego powyżej profilu. Dobrym rozwiązaniem jest wybór nieco starszego Moto G4/G5 Plus, Samsunga ze średniej półki (Galaxy A50, S8), dobrego urządzenia ze średniej półki, jak Nexus 5X, Xiaomi Mi A3 czy Xiaomi Redmi Note 7 i powolne urządzenie, takie jak Alcatel 1X lub Cubot X19, być może w otwartym laboratorium urządzeń. Do testowania na wolniejszych urządzeniach z dławieniem termicznym możesz również kupić Nexusa 4, który kosztuje zaledwie około 100 USD.
Sprawdź też chipsety zastosowane w każdym urządzeniu i nie przesadzaj z jednym chipsetem : kilka generacji Snapdragona i Apple oraz low-end Rockchip, Mediatek wystarczy (dzięki, Patrick!) .
Jeśli nie masz pod ręką urządzenia, emuluj działanie urządzeń mobilnych na komputerze stacjonarnym, testując w zdławionej sieci 3G (np. 300ms RTT, 1,6 Mb/s w dół, 0,8 Mb/s w górę) z dławionym procesorem (5x spowolnienie). W końcu przełącz się na zwykłe 3G, wolne 4G (np. 170ms RTT, 9 Mb/s w dół, 9 Mb/s w górę) i Wi-Fi. Aby wpływ na wydajność był bardziej widoczny, możesz nawet wprowadzić 2G we wtorki lub skonfigurować dławioną sieć 3G/4G w swoim biurze w celu szybszego testowania.
Pamiętaj, że na urządzeniu mobilnym powinniśmy spodziewać się spowolnienia 4×-5× w porównaniu z komputerami stacjonarnymi. Urządzenia mobilne mają różne procesory graficzne, procesory, pamięć i różne charakterystyki baterii. Dlatego ważne jest, aby mieć dobry profil przeciętnego urządzenia i zawsze testować na takim urządzeniu.
- Narzędzia do testów syntetycznych zbierają dane laboratoryjne w odtwarzalnym środowisku z predefiniowanymi ustawieniami urządzenia i sieci (np. Lighthouse , Calibre , WebPageTest ) oraz
- Narzędzia Real User Monitoring ( RUM ) stale oceniają interakcje użytkowników i zbierają dane terenowe (np. SpeedCurve , New Relic — narzędzia zapewniają również testy syntetyczne).
- użyj Lighthouse CI do śledzenia wyników Lighthouse w czasie (to imponujące),
- uruchom Lighthouse w GitHub Actions, aby otrzymać raport Lighthouse wraz z każdym PR,
- przeprowadzić audyt wydajności Lighthouse na każdej stronie witryny (za pośrednictwem Lightouse Parade), z wynikiem zapisanym jako CSV,
- użyj Kalkulatora wyników Lighthouse i wag metrycznych Lighthouse, jeśli chcesz zagłębić się w szczegóły.
- Lighthouse jest również dostępny dla przeglądarki Firefox, ale pod maską wykorzystuje interfejs API PageSpeed Insights i generuje raport na podstawie bezgłowego klienta użytkownika Chrome 79.

Na szczęście istnieje wiele świetnych opcji, które pomagają zautomatyzować zbieranie danych i mierzyć wydajność witryny w czasie zgodnie z tymi wskaźnikami. Należy pamiętać, że dobry obraz wydajności obejmuje zestaw wskaźników wydajności, danych laboratoryjnych i danych terenowych:
Ten pierwszy jest szczególnie przydatny podczas opracowywania , ponieważ pomoże zidentyfikować, wyizolować i naprawić problemy z wydajnością podczas pracy nad produktem. Ta ostatnia jest przydatna do długoterminowej konserwacji , ponieważ pomaga zrozumieć wąskie gardła wydajności, które występują na żywo — kiedy użytkownicy faktycznie uzyskują dostęp do witryny.
Korzystając z wbudowanych interfejsów API RUM, takich jak synchronizacja nawigacji, synchronizacja zasobów, synchronizacja malowania, długie zadania itp., narzędzia do testowania syntetycznego i RUM razem zapewniają pełny obraz wydajności aplikacji. Możesz użyć Calibre, Treo, SpeedCurve, mPulse i Boomerang, Sitespeed.io, które są świetnymi opcjami do monitorowania wydajności. Co więcej, dzięki nagłówkowi Server Timing możesz nawet monitorować wydajność back-endu i front-endu w jednym miejscu.
Uwaga : Bezpieczniej jest zawsze wybrać dławiki na poziomie sieci, zewnętrzne w stosunku do przeglądarki, ponieważ na przykład DevTools ma problemy z interakcją z push HTTP/2 ze względu na sposób jego implementacji ( dzięki, Yoav, Patrick !). Dla Mac OS możemy użyć Network Link Conditioner, dla Windows Traffic Shaper, dla Linuksa netem i dla FreeBSD dummynet.
Ponieważ prawdopodobnie będziesz testować w Lighthouse, pamiętaj, że możesz:
- Skonfiguruj profile „czyste” i „klienta” do testowania.
Podczas przeprowadzania testów w pasywnych narzędziach monitorujących powszechną strategią jest wyłączanie programów antywirusowych i zadań procesora w tle, usuwanie transferów przepustowości w tle i testowanie z czystym profilem użytkownika bez rozszerzeń przeglądarki, aby uniknąć zniekształconych wyników (w Firefoksie i Chrome).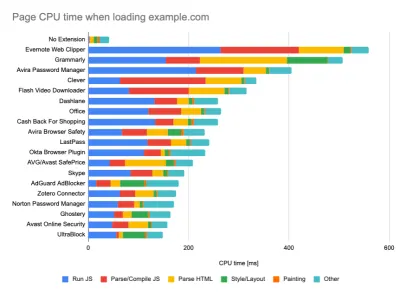
Raport DebugBear podkreśla 20 najwolniejszych rozszerzeń, w tym menedżery haseł, programy do blokowania reklam i popularne aplikacje, takie jak Evernote i Grammarly. (duży podgląd) Jednak dobrym pomysłem jest również zbadanie, z których rozszerzeń przeglądarki często korzystają Twoi klienci, a także przetestowanie na dedykowanych profilach „klientów” . W rzeczywistości niektóre rozszerzenia mogą mieć ogromny wpływ na wydajność (Raport wydajności rozszerzeń Chrome 2020) w Twojej aplikacji, a jeśli Twoi użytkownicy często ich używają, możesz chcieć to rozliczyć z góry. Dlatego same wyniki „czystego” profilu są zbyt optymistyczne i mogą zostać zmiażdżone w rzeczywistych scenariuszach.
- Podziel się celami wydajności z kolegami.
Upewnij się, że cele dotyczące wydajności są znane każdemu członkowi Twojego zespołu, aby uniknąć nieporozumień w przyszłości. Każda decyzja — czy to projektowa, marketingowa, czy cokolwiek pomiędzy — ma wpływ na wydajność , a rozłożenie odpowiedzialności i własności na cały zespół usprawni późniejsze decyzje ukierunkowane na wydajność. Odwzoruj decyzje projektowe w stosunku do budżetu wydajności i priorytetów zdefiniowanych na wczesnym etapie.
Spis treści
- Przygotowanie: planowanie i metryki
- Wyznaczanie realistycznych celów
- Definiowanie środowiska
- Optymalizacje zasobów
- Optymalizacje kompilacji
- Optymalizacje dostawy
- Sieć, HTTP/2, HTTP/3
- Testowanie i monitorowanie
- Szybkie zwycięstwo
- Wszystko na jednej stronie
- Pobierz listę kontrolną (PDF, Apple Pages, MS Word)
- Zapisz się do naszego biuletynu e-mail, aby nie przegapić kolejnych przewodników.