
Front-End Performance 2021: Optymalizacja dostarczania
Opublikowany: 2022-03-10Ten przewodnik został uprzejmie poparty przez naszych przyjaciół z LogRocket, usługi, która łączy monitorowanie wydajności frontendu , odtwarzanie sesji i analizę produktów, aby pomóc Ci budować lepsze doświadczenia klientów. LogRocket śledzi kluczowe wskaźniki, m.in. DOM ukończony, czas do pierwszego bajtu, pierwsze opóźnienie wejścia, użycie procesora klienta i pamięci. Pobierz bezpłatną wersję próbną LogRocket już dziś.

Spis treści
- Przygotowanie: planowanie i metryki
- Wyznaczanie realistycznych celów
- Definiowanie środowiska
- Optymalizacje zasobów
- Optymalizacje kompilacji
- Optymalizacje dostawy
- Sieć, HTTP/2, HTTP/3
- Testowanie i monitorowanie
- Szybkie zwycięstwo
- Wszystko na jednej stronie
- Pobierz listę kontrolną (PDF, Apple Pages, MS Word)
- Zapisz się do naszego biuletynu e-mail, aby nie przegapić kolejnych przewodników.
Optymalizacje dostawy
- Czy używamy
deferdo asynchronicznego ładowania krytycznego kodu JavaScript?
Gdy użytkownik żąda strony, przeglądarka pobiera kod HTML i konstruuje model DOM, następnie pobiera CSS i konstruuje CSSOM, a następnie generuje drzewo renderowania, dopasowując DOM i CSSOM. Jeśli jakiś JavaScript wymaga rozwiązania, przeglądarka nie rozpocznie renderowania strony , dopóki nie zostanie rozwiązany, co opóźni renderowanie. Jako programiści musimy wyraźnie powiedzieć przeglądarce, aby nie czekała i zaczęła renderować stronę. Sposobem na zrobienie tego dla skryptów jest użycie atrybutówdeferiasyncw HTML.W praktyce okazuje się, że lepiej używać
deferzamiastasync. Ach, jaka jest znowu różnica ? Według Steve'a Soudersa, gdy skryptyasyncdotrą, są one wykonywane natychmiast — gdy tylko skrypt jest gotowy. Jeśli dzieje się to bardzo szybko, na przykład, gdy skrypt jest już w pamięci podręcznej, może faktycznie zablokować parser HTML. W przypadkudeferprzeglądarka nie wykonuje skryptów, dopóki kod HTML nie zostanie przeanalizowany. Tak więc, o ile nie potrzebujesz JavaScript do wykonania przed rozpoczęciem renderowania, lepiej użyćdefer. Ponadto wiele plików asynchronicznych będzie wykonywanych w niedeterministycznej kolejności.Warto zauważyć, że istnieje kilka nieporozumień dotyczących
asyncidefer. Co najważniejsze,asyncnie oznacza, że kod będzie uruchamiany, gdy skrypt będzie gotowy; oznacza to, że zostanie uruchomiony, gdy skrypty będą gotowe i wszystkie wcześniejsze prace związane z synchronizacją zostaną wykonane. W słowach Harry'ego Robertsa: „Jeśli umieścisz skryptasyncpo skryptach synchronizacji, twój skryptasyncbędzie tak szybki, jak twój najwolniejszy skrypt synchronizacji”.Ponadto nie zaleca się używania zarówno
async, jak idefer. Nowoczesne przeglądarki obsługują oba, ale zawsze, gdy używane są oba atrybuty,asynczawsze wygrywa.Jeśli chcesz zagłębić się w więcej szczegółów, Milica Mihajlija napisała bardzo szczegółowy przewodnik na temat szybszego budowania DOM, omawiając szczegóły analizowania spekulatywnego, async i odroczenia.
- Lazy ładuje drogie komponenty za pomocą IntersectionObserver i wskazówek dotyczących priorytetów.
Ogólnie zaleca się leniwe ładowanie wszystkich kosztownych komponentów, takich jak ciężki JavaScript, filmy, elementy iframe, widżety i potencjalnie obrazy. Natywne leniwe ładowanie jest już dostępne dla obrazów i ramek iframe z atrybutemloading(tylko Chromium). Pod maską ten atrybut odracza ładowanie zasobu, dopóki nie osiągnie obliczonej odległości od rzutni.<!-- Lazy loading for images, iframes, scripts. Probably for images outside of the viewport. --> <img loading="lazy" ... /> <iframe loading="lazy" ... /> <!-- Prompt an early download of an asset. For critical images, eg hero images. --> <img loading="eager" ... /> <iframe loading="eager" ... />Ten próg zależy od kilku rzeczy, od typu pobieranego zasobu obrazu do efektywnego typu połączenia. Ale eksperymenty przeprowadzone przy użyciu Chrome na Androidzie sugerują, że w 4G 97,5% leniwych ładowanych obrazów poniżej części ekranu zostało w pełni załadowanych w ciągu 10 ms od momentu, gdy stały się widoczne, więc powinno być bezpieczne.
Możemy również użyć atrybutu
importance(highlublow) w elemencie<script>,<img>lub<link>(tylko Blink). W rzeczywistości jest to świetny sposób na zmianę priorytetów obrazów w karuzeli, a także zmianę priorytetów skryptów. Czasami jednak możemy potrzebować nieco bardziej szczegółowej kontroli.<!-- When the browser assigns "High" priority to an image, but we don't actually want that. --> <img src="less-important-image.svg" importance="low" ... /> <!-- We want to initiate an early fetch for a resource, but also deprioritize it. --> <link rel="preload" importance="low" href="/script.js" as="script" />Najbardziej wydajnym sposobem na nieco bardziej wyrafinowane ładowanie z opóźnieniem jest użycie interfejsu API Intersection Observer, który zapewnia sposób asynchronicznego obserwowania zmian w przecięciu elementu docelowego z elementem przodka lub widokiem dokumentu najwyższego poziomu. Zasadniczo musisz utworzyć nowy obiekt
IntersectionObserver, który otrzyma funkcję zwrotną i zestaw opcji. Następnie dodajemy cel do obserwacji.Funkcja wywołania zwrotnego jest wykonywana, gdy cel staje się widoczny lub niewidoczny, więc gdy przechwytuje rzutnię, możesz rozpocząć wykonywanie pewnych działań, zanim element stanie się widoczny. W rzeczywistości mamy szczegółową kontrolę nad tym, kiedy powinno zostać wywołane wywołanie zwrotne obserwatora, z
rootMargin(marginesem wokół korzenia) ithreshold(pojedyncza liczba lub tablica liczb, które wskazują, na jaki procent widoczności celu dążymy).Alejandro Garcia Anglada opublikował przydatny samouczek na temat tego, jak faktycznie go zaimplementować, Rahul Nanwani napisał szczegółowy post na temat leniwego ładowania obrazów pierwszego planu i tła, a Podstawy Google zawierają szczegółowy samouczek na temat leniwego ładowania obrazów i wideo za pomocą Intersection Observer.
Pamiętasz opowiadanie historii kierowane przez sztukę, długie czytanie z ruchomymi i lepkimi obiektami? Możesz również wdrożyć wydajne przewijanie za pomocą obserwatora skrzyżowań.
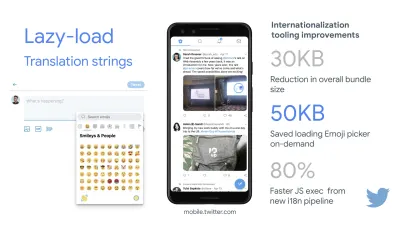
Sprawdź jeszcze raz, co jeszcze możesz leniwy ładować. Pomóc może nawet leniwe ładowanie ciągów tłumaczeniowych i emoji. W ten sposób Mobile Twitter zdołał osiągnąć 80% szybsze wykonanie JavaScript z nowego potoku internacjonalizacji.
Szybkie słowo ostrzeżenia: warto zauważyć, że leniwe ładowanie powinno być wyjątkiem, a nie regułą. Prawdopodobnie nie jest rozsądne leniwe ładowanie czegokolwiek, co faktycznie chcesz, aby ludzie zobaczyli szybko, np. obrazy stron produktów, obrazy bohaterów lub skrypt wymagany do tego, aby główna nawigacja stała się interaktywna.

- Ładuj obrazy progresywnie.
Możesz nawet przenieść leniwe ładowanie na wyższy poziom, dodając progresywne ładowanie obrazu do swoich stron. Podobnie jak w przypadku Facebooka, Pinteresta, Medium i Wolta, możesz najpierw załadować obrazy niskiej jakości lub nawet rozmazane, a następnie w miarę wczytywania strony zastąpić je wersjami w pełnej jakości, korzystając z techniki BlurHash lub LQIP (Low Quality Image Placeholders). technika.Opinie różnią się, czy te techniki poprawiają wrażenia użytkownika, czy nie, ale zdecydowanie skraca to czas do First Contentful Paint. Możemy nawet zautomatyzować to za pomocą SQIP, który tworzy niskiej jakości wersję obrazu jako symbol zastępczy SVG lub Gradient Image Placeholders z liniowymi gradientami CSS.
Te symbole zastępcze mogą być osadzone w HTML, ponieważ naturalnie kompresują się dobrze za pomocą metod kompresji tekstu. W swoim artykule Dean Hume opisał, w jaki sposób można wdrożyć tę technikę za pomocą obserwatora przecięcia.
Awaria? Jeśli przeglądarka nie obsługuje obserwatora skrzyżowania, nadal możemy leniwie załadować wypełnienie lub od razu załadować obrazy. I jest na to nawet biblioteka.
Chcesz być bardziej wytworny? Możesz prześledzić swoje obrazy i użyć prymitywnych kształtów i krawędzi, aby utworzyć lekki symbol zastępczy SVG, załadować go najpierw, a następnie przejść z zastępczego obrazu wektorowego do (załadowanego) obrazu bitmapowego.
- Czy odkładasz renderowanie z
content-visibility?
W przypadku złożonego układu z dużą ilością bloków treści, obrazów i filmów dekodowanie danych i renderowanie pikseli może być dość kosztowną operacją — zwłaszcza na urządzeniach z niższej półki. Dziękicontent-visibility: automożemy skłonić przeglądarkę do pominięcia układu elementów potomnych, gdy kontener znajduje się poza widocznym obszarem.Na przykład możesz pominąć renderowanie stopki i późnych sekcji przy początkowym wczytywaniu:
footer { content-visibility: auto; contain-intrinsic-size: 1000px; /* 1000px is an estimated height for sections that are not rendered yet. */ }Zauważ, że widoczność treści: auto; zachowuje się jak przepełnienie: ukryty; , ale możesz to naprawić, stosując
padding-leftipadding-rightzamiast domyślnegomargin-left: auto;,margin-right: auto;i zadeklarowaną szerokość. Padding w zasadzie pozwala elementom przepełnić zawartość i wejść do padding-box bez opuszczania modelu pudełka jako całości i odcinania się.Pamiętaj też, że możesz wprowadzić trochę CLS, gdy nowa zawartość zostanie w końcu wyrenderowana, więc dobrym pomysłem jest użycie
contain-intrinsic-sizez odpowiednim rozmiarem symbolu zastępczego ( dzięki, Una! ).Thijs Terluin ma o wiele więcej szczegółów na temat obu właściwości i sposobu obliczania
contain-intrinsic-sizeprzez przeglądarkę, Malte Ubl pokazuje, jak można go obliczyć, a krótki film instruktażowy autorstwa Jake'a i Surmy wyjaśnia, jak to wszystko działa.A jeśli potrzebujesz bardziej szczegółowego, z CSS Containment, możesz ręcznie pominąć układ, styl i malowanie dla potomków węzła DOM, jeśli potrzebujesz tylko rozmiaru, wyrównania lub obliczonych stylów na innych elementach — lub element jest aktualnie poza płótnem.


content-visibility: auto do fragmentarycznych obszarów treści zapewnia 7-krotny wzrost wydajności renderowania przy początkowym wczytaniu. (duży podgląd)- Czy odraczasz dekodowanie za pomocą
decoding="async"?
Czasami treść pojawia się poza ekranem, ale chcemy mieć pewność, że jest dostępna, gdy klienci jej potrzebują — najlepiej, aby nie blokować niczego na ścieżce krytycznej, ale dekodować i renderować asynchronicznie. Możemy użyćdecoding="async", aby dać przeglądarce pozwolenie na dekodowanie obrazu poza głównym wątkiem, unikając wpływu użytkownika na czas procesora używany do dekodowania obrazu (poprzez Malte Ubl):<img decoding="async" … />Alternatywnie, w przypadku obrazów poza ekranem, możemy najpierw wyświetlić symbol zastępczy, a gdy obraz znajduje się w oknie widoku, używając IntersectionObserver, wywołać połączenie sieciowe, aby obraz został pobrany w tle. Ponadto możemy odroczyć renderowanie do czasu dekodowania za pomocą img.decode() lub pobrać obraz, jeśli interfejs API Image Decode nie jest dostępny.
Podczas renderowania obrazu możemy wykorzystać na przykład animacje zanikania. Katie Hempenius i Addy Osmani dzielą się więcej spostrzeżeniami w swoim przemówieniu Speed at Scale: Web Performance Tips and Tricks from the Trenches.
- Czy generujesz i obsługujesz krytyczne CSS?
Aby przeglądarki zaczęły renderować Twoją stronę tak szybko, jak to możliwe, powszechną praktyką stało się zbieranie całego kodu CSS wymaganego do rozpoczęcia renderowania pierwszej widocznej części strony (znanej jako „krytyczny CSS” lub „CSS na stronie ") i umieść go w wierszu w<head>strony, zmniejszając w ten sposób podróże w obie strony. Ze względu na ograniczony rozmiar pakietów wymienianych w fazie wolnego startu, Twój budżet na krytyczny CSS wynosi około 14 KB.Jeśli wyjdziesz poza to, przeglądarka będzie potrzebować dodatkowych objazdów, aby pobrać więcej stylów. CriticalCSS i Critical umożliwiają generowanie krytycznego CSS dla każdego używanego szablonu. Z naszego doświadczenia wynika jednak, że żaden automatyczny system nie był lepszy niż ręczne zbieranie krytycznych CSS dla każdego szablonu i rzeczywiście do takiego podejścia powróciliśmy ostatnio.
Następnie możesz wbudować krytyczny CSS i leniwie załadować resztę za pomocą wtyczki critters Webpack. Jeśli to możliwe, rozważ użycie warunkowego podejścia wbudowanego używanego przez Filament Group lub przekonwertuj kod wbudowany na statyczne zasoby w locie.
Jeśli aktualnie ładujesz swój pełny CSS asynchronicznie za pomocą bibliotek takich jak loadCSS, nie jest to naprawdę konieczne. Dzięki
media="print"możesz oszukać przeglądarkę, aby pobierała CSS asynchronicznie, ale stosowała się do środowiska ekranu po załadowaniu. ( dzięki Scott! )<!-- Via Scott Jehl. https://www.filamentgroup.com/lab/load-css-simpler/ --> <!-- Load CSS asynchronously, with low priority --> <link rel="stylesheet" href="full.css" media="print" onload="this.media='all'" />Podczas zbierania wszystkich krytycznych arkuszy CSS dla każdego szablonu często eksploruje się sam obszar „na górze strony”. Jednak w przypadku złożonych układów dobrym pomysłem może być uwzględnienie również podstaw układu, aby uniknąć ogromnych kosztów ponownego przeliczania i ponownego malowania, co w rezultacie pogorszy Twój wynik Core Web Vitals.
Co się stanie, jeśli użytkownik otrzyma adres URL, który prowadzi bezpośrednio do środka strony, ale CSS nie został jeszcze pobrany? W takim przypadku powszechne stało się ukrywanie treści niekrytycznych, np. z
opacity: 0;w wbudowanym CSS iopacity: 1w pełnym pliku CSS i wyświetlaj go, gdy CSS jest dostępny. Ma to jednak poważną wadę , ponieważ użytkownicy korzystający z wolnych połączeń mogą nigdy nie być w stanie odczytać zawartości strony. Dlatego lepiej jest, aby treść była zawsze widoczna, nawet jeśli nie jest ona odpowiednio wystylizowana.Umieszczenie krytycznego CSS (i innych ważnych zasobów) w osobnym pliku w domenie głównej przynosi korzyści, czasami nawet większe niż inline, ze względu na buforowanie. Chrome spekulatywnie otwiera drugie połączenie HTTP z domeną główną podczas żądania strony, co eliminuje potrzebę połączenia TCP w celu pobrania tego kodu CSS. Oznacza to, że możesz utworzyć zestaw krytycznych plików -CSS (np . krytyczna-strona -domowa.css , krytyczna-strona-produktu.css itp.) i udostępniać je ze swojego katalogu głównego, bez konieczności ich inline. ( dzięki Filip! )
Słowo ostrzeżenia: w przypadku HTTP/2 krytyczne CSS mogą być przechowywane w osobnym pliku CSS i dostarczane za pośrednictwem serwera push bez rozdęcia kodu HTML. Haczyk polega na tym, że pushowanie serwerów było kłopotliwe ze względu na wiele problemów i wyścigów w różnych przeglądarkach. Nigdy nie był konsekwentnie wspierany i miał pewne problemy z buforowaniem (patrz slajd 114 i następne prezentacji Hoomana Beheshtiego).
Skutek może w rzeczywistości być negatywny i nadwyrężyć bufory sieciowe, uniemożliwiając dostarczanie prawdziwych ramek w dokumencie. Nie było więc zaskoczeniem, że na razie Chrome planuje usunąć wsparcie dla Server Push.
- Poeksperymentuj z przegrupowaniem reguł CSS.
Przyzwyczailiśmy się do krytycznego CSS, ale jest kilka optymalizacji, które mogą wyjść poza to. Harry Roberts przeprowadził niezwykłe badania z dość zaskakującymi wynikami. Na przykład dobrym pomysłem może być podzielenie głównego pliku CSS na poszczególne zapytania o media. W ten sposób przeglądarka pobierze krytyczny kod CSS o wysokim priorytecie, a wszystko inne o niskim priorytecie — całkowicie poza ścieżką krytyczną.Unikaj również umieszczania
<link rel="stylesheet" />przed fragmentamiasync. Jeśli skrypty nie zależą od arkuszy stylów, rozważ umieszczenie skryptów blokujących nad stylami blokującymi. Jeśli tak, podziel ten JavaScript na dwie części i załaduj go po obu stronach swojego CSS.Scott Jehl rozwiązał inny interesujący problem, buforując wbudowany plik CSS z pracownikiem serwisu, co jest częstym problemem znanym w przypadku krytycznego CSS. Zasadniczo dodajemy atrybut ID do elementu
style, aby można go było łatwo znaleźć za pomocą JavaScript, a następnie mały fragment JavaScript znajduje ten CSS i używa Cache API do przechowywania go w lokalnej pamięci podręcznej przeglądarki (z typem zawartościtext/css) do użycia na kolejnych stronach. Aby uniknąć wstawiania na kolejnych stronach i zamiast tego odwoływać się do zasobów z pamięci podręcznej na zewnątrz, podczas pierwszej wizyty w witrynie ustawiamy plik cookie. Voila!Warto zauważyć, że stylizacja dynamiczna również może być kosztowna, ale zwykle tylko w przypadkach, gdy polegasz na setkach współbieżnie renderowanych skomponowanych komponentów. Jeśli więc używasz CSS-in-JS, upewnij się, że Twoja biblioteka CSS-in-JS optymalizuje wykonanie, gdy Twój CSS nie jest uzależniony od motywu lub rekwizytów i nie nadmiernie komponuj stylizowanych komponentów . Aggelos Arvanitakis udostępnia więcej informacji na temat kosztów wydajności CSS-in-JS.
- Czy przesyłasz odpowiedzi?
Często zapominane i zaniedbywane strumienie zapewniają interfejs do odczytywania lub zapisywania asynchronicznych porcji danych, których tylko podzbiór może być dostępny w pamięci w danym momencie. Zasadniczo umożliwiają stronie, która wysłała pierwotne żądanie, rozpoczęcie pracy z odpowiedzią, gdy tylko dostępna będzie pierwsza porcja danych, i używają parserów zoptymalizowanych pod kątem przesyłania strumieniowego w celu stopniowego wyświetlania zawartości.Moglibyśmy stworzyć jeden strumień z wielu źródeł. Na przykład, zamiast udostępniać pustą powłokę interfejsu użytkownika i pozwalać na jej wypełnienie przez JavaScript, można pozwolić, aby Service Worker utworzył strumień , w którym powłoka pochodzi z pamięci podręcznej, ale treść pochodzi z sieci. Jak zauważył Jeff Posnick, jeśli Twoja aplikacja internetowa jest obsługiwana przez system CMS, który renderuje kod HTML przez serwer, łącząc ze sobą częściowe szablony, model ten przekłada się bezpośrednio na wykorzystanie odpowiedzi strumieniowych, przy czym logika szablonów jest replikowana w procesie roboczym usługi zamiast na serwerze. Artykuł Jake'a Archibalda „The Year of Web Streams” wyjaśnia, jak dokładnie można go zbudować. Wzrost wydajności jest dość zauważalny.
Jedną z ważnych zalet przesyłania strumieniowego całej odpowiedzi HTML jest to, że kod HTML renderowany podczas początkowego żądania nawigacji może w pełni korzystać z parsera strumieniowego HTML przeglądarki. Fragmenty kodu HTML wstawiane do dokumentu po załadowaniu strony (co jest typowe w przypadku treści wypełnianych przez JavaScript) nie mogą skorzystać z tej optymalizacji.
Obsługa przeglądarki? Nadal osiągamy to dzięki częściowemu wsparciu w Chrome, Firefox, Safari i Edge, które obsługuje API i Service Workery obsługiwane we wszystkich nowoczesnych przeglądarkach. A jeśli znów poczujesz się na siłach, możesz sprawdzić eksperymentalną implementację żądań przesyłania strumieniowego, która pozwala rozpocząć wysyłanie żądania przy jednoczesnym generowaniu treści. Dostępny w Chrome 85.
- Rozważ włączenie obsługi połączeń komponentów.
Dane mogą być drogie, a wraz z rosnącym obciążeniem musimy szanować użytkowników, którzy decydują się na oszczędzanie danych podczas uzyskiwania dostępu do naszych witryn lub aplikacji. Nagłówek żądania podpowiedzi klienta Save-Data umożliwia nam dostosowanie aplikacji i ładunku do użytkowników o ograniczonych kosztach i wydajności.W rzeczywistości możesz przepisać żądania obrazów o wysokiej rozdzielczości na obrazy o niskiej rozdzielczości, usunąć czcionki internetowe, fantazyjne efekty paralaksy, podgląd miniatur i nieskończone przewijanie, wyłączyć autoodtwarzanie wideo, push serwera, zmniejszyć liczbę wyświetlanych elementów i obniżyć jakość obrazu lub nawet zmienić sposób dostarczania znaczników. Tim Vereecke opublikował bardzo szczegółowy artykuł na temat strategii data-s(h)aver, który zawiera wiele opcji oszczędzania danych.
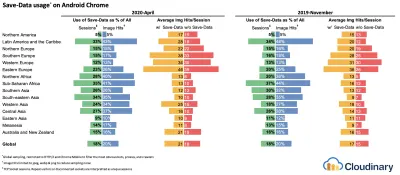
Być może zastanawiasz się, kto używa
save-data? 18% globalnych użytkowników Chrome na Androida ma włączony tryb uproszczony (z włączonymSave-Data), a liczba ta prawdopodobnie będzie wyższa. Według badań Simona Hearne'a wskaźnik opt-in jest najwyższy na tańszych urządzeniach, ale istnieje wiele wartości odstających. Na przykład: użytkownicy w Kanadzie mają wskaźnik zgody na poziomie ponad 34% (w porównaniu do ~7% w USA), a użytkownicy najnowszego flagowego modelu Samsunga mają prawie 18% na całym świecie.Gdy włączony jest tryb
Save-Data, Chrome Mobile zapewnia zoptymalizowane wrażenia, tj. dostęp do sieci proxy z odroczonymi skryptami , wymuszonefont-display: swapi wymuszone leniwe ładowanie. Po prostu rozsądniej jest zbudować środowisko samodzielnie, niż polegać na przeglądarce, aby dokonać tych optymalizacji.Nagłówek jest obecnie obsługiwany tylko w Chromium, w wersji Chrome na Androida lub za pośrednictwem rozszerzenia Data Saver na urządzeniu stacjonarnym. Wreszcie, możesz również użyć interfejsu Network Information API, aby dostarczać kosztowne moduły JavaScript, obrazy i filmy w wysokiej rozdzielczości w oparciu o typ sieci. Network Information API, a konkretnie
navigator.connection.effectiveType. EffectiveType, używają wartościRTT,downlink,effectiveType(i kilku innych), aby zapewnić reprezentację połączenia i dane, które użytkownicy mogą obsłużyć.W tym kontekście Max Bock mówi o komponentach obsługujących połączenia, a Addy Osmani o adaptacyjnej obsłudze modułów. Na przykład w React moglibyśmy napisać komponent, który renderuje się inaczej dla różnych typów połączeń. Jak zasugerował Max, komponent
<Media />w artykule z wiadomościami może generować:-
Offline: symbol zastępczy z tekstemalt, - tryb
2G/save-data: obraz o niskiej rozdzielczości, -
3Gna ekranie innym niż Retina: obraz o średniej rozdzielczości, -
3Gna ekranach Retina: obraz Retina o wysokiej rozdzielczości, -
4G: wideo HD.
Dean Hume zapewnia praktyczną implementację podobnej logiki za pomocą service workera. W przypadku wideo moglibyśmy domyślnie wyświetlić plakat wideo, a następnie wyświetlić ikonę „Odtwórz”, a także powłokę odtwarzacza wideo, metadane wideo itp. Przy lepszych połączeniach. Jako rozwiązanie awaryjne dla nieobsługujących przeglądarek moglibyśmy nasłuchiwać zdarzenia
canplaythroughi użyćPromise.race()do przekroczenia limitu czasu ładowania źródła, jeśli zdarzeniecanplaythroughnie uruchomi się w ciągu 2 sekund.
Jeśli chcesz zanurkować nieco głębiej, oto kilka zasobów na początek:
- Addy Osmani pokazuje, jak zaimplementować serwowanie adaptacyjne w React.
- React Adaptive Loading Hooks & Utilities dostarcza fragmenty kodu dla Reacta,
- Netanel Basel bada komponenty obsługujące połączenia w Angular,
- Theodore Vorilas opowiada, jak działa Serving Adaptive Components za pomocą Network Information API w Vue.
- Umar Hansa pokazuje, jak selektywnie pobierać/wykonywać drogi JavaScript.
-
- Rozważ dostosowanie swoich komponentów do pamięci urządzenia.
Połączenie sieciowe daje nam jednak tylko jedno spojrzenie na kontekst użytkownika. Idąc dalej, możesz również dynamicznie dostosowywać zasoby na podstawie dostępnej pamięci urządzenia za pomocą interfejsu API pamięci urządzenia.navigator.deviceMemoryzwraca ilość pamięci RAM urządzenia w gigabajtach, zaokrągloną w dół do najbliższej potęgi dwójki. Interfejs API zawiera również nagłówek wskazówek klienta,Device-Memory, który zgłasza tę samą wartość.Bonus : Umar Hansa pokazuje, jak odroczyć drogie skrypty z dynamicznym importem, aby zmienić wrażenia w oparciu o pamięć urządzenia, łączność sieciową i współbieżność sprzętu.
- Rozgrzej połączenie, aby przyspieszyć dostarczanie.
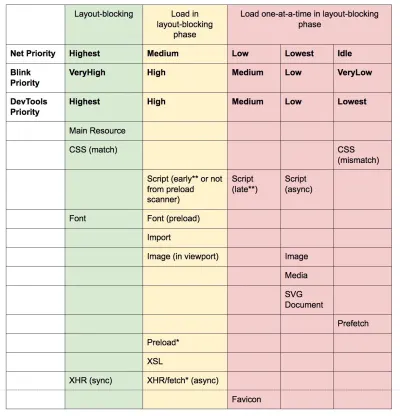
Użyj wskazówek dotyczących zasobów, aby zaoszczędzić czas nadns-prefetch(wykonujący wyszukiwanie DNS w tle),preconnect(który prosi przeglądarkę o uruchomienie uzgadniania połączenia (DNS, TCP, TLS) w tle),prefetch(który prosi przeglądarkę żądać zasobu) ipreloadładowania (które między innymi pobiera zasoby bez ich wykonywania). Dobrze obsługiwane w nowoczesnych przeglądarkach, a wsparcie wkrótce pojawi się w Firefoksie.Pamiętasz
prerender? Wskazówka dotycząca zasobów używana do monitowania przeglądarki o zbudowanie całej strony w tle w celu następnej nawigacji. Problemy z implementacją były dość problematyczne, począwszy od ogromnego zużycia pamięci i przepustowości po wiele zarejestrowanych działań analitycznych i wyświetleń reklam.Nic dziwnego, że został przestarzały, ale zespół Chrome przywrócił go jako mechanizm NoState Prefetch. W rzeczywistości Chrome traktuje podpowiedź przed
prerenderjako prefetch NoState, więc nadal możemy z niej korzystać. Jak wyjaśnia Katie Hempenius w tym artykule, „podobnie jak wstępne renderowanie, NoState Prefetch pobiera zasoby z wyprzedzeniem ; ale w przeciwieństwie do wstępnego renderowania nie wykonuje z wyprzedzeniem JavaScriptu ani nie renderuje żadnej części strony”.NoState Prefetch wykorzystuje tylko ~45MiB pamięci, a podzasoby, które są pobierane, będą pobierane z priorytetem sieci
IDLE. Od wersji Chrome 69 NoState Prefetch dodaje nagłówek Cel: Prefetch do wszystkich żądań, aby odróżnić je od zwykłego przeglądania.Zwróć także uwagę na alternatywy do wstępnego renderowania i portale, nowy wysiłek w kierunku wstępnego renderowania z zachowaniem prywatności, który zapewni wstawkę
previewzawartości umożliwiającą bezproblemową nawigację.Korzystanie ze wskazówek dotyczących zasobów jest prawdopodobnie najłatwiejszym sposobem na zwiększenie wydajności i rzeczywiście działa dobrze. Kiedy używać czego? Jak wyjaśnił Addy Osmani, rozsądne jest wstępne ładowanie zasobów, o których wiemy, że prawdopodobnie będą używane na bieżącej stronie i do przyszłej nawigacji w wielu granicach nawigacji, np. pakiety Webpack potrzebne do stron, których użytkownik jeszcze nie odwiedził.
Artykuł Addy'ego na temat „Loading Priorities in Chrome” pokazuje, jak dokładnie Chrome interpretuje wskazówki dotyczące zasobów, więc gdy już zdecydujesz, które zasoby są krytyczne dla renderowania, możesz przypisać im wysoki priorytet. Aby sprawdzić priorytety swoich żądań, możesz włączyć kolumnę „priorytet” w tabeli żądań sieciowych Chrome DevTools (oraz Safari).
W dzisiejszych czasach przez większość czasu będziemy używać co najmniej
preconnectidns-prefetch, a przy korzystaniu zprefetch,preloadiprerenderbędziemy ostrożni . Zauważ, że nawet zpreconnectidns-prefetch, przeglądarka ma limit liczby hostów, z którymi będzie wyszukiwać/połączać się równolegle, więc bezpiecznie jest zamówić je według priorytetu ( dzięki Philip Tellis! ).Ponieważ czcionki zwykle są ważnymi zasobami na stronie, czasami dobrym pomysłem jest poproszenie przeglądarki o pobranie krytycznych czcionek za pomocą funkcji
preloadładowania . Jednak sprawdź dokładnie, czy rzeczywiście poprawia to wydajność, ponieważ podczas wstępnego ładowania czcionek istnieje zagadka priorytetów: ponieważpreloadładowanie jest postrzegane jako bardzo ważne, może przeskoczyć jeszcze bardziej krytyczne zasoby, takie jak krytyczne CSS. ( dzięki Kasia! )<!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /><!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" />Ponieważ
<link rel="preload">akceptuje atrybutmedia, możesz wybrać selektywne pobieranie zasobów na podstawie reguł zapytań@media, jak pokazano powyżej.Co więcej, możemy użyć
imagesrcsetiimagesizes, aby szybciej wstępnie wczytać późno odkryte obrazy bohaterów lub dowolne obrazy ładowane przez JavaScript, np. plakaty filmowe:<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image><!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image>Możemy również wstępnie załadować plik JSON jako fetch , aby został wykryty, zanim JavaScript otrzyma żądanie:
<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="fetch" href="foo.com/api/movies.json" crossorigin>Moglibyśmy również dynamicznie ładować JavaScript, skutecznie dla leniwego wykonywania skryptu.
/* Adding a preload hint to the head */ var preload = document.createElement("link"); link.href = "myscript.js"; link.rel = "preload"; link.as = "script"; document.head.appendChild(link); /* Injecting a script when we want it to execute */ var script = document.createElement("script"); script.src = "myscript.js"; document.body.appendChild(script);Kilka uwag, o których należy pamiętać:
preloadładowanie jest dobre, gdy czas rozpoczęcia pobierania zasobu jest bliższy początkowemu żądaniu, ale wstępnie załadowane zasoby trafiają do pamięci podręcznej , która jest powiązana ze stroną wysyłającą żądanie.preloaddobrze współpracuje z pamięcią podręczną HTTP: żądanie sieciowe nigdy nie jest wysyłane, jeśli element znajduje się już w pamięci podręcznej HTTP.Dlatego jest przydatny w przypadku ostatnio odkrytych zasobów, obrazów bohaterów ładowanych za pomocą
background-image, wstawiania krytycznego CSS (lub JavaScript) i wstępnego ładowania reszty CSS (lub JavaScript).
Wstępnie wczytuj ważne obrazy; nie musisz czekać na JavaScript, aby je odkryć. (Źródło zdjęcia: „Preload Late-Discovered Hero Images Faster” autorstwa Addy Osmani) (duży podgląd) Znacznik
preloadładowania może zainicjować wstępne ładowanie dopiero po odebraniu przez przeglądarkę kodu HTML z serwera i odnalezieniu znacznikapreloadładowania przez parser lookahead. Wstępne ładowanie za pomocą nagłówka HTTP może być nieco szybsze, ponieważ nie musimy czekać, aż przeglądarka przeanalizuje kod HTML, aby rozpocząć żądanie (choć jest to dyskutowane).Wczesne wskazówki pomogą jeszcze bardziej, umożliwiając wstępne ładowanie, zanim zostaną wysłane nagłówki odpowiedzi dla kodu HTML (na mapie drogowej w Chromium, Firefox). Ponadto wskazówki dotyczące priorytetów pomogą nam wskazać priorytety ładowania skryptów.
Uwaga : jeśli używasz
preload,asmusi być zdefiniowane lub nic się nie ładuje, plus wstępnie załadowane czcionki bez atrybutucrossoriginbędą pobierane podwójnie. Jeśli używaszprefetch, uważaj na problemy z nagłówkiemAgew Firefoksie.
- Użyj pracowników usług do buforowania i sieci awaryjnych.
Żadna optymalizacja wydajności w sieci nie może być szybsza niż lokalnie przechowywana pamięć podręczna na komputerze użytkownika (choć są wyjątki). Jeśli Twoja witryna korzysta z protokołu HTTPS, możemy buforować zasoby statyczne w pamięci podręcznej Service Worker i przechowywać awaryjne rozwiązania offline (lub nawet strony offline) oraz pobierać je z komputera użytkownika, zamiast przechodzić do sieci.Zgodnie z sugestią Phila Waltona, wraz z pracownikami usług, możemy wysyłać mniejsze ładunki HTML, programowo generując nasze odpowiedzi. Service worker może zażądać od serwera tylko niezbędnego minimum danych (np. części treści HTML, pliku Markdown, danych JSON itp.), a następnie może programowo przekształcić te dane w pełny dokument HTML. Tak więc, gdy użytkownik odwiedzi witrynę i zostanie zainstalowany Service Worker, użytkownik nigdy więcej nie zażąda pełnej strony HTML. Wpływ na wydajność może być imponujący.
Obsługa przeglądarki? Pracownicy usług są szeroko obsługiwani, a rezerwą jest i tak sieć. Czy pomaga zwiększyć wydajność ? O tak, tak. I jest coraz lepiej, np. dzięki funkcji pobierania w tle, która umożliwia również przesyłanie/pobieranie w tle za pośrednictwem pracownika serwisu.
Istnieje wiele przypadków użycia pracownika serwisu. Na przykład możesz zaimplementować funkcję „Zapisz do trybu offline”, obsłużyć uszkodzone obrazy, wprowadzić wiadomości między kartami lub zapewnić różne strategie buforowania w oparciu o typy żądań. Ogólnie rzecz biorąc, powszechną niezawodną strategią jest przechowywanie powłoki aplikacji w pamięci podręcznej procesu roboczego wraz z kilkoma krytycznymi stronami, takimi jak strona offline, strona główna i wszystko inne, co może być ważne w Twoim przypadku.
Jest jednak kilka rzeczy, o których należy pamiętać. Mając service worker na miejscu, musimy uważać na żądania zasięgu w Safari (jeśli używasz Workboksa dla service workera, ma on moduł żądania zasięgu). Jeśli kiedykolwiek natknąłeś się na
DOMException: Quota exceeded.błąd w konsoli przeglądarki, a następnie zajrzyj do artykułu Gerardo Kiedy 7KB równa się 7MB.Jak pisze Gerardo: „Jeśli tworzysz progresywną aplikację internetową i doświadczasz nadętej pamięci podręcznej, gdy Twój Service Worker buforuje statyczne zasoby obsługiwane z sieci CDN, upewnij się, że istnieje odpowiedni nagłówek odpowiedzi CORS dla zasobów z różnych źródeł, nie przechowujesz w pamięci podręcznej nieprzezroczystych odpowiedzi z pracownikiem serwisu przypadkowo włączasz zasoby obrazów z różnych źródeł w trybie CORS, dodając atrybut
crossorigindo tagu<img>”.Istnieje wiele wspaniałych zasobów , aby rozpocząć pracę z pracownikami usług:
- Nastawienie Service Worker, które pomaga zrozumieć, jak pracownicy usług pracują za kulisami i co należy zrozumieć podczas ich tworzenia.
- Chris Ferdinandi udostępnia świetną serię artykułów na temat pracowników usług, wyjaśniając, jak tworzyć aplikacje offline i obejmując różne scenariusze, od zapisywania ostatnio przeglądanych stron w trybie offline po ustawianie daty wygaśnięcia elementów w pamięci podręcznej pracowników usług.
- Pułapki Service Worker i najlepsze praktyki, z kilkoma wskazówkami na temat zakresu, opóźniające rejestrację Service Workera i buforowanie Service Worker.
- Świetna seria Ire Aderinokuna na temat „Najpierw offline” z usługą Service Worker, ze strategią wstępnego buforowania powłoki aplikacji.
- Service Worker: wprowadzenie z praktycznymi wskazówkami dotyczącymi korzystania z narzędzia Service Worker w celu uzyskania bogatych środowisk offline, okresowych synchronizacji w tle i powiadomień push.
- Zawsze warto odwołać się do starej dobrej książki kucharskiej Offline Jake'a Archibalda z wieloma przepisami na to, jak upiec własnego pracownika serwisu.
- Workbox to zestaw bibliotek Service Worker stworzonych specjalnie do tworzenia progresywnych aplikacji internetowych.
- Czy używasz pracowników serwerów na CDN/Edge, np. do testów A/B?
W tym momencie jesteśmy przyzwyczajeni do uruchamiania Service Workerów na kliencie, ale dzięki CDN implementującym je na serwerze, moglibyśmy ich użyć również do poprawienia wydajności na brzegu.Na przykład w testach A/B, gdy HTML musi zmieniać swoją zawartość dla różnych użytkowników, do obsługi logiki możemy użyć Service Workerów na serwerach CDN. Moglibyśmy również przesyłać strumieniowo przepisywanie HTML, aby przyspieszyć witryny korzystające z czcionek Google.
- Zoptymalizuj wydajność renderowania.
Ilekroć aplikacja jest powolna, od razu jest to zauważalne. Musimy więc upewnić się, że nie ma opóźnień podczas przewijania strony lub gdy element jest animowany, i że stale osiągasz 60 klatek na sekundę. Jeśli nie jest to możliwe, to przynajmniej zapewnienie spójności klatek na sekundę jest lepsze niż mieszany zakres od 60 do 15. Użyj zmiany w CSSwill-changeaby poinformować przeglądarkę, które elementy i właściwości ulegną zmianie.W każdym przypadku debuguj niepotrzebne przemalowania w DevTools:
- Mierz wydajność renderowania w czasie wykonywania. Sprawdź kilka przydatnych wskazówek, jak nadać temu sens.
- Aby rozpocząć, zapoznaj się z bezpłatnym kursem Udacity Paula Lewisa na temat optymalizacji renderowania w przeglądarce oraz artykułem Georgy'ego Marchuka o malowaniu w przeglądarce i rozważaniach dotyczących wydajności sieci.
- Włącz Flashowanie farby w "Więcej narzędzi → Renderowanie → Flashowanie farby" w Firefox DevTools.
- W React DevTools zaznacz „Podświetl aktualizacje” i włącz „Zapisuj, dlaczego każdy komponent został wyrenderowany”,
- Możesz także użyć opcji Dlaczego renderowałeś, więc gdy komponent jest ponownie renderowany, flash powiadomi Cię o zmianie.
Czy używasz układu murarskiego? Pamiętaj, że już wkrótce może być w stanie zbudować układ Masonry z samą siatką CSS.
Jeśli chcesz zagłębić się w ten temat, Nolan Lawson podzielił się w swoim artykule sztuczkami, aby dokładnie zmierzyć wydajność układu, a Jason Miller również zasugerował alternatywne techniki. Mamy również mały artykuł autorstwa Sergeya Chikuyonoka o tym, jak uzyskać prawidłową animację GPU.

Przeglądarki mogą tanio animować transformację i nieprzezroczystość. Wyzwalacze CSS są przydatne do sprawdzania, czy CSS wyzwala zmiany układu lub ponownego przepływu. (Źródło zdjęcia: Addy Osmani) (duży podgląd) Uwaga : zmiany w warstwach skomponowanych za pomocą GPU są najtańsze, więc jeśli możesz uciec, uruchamiając tylko komponowanie przez
opacityitransform, będziesz na dobrej drodze. Anna Migas przedstawiła również wiele praktycznych porad w swoim przemówieniu na temat debugowania wydajności renderowania interfejsu użytkownika. Aby dowiedzieć się, jak debugować wydajność malowania w DevTools, obejrzyj film dotyczący audytu wydajności malowania firmy Umar. - Czy zoptymalizowałeś pod kątem postrzeganej wydajności?
Chociaż kolejność wyświetlania komponentów na stronie i strategia udostępniania zasobów przeglądarce ma znaczenie, nie powinniśmy również lekceważyć roli postrzeganej wydajności. Koncepcja dotyczy psychologicznych aspektów oczekiwania, w zasadzie utrzymywania zajętych lub zaangażowanych klientów, podczas gdy dzieje się coś innego. Tutaj w grę wchodzą zarządzanie percepcją, wyprzedzający start, wczesne ukończenie i zarządzanie tolerancją.Co to wszystko znaczy? Podczas wczytywania zasobów możemy zawsze starać się być o krok przed klientem, dzięki czemu obsługa jest szybka, gdy w tle dzieje się całkiem sporo. Aby utrzymać zaangażowanie klienta, zamiast wskaźników wczytywania możemy testować szkieletowe ekrany (demo wdrożeniowe), dodawać przejścia/animacje i w zasadzie oszukiwać UX, gdy nie ma już nic do optymalizacji.
W swoim studium przypadku The Art of UI Skeletons, Kumar McMillan dzieli się kilkoma pomysłami i technikami symulacji dynamicznych list, tekstu i ekranu końcowego, a także rozważania myślenia szkieletowego w React.
Uważaj jednak: ekrany szkieletowe powinny zostać przetestowane przed wdrożeniem, ponieważ niektóre testy wykazały, że ekrany szkieletowe mogą działać najgorzej według wszystkich wskaźników.
- Czy zapobiegasz przesunięciom układu i ponownemu malowaniu?
W sferze postrzeganej wydajności prawdopodobnie jednym z bardziej destrukcyjnych doświadczeń jest przesunięcie układu lub zmiany układu stron spowodowane przeskalowanymi obrazami i filmami, czcionkami internetowymi, wstrzykiwanymi reklamami lub niedawno odkrytymi skryptami, które wypełniają komponenty rzeczywistą treścią. W rezultacie klient może zacząć czytać artykuł tylko po to, by przerwać mu skok układu nad obszarem czytania. Doświadczenie jest często nagłe i dość dezorientujące: i prawdopodobnie jest to przypadek ładowania priorytetów, które należy ponownie rozważyć.Społeczność opracowała kilka technik i obejścia, aby uniknąć zmian. Ogólnie rzecz biorąc, dobrym pomysłem jest unikanie wstawiania nowej treści nad istniejącą , chyba że dzieje się to w odpowiedzi na interakcję użytkownika. Zawsze ustawiaj atrybuty szerokości i wysokości na obrazach, aby nowoczesne przeglądarki przydzielały pole i domyślnie rezerwowały miejsce (Firefox, Chrome).
Zarówno w przypadku obrazów, jak i filmów możemy użyć symbolu zastępczego SVG, aby zarezerwować pole wyświetlania, w którym pojawią się multimedia. Oznacza to, że obszar zostanie odpowiednio zarezerwowany, gdy będziesz musiał również zachować jego proporcje. Możemy również używać symboli zastępczych lub obrazów zastępczych dla reklam i treści dynamicznych, a także wstępnie przydzielać boksy układu.
Zamiast leniwego ładowania obrazów za pomocą zewnętrznych skryptów, rozważ użycie natywnego leniwego ładowania lub hybrydowego leniwego ładowania, gdy ładujemy zewnętrzny skrypt tylko wtedy, gdy natywne ładowanie z opóźnieniem nie jest obsługiwane.
Jak wspomniano powyżej, zawsze grupuj odświeżenia czcionek internetowych i przechodź od wszystkich czcionek zastępczych do wszystkich czcionek internetowych naraz — po prostu upewnij się, że ten przełącznik nie jest zbyt gwałtowny, dostosowując wysokość linii i odstępy między czcionkami za pomocą funkcji dopasowania stylu czcionki .
Aby przesłonić metryki czcionek dla czcionki zastępczej, aby emulować czcionkę internetową, możemy użyć deskryptorów @font-face do nadpisania metryk czcionek (demo, włączone w Chrome 87). (Pamiętaj, że korekty są skomplikowane w przypadku skomplikowanych stosów czcionek.)
W przypadku późnego CSS możemy zapewnić, że CSS krytyczny dla układu jest wbudowany w nagłówek każdego szablonu. Co więcej: w przypadku długich stron dodany pionowy pasek przewijania powoduje przesunięcie głównej treści o 16 pikseli w lewo. Aby wcześnie wyświetlić pasek przewijania, możemy dodać
overflow-y: scrollonhtml, aby wymusić pasek przewijania przy pierwszym malowaniu. To ostatnie pomaga, ponieważ paski przewijania mogą powodować nietrywialne przesunięcia układu z powodu ponownego wlewania zawartości powyżej części zagięcia, gdy zmienia się szerokość. Powinno to jednak mieć miejsce głównie na platformach z paskami przewijania bez nakładek, takich jak Windows. Ale: breaksposition: sticky, ponieważ te elementy nigdy nie zostaną przewinięte z kontenera.Jeśli masz do czynienia z nagłówkami, które przyklejają się na stałe lub przyklejają się do góry strony podczas przewijania, zarezerwuj miejsce na nagłówek, gdy zostanie on wyschnięty, np. z elementem zastępczym lub
margin-topna treści. Wyjątkiem powinny być banery zgody na pliki cookie, które nie powinny mieć wpływu na CLS, ale czasami mają: zależy to od implementacji. W tym wątku na Twitterze jest kilka interesujących strategii i propozycji.W przypadku komponentu karty, który może zawierać różne ilości tekstów, możesz zapobiec przesunięciom układu za pomocą stosów siatki CSS. Umieszczając zawartość każdej zakładki w tym samym obszarze siatki i ukrywając jedną z nich na raz, możemy zapewnić, że kontener zawsze przyjmuje wysokość większego elementu, dzięki czemu nie wystąpią przesunięcia układu.
Ach, i oczywiście nieskończone przewijanie i „Załaduj więcej” mogą również powodować zmiany układu, jeśli pod listą znajduje się treść (np. stopka). Aby ulepszyć CLS, zarezerwuj wystarczająco dużo miejsca na treść, która zostanie załadowana, zanim użytkownik przewinie do tej części strony, usuń stopkę lub wszelkie elementy DOM na dole strony, które mogą zostać zepchnięte w dół podczas ładowania treści. Wstępnie pobieraj dane i obrazy dla treści w części strony widocznej na ekranie, aby zanim użytkownik przewinął tak daleko, już tam jest. Możesz użyć bibliotek wirtualizacji list, takich jak React-window, do optymalizacji długich list ( dzięki, Addy Osmani! ).
Aby upewnić się, że wpływ zmian przepływu jest uwzględniony, zmierz stabilność układu za pomocą interfejsu Layout Instability API. Dzięki niemu możesz obliczyć wynik skumulowanego przesunięcia układu ( CLS ) i uwzględnić go jako wymaganie w swoich testach, więc za każdym razem, gdy pojawi się regresja, możesz go śledzić i naprawić.
Aby obliczyć wynik przesunięcia układu, przeglądarka sprawdza rozmiar okienka ekranu i ruch niestabilnych elementów w rzutni między dwiema renderowanymi ramkami. W idealnym przypadku wynik byłby bliski
0. Jest świetny przewodnik autorstwa Milicy Mihajlija i Philipa Waltona na temat tego, czym jest CLS i jak go mierzyć. To dobry punkt wyjścia do mierzenia i utrzymywania postrzeganej wydajności oraz unikania zakłóceń, zwłaszcza w przypadku zadań o znaczeniu krytycznym dla firmy.Szybka wskazówka : aby dowiedzieć się, co spowodowało zmianę układu w DevTools, możesz zbadać zmiany układu w sekcji „Doświadczenie” w Panelu wydajności.
Bonus : jeśli chcesz ograniczyć odświeżanie i odświeżanie, sprawdź przewodnik Charisa Theodoulou na temat minimalizacji DOM Reflow/Layout Thrashing i listę Paula Irisha Co wymusza układ/przerysowanie, a także CSSTriggers.com, tabelę referencyjną właściwości CSS, które wyzwalają układ, malowanie i komponowanie.
Spis treści
- Przygotowanie: planowanie i metryki
- Wyznaczanie realistycznych celów
- Definiowanie środowiska
- Optymalizacje zasobów
- Optymalizacje kompilacji
- Optymalizacje dostawy
- Sieć, HTTP/2, HTTP/3
- Testowanie i monitorowanie
- Szybkie zwycięstwo
- Wszystko na jednej stronie
- Pobierz listę kontrolną (PDF, Apple Pages, MS Word)
- Zapisz się do naszego biuletynu e-mail, aby nie przegapić kolejnych przewodników.