
Lista kontrolna wydajności frontonu 2021 (PDF, Apple Pages, MS Word)
Opublikowany: 2022-03-10Ten przewodnik został uprzejmie poparty przez naszych przyjaciół z LogRocket, usługi, która łączy monitorowanie wydajności frontendu , odtwarzanie sesji i analizę produktów, aby pomóc Ci budować lepsze doświadczenia klientów. LogRocket śledzi kluczowe wskaźniki, m.in. DOM ukończony, czas do pierwszego bajtu, pierwsze opóźnienie wejścia, użycie procesora klienta i pamięci. Pobierz bezpłatną wersję próbną LogRocket już dziś.

Wydajność sieci to trudna bestia, prawda? Skąd właściwie wiemy, gdzie jesteśmy pod względem wydajności i jakie dokładnie są nasze wąskie gardła? Czy to drogi JavaScript, wolne dostarczanie czcionek internetowych, ciężkie obrazy lub powolne renderowanie? Czy zoptymalizowaliśmy wystarczająco dużo z drżeniem drzewa, przenoszeniem zakresu, dzieleniem kodu i wszystkimi fantazyjnymi wzorcami ładowania z obserwatorem skrzyżowań, progresywnym nawodnieniem, wskazówkami dla klientów, HTTP/3, pracownikami usługowymi i — o mój — pracownikami brzegowymi? A co najważniejsze, od czego w ogóle zaczynamy poprawiać wydajność i jak budować długoterminową kulturę wydajności?
Kiedyś występy były często tylko refleksją . Często odraczany do samego końca projektu, sprowadzałby się do minifikacji, łączenia, optymalizacji zasobów i potencjalnie kilku drobnych korekt w pliku config serwera. Patrząc wstecz, wydaje się, że sytuacja zmieniła się dość znacząco.
Wydajność to nie tylko kwestia techniczna: wpływa na wszystko, od dostępności, przez użyteczność, po optymalizację pod kątem wyszukiwarek, a podczas włączania jej do przepływu pracy, decyzje projektowe muszą być oparte na ich wpływie na wydajność. Wydajność należy stale mierzyć, monitorować i udoskonalać , a rosnąca złożoność sieci stwarza nowe wyzwania, które utrudniają śledzenie wskaźników, ponieważ dane będą się znacznie różnić w zależności od urządzenia, przeglądarki, protokołu, typu sieci i opóźnień ( Sieci CDN, dostawcy usług internetowych, pamięci podręczne, serwery proxy, zapory ogniowe, systemy równoważenia obciążenia i serwery odgrywają rolę w wydajności).
Tak więc, gdybyśmy stworzyli przegląd wszystkich rzeczy, o których musimy pamiętać przy poprawianiu wydajności — od samego początku projektu do ostatecznego wydania strony internetowej — jak by to wyglądało? Poniżej znajduje się (miejmy nadzieję, bezstronna i obiektywna) lista kontrolna wydajności front-endu na rok 2021 — zaktualizowany przegląd problemów, które należy wziąć pod uwagę, aby zapewnić szybkie czasy reakcji, płynną interakcję z użytkownikami, a witryny nie wyczerpać przepustowość użytkownika.
Spis treści
- Wszystko na osobnych stronach
- Przygotowanie: planowanie i metryki
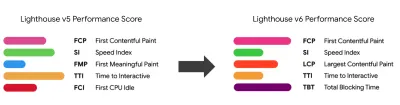
Kultura wydajności, Core Web Vitals, profile wydajności, CrUX, Lighthouse, FID, TTI, CLS, urządzenia. - Wyznaczanie realistycznych celów
Budżety wydajnościowe, cele wydajnościowe, framework RAIL, budżety 170KB/30KB. - Definiowanie środowiska
Wybór frameworka, bazowy koszt wydajności, Webpack, zależności, CDN, architektura front-end, CSR, SSR, CSR + SSR, renderowanie statyczne, renderowanie wstępne, wzorzec PRPL. - Optymalizacje zasobów
Brotli, AVIF, WebP, responsywne obrazy, AV1, adaptacyjne ładowanie mediów, kompresja wideo, czcionki internetowe, czcionki Google. - Optymalizacje kompilacji
Moduły JavaScript, wzorzec modułu/nomodule, drżenie drzewa, dzielenie kodu, przenoszenie zakresu, Webpack, serwowanie różnicowe, web worker, WebAssembly, pakiety JavaScript, React, SPA, częściowe uwodnienie, import na interakcję, strony trzecie, pamięć podręczna. - Optymalizacje dostawy
Lazy loading, obserwator skrzyżowania, odroczone renderowanie i dekodowanie, krytyczne CSS, przesyłanie strumieniowe, wskazówki dotyczące zasobów, zmiany układu, pracownik serwisu. - Sieć, HTTP/2, HTTP/3
Zszywanie OCSP, certyfikaty EV/DV, pakowanie, IPv6, QUIC, HTTP/3. - Testowanie i monitorowanie
Audyt przepływu pracy, przeglądarki proxy, strona 404, monity o zgodę na pliki cookie RODO, diagnostyka wydajności CSS, dostępność. - Szybkie zwycięstwo
- Pobierz listę kontrolną (PDF, Apple Pages, MS Word)
- No to idziemy!
(Możesz też po prostu pobrać listę kontrolną PDF (166 KB) lub pobrać edytowalny plik Apple Pages (275 KB) lub plik .docx (151 KB). Życzymy wszystkim miłej optymalizacji!)
Przygotowanie: planowanie i metryki
Mikrooptymalizacje doskonale nadają się do utrzymywania wydajności na właściwym torze, ale bardzo ważne jest, aby mieć na uwadze jasno określone cele — mierzalne cele, które wpłyną na wszelkie decyzje podejmowane w trakcie procesu. Istnieje kilka różnych modeli, a te omówione poniżej są dość uparte — po prostu upewnij się, że wcześniej ustaliłeś własne priorytety.
- Stwórz kulturę wydajności.
W wielu organizacjach programiści front-end dokładnie wiedzą, jakie są wspólne problemy i jakie strategie należy zastosować, aby je naprawić. Jednak dopóki nie ma ustalonego poparcia dla kultury wydajności, każda decyzja zamieni się w pole bitwy działów, rozbijając organizację na silosy. Potrzebujesz akceptacji interesariuszy biznesowych, a aby je uzyskać, musisz opracować studium przypadku lub dowód koncepcji szybkości — zwłaszcza podstawowe wskaźniki internetowe , które omówimy szczegółowo później — wskaźniki korzyści i kluczowe wskaźniki wydajności ( KPI ), na których im zależy.Na przykład, aby wydajność była bardziej namacalna, można wyeksponować wpływ wydajności na przychody, pokazując korelację między współczynnikiem konwersji i czasem w stosunku do obciążenia aplikacji, a także wydajności renderowania. Lub szybkość indeksowania robota wyszukiwania (PDF, strony 27–50).
Bez silnego powiązania między zespołami deweloperskimi/projektowymi i biznesowymi/marketingowymi wydajność nie utrzyma się na dłuższą metę. Zbadaj typowe skargi napływające do zespołu obsługi klienta i sprzedaży, przeanalizuj dane analityczne pod kątem wysokich współczynników odrzuceń i spadków konwersji. Dowiedz się, jak poprawa wydajności może pomóc w rozwiązaniu niektórych z tych typowych problemów. Dostosuj argumentację w zależności od grupy interesariuszy, z którymi rozmawiasz.
Przeprowadzaj eksperymenty skuteczności i mierz wyniki — zarówno na urządzeniach mobilnych, jak i na komputerach (na przykład za pomocą Google Analytics). Pomoże Ci stworzyć studium przypadku dostosowane do potrzeb firmy z rzeczywistymi danymi. Co więcej, korzystanie z danych ze studiów przypadków i eksperymentów opublikowanych w Statystykach WPO pomoże zwiększyć wrażliwość biznesu na to, dlaczego wydajność ma znaczenie i jaki ma to wpływ na wrażenia użytkownika i wskaźniki biznesowe. Samo stwierdzenie, że wydajność ma znaczenie, nie wystarczy — musisz także ustalić pewne mierzalne i możliwe do śledzenia cele i obserwować je w czasie.
Jak się tam dostać? W swoim przemówieniu na temat budowania wydajności w perspektywie długoterminowej Allison McKnight dzieli się obszernym studium przypadku, w jaki sposób pomogła stworzyć kulturę wydajności w Etsy (slajdy). Niedawno Tammy Everts mówił o nawykach wysoce efektywnych zespołów wydajnościowych zarówno w małych, jak i dużych organizacjach.
Prowadząc takie rozmowy w organizacjach, należy pamiętać, że podobnie jak UX to spektrum doświadczeń, wydajność sieci jest dystrybucją. Jak zauważyła Karolina Szczur, „oczekiwanie, że pojedyncza liczba będzie w stanie zapewnić ocenę, do której można aspirować, jest błędnym założeniem”. Dlatego cele wydajności muszą być szczegółowe, możliwe do śledzenia i namacalne.
- Cel: Być co najmniej 20% szybszym od swojego najszybszego konkurenta.
Według badań psychologicznych, jeśli chcesz, aby użytkownicy czuli, że Twoja witryna jest szybsza od witryny konkurencji, musisz być co najmniej o 20% szybszy. Przeanalizuj swoich głównych konkurentów, zbierz wskaźniki ich wyników na urządzeniach mobilnych i stacjonarnych oraz ustal progi, które pomogą Ci ich wyprzedzić. Aby jednak uzyskać dokładne wyniki i cele, upewnij się, że najpierw uzyskasz dokładny obraz doświadczeń użytkowników, analizując swoje dane analityczne. Następnie możesz naśladować doświadczenie 90. percentyla podczas testowania.Aby uzyskać dobre pierwsze wrażenie na temat wyników konkurencji, możesz skorzystać z Chrome UX Report ( CrUX , gotowy zestaw danych RUM, wprowadzenie wideo autorstwa Ilyi Grigorika i szczegółowy przewodnik autorstwa Ricka Viscomiego) lub Treo, narzędzie do monitorowania RUM, które jest obsługiwany przez raport Chrome UX. Dane są zbierane od użytkowników przeglądarki Chrome, więc raporty będą dotyczyć tylko przeglądarki Chrome, ale zapewnią dość dokładny rozkład wydajności, a przede wszystkim wyniki Core Web Vitals, wśród szerokiego grona użytkowników. Zauważ, że nowe zestawy danych CrUX są publikowane w drugi wtorek każdego miesiąca .
Alternatywnie możesz również użyć:
- Narzędzie do porównywania raportów Chrome UX firmy Addy Osmani,
- Speed Scorecard (zapewnia również szacowanie wpływu na przychody),
- Porównanie testów rzeczywistych doświadczeń użytkownika lub
- SiteSpeed CI (na podstawie testów syntetycznych).
Uwaga : jeśli korzystasz z interfejsu Page Speed Insights lub Page Speed Insights API (nie, to nie jest przestarzałe!), możesz uzyskać dane o wydajności CrUX dla określonych stron zamiast tylko danych zbiorczych. Te dane mogą być znacznie bardziej przydatne do ustawiania celów skuteczności dla zasobów, takich jak „strona docelowa” lub „lista produktów”. A jeśli używasz CI do testowania budżetów, musisz upewnić się, że twoje testowane środowisko pasuje do CrUX, jeśli użyłeś CrUX do ustawienia celu ( dzięki Patrickowi Meenan! ).
Jeśli potrzebujesz pomocy, aby pokazać rozumowanie stojące za ustalaniem priorytetów szybkości, lub chcesz wizualizować spadek współczynnika konwersji lub wzrost współczynnika odrzuceń przy niższej wydajności, lub być może potrzebujesz orędowania za rozwiązaniem RUM w swojej organizacji, Sergey Chernyshev zbudował Kalkulator prędkości UX, narzędzie typu open source, które pomaga symulować dane i wizualizować je w celu osiągnięcia celu.
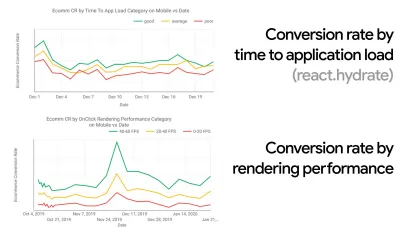
CrUX generuje przegląd rozkładów wydajności w czasie, z ruchem zbieranym od użytkowników Google Chrome. Możesz tworzyć własne w panelu Chrome UX Dashboard. (duży podgląd) 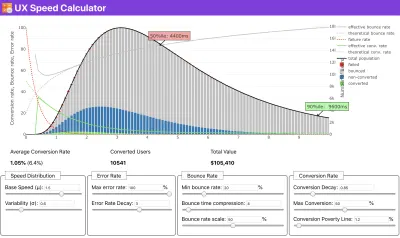
Właśnie wtedy, gdy potrzebujesz argumentów za wydajnością, aby osiągnąć cel: Kalkulator prędkości UX wizualizuje wpływ wydajności na współczynniki odrzuceń, konwersję i całkowity przychód — na podstawie rzeczywistych danych. (duży podgląd) Czasami możesz chcieć wejść nieco głębiej, łącząc dane pochodzące z CrUX z dowolnymi innymi danymi, które już musisz szybko ustalić, gdzie leżą spowolnienia, martwe punkty i nieefektywność — dla konkurencji lub dla twojego projektu. W swojej pracy Harry Roberts korzystał z arkusza kalkulacyjnego topografii Site-Speed, którego używa do rozbicia wydajności według kluczowych typów stron i śledzenia różnych kluczowych wskaźników na nich. Możesz pobrać arkusz kalkulacyjny jako Arkusze Google, Excel, dokument OpenOffice lub CSV.
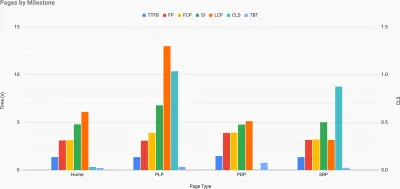
Topografia szybkości witryny z kluczowymi wskaźnikami przedstawianymi dla kluczowych stron w witrynie. (duży podgląd) A jeśli chcesz przejść na całość , możesz przeprowadzić audyt wydajności Lighthouse na każdej stronie witryny (za pośrednictwem Lightouse Parade), z wynikiem zapisanym jako CSV. Pomoże Ci to określić, które konkretnie strony (lub typy stron) konkurencji osiągają gorsze lub lepsze wyniki i na czym możesz chcieć skoncentrować swoje wysiłki. (W przypadku własnej witryny prawdopodobnie lepiej wysłać dane do punktu końcowego analizy!).

Dzięki Lighthouse Parade możesz przeprowadzić audyt wydajności Lighthouse na każdej stronie witryny, z wynikiem zapisanym jako CSV. (duży podgląd) Zbieraj dane, skonfiguruj arkusz kalkulacyjny, zmniejsz o 20% i skonfiguruj swoje cele ( budżety wydajnościowe ) w ten sposób. Teraz masz coś mierzalnego do sprawdzenia. Jeśli pamiętasz o budżecie i próbujesz wysłać tylko minimalną ładowność, aby uzyskać szybki czas na interakcję, jesteś na rozsądnej ścieżce.
Potrzebujesz zasobów, aby rozpocząć?
- Addy Osmani napisał bardzo szczegółowy opis, jak rozpocząć budżetowanie wydajnościowe, jak określić ilościowo wpływ nowych funkcji i od czego zacząć, gdy przekroczysz budżet.
- Przewodnik Lary Hogan na temat podejścia do projektów z budżetem wydajności może dostarczyć przydatnych wskazówek projektantom.
- Harry Roberts opublikował przewodnik dotyczący konfigurowania arkusza Google do wyświetlania wpływu skryptów innych firm na wydajność za pomocą mapy żądań,
- Kalkulator budżetu wydajności Jonathana Fieldinga, kalkulator budżetu perf-budget Katie Hempenius i kalorie przeglądarki mogą pomóc w tworzeniu budżetów (podziękowania dla Karoliny Szczur za ostrzeżenie).
- W wielu firmach budżety zadaniowe nie powinny być aspiracyjne, ale raczej pragmatyczne, służąc jako znak wstrzymania, aby uniknąć przekroczenia pewnego punktu. W takim przypadku możesz wybrać najgorszy punkt danych w ciągu ostatnich dwóch tygodni jako próg i przyjąć go stamtąd. Budżety wydajnościowe, pragmatycznie pokazuje strategię, aby to osiągnąć.
- Ponadto uwidocznij zarówno budżet wydajności, jak i bieżącą wydajność, konfigurując pulpity nawigacyjne z wykresami raportującymi rozmiary kompilacji. Istnieje wiele narzędzi, które pozwalają to osiągnąć: pulpit nawigacyjny SiteSpeed.io (open source), SpeedCurve i Calibre to tylko kilka z nich, a więcej narzędzi można znaleźć na perf.rocks.

Kalorie przeglądarki pomagają ustawić budżet wydajności i zmierzyć, czy strona przekracza te liczby, czy nie. (duży podgląd) Po ustaleniu budżetu, uwzględnij je w procesie kompilacji za pomocą Webpack Performance Hints and Bundlesize, Lighthouse CI, PWMetrics lub Sitespeed CI, aby wymusić budżety na żądaniach ściągnięcia i zapewnić historię wyników w komentarzach PR.
Aby udostępnić budżety wydajności całemu zespołowi, zintegruj budżety wydajności w Lighthouse za pośrednictwem Lightwallet lub użyj LHCI Action do szybkiej integracji z Github Actions. A jeśli potrzebujesz czegoś niestandardowego, możesz użyć webpagetest-charts-api, API punktów końcowych do tworzenia wykresów z wyników WebPagetest.
Świadomość wydajności nie powinna jednak pochodzić wyłącznie z budżetów wydajności. Podobnie jak Pinterest, możesz utworzyć niestandardową regułę eslint , która uniemożliwia importowanie z plików i katalogów, o których wiadomo, że zawierają duże zależności i które spowodowałyby rozdęcie pakietu. Skonfiguruj listę „bezpiecznych” pakietów, które można udostępniać całemu zespołowi.
Pomyśl także o krytycznych zadaniach klienta, które są najbardziej korzystne dla Twojej firmy. Przestudiuj, omów i zdefiniuj dopuszczalne progi czasowe dla krytycznych działań i ustal „przygotowane na UX” znaczniki czasu użytkownika, które zatwierdziła cała organizacja. W wielu przypadkach podróże użytkowników będą dotyczyć pracy wielu różnych działów, więc dostosowanie pod względem akceptowalnego harmonogramu pomoże wesprzeć lub zapobiec dyskusjom na temat wydajności w przyszłości. Upewnij się, że dodatkowe koszty dodanych zasobów i funkcji są widoczne i zrozumiałe.
Połącz wysiłki w zakresie wydajności z innymi inicjatywami technologicznymi, od nowych funkcji tworzonego produktu, przez refaktoryzację, po docieranie do nowych odbiorców na całym świecie. Tak więc za każdym razem, gdy odbywa się rozmowa o dalszym rozwoju, częścią tej rozmowy jest również wydajność. Znacznie łatwiej jest osiągnąć cele wydajnościowe, gdy baza kodu jest świeża lub właśnie jest refaktorowana.
Ponadto, jak zasugerował Patrick Meenan, warto zaplanować sekwencję ładowania i kompromisy podczas procesu projektowania. Jeśli wcześnie określisz priorytety, które części są bardziej krytyczne i określisz kolejność, w jakiej powinny się pojawiać, będziesz również wiedział, co można opóźnić. Najlepiej byłoby, gdyby ta kolejność odzwierciedlała również kolejność importów CSS i JavaScript, więc obsługa ich podczas procesu budowania będzie łatwiejsza. Zastanów się również, jakie wrażenia wizualne powinny znajdować się w stanach „pomiędzy” podczas ładowania strony (np. gdy czcionki internetowe nie zostały jeszcze załadowane).
Gdy już ustanowisz silną kulturę wydajności w swojej organizacji, postaraj się być o 20% szybszy niż poprzednie ja , aby zachować priorytety w miarę upływu czasu ( dzięki, Guy Podjarny! ). Ale weź pod uwagę różne typy i zachowania użytkowników (które Tobias Baldauf nazwał kadencją i kohortami), a także ruch botów i efekty sezonowości.
Planowanie, planowanie, planowanie. Może być kuszące, aby wcześnie przejść do kilku szybkich optymalizacji „nisko wiszących” — i może to być dobra strategia na szybkie zwycięstwa — ale bardzo trudno będzie utrzymać wydajność jako priorytet bez planowania i ustawiania realistycznego, firma -dopasowane cele wydajnościowe.
- Wybierz odpowiednie dane.
Nie wszystkie metryki są równie ważne. Sprawdź, jakie metryki mają największe znaczenie dla Twojej aplikacji: zazwyczaj będą one definiowane na podstawie tego, jak szybko możesz zacząć renderować najważniejsze piksele interfejsu i jak szybko możesz zapewnić czas reakcji wejściowej dla tych renderowanych pikseli. Ta wiedza zapewni Ci najlepszy cel optymalizacji bieżących wysiłków. Ostatecznie to nie zdarzenia ładowania lub czasy odpowiedzi serwera definiują wrażenia, ale postrzeganie tego, jak zgrabny jest interfejs .Co to znaczy? Zamiast skupiać się na czasie pełnego wczytywania strony (na przykład przez czasy onLoad i DOMContentLoaded ), nadaj priorytet ładowaniu strony, tak jak postrzegają to Twoi klienci. Oznacza to skupienie się na nieco innym zestawie wskaźników. W rzeczywistości wybór odpowiedniego wskaźnika to proces bez oczywistych zwycięzców.
Bazując na badaniach Tima Kadleca i notatkach Marcosa Iglesiasa w jego przemówieniu, tradycyjne metryki można pogrupować w kilka zestawów. Zwykle potrzebujemy ich wszystkich, aby uzyskać pełny obraz wydajności, a w konkretnym przypadku niektóre z nich będą ważniejsze od innych.
- Mierniki oparte na ilości mierzą liczbę żądań, wagę i wynik wydajności. Dobry do zgłaszania alarmów i monitorowania zmian w czasie, nie tak dobry do zrozumienia doświadczenia użytkownika.
- Metryki kamieni milowych wykorzystują stany w czasie życia procesu ładowania, np. Time To First Byte i Time To Interactive . Dobry do opisywania wrażenia użytkownika i monitorowania, nie tak dobry, aby wiedzieć, co dzieje się między kamieniami milowymi.
- Metryki renderowania zapewniają oszacowanie szybkości renderowania treści (np. czas rozpoczęcia renderowania , indeks szybkości ). Dobry do mierzenia i poprawiania wydajności renderowania, ale nie tak dobry do mierzenia, kiedy pojawia się ważna treść i można z nią wchodzić w interakcję.
- Niestandardowe metryki mierzą konkretne, niestandardowe zdarzenie dla użytkownika, np. Czas do pierwszego tweeta na Twitterze i PinnerWaitTime na Pintereście. Dobry do dokładnego opisania doświadczenia użytkownika, nie tak dobry do skalowania metryk i porównywania z konkurencją.
Aby uzupełnić obraz, zwykle szukamy przydatnych danych we wszystkich tych grupach. Zazwyczaj najbardziej szczegółowe i odpowiednie są:
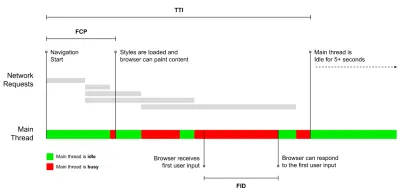
- Czas na interakcję (TTI)
Punkt, w którym układ się ustabilizował , widoczne są kluczowe czcionki internetowe, a główny wątek jest wystarczająco dostępny, aby obsłużyć dane wejściowe użytkownika — w zasadzie oznacza to czas, kiedy użytkownik może wchodzić w interakcję z interfejsem użytkownika. Kluczowe wskaźniki pozwalające zrozumieć, ile czasu musi czekać użytkownik, aby korzystać z witryny bez opóźnień. Boris Schapira napisał szczegółowy post o tym, jak wiarygodnie mierzyć TTI. - Opóźnienie pierwszego wejścia (FID) lub reakcja na wejście
Czas od pierwszej interakcji użytkownika z Twoją witryną do momentu, w którym przeglądarka rzeczywiście jest w stanie zareagować na tę interakcję. Bardzo dobrze uzupełnia TTI, ponieważ opisuje brakującą część obrazu: co się dzieje, gdy użytkownik faktycznie wchodzi w interakcję z witryną. Przeznaczone wyłącznie jako metryka RUM. W przeglądarce dostępna jest biblioteka JavaScript do pomiaru FID. - Największa zawartość farby (LCP)
Oznacza punkt na osi czasu ładowania strony, w którym prawdopodobnie została załadowana ważna treść strony. Założenie jest takie, że najważniejszym elementem strony jest największy widoczny w widoku użytkownika. Jeśli elementy są renderowane zarówno nad, jak i pod zakładką, tylko widoczna część jest uważana za istotną. - Całkowity czas blokowania ( TBT )
Miernik, który pomaga w ilościowym określeniu stopnia, w jakim strona nie jest interaktywna, zanim stanie się niezawodnie interaktywna (oznacza to, że główny wątek był wolny od zadań trwających ponad 50 ms ( długie zadania ) przez co najmniej 5 s). Metryka mierzy łączny czas między pierwszym malowaniem a czasem do interakcji (TTI), w którym wątek główny był blokowany na tyle długo, aby uniemożliwić reagowanie na dane wejściowe. Nic więc dziwnego, że niski TBT jest dobrym wskaźnikiem dobrej wydajności. (dzięki, Artem, Phil) - Zbiorcze przesunięcie układu ( CLS )
Wskaźnik pokazuje, jak często użytkownicy doświadczają nieoczekiwanych zmian układu (zmiany układu ) podczas uzyskiwania dostępu do witryny. Bada niestabilne elementy i ich wpływ na ogólne wrażenia. Im niższy wynik, tym lepiej. - Indeks prędkości
Mierzy, jak szybko zawartość strony jest wizualnie wypełniana; im niższy wynik, tym lepiej. Wynik indeksu prędkości jest obliczany na podstawie szybkości postępu wizualnego , ale jest to tylko wartość obliczona. Jest również wrażliwy na rozmiar widocznego obszaru, więc musisz zdefiniować szereg konfiguracji testowych, które pasują do docelowych odbiorców. Zauważ, że staje się to mniej ważne, a LCP staje się bardziej odpowiednią metryką ( dzięki, Boris, Artem! ). - Czas spędzony na procesorze
Miara, która pokazuje, jak często i jak długo główny wątek jest blokowany, pracując nad malowaniem, renderowaniem, skryptowaniem i ładowaniem. Wysoki czas procesora jest wyraźnym wskaźnikiem złego doświadczenia, tj. kiedy użytkownik odczuwa zauważalne opóźnienie między akcją a reakcją. Za pomocą WebPageTest możesz wybrać opcję „Capture Dev Tools Timeline” na karcie „Chrome”, aby ujawnić podział głównego wątku, gdy działa on na dowolnym urządzeniu za pomocą WebPageTest. - Koszty procesora na poziomie komponentów
Podobnie jak w przypadku czasu spędzonego na CPU , ta metryka, zaproponowana przez Stoyana Stefanova, bada wpływ JavaScript na CPU . Pomysł polega na użyciu liczby instrukcji procesora na komponent, aby zrozumieć jej wpływ na ogólne wrażenia, w odosobnieniu. Może być zaimplementowany przy użyciu Puppeteer i Chrome. - Wskaźnik frustracji
Podczas gdy wiele wskaźników przedstawionych powyżej wyjaśnia, kiedy ma miejsce określone zdarzenie, FrustrationIndex Tima Vereecke'a analizuje luki między wskaźnikami, zamiast patrzeć na nie indywidualnie. Analizuje kluczowe kamienie milowe postrzegane przez użytkownika końcowego, takie jak widoczny tytuł, widoczna pierwsza treść, gotowa wizualnie i strona wygląda na gotową, i oblicza wynik wskazujący poziom frustracji podczas ładowania strony. Im większa różnica, tym większa szansa, że użytkownik będzie sfrustrowany. Potencjalnie dobry KPI dla doświadczenia użytkownika. Tim opublikował szczegółowy post na temat FrustrationIndex i sposobu jego działania. - Wpływ wagi reklamy
Jeśli Twoja witryna jest uzależniona od przychodów generowanych przez reklamy, warto śledzić wagę kodu związanego z reklamą. Skrypt Paddy Ganti konstruuje dwa adresy URL (jeden normalny i jeden blokujący reklamy), monituje o wygenerowanie porównania wideo za pośrednictwem WebPageTest i zgłasza deltę. - Mierniki odchyleń
Jak zauważyli inżynierowie Wikipedii, dane o tym, jak duże są rozbieżności w twoich wynikach, mogą informować o tym, jak niezawodne są twoje instrumenty i jak dużo uwagi powinieneś zwrócić na odchylenia i wartości odstające. Duża wariancja jest wskaźnikiem korekt potrzebnych w konfiguracji. Pomaga również zrozumieć, czy niektóre strony są trudniejsze do wiarygodnego pomiaru, np. z powodu skryptów stron trzecich powodujących znaczne różnice. Dobrym pomysłem może być również śledzenie wersji przeglądarki, aby zrozumieć skoki wydajności po wprowadzeniu nowej wersji przeglądarki. - Dane niestandardowe
Niestandardowe metryki są definiowane na podstawie Twoich potrzeb biznesowych i doświadczenia klienta. Wymaga zidentyfikowania ważnych pikseli, krytycznych skryptów, niezbędnych CSS i odpowiednich zasobów oraz zmierzenia, jak szybko są dostarczane do użytkownika. W tym celu możesz monitorować Hero Rendering Times lub skorzystać z Performance API, oznaczając konkretne sygnatury czasowe dla wydarzeń, które są ważne dla Twojej firmy. Ponadto możesz zbierać niestandardowe metryki za pomocą WebPagetest, wykonując dowolny kod JavaScript na końcu testu.
Zauważ, że pierwsza znacząca farba (FMP) nie pojawia się w powyższym przeglądzie. Kiedyś zapewniał wgląd w to, jak szybko serwer wyprowadza dane. Długi FMP zwykle wskazywał, że JavaScript blokuje główny wątek, ale może być również związany z problemami z zapleczem/serwerem. Jednak wskaźnik ten został ostatnio przestarzały, ponieważ wydaje się, że nie jest dokładny w około 20% przypadków. Został skutecznie zastąpiony przez LCP, który jest zarówno bardziej niezawodny, jak i łatwiejszy do zrozumienia. Nie jest już obsługiwany w Lighthouse. Dokładnie sprawdź najnowsze metryki i zalecenia dotyczące wydajności zorientowane na użytkownika, aby upewnić się, że jesteś na bezpiecznej stronie ( dzięki, Patrick Meenan ).
Steve Souders szczegółowo wyjaśnia wiele z tych wskaźników. Należy zauważyć, że podczas gdy czas do interakcji jest mierzony poprzez przeprowadzanie automatycznych audytów w tak zwanym środowisku laboratoryjnym , opóźnienie pierwszego wejścia reprezentuje rzeczywiste wrażenia użytkownika, przy czym faktyczni użytkownicy doświadczają zauważalnego opóźnienia. Ogólnie rzecz biorąc, dobrym pomysłem jest zawsze mierzenie i śledzenie ich obu.
W zależności od kontekstu Twojej aplikacji preferowane metryki mogą się różnić: np. w przypadku interfejsu użytkownika Netflix TV bardziej krytyczne są czas reakcji na wprowadzanie danych, użycie pamięci i TTI, a w przypadku Wikipedii ważniejsze są pierwsze/ostatnie zmiany wizualne oraz metryki czasu pracy procesora.
Uwaga : zarówno FID, jak i TTI nie uwzględniają przewijania; przewijanie może odbywać się niezależnie, ponieważ jest poza głównym wątkiem, więc w przypadku wielu witryn konsumujących treści te dane mogą być znacznie mniej ważne ( dzięki, Patrick! ).
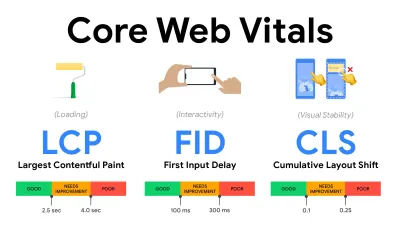
- Mierz i optymalizuj podstawowe wskaźniki internetowe .
Przez długi czas wskaźniki wydajności były dość techniczne i skupiały się na inżynierskim spojrzeniu na to, jak szybko serwery reagują i jak szybko ładują się przeglądarki. Wskaźniki zmieniały się na przestrzeni lat — próbując znaleźć sposób na uchwycenie rzeczywistego doświadczenia użytkownika, a nie czasy serwera. W maju 2020 r. Google ogłosił Core Web Vitals, zestaw nowych metryk wydajności skoncentrowanych na użytkowniku, z których każdy reprezentuje inny aspekt doświadczenia użytkownika.Dla każdego z nich Google zaleca szereg akceptowalnych celów dotyczących szybkości. Aby zaliczyć tę ocenę, co najmniej 75% wszystkich odsłon powinno przekraczać zakres Dobry . Wskaźniki te szybko zyskały popularność, a ponieważ kluczowe wskaźniki sieciowe stały się sygnałami rankingowymi dla wyszukiwarki Google w maju 2021 r. ( aktualizacja algorytmu rankingu Page Experience ), wiele firm zwróciło uwagę na swoje wyniki wydajności.
Przeanalizujmy każdy z kluczowych wskaźników internetowych, jeden po drugim, wraz z przydatnymi technikami i narzędziami do optymalizacji doświadczeń z uwzględnieniem tych wskaźników. (Warto zauważyć, że postępując zgodnie z ogólną radą w tym artykule, uzyskasz lepsze wyniki Core Web Vitals).
- Największa zawartość farby ( LCP ) < 2,5 sek.
Mierzy ładowanie strony i zgłasza czas renderowania największego bloku obrazu lub tekstu widocznego w widocznym obszarze. W związku z tym na LCP wpływa wszystko, co opóźnia renderowanie ważnych informacji — czy to powolne czasy odpowiedzi serwera, blokowanie CSS, JavaScript w locie (własne lub zewnętrzne), ładowanie czcionek internetowych, kosztowne operacje renderowania lub malowania, leniwy - załadowane obrazy, ekrany szkieletowe lub renderowanie po stronie klienta.
Aby zapewnić dobre wrażenia, LCP powinno nastąpić w ciągu 2,5 s od pierwszego rozpoczęcia ładowania strony. Oznacza to, że musimy wyrenderować pierwszą widoczną część strony tak wcześnie, jak to możliwe. Będzie to wymagało dostosowanego krytycznego kodu CSS dla każdego szablonu, uporządkowania kolejności<head>i wstępnego pobierania krytycznych zasobów (omówimy je później).Głównym powodem niskiego wyniku LCP są zwykle obrazy. Aby dostarczyć LCP w <2,5 s na Fast 3G — hostowanym na dobrze zoptymalizowanym serwerze, całkowicie statycznym bez renderowania po stronie klienta i z obrazem pochodzącym z dedykowanej sieci CDN obrazu — oznacza to, że maksymalny teoretyczny rozmiar obrazu wynosi tylko około 144 KB . Dlatego ważne są responsywne obrazy, a także wczesne wczytywanie krytycznych obrazów (za pomocą
preloadładowania ).Szybka wskazówka : aby dowiedzieć się, co jest uważane za LCP na stronie, w DevTools możesz najechać kursorem na znaczek LCP w sekcji „Czasy” w Panelu wydajności ( dzięki, Tim Kadlec !).
- Opóźnienie pierwszego wejścia ( FID ) < 100ms.
Mierzy czas reakcji interfejsu użytkownika, tj. jak długo przeglądarka była zajęta innymi zadaniami, zanim mogła zareagować na dyskretne zdarzenie wejściowe użytkownika, takie jak dotknięcie lub kliknięcie. Został zaprojektowany do przechwytywania opóźnień wynikających z zajętości głównego wątku, zwłaszcza podczas ładowania strony.
Celem jest utrzymanie się w granicach 50-100 ms dla każdej interakcji. Aby się tam dostać, musimy zidentyfikować długie zadania (blokuje główny wątek na >50ms) i je rozbić, podzielić kod na wiele części, skrócić czas wykonania JavaScript, zoptymalizować pobieranie danych, odroczyć wykonywanie skryptów przez strony trzecie , przenieś JavaScript do wątku w tle z pracownikami sieci Web i użyj progresywnego nawadniania, aby zmniejszyć koszty ponownego nawadniania w SPA.Szybka wskazówka : ogólnie rzecz biorąc, niezawodną strategią uzyskania lepszego wyniku FID jest zminimalizowanie pracy nad głównym wątkiem poprzez rozbicie większych pakietów na mniejsze i służenie tym, czego użytkownik potrzebuje, gdy tego potrzebuje, aby interakcje użytkownika nie były opóźnione . Szczegółowo omówimy to poniżej.
- Łączne przesunięcie układu ( CLS ) < 0,1.
Mierzy stabilność wizualną interfejsu użytkownika, aby zapewnić płynne i naturalne interakcje, tj. sumę wszystkich indywidualnych wyników zmian układu dla każdej nieoczekiwanej zmiany układu, która ma miejsce w trakcie życia strony. Indywidualne przesunięcie układu następuje za każdym razem, gdy element, który był już widoczny, zmienia swoje położenie na stronie. Jest oceniany na podstawie rozmiaru treści i odległości, jaką przebył.
Tak więc za każdym razem, gdy pojawia się zmiana — np. gdy czcionki rezerwowe i czcionki internetowe mają różne metryki czcionek lub reklamy, elementy osadzone lub ramki iframe pojawiają się późno, lub wymiary obrazu/wideo nie są zarezerwowane, lub późny CSS wymusza odświeżenie lub wstrzykuje zmiany przez późny JavaScript — ma wpływ na wynik CLS. Zalecaną wartością dobrego doświadczenia jest CLS < 0,1.
Warto zauważyć, że Core Web Vitals ma ewoluować w czasie, z przewidywalnym cyklem rocznym . W przypadku aktualizacji z pierwszego roku możemy spodziewać się awansu First Contentful Paint do Core Web Vitals, obniżonego progu FID i lepszej obsługi aplikacji jednostronicowych. We might also see the responding to user inputs after load gaining more weight, along with security, privacy and accessibility (!) considerations.
Related to Core Web Vitals, there are plenty of useful resources and articles that are worth looking into:
- Web Vitals Leaderboard allows you to compare your scores against competition on mobile, tablet, desktop, and on 3G and 4G.
- Core SERP Vitals, a Chrome extension that shows the Core Web Vitals from CrUX in the Google Search Results.
- Layout Shift GIF Generator that visualizes CLS with a simple GIF (also available from the command line).
- web-vitals library can collect and send Core Web Vitals to Google Analytics, Google Tag Manager or any other analytics endpoint.
- Analyzing Web Vitals with WebPageTest, in which Patrick Meenan explores how WebPageTest exposes data about Core Web Vitals.
- Optimizing with Core Web Vitals, a 50-min video with Addy Osmani, in which he highlights how to improve Core Web Vitals in an eCommerce case-study.
- Cumulative Layout Shift in Practice and Cumulative Layout Shift in the Real World are comprehensive articles by Nic Jansma, which cover pretty much everything about CLS and how it correlates with key metrics such as Bounce Rate, Session Time or Rage Clicks.
- What Forces Reflow, with an overview of properties or methods, when requested/called in JavaScript, that will trigger the browser to synchronously calculate the style and layout.
- CSS Triggers shows which CSS properties trigger Layout, Paint and Composite.
- Fixing Layout Instability is a walkthrough of using WebPageTest to identify and fix layout instability issues.
- Cumulative Layout Shift, The Layout Instability Metric, another very detailed guide by Boris Schapira on CLS, how it's calcualted, how to measure and how to optimize for it.
- How To Improve Core Web Vitals, a detailed guide by Simon Hearne on each of the metrics (including other Web Vitals, such as FCP, TTI, TBT), when they occur and how they are measured.
So, are Core Web Vitals the ultimate metrics to follow ? Not quite. They are indeed exposed in most RUM solutions and platforms already, including Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (in the filmstrip view already), Newrelic, Shopify, Next.js, all Google tools (PageSpeed Insights, Lighthouse + CI, Search Console etc.) and many others.
However, as Katie Sylor-Miller explains, some of the main problems with Core Web Vitals are the lack of cross-browser support, we don't really measure the full lifecycle of a user's experience, plus it's difficult to correlate changes in FID and CLS with business outcomes.
As we should be expecting Core Web Vitals to evolve, it seems only reasonable to always combine Web Vitals with your custom-tailored metrics to get a better understanding of where you stand in terms of performance.
- Największa zawartość farby ( LCP ) < 2,5 sek.
- Gather data on a device representative of your audience.
To gather accurate data, we need to thoroughly choose devices to test on. In most companies, that means looking into analytics and creating user profiles based on most common device types. Yet often, analytics alone doesn't provide a complete picture. A significant portion of the target audience might be abandoning the site (and not returning back) just because their experience is too slow, and their devices are unlikely to show up as the most popular devices in analytics for that reason. So, additionally conducting research on common devices in your target group might be a good idea.Globally in 2020, according to the IDC, 84.8% of all shipped mobile phones are Android devices. An average consumer upgrades their phone every 2 years, and in the US phone replacement cycle is 33 months. Average bestselling phones around the world will cost under $200.
A representative device, then, is an Android device that is at least 24 months old , costing $200 or less, running on slow 3G, 400ms RTT and 400kbps transfer, just to be slightly more pessimistic. This might be very different for your company, of course, but that's a close enough approximation of a majority of customers out there. In fact, it might be a good idea to look into current Amazon Best Sellers for your target market. ( Thanks to Tim Kadlec, Henri Helvetica and Alex Russell for the pointers! ).
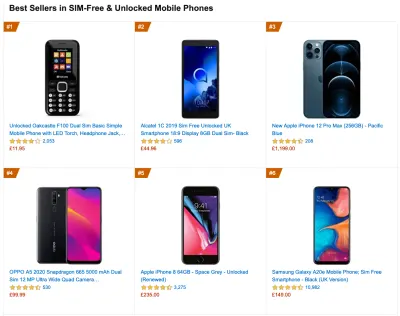
When building a new site or app, always check current Amazon Best Sellers for your target market first. (duży podgląd) What test devices to choose then? The ones that fit well with the profile outlined above. It's a good option to choose a slightly older Moto G4/G5 Plus, a mid-range Samsung device (Galaxy A50, S8), a good middle-of-the-road device like a Nexus 5X, Xiaomi Mi A3 or Xiaomi Redmi Note 7 and a slow device like Alcatel 1X or Cubot X19, perhaps in an open device lab. For testing on slower thermal-throttled devices, you could also get a Nexus 4, which costs just around $100.
Also, check the chipsets used in each device and do not over-represent one chipset : a few generations of Snapdragon and Apple as well as low-end Rockchip, Mediatek would be enough (thanks, Patrick!) .
If you don't have a device at hand, emulate mobile experience on desktop by testing on a throttled 3G network (eg 300ms RTT, 1.6 Mbps down, 0.8 Mbps up) with a throttled CPU (5× slowdown). Eventually switch over to regular 3G, slow 4G (eg 170ms RTT, 9 Mbps down, 9Mbps up), and Wi-Fi. To make the performance impact more visible, you could even introduce 2G Tuesdays or set up a throttled 3G/4G network in your office for faster testing.
Keep in mind that on a mobile device, we should be expecting a 4×–5× slowdown compared to desktop machines. Mobile devices have different GPUs, CPU, memory and different battery characteristics. That's why it's important to have a good profile of an average device and always test on such a device.
- Synthetic testing tools collect lab data in a reproducible environment with predefined device and network settings (eg Lighthouse , Calibre , WebPageTest ) and
- Real User Monitoring ( RUM ) tools evaluate user interactions continuously and collect field data (eg SpeedCurve , New Relic — the tools provide synthetic testing, too).
- use Lighthouse CI to track Lighthouse scores over time (it's quite impressive),
- run Lighthouse in GitHub Actions to get a Lighthouse report alongside every PR,
- run a Lighthouse performance audit on every page of a site (via Lightouse Parade), with an output saved as CSV,
- use Lighthouse Scores Calculator and Lighthouse metric weights if you need to dive into more detail.
- Lighthouse is available for Firefox as well, but under the hood it uses the PageSpeed Insights API and generates a report based on a headless Chrome 79 User-Agent.

Luckily, there are many great options that help you automate the collection of data and measure how your website performs over time according to these metrics. Keep in mind that a good performance picture covers a set of performance metrics, lab data and field data:
The former is particularly useful during development as it will help you identify, isolate and fix performance issues while working on the product. The latter is useful for long-term maintenance as it will help you understand your performance bottlenecks as they are happening live — when users actually access the site.
By tapping into built-in RUM APIs such as Navigation Timing, Resource Timing, Paint Timing, Long Tasks, etc., synthetic testing tools and RUM together provide a complete picture of performance in your application. You could use Calibre, Treo, SpeedCurve, mPulse and Boomerang, Sitespeed.io, which all are great options for performance monitoring. Furthermore, with Server Timing header, you could even monitor back-end and front-end performance all in one place.
Note : It's always a safer bet to choose network-level throttlers, external to the browser, as, for example, DevTools has issues interacting with HTTP/2 push, due to the way it's implemented ( thanks, Yoav, Patrick !). For Mac OS, we can use Network Link Conditioner, for Windows Windows Traffic Shaper, for Linux netem, and for FreeBSD dummynet.
As it's likely that you'll be testing in Lighthouse, keep in mind that you can:
- Set up "clean" and "customer" profiles for testing.
While running tests in passive monitoring tools, it's a common strategy to turn off anti-virus and background CPU tasks, remove background bandwidth transfers and test with a clean user profile without browser extensions to avoid skewed results (in Firefox, and in Chrome).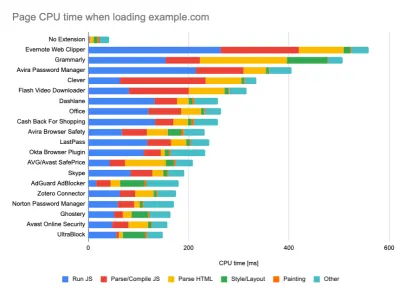
DebugBear's report highlights 20 slowest extensions, including password managers, ad-blockers and popular applications like Evernote and Grammarly. (duży podgląd) However, it's also a good idea to study which browser extensions your customers use frequently, and test with dedicated "customer" profiles as well. In fact, some extensions might have a profound performance impact (2020 Chrome Extension Performance Report) on your application, and if your users use them a lot, you might want to account for it up front. Hence, "clean" profile results alone are overly optimistic and can be crushed in real-life scenarios.
- Podziel się celami wydajności z kolegami.
Upewnij się, że cele dotyczące wydajności są znane każdemu członkowi Twojego zespołu, aby uniknąć nieporozumień w przyszłości. Każda decyzja — czy to projektowa, marketingowa, czy cokolwiek pomiędzy — ma wpływ na wydajność , a rozłożenie odpowiedzialności i własności na cały zespół usprawni późniejsze decyzje ukierunkowane na wydajność. Odwzoruj decyzje projektowe w stosunku do budżetu wydajności i priorytetów zdefiniowanych na wczesnym etapie.
Wyznaczanie realistycznych celów
- Czas reakcji 100 milisekund, 60 kl./s.
Aby interakcja była płynna, interfejs ma 100 ms na reakcję na dane wejściowe użytkownika. Po dłuższym czasie użytkownik postrzega aplikację jako opóźnioną. RAIL, model wydajności zorientowany na użytkownika, zapewnia zdrowe cele : aby umożliwić odpowiedź <100 milisekund, strona musi przekazywać kontrolę z powrotem do głównego wątku najpóźniej po każdych <50 milisekundach. Szacowane opóźnienie wejścia informuje nas, czy osiągamy ten próg, a najlepiej, aby był poniżej 50 ms. W przypadku punktów o wysokim ciśnieniu, takich jak animacja, najlepiej nie robić nic innego tam, gdzie możesz, a absolutne minimum tam, gdzie nie możesz.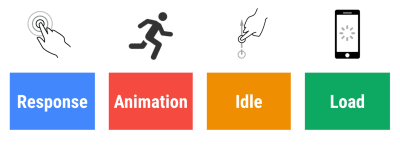
RAIL, model wydajności zorientowany na użytkownika. Ponadto każda klatka animacji powinna zostać ukończona w czasie krótszym niż 16 milisekund, osiągając w ten sposób 60 klatek na sekundę (1 sekunda ÷ 60 = 16,6 milisekund) — najlepiej poniżej 10 milisekund. Ponieważ przeglądarka potrzebuje czasu, aby narysować nową klatkę na ekranie, Twój kod powinien zakończyć wykonywanie przed osiągnięciem znaku 16,6 milisekund. Zaczynamy rozmawiać na temat 120 klatek na sekundę (np. ekrany iPada Pro działają z częstotliwością 120 Hz), a Surma omówiła niektóre rozwiązania w zakresie wydajności renderowania dla 120 klatek na sekundę, ale prawdopodobnie nie jest to cel, na który jeszcze patrzymy.
Bądź pesymistyczny jeśli chodzi o oczekiwania dotyczące wydajności, ale bądź optymistą w projektowaniu interfejsu i mądrze wykorzystuj czas bezczynności (sprawdź idlize, idle-do-pilny i reaguj-idle). Oczywiście te cele dotyczą wydajności środowiska wykonawczego, a nie wydajności ładowania.
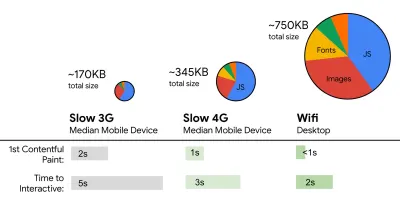
- FID < 100 ms, LCP < 2,5 s, TTI < 5 s w sieci 3G, budżet krytycznego rozmiaru pliku < 170 KB (skompresowany w formacie gzip).
Chociaż może to być bardzo trudne do osiągnięcia, dobrym ostatecznym celem byłby czas na interaktywność poniżej 5 roku życia, a w przypadku powtórnych wizyt dążyć do wieku poniżej 2 lat (osiągalne tylko z pracownikiem serwisu). Dąż do uzyskania największej zawartości farby w czasie poniżej 2,5 s i zminimalizuj łączny czas blokowania oraz skumulowaną zmianę układu . Akceptowalne opóźnienie pierwszego wejścia wynosi poniżej 100ms-70ms. Jak wspomniano powyżej, rozważamy jako podstawę telefon z Androidem za 200 USD (np. Moto G4) w wolnej sieci 3G, emulowany przy 400 ms RTT i prędkości transferu 400 kb/s.Mamy dwa główne ograniczenia, które skutecznie kształtują rozsądny cel szybkiego dostarczania treści w sieci. Z jednej strony mamy ograniczenia dostarczania sieci ze względu na powolny start TCP. Pierwsze 14 KB kodu HTML — 10 pakietów TCP, każdy 1460 bajtów, co daje około 14,25 KB, choć nie należy brać dosłownie — jest najbardziej krytycznym fragmentem ładunku i jedyną częścią budżetu, którą można dostarczyć w pierwszej podróży w obie strony ( to wszystko, co otrzymujesz w ciągu 1 sekundy przy 400 ms RTT ze względu na mobilne czasy budzenia).

W przypadku połączeń TCP zaczynamy od małego okna przeciążenia i podwajamy je dla każdej podróży w obie strony. W pierwszej turze możemy zmieścić 14 KB. Od: High Performance Browser Networking autorstwa Ilyi Grigorik. (duży podgląd) ( Uwaga : ponieważ TCP generalnie w znacznym stopniu nie wykorzystuje połączenia sieciowego, Google opracowało przepustowość wąskich gardeł i RRT ( BBR ), algorytm kontroli przepływu TCP sterowany opóźnieniami TCP. Zaprojektowany dla nowoczesnej sieci, reaguje na rzeczywiste przeciążenie, zamiast utraty pakietów, jak to robi TCP, jest znacznie szybszy, ma wyższą przepustowość i mniejsze opóźnienia — a algorytm działa inaczej ( dzięki, Victor, Barry! )
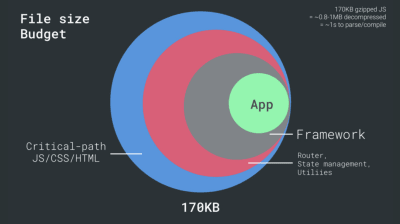
Z drugiej strony mamy ograniczenia sprzętowe dotyczące pamięci i procesora ze względu na czasy parsowania i wykonania JavaScript (omówimy je szczegółowo później). Aby osiągnąć cele określone w pierwszym akapicie, musimy wziąć pod uwagę budżet krytycznego rozmiaru pliku dla JavaScript. Opinie na temat tego, jaki powinien być ten budżet, są różne (i zależy to w dużej mierze od charakteru twojego projektu), ale budżet 170KB już spakowany JavaScript zajmie do 1s, aby przeanalizować i skompilować na telefonie średniej klasy. Zakładając, że 170 KB rozszerza się do 3 razy po dekompresji (0,7 MB), może to już oznaczać śmierć dla „przyzwoitego” doświadczenia użytkownika w Moto G4/G5 Plus.
W przypadku witryny Wikipedii w 2020 r. globalnie wykonanie kodu dla użytkowników Wikipedii przyspieszyło o 19%. Tak więc, jeśli Twoje metryki wydajności sieci z roku na rok pozostają stabilne, jest to zwykle sygnał ostrzegawczy, ponieważ faktycznie cofasz się w miarę poprawy środowiska (szczegóły w poście na blogu autorstwa Gillesa Dubuca).
Jeśli chcesz dotrzeć do rozwijających się rynków, takich jak Azja Południowo-Wschodnia, Afryka czy Indie, będziesz musiał przyjrzeć się zupełnie innym ograniczeniom. Addy Osmani obejmuje główne ograniczenia funkcji telefonu, takie jak kilka tanich, wysokiej jakości urządzeń, niedostępność sieci wysokiej jakości i drogie dane mobilne — wraz z budżetem PRPL-30 i wytycznymi dotyczącymi rozwoju dla tych środowisk.
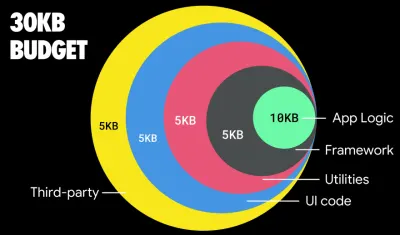
Według Addy'ego Osmaniego zalecany rozmiar dla tras z leniwym obciążeniem również wynosi mniej niż 35 KB. (duży podgląd) 
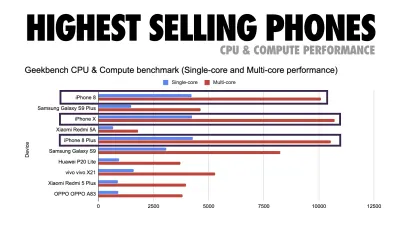
Addy Osmani sugeruje budżet wydajności PRPL-30 (30 KB skompresowany w formacie gzip + zminimalizowany pakiet początkowy), jeśli jest kierowany na telefon z internetem. (duży podgląd) W rzeczywistości Alex Russell z Google zaleca dążenie do 130-170 KB spakowanych gzipem jako rozsądną górną granicę. W rzeczywistych scenariuszach większość produktów nie jest nawet zbliżona: średni rozmiar pakietu wynosi dziś około 452 KB, co stanowi wzrost o 53,6% w porównaniu z początkiem 2015 r. Na urządzeniu mobilnym klasy średniej odpowiada to 12–20 sekundom czasu -Do-interaktywny .
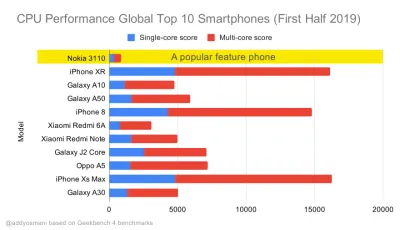
Testy wydajności procesora Geekbench dla najlepiej sprzedających się smartfonów na świecie w 2019 roku. JavaScript kładzie nacisk na wydajność jednego rdzenia (pamiętaj, że jest z natury bardziej jednowątkowy niż reszta platformy internetowej) i jest powiązany z procesorem. Z artykułu Addy'ego „Szybkie ładowanie stron internetowych na telefonie komórkowym o wartości 20 USD”. (duży podgląd) Moglibyśmy jednak wyjść poza budżet wielkości pakietu. Na przykład, moglibyśmy ustawić budżety wydajności w oparciu o działania głównego wątku przeglądarki, tj. czas malowania przed rozpoczęciem renderowania, lub wyśledzić świnie procesora front-endu. Narzędzia takie jak Calibre, SpeedCurve i Bundlesize mogą pomóc w kontrolowaniu budżetów i można je zintegrować z procesem budowania.
Wreszcie budżet zadaniowy prawdopodobnie nie powinien być wartością stałą . W zależności od połączenia sieciowego budżety wydajności powinny się dostosowywać, ale ładunek na wolniejszym połączeniu jest znacznie bardziej „drogi”, niezależnie od tego, w jaki sposób są używane.
Uwaga : ustalanie tak sztywnych budżetów może brzmieć dziwnie w czasach powszechnego HTTP/2, nadchodzącego 5G i HTTP/3, szybko rozwijających się telefonów komórkowych i kwitnących SPA. Jednak brzmią rozsądnie, gdy mamy do czynienia z nieprzewidywalną naturą sieci i sprzętu, w tym wszystkiego, od przeciążonych sieci, przez powoli rozwijającą się infrastrukturę, po limity danych, przeglądarki proxy, tryb zapisywania danych i podstępne opłaty roamingowe.
Definiowanie środowiska
- Wybierz i skonfiguruj swoje narzędzia do budowania.
Nie zwracaj zbytniej uwagi na to, co w dzisiejszych czasach podobno jest fajne. Trzymaj się swojego środowiska do budowania, czy to Grunt, Gulp, Webpack, Parcel, czy kombinację narzędzi. Dopóki uzyskujesz wyniki, których potrzebujesz i nie masz problemów z utrzymaniem procesu budowania, radzisz sobie dobrze.Wśród narzędzi do kompilacji Rollup zyskuje na popularności, podobnie jak Snowpack, ale Webpack wydaje się być najbardziej ugruntowanym, z dosłownie setkami dostępnych wtyczek do optymalizacji rozmiaru twoich kompilacji. Uważaj na Webpack Roadmap 2021.
Jedną z najbardziej godnych uwagi strategii, która pojawiła się ostatnio, jest chunking granularny z pakietem Webpack w Next.js i Gatsby w celu zminimalizowania duplikowania kodu. Domyślnie moduły, które nie są współużytkowane w każdym punkcie wejścia, można żądać dla tras, które z niego nie korzystają. To kończy się obciążeniem, ponieważ pobieranych jest więcej kodu, niż jest to konieczne. Dzięki szczegółowemu dzieleniu fragmentów w Next.js możemy użyć pliku manifestu kompilacji po stronie serwera, aby określić, które wyjściowe fragmenty są używane przez różne punkty wejścia.
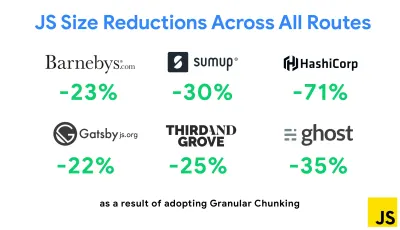
Aby zredukować zduplikowany kod w projektach Webpack, możemy użyć granularnego chunkingu, domyślnie włączonej w Next.js i Gatsby. Źródło obrazu: Addy Osmani. (duży podgląd) Dzięki SplitChunksPlugin wiele podzielonych porcji jest tworzonych w zależności od wielu warunków, aby zapobiec pobieraniu zduplikowanego kodu na wielu trasach. Poprawia to czas ładowania strony i pamięć podręczną podczas nawigacji. Dostarczane w Next.js 9.2 i Gatsby v2.20.7.
Rozpoczęcie korzystania z Webpack może być jednak trudne. Więc jeśli chcesz zagłębić się w Webpack, istnieje kilka świetnych zasobów:
- Dokumentacja Webpack — oczywiście — jest dobrym punktem wyjścia, podobnie jak Webpack — The Confusing Bits autorstwa Raja Rao i An Annotated Webpack Config autorstwa Andrew Welcha.
- Sean Larkin ma darmowy kurs na Webpack: The Core Concepts, a Jeffrey Way wydał fantastyczny darmowy kurs na Webpack dla każdego. Oba są świetnym wprowadzeniem do zanurzenia się w Webpack.
- Webpack Fundamentals to bardzo obszerny 4-godzinny kurs z Seanem Larkinem, wydany przez FrontendMasters.
- Przykładowe pakiety Webpack zawierają setki gotowych do użycia konfiguracji Webpacków, podzielonych na kategorie według tematu i celu. Bonus: istnieje również konfigurator konfiguracji Webpack, który generuje podstawowy plik konfiguracyjny.
- awesome-webpack to wyselekcjonowana lista przydatnych zasobów, bibliotek i narzędzi Webpack, w tym artykułów, filmów, kursów, książek i przykładów dla projektów Angular, React i framework-agnostic.
- Podróż do szybkiego budowania zasobów produkcyjnych za pomocą Webpack to studium przypadku Etsy dotyczące tego, jak zespół przeszedł z systemu kompilacji JavaScript opartego na RequireJS na korzystanie z Webpack i jak zoptymalizował swoje kompilacje, zarządzając ponad 13 200 zasobami średnio w 4 minuty .
- Wskazówki dotyczące wydajności pakietu Webpack to wątek kopalni złota autorstwa Ivana Akulova, zawierający wiele wskazówek dotyczących wydajności, w tym te dotyczące konkretnie pakietu Webpack.
- awesome-webpack-perf to repozytorium Goldmine GitHub z przydatnymi narzędziami Webpack i wtyczkami zwiększającymi wydajność. Utrzymywany również przez Ivana Akulova.
- Użyj domyślnie stopniowego ulepszania.
Mimo to, po tylu latach, utrzymanie progresywnego ulepszania jako naczelnej zasady architektury front-endu i wdrożenia jest bezpiecznym zakładem. Najpierw zaprojektuj i zbuduj podstawowe środowisko, a następnie ulepsz środowisko za pomocą zaawansowanych funkcji dla wydajnych przeglądarek, tworząc elastyczne środowiska. Jeśli Twoja witryna działa szybko na wolnym komputerze ze słabym ekranem w słabej przeglądarce w nieoptymalnej sieci, będzie działać szybciej tylko na szybkim komputerze z dobrą przeglądarką w przyzwoitej sieci.W rzeczywistości, z obsługą modułów adaptacyjnych, wydaje się, że przenosimy progresywne ulepszanie na wyższy poziom, udostępniając „lite” podstawowe doświadczenia urządzeniom z niższej półki i ulepszając je bardziej wyrafinowanymi funkcjami dla urządzeń z wyższej półki. Progresywne ulepszanie prawdopodobnie nie zniknie w najbliższym czasie.
- Wybierz solidną podstawę wydajności.
Przy tak wielu niewiadomych wpływających na ładowanie — sieć, ograniczanie temperatury, wyrzucanie pamięci podręcznej, skrypty innych firm, wzorce blokowania parsera, we/wy dysku, opóźnienia IPC, zainstalowane rozszerzenia, oprogramowanie antywirusowe i zapory, zadania procesora w tle, ograniczenia sprzętowe i pamięciowe, różnice w buforowaniu L2/L3, RTTS — JavaScript jest najbardziej kosztowny, obok czcionek internetowych domyślnie blokujących renderowanie i obrazów często zużywających zbyt dużo pamięci. Ponieważ wąskie gardła wydajności przesuwają się z serwera na klienta, jako programiści, musimy rozważyć wszystkie te niewiadome bardziej szczegółowo.Mając budżet 170KB, który zawiera już ścieżkę krytyczną HTML/CSS/JavaScript, router, zarządzanie stanem, narzędzia, framework i logikę aplikacji, musimy dokładnie zbadać koszt transferu sieciowego, czas parsowania/kompilacji i koszt środowiska wykonawczego wybranych przez nas ram. Na szczęście w ciągu ostatnich kilku lat zauważyliśmy ogromną poprawę szybkości analizowania i kompilowania skryptów przez przeglądarki. Jednak wykonanie JavaScript jest nadal głównym wąskim gardłem, więc zwracanie szczególnej uwagi na czas wykonania skryptu i sieć może mieć wpływ.
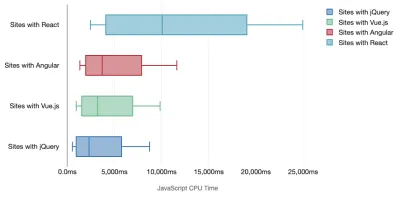
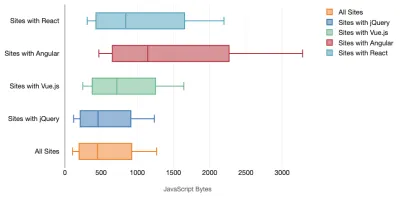
Tim Kadlec przeprowadził fantastyczne badania wydajności nowoczesnych frameworków i podsumował je w artykule „Struktury JavaScript mają swój koszt”. Często mówimy o wpływie samodzielnych frameworków, ale jak zauważa Tim, w praktyce często używa się wielu frameworków . Być może starsza wersja jQuery, która jest powoli migrowana do nowoczesnego frameworka, wraz z kilkoma starszymi aplikacjami korzystającymi ze starszej wersji Angulara. Dlatego bardziej rozsądne jest zbadanie skumulowanego kosztu bajtów JavaScript i czasu wykonywania procesora, które mogą łatwo sprawić, że doświadczenia użytkownika będą ledwo użyteczne, nawet na urządzeniach z najwyższej półki.
Ogólnie rzecz biorąc, nowoczesne struktury nie traktują priorytetowo mniej wydajnych urządzeń , więc wrażenia na telefonie i na komputerze często będą się znacznie różnić pod względem wydajności. Według badań strony z Reactem lub Angularem spędzają więcej czasu na procesorze niż inne (co oczywiście niekoniecznie oznacza, że React jest droższy na procesorze niż Vue.js).
Według Tima jedna rzecz jest oczywista: „jeśli używasz frameworka do budowy swojej witryny, dokonujesz kompromisu pod względem początkowej wydajności — nawet w najlepszym scenariuszu”.
- Oceń frameworki i zależności.
Teraz nie każdy projekt potrzebuje frameworka i nie każda strona jednostronicowej aplikacji musi załadować framework. W przypadku Netflix „usunięcie Reacta, kilku bibliotek i odpowiedniego kodu aplikacji po stronie klienta zmniejszyło całkowitą ilość JavaScriptu o ponad 200 KB, powodując ponad 50% skrócenie czasu interakcji Netflix dla wylogowanej strony głównej ”. Następnie zespół wykorzystał czas spędzony przez użytkowników na stronie docelowej, aby wstępnie pobrać React dla kolejnych stron, na które użytkownicy prawdopodobnie trafią (szczegóły znajdziesz w dalszej części).A co, jeśli całkowicie usuniesz istniejący framework na krytycznych stronach? Dzięki Gatsby możesz sprawdzić gatsby-plugin-no-javascript, który usuwa wszystkie pliki JavaScript utworzone przez Gatsby ze statycznych plików HTML. W Vercel możesz także zezwolić na wyłączenie produkcyjnego JavaScriptu w czasie wykonywania dla niektórych stron (eksperymentalnie).
Po wybraniu frameworka pozostaniemy przy nim przez co najmniej kilka lat, więc jeśli musimy go użyć, musimy upewnić się, że nasz wybór jest świadomy i dobrze przemyślany — dotyczy to zwłaszcza kluczowych wskaźników wydajności, które troszczyć się o.
Dane pokazują, że domyślnie frameworki są dość drogie: 58,6% stron React dostarcza ponad 1 MB JavaScript, a 36% załadowanych stron Vue.js ma pierwsze wyrenderowanie treści trwające <1,5 s. Według badania przeprowadzonego przez Ankur Sethi „Twoja aplikacja React nigdy nie ładuje się szybciej niż około 1,1 sekundy na przeciętnym telefonie w Indiach, bez względu na to, jak bardzo ją zoptymalizujesz. Twoja aplikacja Angular zawsze będzie się uruchamiać co najmniej 2,7 sekundy. użytkownicy Twojej aplikacji Vue będą musieli poczekać co najmniej 1 sekundę, zanim będą mogli zacząć z niej korzystać”. Być może nie kierujesz reklam na Indie jako rynek podstawowy, ale użytkownicy uzyskujący dostęp do Twojej witryny o nieoptymalnych warunkach sieciowych będą mieli porównywalne wrażenia.
Oczywiście możliwe jest szybkie tworzenie SPA, ale nie są one szybkie po wyjęciu z pudełka, więc musimy wziąć pod uwagę czas i wysiłek potrzebny do ich wykonania i utrzymania . Prawdopodobnie będzie łatwiej, wybierając na wczesnym etapie lekki podstawowy koszt wydajności.
Jak więc wybrać framework ? Dobrym pomysłem jest rozważenie przynajmniej całkowitego kosztu rozmiaru + początkowego czasu realizacji przed wyborem opcji; lekkie opcje, takie jak Preact, Inferno, Vue, Svelte, Alpine lub Polymer, mogą dobrze wykonać zadanie. Rozmiar linii bazowej zdefiniuje ograniczenia dla kodu aplikacji.
Jak zauważył Seb Markbage, dobrym sposobem na zmierzenie kosztów uruchomienia frameworków jest najpierw wyrenderowanie widoku, a następnie usunięcie go i ponowne renderowanie, ponieważ może on powiedzieć, jak skaluje się framework. Pierwsze renderowanie ma tendencję do rozgrzewania sporej ilości leniwie skompilowanego kodu, z którego może skorzystać większe drzewo, gdy się skaluje. Drugie renderowanie jest w zasadzie emulacją tego, jak ponowne użycie kodu na stronie wpływa na charakterystykę wydajności w miarę wzrostu złożoności strony.
Możesz posunąć się nawet do oceny swoich kandydatów (lub ogólnie dowolnej biblioteki JavaScript) w 12-punktowym systemie punktacji Sacha Greif, badając funkcje, dostępność, stabilność, wydajność, ekosystem pakietów , społeczność, krzywą uczenia się, dokumentację, oprzyrządowanie, osiągnięcia , zespół, kompatybilność, np. bezpieczeństwo.
Perf Track śledzi wydajność struktury na dużą skalę. (duży podgląd) Możesz również polegać na danych gromadzonych w sieci przez dłuższy czas. Na przykład, Perf Track śledzi wydajność platformy na dużą skalę, pokazując zagregowane wyniki Core Web Vitals dla witryn zbudowanych w Angular, React, Vue, Polymer, Preact, Ember, Svelte i AMP. Możesz nawet określić i porównać strony internetowe zbudowane za pomocą Gatsby, Next.js lub Create React App, a także strony zbudowane za pomocą Nuxt.js (Vue) lub Sapper (Svelte).
Dobrym punktem wyjścia jest wybór dobrego domyślnego stosu dla twojej aplikacji. Gatsby (React), Next.js (React), Vuepress (Vue), Preact CLI i PWA Starter Kit zapewniają rozsądne ustawienia domyślne do szybkiego ładowania po wyjęciu z pudełka na przeciętnym sprzęcie mobilnym. Również spójrz na wytyczne dotyczące wydajności dla frameworków web.dev dla React i Angular ( dzięki, Phillip! ).
I być może mógłbyś przyjąć nieco bardziej odświeżające podejście do tworzenia aplikacji jednostronicowych — Turbolinks, 15-KB biblioteka JavaScript, która używa HTML zamiast JSON do renderowania widoków. Tak więc, gdy podążasz za linkiem, Turbolinks automatycznie pobiera stronę, zamienia
<body>i łączy<head>, a wszystko to bez ponoszenia kosztów pełnego załadowania strony. Możesz sprawdzić szybkie szczegóły i pełną dokumentację dotyczącą stosu (Hotwire).
- Renderowanie po stronie klienta czy renderowanie po stronie serwera? Obie!
To dość gorąca rozmowa. Ostatecznym podejściem byłoby skonfigurowanie pewnego rodzaju progresywnego uruchamiania: użyj renderowania po stronie serwera, aby uzyskać szybkie pierwsze wyrenderowanie treści, ale także dodaj trochę niezbędnego JavaScript, aby utrzymać czas do interakcji bliski Pierwszemu wyrenderowaniu treści. Jeśli JavaScript pojawi się zbyt późno po FCP, przeglądarka zablokuje główny wątek podczas analizowania, kompilowania i wykonywania późno odkrytego JavaScriptu, ograniczając w ten sposób interaktywność witryny lub aplikacji.Aby tego uniknąć, zawsze dziel wykonywanie funkcji na oddzielne, asynchroniczne zadania i tam, gdzie to możliwe, używaj
requestIdleCallback. Rozważ leniwe ładowanie części interfejsu użytkownika za pomocą dynamicznej obsługiimport()w WebPack, unikając obciążenia, analizowania i kompilowania kosztów, dopóki użytkownicy naprawdę ich nie potrzebują ( dzięki Addy! ).Jak wspomniano powyżej, Time to Interactive (TTI) informuje nas o czasie między nawigacją a interaktywnością. W szczegółach metryka jest definiowana przez spojrzenie na pierwsze pięciosekundowe okno po wyrenderowaniu początkowej zawartości, w którym żadne zadania JavaScript nie trwają dłużej niż 50 ms ( Long Tasks ). Jeśli wystąpi zadanie trwające ponad 50 ms, wyszukiwanie pięciosekundowego okna rozpoczyna się od nowa. W rezultacie przeglądarka najpierw założy, że dotarła do Interactive , tylko po to, by przełączyć się na Frozen , by ostatecznie przełączyć się z powrotem na Interactive .
Gdy dotarliśmy do Interactive , możemy — na żądanie lub w miarę czasu — uruchomić mniej istotne części aplikacji. Niestety, jak zauważył Paul Lewis, frameworki zazwyczaj nie mają prostego pojęcia priorytetu, który można przedstawić programistom, a zatem progresywne uruchamianie nie jest łatwe do zaimplementowania w większości bibliotek i frameworków.
A jednak do tego dochodzimy. Obecnie istnieje kilka możliwości, które możemy zbadać, a Houssein Djirdeh i Jason Miller zapewniają doskonały przegląd tych opcji w swoim przemówieniu na temat Renderowania w sieci oraz w artykule Jasona i Addy'ego na temat nowoczesnych architektur frontonu. Poniższy przegląd opiera się na ich gwiezdnej pracy.
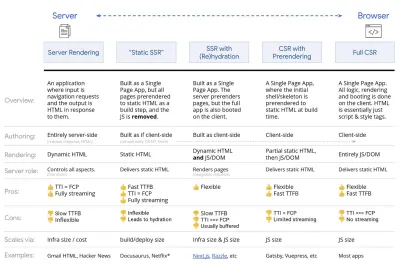
- Pełne renderowanie po stronie serwera (SSR)
W klasycznym SSR, takim jak WordPress, wszystkie żądania są obsługiwane w całości na serwerze. Żądana treść jest zwracana jako gotowa strona HTML, a przeglądarki mogą ją od razu renderować. W związku z tym aplikacje SSR nie mogą tak naprawdę korzystać na przykład z interfejsów API DOM. Różnica między First Contentful Paint a Time to Interactive jest zwykle niewielka, a strona może być renderowana od razu, gdy HTML jest przesyłany strumieniowo do przeglądarki.Pozwala to uniknąć dodatkowych podróży w obie strony w celu pobierania danych i tworzenia szablonów na kliencie, ponieważ jest to obsługiwane, zanim przeglądarka otrzyma odpowiedź. Jednak kończy się to dłuższym czasem myślenia serwera, a co za tym idzie Time To First Byte i nie korzystamy z responsywnych i bogatych funkcji nowoczesnych aplikacji.
- Renderowanie statyczne
Tworzymy produkt jako aplikację jednostronicową, ale wszystkie strony są wstępnie renderowane do statycznego kodu HTML z minimalnym kodem JavaScript jako etapem tworzenia. Oznacza to, że przy statycznym renderowaniu tworzymy z wyprzedzeniem indywidualne pliki HTML dla każdego możliwego adresu URL , na co nie może sobie pozwolić wiele aplikacji. Ale ponieważ kod HTML strony nie musi być generowany w locie, możemy osiągnąć niezmiennie szybki czas do pierwszego bajtu. W ten sposób możemy szybko wyświetlić stronę docelową, a następnie wstępnie pobrać szkielet SPA dla kolejnych stron. Netflix zastosował to podejście, zmniejszając ładowanie i czas do interakcji o 50%. - Renderowanie po stronie serwera z (re)hydratacją (renderowanie uniwersalne, SSR + CSR)
Możemy spróbować wykorzystać to, co najlepsze z obu światów — podejścia SSR i CSR. Z uwodnieniem w mieszance, strona HTML zwrócona z serwera zawiera również skrypt, który ładuje w pełni rozwiniętą aplikację po stronie klienta. Idealnie, aby osiągnąć szybkie pierwsze wyrenderowanie treści (takie jak SSR), a następnie kontynuować renderowanie z (ponownym) nawodnieniem. Niestety rzadko tak się dzieje. Częściej strona wygląda na gotową, ale nie odpowiada na wpisy użytkownika, powodując wściekłość i porzucenia.Dzięki React możemy użyć modułu
ReactDOMServerna serwerze Node, takim jak Express, a następnie wywołać metodęrenderToString, aby wyrenderować komponenty najwyższego poziomu jako statyczny ciąg HTML.Dzięki Vue.js możemy użyć vue-server-renderer do renderowania instancji Vue do HTML za pomocą
renderToString. W Angularze możemy użyć@nguniversaldo przekształcenia żądań klienta w strony HTML w pełni renderowane przez serwer. W pełni renderowane na serwerze doświadczenie można również uzyskać po wyjęciu z pudełka za pomocą Next.js (React) lub Nuxt.js (Vue).To podejście ma swoje wady. W rezultacie zyskujemy pełną elastyczność aplikacji po stronie klienta, zapewniając jednocześnie szybsze renderowanie po stronie serwera, ale kończy się to również dłuższą przerwą między First Contentful Paint i Time To Interactive oraz zwiększonym opóźnieniem pierwszego wejścia. Nawodnienie jest bardzo drogie i zwykle sama ta strategia nie wystarczy, ponieważ znacznie opóźnia Time To Interactive.
- Renderowanie strumieniowe po stronie serwera z progresywnym nawodnieniem (SSR + CSR)
Aby zminimalizować lukę między Time To Interactive a First Contentful Paint, renderujemy wiele żądań jednocześnie i wysyłamy zawartość porcjami w miarę ich generowania. Nie musimy więc czekać na pełny ciąg kodu HTML przed wysłaniem treści do przeglądarki, a tym samym ulepszamy Time To First Byte.W React, zamiast
renderToString(), możemy użyć renderToNodeStream() do potoku odpowiedzi i wysłania kodu HTML w kawałkach. W Vue możemy użyć renderToStream(), które można przesyłać potokowo i przesyłać strumieniowo. Dzięki React Suspense możemy również w tym celu użyć renderowania asynchronicznego.Po stronie klienta, zamiast uruchamiać całą aplikację naraz, uruchamiamy komponenty stopniowo . Sekcje aplikacji są najpierw dzielone na samodzielne skrypty z podziałem kodu, a następnie stopniowo uwadniane (w kolejności naszych priorytetów). W rzeczywistości możemy najpierw nawodnić kluczowe składniki, podczas gdy resztę można nawodnić później. Rolę renderowania po stronie klienta i po stronie serwera można następnie zdefiniować w różny sposób dla poszczególnych komponentów. Możemy wtedy również odroczyć uwodnienie niektórych komponentów, dopóki nie pojawią się one w widoku lub będą potrzebne do interakcji użytkownika lub gdy przeglądarka jest bezczynna.
Dla Vue Markus Oberlehner opublikował przewodnik na temat skrócenia Time To Interactive aplikacji SSR za pomocą uwodnienia interakcji użytkownika, a także vue-lazy-hydration, wtyczki na wczesnym etapie, która umożliwia uwodnienie komponentów w przypadku widoczności lub określonej interakcji użytkownika. Zespół Angular pracuje nad progresywnym nawodnieniem z Ivy Universal. Częściowe nawodnienie można również wdrożyć za pomocą Preact i Next.js.
- Renderowanie trizomorficzne
Mając wdrożone procesy robocze, możemy użyć renderowania serwera przesyłania strumieniowego dla nawigacji początkowych/nie JS, a następnie, po zainstalowaniu, pracownik usługowy zajmie się renderowaniem kodu HTML dla nawigacji. W takim przypadku Service Worker wstępnie renderuje zawartość i włącza nawigacje w stylu SPA w celu renderowania nowych widoków w tej samej sesji. Działa dobrze, gdy możesz współużytkować ten sam kod szablonów i routingu między serwerem, stroną klienta i procesem Service Worker.
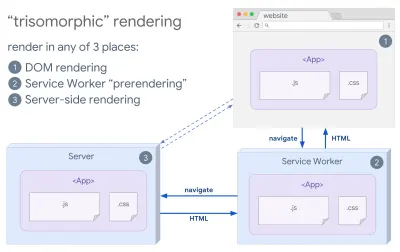
Renderowanie trizomorficzne, z tym samym renderowaniem kodu w dowolnych 3 miejscach: na serwerze, w DOM lub w service workerze. (źródło obrazu: Google Developers) (duży podgląd) - CSR z prerenderowaniem
Wstępne renderowanie jest podobne do renderowania po stronie serwera, ale zamiast dynamicznie renderować strony na serwerze, renderujemy aplikację do statycznego kodu HTML w czasie kompilacji. Chociaż strony statyczne są w pełni interaktywne i nie zawierają dużo kodu JavaScript po stronie klienta, wstępne renderowanie działa inaczej . Zasadniczo przechwytuje początkowy stan aplikacji po stronie klienta jako statyczny HTML w czasie kompilacji, podczas gdy z prerenderowaniem aplikacja musi zostać uruchomiona na kliencie, aby strony były interaktywne.Dzięki Next.js możemy użyć statycznego eksportu HTML, wstępnie renderując aplikację do statycznego HTML. W Gatsby, generatorze witryn statycznych typu open source, który korzysta z React, podczas kompilacji używa metody
renderToStaticMarkupzamiast metodyrenderToString, przy czym główny fragment JS jest wstępnie ładowany, a przyszłe trasy są wstępnie pobierane, bez atrybutów DOM, które nie są potrzebne w przypadku prostych stron statycznych.W przypadku Vue możemy wykorzystać Vuepress do osiągnięcia tego samego celu. Możesz także użyć prerender-loadera z Webpackiem. Navi zapewnia również renderowanie statyczne.
Rezultatem jest lepsze wyrenderowanie czasu do pierwszego bajtu i pierwsze wyrenderowanie treści, a także zmniejszamy lukę między wyrenderowaniem czasu do interaktywnego a pierwszym wyrenderowaniem treści. Nie możemy zastosować tego podejścia, jeśli oczekuje się, że zawartość zmieni się znacznie. Ponadto wszystkie adresy URL muszą być znane z wyprzedzeniem, aby wygenerować wszystkie strony. Tak więc niektóre komponenty mogą być renderowane za pomocą renderowania wstępnego, ale jeśli potrzebujemy czegoś dynamicznego, musimy polegać na aplikacji, aby pobrać zawartość.
- Pełne renderowanie po stronie klienta (CSR)
Cała logika, renderowanie i uruchamianie są wykonywane na kliencie. Rezultatem jest zwykle ogromna luka między Time To Interactive a First Contentful Paint. W rezultacie aplikacje często działają wolno, ponieważ cała aplikacja musi zostać uruchomiona na kliencie, aby cokolwiek renderować.Ponieważ JavaScript wiąże się z kosztami wydajności, wraz ze wzrostem ilości JavaScriptu wraz z aplikacją, agresywne dzielenie kodu i odkładanie kodu JavaScript będzie absolutnie konieczne, aby okiełznać wpływ JavaScriptu. W takich przypadkach renderowanie po stronie serwera jest zwykle lepszym podejściem, jeśli nie jest wymagana duża interaktywność. Jeśli nie jest to możliwe, rozważ użycie modelu powłoki aplikacji.
Ogólnie rzecz biorąc, SSR jest szybszy niż CSR. Jednak nadal jest to dość częsta implementacja dla wielu aplikacji.
A więc po stronie klienta czy po stronie serwera? Ogólnie rzecz biorąc, dobrym pomysłem jest ograniczenie korzystania z frameworków w pełni po stronie klienta do stron, które absolutnie ich wymagają. W przypadku zaawansowanych aplikacji nie jest dobrym pomysłem poleganie wyłącznie na renderowaniu po stronie serwera. Zarówno renderowanie przez serwer, jak i renderowanie przez klienta jest katastrofą, jeśli zostanie wykonane źle.
Niezależnie od tego, czy skłaniasz się ku CSR, czy SSR, upewnij się, że renderujesz ważne piksele tak szybko, jak to możliwe i minimalizuj lukę między tym renderowaniem a Time To Interactive. Rozważ wstępne renderowanie, jeśli Twoje strony nie zmieniają się zbytnio, i opóźnij uruchamianie frameworków, jeśli możesz. Przesyłaj strumieniowo HTML w kawałkach z renderowaniem po stronie serwera i wdrażaj progresywne nawadnianie renderowania po stronie klienta — i koncentruj się na widoczności, interakcji lub w czasie bezczynności, aby uzyskać to, co najlepsze z obu światów.
- Pełne renderowanie po stronie serwera (SSR)

- Ile możemy podać statycznie?
Niezależnie od tego, czy pracujesz nad dużą aplikacją, czy małą witryną, warto zastanowić się, jaka zawartość może być serwowana statycznie z CDN (tj. JAM Stack), a nie generowana dynamicznie w locie. Nawet jeśli masz tysiące produktów i setki filtrów z mnóstwem opcji personalizacji, nadal możesz chcieć wyświetlać krytyczne strony docelowe w sposób statyczny i oddzielić te strony od wybranych przez siebie ram.Istnieje wiele generatorów witryn statycznych, a generowane przez nie strony są często bardzo szybkie. The more content we can pre-build ahead of time instead of generating page views on a server or client at request time, the better performance we will achieve.
In Building Partially Hydrated, Progressively Enhanced Static Websites, Markus Oberlehner shows how to build out websites with a static site generator and an SPA, while achieving progressive enhancement and a minimal JavaScript bundle size. Markus uses Eleventy and Preact as his tools, and shows how to set up the tools, add partial hydration, lazy hydration, client entry file, configure Babel for Preact and bundle Preact with Rollup — from start to finish.
With JAMStack used on large sites these days, a new performance consideration appeared: the build time . In fact, building out even thousands of pages with every new deploy can take minutes, so it's promising to see incremental builds in Gatsby which improve build times by 60 times , with an integration into popular CMS solutions like WordPress, Contentful, Drupal, Netlify CMS and others.
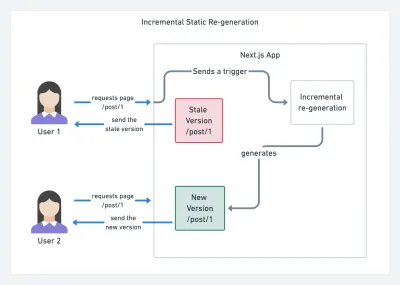
Incremental static regeneration with Next.js. (Image credit: Prisma.io) (Large preview) Also, Next.js announced ahead-of-time and incremental static generation, which allows us to add new static pages at runtime and update existing pages after they've been already built, by re-rendering them in the background as traffic comes in.
Need an even more lightweight approach? In his talk on Eleventy, Alpine and Tailwind: towards a lightweight Jamstack, Nicola Goutay explains the differences between CSR, SSR and everything-in-between, and shows how to use a more lightweight approach — along with a GitHub repo that shows the approach in practice.
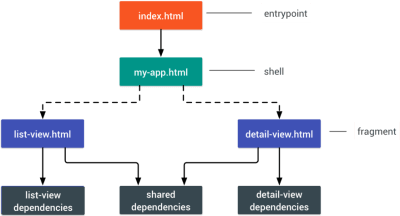
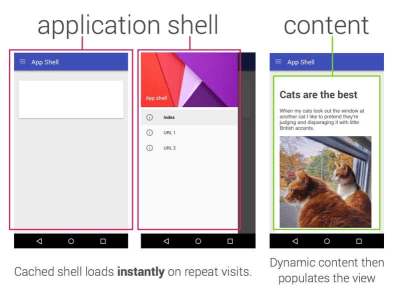
- Consider using PRPL pattern and app shell architecture.
Different frameworks will have different effects on performance and will require different strategies of optimization, so you have to clearly understand all of the nuts and bolts of the framework you'll be relying on. When building a web app, look into the PRPL pattern and application shell architecture. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
- Have you optimized the performance of your APIs?
APIs are communication channels for an application to expose data to internal and third-party applications via endpoints . When designing and building an API, we need a reasonable protocol to enable the communication between the server and third-party requests. Representational State Transfer ( REST ) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion. Web services that conform to the REST constraints, are called RESTful web services .As with good ol' HTTP requests, when data is retrieved from an API, any delay in server response will propagate to the end user, hence delaying rendering . When a resource wants to retrieve some data from an API, it will need to request the data from the corresponding endpoint. A component that renders data from several resources, such as an article with comments and author photos in each comment, may need several roundtrips to the server to fetch all the data before it can be rendered. Furthermore, the amount of data returned through REST is often more than what is needed to render that component.
If many resources require data from an API, the API might become a performance bottleneck. GraphQL provides a performant solution to these issues. Per se, GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. Unlike REST, GraphQL can retrieve all data in a single request , and the response will be exactly what is required, without over or under -fetching data as it typically happens with REST.
In addition, because GraphQL is using schema (metadata that tells how the data is structured), it can already organize data into the preferred structure, so, for example, with GraphQL, we could remove JavaScript code used for dealing with state management, producing a cleaner application code that runs faster on the client.
If you want to get started with GraphQL or encounter performance issues, these articles might be quite helpful:
- A GraphQL Primer: Why We Need A New Kind Of API by Eric Baer,
- A GraphQL Primer: The Evolution Of API Design by Eric Baer,
- Designing a GraphQL server for optimal performance by Leonardo Losoviz,
- GraphQL performance explained by Wojciech Trocki.
- Will you be using AMP or Instant Articles?
Depending on the priorities and strategy of your organization, you might want to consider using Google's AMP or Facebook's Instant Articles or Apple's Apple News. You can achieve good performance without them, but AMP does provide a solid performance framework with a free content delivery network (CDN), while Instant Articles will boost your visibility and performance on Facebook.The seemingly obvious benefit of these technologies for users is guaranteed performance , so at times they might even prefer AMP-/Apple News/Instant Pages-links over "regular" and potentially bloated pages. For content-heavy websites that are dealing with a lot of third-party content, these options could potentially help speed up render times dramatically.
Unless they don't. According to Tim Kadlec, for example, "AMP documents tend to be faster than their counterparts, but they don't necessarily mean a page is performant. AMP is not what makes the biggest difference from a performance perspective."
A benefit for the website owner is obvious: discoverability of these formats on their respective platforms and increased visibility in search engines.
Well, at least that's how it used to be. As AMP is no longer a requirement for Top Stories , publishers might be moving away from AMP to a traditional stack instead ( thanks, Barry! ).
Still, you could build progressive web AMPs, too, by reusing AMPs as a data source for your PWA. Downside? Obviously, a presence in a walled garden places developers in a position to produce and maintain a separate version of their content, and in case of Instant Articles and Apple News without actual URLs (thanks Addy, Jeremy!) .
- Choose your CDN wisely.
As mentioned above, depending on how much dynamic data you have, you might be able to "outsource" some part of the content to a static site generator, pushing it to a CDN and serving a static version from it, thus avoiding requests to the server. In fact, some of those generators are actually website compilers with many automated optimizations provided out of the box. As compilers add optimizations over time, the compiled output gets smaller and faster over time.Notice that CDNs can serve (and offload) dynamic content as well. So, restricting your CDN to static assets is not necessary. Double-check whether your CDN performs compression and conversion (eg image optimization and resizing at the edge), whether they provide support for servers workers, A/B testing, as well as edge-side includes, which assemble static and dynamic parts of pages at the CDN's edge (ie the server closest to the user), and other tasks. Also, check if your CDN supports HTTP over QUIC (HTTP/3).
Katie Hempenius has written a fantastic guide to CDNs that provides insights on how to choose a good CDN , how to finetune it and all the little things to keep in mind when evaluating one. In general, it's a good idea to cache content as aggressively as possible and enable CDN performance features like Brotli, TLS 1.3, HTTP/2, and HTTP/3.
Note : based on research by Patrick Meenan and Andy Davies, HTTP/2 prioritization is effectively broken on many CDNs, so be careful when choosing a CDN. Patrick has more details in his talk on HTTP/2 Prioritization ( thanks, Barry! ).
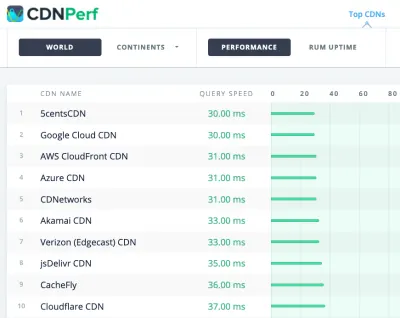
CDNPerf measures query speed for CDNs by gathering and analyzing 300 million tests every day. (duży podgląd) When choosing a CDN, you can use these comparison sites with a detailed overview of their features:
- Porównanie CDN, macierz porównania CDN dla Cloudfront, Aazure, KeyCDN, Fastly, Verizon, Stackpach, Akamai i wielu innych.
- CDN Perf mierzy szybkość zapytań dla sieci CDN, zbierając i analizując 300 milionów testów każdego dnia, a wszystkie wyniki są oparte na danych RUM od użytkowników z całego świata. Sprawdź także porównanie wydajności DNS i porównanie wydajności chmury.
- CDN Planet Guides zawiera przegląd sieci CDN dla określonych tematów, takich jak Serve Nieaktualne, Oczyszczanie, Origin Shield, Prefetch i Compression.
- Web Almanach: Adopcja i użytkowanie CDN zapewnia wgląd w najlepszych dostawców CDN, ich zarządzanie RTT i TLS, czas negocjacji TLS, adopcję HTTP/2 i inne. (Niestety dane pochodzą tylko z 2019 r.).
Optymalizacje zasobów
- Użyj Brotli do kompresji zwykłego tekstu.
W 2015 r. Google wprowadził Brotli, nowy bezstratny format danych typu open source, który jest teraz obsługiwany we wszystkich nowoczesnych przeglądarkach. Biblioteka Brotli o otwartym kodzie źródłowym, która implementuje koder i dekoder dla Brotli, ma 11 predefiniowanych poziomów jakości dla kodera, przy czym wyższy poziom jakości wymaga więcej procesora w zamian za lepszy współczynnik kompresji. Wolniejsza kompresja ostatecznie doprowadzi do wyższych współczynników kompresji, a mimo to Brotli szybko się dekompresuje. Warto jednak zauważyć, że Brotli z poziomem kompresji 4 jest zarówno mniejszy, jak i kompresuje się szybciej niż Gzip.W praktyce Brotli wydaje się być znacznie skuteczniejszy niż Gzip. Opinie i doświadczenia różnią się, ale jeśli Twoja witryna jest już zoptymalizowana za pomocą Gzip, możesz spodziewać się co najmniej jednocyfrowych ulepszeń, a w najlepszym przypadku dwucyfrowych ulepszeń w zmniejszaniu rozmiaru i taktowaniu FCP. Możesz także oszacować oszczędności w kompresji Brotli dla swojej witryny.
Przeglądarki zaakceptują Brotli tylko wtedy, gdy użytkownik odwiedza witrynę przez HTTPS. Brotli jest szeroko obsługiwany i obsługuje go wiele CDN (Akamai, Netlify Edge, AWS, KeyCDN, Fastly (obecnie tylko jako pass-through), Cloudflare, CDN77) i możesz włączyć Brotli nawet na CDN, które jeszcze go nie obsługują (z pracownikiem serwisu).
Haczyk polega na tym, że kompresja wszystkich zasobów za pomocą Brotli na wysokim poziomie kompresji jest droga, wielu dostawców hostingu nie może jej używać na pełną skalę tylko z powodu ogromnych kosztów ogólnych, jakie generuje. W rzeczywistości, na najwyższym poziomie kompresji, Brotli jest tak powolny, że każdy potencjalny wzrost rozmiaru pliku może zostać zniwelowany przez czas potrzebny serwerowi na rozpoczęcie wysyłania odpowiedzi w oczekiwaniu na dynamiczną kompresję zasobu. (Ale jeśli masz czas w czasie kompilacji z kompresją statyczną, oczywiście preferowane są wyższe ustawienia kompresji.)
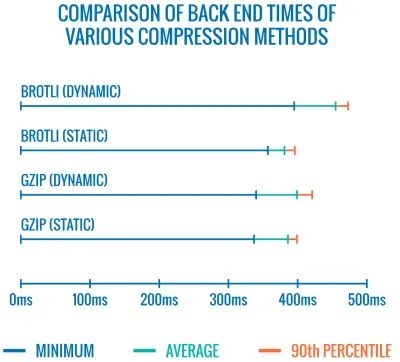
Porównanie czasów końcowych różnych metod kompresji. Nic dziwnego, że Brotli jest wolniejszy niż gzip (na razie). (duży podgląd) To może się jednak zmienić. Format pliku Brotli zawiera wbudowany słownik statyczny , a oprócz tego, że zawiera różne ciągi w wielu językach, obsługuje również opcję zastosowania wielu transformacji do tych słów, zwiększając jego wszechstronność. W swoich badaniach Felix Hanau odkrył sposób na poprawę kompresji na poziomach od 5 do 9, używając „bardziej wyspecjalizowanego podzbioru słownika niż domyślny” i polegając na nagłówku
Content-Type, który informuje kompresor, czy powinien użyć słownik HTML, JavaScript lub CSS. Rezultatem był „nieistotny wpływ na wydajność (od 1% do 3% więcej procesora w porównaniu do 12% normalnie) podczas kompresji treści internetowych na wysokim poziomie kompresji przy użyciu podejścia ograniczonego użycia słownika”.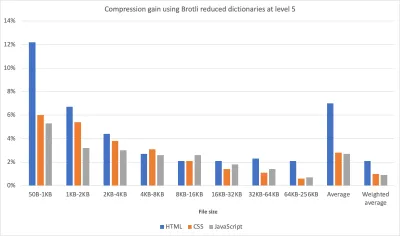
Dzięki ulepszonemu podejściu słownikowemu możemy szybciej kompresować zasoby na wyższych poziomach kompresji, a wszystko to przy użyciu tylko od 1% do 3% więcej procesora. Zwykle poziom kompresji 6 powyżej 5 zwiększa wykorzystanie procesora nawet o 12%. (duży podgląd) Co więcej, dzięki badaniom Eleny Kirilenko możemy osiągnąć szybką i wydajną dekompresję Brotli przy użyciu wcześniejszych artefaktów kompresji. Według Eleny „kiedy mamy zasób skompresowany przez Brotli i próbujemy skompresować dynamiczną zawartość w locie, gdzie zawartość przypomina zawartość dostępną dla nas z wyprzedzeniem, możemy osiągnąć znaczną poprawę czasu kompresji. "
Jak często to się dzieje? Np. z dostarczaniem podzbiorów pakunków JavaScript (np. gdy części kodu są już buforowane na kliencie lub z dynamicznym pakunkiem obsługującym za pomocą WebBundles). Lub z dynamicznym kodem HTML opartym na szablonach znanych z wyprzedzeniem lub dynamicznie podzbieranymi czcionkami WOFF2 . Według Eleny, możemy uzyskać 5,3% poprawę kompresji i 39% poprawę szybkości kompresji przy usuwaniu 10% treści oraz 3,2% lepsze współczynniki kompresji i 26% szybszą kompresję przy usuwaniu 50% treści.
Kompresja Brotli jest coraz lepsza, więc jeśli możesz ominąć koszt dynamicznej kompresji zasobów statycznych, zdecydowanie jest to warte wysiłku. Nie trzeba dodawać, że Brotli może być używany do dowolnego ładunku w postaci zwykłego tekstu — HTML, CSS, SVG, JavaScript, JSON i tak dalej.
Uwaga : od początku 2021 r. około 60% odpowiedzi HTTP jest dostarczanych bez kompresji tekstowej, 30,82% z kompresją Gzip i 9,1% z kompresją Brotli (zarówno na urządzeniach mobilnych, jak i na komputerach). Np. 23,4% stron Angulara nie jest skompresowanych (przez gzip lub Brotli). Jednak często włączenie kompresji jest jednym z najłatwiejszych sposobów na poprawę wydajności za pomocą prostego przełączenia przełącznika.
Strategia? Wstępnie skompresuj statyczne zasoby za pomocą Brotli+Gzip na najwyższym poziomie i skompresuj (dynamiczny) HTML na bieżąco za pomocą Brotli na poziomach 4–6. Upewnij się, że serwer prawidłowo obsługuje negocjacje treści dla Brotli lub Gzip.
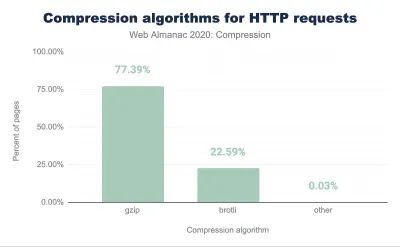
- Czy korzystamy z adaptacyjnego ładowania mediów i podpowiedzi dla klientów?
Pochodzi z krainy starych wiadomości, ale zawsze jest dobrym przypomnieniem, aby używać responsywnych obrazów zsrcset,sizesi elementem<picture>. Zwłaszcza w przypadku witryn, które zajmują dużo miejsca w mediach, możemy pójść o krok dalej dzięki adaptacyjnemu ładowaniu multimediów (w tym przykładzie React + Next.js), dostarczając lekkie wrażenia powolnym sieciom i urządzeniom o małej ilości pamięci oraz pełne doświadczenie w szybkich sieciach i wysokich -urządzenia pamięci. W kontekście Reacta możemy to osiągnąć dzięki podpowiedziom klienta na serwerze i reakcjom adaptacyjnym na kliencie.Przyszłość responsywnych obrazów może się radykalnie zmienić wraz z szerszym przyjęciem wskazówek dla klientów. Podpowiedziami klienta są pola nagłówka żądania HTTP, np.
DPR,Viewport-Width,Width,Save-Data,Accept(w celu określenia preferencji formatu obrazu) i inne. Mają za zadanie informować serwer o specyfice przeglądarki użytkownika, ekranu, połączenia itp.W rezultacie serwer może zdecydować, jak wypełnić układ obrazami o odpowiedniej wielkości i wyświetlać tylko te obrazy w żądanych formatach. Dzięki wskazówkom klienta przenosimy wybór zasobów ze znaczników HTML do negocjacji żądanie-odpowiedź między klientem a serwerem.
Adaptacyjne media służące w użyciu. Wysyłamy symbol zastępczy z tekstem do użytkowników, którzy są w trybie offline, obraz w niskiej rozdzielczości do użytkowników 2G, obraz w wysokiej rozdzielczości do użytkowników 3G i wideo HD do użytkowników 4G. Poprzez szybkie ładowanie stron internetowych na telefonie z funkcją telefonu za 20 USD. (duży podgląd) Jak zauważył Ilya Grigorik jakiś czas temu, wskazówki dla klientów uzupełniają obraz — nie są alternatywą dla responsywnych obrazów. „Element
<picture>zapewnia niezbędną kontrolę kierunku grafiki w znacznikach HTML. Wskazówki klienta zawierają adnotacje do wynikowych żądań obrazów, które umożliwiają automatyzację wyboru zasobów. Service Worker zapewnia pełne możliwości zarządzania żądaniami i odpowiedziami na kliencie”.Pracownik serwisu może na przykład dołączyć do żądania nowe wartości nagłówków wskazówek klienta , przepisać adres URL i skierować żądanie obrazu do sieci CDN, dostosować odpowiedź na podstawie łączności i preferencji użytkownika itp. Dotyczy to nie tylko zasobów graficznych, ale dla prawie wszystkich innych próśb.
W przypadku klientów, którzy obsługują wskazówki dla klientów, można zmierzyć 42% oszczędności bajtów na obrazach i 1 MB+ mniej bajtów dla 70. percentyla. W Smashing Magazine mogliśmy również zmierzyć poprawę o 19-32%. Wskazówki dla klientów są obsługiwane w przeglądarkach opartych na Chromium, ale nadal są brane pod uwagę w przeglądarce Firefox.
Jeśli jednak podasz zarówno normalne znaczniki responsywnych obrazów, jak i znacznik
<meta>dla wskazówek klienta, wówczas obsługująca przeglądarka oceni znaczniki responsywnych obrazów i zażąda odpowiedniego źródła obrazu za pomocą nagłówków HTTP Client Hints. - Czy używamy responsywnych obrazów do obrazów tła?
Na pewno powinniśmy! Dziękiimage-set, który jest teraz obsługiwany w Safari 14 i w większości nowoczesnych przeglądarek z wyjątkiem Firefox, możemy wyświetlać również responsywne obrazy tła:background-image: url("fallback.jpg"); background-image: image-set( "photo-small.jpg" 1x, "photo-large.jpg" 2x, "photo-print.jpg" 600dpi);Zasadniczo możemy warunkowo wyświetlać obrazy tła o niskiej rozdzielczości z deskryptorem
1xi obrazy o wyższej rozdzielczości z deskryptorem2x, a nawet obraz o jakości do druku z deskryptorem600dpi. Uważaj jednak: przeglądarki nie udostępniają technologii wspomagających żadnych specjalnych informacji o obrazach tła, więc najlepiej byłoby, gdyby te zdjęcia były jedynie dekoracją. - Czy używamy WebP?
Kompresja obrazu jest często uważana za szybką wygraną, ale w praktyce nadal jest w dużym stopniu wykorzystywana. Oczywiście obrazy nie blokują renderowania, ale w dużym stopniu przyczyniają się do słabych wyników LCP i bardzo często są po prostu zbyt ciężkie i zbyt duże dla urządzenia, na którym są konsumowane.Tak więc przynajmniej możemy eksplorować przy użyciu formatu WebP dla naszych obrazów. W rzeczywistości saga WebP zbliża się do końca w zeszłym roku, gdy Apple dodał obsługę WebP w Safari 14. Tak więc po wielu latach dyskusji i debat, na dzień dzisiejszy WebP jest obsługiwane we wszystkich nowoczesnych przeglądarkach. Możemy więc udostępniać obrazy WebP z elementem
<picture>i awaryjnym plikiem JPEG, jeśli to konieczne (zobacz fragment kodu Andreasa Bovensa) lub za pomocą negocjacji treści (używając nagłówkówAccept).WebP nie jest jednak pozbawiony wad . Podczas gdy rozmiary plików obrazów WebP w porównaniu z odpowiednikami Guetzli i Zopfli, format nie obsługuje progresywnego renderowania, takiego jak JPEG, dlatego użytkownicy mogą szybciej widzieć gotowy obraz przy użyciu starego dobrego JPEG, chociaż obrazy WebP mogą być szybsze w sieci. Dzięki JPEG możemy zapewnić „przyzwoite” doświadczenie użytkownika z połową lub nawet jedną czwartą danych, a resztę załadować później, zamiast mieć w połowie pusty obraz, jak to ma miejsce w przypadku WebP.
Twoja decyzja będzie zależeć od tego, czego szukasz: dzięki WebP zmniejszysz ładunek, a dzięki JPEG poprawisz postrzeganą wydajność. Możesz dowiedzieć się więcej o WebP w rozmowie WebP Rewind autorstwa Pascala Massimino z Google.
Do konwersji do WebP możesz użyć WebP Converter, cwebp lub libwebp. Ire Aderinokun ma również bardzo szczegółowy samouczek dotyczący konwersji obrazów do WebP — podobnie jak Josh Comeau w swoim artykule na temat korzystania z nowoczesnych formatów obrazów.

Dokładna rozmowa o WebP: WebP Rewind autorstwa Pascala Massimino. (duży podgląd) Sketch natywnie obsługuje WebP, a obrazy WebP można eksportować z programu Photoshop za pomocą wtyczki WebP do programu Photoshop. Ale dostępne są również inne opcje.
Jeśli korzystasz z WordPressa lub Joomla, istnieją rozszerzenia, które pomogą Ci łatwo wdrożyć obsługę WebP, takie jak Optimus i Cache Enabler dla WordPress oraz własne obsługiwane rozszerzenie Joomla (przez Cody Arsenault). Możesz także wyabstrahować element
<picture>za pomocą React, styled components lub gatsby-image.Ach — bezwstydna wtyczka! — Jeremy Wagner opublikował nawet książkę Smashing na WebP, którą możesz sprawdzić, jeśli interesuje Cię wszystko, co dotyczy WebP.
- Czy używamy AVIF?
Być może słyszałeś wielką wiadomość: AVIF wylądował. Jest to nowy format obrazu wywodzący się z klatek kluczowych wideo AV1. Jest to otwarty, wolny od opłat format, który obsługuje stratną i bezstratną kompresję, animację, stratny kanał alfa i może obsługiwać ostre linie i jednolite kolory (co było problemem w przypadku JPEG), zapewniając jednocześnie lepsze wyniki w obu przypadkach.W rzeczywistości, w porównaniu do WebP i JPEG, AVIF działa znacznie lepiej , zapewniając zmniejszenie mediany rozmiaru pliku do 50% przy tym samym DSSIM (((nie)podobieństwo między dwoma lub więcej obrazami przy użyciu algorytmu aproksymującego ludzkie widzenie). W rzeczywistości, w swoim szczegółowym poście na temat optymalizacji ładowania obrazów, Malte Ubl zauważa, że AVIF „bardzo konsekwentnie przewyższa JPEG w bardzo znaczący sposób. Różni się to od WebP, który nie zawsze tworzy mniejsze obrazy niż JPEG i może w rzeczywistości być siecią strata z powodu braku wsparcia dla progresywnego obciążenia."

Możemy użyć AVIF jako progresywnego ulepszenia, dostarczającego WebP, JPEG lub PNG do starszych przeglądarek. (Duży podgląd). Zobacz widok zwykłego tekstu poniżej. Jak na ironię, AVIF może działać nawet lepiej niż duże SVG, chociaż oczywiście nie należy go postrzegać jako zamiennika SVG. Jest to również jeden z pierwszych formatów obrazu obsługujących obsługę kolorów HDR; oferując wyższą jasność, głębię kolorów i gamy kolorów. Jedynym minusem jest to, że obecnie AVIF nie obsługuje progresywnego dekodowania obrazu (jeszcze?) i podobnie jak Brotli, kodowanie z wysokim współczynnikiem kompresji jest obecnie dość powolne, chociaż dekodowanie jest szybkie.
AVIF jest obecnie obsługiwany w przeglądarkach Chrome, Firefox i Opera, a wsparcie w Safari ma pojawić się wkrótce (ponieważ Apple jest członkiem grupy, która stworzyła AV1).
Jaki jest zatem najlepszy sposób na wyświetlanie obrazów w dzisiejszych czasach ? W przypadku ilustracji i obrazów wektorowych (skompresowany) SVG jest niewątpliwie najlepszym wyborem. W przypadku zdjęć stosujemy metody negocjacji treści z elementem
picture. Jeśli AVIF jest obsługiwany, wysyłamy obraz AVIF; jeśli tak nie jest, najpierw wracamy do WebP, a jeśli WebP również nie jest obsługiwany, przełączamy się na JPEG lub PNG jako rezerwę (stosując w razie potrzeby warunki@media):<picture> <source type="image/avif"> <source type="image/webp"> <img src="image.jpg" alt="Photo" width="450" height="350"> </picture>Szczerze mówiąc, bardziej prawdopodobne jest, że użyjemy pewnych warunków w elemencie
picture:<picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture><picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture>Możesz pójść jeszcze dalej, zamieniając animowane obrazy na statyczne obrazy dla klientów, którzy zdecydują się na mniej ruchu dzięki
prefers-reduced-motion:<picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture><picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture>W ciągu kilku miesięcy AVIF zyskał na popularności:
- Możemy przetestować awaryjne WebP/AVIF w panelu Rendering w DevTools.
- Możemy używać Squoosh, AVIF.io i libavif do kodowania, dekodowania, kompresowania i konwertowania plików AVIF.
- Możemy użyć komponentu AVIF Preact Jake'a Archibalda, który dekoduje plik AVIF w procesie roboczym i wyświetla wynik na płótnie,
- Aby dostarczyć AVIF tylko do obsługiwanych przeglądarek, możemy użyć wtyczki PostCSS wraz ze skryptem 315B do użycia AVIF w deklaracjach CSS.
- Możemy stopniowo dostarczać nowe formaty obrazów za pomocą CSS i Cloudlare Workers, aby dynamicznie zmieniać zwrócony dokument HTML, wywnioskować informacje z nagłówka
accept, a następnie dodać odpowiedniowebp/avifitp. - AVIF jest już dostępny w Cloudinary (z limitami użytkowania), Cloudflare obsługuje AVIF w zmianie rozmiaru obrazu, a możesz włączyć AVIF z niestandardowymi nagłówkami AVIF w Netlify.
- Jeśli chodzi o animację, AVIF działa tak samo jak
<img src=mp4>z Safari, ogólnie przewyższając GIF i WebP, ale MP4 nadal działa lepiej. - Ogólnie w przypadku animacji AVC1 (h264) > HVC1 > WebP > AVIF > GIF, zakładając, że przeglądarki oparte na Chromium będą zawsze obsługiwać
<img src=mp4>. - Więcej informacji na temat AVIF można znaleźć w rozmowie o AVIF for Next Generation Image Coding autorstwa Adityi Mavlankar z Netflix oraz rozmowie o AVIF Image Format, którą wygłosił Kornel Lesinski z Cloudflare.
- Świetne odniesienie do wszystkiego o AVIF: obszerny post Jake'a Archibalda na temat AVIF wylądował.
Czy zatem przyszły AVIF ? Jon Sneyers nie zgadza się: AVIF działa o 60% gorzej niż JPEG XL, inny darmowy i otwarty format opracowany przez Google i Cloudinary. W rzeczywistości JPEG XL wydaje się działać znacznie lepiej na całym świecie. Jednak JPEG XL jest dopiero w końcowej fazie standaryzacji i nie działa jeszcze w żadnej przeglądarce. (Nie mylić z JPEG-XR Microsoftu pochodzącym ze starego, dobrego Internet Explorera 9 razy).
- Czy pliki JPEG/PNG/SVG są odpowiednio zoptymalizowane?
Kiedy pracujesz nad stroną docelową, na której kluczowe jest, aby obraz bohatera ładował się niesamowicie szybko, upewnij się, że pliki JPEG są progresywne i skompresowane za pomocą mozJPEG (co skraca czas rozpoczęcia renderowania poprzez manipulowanie poziomami skanowania) lub Guetzli, otwartego źródła Google koder skupiający się na percepcyjnej wydajności i wykorzystujący wnioski z Zopfli i WebP. Jedyny minus: wolne czasy przetwarzania (minuta procesora na megapiksel).Dla PNG możemy użyć Pingo, a dla SVG możemy użyć SVGO lub SVGOMG. A jeśli chcesz szybko wyświetlić podgląd i skopiować lub pobrać wszystkie zasoby SVG ze strony internetowej, svg-grabber może to zrobić również za Ciebie.
W każdym artykule dotyczącym optymalizacji obrazu jest to napisane, ale zawsze warto wspomnieć o utrzymywaniu czystych i zwartych zasobów wektorowych. Upewnij się, że wyczyściłeś nieużywane zasoby, usuń niepotrzebne metadane i zmniejsz liczbę punktów ścieżki w grafice (a tym samym w kodzie SVG). ( Dzięki Jeremy! )
Dostępne są również przydatne narzędzia online:
- Użyj Squoosh, aby kompresować, zmieniać rozmiar i manipulować obrazami na optymalnych poziomach kompresji (stratnej lub bezstratnej),
- Użyj Guetzli.it do kompresji i optymalizacji obrazów JPEG za pomocą Guetzli, który działa dobrze w przypadku obrazów z ostrymi krawędziami i jednolitymi kolorami (ale może być nieco wolniejszy)).
- Użyj generatora responsywnych punktów przerwania obrazu lub usługi takiej jak Cloudinary lub Imgix, aby zautomatyzować optymalizację obrazu. Ponadto, w wielu przypadkach, używanie
srcsetisizesprzyniesie znaczące korzyści. - Aby sprawdzić wydajność swoich responsywnych znaczników, możesz użyć obrazowania-sterty, narzędzia wiersza poleceń, które mierzy wydajność w różnych rozmiarach okien ekranu i proporcjach pikseli urządzenia.
- Możesz dodać automatyczną kompresję obrazu do przepływów pracy GitHub, dzięki czemu żaden obraz nie trafi do produkcji bez kompresji. Akcja wykorzystuje mozjpeg i libvips, które działają z PNG i JPG.
- Aby zoptymalizować przechowywanie wewnętrznie, możesz użyć nowego formatu Lepton Dropbox do bezstratnej kompresji plików JPEG średnio o 22%.
- Użyj BlurHash, jeśli chcesz wcześniej wyświetlić obraz zastępczy. BlurHash pobiera obraz i podaje krótki ciąg (tylko 20-30 znaków!), który reprezentuje symbol zastępczy tego obrazu. Ciąg jest na tyle krótki, że można go łatwo dodać jako pole w obiekcie JSON.
BlurHash to niewielka, zwarta reprezentacja symbolu zastępczego obrazu. (duży podgląd) Czasami sama optymalizacja obrazów nie wystarczy. Aby skrócić czas potrzebny do rozpoczęcia renderowania obrazu krytycznego, leniwe ładowanie mniej ważnych obrazów i odroczenie wczytywania skryptów po wyrenderowaniu obrazów krytycznych. Najbardziej kuloodpornym sposobem jest hybrydowe lazy-loading, kiedy wykorzystujemy natywne lazy-loading i lazyload, bibliotekę, która wykrywa wszelkie zmiany widoczności wywołane interakcją użytkownika (z IntersectionObserver, które omówimy później). Do tego:
- Rozważ wstępne wczytanie krytycznych obrazów, aby przeglądarka nie odkryła ich zbyt późno. W przypadku obrazów tła, jeśli chcesz być jeszcze bardziej agresywny, możesz dodać obraz jako zwykły obrazek za pomocą
<img src>, a następnie ukryć go na ekranie. - Rozważ zamianę obrazów z atrybutem rozmiarów, określając różne wymiary wyświetlania obrazu w zależności od zapytań o media, np. aby manipulować
sizesw celu zamiany źródeł w komponencie powiększającym. - Przejrzyj niespójności w pobieraniu obrazów, aby zapobiec nieoczekiwanym pobraniom obrazów pierwszego planu i tła. Uważaj na obrazy, które są wczytywane domyślnie, ale mogą nigdy nie być wyświetlane — np. w karuzeli, akordeonach i galeriach obrazów.
- Pamiętaj, aby zawsze ustawiać
widthiheightobrazów. Zwróć uwagę na właściwośćaspect-ratiow CSS i atrybutintrinsicsize, który pozwoli nam ustawić proporcje i wymiary obrazów, aby przeglądarka mogła wcześniej zarezerwować wstępnie zdefiniowany boks układu, aby uniknąć przeskoków układu podczas wczytywania strony.
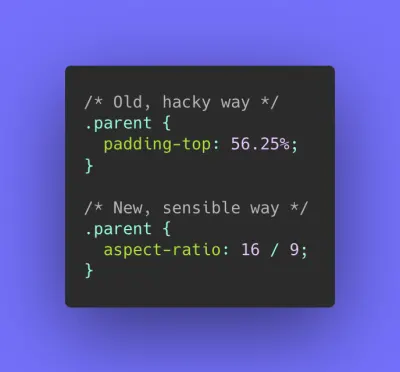
Powinno to zająć tylko kilka tygodni lub miesięcy, a współczynnik proporcji wyląduje w przeglądarkach. W Safari Technical Preview 118 już. Obecnie za flagą w Firefox i Chrome. (duży podgląd) Jeśli masz ochotę na przygodę, możesz pociąć i zmienić kolejność strumieni HTTP/2 za pomocą pracowników Edge, w zasadzie filtra czasu rzeczywistego działającego w sieci CDN, aby szybciej wysyłać obrazy przez sieć. Pracownicy brzegowi używają strumieni JavaScript, które używają fragmentów, które możesz kontrolować (w zasadzie są to JavaScript, który działa na brzegu CDN, który może modyfikować odpowiedzi strumieniowe), dzięki czemu możesz kontrolować dostarczanie obrazów.
Z pracownikiem serwisu jest już za późno, ponieważ nie możesz kontrolować tego, co jest w sieci, ale działa z pracownikami Edge. Możesz więc używać ich na statycznych plikach JPEG zapisanych progresywnie dla konkretnej strony docelowej.
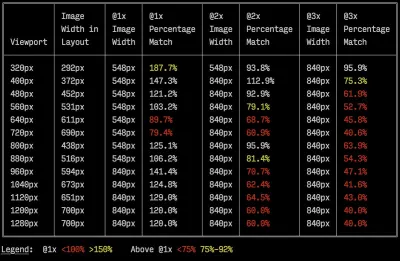
Przykładowe dane wyjściowe przez obrazowanie-stertę, narzędzie wiersza poleceń, które mierzy wydajność w różnych rozmiarach okien ekranu i proporcjach pikseli urządzenia. (źródło obrazu) (duży podgląd) Nie wystarczająco dobre? Cóż, możesz również poprawić postrzeganą wydajność obrazów za pomocą techniki wielu obrazów tła. Pamiętaj, że granie z kontrastem i zamazywanie niepotrzebnych szczegółów (lub usuwanie kolorów) również może zmniejszyć rozmiar pliku. Ach, trzeba powiększyć małe zdjęcie bez utraty jakości? Rozważ użycie Letsenhance.io.
Te dotychczasowe optymalizacje obejmują tylko podstawy. Addy Osmani opublikował bardzo szczegółowy przewodnik po Essential Image Optimization, w którym szczegółowo opisano kompresję obrazu i zarządzanie kolorami. Na przykład możesz rozmyć niepotrzebne części obrazu (stosując do nich filtr rozmycia gaussowskiego), aby zmniejszyć rozmiar pliku, a ostatecznie możesz nawet zacząć usuwać kolory lub zmienić obraz na czarno-biały, aby jeszcze bardziej zmniejszyć rozmiar . W przypadku obrazów tła eksportowanie zdjęć z programu Photoshop w jakości od 0 do 10% również może być całkowicie akceptowalne.
W Smashing Magazine używamy przyrostka
-optdla nazw obrazów — na przykładbrotli-compression-opt.png; za każdym razem, gdy obraz zawiera ten przyrostek, wszyscy w zespole wiedzą, że obraz został już zoptymalizowany.Ach, i nie używaj JPEG-XR w Internecie — „przetwarzanie dekodowania plików JPEG-XR po stronie oprogramowania na procesorze unieważnia, a nawet przewyższa potencjalnie pozytywny wpływ oszczędności rozmiaru bajtów, szczególnie w kontekście SPA” (nie pomieszać z Cloudinary/Google JPEG XL).

- Czy filmy są odpowiednio zoptymalizowane?
Do tej pory omawialiśmy obrazy, ale uniknęliśmy rozmowy o starych, dobrych GIF-ach. Pomimo naszej miłości do GIF-ów, naprawdę nadszedł czas, aby porzucić je na dobre (przynajmniej w naszych witrynach i aplikacjach). Zamiast ładować ciężkie animowane pliki GIF, które wpływają zarówno na wydajność renderowania, jak i przepustowość, dobrym pomysłem jest przełączenie się na animowany WebP (gdy GIF jest zastępczym) lub zastąpienie ich całkowicie zapętlonymi filmami HTML5.W przeciwieństwie do obrazów przeglądarki nie ładują wstępnie treści
<video>, ale filmy HTML5 są zwykle znacznie lżejsze i mniejsze niż GIF-y. Nie masz opcji? Cóż, przynajmniej możemy dodać stratną kompresję do GIF-ów za pomocą Stratnego GIF, gifsicle lub giflossy.Testy przeprowadzone przez Colina Bendella pokazują, że filmy w tekście w tagach
imgw Safari Technology Preview wyświetlają się co najmniej 20 razy szybciej i dekodują 7 razy szybciej niż odpowiedniki w formacie GIF, a ponadto mają ułamek rozmiaru pliku. Nie jest to jednak obsługiwane w innych przeglądarkach.W krainie dobrych wiadomości formaty wideo przez lata bardzo się rozwijały . Przez długi czas mieliśmy nadzieję, że WebM stanie się formatem, który będzie rządził nimi wszystkimi, a WebP (który jest w zasadzie jednym nieruchomym obrazem w kontenerze wideo WebM) stanie się zamiennikiem przestarzałych formatów obrazów. Rzeczywiście, Safari obsługuje teraz WebP, ale pomimo tego, że WebP i WebM zyskują obecnie wsparcie, przełom tak naprawdę nie nastąpił.
Mimo to moglibyśmy używać WebM dla większości nowoczesnych przeglądarek:
<!-- By Houssein Djirdeh. https://web.dev/replace-gifs-with-videos/ --> <!-- A common scenartio: MP4 with a WEBM fallback. --> <video autoplay loop muted playsinline> <source src="my-animation.webm" type="video/webm"> <source src="my-animation.mp4" type="video/mp4"> </video>Ale być może moglibyśmy całkowicie to przemyśleć. W 2018 roku Alliance of Open Media wydała nowy obiecujący format wideo o nazwie AV1 . AV1 ma kompresję podobną do kodeka H.265 (ewolucja H.264), ale w przeciwieństwie do tego ostatniego, AV1 jest bezpłatny. Ceny licencji H.265 skłoniły producentów przeglądarek do przyjęcia porównywalnie wydajnego AV1: AV1 (podobnie jak H.265) kompresuje dwa razy lepiej niż WebM .

AV1 ma duże szanse stać się najlepszym standardem wideo w sieci. (Źródło zdjęcia: Wikimedia.org) (duży podgląd) W rzeczywistości Apple używa obecnie formatu HEIF i HEVC (H.265), a wszystkie zdjęcia i filmy w najnowszym systemie iOS są zapisywane w tych formatach, a nie w JPEG. Podczas gdy HEIF i HEVC (H.265) nie są odpowiednio eksponowane w Internecie (jeszcze?), AV1 jest — i zyskuje obsługę przeglądarek. Dlatego dodanie źródła
AV1w tagu<video>jest rozsądne, ponieważ wszyscy dostawcy przeglądarek wydają się być na pokładzie.Na razie najczęściej używanym i obsługiwanym kodowaniem jest H.264, obsługiwany przez pliki MP4, więc przed udostępnieniem pliku upewnij się, że Twoje pliki MP4 są przetwarzane z wieloprzebiegowym kodowaniem, zamazane z efektem frei0r iirblur (jeśli dotyczy) i Metadane atomu moov są przenoszone do nagłówka pliku, podczas gdy serwer akceptuje serwowanie bajtów. Boris Schapira zapewnia dokładne instrukcje dotyczące FFmpeg, aby zoptymalizować filmy do maksimum. Oczywiście pomogłoby również zapewnienie formatu WebM jako alternatywy.
Chcesz zacząć renderować filmy szybciej, ale pliki wideo są nadal zbyt duże ? Na przykład, kiedy masz duży film w tle na stronie docelowej? Powszechną techniką jest pokazanie najpierw pierwszej klatki jako nieruchomego obrazu lub wyświetlenie mocno zoptymalizowanego, krótkiego segmentu zapętlonego, który może być zinterpretowany jako część wideo, a następnie, gdy wideo jest wystarczająco zbuforowane, rozpocznij odtwarzanie rzeczywisty film. Doug Sillars ma napisany szczegółowy przewodnik po wydajności wideo w tle, który może być pomocny w takim przypadku. ( Dzięki, Guy Podjarny! ).
W powyższym scenariuszu możesz chcieć udostępnić responsywne obrazy plakatów . Domyślnie elementy
videodopuszczają tylko jeden obraz jako plakat, co niekoniecznie jest optymalne. Możemy użyć Responsive Video Poster, biblioteki JavaScript, która pozwala używać różnych obrazów plakatów dla różnych ekranów, a także dodaje nakładkę przejścia i pełną kontrolę stylizacji symboli zastępczych wideo.Badania pokazują, że jakość strumienia wideo wpływa na zachowanie widzów. W rzeczywistości widzowie zaczynają porzucać wideo, jeśli opóźnienie uruchamiania przekracza około 2 sekund. Powyżej tego punktu, 1-sekundowy wzrost opóźnienia skutkuje około 5,8% wzrostem wskaźnika porzuceń. Nie jest więc zaskakujące, że mediana czasu rozpoczęcia wideo wynosi 12,8 s, przy czym 40% filmów ma co najmniej 1 zatrzymanie, a 20% co najmniej 2 sekundy odtwarzania zatrzymanego wideo. W rzeczywistości stoiska wideo są nieuniknione w 3G, ponieważ filmy są odtwarzane szybciej niż sieć może dostarczyć zawartość.
Więc jakie jest rozwiązanie? Zazwyczaj urządzenia z małym ekranem nie są w stanie obsłużyć 720p i 1080p, które obsługujemy na pulpicie. Według Douga Sillarsa możemy tworzyć mniejsze wersje naszych filmów i używać JavaScript do wykrywania źródła mniejszych ekranów, aby zapewnić szybkie i płynne odtwarzanie na tych urządzeniach. Alternatywnie możemy użyć strumieniowego przesyłania wideo. Strumienie wideo HLS dostarczą do urządzenia wideo o odpowiedniej wielkości — abstrahując od potrzeby tworzenia różnych filmów na różnych ekranach. Będzie również negocjować prędkość sieci i dostosować szybkość transmisji wideo do szybkości używanej sieci.
Aby uniknąć marnowania przepustowości, moglibyśmy dodać źródło wideo tylko dla urządzeń, które faktycznie potrafią dobrze odtwarzać wideo. Alternatywnie możemy całkowicie usunąć atrybut
autoplayz taguvideoi użyć JavaScript, aby wstawićautoplayna większych ekranach. Dodatkowo musimy dodaćpreload="none"dovideo, aby poinformować przeglądarkę, aby nie pobierała żadnego z plików wideo, dopóki faktycznie nie będzie potrzebować pliku:<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Następnie możemy kierować reklamy w szczególności na przeglądarki, które faktycznie obsługują AV1:
<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.av1.mp4" type="video/mp4; codecs=av01.0.05M.08"> <source src="video.hevc.mp4" type="video/mp4; codecs=hevc"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Następnie możemy ponownie dodać
autoplaypowyżej pewnego progu (np. 1000px):/* By Doug Sillars. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ */ <script> window.onload = addAutoplay(); var videoLocation = document.getElementById("hero-video"); function addAutoplay() { if(window.innerWidth > 1000){ videoLocation.setAttribute("autoplay",""); }; } </script>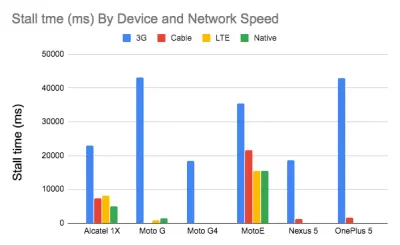
Liczba straganów według urządzenia i szybkości sieci. Szybsze urządzenia w szybszych sieciach praktycznie nie mają straganów. Według badań Douga Sillarsa. (duży podgląd) Wydajność odtwarzania wideo to osobna historia, a jeśli chcesz zagłębić się w nią szczegółowo, zapoznaj się z inną serią Douga Sillarsa na temat Aktualny stan najlepszych praktyk w zakresie dostarczania wideo i wideo, która zawiera szczegółowe informacje na temat wskaźników dostarczania wideo , wstępne ładowanie wideo, kompresja i przesyłanie strumieniowe. Na koniec możesz sprawdzić, jak wolne lub szybkie będzie przesyłanie strumieniowe wideo za pomocą funkcji Stream or Not.
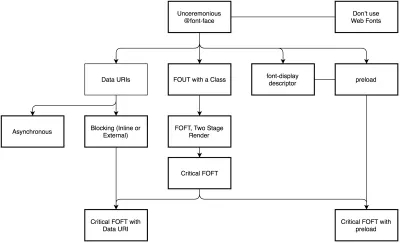
- Czy dostarczanie czcionek internetowych jest zoptymalizowane?
The first question that's worth asking is if we can get away with using UI system fonts in the first place — we just need to make sure to double check that they appear correctly on various platforms. If it's not the case, chances are high that the web fonts we are serving include glyphs and extra features and weights that aren't being used. We can ask our type foundry to subset web fonts or if we are using open-source fonts, subset them on our own with Glyphhanger or Fontsquirrel. We can even automate our entire workflow with Peter Muller's subfont, a command line tool that statically analyses your page in order to generate the most optimal web font subsets, and then inject them into our pages.WOFF2 support is great, and we can use WOFF as fallback for browsers that don't support it — or perhaps legacy browsers could be served system fonts. There are many, many, many options for web font loading, and we can choose one of the strategies from Zach Leatherman's "Comprehensive Guide to Font-Loading Strategies," (code snippets also available as Web font loading recipes).
Probably the better options to consider today are Critical FOFT with
preloadand "The Compromise" method. Both of them use a two-stage render for delivering web fonts in steps — first a small supersubset required to render the page fast and accurately with the web font, and then load the rest of the family async. The difference is that "The Compromise" technique loads polyfill asynchronously only if font load events are not supported, so you don't need to load the polyfill by default. Need a quick win? Zach Leatherman has a quick 23-min tutorial and case study to get your fonts in order.In general, it might be a good idea to use the
preloadresource hint to preload fonts, but in your markup include the hints after the link to critical CSS and JavaScript. Withpreload, there is a puzzle of priorities, so consider injectingrel="preload"elements into the DOM just before the external blocking scripts. According to Andy Davies, "resources injected using a script are hidden from the browser until the script executes, and we can use this behaviour to delay when the browser discovers thepreloadhint." Otherwise, font loading will cost you in the first render time.
When everything is critical, nothing is critical. preload only one or a maximum of two fonts of each family. (Image credit: Zach Leatherman – slide 93) (Large preview) It's a good idea to be selective and choose files that matter most, eg the ones that are critical for rendering or that would help you avoiding visible and disruptive text reflows. In general, Zach advises to preload one or two fonts of each family — it also makes sense to delay some font loading if they are less critical.
It has become quite common to use
local()value (which refers to a local font by name) when defining afont-familyin the@font-facerule:/* Warning! Not a good idea! */ @font-face { font-family: Open Sans; src: local('Open Sans Regular'), local('OpenSans-Regular'), url('opensans.woff2') format ('woff2'), url('opensans.woff') format('woff'); }The idea is reasonable: some popular open-source fonts such as Open Sans are coming pre-installed with some drivers or apps, so if the font is available locally, the browser doesn't need to download the web font and can display the local font immediately. As Bram Stein noted, "though a local font matches the name of a web font, it most likely isn't the same font . Many web fonts differ from their "desktop" version. The text might be rendered differently, some characters may fall back to other fonts, OpenType features can be missing entirely, or the line height may be different."
Also, as typefaces evolve over time, the locally installed version might be very different from the web font, with characters looking very different. So, according to Bram, it's better to never mix locally installed fonts and web fonts in
@font-facerules. Google Fonts has followed suit by disablinglocal()on the CSS results for all users, other than Android requests for Roboto.Nobody likes waiting for the content to be displayed. With the
font-displayCSS descriptor, we can control the font loading behavior and enable content to be readable immediately (withfont-display: optional) or almost immediately (with a timeout of 3s, as long as the font gets successfully downloaded — withfont-display: swap). (Well, it's a bit more complicated than that.)However, if you want to minimize the impact of text reflows, we could use the Font Loading API (supported in all modern browsers). Specifically that means for every font, we'd creata a
FontFaceobject, then try to fetch them all, and only then apply them to the page. This way, we group all repaints by loading all fonts asynchronously, and then switch from fallback fonts to the web font exactly once. Take a look at Zach's explanation, starting at 32:15, and the code snippet):/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));To initiate a very early fetch of the fonts with Font Loading API in use, Adrian Bece suggests to add a non-breaking space
nbsp;at the top of thebody, and hide it visually witharia-visibility: hiddenand a.hiddenclass:<body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body><body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body>This goes along with CSS that has different font families declared for different states of loading, with the change triggered by Font Loading API once the fonts have successfully loaded:
body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }If you ever wondered why despite all your optimizations, Lighthouse still suggests to eliminate render-blocking resources (fonts), in the same article Adrian Bece provides a few techniques to make Lighthouse happy, along with a Gatsby Omni Font Loader, a performant asynchronous font loading and Flash Of Unstyled Text (FOUT) handling plugin for Gatsby.
Now, many of us might be using a CDN or a third-party host to load web fonts from. In general, it's always better to self-host all your static assets if you can, so consider using google-webfonts-helper, a hassle-free way to self-host Google Fonts. And if it's not possible, you can perhaps proxy the Google Font files through the page origin.

It's worth noting though that Google is doing quite a bit of work out of the box, so a server might need a bit of tweaking to avoid delays ( thanks, Barry! )
This is quite important especially as since Chrome v86 (released October 2020), cross-site resources like fonts can't be shared on the same CDN anymore — due to the partitioned browser cache. This behavior was a default in Safari for years.
But if it's not possible at all, there is a way to get to the fastest possible Google Fonts with Harry Roberts' snippet:
<!-- By Harry Roberts. https://csswizardry.com/2020/05/the-fastest-google-fonts/ - 1. Preemptively warm up the fonts' origin. - 2. Initiate a high-priority, asynchronous fetch for the CSS file. Works in - most modern browsers. - 3. Initiate a low-priority, asynchronous fetch that gets applied to the page - only after it's arrived. Works in all browsers with JavaScript enabled. - 4. In the unlikely event that a visitor has intentionally disabled - JavaScript, fall back to the original method. The good news is that, - although this is a render-blocking request, it can still make use of the - preconnect which makes it marginally faster than the default. --> <!-- [1] --> <link rel="preconnect" href="https://fonts.gstatic.com" crossorigin /> <!-- [2] --> <link rel="preload" as="style" href="$CSS&display=swap" /> <!-- [3] --> <link rel="stylesheet" href="$CSS&display=swap" media="print" onload="this.media='all'" /> <!-- [4] --> <noscript> <link rel="stylesheet" href="$CSS&display=swap" /> </noscript>Harry's strategy is to pre-emptively warm up the fonts' origin first. Then we initiate a high-priority, asynchronous fetch for the CSS file. Afterwards, we initiate a low-priority, asynchronous fetch that gets applied to the page only after it's arrived (with a print stylesheet trick). Finally, if JavaScript isn't supported, we fall back to the original method.
Ah, talking about Google Fonts: you can shave up to 90% of the size of Google Fonts requests by declaring only characters you need with
&text. Plus, the support for font-display was added recently to Google Fonts as well, so we can use it out of the box.Szybkie słowo ostrzeżenia. Jeśli używasz
font-display: optional, użyciepreloadładowania może być nieoptymalne, ponieważ wcześnie wyzwoli to żądanie czcionki internetowej (powodując przeciążenie sieci , jeśli masz inne zasoby ścieżki krytycznej, które należy pobrać). Użyj funkcjipreconnectłączenia, aby uzyskać szybsze żądania czcionek między różnymi źródłami, ale zachowaj ostrożność podczaspreloadładowania, ponieważ wstępne ładowanie czcionek z innego źródła spowoduje rywalizację w sieci. Wszystkie te techniki zostały opisane w przepisach Zacha na ładowanie czcionek internetowych.Z drugiej strony dobrym pomysłem może być zrezygnowanie z czcionek internetowych (lub przynajmniej drugiego etapu renderowania), jeśli użytkownik włączył opcję Zmniejsz ruch w preferencjach dostępności lub włączył tryb oszczędzania danych (patrz nagłówek
Save-Data) , lub gdy użytkownik ma wolną łączność (za pośrednictwem interfejsu Network Information API).Możemy również użyć zapytania o media CSS
prefers-reduced-data, aby nie definiować deklaracji czcionek, jeśli użytkownik wybrał tryb oszczędzania danych (istnieją też inne przypadki użycia). Zapytanie o media zasadniczo ujawniłoby, gdyby nagłówek żądaniaSave-Dataz rozszerzenia HTTP Client Hint był włączony/wyłączony, aby umożliwić użycie z CSS. Obecnie obsługiwane tylko w Chrome i Edge za flagą.Metryka? Aby zmierzyć wydajność ładowania czcionek internetowych, weź pod uwagę pomiar Cały tekst widoczny (moment, w którym wszystkie czcionki zostały załadowane, a cała treść jest wyświetlana w czcionkach internetowych), czas do rzeczywistej kursywy oraz licznik ponownego przepływu czcionki internetowej po pierwszym renderowaniu. Oczywiście im niższe są obie metryki, tym lepsza jest wydajność.
A co ze zmiennymi czcionkami , możesz zapytać? Należy zauważyć, że czcionki zmienne mogą wymagać znacznego rozważenia wydajności. Dają nam znacznie szerszą przestrzeń projektową dla wyborów typograficznych, ale odbywa się to kosztem pojedynczego żądania seryjnego w przeciwieństwie do wielu indywidualnych żądań plików.
Chociaż czcionki zmienne drastycznie zmniejszają całkowity łączny rozmiar plików czcionek, to pojedyncze żądanie może być powolne, blokując renderowanie całej zawartości strony. Tak więc podzbiór i podział czcionki na zestawy znaków nadal mają znaczenie. Jednak z dobrej strony, gdy wstawisz zmienną czcionkę, domyślnie otrzymamy dokładnie jeden odświeżanie strony, więc nie będzie wymagany JavaScript do grupowania odświeżeń.
Co w takim razie stworzyłoby kuloodporną strategię ładowania czcionek internetowych ? Podzbiór czcionek i przygotowanie ich do renderowania dwuetapowego, zadeklarowanie ich za pomocą deskryptora
font-displayczcionek, użycie interfejsu API ładowania czcionek do grupowania odświeżeń i przechowywania czcionek w trwałej pamięci podręcznej procesu roboczego. Podczas pierwszej wizyty wstrzyknij wstępne ładowanie skryptów tuż przed zablokowaniem zewnętrznych skryptów. W razie potrzeby możesz wrócić do obserwatora twarzy Brama Steina. A jeśli interesuje Cię mierzenie wydajności ładowania czcionek, Andreas Marschke bada śledzenie wydajności za pomocą Font API i UserTiming API.Na koniec nie zapomnij uwzględnić
unicode-rangeaby podzielić dużą czcionkę na mniejsze, specyficzne dla języka, i użyj dopasowywania stylów czcionek Moniki Dinculescu, aby zminimalizować wstrząsające przesunięcie w układzie, spowodowane rozbieżnościami w rozmiarach między rezerwą a czcionki internetowe.Alternatywnie, aby emulować czcionkę internetową dla czcionki zastępczej, możemy użyć deskryptorów @font-face, aby zastąpić metryki czcionek (demo, włączone w Chrome 87). (Pamiętaj, że korekty są skomplikowane w przypadku skomplikowanych stosów czcionek.)
Czy przyszłość wygląda świetlanie? Dzięki progresywnemu wzbogacaniu czcionek, w końcu możemy być w stanie „pobrać tylko wymaganą część czcionki na danej stronie, a w przypadku kolejnych żądań tej czcionki, aby dynamicznie „załatać” oryginalne pobranie dodatkowymi zestawami glifów, zgodnie z wymaganiami na kolejnej stronie poglądów”, jak wyjaśnia Jason Pamental. Demo transferu przyrostowego jest już dostępne i trwa.
Optymalizacje kompilacji
- Czy określiliśmy nasze priorytety?
Warto najpierw wiedzieć, z czym masz do czynienia. Przeprowadź spis wszystkich swoich zasobów (JavaScript, obrazy, czcionki, skrypty stron trzecich i „drogie” moduły na stronie, takie jak karuzele, złożone infografiki i treści multimedialne) i podziel je na grupy.Skonfiguruj arkusz kalkulacyjny . Zdefiniuj podstawowe środowisko dla starszych przeglądarek (tj. w pełni dostępną zawartość podstawową), ulepszone środowisko dla obsługiwanych przeglądarek (tj. wzbogacone, pełne środowisko) oraz dodatki (zasoby, które nie są absolutnie wymagane i mogą być ładowane z opóźnieniem, takie jak czcionki internetowe, niepotrzebne style, skrypty karuzeli, odtwarzacze wideo, widżety mediów społecznościowych, duże obrazy). Wiele lat temu opublikowaliśmy artykuł „Improving Smashing Magazine's Performance”, w którym szczegółowo opisano to podejście.
Optymalizując wydajność, musimy odzwierciedlać nasze priorytety. Natychmiast załaduj podstawowe środowisko, następnie ulepszenia , a następnie dodatki .
- Czy używasz natywnych modułów JavaScript w produkcji?
Pamiętasz starą dobrą technikę cięcia musztardy, która umożliwia wysyłanie podstawowego środowiska do starszych przeglądarek i ulepszonego interfejsu do nowoczesnych przeglądarek? Zaktualizowany wariant tej techniki może wykorzystywać ES2017+<script type="module">, znany również jako wzorzec moduł/nomodule (wprowadzony również przez Jeremy'ego Wagnera jako serwowanie różnicowe ).Chodzi o to, aby skompilować i obsłużyć dwa oddzielne pakiety JavaScript : „zwykłą” wersję, ten z transformacjami Babel i wypełniaczami i udostępniać je tylko starszym przeglądarkom, które faktycznie ich potrzebują, oraz inny pakiet (taka sama funkcjonalność), który nie ma przekształceń lub wypełniacze.
W rezultacie pomagamy zmniejszyć blokowanie głównego wątku, zmniejszając liczbę skryptów, które przeglądarka musi przetworzyć. Jeremy Wagner opublikował obszerny artykuł o serwowaniu różnicowym i o tym, jak skonfigurować go w potoku kompilacji, od konfiguracji Babel, po poprawki, które należy wprowadzić w pakiecie Webpack, a także o korzyściach płynących z wykonywania całej tej pracy.
Skrypty natywnego modułu JavaScript są domyślnie odroczone, więc podczas parsowania HTML przeglądarka pobierze główny moduł.

Natywne moduły JavaScript są domyślnie odroczone. Prawie wszystko o natywnych modułach JavaScript. (duży podgląd) Jedna uwaga ostrzegawcza: wzorzec moduł/nomodule może zadziałać odwrotnie na niektórych klientach, więc warto rozważyć obejście: mniej ryzykowny wzorzec obsługi różnicowej Jeremy'ego, który jednak omija skaner wstępnego ładowania, co może wpłynąć na wydajność w sposób, w jaki nie przewidywać. ( dzięki Jeremy! )
W rzeczywistości Rollup obsługuje moduły jako format wyjściowy, więc możemy zarówno łączyć kod, jak i wdrażać moduły w środowisku produkcyjnym. Parcel obsługuje moduły w Parcel 2. W przypadku Webpack moduł module-nomodule-plugin automatyzuje generowanie skryptów modułu/nomodule.
Uwaga : warto zaznaczyć, że samo wykrywanie funkcji nie wystarczy do podjęcia świadomej decyzji dotyczącej ładunku wysyłanego do tej przeglądarki. Na własną rękę nie możemy wywnioskować możliwości urządzenia z wersji przeglądarki. Na przykład tanie telefony z Androidem w krajach rozwijających się w większości korzystają z przeglądarki Chrome i odetną musztardę pomimo ograniczonych możliwości pamięci i procesora.
Ostatecznie, korzystając z nagłówka wskazówek klienta pamięci urządzenia, będziemy mogli bardziej niezawodnie kierować reklamy na urządzenia z niższej półki. W chwili pisania tego tekstu nagłówek jest obsługiwany tylko w Blink (ogólnie dotyczy podpowiedzi dla klientów). Ponieważ pamięć urządzenia ma również interfejs API JavaScript, który jest dostępny w Chrome, jedną z opcji może być wykrywanie funkcji na podstawie interfejsu API i powrót do wzorca moduł/nomoduł, jeśli nie jest obsługiwany ( dzięki, Yoav! ).
- Czy korzystasz z drżenia drzewa, podnoszenia zasięgu i dzielenia kodu?
Potrząsanie drzewem to sposób na uporządkowanie procesu kompilacji przez uwzględnienie tylko kodu, który jest faktycznie używany w produkcji i wyeliminowanie nieużywanych importów w pakiecie Webpack. W przypadku Webpack i Rollup mamy również możliwość podnoszenia zakresu, która pozwala obu narzędziom wykryć, gdzie łańcuchimportmoże zostać spłaszczony i przekształcony w jedną wbudowaną funkcję bez narażania kodu. Dzięki Webpack możemy również użyć JSON Tree Shaking.Dzielenie kodu to kolejna funkcja pakietu Webpack, która dzieli bazę kodu na „kawałki”, które są ładowane na żądanie. Nie cały JavaScript musi zostać pobrany, przeanalizowany i skompilowany od razu. Po zdefiniowaniu punktów podziału w kodzie, Webpack może zająć się zależnościami i plikami wyjściowymi. Pozwala zachować niewielkie początkowe pobieranie i zażądać kodu na żądanie, gdy zażąda tego aplikacja. Alexander Kondrov ma fantastyczne wprowadzenie do dzielenia kodu za pomocą Webpack i React.
Rozważ użycie wtyczki preload-webpack-plugin, która pobiera trasy, które dzielisz w kodzie, a następnie monituje przeglądarkę o ich wstępne załadowanie za pomocą
<link rel="preload">lub<link rel="prefetch">. Wbudowane dyrektywy Webpack dają również pewną kontrolę nadpreload/prefetch. (Uważaj jednak na problemy z ustalaniem priorytetów.)Gdzie zdefiniować punkty podziału? Śledząc, które fragmenty CSS/JavaScript są używane, a które nie. Umar Hansa wyjaśnia, w jaki sposób możesz użyć Code Coverage od Devtools, aby to osiągnąć.
W przypadku aplikacji jednostronicowych potrzebujemy trochę czasu na zainicjowanie aplikacji, zanim będziemy mogli renderować stronę. Twoje ustawienie będzie wymagało niestandardowego rozwiązania, ale możesz uważać na moduły i techniki przyspieszające początkowy czas renderowania. Na przykład, oto jak debugować wydajność React i wyeliminować typowe problemy z wydajnością React, a oto jak poprawić wydajność w Angular. Ogólnie rzecz biorąc, większość problemów z wydajnością pojawia się od pierwszego uruchomienia aplikacji.
Jaki jest więc najlepszy sposób na agresywne, ale niezbyt agresywne dzielenie kodu? Według Phila Waltona „oprócz dzielenia kodu za pomocą dynamicznego importu, [możemy] również użyć dzielenia kodu na poziomie pakietu , gdzie każdy zaimportowany moduł węzła jest umieszczany w porcji na podstawie nazwy swojego pakietu”. Phil zapewnia również samouczek, jak go zbudować.
- Czy możemy poprawić wydajność Webpacka?
Ponieważ Webpack jest często uważany za tajemniczy, istnieje wiele wtyczek Webpack, które mogą się przydać w celu dalszego zmniejszenia wydajności Webpacka. Poniżej znajdują się niektóre z bardziej niejasnych, które mogą wymagać nieco więcej uwagi.Jedna z ciekawszych pochodzi z wątku Iwana Akulowa. Wyobraź sobie, że masz funkcję, którą wywołujesz raz, przechowujesz jej wynik w zmiennej, a potem nie używaj tej zmiennej. Potrząsanie drzewem usunie zmienną, ale nie funkcję, ponieważ może być używana w inny sposób. Jeśli jednak funkcja nie jest nigdzie używana, możesz ją usunąć. Aby to zrobić, poprzedź wywołanie funkcji znakiem
/*#__PURE__*/, który jest obsługiwany przez Uglify i Terser — gotowe!
Aby usunąć taką funkcję, gdy jej wynik nie jest używany, poprzedź wywołanie funkcji przedrostkiem /*#__PURE__*/. Via Ivan Akulov.(duży podgląd)Oto kilka innych narzędzi zalecanych przez Ivana:
- purgecss-webpack-plugin usuwa nieużywane klasy, zwłaszcza gdy używasz Bootstrap lub Tailwind.
- Włącz
optimization.splitChunks: 'all'z wtyczką split-chunks-plugin. To spowodowałoby, że pakiet webpack automatycznie podzieli kodem pakiety wpisów w celu lepszego buforowania. - Ustaw
optimization.runtimeChunk: true. Przeniosłoby to środowisko wykonawcze pakietu webpack do osobnej części — a także poprawiłoby buforowanie. - google-fonts-webpack-plugin pobiera pliki czcionek, dzięki czemu możesz je wyświetlać ze swojego serwera.
- workbox-webpack-plugin umożliwia wygenerowanie pracownika usługi z konfiguracją wstępnego buforowania dla wszystkich zasobów pakietu webpack. Sprawdź także Service Worker Packages, obszerny przewodnik po modułach, które można zastosować od razu. Lub użyj preload-webpack-plugin, aby wygenerować
preloadładowanie/wstępneprefetchdla wszystkich fragmentów JavaScript. - speed-measure-webpack-plugin mierzy szybkość kompilacji pakietu internetowego, zapewniając wgląd w to, które etapy procesu kompilacji są najbardziej czasochłonne.
- Duplicate-package-checker-webpack-plugin ostrzega, gdy twój pakiet zawiera wiele wersji tego samego pakietu.
- Użyj izolacji zakresu i dynamicznie skracaj nazwy klas CSS w czasie kompilacji.
- Czy możesz przeładować JavaScript do Web Workera?
Aby zredukować negatywny wpływ na czas do interakcji, dobrym pomysłem może być przerzucenie ciężkiego kodu JavaScript na robota internetowego.Wraz ze wzrostem bazy kodu pojawią się wąskie gardła wydajności interfejsu użytkownika, spowalniając wrażenia użytkownika. Dzieje się tak, ponieważ operacje DOM działają równolegle z twoim JavaScriptem w głównym wątku. Za pomocą pracowników sieci Web możemy przenieść te kosztowne operacje do procesu działającego w tle w innym wątku. Typowe przypadki użycia dla pracowników sieci Web to wstępne pobieranie danych i progresywne aplikacje internetowe w celu załadowania i przechowywania niektórych danych z wyprzedzeniem, aby można było ich później użyć w razie potrzeby. Możesz też użyć Comlink do usprawnienia komunikacji między stroną główną a pracownikiem. Jeszcze trochę pracy do wykonania, ale do tego dochodzimy.
Istnieje kilka interesujących studiów przypadków dotyczących pracowników sieci Web, które pokazują różne podejścia do przenoszenia struktury i logiki aplikacji do pracowników sieci Web. Wniosek: generalnie wciąż jest kilka wyzwań, ale jest już kilka dobrych przypadków użycia ( dzięki, Ivan Akulov! ).
Począwszy od przeglądarki Chrome 80, został udostępniony nowy tryb dla pracowników sieci Web z korzyściami wydajnościowymi modułów JavaScript, zwany pracownikami modułu. Możemy zmienić ładowanie i wykonanie skryptu, aby dopasować go do
script type="module", a także możemy użyć dynamicznego importu do leniwego ładowania kodu bez blokowania wykonywania procesu roboczego.Jak zacząć? Oto kilka zasobów, którym warto się przyjrzeć:
- Surma opublikowała doskonały przewodnik o tym, jak uruchomić JavaScript z głównego wątku przeglądarki, a także Kiedy należy używać Web Workers?
- Sprawdź także dyskusję Surmy o architekturze głównego wątku.
- Shubhie Panicker i Jason Miller „Quest to Guaranteeness” zapewniają szczegółowy wgląd w to, jak korzystać z pracowników sieci Web i kiedy ich unikać.
- Zejście z drogi użytkowników: mniej Jank with Web Workers wskazuje przydatne wzorce pracy z pracownikami sieciowymi, skuteczne sposoby komunikacji między pracownikami, obsługę złożonego przetwarzania danych poza głównym wątkiem oraz testowanie i debugowanie ich.
- Workerize umożliwia przeniesienie modułu do Web Worker, automatycznie odzwierciedlając wyeksportowane funkcje jako asynchroniczne proxy.
- Jeśli używasz Webpack, możesz użyć workize-loader. Alternatywnie możesz również użyć wtyczki roboczej.

Używaj pracowników sieci Web, gdy kod blokuje się przez długi czas, ale unikaj ich, gdy polegasz na modelu DOM, obsługujesz odpowiedź wejściową i potrzebujesz minimalnego opóźnienia. (przez Addy Osmani) (duży podgląd) Należy zauważyć, że Web Workers nie mają dostępu do DOM, ponieważ DOM nie jest „bezpieczny wątkowo”, a wykonywany przez nich kod musi być zawarty w osobnym pliku.
- Czy można odciążyć „gorące ścieżki” do WebAssembly?
Moglibyśmy przenieść ciężkie obliczeniowo zadania do WebAssembly ( WASM ), formatu instrukcji binarnych, zaprojektowanego jako przenośny cel do kompilacji języków wysokiego poziomu, takich jak C/C++/Rust. Obsługa przeglądarki jest niezwykła, a ostatnio stała się opłacalna, ponieważ wywołania funkcji między JavaScript i WASM są coraz szybsze. Ponadto jest obsługiwany nawet w chmurze brzegowej Fastly.Oczywiście WebAssembly nie ma zastępować JavaScript, ale może go uzupełniać w przypadkach, gdy zauważysz „hogs” procesora. W przypadku większości aplikacji internetowych lepiej sprawdza się JavaScript, a WebAssembly najlepiej sprawdza się w przypadku aplikacji internetowych wymagających dużej mocy obliczeniowej , takich jak gry.
Jeśli chcesz dowiedzieć się więcej o WebAssembly:
- Lin Clark napisał obszerną serię dla WebAssembly, a Milica Mihajlija przedstawia ogólny przegląd tego, jak uruchomić natywny kod w przeglądarce, dlaczego warto to zrobić i co to wszystko oznacza dla JavaScript i przyszłości tworzenia stron internetowych.
- W jaki sposób wykorzystaliśmy WebAssembly, aby przyspieszyć działanie naszej aplikacji internetowej do 20x (studium przypadku) przedstawia studium przypadku, w którym powolne obliczenia JavaScript zostały zastąpione skompilowanym WebAssembly i przyniosły znaczną poprawę wydajności.
- Patrick Hamann mówi o rosnącej roli WebAssembly, obala niektóre mity na temat WebAssembly, bada jego wyzwania i możemy go dziś wykorzystać praktycznie w aplikacjach.
- Google Codelabs zapewnia wprowadzenie do WebAssembly, 60-minutowy kurs, w którym dowiesz się, jak wziąć natywny kod — w C i skompilować go do WebAssembly, a następnie wywołać go bezpośrednio z JavaScript.
- Alex Danilo wyjaśnił WebAssembly i jak to działa podczas swojej rozmowy Google I/O. Benedek Gagyi podzielił się również praktycznym studium przypadku dotyczącym WebAssembly, a konkretnie sposobu, w jaki zespół używa go jako formatu wyjściowego dla swojej bazy kodu C++ na iOS, Androida i na stronie internetowej.
Nadal nie masz pewności, kiedy użyć Web Workers, Web Assembly, strumieni, a może WebGL JavaScript API, aby uzyskać dostęp do GPU? Akceleracja JavaScript to krótki, ale pomocny przewodnik, który wyjaśnia, kiedy używać czego i dlaczego — również z podręcznym schematem blokowym i mnóstwem przydatnych zasobów.
- Czy udostępniamy starszy kod tylko starszym przeglądarkom?
Ponieważ ES2017 jest wyjątkowo dobrze obsługiwany w nowoczesnych przeglądarkach, możemy użyćbabelEsmPlugin, aby transpilować tylko funkcje ES2017+ nieobsługiwane przez nowoczesne przeglądarki docelowe.Houssein Djirdeh i Jason Miller opublikowali niedawno obszerny przewodnik na temat transpilacji i obsługi nowoczesnego i starszego kodu JavaScript, szczegółowo omawiający jego działanie z pakietami Webpack i Rollup oraz niezbędnymi narzędziami. Możesz także oszacować, ile kodu JavaScript możesz usunąć w swojej witrynie lub pakietach aplikacji.
Moduły JavaScript są obsługiwane we wszystkich głównych przeglądarkach, więc użyj
script type="module"aby umożliwić przeglądarkom z modułem ES ładowanie pliku, podczas gdy starsze przeglądarki mogą wczytywać starsze kompilacje za pomocąscript nomodule.W dzisiejszych czasach możemy pisać JavaScript oparty na modułach, który działa natywnie w przeglądarce, bez transpilatorów i bundlerów. Nagłówek
<link rel="modulepreload">umożliwia zainicjowanie wczesnego (i wysokim priorytetem) ładowania skryptów modułu. Zasadniczo jest to sprytny sposób na zmaksymalizowanie wykorzystania przepustowości poprzez poinformowanie przeglądarki o tym, co musi pobrać, aby nie utknęła z niczym do zrobienia podczas tych długich podróży w obie strony. Ponadto, Jake Archibald opublikował szczegółowy artykuł z problemami i rzeczami, o których należy pamiętać przy modułach ES, które warto przeczytać.
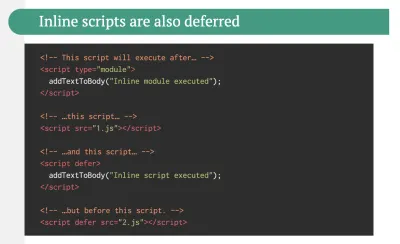
- Identyfikuj starszy kod i przepisuj go na nowo dzięki stopniowemu rozdzielaniu .
Długowieczne projekty mają tendencję do gromadzenia się kurzu i przestarzałego kodu. Sprawdź ponownie swoje zależności i oceń, ile czasu potrzeba na refaktoryzację lub przepisanie starszego kodu, który ostatnio sprawiał problemy. Oczywiście zawsze jest to duże przedsięwzięcie, ale gdy poznasz wpływ starszego kodu, możesz zacząć od stopniowego oddzielenia.Najpierw skonfiguruj metryki, które śledzą, czy stosunek wywołań starszego kodu pozostaje stały, czy spada, a nie wzrasta. Publicznie zniechęcaj zespół do korzystania z biblioteki i upewnij się, że Twój CI ostrzega programistów, jeśli jest używany w żądaniach ściągnięcia. wypełniacze mogą pomóc w przejściu ze starszego kodu do przepisanej bazy kodu, która wykorzystuje standardowe funkcje przeglądarki.
- Zidentyfikuj i usuń nieużywany CSS/JS .
Pokrycie kodu CSS i JavaScript w Chrome pozwala dowiedzieć się, który kod został wykonany/zastosowany, a który nie. Możesz rozpocząć rejestrowanie pokrycia, wykonywać czynności na stronie, a następnie eksplorować wyniki pokrycia kodu. Po wykryciu nieużywanego kodu znajdź te moduły i leniwe ładowanie za pomocą funkcjiimport()(zobacz cały wątek). Następnie powtórz profil pokrycia i sprawdź, czy teraz dostarcza mniej kodu przy początkowym załadowaniu.Możesz użyć Puppeteer, aby programowo zbierać pokrycie kodu. Chrome umożliwia również eksportowanie wyników pokrycia kodu. Jak zauważył Andy Davies, możesz chcieć zebrać pokrycie kodu zarówno dla nowoczesnych, jak i starszych przeglądarek.
Istnieje wiele innych przypadków użycia i narzędzi dla Puppettera, które mogą wymagać nieco większej ekspozycji:
- Przypadki użycia dla Puppeteer, takie jak np. automatyczne porównywanie wizualne czy monitorowanie nieużywanego CSS przy każdym buildzie,
- Receptury występów internetowych z Puppeteer,
- Przydatne narzędzia do nagrywania i generowania skryptów Pupeeteer i Playwright,
- Dodatkowo możesz nawet nagrywać testy bezpośrednio w DevTools,
- Kompleksowy przegląd Puppeteer autorstwa Nitay Neeman, z przykładami i przypadkami użycia.
Możemy użyć Puppeteer Recorder i Puppeteer Sandbox do nagrywania interakcji przeglądarki i generowania skryptów Puppeteer i Playwright. (duży podgląd) Ponadto purgecss, UnCSS i Helium mogą pomóc w usunięciu nieużywanych stylów z CSS. A jeśli nie masz pewności, czy gdzieś użyto podejrzanego fragmentu kodu, możesz skorzystać z rady Harry'ego Robertsa: utwórz przezroczysty GIF 1×1px dla konkretnej klasy i wrzuć go do katalogu
dead/, np./assets/img/dead/comments.gif.Następnie ustawiasz ten konkretny obraz jako tło w odpowiednim selektorze w swoim CSS, usiądź wygodnie i poczekaj kilka miesięcy, jeśli plik pojawi się w twoich dziennikach. Jeśli nie ma żadnych wpisów, nikt nie wyrenderował tego starszego komponentu na swoim ekranie: prawdopodobnie możesz to wszystko usunąć.
W przypadku działu „czuję się żądny przygód ” można nawet zautomatyzować gromadzenie nieużywanych arkuszy CSS za pomocą zestawu stron, monitorując DevTools za pomocą DevTools.
- Przytnij rozmiar swoich pakietów JavaScript.
Jak zauważył Addy Osmani, istnieje duża szansa, że wysyłasz pełne biblioteki JavaScript, gdy potrzebujesz tylko ułamka, wraz z przestarzałymi wypełnieniami dla przeglądarek, które ich nie potrzebują, lub po prostu zduplikowanym kodem. Aby uniknąć narzutu, rozważ użycie webpack-libs-optimisations, które usuwają nieużywane metody i wypełniacze podczas procesu kompilacji.Sprawdź i przejrzyj wypełniacze , które wysyłasz do starszych i nowoczesnych przeglądarek, i podejdź do nich bardziej strategicznie. Spójrz na polyfill.io, który jest usługą, która akceptuje żądania zestawu funkcji przeglądarki i zwraca tylko te wypełnienia, które są potrzebne przeglądarce, która wysyła żądanie.
Dodaj audyt pakietów również do swojego zwykłego przepływu pracy. Mogą istnieć lekkie alternatywy dla ciężkich bibliotek, które dodałeś lata temu, np. Moment.js (obecnie wycofany) można zastąpić:
- Natywne API internacjonalizacji,
- Day.js ze znajomym API i wzorcami Moment.js,
- data-fns lub
- Luxon.
- Możesz także użyć usługi Skypack Discover, która łączy rekomendacje pakietów recenzowanych przez ludzi z wyszukiwaniem skoncentrowanym na jakości.
Badania Benedikta Rotscha wykazały, że przejście z Moment.js na date-fns może skrócić około 300 ms dla First Paint na 3G i tanim telefonie komórkowym.
W przypadku audytu pakietu Bundlephobia może pomóc w określeniu kosztu dodania pakietu npm do pakietu. size-limit rozszerza podstawowe sprawdzanie rozmiaru pakietu o szczegóły dotyczące czasu wykonania JavaScript. Możesz nawet zintegrować te koszty z audytem Lighthouse Custom. Dotyczy to również ram. Po usunięciu lub przycięciu adaptera Vue MDC (Składniki materiałowe dla Vue) style spadają ze 194 KB do 10 KB.
Istnieje wiele innych narzędzi, które pomogą Ci podjąć świadomą decyzję dotyczącą wpływu Twoich zależności i realnych alternatyw:
- analizator-pakietów-webpack
- Eksplorator mapy źródłowej
- Pakiet Buddy
- Bundlefobia
- Analiza Webpack pokazuje, dlaczego w pakiecie znajduje się konkretny moduł.
- bundle-wizard buduje również mapę zależności dla całej strony.
- Wtyczka rozmiaru pakietu internetowego
- Koszt importu kodu wizualnego
Alternatywnie do dostarczenia całego frameworka, możesz przyciąć swój framework i skompilować go do surowego pakietu JavaScript , który nie wymaga dodatkowego kodu. Robi to Svelte, podobnie jak wtyczka Rawact Babel, która transpiluje komponenty React.js do natywnych operacji DOM w czasie budowania. Czemu? Cóż, jak wyjaśniają opiekunowie, „react-dom zawiera kod dla każdego możliwego komponentu/HTMLElement, który może być renderowany, w tym kod do renderowania przyrostowego, planowania, obsługi zdarzeń itp. Istnieją jednak aplikacje, które nie potrzebują wszystkich tych funkcji (na początku W przypadku takich aplikacji sensowne może być użycie natywnych operacji DOM do zbudowania interaktywnego interfejsu użytkownika”.
- Czy stosujemy częściowe nawilżenie?
Biorąc pod uwagę ilość JavaScript używanego w aplikacjach, musimy wymyślić sposoby wysyłania jak najmniejszej ilości do klienta. Jednym ze sposobów na zrobienie tego – i już to krótko omówiliśmy – jest częściowe nawodnienie. Pomysł jest dość prosty: zamiast wykonać SSR, a następnie wysłać całą aplikację do klienta, tylko małe fragmenty kodu JavaScript aplikacji zostaną wysłane do klienta, a następnie nawodnione. Możemy myśleć o tym jako o wielu małych aplikacjach React z wieloma korzeniami renderowania na statycznej stronie internetowej.W artykule „Przypadek częściowego nawodnienia (z Next i Preact)” Lukas Bombach wyjaśnia, w jaki sposób zespół odpowiedzialny za Welt.de, jeden z serwisów informacyjnych w Niemczech, osiągnął lepsze wyniki dzięki częściowemu nawodnieniu. Możesz także sprawdzić następne superwydajne repozytorium GitHub z wyjaśnieniami i fragmentami kodu.
Możesz również rozważyć alternatywne opcje:
- częściowe nawilżenie dzięki Preact i Eleveny,
- progresywne nawodnienie w repozytorium React GitHub,
- leniwe nawodnienie w Vue.js (repo GitHub),
- Importuj według wzorca interakcji, aby leniwie ładować niekrytyczne zasoby (np. komponenty, elementy osadzone), gdy użytkownik wchodzi w interakcję z interfejsem użytkownika, który tego potrzebuje.
Jason Miller opublikował robocze wersje demonstracyjne pokazujące, w jaki sposób można wdrożyć progresywne nawadnianie w React, więc możesz ich użyć od razu: demo 1, demo 2, demo 3 (dostępne również na GitHub). Dodatkowo możesz zajrzeć do biblioteki komponentów renderowanych w reakcji.
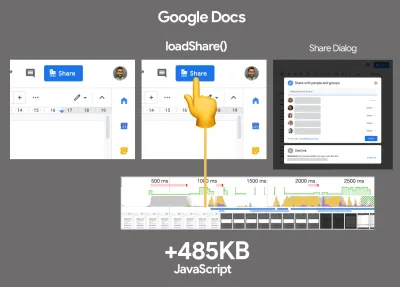
Importowanie podczas interakcji dla kodu własnego powinno być wykonywane tylko wtedy, gdy nie możesz wstępnie pobrać zasobów przed interakcją. (duży podgląd) - Czy zoptymalizowaliśmy strategię dla React/SPA?
Masz problemy z wydajnością w swojej aplikacji jednostronicowej? Jeremy Wagner zbadał wpływ wydajności frameworka po stronie klienta na różne urządzenia, podkreślając niektóre z implikacji i wskazówek, których możemy chcieć być świadomym podczas korzystania z jednego z nich.W rezultacie, oto strategia SPA, którą Jeremy sugeruje użyć dla frameworka React (ale nie powinna się znacząco zmieniać dla innych frameworków):
- Jeśli to możliwe, refaktoryzuj komponenty stanowe jako komponenty bezstanowe .
- Jeśli to możliwe, renderuj wstępnie komponenty bezstanowe, aby zminimalizować czas odpowiedzi serwera. Renderuj tylko na serwerze.
- W przypadku składników stanowych z prostą interaktywnością rozważ wstępne renderowanie lub renderowanie przez serwer tego składnika i zastąp jego interaktywność detektorami zdarzeń niezależnymi od struktury .
- Jeśli musisz nawodnić stanowe komponenty klienta, użyj leniwego nawodnienia na widoczność lub interakcję.
- W przypadku leniwie nawadnianych składników zaplanuj ich nawodnienie w czasie bezczynności głównego wątku za pomocą
requestIdleCallback.
Istnieje kilka innych strategii, które możesz chcieć zastosować lub przejrzeć:
- Zagadnienia dotyczące wydajności CSS-in-JS w aplikacjach React
- Zmniejsz rozmiar pakietu Next.js, ładując wypełnienie tylko wtedy, gdy jest to konieczne, używając dynamicznego importu i leniwego nawadniania.
- Sekrety JavaScript: opowieść o React, optymalizacji wydajności i wielowątkowości, długa 7-częściowa seria o ulepszaniu wyzwań związanych z interfejsem użytkownika za pomocą Reacta,
- Jak mierzyć wydajność React i jak profilować aplikacje React.
- Budowanie mobilnych animacji internetowych w React, fantastyczne przemówienie Alexa Holachka, wraz ze slajdami i repozytorium GitHub ( dzięki za wskazówkę, Addy! ).
- webpack-libs-optimizations to fantastyczne repozytorium GitHub z mnóstwem przydatnych optymalizacji związanych z wydajnością specyficznych dla Webpack. Utrzymywany przez Iwana Akulowa.
- Ulepszenia wydajności React w Notion, przewodnik Ivana Akulova o tym, jak poprawić wydajność w React, z mnóstwem przydatnych wskazówek, dzięki którym aplikacja będzie szybsza o około 30%.
- Wtyczka React Refresh Webpack (eksperymentalna) pozwala na przeładowanie na gorąco, które zachowuje stan komponentów i obsługuje hooki oraz komponenty funkcyjne.
- Uważaj na React Server Components o zerowej wielkości pakietu, nowy proponowany rodzaj komponentów, który nie będzie miał wpływu na wielkość pakietu. Projekt jest obecnie w fazie rozwoju, ale wszelkie opinie społeczności są bardzo mile widziane (świetne wyjaśnienie autorstwa Sophie Alpert).
- Czy korzystasz z predykcyjnego pobierania z wyprzedzeniem dla fragmentów JavaScript?
Moglibyśmy użyć heurystyki, aby zdecydować, kiedy wstępnie ładować fragmenty JavaScript. Guess.js to zestaw narzędzi i bibliotek, które wykorzystują dane Google Analytics do określania, którą stronę użytkownik z największym prawdopodobieństwem odwiedzi jako następną z danej strony. Na podstawie wzorców nawigacji użytkownika zebranych z Google Analytics lub innych źródeł Guess.js buduje model uczenia maszynowego do przewidywania i wstępnego pobierania kodu JavaScript, który będzie wymagany na każdej kolejnej stronie.W związku z tym każdy element interaktywny otrzymuje ocenę prawdopodobieństwa zaangażowania, a na podstawie tej oceny skrypt po stronie klienta decyduje o wstępnym pobraniu zasobu z wyprzedzeniem. Możesz zintegrować tę technikę z aplikacją Next.js, Angular i React, a także jest wtyczka Webpack, która automatyzuje proces instalacji.
Oczywiście możesz skłaniać przeglądarkę do wykorzystania niepotrzebnych danych i wstępnego pobierania niepożądanych stron, więc dobrym pomysłem jest dość ostrożne podejście do liczby wstępnie pobranych żądań. Dobrym przypadkiem użycia byłoby wstępne pobieranie skryptów walidacji wymaganych podczas realizacji zakupu lub spekulacyjne pobieranie z wyprzedzeniem, gdy krytyczne wezwanie do działania pojawi się w widocznym obszarze.
Potrzebujesz czegoś mniej wyrafinowanego? DNStradamus wykonuje wstępne pobieranie DNS dla linków wychodzących, gdy pojawiają się one w widoku. Quicklink, InstantClick i Instant.page to małe biblioteki, które automatycznie wstępnie pobierają łącza w oknie roboczym w czasie bezczynności, aby przyspieszyć ładowanie następnej strony. Quicklink pozwala wstępnie pobrać trasy routera React i Javascript; plus jest przemyślany na dane, więc nie pobiera z wyprzedzeniem w 2G lub jeśli włączony jest
Data-Saver. Podobnie jest z Instant.page, jeśli tryb jest ustawiony na używanie wstępnego pobierania rzutni (co jest ustawieniem domyślnym).Jeśli chcesz szczegółowo przyjrzeć się nauce predykcyjnego pobierania z wyprzedzeniem, Divya Tagtachian ma świetny wykład na temat The Art of Predictive Prefetch, obejmujący wszystkie opcje od początku do końca.
- Skorzystaj z optymalizacji dla docelowego silnika JavaScript.
Sprawdź, jakie silniki JavaScript dominują w Twojej bazie użytkowników, a następnie poznaj sposoby ich optymalizacji. Na przykład podczas optymalizacji pod kątem V8, który jest używany w przeglądarkach Blink, środowisku uruchomieniowym Node.js i Electronie, skorzystaj ze strumieniowego przesyłania skryptów dla skryptów monolitycznych.Przesyłanie strumieniowe skryptów umożliwia analizowanie skryptów
asynclubdefer scriptsw osobnym wątku w tle po rozpoczęciu pobierania, co w niektórych przypadkach skraca czas ładowania strony nawet o 10%. Practically, use<script defer>in the<head>, so that the browsers can discover the resource early and then parse it on the background thread.Caveat : Opera Mini doesn't support script deferment, so if you are developing for India or Africa,
deferwill be ignored, resulting in blocking rendering until the script has been evaluated (thanks Jeremy!) .You could also hook into V8's code caching as well, by splitting out libraries from code using them, or the other way around, merge libraries and their uses into a single script, group small files together and avoid inline scripts. Or perhaps even use v8-compile-cache.
When it comes to JavaScript in general, there are also some practices that are worth keeping in mind:
- Clean Code concepts for JavaScript, a large collection of patterns for writing readable, reusable, and refactorable code.
- You can Compress data from JavaScript with the CompressionStream API, eg to gzip before uploading data (Chrome 80+).
- Detached window memory leaks and Fixing memory leaks in web apps are detailed guides on how to find and fix tricky JavaScript memory leaks. Plus, you can use queryObjects(SomeConstructor) from the DevTools Console ( thanks, Mathias! ).
- Reexports are bad for loading and runtime performance, and avoiding them can help reduce the bundle size significantly.
- We can improve scroll performance with passive event listeners by setting a flag in the
optionsparameter. So browsers can scroll the page immediately, rather than after the listener has finished. (via Kayce Basques). - If you have any
scrollortouch*listeners, passpassive: trueto addEventListener. This tells the browser you're not planning to callevent.preventDefault()inside, so it can optimize the way it handles these events. (via Ivan Akulov) - We can achieve better JavaScript scheduling with isInputPending(), a new API that attempts to bridge the gap between loading and responsiveness with the concepts of interrupts for user inputs on the web, and allows for JavaScript to be able to check for input without yielding to the browser.
- You can also automatically remove an event listener after it has executed.
- Firefox's recently released Warp, a significant update to SpiderMonkey (shipped in Firefox 83), Baseline Interpreter and there are a few JIT Optimization Strategies available as well.
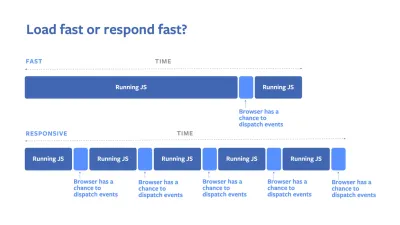
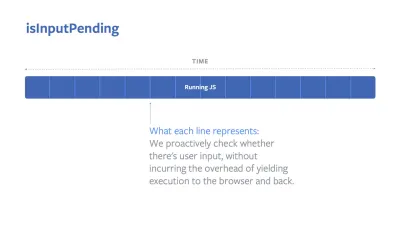
- Always prefer to self-host third-party assets.
Yet again, self-host your static assets by default. It's common to assume that if many sites use the same public CDN and the same version of a JavaScript library or a web font, then the visitors would land on our site with the scripts and fonts already cached in their browser, speeding up their experience considerably. However, it's very unlikely to happen.For security reasons, to avoid fingerprinting, browsers have been implementing partitioned caching that was introduced in Safari back in 2013, and in Chrome last year. So if two sites point to the exact same third-party resource URL, the code is downloaded once per domain , and the cache is "sandboxed" to that domain due to privacy implications ( thanks, David Calhoun! ). Hence, using a public CDN will not automatically lead to better performance.
Furthermore, it's worth noting that resources don't live in the browser's cache as long as we might expect, and first-party assets are more likely to stay in the cache than third-party assets. Therefore, self-hosting is usually more reliable and secure, and better for performance, too.
- Constrain the impact of third-party scripts.
With all performance optimizations in place, often we can't control third-party scripts coming from business requirements. Third-party-scripts metrics aren't influenced by end-user experience, so too often one single script ends up calling a long tail of obnoxious third-party scripts, hence ruining a dedicated performance effort. To contain and mitigate performance penalties that these scripts bring along, it's not enough to just defer their loading and execution and warm up connections via resource hints, iedns-prefetchorpreconnect.Currently 57% of all JavaScript code excution time is spent on third-party code. The median mobile site accesses 12 third-party domains , with a median of 37 different requests (or about 3 requests made to each third party).
Furthermore, these third-parties often invite fourth-party scripts to join in, ending up with a huge performance bottleneck, sometimes going as far as to the eigth-party scripts on a page. So regularly auditing your dependencies and tag managers can bring along costly surprises.
Another problem, as Yoav Weiss explained in his talk on third-party scripts, is that in many cases these scripts download resources that are dynamic. The resources change between page loads, so we don't necessarily know which hosts the resources will be downloaded from and what resources they would be.
Deferring, as shown above, might be just a start though as third-party scripts also steal bandwidth and CPU time from your app. We could be a bit more aggressive and load them only when our app has initialized.
/* Before */ const App = () => { return <div> <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> </div> } /* After */ const App = () => { const[isRendered, setRendered] = useState(false); useEffect(() => setRendered(true)); return <div> {isRendered ? <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> : null} </div> }In a fantastic post on "Reducing the Site-Speed Impact of Third-Party Tags", Andy Davies explores a strategy of minimizing the footprint of third-parties — from identifying their costs towards reducing their impact.
According to Andy, there are two ways tags impact site-speed — they compete for network bandwidth and processing time on visitors' devices, and depending on how they're implemented, they can delay HTML parsing as well. So the first step is to identify the impact that third-parties have, by testing the site with and without scripts using WebPageTest. With Simon Hearne's Request Map, we can also visualize third-parties on a page along with details on their size, type and what triggered their load.
Preferably self-host and use a single hostname, but also use a request map to exposes fourth-party calls and detect when the scripts change. You can use Harry Roberts' approach for auditing third parties and produce spreadsheets like this one (also check Harry's auditing workflow).
Afterwards, we can explore lightweight alternatives to existing scripts and slowly replace duplicates and main culprits with lighter options. Perhaps some of the scripts could be replaced with their fallback tracking pixel instead of the full tag.

Loading YouTube with facades, eg lite-youtube-embed that's significantly smaller than an actual YouTube player. (źródło obrazu) (duży podgląd) If it's not viable, we can at least lazy load third-party resources with facades, ie a static element which looks similar to the actual embedded third-party, but is not functional and therefore much less taxing on the page load. The trick, then, is to load the actual embed only on interaction .
For example, we can use:
- lite-vimeo-embed for the Vimeo player,
- lite-vimeo for the Vimeo player,
- lite-youtube-embed for the YouTube player,
- react-live-chat-loader for a live chat (case study, and another case-study),
- lazyframe for iframes.
One of the reasons why tag managers are usually large in size is because of the many simultaneous experiments that are running at the same time, along with many user segments, page URLs, sites etc., so according to Andy, reducing them can reduce both the download size and the time it takes to execute the script in the browser.
And then there are anti-flicker snippets. Third-parties such as Google Optimize, Visual Web Optimizer (VWO) and others are unanimous in using them. These snippets are usually injected along with running A/B tests : to avoid flickering between the different test scenarios, they hide the
bodyof the document withopacity: 0, then adds a function that gets called after a few seconds to bring theopacityback. This often results in massive delays in rendering due to massive client-side execution costs.
With A/B testing in use, customers would often see flickering like this one. Anti-Flicker snippets prevent that, but they also cost in performance. Via Andy Davies. (duży podgląd) Therefore keep track how often the anti-flicker timeout is triggered and reduce the timeout. Default blocks display of your page by up to 4s which will ruin conversion rates. According to Tim Kadlec, "Friends don't let friends do client side A/B testing". Server-side A/B testing on CDNs (eg Edge Computing, or Edge Slice Rerendering) is always a more performant option.
If you have to deal with almighty Google Tag Manager , Barry Pollard provides some guidelines to contain the impact of Google Tag Manager. Also, Christian Schaefer explores strategies for loading ads.
Uwaga: niektóre widżety innych firm ukrywają się przed narzędziami audytu, więc mogą być trudniejsze do wykrycia i zmierzenia. Aby przetestować strony trzecie, sprawdź podsumowania od dołu do góry na stronie Profil wydajności w DevTools, przetestuj, co się stanie, jeśli żądanie zostanie zablokowane lub upłynął limit czasu — w tym drugim przypadku możesz użyć serwera Blackhole WebPageTest
blackhole.webpagetest.orgmoże wskazywać określone domeny w plikuhosts.Jakie mamy wtedy opcje? Rozważ użycie funkcji Service Worker, ścigając pobieranie zasobu z limitem czasu , a jeśli zasób nie odpowie w określonym czasie, zwróć pustą odpowiedź, aby poinformować przeglądarkę, aby kontynuowała analizowanie strony. Możesz także rejestrować lub blokować żądania innych firm, które nie są skuteczne lub nie spełniają określonych kryteriów. Jeśli możesz, ładuj skrypt innej firmy z własnego serwera, a nie z serwera dostawcy i ładuj je leniwie.
Inną opcją jest ustanowienie polityki bezpieczeństwa treści (CSP) , aby ograniczyć wpływ skryptów innych firm, np. zabraniając pobierania plików audio lub wideo. Najlepszą opcją jest osadzenie skryptów przez
<iframe>, aby skrypty działały w kontekście iframe, a zatem nie miały dostępu do DOM strony i nie mogły uruchamiać dowolnego kodu w Twojej domenie. Elementy iframe można dodatkowo ograniczyć za pomocą atrybutusandbox, dzięki czemu można wyłączyć dowolną funkcjonalność, którą może wykonywać element iframe, np. uniemożliwić uruchamianie skryptów, zapobiegać alertom, przesyłaniu formularzy, wtyczek, dostępowi do górnej nawigacji i tak dalej.Możesz także kontrolować strony trzecie za pomocą linkowania wydajności w przeglądarce z zasadami funkcji, stosunkowo nową funkcją, która pozwala
włączyć lub wyłączyć niektóre funkcje przeglądarki w swojej witrynie. (Na marginesie, można go również użyć, aby uniknąć przewymiarowanych i niezoptymalizowanych obrazów, niewymiarowych multimediów, skryptów synchronizacji i innych). Obecnie obsługiwane w przeglądarkach opartych na technologii Blink. /* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'/* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'Ponieważ wiele skryptów innych firm działa w ramkach iframe, prawdopodobnie musisz być dokładny w ograniczaniu ich uprawnień. Elementy iframe w trybie piaskownicy są zawsze dobrym pomysłem, a każde z ograniczeń można znieść za pomocą kilku wartości
alloww atrybuciesandbox. Piaskownica jest obsługiwana prawie wszędzie, więc ogranicz skrypty stron trzecich do absolutnego minimum tego, co powinny one robić.
ThirdPartyWeb.Today grupuje wszystkie skrypty stron trzecich według kategorii (analityczne, społecznościowe, reklamowe, hostingowe, menedżer tagów itp.) i wizualizuje, ile czasu zajmuje wykonanie skryptów podmiotu (średnio). (duży podgląd) Rozważ użycie obserwatora skrzyżowania; które umożliwiłyby umieszczanie reklam w ramkach iframe przy jednoczesnym wysyłaniu zdarzeń lub uzyskiwaniu potrzebnych informacji z DOM (np. widoczność reklam). Uważaj na nowe zasady, takie jak polityka funkcji, limity rozmiaru zasobów i priorytet procesora/przepustowości, aby ograniczyć szkodliwe funkcje i skrypty internetowe, które spowalniałyby przeglądarkę, np. skrypty synchroniczne, synchroniczne żądania XHR, dokument.write i przestarzałe implementacje.
Wreszcie, wybierając usługę innej firmy, rozważ sprawdzenie ThirdPartyWeb.Today Patricka Hulce'a, usługi, która grupuje wszystkie skrypty firm zewnętrznych według kategorii (analityczne, społecznościowe, reklamowe, hostingowe, menedżer tagów itp.) i wizualizuje czas trwania skryptów podmiotu podjąć się wykonania (średnio). Oczywiście największe podmioty mają najgorszy wpływ na wydajność stron, na których się znajdują. Po prostu przeglądając stronę, dowiesz się, jakiego śladu wydajności powinieneś się spodziewać.
Ach, i nie zapominaj o zwykłych podejrzanych: zamiast widżetów stron trzecich do udostępniania, możemy użyć statycznych przycisków udostępniania społecznościowego (takich jak SSBG) i statycznych linków do interaktywnych map zamiast interaktywnych map.
- Ustaw poprawnie nagłówki pamięci podręcznej HTTP.
Buforowanie wydaje się być tak oczywistą rzeczą do zrobienia, ale może być dość trudne do zrobienia. Musimy dokładnie sprawdzić, czyexpires,max-age,cache-controli inne nagłówki pamięci podręcznej HTTP zostały poprawnie ustawione. Bez odpowiednich nagłówków pamięci podręcznej HTTP przeglądarki ustawią je automatycznie na 10% czasu, jaki upłynął odlast-modified, co kończy się potencjalnym niedostatecznym i nadmiernym buforowaniem.Ogólnie rzecz biorąc, zasoby powinny być buforowane przez bardzo krótki czas (jeśli mogą się zmienić) lub na czas nieokreślony (jeśli są statyczne) — w razie potrzeby możesz po prostu zmienić ich wersję w adresie URL. Można to nazwać strategią Cache-Forever, w której możemy przekazywać nagłówki
Cache-ControliExpiresdo przeglądarki, aby umożliwić wygaśnięcie zasobów tylko za rok. W związku z tym przeglądarka nawet nie zażądałaby zasobu, jeśli ma go w pamięci podręcznej.Wyjątkiem są odpowiedzi API (np.
/api/user). Aby zapobiec buforowaniu, możemy użyćprivate, no store, a niemax-age=0, no-store:Cache-Control: private, no-storeUżyj
Cache-control: immutable, aby uniknąć ponownej weryfikacji długich okresów istnienia pamięci podręcznej, gdy użytkownicy klikną przycisk ponownego ładowania. W przypadku przeładowania,immutablezapisuje żądania HTTP i poprawia czas ładowania dynamicznego kodu HTML, ponieważ nie konkurują one już z mnóstwem 304 odpowiedzi.Typowym przykładem, w którym chcemy użyć
immutable, są zasoby CSS/JavaScript z hashem w nazwie. W ich przypadku prawdopodobnie chcemy przechowywać pamięć podręczną tak długo, jak to możliwe i zapewnić, że nigdy nie zostaną ponownie zweryfikowane:Cache-Control: max-age: 31556952, immutableWedług badań Colina Bendella,
immutablezmniejsza przekierowania 304 o około 50%, ponieważ nawet przymax-agew użyciu, klienci nadal weryfikują i blokują się po odświeżeniu. Jest obsługiwany w przeglądarkach Firefox, Edge i Safari, a Chrome wciąż debatuje nad tym problemem.Według Web Almanac „jego użycie wzrosło do 3,5% i jest szeroko stosowane w odpowiedziach stron trzecich na Facebooku i Google”.

Kontrola pamięci podręcznej: Niezmienność zmniejsza 304s o około 50%, zgodnie z badaniami Colina Bendella w Cloudinary. (duży podgląd) Czy pamiętasz stare dobre „przestarzałe w trakcie-rewalidacji”? Gdy określimy czas buforowania za pomocą nagłówka odpowiedzi
Cache-Control(npCache-Control: max-age=604800), po wygaśnięciumax-ageprzeglądarka ponownie pobierze żądaną zawartość, powodując wolniejsze ładowanie strony. Tego spowolnienia można uniknąć za pomocąstale-while-revalidate; zasadniczo definiuje dodatkowe okno czasu, w którym pamięć podręczna może używać przestarzałego zasobu, o ile ponownie weryfikuje go asynchronicznie w tle. W ten sposób „ukrywa” opóźnienia (zarówno w sieci, jak i na serwerze) przed klientami.Na przełomie czerwca i lipca 2019 r. Chrome i Firefox uruchomiły obsługę
stale-while-revalidatew nagłówku HTTP Cache-Control, co w rezultacie powinno poprawić opóźnienia w ładowaniu kolejnych stron, ponieważ przestarzałe zasoby nie znajdują się już na ścieżce krytycznej. Wynik: zero RTT dla powtórnych widoków.Uważaj na nagłówek differ, szczególnie w odniesieniu do sieci CDN, i uważaj na warianty reprezentacji HTTP, które pomagają uniknąć dodatkowej podróży w obie strony w celu walidacji, gdy nowe żądanie różni się nieznacznie (ale nie znacząco) od wcześniejszych żądań ( dzięki, Guy i Mark ! ).
Sprawdź również, czy nie wysyłasz niepotrzebnych nagłówków (np
x-powered-by,pragma,x-ua-compatible,expires,X-XSS-Protectioni inne) oraz czy dołączasz przydatne nagłówki dotyczące bezpieczeństwa i wydajności (takie jakoContent-Security-Policy,X-Content-Type-Optionsi inne). Na koniec należy pamiętać o kosztach wydajności żądań CORS w aplikacjach jednostronicowych.Uwaga : często zakładamy, że zasoby z pamięci podręcznej są pobierane natychmiast, ale badania pokazują, że odzyskanie obiektu z pamięci podręcznej może zająć setki milisekund. W rzeczywistości, według Simona Hearne, „czasami sieć może być szybsza niż pamięć podręczna, a pobieranie zasobów z pamięci podręcznej może być kosztowne przy dużej liczbie zasobów z pamięci podręcznej (nie o rozmiarze pliku) i urządzeniach użytkownika. Na przykład: średnie pobieranie z pamięci podręcznej w systemie operacyjnym Chrome podwaja się z ~50ms z 5 buforowanymi zasobami do ~100ms z 25 zasobami”.
Poza tym często zakładamy, że rozmiar pakietu nie jest dużym problemem i użytkownicy będą go pobierać raz, a następnie korzystać z wersji z pamięci podręcznej. Jednocześnie, dzięki CI/CD, kilka razy dziennie wypychamy kod do produkcji, pamięć podręczna jest za każdym razem unieważniana, więc strategiczne podejście do pamięci podręcznej ma znaczenie.
Jeśli chodzi o buforowanie, istnieje wiele zasobów, które warto przeczytać:
- Cache-Control for Civilians, szczegółowe omówienie wszystkiego, co jest buforowane z Harrym Robertsem.
- Elementarz Heroku dotyczący nagłówków buforowania HTTP,
- Buforowanie najlepszych praktyk autorstwa Jake'a Archibalda,
- Elementarz buforowania HTTP autorstwa Ilyi Grigorik,
- Utrzymanie świeżości dzięki nieaktualnej weryfikacji przez Jeffa Posnicka.
- CS Visualized: CORS autorstwa Lydii Hallie jest świetnym objaśnieniem CORS, jak to działa i jak to zrozumieć.
- Mówiąc o CORS, oto małe przypomnienie o Polityce tego samego pochodzenia autorstwa Erica Portisa.
Optymalizacje dostawy
- Czy używamy
deferdo asynchronicznego ładowania krytycznego kodu JavaScript?
Gdy użytkownik żąda strony, przeglądarka pobiera kod HTML i konstruuje model DOM, następnie pobiera CSS i konstruuje CSSOM, a następnie generuje drzewo renderowania, dopasowując DOM i CSSOM. Jeśli jakiś JavaScript wymaga rozwiązania, przeglądarka nie rozpocznie renderowania strony , dopóki nie zostanie rozwiązany, co opóźni renderowanie. Jako programiści musimy wyraźnie powiedzieć przeglądarce, aby nie czekała i zaczęła renderować stronę. Sposobem na zrobienie tego dla skryptów jest użycie atrybutówdeferiasyncw HTML.W praktyce okazuje się, że lepiej używać
deferzamiastasync. Ach, jaka jest znowu różnica ? Według Steve'a Soudersa, gdy skryptyasyncdotrą, są one wykonywane natychmiast — gdy tylko skrypt jest gotowy. Jeśli dzieje się to bardzo szybko, na przykład, gdy skrypt jest już w pamięci podręcznej, może faktycznie zablokować parser HTML. W przypadkudeferprzeglądarka nie wykonuje skryptów, dopóki kod HTML nie zostanie przeanalizowany. Tak więc, o ile nie potrzebujesz JavaScript do wykonania przed rozpoczęciem renderowania, lepiej użyćdefer. Ponadto wiele plików asynchronicznych będzie wykonywanych w niedeterministycznej kolejności.Warto zauważyć, że istnieje kilka nieporozumień dotyczących
asyncidefer. Co najważniejsze,asyncnie oznacza, że kod będzie uruchamiany, gdy skrypt będzie gotowy; oznacza to, że zostanie uruchomiony, gdy skrypty będą gotowe i wszystkie wcześniejsze prace związane z synchronizacją zostaną wykonane. W słowach Harry'ego Robertsa: „Jeśli umieścisz skryptasyncpo skryptach synchronizacji, twój skryptasyncbędzie tak szybki, jak twój najwolniejszy skrypt synchronizacji”.Ponadto nie zaleca się używania zarówno
async, jak idefer. Nowoczesne przeglądarki obsługują oba, ale zawsze, gdy używane są oba atrybuty,asynczawsze wygrywa.Jeśli chcesz zagłębić się w więcej szczegółów, Milica Mihajlija napisała bardzo szczegółowy przewodnik na temat szybszego budowania DOM, omawiając szczegóły analizowania spekulatywnego, async i odroczenia.
- Lazy ładuje drogie komponenty za pomocą IntersectionObserver i wskazówek dotyczących priorytetów.
Ogólnie zaleca się leniwe ładowanie wszystkich kosztownych komponentów, takich jak ciężki JavaScript, filmy, elementy iframe, widżety i potencjalnie obrazy. Natywne leniwe ładowanie jest już dostępne dla obrazów i ramek iframe z atrybutemloading(tylko Chromium). Pod maską ten atrybut odracza ładowanie zasobu, dopóki nie osiągnie obliczonej odległości od rzutni.<!-- Lazy loading for images, iframes, scripts. Probably for images outside of the viewport. --> <img loading="lazy" ... /> <iframe loading="lazy" ... /> <!-- Prompt an early download of an asset. For critical images, eg hero images. --> <img loading="eager" ... /> <iframe loading="eager" ... />Ten próg zależy od kilku rzeczy, od typu pobieranego zasobu obrazu do efektywnego typu połączenia. Ale eksperymenty przeprowadzone przy użyciu Chrome na Androidzie sugerują, że w 4G 97,5% leniwych ładowanych obrazów poniżej części ekranu zostało w pełni załadowanych w ciągu 10 ms od momentu, gdy stały się widoczne, więc powinno być bezpieczne.
Możemy również użyć atrybutu
importance(highlublow) w elemencie<script>,<img>lub<link>(tylko Blink). W rzeczywistości jest to świetny sposób na zmianę priorytetów obrazów w karuzeli, a także zmianę priorytetów skryptów. Czasami jednak możemy potrzebować nieco bardziej szczegółowej kontroli.<!-- When the browser assigns "High" priority to an image, but we don't actually want that. --> <img src="less-important-image.svg" importance="low" ... /> <!-- We want to initiate an early fetch for a resource, but also deprioritize it. --> <link rel="preload" importance="low" href="/script.js" as="script" />Najbardziej wydajnym sposobem na nieco bardziej wyrafinowane ładowanie z opóźnieniem jest użycie interfejsu API Intersection Observer, który zapewnia sposób asynchronicznego obserwowania zmian w przecięciu elementu docelowego z elementem przodka lub widokiem dokumentu najwyższego poziomu. Zasadniczo musisz utworzyć nowy obiekt
IntersectionObserver, który otrzyma funkcję zwrotną i zestaw opcji. Następnie dodajemy cel do obserwacji.Funkcja wywołania zwrotnego jest wykonywana, gdy cel staje się widoczny lub niewidoczny, więc gdy przechwytuje rzutnię, możesz rozpocząć wykonywanie pewnych działań, zanim element stanie się widoczny. W rzeczywistości mamy szczegółową kontrolę nad tym, kiedy powinno zostać wywołane wywołanie zwrotne obserwatora, z
rootMargin(marginesem wokół korzenia) ithreshold(pojedyncza liczba lub tablica liczb, które wskazują, na jaki procent widoczności celu dążymy).Alejandro Garcia Anglada opublikował przydatny samouczek na temat tego, jak faktycznie go zaimplementować, Rahul Nanwani napisał szczegółowy post na temat leniwego ładowania obrazów pierwszego planu i tła, a Podstawy Google zawierają szczegółowy samouczek na temat leniwego ładowania obrazów i wideo za pomocą Intersection Observer.
Pamiętasz opowiadanie historii kierowane przez sztukę, długie czytanie z ruchomymi i lepkimi obiektami? Możesz również wdrożyć wydajne przewijanie za pomocą obserwatora skrzyżowań.
Sprawdź jeszcze raz, co jeszcze możesz leniwy ładować. Pomóc może nawet leniwe ładowanie ciągów tłumaczeniowych i emoji. W ten sposób Mobile Twitter zdołał osiągnąć 80% szybsze wykonanie JavaScript z nowego potoku internacjonalizacji.
Szybkie słowo ostrzeżenia: warto zauważyć, że leniwe ładowanie powinno być wyjątkiem, a nie regułą. Prawdopodobnie nie jest rozsądne leniwe ładowanie czegokolwiek, co faktycznie chcesz, aby ludzie zobaczyli szybko, np. obrazy stron produktów, obrazy bohaterów lub skrypt wymagany do tego, aby główna nawigacja stała się interaktywna.

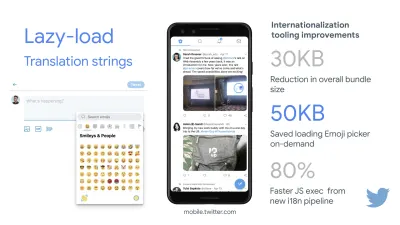
- Ładuj obrazy progresywnie.
Możesz nawet przenieść leniwe ładowanie na wyższy poziom, dodając progresywne ładowanie obrazu do swoich stron. Podobnie jak w przypadku Facebooka, Pinteresta, Medium i Wolta, możesz najpierw załadować obrazy niskiej jakości lub nawet rozmazane, a następnie w miarę wczytywania strony zastąpić je wersjami w pełnej jakości, korzystając z techniki BlurHash lub LQIP (Low Quality Image Placeholders). technika.Opinie różnią się, czy te techniki poprawiają wrażenia użytkownika, czy nie, ale zdecydowanie skraca to czas do First Contentful Paint. Możemy nawet zautomatyzować to za pomocą SQIP, który tworzy niskiej jakości wersję obrazu jako symbol zastępczy SVG lub Gradient Image Placeholders z liniowymi gradientami CSS.
Te symbole zastępcze mogą być osadzone w HTML, ponieważ naturalnie kompresują się dobrze za pomocą metod kompresji tekstu. W swoim artykule Dean Hume opisał, w jaki sposób można wdrożyć tę technikę za pomocą obserwatora przecięcia.
Awaria? Jeśli przeglądarka nie obsługuje obserwatora skrzyżowania, nadal możemy leniwie załadować wypełnienie lub od razu załadować obrazy. I jest na to nawet biblioteka.
Chcesz być bardziej wytworny? Możesz prześledzić swoje obrazy i użyć prymitywnych kształtów i krawędzi, aby utworzyć lekki symbol zastępczy SVG, załadować go najpierw, a następnie przejść z zastępczego obrazu wektorowego do (załadowanego) obrazu bitmapowego.
- Czy odkładasz renderowanie z
content-visibility?
W przypadku złożonego układu z dużą ilością bloków treści, obrazów i filmów dekodowanie danych i renderowanie pikseli może być dość kosztowną operacją — zwłaszcza na urządzeniach z niższej półki. Dziękicontent-visibility: automożemy skłonić przeglądarkę do pominięcia układu elementów potomnych, gdy kontener znajduje się poza widocznym obszarem.Na przykład możesz pominąć renderowanie stopki i późnych sekcji przy początkowym wczytywaniu:
footer { content-visibility: auto; contain-intrinsic-size: 1000px; /* 1000px is an estimated height for sections that are not rendered yet. */ }Zauważ, że widoczność treści: auto; zachowuje się jak przepełnienie: ukryty; , ale możesz to naprawić, stosując
padding-leftipadding-rightzamiast domyślnegomargin-left: auto;,margin-right: auto;i zadeklarowaną szerokość. Padding w zasadzie pozwala elementom przepełnić zawartość i wejść do padding-box bez opuszczania modelu pudełka jako całości i odcinania się.Pamiętaj też, że możesz wprowadzić trochę CLS, gdy nowa zawartość zostanie w końcu wyrenderowana, więc dobrym pomysłem jest użycie
contain-intrinsic-sizez odpowiednim rozmiarem symbolu zastępczego ( dzięki, Una! ).Thijs Terluin ma o wiele więcej szczegółów na temat obu właściwości i sposobu obliczania
contain-intrinsic-sizeprzez przeglądarkę, Malte Ubl pokazuje, jak można go obliczyć, a krótki film instruktażowy autorstwa Jake'a i Surmy wyjaśnia, jak to wszystko działa.A jeśli potrzebujesz bardziej szczegółowego, z CSS Containment, możesz ręcznie pominąć układ, styl i malowanie dla potomków węzła DOM, jeśli potrzebujesz tylko rozmiaru, wyrównania lub obliczonych stylów na innych elementach — lub element jest aktualnie poza płótnem.


content-visibility: auto do fragmentarycznych obszarów treści zapewnia 7-krotny wzrost wydajności renderowania przy początkowym wczytaniu. (duży podgląd)- Czy odraczasz dekodowanie za pomocą
decoding="async"?
Czasami treść pojawia się poza ekranem, ale chcemy mieć pewność, że jest dostępna, gdy klienci jej potrzebują — najlepiej, aby nie blokować niczego na ścieżce krytycznej, ale dekodować i renderować asynchronicznie. Możemy użyćdecoding="async", aby dać przeglądarce pozwolenie na dekodowanie obrazu poza głównym wątkiem, unikając wpływu użytkownika na czas procesora używany do dekodowania obrazu (poprzez Malte Ubl):<img decoding="async" … />Alternatywnie, w przypadku obrazów poza ekranem, możemy najpierw wyświetlić symbol zastępczy, a gdy obraz znajduje się w oknie widoku, używając IntersectionObserver, wywołać połączenie sieciowe, aby obraz został pobrany w tle. Ponadto możemy odroczyć renderowanie do czasu dekodowania za pomocą img.decode() lub pobrać obraz, jeśli interfejs API Image Decode nie jest dostępny.
Podczas renderowania obrazu możemy wykorzystać na przykład animacje zanikania. Katie Hempenius i Addy Osmani dzielą się więcej spostrzeżeniami w swoim przemówieniu Speed at Scale: Web Performance Tips and Tricks from the Trenches.
- Czy generujesz i obsługujesz krytyczne CSS?
Aby przeglądarki zaczęły renderować Twoją stronę tak szybko, jak to możliwe, powszechną praktyką stało się zbieranie całego kodu CSS wymaganego do rozpoczęcia renderowania pierwszej widocznej części strony (znanej jako „krytyczny CSS” lub „CSS na stronie ") i umieść go w wierszu w<head>strony, zmniejszając w ten sposób podróże w obie strony. Ze względu na ograniczony rozmiar pakietów wymienianych w fazie wolnego startu, Twój budżet na krytyczny CSS wynosi około 14 KB.Jeśli wyjdziesz poza to, przeglądarka będzie potrzebować dodatkowych objazdów, aby pobrać więcej stylów. CriticalCSS i Critical umożliwiają generowanie krytycznego CSS dla każdego używanego szablonu. Z naszego doświadczenia wynika jednak, że żaden automatyczny system nie był lepszy niż ręczne zbieranie krytycznych CSS dla każdego szablonu i rzeczywiście do takiego podejścia powróciliśmy ostatnio.
Następnie możesz wbudować krytyczny CSS i leniwie załadować resztę za pomocą wtyczki critters Webpack. Jeśli to możliwe, rozważ użycie warunkowego podejścia wbudowanego używanego przez Filament Group lub przekonwertuj kod wbudowany na statyczne zasoby w locie.
Jeśli aktualnie ładujesz swój pełny CSS asynchronicznie za pomocą bibliotek takich jak loadCSS, nie jest to naprawdę konieczne. Dzięki
media="print"możesz oszukać przeglądarkę, aby pobierała CSS asynchronicznie, ale stosowała się do środowiska ekranu po załadowaniu. ( dzięki Scott! )<!-- Via Scott Jehl. https://www.filamentgroup.com/lab/load-css-simpler/ --> <!-- Load CSS asynchronously, with low priority --> <link rel="stylesheet" href="full.css" media="print" onload="this.media='all'" />Podczas zbierania wszystkich krytycznych arkuszy CSS dla każdego szablonu często eksploruje się sam obszar „na górze strony”. Jednak w przypadku złożonych układów dobrym pomysłem może być uwzględnienie również podstaw układu, aby uniknąć ogromnych kosztów ponownego przeliczania i ponownego malowania, co w rezultacie pogorszy Twój wynik Core Web Vitals.
Co się stanie, jeśli użytkownik otrzyma adres URL, który prowadzi bezpośrednio do środka strony, ale CSS nie został jeszcze pobrany? W takim przypadku powszechne stało się ukrywanie treści niekrytycznych, np. z
opacity: 0;w wbudowanym CSS iopacity: 1w pełnym pliku CSS i wyświetlaj go, gdy CSS jest dostępny. Ma to jednak poważną wadę , ponieważ użytkownicy korzystający z wolnych połączeń mogą nigdy nie być w stanie odczytać zawartości strony. Dlatego lepiej jest, aby treść była zawsze widoczna, nawet jeśli nie jest ona odpowiednio wystylizowana.Umieszczenie krytycznego CSS (i innych ważnych zasobów) w osobnym pliku w domenie głównej przynosi korzyści, czasami nawet większe niż inline, ze względu na buforowanie. Chrome spekulatywnie otwiera drugie połączenie HTTP z domeną główną podczas żądania strony, co eliminuje potrzebę połączenia TCP w celu pobrania tego kodu CSS. Oznacza to, że możesz utworzyć zestaw krytycznych plików -CSS (np . krytyczna-strona -domowa.css , krytyczna-strona-produktu.css itp.) i udostępniać je ze swojego katalogu głównego, bez konieczności ich inline. ( dzięki Filip! )
Słowo ostrzeżenia: w przypadku HTTP/2 krytyczne CSS mogą być przechowywane w osobnym pliku CSS i dostarczane za pośrednictwem serwera push bez rozdęcia kodu HTML. Haczyk polega na tym, że pushowanie serwerów było kłopotliwe ze względu na wiele problemów i wyścigów w różnych przeglądarkach. Nigdy nie był konsekwentnie wspierany i miał pewne problemy z buforowaniem (patrz slajd 114 i następne prezentacji Hoomana Beheshtiego).
Skutek może w rzeczywistości być negatywny i nadwyrężyć bufory sieciowe, uniemożliwiając dostarczanie prawdziwych ramek w dokumencie. Nie było więc zaskoczeniem, że na razie Chrome planuje usunąć wsparcie dla Server Push.
- Poeksperymentuj z przegrupowaniem reguł CSS.
Przyzwyczailiśmy się do krytycznego CSS, ale jest kilka optymalizacji, które mogą wyjść poza to. Harry Roberts przeprowadził niezwykłe badania z dość zaskakującymi wynikami. Na przykład dobrym pomysłem może być podzielenie głównego pliku CSS na poszczególne zapytania o media. W ten sposób przeglądarka pobierze krytyczny kod CSS o wysokim priorytecie, a wszystko inne o niskim priorytecie — całkowicie poza ścieżką krytyczną.Unikaj również umieszczania
<link rel="stylesheet" />przed fragmentamiasync. Jeśli skrypty nie zależą od arkuszy stylów, rozważ umieszczenie skryptów blokujących nad stylami blokującymi. Jeśli tak, podziel ten JavaScript na dwie części i załaduj go po obu stronach swojego CSS.Scott Jehl rozwiązał inny interesujący problem, buforując wbudowany plik CSS z pracownikiem serwisu, co jest częstym problemem znanym w przypadku krytycznego CSS. Zasadniczo dodajemy atrybut ID do elementu
style, aby można go było łatwo znaleźć za pomocą JavaScript, a następnie mały fragment JavaScript znajduje ten CSS i używa Cache API do przechowywania go w lokalnej pamięci podręcznej przeglądarki (z typem zawartościtext/css) do użycia na kolejnych stronach. Aby uniknąć wstawiania na kolejnych stronach i zamiast tego odwoływać się do zasobów z pamięci podręcznej na zewnątrz, podczas pierwszej wizyty w witrynie ustawiamy plik cookie. Voila!Warto zauważyć, że stylizacja dynamiczna również może być kosztowna, ale zwykle tylko w przypadkach, gdy polegasz na setkach współbieżnie renderowanych skomponowanych komponentów. Jeśli więc używasz CSS-in-JS, upewnij się, że Twoja biblioteka CSS-in-JS optymalizuje wykonanie, gdy Twój CSS nie jest uzależniony od motywu lub rekwizytów i nie nadmiernie komponuj stylizowanych komponentów . Aggelos Arvanitakis udostępnia więcej informacji na temat kosztów wydajności CSS-in-JS.
- Czy przesyłasz odpowiedzi?
Często zapominane i zaniedbywane strumienie zapewniają interfejs do odczytywania lub zapisywania asynchronicznych porcji danych, których tylko podzbiór może być dostępny w pamięci w danym momencie. Zasadniczo umożliwiają stronie, która wysłała pierwotne żądanie, rozpoczęcie pracy z odpowiedzią, gdy tylko dostępna będzie pierwsza porcja danych, i używają parserów zoptymalizowanych pod kątem przesyłania strumieniowego w celu stopniowego wyświetlania zawartości.Moglibyśmy stworzyć jeden strumień z wielu źródeł. Na przykład, zamiast udostępniać pustą powłokę interfejsu użytkownika i pozwalać na jej wypełnienie przez JavaScript, można pozwolić, aby Service Worker utworzył strumień , w którym powłoka pochodzi z pamięci podręcznej, ale treść pochodzi z sieci. Jak zauważył Jeff Posnick, jeśli Twoja aplikacja internetowa jest obsługiwana przez system CMS, który renderuje kod HTML przez serwer, łącząc ze sobą częściowe szablony, model ten przekłada się bezpośrednio na wykorzystanie odpowiedzi strumieniowych, przy czym logika szablonów jest replikowana w procesie roboczym usługi zamiast na serwerze. Artykuł Jake'a Archibalda „The Year of Web Streams” wyjaśnia, jak dokładnie można go zbudować. Wzrost wydajności jest dość zauważalny.
Jedną z ważnych zalet przesyłania strumieniowego całej odpowiedzi HTML jest to, że kod HTML renderowany podczas początkowego żądania nawigacji może w pełni korzystać z parsera strumieniowego HTML przeglądarki. Fragmenty kodu HTML wstawiane do dokumentu po załadowaniu strony (co jest typowe w przypadku treści wypełnianych przez JavaScript) nie mogą skorzystać z tej optymalizacji.
Obsługa przeglądarki? Nadal osiągamy to dzięki częściowemu wsparciu w Chrome, Firefox, Safari i Edge, które obsługuje API i Service Workery obsługiwane we wszystkich nowoczesnych przeglądarkach. A jeśli znów poczujesz się na siłach, możesz sprawdzić eksperymentalną implementację żądań przesyłania strumieniowego, która pozwala rozpocząć wysyłanie żądania przy jednoczesnym generowaniu treści. Dostępny w Chrome 85.
- Rozważ włączenie obsługi połączeń komponentów.
Dane mogą być drogie, a wraz z rosnącym obciążeniem musimy szanować użytkowników, którzy decydują się na oszczędzanie danych podczas uzyskiwania dostępu do naszych witryn lub aplikacji. Nagłówek żądania podpowiedzi klienta Save-Data umożliwia nam dostosowanie aplikacji i ładunku do użytkowników o ograniczonych kosztach i wydajności.W rzeczywistości możesz przepisać żądania obrazów o wysokiej rozdzielczości na obrazy o niskiej rozdzielczości, usunąć czcionki internetowe, fantazyjne efekty paralaksy, podgląd miniatur i nieskończone przewijanie, wyłączyć autoodtwarzanie wideo, push serwera, zmniejszyć liczbę wyświetlanych elementów i obniżyć jakość obrazu lub nawet zmienić sposób dostarczania znaczników. Tim Vereecke opublikował bardzo szczegółowy artykuł na temat strategii data-s(h)aver, który zawiera wiele opcji oszczędzania danych.
Być może zastanawiasz się, kto używa
save-data? 18% globalnych użytkowników Chrome na Androida ma włączony tryb uproszczony (z włączonymSave-Data), a liczba ta prawdopodobnie będzie wyższa. Według badań Simona Hearne'a wskaźnik opt-in jest najwyższy na tańszych urządzeniach, ale istnieje wiele wartości odstających. Na przykład: użytkownicy w Kanadzie mają wskaźnik zgody na poziomie ponad 34% (w porównaniu do ~7% w USA), a użytkownicy najnowszego flagowego modelu Samsunga mają prawie 18% na całym świecie.Gdy włączony jest tryb
Save-Data, Chrome Mobile zapewnia zoptymalizowane wrażenia, tj. dostęp do sieci proxy z odroczonymi skryptami , wymuszonefont-display: swapi wymuszone leniwe ładowanie. Po prostu rozsądniej jest zbudować środowisko samodzielnie, niż polegać na przeglądarce, aby dokonać tych optymalizacji.Nagłówek jest obecnie obsługiwany tylko w Chromium, w wersji Chrome na Androida lub za pośrednictwem rozszerzenia Data Saver na urządzeniu stacjonarnym. Wreszcie, możesz również użyć interfejsu Network Information API, aby dostarczać kosztowne moduły JavaScript, obrazy i filmy w wysokiej rozdzielczości w oparciu o typ sieci. Network Information API, a konkretnie
navigator.connection.effectiveType. EffectiveType, używają wartościRTT,downlink,effectiveType(i kilku innych), aby zapewnić reprezentację połączenia i dane, które użytkownicy mogą obsłużyć.W tym kontekście Max Bock mówi o komponentach obsługujących połączenia, a Addy Osmani o adaptacyjnej obsłudze modułów. Na przykład w React moglibyśmy napisać komponent, który renderuje się inaczej dla różnych typów połączeń. Jak zasugerował Max, komponent
<Media />w artykule z wiadomościami może generować:-
Offline: symbol zastępczy z tekstemalt, - tryb
2G/save-data: obraz o niskiej rozdzielczości, -
3Gna ekranie innym niż Retina: obraz o średniej rozdzielczości, -
3Gna ekranach Retina: obraz Retina o wysokiej rozdzielczości, -
4G: wideo HD.
Dean Hume zapewnia praktyczną implementację podobnej logiki za pomocą service workera. W przypadku wideo moglibyśmy domyślnie wyświetlić plakat wideo, a następnie wyświetlić ikonę „Odtwórz”, a także powłokę odtwarzacza wideo, metadane wideo itp. Przy lepszych połączeniach. Jako rozwiązanie awaryjne dla nieobsługujących przeglądarek moglibyśmy nasłuchiwać zdarzenia
canplaythroughi użyćPromise.race()do przekroczenia limitu czasu ładowania źródła, jeśli zdarzeniecanplaythroughnie uruchomi się w ciągu 2 sekund.Jeśli chcesz zanurkować nieco głębiej, oto kilka zasobów na początek:
- Addy Osmani pokazuje, jak zaimplementować serwowanie adaptacyjne w React.
- React Adaptive Loading Hooks & Utilities dostarcza fragmenty kodu dla Reacta,
- Netanel Basel bada komponenty obsługujące połączenia w Angular,
- Theodore Vorilas opowiada, jak działa Serving Adaptive Components za pomocą Network Information API w Vue.
- Umar Hansa pokazuje, jak selektywnie pobierać/wykonywać drogi JavaScript.
-
- Rozważ dostosowanie swoich komponentów do pamięci urządzenia.
Połączenie sieciowe daje nam jednak tylko jedno spojrzenie na kontekst użytkownika. Idąc dalej, możesz również dynamicznie dostosowywać zasoby na podstawie dostępnej pamięci urządzenia za pomocą interfejsu API pamięci urządzenia.navigator.deviceMemoryreturns how much RAM the device has in gigabytes, rounded down to the nearest power of two. The API also features a Client Hints Header,Device-Memory, that reports the same value.Bonus : Umar Hansa shows how to defer expensive scripts with dynamic imports to change the experience based on device memory, network connectivity and hardware concurrency.
- Warm up the connection to speed up delivery.
Use resource hints to save time ondns-prefetch(which performs a DNS lookup in the background),preconnect(which asks the browser to start the connection handshake (DNS, TCP, TLS) in the background),prefetch(which asks the browser to request a resource) andpreload(which prefetches resources without executing them, among other things). Well supported in modern browsers, with support coming to Firefox soon.Remember
prerender? The resource hint used to prompt browser to build out the entire page in the background for next navigation. The implementations issues were quite problematic, ranging from a huge memory footprint and bandwidth usage to multiple registered analytics hits and ad impressions.Unsurprinsingly, it was deprecated, but the Chrome team has brought it back as NoState Prefetch mechanism. In fact, Chrome treats the
prerenderhint as a NoState Prefetch instead, so we can still use it today. As Katie Hempenius explains in that article, "like prerendering, NoState Prefetch fetches resources in advance ; but unlike prerendering, it does not execute JavaScript or render any part of the page in advance."NoState Prefetch only uses ~45MiB of memory and subresources that are fetched will be fetched with an
IDLENet Priority. Since Chrome 69, NoState Prefetch adds the header Purpose: Prefetch to all requests in order to make them distinguishable from normal browsing.Also, watch out for prerendering alternatives and portals, a new effort toward privacy-conscious prerendering, which will provide the inset
previewof the content for seamless navigations.Using resource hints is probably the easiest way to boost performance , and it works well indeed. When to use what? As Addy Osmani has explained, it's reasonable to preload resources that we know are very likely to be used on the current page and for future navigations across multiple navigation boundaries, eg Webpack bundles needed for pages the user hasn't visited yet.
Addy's article on "Loading Priorities in Chrome" shows how exactly Chrome interprets resource hints, so once you've decided which assets are critical for rendering, you can assign high priority to them. To see how your requests are prioritized, you can enable a "priority" column in the Chrome DevTools network request table (as well as Safari).
Most of the time these days, we'll be using at least
preconnectanddns-prefetch, and we'll be cautious with usingprefetch,preloadandprerender. Note that even withpreconnectanddns-prefetch, the browser has a limit on the number of hosts it will look up/connect to in parallel, so it's a safe bet to order them based on priority ( thanks Philip Tellis! ).Since fonts usually are important assets on a page, sometimes it's a good idea to request the browser to download critical fonts with
preload. However, double check if it actually helps performance as there is a puzzle of priorities when preloading fonts: aspreloadis seen as high importance, it can leapfrog even more critical resources like critical CSS. ( thanks, Barry! )<!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /><!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" />Since
<link rel="preload">accepts amediaattribute, you could choose to selectively download resources based on@mediaquery rules, as shown above.Furthermore, we can use
imagesrcsetandimagesizesattributes to preload late-discovered hero images faster, or any images that are loaded via JavaScript, eg movie posters:<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image><!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image>We can also preload the JSON as fetch , so it's discovered before JavaScript gets to request it:
<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="fetch" href="foo.com/api/movies.json" crossorigin>We could also load JavaScript dynamically, effectively for lazy execution of the script.
/* Adding a preload hint to the head */ var preload = document.createElement("link"); link.href = "myscript.js"; link.rel = "preload"; link.as = "script"; document.head.appendChild(link); /* Injecting a script when we want it to execute */ var script = document.createElement("script"); script.src = "myscript.js"; document.body.appendChild(script);A few gotchas to keep in mind:
preloadis good for moving the start download time of an asset closer to the initial request, but preloaded assets land in the memory cache which is tied to the page making the request.preloadplays well with the HTTP cache: a network request is never sent if the item is already there in the HTTP cache.Hence, it's useful for late-discovered resources, hero images loaded via
background-image, inlining critical CSS (or JavaScript) and pre-loading the rest of the CSS (or JavaScript).
Preload important images early; no need to wait on JavaScript to discover them. (Image credit: “Preload Late-Discovered Hero Images Faster” by Addy Osmani) (Large preview) A
preloadtag can initiate a preload only after the browser has received the HTML from the server and the lookahead parser has found thepreloadtag. Preloading via the HTTP header could be a bit faster since we don't to wait for the browser to parse the HTML to start the request (it's debated though).Early Hints will help even further, enabling preload to kick in even before the response headers for the HTML are sent (on the roadmap in Chromium, Firefox). Plus, Priority Hints will help us indicate loading priorities for scripts.
Beware : if you're using
preload,asmust be defined or nothing loads, plus preloaded fonts without thecrossoriginattribute will double fetch. If you're usingprefetch, beware of theAgeheader issues in Firefox.
- Use service workers for caching and network fallbacks.
No performance optimization over a network can be faster than a locally stored cache on a user's machine (there are exceptions though). If your website is running over HTTPS, we can cache static assets in a service worker cache and store offline fallbacks (or even offline pages) and retrieve them from the user's machine, rather than going to the network.As suggested by Phil Walton, with service workers, we can send smaller HTML payloads by programmatically generating our responses. A service worker can request just the bare minimum of data it needs from the server (eg an HTML content partial, a Markdown file, JSON data, etc.), and then it can programmatically transform that data into a full HTML document. So once a user visits a site and the service worker is installed, the user will never request a full HTML page again. The performance impact can be quite impressive.
Browser support? Service workers are widely supported and the fallback is the network anyway. Does it help boost performance ? Oh yes, it does. And it's getting better, eg with Background Fetch allowing background uploads/downloads via a service worker as well.
There are a number of use cases for a service worker. For example, you could implement "Save for offline" feature, handle broken images, introduce messaging between tabs or provide different caching strategies based on request types. In general, a common reliable strategy is to store the app shell in the service worker's cache along with a few critical pages, such as offline page, frontpage and anything else that might be important in your case.
There are a few gotchas to keep in mind though. With a service worker in place, we need to beware range requests in Safari (if you are using Workbox for a service worker it has a range request module). If you ever stumbled upon
DOMException: Quota exceeded.error in the browser console, then look into Gerardo's article When 7KB equals 7MB.Jak pisze Gerardo: „Jeśli tworzysz progresywną aplikację internetową i doświadczasz nadętej pamięci podręcznej, gdy Twój Service Worker buforuje statyczne zasoby obsługiwane z sieci CDN, upewnij się, że istnieje odpowiedni nagłówek odpowiedzi CORS dla zasobów z różnych źródeł, nie przechowujesz w pamięci podręcznej nieprzezroczystych odpowiedzi z pracownikiem serwisu przypadkowo włączasz zasoby obrazów z różnych źródeł w trybie CORS, dodając atrybut
crossorigindo tagu<img>”.Istnieje wiele wspaniałych zasobów , aby rozpocząć pracę z pracownikami usług:
- Nastawienie Service Worker, które pomaga zrozumieć, jak pracownicy usług pracują za kulisami i co należy zrozumieć podczas ich tworzenia.
- Chris Ferdinandi udostępnia świetną serię artykułów na temat pracowników usług, wyjaśniając, jak tworzyć aplikacje offline i obejmując różne scenariusze, od zapisywania ostatnio przeglądanych stron w trybie offline po ustawianie daty wygaśnięcia elementów w pamięci podręcznej pracowników usług.
- Pułapki Service Worker i najlepsze praktyki, z kilkoma wskazówkami na temat zakresu, opóźniające rejestrację Service Workera i buforowanie Service Worker.
- Świetna seria Ire Aderinokuna na temat „Najpierw offline” z usługą Service Worker, ze strategią wstępnego buforowania powłoki aplikacji.
- Service Worker: wprowadzenie z praktycznymi wskazówkami dotyczącymi korzystania z narzędzia Service Worker w celu uzyskania bogatych środowisk offline, okresowych synchronizacji w tle i powiadomień push.
- Zawsze warto odwołać się do starej dobrej książki kucharskiej Offline Jake'a Archibalda z wieloma przepisami na to, jak upiec własnego pracownika serwisu.
- Workbox to zestaw bibliotek Service Worker stworzonych specjalnie do tworzenia progresywnych aplikacji internetowych.
- Czy używasz pracowników serwerów na CDN/Edge, np. do testów A/B?
W tym momencie jesteśmy przyzwyczajeni do uruchamiania Service Workerów na kliencie, ale dzięki CDN implementującym je na serwerze, moglibyśmy ich użyć również do poprawienia wydajności na brzegu.Na przykład w testach A/B, gdy HTML musi zmieniać swoją zawartość dla różnych użytkowników, do obsługi logiki możemy użyć Service Workerów na serwerach CDN. Moglibyśmy również przesyłać strumieniowo przepisywanie HTML, aby przyspieszyć witryny korzystające z czcionek Google.
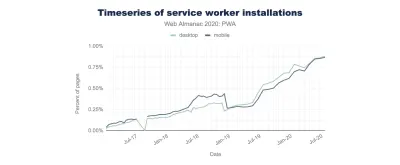
- Zoptymalizuj wydajność renderowania.
Ilekroć aplikacja jest powolna, od razu jest to zauważalne. Musimy więc upewnić się, że nie ma opóźnień podczas przewijania strony lub gdy element jest animowany, i że stale osiągasz 60 klatek na sekundę. Jeśli nie jest to możliwe, to przynajmniej zapewnienie spójności klatek na sekundę jest lepsze niż mieszany zakres od 60 do 15. Użyj zmiany w CSSwill-changeaby poinformować przeglądarkę, które elementy i właściwości ulegną zmianie.W każdym przypadku debuguj niepotrzebne przemalowania w DevTools:
- Mierz wydajność renderowania w czasie wykonywania. Sprawdź kilka przydatnych wskazówek, jak nadać temu sens.
- Aby rozpocząć, zapoznaj się z bezpłatnym kursem Udacity Paula Lewisa na temat optymalizacji renderowania w przeglądarce oraz artykułem Georgy'ego Marchuka o malowaniu w przeglądarce i rozważaniach dotyczących wydajności sieci.
- Włącz Flashowanie farby w "Więcej narzędzi → Renderowanie → Flashowanie farby" w Firefox DevTools.
- W React DevTools zaznacz „Podświetl aktualizacje” i włącz „Zapisuj, dlaczego każdy komponent został wyrenderowany”,
- Możesz także użyć opcji Dlaczego renderowałeś, więc gdy komponent jest ponownie renderowany, flash powiadomi Cię o zmianie.
Czy używasz układu murarskiego? Pamiętaj, że już wkrótce może być w stanie zbudować układ Masonry z samą siatką CSS.
Jeśli chcesz zagłębić się w ten temat, Nolan Lawson podzielił się w swoim artykule sztuczkami, aby dokładnie zmierzyć wydajność układu, a Jason Miller również zasugerował alternatywne techniki. Mamy również mały artykuł autorstwa Sergeya Chikuyonoka o tym, jak uzyskać prawidłową animację GPU.

Przeglądarki mogą tanio animować transformację i nieprzezroczystość. Wyzwalacze CSS są przydatne do sprawdzania, czy CSS wyzwala zmiany układu lub ponownego przepływu. (Źródło zdjęcia: Addy Osmani) (duży podgląd) Uwaga : zmiany w warstwach skomponowanych za pomocą GPU są najtańsze, więc jeśli możesz uciec, uruchamiając tylko komponowanie przez
opacityitransform, będziesz na dobrej drodze. Anna Migas przedstawiła również wiele praktycznych porad w swoim przemówieniu na temat debugowania wydajności renderowania interfejsu użytkownika. Aby dowiedzieć się, jak debugować wydajność malowania w DevTools, obejrzyj film dotyczący audytu wydajności malowania firmy Umar. - Czy zoptymalizowałeś pod kątem postrzeganej wydajności?
Chociaż kolejność wyświetlania komponentów na stronie i strategia udostępniania zasobów przeglądarce ma znaczenie, nie powinniśmy również lekceważyć roli postrzeganej wydajności. Koncepcja dotyczy psychologicznych aspektów oczekiwania, w zasadzie utrzymywania zajętych lub zaangażowanych klientów, podczas gdy dzieje się coś innego. Tutaj w grę wchodzą zarządzanie percepcją, wyprzedzający start, wczesne ukończenie i zarządzanie tolerancją.Co to wszystko znaczy? Podczas wczytywania zasobów możemy zawsze starać się być o krok przed klientem, dzięki czemu obsługa jest szybka, gdy w tle dzieje się całkiem sporo. Aby utrzymać zaangażowanie klienta, zamiast wskaźników wczytywania możemy testować szkieletowe ekrany (demo wdrożeniowe), dodawać przejścia/animacje i w zasadzie oszukiwać UX, gdy nie ma już nic do optymalizacji.
W swoim studium przypadku The Art of UI Skeletons, Kumar McMillan dzieli się kilkoma pomysłami i technikami symulacji dynamicznych list, tekstu i ekranu końcowego, a także rozważania myślenia szkieletowego w React.
Uważaj jednak: ekrany szkieletowe powinny zostać przetestowane przed wdrożeniem, ponieważ niektóre testy wykazały, że ekrany szkieletowe mogą działać najgorzej według wszystkich wskaźników.
- Czy zapobiegasz przesunięciom układu i ponownemu malowaniu?
W sferze postrzeganej wydajności prawdopodobnie jednym z bardziej destrukcyjnych doświadczeń jest przesunięcie układu lub zmiany układu stron spowodowane przeskalowanymi obrazami i filmami, czcionkami internetowymi, wstrzykiwanymi reklamami lub niedawno odkrytymi skryptami, które wypełniają komponenty rzeczywistą treścią. W rezultacie klient może zacząć czytać artykuł tylko po to, by przerwać mu skok układu nad obszarem czytania. Doświadczenie jest często nagłe i dość dezorientujące: i prawdopodobnie jest to przypadek ładowania priorytetów, które należy ponownie rozważyć.Społeczność opracowała kilka technik i obejścia, aby uniknąć zmian. Ogólnie rzecz biorąc, dobrym pomysłem jest unikanie wstawiania nowej treści nad istniejącą , chyba że dzieje się to w odpowiedzi na interakcję użytkownika. Zawsze ustawiaj atrybuty szerokości i wysokości na obrazach, aby nowoczesne przeglądarki przydzielały pole i domyślnie rezerwowały miejsce (Firefox, Chrome).
Zarówno w przypadku obrazów, jak i filmów możemy użyć symbolu zastępczego SVG, aby zarezerwować pole wyświetlania, w którym pojawią się multimedia. Oznacza to, że obszar zostanie odpowiednio zarezerwowany, gdy będziesz musiał również zachować jego proporcje. Możemy również używać symboli zastępczych lub obrazów zastępczych dla reklam i treści dynamicznych, a także wstępnie przydzielać boksy układu.
Zamiast leniwego ładowania obrazów za pomocą zewnętrznych skryptów, rozważ użycie natywnego leniwego ładowania lub hybrydowego leniwego ładowania, gdy ładujemy zewnętrzny skrypt tylko wtedy, gdy natywne ładowanie z opóźnieniem nie jest obsługiwane.
Jak wspomniano powyżej, zawsze grupuj odświeżenia czcionek internetowych i przechodź od wszystkich czcionek zastępczych do wszystkich czcionek internetowych naraz — po prostu upewnij się, że ten przełącznik nie jest zbyt gwałtowny, dostosowując wysokość linii i odstępy między czcionkami za pomocą funkcji dopasowania stylu czcionki .
Aby przesłonić metryki czcionek dla czcionki zastępczej, aby emulować czcionkę internetową, możemy użyć deskryptorów @font-face do nadpisania metryk czcionek (demo, włączone w Chrome 87). (Pamiętaj, że korekty są skomplikowane w przypadku skomplikowanych stosów czcionek.)
W przypadku późnego CSS możemy zapewnić, że CSS krytyczny dla układu jest wbudowany w nagłówek każdego szablonu. Co więcej: w przypadku długich stron dodany pionowy pasek przewijania powoduje przesunięcie głównej treści o 16 pikseli w lewo. Aby wcześnie wyświetlić pasek przewijania, możemy dodać
overflow-y: scrollonhtml, aby wymusić pasek przewijania przy pierwszym malowaniu. To ostatnie pomaga, ponieważ paski przewijania mogą powodować nietrywialne przesunięcia układu z powodu ponownego wlewania zawartości powyżej części zagięcia, gdy zmienia się szerokość. Powinno to jednak mieć miejsce głównie na platformach z paskami przewijania bez nakładek, takich jak Windows. Ale: breaksposition: sticky, ponieważ te elementy nigdy nie zostaną przewinięte z kontenera.Jeśli masz do czynienia z nagłówkami, które przyklejają się na stałe lub przyklejają się do góry strony podczas przewijania, zarezerwuj miejsce na nagłówek, gdy zostanie on wyschnięty, np. z elementem zastępczym lub
margin-topna treści. Wyjątkiem powinny być banery zgody na pliki cookie, które nie powinny mieć wpływu na CLS, ale czasami mają: zależy to od implementacji. W tym wątku na Twitterze jest kilka interesujących strategii i propozycji.W przypadku komponentu karty, który może zawierać różne ilości tekstów, możesz zapobiec przesunięciom układu za pomocą stosów siatki CSS. Umieszczając zawartość każdej zakładki w tym samym obszarze siatki i ukrywając jedną z nich na raz, możemy zapewnić, że kontener zawsze przyjmuje wysokość większego elementu, dzięki czemu nie wystąpią przesunięcia układu.
Ach, i oczywiście nieskończone przewijanie i „Załaduj więcej” mogą również powodować zmiany układu, jeśli pod listą znajduje się treść (np. stopka). Aby ulepszyć CLS, zarezerwuj wystarczająco dużo miejsca na treść, która zostanie załadowana, zanim użytkownik przewinie do tej części strony, usuń stopkę lub wszelkie elementy DOM na dole strony, które mogą zostać zepchnięte w dół podczas ładowania treści. Wstępnie pobieraj dane i obrazy dla treści w części strony widocznej na ekranie, aby zanim użytkownik przewinął tak daleko, już tam jest. Możesz użyć bibliotek wirtualizacji list, takich jak React-window, do optymalizacji długich list ( dzięki, Addy Osmani! ).
Aby upewnić się, że wpływ zmian przepływu jest uwzględniony, zmierz stabilność układu za pomocą interfejsu Layout Instability API. Dzięki niemu możesz obliczyć wynik skumulowanego przesunięcia układu ( CLS ) i uwzględnić go jako wymaganie w swoich testach, więc za każdym razem, gdy pojawi się regresja, możesz go śledzić i naprawić.
Aby obliczyć wynik przesunięcia układu, przeglądarka sprawdza rozmiar okienka ekranu i ruch niestabilnych elementów w rzutni między dwiema renderowanymi ramkami. W idealnym przypadku wynik byłby bliski
0. Jest świetny przewodnik autorstwa Milicy Mihajlija i Philipa Waltona na temat tego, czym jest CLS i jak go mierzyć. To dobry punkt wyjścia do mierzenia i utrzymywania postrzeganej wydajności oraz unikania zakłóceń, zwłaszcza w przypadku zadań o znaczeniu krytycznym dla firmy.Szybka wskazówka : aby dowiedzieć się, co spowodowało zmianę układu w DevTools, możesz zbadać zmiany układu w sekcji „Doświadczenie” w Panelu wydajności.
Bonus : jeśli chcesz ograniczyć odświeżanie i odświeżanie, sprawdź przewodnik Charisa Theodoulou na temat minimalizacji DOM Reflow/Layout Thrashing i listę Paula Irisha Co wymusza układ/przerysowanie, a także CSSTriggers.com, tabelę referencyjną właściwości CSS, które wyzwalają układ, malowanie i komponowanie.
Sieć i HTTP/2
- Czy zszywanie OCSP jest włączone?
Włączając zszywanie OCSP na serwerze, możesz przyspieszyć uzgadnianie TLS. Protokół OCSP (Online Certificate Status Protocol) został utworzony jako alternatywa dla protokołu listy odwołań certyfikatów (CRL). Oba protokoły służą do sprawdzania, czy certyfikat SSL został unieważniony.Jednak protokół OCSP nie wymaga, aby przeglądarka poświęcała czas na pobieranie, a następnie przeszukiwanie listy w celu uzyskania informacji o certyfikacie, co skraca czas potrzebny na uzgadnianie.
- Czy ograniczyłeś wpływ unieważniania certyfikatu SSL?
W swoim artykule „Koszt wydajności certyfikatów EV” Simon Hearne przedstawia doskonały przegląd powszechnych certyfikatów oraz wpływ, jaki wybór certyfikatu może mieć na ogólną wydajność.Jak pisze Simon, w świecie HTTPS istnieje kilka rodzajów poziomów walidacji certyfikatów używanych do zabezpieczania ruchu:
- Walidacja domeny (DV) sprawdza, czy osoba żądająca certyfikatu jest właścicielem domeny,
- Weryfikacja organizacji (OV) potwierdza, że organizacja jest właścicielem domeny,
- Extended Validation (EV) potwierdza, że organizacja jest właścicielem domeny, z rygorystyczną walidacją.
Należy zauważyć, że wszystkie te certyfikaty są takie same pod względem technologii; różnią się jedynie informacjami i właściwościami zawartymi w tych certyfikatach.
Certyfikaty EV są drogie i czasochłonne , ponieważ wymagają od człowieka sprawdzenia certyfikatu i zapewnienia jego ważności. Z drugiej strony certyfikaty DV są często udostępniane za darmo — np. przez Let's Encrypt — otwarty, zautomatyzowany urząd certyfikacji, który jest dobrze zintegrowany z wieloma dostawcami hostingu i sieciami CDN. W chwili pisania tego tekstu obsługuje ponad 225 milionów stron internetowych (PDF), chociaż stanowi tylko 2,69% stron (otwieranych w Firefoksie).
Więc jaki jest problem? Problem polega na tym, że certyfikaty EV nie obsługują w pełni zszywania OCSP , o którym mowa powyżej. Podczas gdy zszywanie pozwala serwerowi sprawdzić w Urzędzie Certyfikacji, czy certyfikat został unieważniony, a następnie dodać („zszywkę”) tę informację do certyfikatu, bez zszywania klient musi wykonać całą pracę, co skutkuje niepotrzebnymi żądaniami podczas negocjacji TLS . W przypadku słabych połączeń może to skończyć się zauważalnymi kosztami wydajności (1000ms+).
Certyfikaty EV nie są doskonałym wyborem dla wydajności sieci i mogą mieć znacznie większy wpływ na wydajność niż certyfikaty DV. Aby uzyskać optymalną wydajność sieci, zawsze podawaj zszyty certyfikat DV OCSP. Są również znacznie tańsze niż certyfikaty EV i mniej kłopotliwe w ich uzyskaniu. Cóż, przynajmniej dopóki CRLite nie będzie dostępne.
Kompresja ma znaczenie: 40–43% nieskompresowanych łańcuchów certyfikatów jest zbyt dużych, aby zmieścić się w jednym locie QUIC zawierającym 3 datagramy UDP. (Źródło obrazu:) Szybko) (Duży podgląd) Uwaga : Mając QUIC/HTTP/3, warto zauważyć, że łańcuch certyfikatów TLS jest jedyną zawartością o zmiennej wielkości, która dominuje w liczbie bajtów w QUIC Handshake. Rozmiar waha się od kilkuset bajtów do ponad 10 KB.
Tak więc utrzymywanie małych certyfikatów TLS ma duże znaczenie na QUIC/HTTP/3, ponieważ duże certyfikaty będą powodować wielokrotne uściski dłoni. Ponadto musimy upewnić się, że certyfikaty są skompresowane, ponieważ w przeciwnym razie łańcuchy certyfikatów byłyby zbyt duże, aby zmieścić się w jednym locie QUIC.
Możesz znaleźć o wiele więcej szczegółów i wskazówek do problemu i rozwiązań na:
- Certyfikaty EV spowalniają i sprawiają, że sieć staje się zawodna, Aaron Peters,
- Wpływ unieważnienia certyfikatu SSL na wydajność sieci przez Matta Hobbsa,
- Koszt wydajności certyfikatów EV, Simon Hearne,
- Czy uścisk dłoni QUIC wymaga szybkiej kompresji? autorstwa Patricka McManusa.
- Czy zaadoptowałeś już IPv6?
Ponieważ brakuje nam miejsca na IPv4, a główne sieci komórkowe szybko przyjmują IPv6 (USA osiągnęły prawie 50% próg przyjęcia IPv6), dobrym pomysłem jest aktualizacja DNS do IPv6, aby zachować kuloodporność na przyszłość. Po prostu upewnij się, że obsługa dwóch stosów jest dostępna w całej sieci — umożliwia to jednoczesne działanie protokołów IPv6 i IPv4 obok siebie. W końcu IPv6 nie jest kompatybilny wstecz. Ponadto badania pokazują, że dzięki protokołowi IPv6 te witryny są od 10 do 15% szybsze dzięki wykrywaniu sąsiadów (NDP) i optymalizacji tras. - Upewnij się, że wszystkie zasoby działają przez HTTP/2 (lub HTTP/3).
Ponieważ w ciągu ostatnich kilku lat Google dążył do bezpieczniejszej sieci HTTPS, przejście na środowisko HTTP/2 jest zdecydowanie dobrą inwestycją. W rzeczywistości, według Web Almanac, 64% wszystkich żądań działa już przez HTTP/2.Ważne jest, aby zrozumieć, że HTTP/2 nie jest doskonały i ma problemy z ustalaniem priorytetów, ale jest bardzo dobrze obsługiwany; i w większości przypadków lepiej z tym.
Słowo ostrzeżenia: HTTP/2 Server Push jest usuwany z Chrome, więc jeśli Twoja implementacja opiera się na Server Push, może być konieczne ponowne jej odwiedzenie. Zamiast tego możemy przyjrzeć się Wczesnym wskazówkom, które są już zintegrowane jako eksperymentalne w Fastly.
Jeśli nadal korzystasz z protokołu HTTP, najbardziej czasochłonnym zadaniem będzie najpierw migracja do protokołu HTTPS, a następnie dostosowanie procesu kompilacji do multipleksowania i równoległości HTTP/2. Wprowadzenie HTTP/2 do Gov.uk to fantastyczne studium przypadku właśnie tego, polegającego na znalezieniu drogi przez CORS, SRI i WPT. W dalszej części tego artykułu zakładamy, że przechodzisz na HTTP/2 lub już przeszedłeś na HTTP/2.
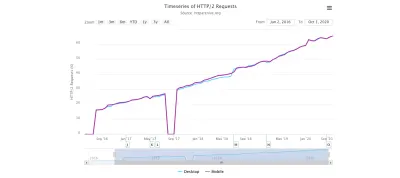
- Prawidłowo wdróż protokół HTTP/2.
Ponownie, udostępnianie zasobów przez HTTP/2 może skorzystać na częściowej zmianie dotychczasowego sposobu wyświetlania zasobów. Musisz znaleźć równowagę między pakowaniem modułów a ładowaniem wielu małych modułów równolegle. Ostatecznie najlepszym żądaniem jest brak żądania, jednak celem jest znalezienie odpowiedniej równowagi między szybką dostawą zasobów po raz pierwszy a buforowaniem.Z jednej strony możesz chcieć całkowicie uniknąć łączenia zasobów, zamiast dzielić cały interfejs na wiele małych modułów, kompresować je w ramach procesu budowania i ładować je równolegle. Zmiana w jednym pliku nie wymaga ponownego pobrania całego arkusza stylów ani kodu JavaScript. Minimalizuje również czas parsowania i utrzymuje niską zawartość poszczególnych stron.
Z drugiej strony opakowanie nadal ma znaczenie. Używając wielu małych skryptów, ucierpi ogólna kompresja i wzrośnie koszt pobierania obiektów z pamięci podręcznej. Kompresja dużego pakietu skorzysta na ponownym wykorzystaniu słownika, podczas gdy małe oddzielne pakiety nie. Istnieje standardowa praca, aby to rozwiązać, ale na razie jest to odległe. Po drugie, przeglądarki nie zostały jeszcze zoptymalizowane pod kątem takich przepływów pracy. Na przykład Chrome uruchomi komunikację między procesami (IPC) liniowo w zależności od liczby zasobów, więc włączenie setek zasobów spowoduje koszty środowiska uruchomieniowego przeglądarki.
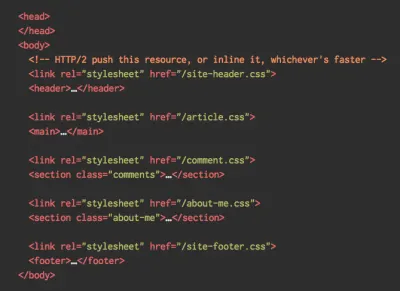
Aby osiągnąć najlepsze wyniki z HTTP/2, rozważ stopniowe ładowanie CSS, jak sugeruje Jake Archibald z Chrome. Mimo to możesz próbować ładować CSS stopniowo. W rzeczywistości CSS w treści nie blokuje już renderowania w Chrome. Są jednak pewne problemy z ustalaniem priorytetów, więc nie jest to tak proste, ale warto z nimi eksperymentować.
Scalanie połączeń HTTP/2 może ujść na sucho, co pozwala na korzystanie z dzielenia domeny przy jednoczesnym korzystaniu z protokołu HTTP/2, ale osiągnięcie tego w praktyce jest trudne i ogólnie nie jest uważane za dobrą praktykę. Ponadto HTTP/2 i integralność zasobów podrzędnych nie zawsze działają.
Co robić? Cóż, jeśli korzystasz z HTTP/2, wysyłanie około 6–10 pakietów wydaje się przyzwoitym kompromisem (i nie jest takie złe w przypadku starszych przeglądarek). Eksperymentuj i mierz, aby znaleźć odpowiednią równowagę dla swojej witryny.
- Czy wysyłamy wszystkie zasoby przez jedno połączenie HTTP/2?
Jedną z głównych zalet protokołu HTTP/2 jest to, że pozwala nam przesyłać zasoby za pośrednictwem jednego połączenia. Czasami jednak mogliśmy zrobić coś złego — np. mieć problem z CORS lub źle skonfigurować atrybutcrossorigin, przez co przeglądarka byłaby zmuszona otworzyć nowe połączenie.Aby sprawdzić, czy wszystkie żądania używają pojedynczego połączenia HTTP/2, czy coś jest źle skonfigurowane, włącz kolumnę „Identyfikator połączenia” w DevTools → Sieć. Np. tutaj wszystkie żądania współdzielą to samo połączenie (286) — z wyjątkiem manifest.json, który otwiera osobny (451).
- Czy twoje serwery i sieci CDN obsługują protokół HTTP/2?
Różne serwery i sieci CDN (nadal) w różny sposób obsługują protokół HTTP/2. Użyj porównania CDN, aby sprawdzić opcje lub szybko sprawdź, jak działają Twoje serwery i jakie funkcje mogą być obsługiwane.Skonsultuj się z niesamowitymi badaniami Pata Meenana na temat priorytetów HTTP/2 (wideo) i wsparcia serwera testowego dla priorytetyzacji HTTP/2. Według Pat, zalecane jest włączenie kontroli przeciążenia BBR i ustawienie
tcp_notsent_lowatna 16 KB, aby priorytetyzacja HTTP/2 działała niezawodnie na jądrach Linuksa 4.9 i nowszych ( dzięki, Yoav! ). Andy Davies przeprowadził podobne badanie dotyczące priorytetyzacji HTTP/2 w przeglądarkach, sieciach CDN i usługach hostingowych w chmurze.Będąc na nim, dokładnie sprawdź, czy twoje jądro obsługuje TCP BBR i włącz je, jeśli to możliwe. Obecnie jest używany w Google Cloud Platform, Amazon Cloudfront, Linux (np. Ubuntu).
- Czy używana jest kompresja HPACK?
Jeśli używasz protokołu HTTP/2, sprawdź, czy serwery implementują kompresję HPACK dla nagłówków odpowiedzi HTTP, aby zmniejszyć niepotrzebne obciążenie. Niektóre serwery HTTP/2 mogą nie w pełni obsługiwać specyfikację, czego przykładem jest HPACK. H2spec to świetne (choć bardzo szczegółowe technicznie) narzędzie do sprawdzenia tego. Algorytm kompresji HPACK jest imponujący i działa. - Upewnij się, że zabezpieczenia na Twoim serwerze są kuloodporne.
Wszystkie implementacje HTTP/2 w przeglądarkach działają przez TLS, więc prawdopodobnie będziesz chciał uniknąć ostrzeżeń bezpieczeństwa lub niektórych elementów na Twojej stronie, które nie działają. Sprawdź dokładnie, czy nagłówki zabezpieczeń są prawidłowo ustawione, wyeliminuj znane luki w zabezpieczeniach i sprawdź konfigurację HTTPS.Upewnij się również, że wszystkie zewnętrzne wtyczki i skrypty śledzenia są ładowane przez HTTPS, że nie jest możliwe wykonywanie skryptów między witrynami oraz że zarówno nagłówki HTTP Strict Transport Security, jak i nagłówki Content Security Policy są prawidłowo ustawione.
- Czy twoje serwery i sieci CDN obsługują HTTP/3?
Chociaż protokół HTTP/2 przyniósł szereg znaczących ulepszeń wydajności w sieci, pozostawił również sporo miejsca do poprawy — zwłaszcza blokowanie nagłówka linii w TCP, które było zauważalne w wolnej sieci ze znaczną utratą pakietów. HTTP/3 rozwiązuje te problemy na dobre (artykuł).Aby rozwiązać problemy związane z HTTP/2, IETF wraz z Google, Akamai i innymi pracuje nad nowym protokołem, który został niedawno ustandaryzowany jako HTTP/3.
Robin Marx bardzo dobrze wyjaśnił HTTP/3, a poniższe wyjaśnienie opiera się na jego wyjaśnieniu. W swojej istocie HTTP/3 jest bardzo podobny do HTTP/2 pod względem funkcji, ale pod maską działa zupełnie inaczej. HTTP/3 zapewnia szereg ulepszeń: szybsze uzgadnianie, lepsze szyfrowanie, bardziej niezawodne niezależne strumienie, lepsze szyfrowanie i kontrola przepływu. Zauważalną różnicą jest to, że HTTP/3 używa QUIC jako warstwy transportowej, z pakietami QUIC hermetyzowanymi na diagramach UDP, a nie TCP.
QUIC w pełni integruje TLS 1.3 z protokołem, podczas gdy w TCP jest nałożony na wierzch. W typowym stosie TCP mamy kilka czasów narzutu w obie strony, ponieważ protokoły TCP i TLS muszą wykonać własne oddzielne uściski dłoni, ale w przypadku QUIC oba z nich można połączyć i wykonać tylko w jednej podróży w obie strony . Ponieważ protokół TLS 1.3 pozwala nam skonfigurować klucze szyfrowania dla kolejnego połączenia, począwszy od drugiego połączenia, możemy już wysyłać i odbierać dane warstwy aplikacji w pierwszej rundzie w obie strony, która nazywa się „0-RTT”.
Również algorytm kompresji nagłówków HTTP/2 został całkowicie przepisany, wraz z jego systemem priorytetyzacji. Ponadto QUIC obsługuje migrację połączenia z Wi-Fi do sieci komórkowej za pomocą identyfikatorów połączeń w nagłówku każdego pakietu QUIC. Większość implementacji jest wykonywana w przestrzeni użytkownika, a nie w przestrzeni jądra (jak to ma miejsce w przypadku TCP), więc powinniśmy spodziewać się, że protokół będzie ewoluował w przyszłości.
Czy to wszystko zrobi dużą różnicę? Prawdopodobnie tak, zwłaszcza mając wpływ na czas ładowania na urządzeniach mobilnych, ale także na to, jak obsługujemy zasoby użytkownikom końcowym. Podczas gdy w HTTP/2 wiele żądań współużytkuje połączenie, w żądaniach HTTP/3 również współużytkują połączenie, ale przesyłają strumieniowo niezależnie, więc porzucony pakiet nie wpływa już na wszystkie żądania, tylko na jeden strumień.
Oznacza to, że podczas gdy w przypadku jednego dużego pakietu JavaScript przetwarzanie zasobów zostanie spowolnione, gdy jeden strumień zostanie wstrzymany, wpływ będzie mniej znaczący, gdy wiele plików będzie przesyłanych równolegle (HTTP/3). Tak więc opakowanie nadal ma znaczenie .
HTTP/3 nadal trwa. Chrome, Firefox i Safari mają już implementacje. Niektóre sieci CDN obsługują już QUIC i HTTP/3. Pod koniec 2020 r. Chrome zaczął wdrażać HTTP/3 i IETF QUIC, a w rzeczywistości wszystkie usługi Google (Google Analytics, YouTube itp.) już działają w HTTP/3. LiteSpeed Web Server obsługuje HTTP/3, ale ani Apache, nginx ani IIS jeszcze go nie obsługują, ale prawdopodobnie szybko się to zmieni w 2021 roku.
Najważniejsze : jeśli masz możliwość korzystania z HTTP/3 na serwerze i w CDN, prawdopodobnie jest to bardzo dobry pomysł. Główną korzyścią będzie jednoczesne pobieranie wielu obiektów, zwłaszcza w przypadku połączeń o dużym opóźnieniu. Nie wiemy jeszcze na pewno, ponieważ w tej przestrzeni nie prowadzi się zbyt wielu badań, ale pierwsze wyniki są bardzo obiecujące.
Jeśli chcesz bardziej zagłębić się w szczegóły i zalety protokołu, oto kilka dobrych punktów wyjścia do sprawdzenia:
- Objaśnienie HTTP/3, wspólny wysiłek w celu udokumentowania protokołów HTTP/3 i QUIC. Dostępne w różnych językach, również w formacie PDF.
- Zwiększanie wydajności sieci dzięki HTTP/3 z Danielem Stenbergiem.
- An Academic's Guide to QUIC with Robin Marx przedstawia podstawowe koncepcje protokołów QUIC i HTTP/3, wyjaśnia, w jaki sposób HTTP/3 obsługuje blokowanie nagłówka i migrację połączeń oraz jak protokół HTTP/3 ma być wiecznie zielony (dzięki, Simon !).
- Możesz sprawdzić, czy twój serwer działa na HTTP/3 na HTTP3Check.net.
Testowanie i monitorowanie
- Czy zoptymalizowałeś przepływ pracy podczas audytu?
Może to nie brzmieć jak wielka sprawa, ale posiadanie odpowiednich ustawień na wyciągnięcie ręki może zaoszczędzić sporo czasu na testowaniu. Rozważ użycie Alfred Workflow Tima Kadleca dla WebPageTest do przesłania testu do publicznej instancji WebPageTest. W rzeczywistości WebPageTest ma wiele niejasnych funkcji, więc poświęć trochę czasu, aby nauczyć się czytać wykres WebPageTest Waterfall View i jak czytać wykres WebPageTest Connection View, aby szybciej diagnozować i rozwiązywać problemy z wydajnością.Możesz także uruchomić WebPageTest z arkusza kalkulacyjnego Google i włączyć dostępność, wydajność i wyniki SEO do swojej konfiguracji Travis za pomocą Lighthouse CI lub bezpośrednio do Webpack.
Spójrz na niedawno wydaną AutoWebPerf, modułowe narzędzie, które umożliwia automatyczne zbieranie danych o wydajności z wielu źródeł. Na przykład możemy ustawić codzienny test na Twoich krytycznych stronach, aby przechwycić dane terenowe z CrUX API i dane laboratoryjne z raportu Lighthouse z PageSpeed Insights.
A jeśli potrzebujesz szybko coś debugować, ale proces kompilacji wydaje się być wyjątkowo powolny, pamiętaj, że „usuwanie białych znaków i zniekształcanie symboli odpowiada za 95% zmniejszenia rozmiaru w zminifikowanym kodzie w przypadku większości JavaScript — a nie skomplikowane przekształcenia kodu. po prostu wyłącz kompresję, aby przyspieszyć kompilacje Uglify od 3 do 4 razy”.
- Czy testowałeś w przeglądarkach proxy i starszych przeglądarkach?
Testowanie w Chrome i Firefox nie wystarczy. Sprawdź, jak Twoja witryna działa w przeglądarkach proxy i starszych przeglądarkach. Na przykład UC Browser i Opera Mini mają znaczny udział w rynku azjatyckim (do 35% w Azji). Mierz średnią prędkość Internetu w interesujących Cię krajach, aby uniknąć dużych niespodzianek. Przetestuj z ograniczaniem przepustowości sieci i emuluj urządzenie o wysokiej rozdzielczości. BrowserStack jest fantastyczny do testowania na zdalnych rzeczywistych urządzeniach i uzupełnia go przynajmniej kilkoma prawdziwymi urządzeniami w biurze — warto.
- Czy przetestowałeś wydajność swoich stron 404?
Zwykle nie zastanawiamy się dwa razy, jeśli chodzi o strony 404. W końcu, gdy klient zażąda strony, która nie istnieje na serwerze, serwer odpowie kodem stanu 404 i powiązaną stroną 404. Nie ma w tym zbyt wiele, prawda?Ważnym aspektem odpowiedzi 404 jest rzeczywisty rozmiar treści odpowiedzi wysyłanej do przeglądarki. Zgodnie z badaniem stron 404 przeprowadzonym przez Matta Hobbsa, zdecydowana większość odpowiedzi 404 pochodzi z brakujących favicon, żądań przesłanych przez WordPress, uszkodzonych żądań JavaScript, plików manifestu, a także plików CSS i czcionek. Za każdym razem, gdy klient zażąda zasobu, który nie istnieje, otrzyma odpowiedź 404 — i często ta odpowiedź jest ogromna.
Sprawdź i zoptymalizuj strategię buforowania stron 404. Naszym celem jest dostarczanie HTML do przeglądarki tylko wtedy, gdy oczekuje ona odpowiedzi HTML i zwracanie małego ładunku błędu dla wszystkich innych odpowiedzi. Według Matta „jeśli umieścimy CDN przed naszym punktem początkowym, mamy szansę na buforowanie odpowiedzi strony 404 w CDN. Jest to przydatne, ponieważ bez tego trafienie strony 404 może być użyte jako wektor ataku DoS, przez zmuszając serwer pochodzenia do odpowiedzi na każde żądanie 404, zamiast zezwalać CDN na odpowiedź z wersją z pamięci podręcznej.
Błędy 404 nie tylko mogą negatywnie wpłynąć na wydajność, ale mogą również kosztować ruch, dlatego dobrym pomysłem jest włączenie strony błędu 404 do zestawu testowego Lighthouse i śledzenie jej wyniku w czasie.
- Czy przetestowałeś działanie swoich próśb o zgodę na RODO?
W czasach RODO i CCPA powszechne stało się poleganie na stronach trzecich, aby zapewnić klientom z UE opcje włączenia lub rezygnacji ze śledzenia. Jednak, podobnie jak w przypadku każdego innego skryptu innej firmy, ich wydajność może mieć dość niszczycielski wpływ na cały wysiłek związany z wydajnością.Oczywiście faktyczna zgoda prawdopodobnie zmieni wpływ skryptów na ogólną wydajność, więc, jak zauważył Boris Schapira, możemy chcieć przestudiować kilka różnych profili wydajności sieci:
- Całkowicie odmówiono zgody,
- Zgoda została częściowo odrzucona,
- Zgoda została udzielona w całości.
- Użytkownik nie zareagował na monit o zgodę (lub monit został zablokowany przez bloker treści),
Zwykle monity o zgodę na pliki cookie nie powinny mieć wpływu na CLS, ale czasami mają, więc rozważ skorzystanie z opcji bezpłatnych i open source Osano lub cookie-consent-box.
Ogólnie rzecz biorąc, warto przyjrzeć się wydajności wyskakującego okienka, ponieważ będziesz musiał określić poziome lub pionowe przesunięcie zdarzenia myszy i prawidłowo ustawić wyskakujące okienko względem kotwicy. Noam Rosenthal dzieli się odkryciami zespołu Wikimedia w artykule Studium przypadku wydajności sieci Web: Podglądy stron Wikipedii (dostępne również jako wideo i minuty).
- Czy prowadzisz CSS diagnostyki wydajności?
Chociaż możemy uwzględnić wszelkiego rodzaju kontrole, aby upewnić się, że niesprawny kod zostanie wdrożony, często warto szybko zorientować się, jakie problemy można łatwo rozwiązać. W tym celu moglibyśmy skorzystać z genialnego kodu CSS Performance Diagnostics Tima Kadleca (zainspirowanego fragmentem kodu Harry'ego Robertsa, który podkreśla leniwie ładowane obrazy, obrazy o nierozmiarowych rozmiarach, obrazy w starszym formacie i skrypty synchroniczne.Np. możesz chcieć upewnić się, że żadne obrazy powyżej strony zgięcia nie są ładowane z opóźnieniem. Możesz dostosować fragment do swoich potrzeb, np. aby wyróżnić nieużywane czcionki internetowe lub wykryć czcionki ikon. Świetne małe narzędzie, które zapewnia, że błędy są widoczne podczas debugowania lub po prostu do bardzo szybkiego audytu bieżącego projektu.
/* Performance Diagnostics CSS */ /* via Harry Roberts. https://twitter.com/csswizardry/status/1346477682544951296 */ img[loading=lazy] { outline: 10px solid red; }
- Have you tested the impact on accessibility?
When the browser starts to load a page, it builds a DOM, and if there is an assistive technology like a screen reader running, it also creates an accessibility tree. The screen reader then has to query the accessibility tree to retrieve the information and make it available to the user — sometimes by default, and sometimes on demand. And sometimes it takes time.When talking about fast Time to Interactive, usually we mean an indicator of how soon a user can interact with the page by clicking or tapping on links and buttons. The context is slightly different with screen readers. In that case, fast Time to Interactive means how much time passes by until the screen reader can announce navigation on a given page and a screen reader user can actually hit keyboard to interact.
Leonie Watson has given an eye-opening talk on accessibility performance and specifically the impact slow loading has on screen reader announcement delays. Screen readers are used to fast-paced announcements and quick navigation, and therefore might potentially be even less patient than sighted users.
Large pages and DOM manipulations with JavaScript will cause delays in screen reader announcements. A rather unexplored area that could use some attention and testing as screen readers are available on literally every platform (Jaws, NVDA, Voiceover, Narrator, Orca).
- Is continuous monitoring set up?
Having a private instance of WebPagetest is always beneficial for quick and unlimited tests. However, a continuous monitoring tool — like Sitespeed, Calibre and SpeedCurve — with automatic alerts will give you a more detailed picture of your performance. Set your own user-timing marks to measure and monitor business-specific metrics. Also, consider adding automated performance regression alerts to monitor changes over time.Look into using RUM-solutions to monitor changes in performance over time. For automated unit-test-alike load testing tools, you can use k6 with its scripting API. Also, look into SpeedTracker, Lighthouse and Calibre.
Szybkie zwycięstwo
This list is quite comprehensive, and completing all of the optimizations might take quite a while. So, if you had just 1 hour to get significant improvements, what would you do? Let's boil it all down to 17 low-hanging fruits . Obviously, before you start and once you finish, measure results, including Largest Contentful Paint and Time To Interactive on a 3G and cable connection.
- Measure the real world experience and set appropriate goals. Aim to be at least 20% faster than your fastest competitor. Stay within Largest Contentful Paint < 2.5s, a First Input Delay < 100ms, Time to Interactive < 5s on slow 3G, for repeat visits, TTI < 2s. Optimize at least for First Contentful Paint and Time To Interactive.
- Optimize images with Squoosh, mozjpeg, guetzli, pingo and SVGOMG, and serve AVIF/WebP with an image CDN.
- Prepare critical CSS for your main templates, and inline them in the
<head>of each template. For CSS/JS, operate within a critical file size budget of max. 170KB gzipped (0.7MB decompressed). - Trim, optimize, defer and lazy-load scripts. Invest in the config of your bundler to remove redundancies and check lightweight alternatives.
- Always self-host your static assets and always prefer to self-host third-party assets. Limit the impact of third-party scripts. Use facades, load widgets on interaction and beware of anti-flicker snippets.
- Be selective when choosing a framework. For single-page-applications, identify critical pages and serve them statically, or at least prerender them, and use progressive hydration on component-level and import modules on interaction.
- Client-side rendering alone isn't a good choice for performance. Prerender if your pages don't change much, and defer the booting of frameworks if you can. If possible, use streaming server-side rendering.
- Serve legacy code only to legacy browsers with
<script type="module">and module/nomodule pattern. - Experiment with regrouping your CSS rules and test in-body CSS.
- Add resource hints to speed up delivery with faster
dns-lookup,preconnect,prefetch,preloadandprerender. - Subset web fonts and load them asynchronously, and utilize
font-displayin CSS for fast first rendering. - Check that HTTP cache headers and security headers are set properly.
- Enable Brotli compression on the server. (If that's not possible, at least make sure that Gzip compression is enabled.)
- Enable TCP BBR congestion as long as your server is running on the Linux kernel version 4.9+.
- Enable OCSP stapling and IPv6 if possible. Always serve an OCSP stapled DV certificate.
- Enable HPACK compression for HTTP/2 and move to HTTP/3 if it's available.
- Cache assets such as fonts, styles, JavaScript and images in a service worker cache.
Download The Checklist (PDF, Apple Pages)
With this checklist in mind, you should be prepared for any kind of front-end performance project. Feel free to download the print-ready PDF of the checklist as well as an editable Apple Pages document to customize the checklist for your needs:
- Download the checklist PDF (PDF, 166 KB)
- Download the checklist in Apple Pages (.pages, 275 KB)
- Download the checklist in MS Word (.docx, 151 KB)
If you need alternatives, you can also check the front-end checklist by Dan Rublic, the "Designer's Web Performance Checklist" by Jon Yablonski and the FrontendChecklist.
No to idziemy!
Some of the optimizations might be beyond the scope of your work or budget or might just be overkill given the legacy code you have to deal with. That's fine! Use this checklist as a general (and hopefully comprehensive) guide, and create your own list of issues that apply to your context. But most importantly, test and measure your own projects to identify issues before optimizing. Happy performance results in 2021, everyone!
A huge thanks to Guy Podjarny, Yoav Weiss, Addy Osmani, Artem Denysov, Denys Mishunov, Ilya Pukhalski, Jeremy Wagner, Colin Bendell, Mark Zeman, Patrick Meenan, Leonardo Losoviz, Andy Davies, Rachel Andrew, Anselm Hannemann, Barry Pollard, Patrick Hamann, Gideon Pyzer, Andy Davies, Maria Prosvernina, Tim Kadlec, Rey Bango, Matthias Ott, Peter Bowyer, Phil Walton, Mariana Peralta, Pepijn Senders, Mark Nottingham, Jean Pierre Vincent, Philipp Tellis, Ryan Townsend, Ingrid Bergman, Mohamed Hussain SH, Jacob Groß, Tim Swalling, Bob Visser, Kev Adamson, Adir Amsalem, Aleksey Kulikov and Rodney Rehm for reviewing this article, as well as our fantastic community which has shared techniques and lessons learned from its work in performance optimization for everybody to use. Naprawdę miażdżysz!