
Łuszczące się testy: pozbycie się żywego koszmaru podczas testów
Opublikowany: 2022-03-10Jest taka bajka, o której ostatnio dużo myślę. Bajkę opowiedziano mi jako dziecko. Nazywa się „Chłopiec, który zawołał wilka” Ezopa. Opowiada o chłopcu pasącym owce w swojej wiosce. Nudzi mu się i udaje, że wilk atakuje stado, wołając o pomoc wieśniaków — tylko po to, by z rozczarowaniem zdali sobie sprawę, że to fałszywy alarm i zostawili chłopca w spokoju. Potem, gdy wilk rzeczywiście pojawia się, a chłopiec woła o pomoc, mieszkańcy wioski uważają, że to kolejny fałszywy alarm i nie przychodzą na ratunek, a owce zostają zjedzone przez wilka.
Morał tej historii najlepiej podsumowuje sam autor:
„Kłamcy nie uwierzy, nawet jeśli mówi prawdę”.
Wilk atakuje owcę, a chłopiec woła o pomoc, ale po wielu kłamstwach nikt mu już nie wierzy. Ten morał można zastosować do testowania: historia Ezopa jest ładną alegorią pasującego wzorca, na który natknąłem się: niestabilne testy, które nie dostarczają żadnej wartości.
Testowanie front-endu: po co w ogóle zawracać sobie głowę?
Większość moich dni spędzam na testowaniu front-endu. Nie powinno więc Cię dziwić, że przykłady kodu w tym artykule będą w większości pochodziły z testów front-endowych, na które natknąłem się w swojej pracy. Jednak w większości przypadków można je łatwo przetłumaczyć na inne języki i zastosować w innych frameworkach. Mam więc nadzieję, że artykuł będzie dla Ciebie przydatny — niezależnie od posiadanej wiedzy.
Warto przypomnieć, co oznacza testowanie front-endu. W swojej istocie, testowanie front-end to zestaw praktyk testowania interfejsu użytkownika aplikacji internetowej, w tym jej funkcjonalności.
Zaczynając jako inżynier ds. zapewniania jakości, znam ból związany z niekończącymi się ręcznymi testami z listy kontrolnej tuż przed wydaniem. Tak więc, oprócz zapewnienia, że aplikacja pozostaje wolna od błędów podczas kolejnych aktualizacji, starałem się odciążyć testy spowodowane rutynowymi zadaniami, do których tak naprawdę nie potrzebujesz człowieka. Teraz, jako programista, uważam, że temat nadal jest aktualny, zwłaszcza, że staram się bezpośrednio pomagać użytkownikom i współpracownikom. I jest jeden problem w szczególności z testowaniem, który przyprawia nas o koszmary.
Nauka o łuszczących się testach
Test łuszczący się to taki, który nie daje takich samych wyników za każdym razem, gdy przeprowadzana jest ta sama analiza. Kompilacja kończy się niepowodzeniem tylko sporadycznie: raz minie, innym razem się nie powiedzie, następnym razem znowu minie, bez żadnych zmian w kompilacji.
Kiedy przypominam sobie koszmary związane z testowaniem, przychodzi mi do głowy szczególnie jeden przypadek. To było w teście interfejsu użytkownika. Zbudowaliśmy niestandardowe pole kombi (tj. listę do wyboru z polem wejściowym):
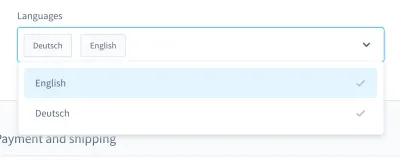
Za pomocą tego pola kombi możesz wyszukać produkt i wybrać jeden lub więcej wyników. Przez wiele dni ten test wypadł dobrze, ale w pewnym momencie wszystko się zmieniło. W jednym z około dziesięciu kompilacji naszego systemu ciągłej integracji (CI) test wyszukiwania i wybierania produktu w tym polu kombi nie powiódł się.
Zrzut ekranu niepowodzenia pokazuje, że lista wyników nie jest filtrowana, pomimo udanego wyszukiwania:
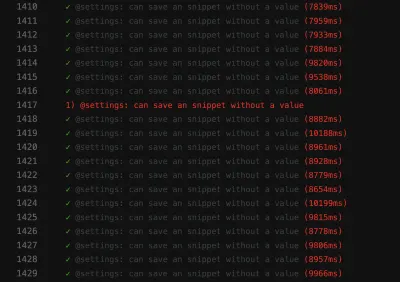
Niepewny test, taki jak ten , może zablokować ciągły potok wdrażania , przez co dostarczanie funkcji będzie wolniejsze, niż jest to konieczne. Co więcej, łuszczący się test jest problematyczny, ponieważ nie jest już deterministyczny — co czyni go bezużytecznym. W końcu nie ufałbyś nikomu bardziej niż kłamcy.
Ponadto niestabilne testy są kosztowne w naprawie , a debugowanie często wymaga godzin, a nawet dni. Mimo że testy end-to-end są bardziej podatne na łamanie, doświadczyłem ich we wszelkiego rodzaju testach: testach jednostkowych, testach funkcjonalnych, testach end-to-end i wszystkim pomiędzy.
Innym poważnym problemem związanym z niestabilnymi testami jest nastawienie, które wpaja nam, programistom. Kiedy zacząłem pracować w automatyzacji testów, często słyszałem, jak deweloperzy mówią to w odpowiedzi na nieudany test:
„Ach, ta konstrukcja. Nieważne, po prostu rozpocznij od nowa. Kiedyś to minie.
To dla mnie wielka czerwona flaga . Pokazuje mi, że błąd w kompilacji nie będzie traktowany poważnie. Zakłada się, że niestabilny test nie jest prawdziwym błędem, ale jest „tylko” niestabilny, bez konieczności dbania o niego ani nawet debugowania. Test i tak przejdzie później, prawda? Nie! Jeśli taki commit zostanie scalony, w najgorszym przypadku będziemy mieli w produkcie nowy test płatków.
Przyczyny
Tak więc łuszczące się testy są problematyczne. Co powinniśmy z nimi zrobić? Cóż, jeśli znamy problem, możemy zaprojektować kontr-strategię.
Często spotykam się z przyczynami w życiu codziennym. Można je znaleźć w samych testach . Testy mogą być napisane nieoptymalnie, zawierać błędne założenia lub zawierać złe praktyki. Jednak nie tylko. Testy łuszczące się mogą wskazywać na coś znacznie gorszego.
W kolejnych sekcjach omówimy najczęstsze, z którymi się spotkałem.
1. Przyczyny po stronie testu
W idealnym świecie początkowy stan aplikacji powinien być nieskazitelny i w 100% przewidywalny. W rzeczywistości nigdy nie wiadomo, czy identyfikator, którego użyłeś w teście, będzie zawsze taki sam.
Przyjrzyjmy się dwóm przykładom pojedynczej porażki z mojej strony. Błąd numer jeden polegał na użyciu identyfikatora w moich testowych urządzeniach:
{ "id": "f1d2554b0ce847cd82f3ac9bd1c0dfca", "name": "Variant product", }Drugim błędem było szukanie unikalnego selektora do użycia w teście interfejsu użytkownika i myślenie: „Ok, ten identyfikator wydaje się wyjątkowy. Wykorzystam to.
<!-- This is a text field I took from a project I worked on --> <input type="text" />Jeśli jednak uruchomiłbym test na innej instalacji lub później na kilku kompilacjach w CI, testy te mogą się nie powieść. Nasza aplikacja generowałaby identyfikatory na nowo, zmieniając je między kompilacjami. Tak więc pierwszą możliwą przyczyną są zakodowane na sztywno identyfikatory .
Druga przyczyna może wynikać z losowo (lub w inny sposób) wygenerowanych danych demonstracyjnych . Jasne, możesz myśleć, że ta „wada” jest uzasadniona — w końcu generowanie danych jest losowe — ale pomyśl o debugowaniu tych danych. Bardzo trudno jest sprawdzić, czy błąd tkwi w samych testach, czy w danych demonstracyjnych.
Następna jest przyczyna po stronie testów, z którą wielokrotnie się zmagałem: testy z zależnościami krzyżowymi . Niektóre testy mogą nie działać niezależnie lub w losowej kolejności, co jest problematyczne. Ponadto poprzednie testy mogły kolidować z kolejnymi. Te scenariusze mogą powodować niestabilne testy, wprowadzając skutki uboczne.
Nie zapominaj jednak, że testy dotyczą trudnych założeń . Co się stanie, jeśli twoje założenia są błędne? Doświadczyłem tego często, a moje ulubione to błędne założenia dotyczące czasu.
Jednym z przykładów jest użycie niedokładnych czasów oczekiwania, zwłaszcza w testach interfejsu użytkownika — na przykład przy użyciu stałych czasów oczekiwania . Poniższy wiersz pochodzi z testu Nightwatch.js.
// Please never do that unless you have a very good reason! // Waits for 1 second browser.pause(1000);Kolejne błędne założenie dotyczy samego czasu. Kiedyś odkryłem, że niestabilny test PHPUnit zawodzi tylko w naszych nocnych kompilacjach. Po pewnym debugowaniu odkryłem, że winowajcą była zmiana czasu między wczoraj a dziś. Innym dobrym przykładem są awarie spowodowane strefami czasowymi .
Na tym nie kończą się fałszywe założenia. Możemy również mieć błędne założenia dotyczące kolejności danych . Wyobraź sobie siatkę lub listę zawierającą wiele wpisów z informacjami, takimi jak lista walut:
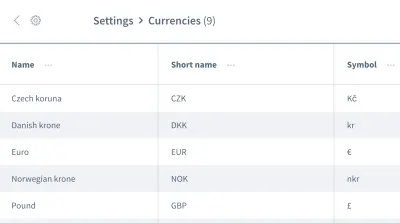
Chcemy pracować z informacjami z pierwszego wpisu, walutą „czeska korona”. Czy możesz być pewien, że Twoja aplikacja zawsze umieści tę część danych jako pierwszy wpis za każdym razem, gdy Twój test jest wykonywany? Czy to możliwe, że przy niektórych okazjach pierwszym wpisem będzie „euro” lub inna waluta ?
Nie zakładaj, że Twoje dane pojawią się w takiej kolejności, w jakiej ich potrzebujesz. Podobnie jak w przypadku identyfikatorów zakodowanych na sztywno, kolejność może się zmieniać między kompilacjami, w zależności od projektu aplikacji.
2. Przyczyny po stronie środowiska
Następna kategoria przyczyn dotyczy wszystkiego poza twoimi testami. W szczególności mówimy o środowisku, w którym testy są wykonywane, o zależnościach związanych z CI i dockerem poza twoimi testami — wszystkie te rzeczy, na które ledwo masz wpływ, przynajmniej jako tester.
Częstą przyczyną po stronie środowiska są wycieki zasobów : często jest to obciążona aplikacja, powodująca różne czasy ładowania lub nieoczekiwane zachowanie. Duże testy mogą łatwo powodować wycieki, pochłaniając dużo pamięci. Innym częstym problemem jest brak czyszczenia .
Szczególnie koszmary przyprawiają mnie niekompatybilność między zależnościami. Jeden koszmar miał miejsce, gdy pracowałem z Nightwatch.js przy testowaniu interfejsu użytkownika. Nightwatch.js korzysta z WebDriver, który oczywiście zależy od Chrome. Gdy Chrome przyspieszył z aktualizacją, wystąpił problem z kompatybilnością: Chrome, WebDriver i sam Nightwatch.js nie współpracowały już ze sobą, co powodowało, że nasze kompilacje od czasu do czasu nie działały.
Mówiąc o zależnościach : wyróżnienie dotyczy wszelkich problemów z npm, takich jak brak uprawnień lub niedziałanie npm. Wszystkiego tego doświadczyłem obserwując CI.
Jeśli chodzi o błędy w testach interfejsu użytkownika spowodowane problemami środowiskowymi, pamiętaj, że do ich uruchomienia potrzebny jest cały stos aplikacji. Im więcej rzeczy jest zaangażowanych, tym większe prawdopodobieństwo błędu . Testy JavaScript są zatem najtrudniejszymi testami do ustabilizowania w tworzeniu stron internetowych, ponieważ obejmują dużą ilość kodu.
3. Przyczyny po stronie produktu
Na koniec musimy naprawdę uważać na ten trzeci obszar — obszar z rzeczywistymi błędami. Mówię o przyczynach złuszczania się produktu. Jednym z najbardziej znanych przykładów są warunki wyścigu w aplikacji. Gdy tak się stanie, błąd należy naprawić w produkcie, a nie w teście! Próba naprawienia testu lub środowiska w tym przypadku nie będzie miała sensu.
Sposoby walki z łuszczeniem
Zidentyfikowaliśmy trzy przyczyny łuszczenia się. Na tym możemy zbudować naszą kontr-strategię! Oczywiście, już wiele zyskasz, pamiętając o trzech przyczynach, gdy napotkasz niestabilne testy. Będziesz już wiedział, czego szukać i jak poprawić testy. Jednak oprócz tego istnieje kilka strategii, które pomogą nam projektować, pisać i debugować testy, i przyjrzymy się im razem w kolejnych sekcjach.
Skoncentruj się na swoim zespole
Twój zespół jest prawdopodobnie najważniejszym czynnikiem . Na początek przyznaj, że masz problem z łuszczącymi się testami. Kluczowe jest zaangażowanie całego zespołu! Następnie, jako zespół, musisz zdecydować, jak radzić sobie z niestabilnymi testami.
Przez lata pracy w technologii natknąłem się na cztery strategie stosowane przez zespoły do przeciwdziałania łuszczeniu się:
- Nie rób nic i zaakceptuj łuszczący się wynik testu.
Oczywiście ta strategia wcale nie jest rozwiązaniem. Test nie przyniesie żadnej wartości, ponieważ nie możesz już mu ufać — nawet jeśli zaakceptujesz łuszczenie. Więc możemy to dość szybko pominąć. - Ponów test, aż zakończy się pomyślnie.
Ta strategia była powszechna na początku mojej kariery, co zaowocowało reakcją, o której wspomniałem wcześniej. Ponowne próby testów były akceptowalne, dopóki nie zdały. Ta strategia nie wymaga debugowania, ale jest leniwa. Oprócz ukrycia symptomów problemu, jeszcze bardziej spowolni to twój zestaw testowy, co sprawia, że rozwiązanie nie jest opłacalne. Jednak mogą istnieć pewne wyjątki od tej reguły, które wyjaśnię później. - Usuń i zapomnij o teście.
Ten jest oczywisty: po prostu usuń niestabilny test, aby nie przeszkadzał już w twoim zestawie testów. Jasne, zaoszczędzisz pieniądze, ponieważ nie będziesz już musiał debugować i naprawiać testu. Ale dzieje się to kosztem utraty części pokrycia testowego i utraty potencjalnych poprawek. Test istnieje nie bez powodu! Nie strzelaj do posłańca, usuwając test. - Poddaj kwarantannie i napraw.
Odniosłem największy sukces dzięki tej strategii. W takim przypadku tymczasowo pominęlibyśmy test, a zestaw testów stale przypominał nam, że test został pominięty. Aby mieć pewność, że poprawka nie zostanie przeoczona, zaplanujemy bilet na następny sprint. Przypomnienia o botach również działają dobrze. Po naprawieniu problemu powodującego niestabilność, ponownie zintegrujemy (tj. cofniemy pominięcie) testu. Niestety chwilowo stracimy zasięg, ale wróci on z poprawką, więc nie potrwa to długo.
Strategie te pomagają nam radzić sobie z problemami testowymi na poziomie przepływu pracy i nie tylko ja się z nimi spotkałem. W swoim artykule Sam Saffron dochodzi do podobnego wniosku. Ale w naszej codziennej pracy pomagają nam w ograniczonym stopniu. Jak więc postępować, gdy takie zadanie staje na naszej drodze?

Trzymaj testy izolowane
Planując przypadki testowe i strukturę, zawsze trzymaj testy odizolowane od innych testów, aby można było je uruchomić w niezależnej lub losowej kolejności. Najważniejszym krokiem jest przywrócenie czystej instalacji między testami . Ponadto testuj tylko przepływ pracy, który chcesz przetestować, i twórz dane próbne tylko dla samego testu. Kolejną zaletą tego skrótu jest to, że poprawia wydajność testu . Jeśli zastosujesz się do tych punktów, żadne skutki uboczne z innych testów lub pozostałości danych nie staną na przeszkodzie.
Poniższy przykład pochodzi z testów UI platformy e-commerce i dotyczy logowania klienta w witrynie sklepu. (Test jest napisany w JavaScript, przy użyciu frameworka Cypress.)
// File: customer-login.spec.js let customer = {}; beforeEach(() => { // Set application to clean state cy.setInitialState() .then(() => { // Create test data for the test specifically return cy.setFixture('customer'); }) }): Pierwszym krokiem jest zresetowanie aplikacji do czystej instalacji. Odbywa się to jako pierwszy krok w haczyku cyklu życia beforeEach , aby upewnić się, że reset jest wykonywany za każdym razem. Następnie dane testowe są tworzone specjalnie na potrzeby testu — w tym przypadku testowym klient zostałby utworzony za pomocą niestandardowego polecenia. Następnie możemy zacząć od jednego przepływu pracy, który chcemy przetestować: logowania klienta.
Dalsza optymalizacja struktury testowej
Możemy wprowadzić kilka innych drobnych poprawek, aby nasza struktura testowa była bardziej stabilna. Pierwsza jest dość prosta: zacznij od mniejszych testów. Jak wspomniano wcześniej, im więcej robisz w teście, tym więcej może się nie udać. Utrzymuj testy tak proste, jak to tylko możliwe i unikaj dużej logiki w każdym z nich.
Jeśli chodzi o nieprzyjmowanie kolejności danych (na przykład, gdy mamy do czynienia z kolejnością wpisów na liście w testowaniu interfejsu użytkownika), możemy zaprojektować test tak, aby działał niezależnie od dowolnej kolejności. Aby przywrócić przykład siatki z zawartymi w niej informacjami, nie używalibyśmy pseudoselektorów ani innych CSS, które są silnie zależne od kolejności. Zamiast selektora nth-child(3) moglibyśmy użyć tekstu lub innych rzeczy, dla których kolejność nie ma znaczenia. Na przykład moglibyśmy użyć stwierdzenia typu „Znajdź mi element z tym jednym ciągiem tekstowym w tej tabeli”.
Czekać! Ponowne próby są czasami w porządku?
Ponawianie testów to kontrowersyjny temat i słusznie. Ciągle myślę o tym jako o anty-wzorcu, jeśli test jest ponawiany na ślepo, aż do pomyślnego zakończenia. Jest jednak ważny wyjątek: jeśli nie możesz kontrolować błędów, ponowna próba może być ostatecznością (na przykład w celu wykluczenia błędów z zależności zewnętrznych). W takim przypadku nie mamy wpływu na źródło błędu. Zachowaj jednak szczególną ostrożność podczas wykonywania tego testu: nie bądź ślepy na łuszczenie się podczas ponawiania testu i używaj powiadomień , aby przypomnieć, że test jest pomijany.
Poniższy przykład to taki, którego użyłem w naszym CI z GitLab. Inne środowiska mogą mieć inną składnię do uzyskiwania ponownych prób, ale to powinno dać ci przedsmak:
test: script: rspec retry: max: 2 when: runner_system_failureW tym przykładzie konfigurujemy, ile ponownych prób należy wykonać, jeśli zadanie się nie powiedzie. Interesująca jest możliwość ponawiania próby w przypadku wystąpienia błędu w systemie runnera (np. nieudana konfiguracja zadania). Decydujemy się na ponowną próbę naszej pracy tylko wtedy, gdy coś w konfiguracji dockera nie powiedzie się.
Zwróć uwagę, że po uruchomieniu spowoduje to ponowną próbę wykonania całego zadania. Jeśli chcesz ponowić próbę tylko błędnego testu, musisz poszukać funkcji w swoim frameworku testowym, aby to obsłużyć. Poniżej znajduje się przykład z Cypress, który wspierał ponowne próby pojedynczego testu od wersji 5:
{ "retries": { // Configure retry attempts for 'cypress run` "runMode": 2, // Configure retry attempts for 'cypress open` "openMode": 2, } } Możesz aktywować ponowne próby w pliku konfiguracyjnym Cypress, cypress.json . Tam możesz zdefiniować ponowną próbę w trybie biegacza testowego i trybie bezgłowym.
Korzystanie z dynamicznych czasów oczekiwania
Ten punkt jest ważny dla wszelkiego rodzaju testów, ale zwłaszcza testowania interfejsu użytkownika. Nie mogę tego wystarczająco podkreślić: nigdy nie używaj stałych czasów oczekiwania — przynajmniej nie bez bardzo dobrego powodu. Jeśli to zrobisz, rozważ możliwe wyniki. W najlepszym przypadku wybierzesz zbyt długi czas oczekiwania, przez co zestaw testowy będzie wolniejszy niż powinien. W najgorszym przypadku nie będziesz czekać wystarczająco długo, więc test nie będzie kontynuowany, ponieważ aplikacja nie jest jeszcze gotowa, co powoduje, że test kończy się niepowodzeniem. Z mojego doświadczenia wynika, że jest to najczęstsza przyczyna łuszczących się testów.
Zamiast tego używaj dynamicznych czasów oczekiwania. Jest na to wiele sposobów, ale Cypress radzi sobie z nimi szczególnie dobrze.
Wszystkie polecenia Cypress posiadają niejawną metodę oczekiwania: sprawdzają już, czy element, do którego polecenie jest stosowane, istnieje w DOM przez określony czas — co wskazuje na możliwość ponownej próby Cypress. Jednak sprawdza tylko istnienie i nic więcej. Dlatego polecam pójść o krok dalej — czekać na jakiekolwiek zmiany w interfejsie użytkownika witryny lub aplikacji, które zobaczy prawdziwy użytkownik, takie jak zmiany w samym interfejsie użytkownika lub w animacji.
Ten przykład używa jawnego czasu oczekiwania na elemencie z selektorem .offcanvas . Test będzie kontynuowany tylko wtedy, gdy element będzie widoczny do określonego czasu, który możesz skonfigurować:
// Wait for changes in UI (until element is visible) cy.get(#element).should('be.visible'); Kolejną fajną możliwością dynamicznego oczekiwania w Cypressie są funkcje sieciowe. Tak, możemy poczekać na pojawienie się żądań i na wyniki ich odpowiedzi. Szczególnie często korzystam z tego rodzaju czekania. W poniższym przykładzie definiujemy żądanie, na które należy czekać, używamy polecenia wait do oczekiwania na odpowiedź i potwierdzamy jego kod statusu:
// File: checkout-info.spec.js // Define request to wait for cy.intercept({ url: '/widgets/customer/info', method: 'GET' }).as('checkoutAvailable'); // Imagine other test steps here... // Assert the response's status code of the request cy.wait('@checkoutAvailable').its('response.statusCode') .should('equal', 200);W ten sposób możemy czekać dokładnie tak długo, jak potrzebuje nasza aplikacja, dzięki czemu testy są bardziej stabilne i mniej podatne na łuszczenie się z powodu wycieków zasobów lub innych problemów środowiskowych.
Debugowanie niestabilnych testów
Teraz wiemy, jak zapobiegać łuszczeniu się testów już na etapie projektowania. Ale co, jeśli masz już do czynienia z łuszczącym się testem? Jak się go pozbyć?
Kiedy debugowałem, umieszczenie wadliwego testu w pętli bardzo mi pomogło w wykryciu niestabilności. Na przykład, jeśli przeprowadzasz test 50 razy i za każdym razem przechodzi on pomyślnie, możesz być bardziej pewny, że test jest stabilny — może Twoja poprawka zadziałała. Jeśli nie, możesz przynajmniej uzyskać lepszy wgląd w test łuszczenia.
// Use in build Lodash to repeat the test 100 times Cypress._.times(100, (k) => { it(`typing hello ${k + 1} / 100`, () => { // Write your test steps in here }) }) Uzyskanie lepszego wglądu w ten łuszczący się test jest szczególnie trudny w CI. Aby uzyskać pomoc, sprawdź, czy Twoja platforma testowa jest w stanie uzyskać więcej informacji o Twojej kompilacji. Jeśli chodzi o testy front-endowe, zazwyczaj możesz skorzystać z pliku console.log w swoich testach:
it('should be a Vue.JS component', () => { // Mock component by a method defined before const wrapper = createWrapper(); // Print out the component's html console.log(wrapper.html()); expect(wrapper.isVueInstance()).toBe(true); }) Ten przykład pochodzi z testu jednostkowego Jest, w którym używam pliku console.log , aby uzyskać dane wyjściowe kodu HTML testowanego komponentu. Jeśli użyjesz tej możliwości logowania w programie uruchamiającym testy Cypress, możesz nawet sprawdzić dane wyjściowe w wybranych narzędziach programistycznych. Ponadto, jeśli chodzi o Cypress w CI, możesz sprawdzić to wyjście w dzienniku CI za pomocą wtyczki.
Zawsze sprawdzaj funkcje swojej platformy testowej, aby uzyskać wsparcie dotyczące rejestrowania. W testowaniu interfejsu użytkownika większość frameworków zapewnia funkcje zrzutów ekranu — przynajmniej w przypadku awarii zrzut ekranu zostanie wykonany automatycznie. Niektóre frameworki zapewniają nawet nagrywanie wideo , co może być ogromną pomocą w uzyskaniu wglądu w to, co dzieje się w twoim teście.
Walcz z koszmarami łuszczenia się!
Ważne jest, aby nieustannie polować na niestabilne testy, czy to poprzez zapobieganie im, czy też debugowanie i naprawianie ich, gdy tylko się pojawią. Musimy traktować je poważnie, ponieważ mogą wskazywać na problemy w Twojej aplikacji.
Dostrzeganie czerwonych flag
Oczywiście najlepiej jest przede wszystkim zapobiegać łuszczeniu się testów. Aby szybko podsumować, oto kilka czerwonych flag:
- Test jest duży i zawiera dużo logiki.
- Test obejmuje dużo kodu (na przykład w testach interfejsu użytkownika).
- Test wykorzystuje stałe czasy oczekiwania.
- Test zależy od poprzednich testów.
- Test zapewnia dane, które nie są w 100% przewidywalne, takie jak użycie identyfikatorów, czasów lub danych demonstracyjnych, zwłaszcza generowanych losowo.
Jeśli będziesz pamiętać wskazówki i strategie z tego artykułu, możesz zapobiec niestabilnym testom, zanim się pojawią. A jeśli się pojawią, będziesz wiedział, jak je debugować i naprawiać.
Te kroki naprawdę pomogły mi odzyskać zaufanie do naszego zestawu testowego. Nasz zestaw testów wydaje się być w tej chwili stabilny. W przyszłości mogą pojawić się problemy — nic nie jest w 100% idealne. Ta wiedza i te strategie pomogą mi sobie z nimi poradzić. W ten sposób nabiorę pewności co do mojej zdolności do walki z tymi koszmarami z testów .
Mam nadzieję, że udało mi się złagodzić przynajmniej część twojego bólu i obaw o łuszczenie!
Dalsza lektura
Jeśli chcesz dowiedzieć się więcej na ten temat, oto kilka fajnych zasobów i artykułów, które bardzo mi pomogły:
- Artykuły o „flake”, Cypress.io
- „Ponowne wykonywanie testów jest w rzeczywistości dobrą rzeczą (jeśli twoje podejście jest właściwe),” Filip Hric, Cypress.io
- „Test łuszczenia się: metody identyfikacji i radzenia sobie z niestabilnymi testami”, Jason Palmer, Spotify R&D Engineering
- „Niestabilne testy w Google i jak je łagodzimy”, John Micco, blog Google Testing