
Szybsze ładowanie obrazu dzięki osadzonym podglądom obrazu
Opublikowany: 2022-03-10Podgląd obrazu niskiej jakości (LQIP) i wariant SQIP oparty na SVG to dwie dominujące techniki leniwego ładowania obrazu. Cechą wspólną obu jest to, że najpierw generujesz obraz podglądu o niskiej jakości. Będzie to wyświetlane jako rozmyte, a później zastąpione oryginalnym obrazem. Co by było, gdybyś mógł zaprezentować obraz podglądu odwiedzającemu stronę bez konieczności ładowania dodatkowych danych?
Pliki JPEG, dla których najczęściej stosuje się leniwe ładowanie, mają możliwość, zgodnie ze specyfikacją, przechowywania zawartych w nich danych w taki sposób, że najpierw wyświetlana jest zgrubna, a potem szczegółowa zawartość obrazu. Zamiast budowania obrazu od góry do dołu podczas ładowania (tryb podstawowy), bardzo szybko można wyświetlić rozmazany obraz, który stopniowo staje się ostrzejszy i ostrzejszy (tryb progresywny).


Oprócz lepszego doświadczenia użytkownika, które zapewnia szybszy wygląd, progresywne pliki JPEG są zwykle również mniejsze niż ich odpowiedniki zakodowane w trybie podstawowym. Według Stoyana Stefanova z zespołu programistów Yahoo w przypadku plików większych niż 10 KB istnieje 94% prawdopodobieństwa mniejszego obrazu podczas korzystania z trybu progresywnego.
Jeśli Twoja witryna składa się z wielu plików JPEG, zauważysz, że nawet progresywne pliki JPEG ładują się jeden po drugim. Dzieje się tak, ponieważ nowoczesne przeglądarki umożliwiają tylko sześć jednoczesnych połączeń z domeną. Same progresywne pliki JPEG nie są zatem rozwiązaniem zapewniającym użytkownikowi jak najszybsze wrażenie strony. W najgorszym przypadku przeglądarka załaduje obraz całkowicie przed rozpoczęciem ładowania następnego.
Przedstawiony tutaj pomysł polega na załadowaniu z serwera tylko tylu bajtów progresywnego JPEG, aby można było szybko uzyskać wgląd w zawartość obrazu. Później, w określonym przez nas czasie (np. gdy wszystkie obrazy podglądu w bieżącej rzutni zostały wczytane), reszta obrazu powinna zostać wczytana bez ponownego żądania podglądu już żądanej części.

Niestety, nie można powiedzieć img w atrybucie, ile obrazu ma zostać załadowane w jakim czasie. W przypadku Ajax jest to jednak możliwe, pod warunkiem, że serwer dostarczający obraz obsługuje żądania zakresu HTTP.
Korzystając z żądań zakresu HTTP, klient może poinformować serwer w nagłówku żądania HTTP, które bajty żądanego pliku mają być zawarte w odpowiedzi HTTP. Ta funkcja, obsługiwana przez każdy z większych serwerów (Apache, IIS, nginx), jest używana głównie do odtwarzania wideo. Jeśli użytkownik przeskoczy do końca filmu, załadowanie całego filmu, zanim użytkownik w końcu zobaczy żądaną część, nie będzie zbyt wydajne. Dlatego serwer żąda tylko danych wideo w czasie żądanym przez użytkownika, aby użytkownik mógł oglądać wideo tak szybko, jak to możliwe.
Stoimy teraz przed trzema wyzwaniami:
- Tworzenie progresywnego JPEG
- Określ przesunięcie bajtów, do którego pierwsze żądanie zakresu HTTP musi załadować obraz podglądu
- Tworzenie frontendowego kodu JavaScript
1. Tworzenie progresywnego JPEG
Progresywny JPEG składa się z kilku tak zwanych segmentów skanowania, z których każdy zawiera część końcowego obrazu. Pierwszy skan pokazuje obraz tylko z grubsza, podczas gdy kolejne w dalszej części pliku dodają coraz więcej szczegółowych informacji do już załadowanych danych i ostatecznie tworzą ostateczny wygląd.
O tym, jak dokładnie wyglądają poszczególne skany, decyduje program generujący pliki JPEG. W programach wiersza poleceń, takich jak cjpeg z projektu mozjpeg, możesz nawet określić, jakie dane zawierają te skany. Wymaga to jednak głębszej wiedzy, wykraczającej poza zakres tego artykułu. W tym celu chciałbym zapoznać się z moim artykułem „Wreszcie zrozumienie JPG”, który uczy podstaw kompresji JPEG. Dokładne parametry, które należy przekazać do programu w skrypcie skanowania, są wyjaśnione w pliku wizard.txt projektu mozjpeg. Moim zdaniem parametry skryptu skanowania (siedem skanów) używane domyślnie przez mozjpeg są dobrym kompromisem między szybką strukturą progresywną a rozmiarem pliku i dlatego można je zastosować.
Aby przekształcić nasz początkowy JPEG w progresywny JPEG, używamy jpegtran z projektu mozjpeg. Jest to narzędzie do wprowadzania bezstratnych zmian w istniejącym pliku JPEG. Wstępnie skompilowane kompilacje dla systemów Windows i Linux są dostępne tutaj: https://mozjpeg.codelove.de/binaries.html. Jeśli wolisz grać bezpiecznie ze względów bezpieczeństwa, lepiej zbudować je samemu.
Z wiersza poleceń tworzymy teraz nasz progresywny JPEG:
$ jpegtran input.jpg > progressive.jpgFakt, że chcemy zbudować progresywny JPEG, jest zakładany przez jpegtran i nie musi być wyraźnie określony. Dane obrazu nie zostaną w żaden sposób zmienione. Zmieniany jest tylko układ danych obrazu w pliku.
Metadane nieistotne dla wyglądu obrazu (takie jak dane Exif, IPTC lub XMP) najlepiej byłoby usunąć z pliku JPEG, ponieważ odpowiednie segmenty mogą być odczytane przez dekodery metadanych tylko wtedy, gdy poprzedzają zawartość obrazu. Ponieważ z tego powodu nie możemy przenieść ich za dane obrazu w pliku, zostałyby już dostarczone z obrazem podglądu i odpowiednio powiększyłyby pierwsze żądanie. Za pomocą programu wiersza poleceń exiftool możesz łatwo usunąć te metadane:
$ exiftool -all= progressive.jpgJeśli nie chcesz używać narzędzia wiersza poleceń, możesz również skorzystać z usługi kompresji online compress-or-die.com, aby wygenerować progresywny plik JPEG bez metadanych.
2. Określ przesunięcie bajtów, do którego pierwsze żądanie zakresu HTTP musi załadować obraz podglądu
Plik JPEG jest podzielony na różne segmenty, z których każdy zawiera różne komponenty (dane obrazu, metadane, takie jak IPTC, Exif i XMP, osadzone profile kolorów, tabele kwantyzacji itp.). Każdy z tych segmentów zaczyna się od znacznika wprowadzonego przez szesnastkowy bajt FF . Po nim następuje bajt wskazujący typ segmentu. Na przykład D8 uzupełnia znacznik do znacznika SOI FF D8 (Początek obrazu), od którego zaczyna się każdy plik JPEG.
Każdy początek skanowania jest oznaczony znacznikiem SOS (Start Of Scan, szesnastkowy FF DA ). Ponieważ dane za znacznikiem SOS są kodowane entropijnie (JPEG używają kodowania Huffmana), istnieje inny segment z tablicami Huffmana (DHT, szesnastkowy FF C4 ) wymagany do dekodowania przed segmentem SOS. Obszar, który nas interesuje w progresywnym pliku JPEG, składa się zatem z naprzemiennych tabel Huffmana/segmentów danych skanowania. Tak więc, jeśli chcemy wyświetlić pierwszy bardzo przybliżony skan obrazu, musimy zażądać od serwera wszystkich bajtów do drugiego wystąpienia segmentu DHT (szesnastkowo FF C4 ).
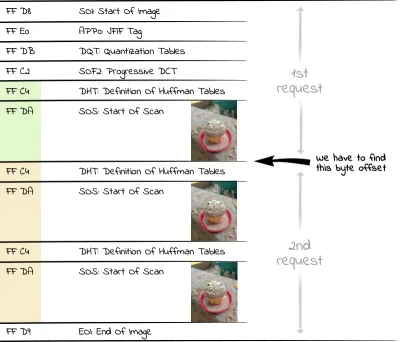
W PHP możemy użyć następującego kodu, aby odczytać liczbę bajtów wymaganych dla wszystkich skanów do tablicy:
<?php $img = "progressive.jpg"; $jpgdata = file_get_contents($img); $positions = []; $offset = 0; while ($pos = strpos($jpgdata, "\xFF\xC4", $offset)) { $positions[] = $pos+2; $offset = $pos+2; }Musimy dodać wartość dwa do znalezionej pozycji, ponieważ przeglądarka renderuje tylko ostatni wiersz obrazu podglądu, gdy napotka nowy znacznik (który składa się z dwóch bajtów, jak już wspomniano).
Ponieważ interesuje nas pierwszy obraz podglądu w tym przykładzie, znajdujemy prawidłową pozycję w $positions[1] , do której musimy zażądać pliku przez HTTP Range Request. Aby zażądać obrazu o lepszej rozdzielczości, moglibyśmy użyć późniejszej pozycji w tablicy, np. $positions[3] .

3. Tworzenie frontendowego kodu JavaScript
Przede wszystkim definiujemy tag img , któremu nadajemy właśnie obliczoną pozycję bajtu:
<img data-src="progressive.jpg" data-bytes="<?= $positions[1] ?>"> Jak to często bywa w przypadku leniwych bibliotek ładowania, nie definiujemy bezpośrednio atrybutu src , aby przeglądarka nie zaczęła od razu żądać obrazu z serwera podczas parsowania kodu HTML.
Za pomocą następującego kodu JavaScript ładujemy teraz obraz podglądu:
var $img = document.querySelector("img[data-src]"); var URL = window.URL || window.webkitURL; var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ $img.src_part = this.response; $img.src = URL.createObjectURL(this.response); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes=0-" + $img.getAttribute('data-bytes')); xhr.responseType = 'blob'; xhr.send(); Ten kod tworzy żądanie Ajax, które mówi serwerowi w nagłówku zakresu HTTP, aby zwrócił plik od początku do pozycji określonej w data-bytes ... i nic więcej. Jeśli serwer rozumie żądania zakresu HTTP, zwraca dane obrazu binarnego w odpowiedzi HTTP-206 (HTTP 206 = Partial Content) w postaci obiektu blob, z którego możemy wygenerować wewnętrzny adres URL przeglądarki za pomocą funkcji createObjectURL . Używamy tego adresu URL jako src dla naszego tagu img . W ten sposób załadowaliśmy nasz obraz podglądu.
Blob przechowujemy dodatkowo w obiekcie DOM we właściwości src_part , ponieważ będziemy potrzebować tych danych natychmiast.
W zakładce sieci konsoli programisty możesz sprawdzić, czy nie załadowaliśmy całego obrazu, a jedynie niewielką część. Dodatkowo ładowanie adresu URL obiektu blob powinno być wyświetlane w rozmiarze 0 bajtów.
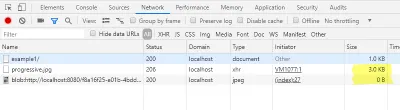
Ponieważ ładujemy już nagłówek JPEG oryginalnego pliku, obraz podglądu ma prawidłowy rozmiar. Dzięki temu w zależności od aplikacji możemy pominąć wysokość i szerokość tagu img .
Alternatywa: ładowanie podglądu obrazu w trybie inline
Ze względu na wydajność możliwe jest również przesłanie danych obrazu podglądu jako identyfikatora URI danych bezpośrednio w kodzie źródłowym HTML. Oszczędza nam to kosztów związanych z przesyłaniem nagłówków HTTP, ale kodowanie base64 sprawia, że dane obrazu są o jedną trzecią większe. Jest to relatywizowane, jeśli dostarczasz kod HTML z kodowaniem treści, takim jak gzip lub brotli , ale nadal powinieneś używać identyfikatorów URI danych dla małych obrazów podglądu.
Dużo ważniejszy jest fakt, że obrazy podglądu są dostępne od razu i nie ma zauważalnego opóźnienia dla użytkownika podczas budowania strony.
Przede wszystkim musimy stworzyć identyfikator URI danych, którego następnie używamy w tagu img jako src . W tym celu tworzymy identyfikator URI danych za pomocą PHP, przy czym ten kod jest oparty na właśnie utworzonym kodzie, który określa przesunięcia bajtów znaczników SOS:
<?php … $fp = fopen($img, 'r'); $data_uri = 'data:image/jpeg;base64,'. base64_encode(fread($fp, $positions[1])); fclose($fp); Utworzony identyfikator URI danych jest teraz wstawiany bezpośrednio do tagu `img` jako src :
<img src="<?= $data_uri ?>" data-src="progressive.jpg" alt="">Oczywiście należy również dostosować kod JavaScript:
<script> var $img = document.querySelector("img[data-src]"); var binary = atob($img.src.slice(23)); var n = binary.length; var view = new Uint8Array(n); while(n--) { view[n] = binary.charCodeAt(n); } $img.src_part = new Blob([view], { type: 'image/jpeg' }); $img.setAttribute('data-bytes', $img.src_part.size - 1); </script> Zamiast żądać danych za pośrednictwem żądania Ajax, gdzie natychmiast otrzymalibyśmy blob, w tym przypadku musimy sami utworzyć blob z identyfikatora URI danych. W tym celu uwalniamy data-URI z części, która nie zawiera danych obrazu: data:image/jpeg;base64 . Dekodujemy pozostałe dane zakodowane w base64 za pomocą polecenia atob . Aby utworzyć obiekt blob z danych w postaci ciągu binarnego, musimy przenieść dane do tablicy Uint8, co zapewnia, że dane nie będą traktowane jako tekst zakodowany w UTF-8. Z tej tablicy możemy teraz utworzyć binarny obiekt blob z danymi obrazu obrazu podglądu.
Abyśmy nie musieli dostosowywać poniższego kodu do tej wbudowanej wersji, dodajemy atrybut data-bytes do tagu img , który w poprzednim przykładzie zawiera offset bajtowy, z którego ma zostać załadowana druga część obrazu .
W zakładce sieci konsoli deweloperskiej również tutaj możesz sprawdzić, że wczytanie obrazu podglądu nie generuje dodatkowego żądania, natomiast rozmiar pliku strony HTML uległ zwiększeniu.
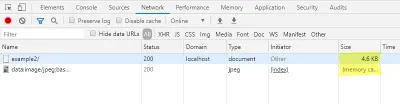
Ładowanie ostatecznego obrazu
W drugim kroku ładujemy resztę pliku obrazu po dwóch sekundach jako przykład:
setTimeout(function(){ var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ var blob = new Blob([$img.src_part, this.response], { type: 'image/jpeg'} ); $img.src = URL.createObjectURL(blob); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes="+ (parseInt($img.getAttribute('data-bytes'), 10)+1) +'-'); xhr.responseType = 'blob'; xhr.send(); }, 2000); W nagłówku Range tym razem określamy, że chcemy zażądać obrazu od pozycji końcowej obrazu podglądu do końca pliku. Odpowiedź na pierwsze żądanie jest przechowywana we właściwości src_part obiektu DOM. Używamy odpowiedzi z obu żądań, aby utworzyć nowy obiekt blob dla new Blob() , który zawiera dane całego obrazu. Wygenerowany z tego adres URL obiektu BLOB jest ponownie używany jako src obiektu DOM. Teraz obraz jest całkowicie załadowany.
Również teraz możemy ponownie sprawdzić załadowane rozmiary w zakładce sieci konsoli programisty..
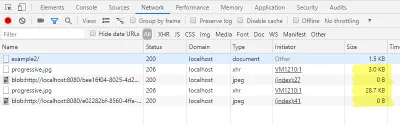
Prototyp
Pod następującym adresem umieściłem prototyp, na którym można poeksperymentować z różnymi parametrami: https://embedded-image-preview.cerdmann.com/prototype/
Repozytorium GitHub dla prototypu można znaleźć tutaj: https://github.com/McSodbrenner/embedded-image-preview
Rozważania na koniec
Korzystając z przedstawionej tutaj technologii Embedded Image Preview (EIP), możemy załadować jakościowo różne obrazy podglądu z progresywnych plików JPEG za pomocą Ajax i HTTP Range Request. Dane z tych obrazów podglądu nie są odrzucane, ale ponownie wykorzystywane do wyświetlania całego obrazu.
Ponadto nie trzeba tworzyć obrazów podglądu. Po stronie serwera należy określić i zapisać tylko przesunięcie bajtów, przy którym kończy się obraz podglądu. W systemie CMS powinno być możliwe zapisanie tego numeru jako atrybutu na obrazie i uwzględnienie go podczas wyprowadzania go w tagu img . Można sobie nawet wyobrazić przepływ pracy, który uzupełnia nazwę pliku obrazu o przesunięcie, np. progressive-8343.jpg , aby nie musieć zapisywać przesunięcia poza plikiem obrazu. To przesunięcie może zostać wyodrębnione przez kod JavaScript.
Ponieważ dane obrazu podglądu są ponownie wykorzystywane, technika ta może być lepszą alternatywą dla zwykłego podejścia polegającego na wczytywaniu obrazu podglądu, a następnie WebP (i zapewnianiu awaryjnego pliku JPEG dla przeglądarek nieobsługujących WebP). Obraz podglądu często niszczy zalety pamięci WebP, które nie obsługują trybu progresywnego.
Obecnie obrazy podglądu w normalnym LQIP są gorszej jakości, ponieważ zakłada się, że ładowanie danych podglądu wymaga dodatkowej przepustowości. Jak Robin Osborne wyjaśnił już w poście na blogu z 2018 roku, nie ma sensu pokazywać symboli zastępczych, które nie dają wyobrażenia o ostatecznym obrazie. Korzystając z sugerowanej tutaj techniki, możemy bez wahania pokazać nieco więcej końcowego obrazu jako obraz podglądu, przedstawiając użytkownikowi późniejszy skan progresywnego JPEG.
W przypadku słabego połączenia sieciowego użytkownika sensowne może być, w zależności od aplikacji, nie ładowanie całego JPEG, ale np. pominięcie dwóch ostatnich skanów. Daje to znacznie mniejszy plik JPEG o tylko nieznacznie obniżonej jakości. Użytkownik nam za to podziękuje, a my nie musimy przechowywać dodatkowego pliku na serwerze.
Teraz życzę Wam dobrej zabawy podczas wypróbowywania prototypu i czekam na Wasze komentarze.