
Wykrywanie fałszywych wiadomości w uczeniu maszynowym [Wyjaśniono na przykładzie kodowania]
Opublikowany: 2021-02-08Fake news to jeden z największych problemów w obecnej erze internetu i mediów społecznościowych. Chociaż to błogosławieństwo, że wiadomości przepływają z jednego zakątka świata do drugiego w ciągu kilku godzin, bolesne jest również to, że wiele osób i grup rozpowszechnia fałszywe wiadomości.
Techniki uczenia maszynowego wykorzystujące przetwarzanie języka naturalnego i głębokie uczenie mogą być w pewnym stopniu wykorzystane do rozwiązania tego problemu. W tym samouczku będziemy budować model wykrywania fałszywych wiadomości przy użyciu uczenia maszynowego.
Pod koniec tego artykułu będziesz wiedzieć, co następuje:
- Obsługa danych tekstowych
- Techniki przetwarzania NLP
- Wektoryzacja zliczania i TF-IDF
- Przewidywanie i klasyfikowanie tekstu wiadomości
Dołącz do kursu AI & ML online z najlepszych światowych uniwersytetów - Masters, Executive Post Graduate Programs i Advanced Certificate Program in ML & AI, aby przyspieszyć swoją karierę.
Spis treści
Dane i problem
Użyjemy danych wyzwania Kaggle Fake News do stworzenia klasyfikatora. Zestaw danych składa się z 4 funkcji i 1 celu binarnego. Te 4 funkcje są następujące:
- id : unikalny identyfikator artykułu z wiadomościami
- title : tytuł artykułu z wiadomościami
- autor : autor artykułu z wiadomościami
- tekst : tekst artykułu; może być niekompletny
A celem jest „etykieta”, która zawiera wartości binarne 0s i 1s. Gdzie 0 oznacza, że jest to wiarygodne źródło wiadomości, czyli innymi słowy, Not Fake. 1 oznacza, że jest to potencjalnie fałszywy news i nie jest wiarygodny. Zbiór danych, który mamy składał się z 20800 instancji. Zanurzmy się od razu.

Wstępne przetwarzanie i czyszczenie danych
| importuj pandy jako PD df=pd.read_csv( 'fałszywe-wiadomości/pociąg.csv' ) df.głowa() |
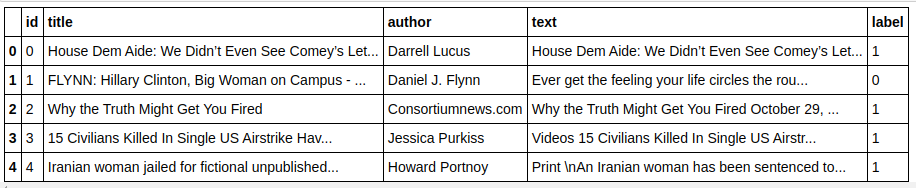
| X=df.drop( 'etykieta' ,oś= 1 ) # Funkcje y=df[ 'etykieta' ] # Cel |
Musimy teraz usunąć instancje z brakującymi danymi.
| df=df.dropna() |
![]()
Jak widać, porzucił wszystkie instancje z brakującymi danymi.
| komunikaty=df.kopiuj() wiadomości.reset_index(inplace= Prawda ) wiadomości.głowa( 10 ) |
Przyjrzyjmy się raz danym.
| wiadomości['tekst'][6] |

Jak widać, konieczne jest wykonanie następujących kroków:
- Usuwanie odrzucanych słów: istnieje wiele słów, które nie dodają wartości żadnemu tekstowi, bez względu na dane. Na przykład „ja”, „a”, „am” itp. Te słowa nie mają wartości informacyjnej i dlatego można je usunąć, aby zmniejszyć rozmiar naszego korpusu, abyśmy mogli skupić się tylko na słowach/tokenach, które mają rzeczywistą wartość .
- Osadzanie słów: Tworzenie i lemmatyzacja to techniki redukujące słowa do ich rdzenia lub rdzenia. Główną zaletą tego kroku jest zmniejszenie rozmiaru słownictwa. Na przykład słowa takie jak Play, Playing, Played zostaną zredukowane do „Play”. Stemming po prostu skraca słowa do najkrótszego słowa i nie uwzględnia gramatycznego aspektu tekstu. Z drugiej strony lematyzacja uwzględnia również gramatykę, a zatem daje znacznie lepsze wyniki. Lematyzacja jest jednak zwykle wolniejsza niż lematyzacja, ponieważ musi odwoływać się do słownika i uwzględniać aspekt gramatyczny.
- Usuwanie wszystkiego poza wartościami alfabetycznymi: Wartości niealfabetyczne nie są tutaj zbyt przydatne, więc można je usunąć. Możesz jednak dokładniej zbadać, czy obecność danych liczbowych lub innych typów danych ma jakikolwiek wpływ na obiekt docelowy.
- Małe litery: małe litery słów, aby zredukować słownictwo.
- Tokenizuj zdania: Generowanie tokenów ze zdań.
| z sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer z nltk.corpus import stopwords z nltk.stem.porter importuj PorterStemmer importuj ponownie ps = PorterStemmer() corpus = [] for i in range(0, len(messages)): recenzja = re.sub('[^a-zA-Z]', ' ', wiadomości['text'][i]) recenzja = recenzja.niższa() recenzja = recenzja.split() review = [ps.stem(word) dla słowa w recenzji jeśli nie słowo w stopwords.words('english')] review = ' '.join(recenzja) corpus.append(recenzja) |
Przyjrzyjmy się teraz naszemu korpusowi.
| korpus[ 3 ] |
![]()
Jak widzimy, słowa są teraz oparte na słowach źródłowych.
Wektoryzator TF-IDF
Teraz musimy zwektoryzować słowa do danych liczbowych, co nazywamy również wektoryzacją. Najłatwiejszym sposobem wektoryzacji jest użycie Worka słów. Ale Bag of Words tworzy rzadką macierz i stąd potrzeba dużo pamięci do przetwarzania. Co więcej, BoW nie bierze pod uwagę częstotliwości słów, co czyni go złym algorytmem.
TF-IDF (Term Frequency – Inverse Document Frequency) to kolejny sposób wektoryzacji słów, który uwzględnia częstotliwości słów. Na przykład popularne słowa, takie jak „my”, „nasz”, „the”, znajdują się w każdym dokumencie/instancji, dlatego wartość BoW będzie zbyt wysoka, a przez to myląca. Doprowadzi to do złego modelu. TF-IDF jest iloczynem Częstotliwości Terminu i Odwrotnej Częstotliwości Dokumentu.
Termin Częstotliwość uwzględnia częstotliwość występowania słów w dokumencie, a Odwrócona częstotliwość dokumentu uwzględnia słowa występujące w całym korpusie. Słowa obecne w całym korpusie mają mniejsze znaczenie, ponieważ wartość IDF jest znacznie niższa. Słowa występujące konkretnie w jednym dokumencie mają wysoką wartość IDF, co powoduje, że całkowita wartość TF-IDF jest wysoka.
| ## TFi df Vectorizer ze sklearn.feature_extraction.text import TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=wiadomości[ 'etykieta' ] |
W powyższym kodzie importujemy Vectorizer TF-IDF z modułu ekstrakcji cech Sklearna. Tworzymy jego obiekt, przekazując max_features jako 5000 i ngram_range jako (1,3). Parametr max_features określa maksymalną liczbę wektorów cech, które chcemy utworzyć, a parametr ngram_range określa kombinacje ngramów, które chcemy uwzględnić. W naszym przypadku otrzymamy 3 kombinacje 1 słowa, 2 słów i 3 słów. Przyjrzyjmy się niektórym utworzonym funkcjom.

| tfidf_v.get_feature_names()[: 20 ] |

Jak widać, powstaje wiele rodzajów kombinacji. Istnieją nazwy cech z 1 żetonem, 2 żetonami, a także z 3 żetonami.
Tworzenie Dataframe
| ## Podziel zbiór danych na Train and Test ze sklearn.model_selection importuj train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, kolumny=tfidf_v.get_feature_names()) count_df.head() |
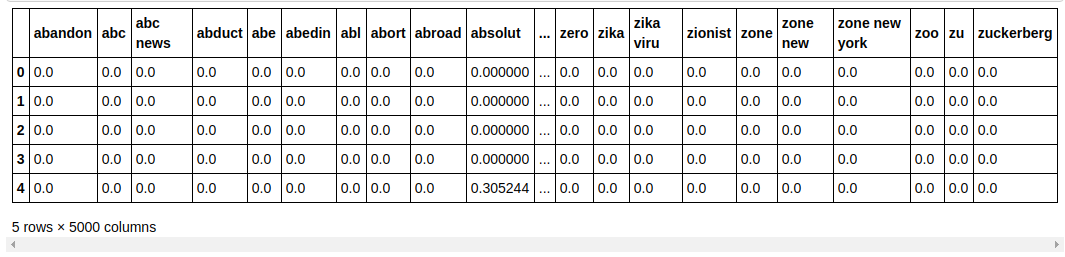
Dzielimy zestaw danych na pociąg i test, dzięki czemu możemy przetestować wydajność modelu na niewidocznych danych. Następnie tworzymy nowy Dataframe, który zawiera w sobie nowe wektory cech.
Modelowanie i tuning
Wielomianowy algorytm NB
Po pierwsze, korzystamy z twierdzenia Multinomial Naive Bayes, które jest najczęstszym i najłatwiejszym algorytmem preferowanym do klasyfikacji danych tekstowych. Dopasowujemy się do danych treningowych i przewidujemy na danych testowych. Później obliczamy i wykreślamy macierz pomyłek i uzyskujemy dokładność 88,1%.
| ze sklearn.naive_bayes importuj MultinomialNB ze sklearn import metryk importuj numer jako np importować itertools ze sklearn.metrics importuj plot_confusion_matrix klasyfikator=WielomianowyNB() classifier.fit(X_train, y_train) pred = klasyfikator.predict(X_test) wynik = metrics.accuracy_score(y_test, pred) print( „dokładność: %0.3f” % wynik) cm = metryki.confusion_matrix(y_test, pred) plot_confusion_matrix(cm, class=[ 'FAKE' , 'REAL' ]) |
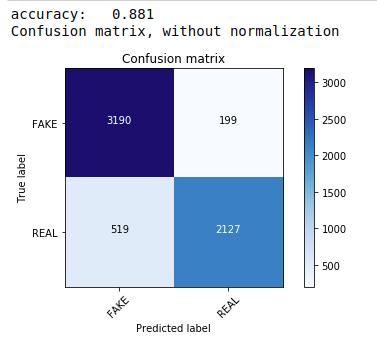
Klasyfikator wielomianowy z dostrajaniem hiperparametrów
MultinomialNB ma parametr alfa, który można dalej dostrajać. Dlatego uruchamiamy pętlę, aby wypróbować wiele klasyfikatorów MultinomialNB z różnymi wartościami alfa i sprawdzić ich wyniki dokładności. I sprawdzamy, czy obecny wynik jest wyższy od poprzedniego. Jeśli tak, to ustawiamy klasyfikator jako aktualny.
| poprzedni_wynik= 0 dla alfa w np.arange( 0 , 1 , 0.1 ): sub_classifier=WielomianowyNB(alfa=alfa) sub_classifier.fit(X_train,y_train) y_pred=sub_classifier.predict(X_test) wynik = metrics.accuracy_score(y_test, y_pred) if score>previous_score: klasyfikator=podklasyfikator print( “Alfa: {}, Ocena : {}” .format(alfa,wynik)) |
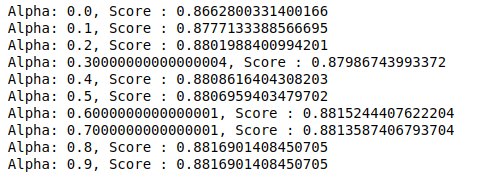
Stąd widzimy, że wartość alfa 0,9 lub 0,8 dawała najwyższy wynik dokładności.
Interpretacja wyników
Zobaczmy teraz, co oznaczają te wartości współczynników klasyfikatora. Najpierw zapiszemy wszystkie nazwy funkcji w innej zmiennej.
| ## Pobieranie nazw funkcji nazwy funkcji = cv.get_feature_names() |
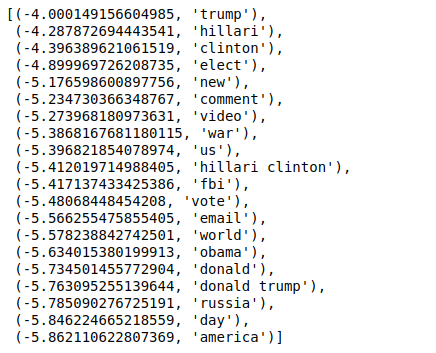
Teraz, gdy sortujemy wartości w odwrotnej kolejności, otrzymujemy wartości o minimalnej wartości -4. Oznaczają one słowa, które są najbardziej prawdziwe lub najmniej fałszywe.
| ### Najbardziej prawdziwe sorted(zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
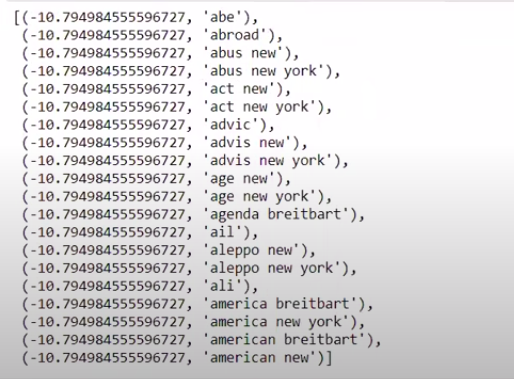
Kiedy sortujemy wartości w nieodwrotnej kolejności, otrzymujemy wartości o minimalnej wartości -10. Oznaczają one słowa najmniej prawdziwe lub najbardziej fałszywe.
| ### Najbardziej prawdziwe sorted(zip(classifier.coef_[ 0 ],feature_names))[: 20 ] |
Wniosek
W tym samouczku użyliśmy tylko algorytmów ML, ale używasz również innych metod sieci neuronowych. Ponadto do wektoryzacji danych tekstowych użyliśmy wektoryzatora TF-IDF. Istnieje więcej wektorów, takich jak Count Vectorizer, Hashing Vectorizer itp., Które mogą być lepsze w wykonywaniu pracy. Wypróbuj i eksperymentuj z innymi algorytmami i technikami, aby zobaczyć, czy możesz osiągnąć lepsze wyniki, czy nie.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, zapoznaj się z programem IIIT-B i upGrad Executive PG w zakresie uczenia maszynowego i sztucznej inteligencji , który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadań, IIIT Status -B Alumni, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Dlaczego istnieje potrzeba wykrywania fałszywych wiadomości?
W obecnym stanie platformy mediów społecznościowych są bardzo potężne i cenne, ponieważ pozwalają użytkownikom dyskutować i wymieniać się pomysłami, a także dyskutować na takie tematy, jak demokracja, edukacja i zdrowie. Jednak niektóre podmioty źle wykorzystują takie platformy, w niektórych okolicznościach dla zysku pieniężnego i tworzenia uprzedzeń, zmiany sposobu myślenia i rozpowszechniania satyry lub śmieszności w innych. Fake news to określenie na to zjawisko. Rozprzestrzenianie się publikowanych w Internecie elementów, które nie są zgodne z rzeczywistością, spowodowało wiele problemów w polityce, sporcie, zdrowiu, nauce i innych dziedzinach.
Które firmy najczęściej wykorzystują wykrywanie fałszywych wiadomości?
Wykrywanie fałszywych wiadomości jest wykorzystywane na platformach takich jak media społecznościowe i witryny informacyjne. Giganty mediów społecznościowych, takie jak Facebook, Instagram i Twitter, są podatne na fałszywe wiadomości, ponieważ większość ich użytkowników polega na nich jako na codziennych źródłach wiadomości, aby uzyskać najbardziej aktualne informacje. Techniki wykrywania fałszywych informacji są również wykorzystywane przez firmy medialne do określania autentyczności posiadanych informacji. E-mail to kolejne medium, przez które osoby fizyczne mogą otrzymywać wiadomości, co utrudnia identyfikację i weryfikację ich prawdziwości. Fałszywe wiadomości, spam i wiadomości-śmieci są dobrze znane z tego, że są przesyłane za pośrednictwem poczty e-mail. W rezultacie większość platform pocztowych wykorzystuje wykrywanie fałszywych wiadomości w celu identyfikacji spamu i wiadomości-śmieci.