
Jak skonfigurować projekt zaplecza API Express z PostgreSQL?
Opublikowany: 2022-03-10Przyjmiemy podejście Test-Driven Development (TDD) i skonfigurujemy zadanie Continuous Integration (CI), aby automatycznie uruchamiać nasze testy na Travis CI i AppVeyor, wraz z raportowaniem jakości kodu i pokrycia. Poznamy kontrolery, modele (z PostgreSQL), obsługę błędów i asynchroniczne oprogramowanie pośredniczące Express. Na koniec zakończymy proces CI/CD, konfigurując automatyczne wdrażanie w Heroku.
Brzmi to dużo, ale ten samouczek jest skierowany do początkujących, którzy są gotowi spróbować swoich sił w projekcie zaplecza o pewnym poziomie złożoności, i którzy nadal mogą być zdezorientowani, jak wszystkie elementy pasują do siebie w prawdziwym projekcie .
Jest solidny, ale nie przytłaczający i jest podzielony na sekcje, które możesz ukończyć w rozsądnym czasie.
Pierwsze kroki
Pierwszym krokiem jest utworzenie nowego katalogu dla projektu i rozpoczęcie nowego projektu węzła. Węzeł jest wymagany do kontynuowania tego samouczka. Jeśli nie masz go zainstalowanego, przejdź do oficjalnej strony internetowej, pobierz i zainstaluj, zanim przejdziesz dalej.
Będę używał przędzy jako mojego menedżera opakowań w tym projekcie. Tutaj znajdują się instrukcje instalacji dla konkretnego systemu operacyjnego. Jeśli chcesz, możesz skorzystać z npm.
Otwórz terminal, utwórz nowy katalog i rozpocznij projekt Node.js.
# create a new directory mkdir express-api-template # change to the newly-created directory cd express-api-template # initialize a new Node.js project npm initOdpowiedz na poniższe pytania, aby wygenerować plik package.json . Ten plik zawiera informacje o Twoim projekcie. Przykład takich informacji obejmuje używane zależności, polecenie uruchomienia projektu i tak dalej.
Możesz teraz otworzyć folder projektu w wybranym przez siebie edytorze. Używam kodu studia wizualnego. Jest to darmowe środowisko IDE z mnóstwem wtyczek, które ułatwiają życie, i jest dostępne na wszystkich głównych platformach. Możesz go pobrać z oficjalnej strony internetowej.
Utwórz następujące pliki w folderze projektu:
- README.md
- .editorconfig
Oto opis tego, co .editorconfig robi z witryny internetowej EditorConfig. (Prawdopodobnie nie potrzebujesz tego, jeśli pracujesz solo, ale to nie zaszkodzi, więc zostawię to tutaj.)
„EditorConfig pomaga utrzymać spójne style kodowania dla wielu programistów pracujących nad tym samym projektem w różnych edytorach i środowiskach IDE”.
Otwórz .editorconfig i wklej następujący kod:
root = true [*] indent_style = space indent_size = 2 charset = utf-8 trim_trailing_whitespace = false insert_final_newline = true [*] oznacza, że chcemy zastosować reguły, które się pod nim znajdują, do każdego pliku w projekcie. Chcemy mieć wcięcie o rozmiarze dwóch spacji i zestaw znaków UTF-8 . Chcemy również przyciąć końcowe białe znaki i wstawić ostatnią pustą linię do naszego pliku.
Otwórz README.md i dodaj nazwę projektu jako element pierwszego poziomu.
# Express API templateDodajmy od razu kontrolę wersji.
# initialize the project folder as a git repository git initUtwórz plik .gitignore i wprowadź następujące wiersze:
node_modules/ yarn-error.log .env .nyc_output coverage build/To są wszystkie pliki i foldery, których nie chcemy śledzić. Nie mamy ich jeszcze w naszym projekcie, ale zobaczymy je w miarę postępów.
W tym momencie powinieneś mieć następującą strukturę folderów.
EXPRESS-API-TEMPLATE ├── .editorconfig ├── .gitignore ├── package.json └── README.mdUważam, że jest to dobry punkt, aby zatwierdzić moje zmiany i przesłać je na GitHub.
Rozpoczęcie nowego projektu ekspresowego
Express to framework Node.js do tworzenia aplikacji internetowych. Według oficjalnej strony internetowej jest to
Szybki, nieoceniony, minimalistyczny framework webowy dla Node.js.
Istnieją inne świetne frameworki aplikacji internetowych dla Node.js, ale Express jest bardzo popularny, z ponad 47 tysiącami gwiazdek GitHub w momencie pisania tego tekstu.
W tym artykule nie będziemy prowadzić wielu dyskusji na temat wszystkich części, które składają się na Express. Do tej dyskusji polecam zapoznać się z serią Jamiego. Pierwsza część jest tutaj, a druga część jest tutaj.
Zainstaluj Express i rozpocznij nowy projekt Express. Możliwe jest ręczne skonfigurowanie serwera Express od podstaw, ale aby ułatwić nam życie, użyjemy ekspresowego generatora do skonfigurowania szkieletu aplikacji.
# install the express generator globally yarn global add express-generator # install express yarn add express # generate the express project in the current folder express -f Flaga -f zmusza Express do utworzenia projektu w bieżącym katalogu.
Przeprowadzimy teraz kilka operacji sprzątania domu.
- Usuń plik index/users.js .
- Usuń foldery
public/iviews/. - Zmień nazwę pliku bin/www na bin/www.js .
- Odinstaluj
jadeza pomocą poleceniayarn remove jade. - Utwórz nowy folder o nazwie
src/i przenieś do niego: 1. plik app.js 2. folderbin/3. folderroutes/do środka. - Otwórz package.json i zaktualizuj skrypt
start, aby wyglądał jak poniżej.
"start": "node ./src/bin/www"W tym momencie struktura folderów projektu wygląda jak poniżej. Możesz zobaczyć, jak VS Code wyróżnia wprowadzone zmiany w plikach.
EXPRESS-API-TEMPLATE ├── node_modules ├── src | ├── bin │ │ ├── www.js │ ├── routes │ | ├── index.js │ └── app.js ├── .editorconfig ├── .gitignore ├── package.json ├── README.md └── yarn.lockOtwórz src/app.js i zastąp zawartość poniższym kodem.
var logger = require('morgan'); var express = require('express'); var cookieParser = require('cookie-parser'); var indexRouter = require('./routes/index'); var app = express(); app.use(logger('dev')); app.use(express.json()); app.use(express.urlencoded({ extended: true })); app.use(cookieParser()); app.use('/v1', indexRouter); module.exports = app; Po zażądaniu kilku bibliotek, poinstruujemy Express, aby obsługiwał każde żądanie przychodzące do /v1 za pomocą indexRouter .
Zastąp zawartość routes/index.js poniższym kodem:
var express = require('express'); var router = express.Router(); router.get('/', function(req, res, next) { return res.status(200).json({ message: 'Welcome to Express API template' }); }); module.exports = router; Bierzemy Express, tworzymy z niego router i obsługujemy trasę / , która zwraca kod statusu 200 i wiadomość JSON.
Uruchom aplikację za pomocą poniższego polecenia:
# start the app yarn start Jeśli wszystko skonfigurowałeś poprawnie, powinieneś widzieć tylko $ node ./src/bin/www w swoim terminalu.
Odwiedź https://localhost:3000/v1 w swojej przeglądarce. Powinieneś zobaczyć następujący komunikat:
{ "message": "Welcome to Express API template" }To dobry moment, aby zatwierdzić nasze zmiany.
- Odpowiednia gałąź w moim repozytorium to 01-install-express.
Konwersja naszego kodu do ES6
Kod generowany przez express-generator znajduje się w ES5 , ale w tym artykule będziemy pisać cały nasz kod w składni ES6 . Skonwertujmy więc nasz istniejący kod do ES6 .
Zastąp zawartość routes/index.js poniższym kodem:
import express from 'express'; const indexRouter = express.Router(); indexRouter.get('/', (req, res) => res.status(200).json({ message: 'Welcome to Express API template' }) ); export default indexRouter; Jest to ten sam kod, który widzieliśmy powyżej, ale z instrukcją import i funkcją strzałki w obsłudze / route.
Zastąp zawartość src/app.js poniższym kodem:
import logger from 'morgan'; import express from 'express'; import cookieParser from 'cookie-parser'; import indexRouter from './routes/index'; const app = express(); app.use(logger('dev')); app.use(express.json()); app.use(express.urlencoded({ extended: true })); app.use(cookieParser()); app.use('/v1', indexRouter); export default app; Przyjrzyjmy się teraz zawartości src/bin/www.js . Będziemy go budować stopniowo. Usuń zawartość src/bin/www.js i wklej poniższy blok kodu.
#!/usr/bin/env node /** * Module dependencies. */ import debug from 'debug'; import http from 'http'; import app from '../app'; /** * Normalize a port into a number, string, or false. */ const normalizePort = val => { const port = parseInt(val, 10); if (Number.isNaN(port)) { // named pipe return val; } if (port >= 0) { // port number return port; } return false; }; /** * Get port from environment and store in Express. */ const port = normalizePort(process.env.PORT || '3000'); app.set('port', port); /** * Create HTTP server. */ const server = http.createServer(app); // next code block goes here Ten kod sprawdza, czy w zmiennych środowiskowych określono port niestandardowy. Jeśli żadna nie jest ustawiona, domyślna wartość portu 3000 jest ustawiana w wystąpieniu aplikacji po znormalizowaniu do ciągu lub liczby przez normalizePort . Serwer jest następnie tworzony z modułu http , z app jako funkcją wywołania zwrotnego.
Linia #!/usr/bin/env node jest opcjonalna, ponieważ określilibyśmy węzeł, gdy chcemy wykonać ten plik. Ale upewnij się, że znajduje się w wierszu 1 pliku src/bin/www.js lub całkowicie go usuń.
Przyjrzyjmy się funkcji obsługi błędów. Skopiuj i wklej ten blok kodu po wierszu, w którym tworzony jest serwer.
/** * Event listener for HTTP server "error" event. */ const onError = error => { if (error.syscall !== 'listen') { throw error; } const bind = typeof port === 'string' ? `Pipe ${port}` : `Port ${port}`; // handle specific listen errors with friendly messages switch (error.code) { case 'EACCES': alert(`${bind} requires elevated privileges`); process.exit(1); break; case 'EADDRINUSE': alert(`${bind} is already in use`); process.exit(1); break; default: throw error; } }; /** * Event listener for HTTP server "listening" event. */ const onListening = () => { const addr = server.address(); const bind = typeof addr === 'string' ? `pipe ${addr}` : `port ${addr.port}`; debug(`Listening on ${bind}`); }; /** * Listen on provided port, on all network interfaces. */ server.listen(port); server.on('error', onError); server.on('listening', onListening); Funkcja onError nasłuchuje błędów na serwerze http i wyświetla odpowiednie komunikaty o błędach. Funkcja onListening po prostu wyświetla port, na którym serwer nasłuchuje konsoli. Wreszcie serwer nasłuchuje przychodzących żądań pod określonym adresem i portem.
W tym momencie cały nasz istniejący kod jest w składni ES6 . Zatrzymaj swój serwer (użyj Ctrl + C ) i uruchom yarn start . Otrzymasz błąd SyntaxError: Invalid or unexpected token . Dzieje się tak, ponieważ Node (w momencie pisania) nie obsługuje niektórych składni, których użyliśmy w naszym kodzie.
Naprawimy to teraz w następnej sekcji.
Konfiguracja zależności programistycznych: babel , nodemon , eslint i prettier
Czas skonfigurować większość skryptów, których będziemy potrzebować w tej fazie projektu.
Zainstaluj wymagane biblioteki za pomocą poniższych poleceń. Możesz po prostu skopiować wszystko i wkleić w terminalu. Linie komentarza zostaną pominięte.
# install babel scripts yarn add @babel/cli @babel/core @babel/plugin-transform-runtime @babel/preset-env @babel/register @babel/runtime @babel/node --dev Instaluje to wszystkie wymienione skrypty babel jako zależności programistyczne. Sprawdź plik package.json i powinieneś zobaczyć sekcję devDependencies . Wszystkie zainstalowane skrypty zostaną tam wymienione.
Skrypty babel, których używamy, są wyjaśnione poniżej:
@babel/cli | Wymagana instalacja do korzystania z babel . Pozwala na korzystanie z Babel z terminala i jest dostępny jako ./node_modules/.bin/babel . |
@babel/core | Podstawowa funkcjonalność Babel. To jest wymagana instalacja. |
@babel/node | Działa to dokładnie tak, jak CLI Node.js, z dodatkową korzyścią kompilacji za pomocą predefiniowanych ustawień babel i wtyczek. Jest to wymagane do użytku z nodemon . |
@babel/plugin-transform-runtime | Pomaga to uniknąć duplikowania skompilowanych danych wyjściowych. |
@babel/preset-env | Zbiór wtyczek odpowiedzialnych za przeprowadzanie transformacji kodu. |
@babel/register | To kompiluje pliki w locie i jest określane jako wymaganie podczas testów. |
@babel/runtime | Działa to w połączeniu z @babel/plugin-transform-runtime . |
Utwórz plik o nazwie .babelrc w katalogu głównym projektu i dodaj następujący kod:
{ "presets": ["@babel/preset-env"], "plugins": ["@babel/transform-runtime"] } Zainstalujmy nodemon
# install nodemon yarn add nodemon --dev nodemon to biblioteka, która monitoruje kod źródłowy naszego projektu i automatycznie restartuje nasz serwer za każdym razem, gdy zauważy jakiekolwiek zmiany.
Utwórz plik o nazwie nodemon.json w katalogu głównym projektu i dodaj poniższy kod:
{ "watch": [ "package.json", "nodemon.json", ".eslintrc.json", ".babelrc", ".prettierrc", "src/" ], "verbose": true, "ignore": ["*.test.js", "*.spec.js"] } Klucz watch mówi nodemon , które pliki i foldery mają obserwować pod kątem zmian. Tak więc za każdym razem, gdy którykolwiek z tych plików ulegnie zmianie, nodemon ponownie uruchomi serwer. Klawisz ignore mówi plikom, aby nie szukały zmian.
Teraz zaktualizuj sekcję scripts w pliku package.json , aby wyglądała następująco:
# build the content of the src folder "prestart": "babel ./src --out-dir build" # start server from the build folder "start": "node ./build/bin/www" # start server in development mode "startdev": "nodemon --exec babel-node ./src/bin/www"- Skrypty
prestartbudują zawartość folderusrc/i umieszczają ją w folderzebuild/. Po wydaniu poleceniayarn startten skrypt jest uruchamiany jako pierwszy przed skryptemstart. - skrypt
startobsługuje teraz zawartość folderubuild/zamiast folderusrc/, który obsługiwaliśmy wcześniej. To jest skrypt, którego będziesz używać podczas udostępniania pliku w środowisku produkcyjnym. W rzeczywistości usługi takie jak Heroku automatycznie uruchamiają ten skrypt podczas wdrażania. -
yarn startdevsłuży do uruchamiania serwera podczas rozwoju. Od teraz będziemy używać tego skryptu podczas tworzenia aplikacji. Zauważ, że teraz do uruchamiania aplikacji używamybabel-nodezamiast zwykłegonode. Flaga--execzmuszababel-nodedo obsługi folderusrc/. W skrypciestartużywamynode, ponieważ pliki w folderzebuild/zostały skompilowane do ES5.
Uruchom yarn startdev i odwiedź https://localhost:3000/v1. Twój serwer powinien znowu działać.
Ostatnim krokiem w tej sekcji jest skonfigurowanie ESLint i prettier . ESLint pomaga w egzekwowaniu reguł składniowych, podczas gdy ładniejszy pomaga w prawidłowym formatowaniu naszego kodu w celu zapewnienia czytelności.
Dodaj oba z nich za pomocą poniższego polecenia. Powinieneś uruchomić to na osobnym terminalu, obserwując terminal, na którym działa nasz serwer. Powinieneś zobaczyć restart serwera. Dzieje się tak, ponieważ monitorujemy plik package.json pod kątem zmian.
# install elsint and prettier yarn add eslint eslint-config-airbnb-base eslint-plugin-import prettier --dev Teraz utwórz plik .eslintrc.json w root projektu i dodaj poniższy kod:
{ "env": { "browser": true, "es6": true, "node": true, "mocha": true }, "extends": ["airbnb-base"], "globals": { "Atomics": "readonly", "SharedArrayBuffer": "readonly" }, "parserOptions": { "ecmaVersion": 2018, "sourceType": "module" }, "rules": { "indent": ["warn", 2], "linebreak-style": ["error", "unix"], "quotes": ["error", "single"], "semi": ["error", "always"], "no-console": 1, "comma-dangle": [0], "arrow-parens": [0], "object-curly-spacing": ["warn", "always"], "array-bracket-spacing": ["warn", "always"], "import/prefer-default-export": [0] } } Ten plik w większości definiuje pewne zasady, według których eslint będzie sprawdzał nasz kod. Widać, że rozszerzamy zasady stylów stosowane przez Airbnb.
W sekcji "rules" określamy, czy eslint powinien pokazywać ostrzeżenie lub błąd w przypadku napotkania określonych naruszeń. Na przykład wyświetla komunikat ostrzegawczy na naszym terminalu dla każdego wcięcia, które nie używa 2 spacji. Wartość [0] wyłącza regułę, co oznacza, że nie otrzymamy ostrzeżenia ani błędu, jeśli naruszymy tę regułę.
Utwórz plik o nazwie .prettierrc i dodaj poniższy kod:
{ "trailingComma": "es5", "tabWidth": 2, "semi": true, "singleQuote": true } Ustawiamy szerokość tabulatora na 2 i wymuszamy stosowanie pojedynczych cudzysłowów w całej naszej aplikacji. Sprawdź ładniejszy przewodnik, aby uzyskać więcej opcji stylizacji.
Teraz dodaj następujące skrypty do swojego package.json :
# add these one after the other "lint": "./node_modules/.bin/eslint ./src" "pretty": "prettier --write '**/*.{js,json}' '!node_modules/**'" "postpretty": "yarn lint --fix" Uruchom yarn lint . W konsoli powinieneś zobaczyć szereg błędów i ostrzeżeń.
pretty polecenie upiększa nasz kod. Polecenie postpretty jest uruchamiane natychmiast po. Uruchamia polecenie lint z dołączoną flagą --fix . Ta flaga mówi ESLint , aby automatycznie naprawił typowe problemy z lintingiem. W ten sposób głównie uruchamiam polecenie yarn pretty bez zawracania sobie głowy poleceniem lint .
Uruchom yarn pretty . Powinieneś zobaczyć, że mamy tylko dwa ostrzeżenia o obecności alert w pliku bin/www.js .
Oto jak wygląda struktura naszego projektu w tym momencie.
EXPRESS-API-TEMPLATE ├── build ├── node_modules ├── src | ├── bin │ │ ├── www.js │ ├── routes │ | ├── index.js │ └── app.js ├── .babelrc ├── .editorconfig ├── .eslintrc.json ├── .gitignore ├── .prettierrc ├── nodemon.json ├── package.json ├── README.md └── yarn.lock Może się okazać, że w katalogu głównym projektu znajduje się dodatkowy plik yarn-error.log . Dodaj go do pliku .gitignore . Zatwierdź swoje zmiany.
- Odpowiednia gałąź w tym momencie w moim repozytorium to zależności 02-dev.
Ustawienia i zmienne środowiskowe w naszym pliku .env
W prawie każdym projekcie będziesz potrzebować miejsca do przechowywania ustawień, które będą używane w całej Twojej aplikacji, np. tajny klucz AWS. Przechowujemy takie ustawienia jako zmienne środowiskowe. To trzyma je z dala od wścibskich oczu i możemy ich używać w naszej aplikacji w razie potrzeby.
Lubię mieć plik settings.js , za pomocą którego czytam wszystkie moje zmienne środowiskowe. Następnie mogę odwołać się do pliku ustawień z dowolnego miejsca w mojej aplikacji. Możesz dowolnie nazwać ten plik, ale istnieje pewien konsensus co do nazywania takich plików settings.js lub config.js .
W przypadku naszych zmiennych środowiskowych będziemy przechowywać je w pliku .env i stamtąd wczytać je do naszego pliku settings .
Utwórz plik .env w katalogu głównym projektu i wprowadź poniższy wiersz:
TEST_ENV_VARIABLE="Environment variable is coming across" Aby móc wczytać zmienne środowiskowe do naszego projektu, istnieje ładna biblioteka dotenv , która odczytuje nasz plik .env i daje nam dostęp do zdefiniowanych w nim zmiennych środowiskowych. Zainstalujmy to.
# install dotenv yarn add dotenv Dodaj plik .env do listy plików obserwowanych przez nodemon .
Teraz utwórz plik settings.js w folderze src/ i dodaj poniższy kod:
import dotenv from 'dotenv'; dotenv.config(); export const testEnvironmentVariable = process.env.TEST_ENV_VARIABLE; Importujemy pakiet dotenv i wywołujemy jego metodę konfiguracji. Następnie eksportujemy testEnvironmentVariable , którą ustawiamy w naszym pliku .env .
Otwórz src/routes/index.js i zamień kod na poniższy.
import express from 'express'; import { testEnvironmentVariable } from '../settings'; const indexRouter = express.Router(); indexRouter.get('/', (req, res) => res.status(200).json({ message: testEnvironmentVariable })); export default indexRouter; Jedyną zmianą, jaką tutaj wprowadziliśmy, jest to, że importujemy testEnvironmentVariable z naszego pliku settings i używamy go jako wiadomości zwrotnej dla żądania z trasy / .
Odwiedź https://localhost:3000/v1 i powinieneś zobaczyć komunikat, jak pokazano poniżej.
{ "message": "Environment variable is coming across." }I to wszystko. Od teraz możemy dodać tyle zmiennych środowiskowych ile chcemy i możemy je wyeksportować z naszego pliku settings.js .
To jest dobry punkt, aby zatwierdzić swój kod. Pamiętaj, aby upiększyć i lintować swój kod.
- Odpowiednia gałąź w moim repozytorium to 03-env-variables.
Pisanie naszego pierwszego testu
Czas włączyć testy do naszej aplikacji. Jedną z rzeczy, które dają programistom zaufanie do ich kodu, są testy. Jestem pewien, że widziałeś niezliczoną ilość artykułów w Internecie, głoszących o Test-Driven Development (TDD). Nie można wystarczająco podkreślić, że Twój kod wymaga pewnych testów. TDD jest bardzo łatwe do naśladowania podczas pracy z Express.js.
W naszych testach wykonamy wywołania naszych punktów końcowych API i sprawdzimy, czy to, co jest zwracane, jest tym, czego oczekujemy.
Zainstaluj wymagane zależności:
# install dependencies yarn add mocha chai nyc sinon-chai supertest coveralls --devKażda z tych bibliotek ma do odegrania swoją rolę w naszych testach.
mocha | biegacz testowy |
chai | używany do twierdzeń |
nyc | zbierz raport pokrycia testowego |
sinon-chai | rozszerza twierdzenia Chai |
supertest | używane do wykonywania wywołań HTTP do naszych punktów końcowych API |
coveralls | do przesyłania pokrycia testowego do coveralls.io |
Utwórz nowy folder test/ w katalogu głównym projektu. Utwórz dwa pliki w tym folderze:
- test/setup.js
- test/indeks.test.js
Mocha automatycznie odnajdzie test/ folder.
Otwórz test/setup.js i wklej poniższy kod. To tylko plik pomocniczy, który pomaga nam organizować wszystkie importy, których potrzebujemy w naszych plikach testowych.
import supertest from 'supertest'; import chai from 'chai'; import sinonChai from 'sinon-chai'; import app from '../src/app'; chai.use(sinonChai); export const { expect } = chai; export const server = supertest.agent(app); export const BASE_URL = '/v1';To jest jak plik ustawień, ale do naszych testów. W ten sposób nie musimy inicjować wszystkiego w każdym z naszych plików testowych. Dlatego importujemy niezbędne pakiety i eksportujemy to, co zainicjowaliśmy — które następnie możemy zaimportować w plikach, które ich potrzebują.
Otwórz index.test.js i wklej następujący kod testowy.
import { expect, server, BASE_URL } from './setup'; describe('Index page test', () => { it('gets base url', done => { server .get(`${BASE_URL}/`) .expect(200) .end((err, res) => { expect(res.status).to.equal(200); expect(res.body.message).to.equal( 'Environment variable is coming across.' ); done(); }); }); }); Tutaj wykonujemy żądanie pobrania bazowego punktu końcowego, którym jest / i potwierdzamy, że res. obiekt body ma klucz message z wartością Environment variable is coming across.
Jeśli nie jesteś zaznajomiony z describe , it zachęcam do szybkiego rzucenia okiem na dokument Mocha „Pierwsze kroki”.
Dodaj polecenie test do sekcji scripts pliku package.json .
"test": "nyc --reporter=html --reporter=text --reporter=lcov mocha -r @babel/register" Ten skrypt wykonuje nasz test z nyc i generuje trzy rodzaje raportu pokrycia: raport HTML, wyprowadzany do folderu coverage/ ; raport tekstowy wyprowadzany do terminala i raport lcov wyprowadzany do folderu .nyc_output/ .
Teraz uruchom yarn test . Powinieneś zobaczyć raport tekstowy w swoim terminalu, taki jak ten na poniższym zdjęciu.
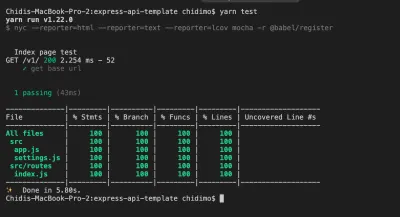
Zwróć uwagę, że generowane są dwa dodatkowe foldery:
-
.nyc_output/ -
coverage/
Zajrzyj do .gitignore , a zobaczysz, że już ignorujemy oba. Zachęcam do otwarcia w przeglądarce internetowej coverage/index.html i obejrzenia raportu z testu dla każdego pliku.
To dobry moment, aby zatwierdzić zmiany.
- Odpowiednia gałąź w moim repozytorium to 04-pierwszy test.
Ciągła integracja (CD) i plakietki: Travis, kombinezony, Code Climate, AppVeyor
Nadszedł czas na skonfigurowanie narzędzi ciągłej integracji i wdrażania (CI/CD). Skonfigurujemy popularne usługi, takie jak travis-ci , coveralls , AppVeyor i codeclimate oraz dodamy identyfikatory do naszego pliku README.
Zacznijmy.
Travis CI
Travis CI to narzędzie, które automatycznie uruchamia nasze testy za każdym razem, gdy wysyłamy commit do GitHub (i ostatnio Bitbucket) oraz za każdym razem, gdy tworzymy pull request. Jest to przydatne głównie podczas wykonywania żądań ściągnięcia, pokazując nam, czy nasz nowy kod zepsuł którykolwiek z naszych testów.
- Odwiedź travis-ci.com lub travis-ci.org i utwórz konto, jeśli go nie masz. Musisz zarejestrować się na swoim koncie GitHub.
- Najedź kursorem na strzałkę rozwijaną obok swojego zdjęcia profilowego i kliknij
settings. - W zakładce
RepositorieskliknijManage repositories on Github, aby zostać przekierowanym do Github. - Na stronie GitHub przewiń w dół do opcji Dostęp do
Repository accessi kliknij pole wyboru obok opcjiOnly select repositories. - Kliknij menu rozwijane
Select repositoriesi znajdź repozytoriumexpress-api-template. Kliknij go, aby dodać go do listy repozytoriów, które chcesz dodać dotravis-ci. - Kliknij
Approve and installi poczekaj na przekierowanie z powrotem dotravis-ci. - U góry strony repozytorium, w pobliżu nazwy repozytorium, kliknij ikonę
build unknown. Z modalnego obrazu stanu wybierz przecenę z listy rozwijanej formatu. - Skopiuj otrzymany kod i wklej go do pliku README.md .
- Na stronie projektu kliknij
More options>Settings. W sekcjiEnvironment Variablesdodaj zmienną envTEST_ENV_VARIABLE. Wprowadzając jego wartość, upewnij się, że jest ona umieszczona w podwójnych cudzysłowach, takich jak"Environment variable is coming across." - Utwórz plik .travis.yml w katalogu głównym projektu i wklej poniższy kod (ustawimy wartość
CC_TEST_REPORTER_IDw sekcji Code Climate).
language: node_js env: global: - CC_TEST_REPORTER_ID=get-this-from-code-climate-repo-page matrix: include: - node_js: '12' cache: directories: [node_modules] install: yarn after_success: yarn coverage before_script: - curl -L https://codeclimate.com/downloads/test-reporter/test-reporter-latest-linux-amd64 > ./cc-test-reporter - chmod +x ./cc-test-reporter - ./cc-test-reporter before-build script: - yarn test after_script: - ./cc-test-reporter after-build --exit-code $TRAVIS_TEST_RESUL Najpierw mówimy Travisowi, aby uruchomił nasz test z Node.js, a następnie ustawiamy globalną zmienną środowiskową CC_TEST_REPORTER_ID (dojdziemy do tego w sekcji Code Climate). W sekcji o matrix mówimy Travisowi, aby uruchomił nasze testy z Node.js v12. Chcemy również buforować katalog node_modules/ , aby nie trzeba było go generować za każdym razem.
Instalujemy nasze zależności za pomocą polecenia yarn , które jest skrótem od yarn install . Polecenia before_script i after_script są używane do przesyłania wyników pokrycia do codeclimate . Wkrótce skonfigurujemy codeclimate . Po pomyślnym yarn test , chcemy również uruchomić yarn coverage które prześle nasz raport dotyczący pokrycia do coveralls.io.
Kombinezony
Coveralls przesyła dane pokrycia testowego w celu łatwej wizualizacji. Możemy wyświetlić pokrycie testowe na naszym komputerze lokalnym z folderu pokrycia, ale kombinezony udostępniają go poza naszym komputerem lokalnym.
- Odwiedź coveralls.io i zaloguj się lub zarejestruj za pomocą swojego konta Github.
- Najedź kursorem na lewą stronę ekranu, aby wyświetlić menu nawigacyjne. Kliknij
ADD REPOS. - Wyszukaj repozytorium
express-api-templatei włącz zasięg za pomocą przycisku przełączania po lewej stronie. Jeśli nie możesz go znaleźć, kliknijSYNC REPOSw prawym górnym rogu i spróbuj ponownie. Pamiętaj, że Twoje repozytorium musi być publiczne, chyba że masz konto PRO. - Kliknij szczegóły, aby przejść do strony szczegółów repozytorium.
- Utwórz plik .coveralls.yml w katalogu głównym projektu i wprowadź poniższy kod. Aby uzyskać
repo_token, kliknij szczegóły repo. Znajdziesz go łatwo na tej stronie. Możesz po prostu wyszukać w przeglądarcerepo_token.
repo_token: get-this-from-repo-settings-on-coveralls.io Ten token mapuje Twoje dane zasięgu do repozytorium w kombinezonach. Teraz dodaj polecenie coverage do sekcji scripts w pliku package.json :
"coverage": "nyc report --reporter=text-lcov | coveralls" To polecenie przesyła raport pokrycia w folderze .nyc_output do coveralls.io. Włącz połączenie internetowe i uruchom:
yarn coveragePowinno to załadować raport o istniejącym zasięgu do kombinezonu. Odśwież stronę repozytorium kombinezonów, aby zobaczyć pełny raport.
Na stronie szczegółów przewiń w dół, aby znaleźć sekcję BADGE YOUR REPO . Kliknij menu rozwijane EMBED i skopiuj kod przeceny i wklej go do pliku README .
Kod Klimat
Code Climate to narzędzie, które pomaga nam mierzyć jakość kodu. Pokazuje nam metryki konserwacji, porównując nasz kod z pewnymi zdefiniowanymi wzorcami. Wykrywa takie rzeczy, jak niepotrzebne powtarzanie i głęboko zagnieżdżone pętle. Zbiera również dane dotyczące pokrycia testowego, podobnie jak coveralls.io.
- Odwiedź codeclimate.com i kliknij „Zarejestruj się w GitHub”. Zaloguj się, jeśli masz już konto.
- W panelu kliknij
Add a repository. - Znajdź repozytorium
express-api-templatez listy i kliknijAdd Reporepozytorium . - Poczekaj na zakończenie kompilacji i przekieruj do pulpitu nawigacyjnego repozytorium.
- W
Codebase Summarykliknij opcjęTest Coverage. W menuTest coverageskopiuj identyfikatorTEST REPORTER IDi wklej go do pliku .travis.yml jako wartośćCC_TEST_REPORTER_ID. - Nadal na tej samej stronie, w lewym panelu nawigacyjnym, w sekcji
EXTRAS, kliknij Odznaki. Skopiuj plakietki dotyczącemaintainabilityitest coveragew formacie przeceny i wklej je do pliku README.md .
Należy zauważyć, że istnieją dwa sposoby konfigurowania kontroli łatwości konserwacji. Istnieją ustawienia domyślne, które są stosowane do każdego repozytorium, ale jeśli chcesz, możesz udostępnić plik .codeclimate.yml w katalogu głównym projektu. Będę używał ustawień domyślnych, które można znaleźć w zakładce Maintainability na stronie ustawień repozytorium. Zachęcam do rzucenia okiem. Jeśli nadal chcesz skonfigurować własne ustawienia, ten przewodnik zawiera wszystkie potrzebne informacje.

AppVeyor
AppVeyor i Travis CI są zautomatyzowanymi programami do uruchamiania testów. Główną różnicą jest to, że travis-ci uruchamia testy w środowisku Linux, podczas gdy AppVeyor uruchamia testy w środowisku Windows. Ta sekcja jest dołączona, aby pokazać, jak rozpocząć pracę z AppVeyor.
- Odwiedź AppVeyor i zaloguj się lub zarejestruj.
- Na następnej stronie kliknij
NEW PROJECT. - Na liście repozytoriów znajdź repozytorium
express-api-template. Najedź na nią i kliknijADD. - Kliknij kartę
Settings. KliknijEnvironmentw lewym panelu nawigacyjnym. DodajTEST_ENV_VARIABLEi jego wartość. Kliknij „Zapisz” u dołu strony. - Utwórz plik appveyor.yml w katalogu głównym projektu i wklej poniższy kod.
environment: matrix: - nodejs_version: "12" install: - yarn test_script: - yarn test build: off Ten kod instruuje AppVeyor, aby uruchamiał nasze testy przy użyciu Node.js v12. Następnie instalujemy nasze zależności projektu za pomocą polecenia yarn . test_script określa polecenie do uruchomienia naszego testu. Ostatnia linia mówi AppVeyor, aby nie tworzył folderu kompilacji.
Kliknij kartę Settings . W nawigacji po lewej stronie kliknij plakietki. Skopiuj kod przeceny i wklej go do pliku README.md .
Zatwierdź swój kod i wypchnij do GitHub. Jeśli zrobiłeś wszystko zgodnie z instrukcjami, wszystkie testy powinny przejść pomyślnie i powinieneś zobaczyć swoje nowe, błyszczące odznaki, jak pokazano poniżej. Sprawdź ponownie, czy ustawiłeś zmienne środowiskowe w Travis i AppVeyor.
Teraz jest dobry moment na wprowadzenie zmian.
- Odpowiednia gałąź w moim repozytorium to 05-ci.
Dodawanie kontrolera
Obecnie obsługujemy żądanie GET do głównego adresu URL, /v1 , wewnątrz src/routes/index.js . Działa to zgodnie z oczekiwaniami i nie ma w tym nic złego. Jednak wraz z rozwojem aplikacji chcesz zachować porządek. Chcesz, aby obawy zostały oddzielone — chcesz wyraźnego oddzielenia kodu obsługującego żądanie i kodu generującego odpowiedź, która zostanie wysłana z powrotem do klienta. Aby to osiągnąć, piszemy controllers . Kontrolery to po prostu funkcje, które obsługują żądania przychodzące przez określony adres URL.
Aby rozpocząć, utwórz folder controllers/ w folderze src/ . Wewnątrz controllers tworzą dwa pliki: index.js i home.js . Wyeksportowalibyśmy nasze funkcje z poziomu index.js . Możesz nazwać home.js , co chcesz, ale zazwyczaj chcesz nazwać kontrolery po tym, co kontrolują. Na przykład możesz mieć plik usersController.js do przechowywania wszystkich funkcji związanych z użytkownikami w Twojej aplikacji.
Otwórz src/controllers/home.js i wpisz poniższy kod:
import { testEnvironmentVariable } from '../settings'; export const indexPage = (req, res) => res.status(200).json({ message: testEnvironmentVariable }); Zauważysz, że przenieśliśmy tylko funkcję, która obsługuje żądanie dla trasy / .
Otwórz src/controllers/index.js i wprowadź poniższy kod.
// export everything from home.js export * from './home'; Eksportujemy wszystko z pliku home.js. To pozwala nam skrócić nasze instrukcje importu, aby import { indexPage } from '../controllers';
Otwórz src/routes/index.js i zamień tam kod na poniższy:
import express from 'express'; import { indexPage } from '../controllers'; const indexRouter = express.Router(); indexRouter.get('/', indexPage); export default indexRouter; Jedyną zmianą jest to, że udostępniliśmy funkcję do obsługi żądania do trasy / .
Właśnie pomyślnie napisałeś swój pierwszy kontroler. Od tego momentu wystarczy dodać więcej plików i funkcji w razie potrzeby.
Śmiało i baw się z aplikacją, dodając jeszcze kilka tras i kontrolerów. Możesz dodać trasę i kontroler dla strony z informacjami. Pamiętaj jednak, aby zaktualizować swój test.
yarn test aby potwierdzić, że niczego nie złamaliśmy. Czy twój test zdał? To super.
To dobry moment, aby zatwierdzić nasze zmiany.
- Odpowiednia gałąź w moim repozytorium to 06-kontrolery.
Podłączanie bazy danych PostgreSQL i pisanie modelu
Nasz kontroler obecnie zwraca zakodowane wiadomości tekstowe. W rzeczywistej aplikacji często musimy przechowywać i pobierać informacje z bazy danych. W tej sekcji połączymy naszą aplikację z bazą danych PostgreSQL.
Wdrożymy przechowywanie i wyszukiwanie prostych wiadomości tekstowych za pomocą bazy danych. Mamy dwie opcje ustawienia bazy danych: możemy udostępnić ją z serwera w chmurze lub możemy skonfigurować własną lokalnie.
Polecam aprowizację bazy danych z serwera w chmurze. ElephantSQL has a free plan that gives 20MB of free storage which is sufficient for this tutorial. Visit the site and click on Get a managed database today . Create an account (if you don't have one) and follow the instructions to create a free plan. Take note of the URL on the database details page. We'll be needing it soon.
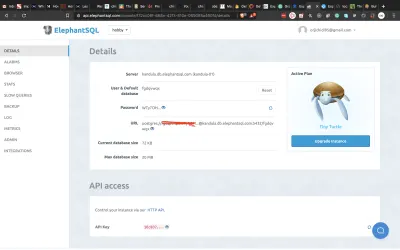
If you would rather set up a database locally, you should visit the PostgreSQL and PgAdmin sites for further instructions.
Once we have a database set up, we need to find a way to allow our Express app to communicate with our database. Node.js by default doesn't support reading and writing to PostgreSQL database, so we'll be using an excellent library, appropriately named, node-postgres.
node-postgres executes SQL queries in node and returns the result as an object, from which we can grab items from the rows key.
Let's connect node-postgres to our application.
# install node-postgres yarn add pgOpen settings.js and add the line below:
export const connectionString = process.env.CONNECTION_STRING; Open your .env file and add the CONNECTION_STRING variable. This is the connection string we'll be using to establish a connection to our database. The general form of the connection string is shown below.
CONNECTION_STRING="postgresql://dbuser:dbpassword@localhost:5432/dbname"If you're using elephantSQL you should copy the URL from the database details page.
Inside your /src folder, create a new folder called models/ . Inside this folder, create two files:
- pool.js
- model.js
Open pools.js and paste the following code:
import { Pool } from 'pg'; import dotenv from 'dotenv'; import { connectionString } from '../settings'; dotenv.config(); export const pool = new Pool({ connectionString }); First, we import the Pool and dotenv from the pg and dotenv packages, and then import the settings we created for our postgres database before initializing dotenv . We establish a connection to our database with the Pool object. In node-postgres , every query is executed by a client. A Pool is a collection of clients for communicating with the database.
To create the connection, the pool constructor takes a config object. You can read more about all the possible configurations here. It also accepts a single connection string, which I will use here.
Open model.js and paste the following code:
import { pool } from './pool'; class Model { constructor(table) { this.pool = pool; this.table = table; this.pool.on('error', (err, client) => `Error, ${err}, on idle client${client}`); } async select(columns, clause) { let query = `SELECT ${columns} FROM ${this.table}`; if (clause) query += clause; return this.pool.query(query); } } export default Model;We create a model class whose constructor accepts the database table we wish to operate on. We'll be using a single pool for all our models.
We then create a select method which we will use to retrieve items from our database. This method accepts the columns we want to retrieve and a clause, such as a WHERE clause. It returns the result of the query, which is a Promise . Remember we said earlier that every query is executed by a client, but here we execute the query with pool. This is because, when we use pool.query , node-postgres executes the query using the first available idle client.
The query you write is entirely up to you, provided it is a valid SQL statement that can be executed by a Postgres engine.
The next step is to actually create an API endpoint to utilize our newly connected database. Before we do that, I'd like us to create some utility functions. The goal is for us to have a way to perform common database operations from the command line.
Create a folder, utils/ inside the src/ folder. Create three files inside this folder:
- queries.js
- queryFunctions.js
- runQuery.js
We're going to create functions to create a table in our database, insert seed data in the table, and to delete the table.
Otwórz query.js i wklej następujący kod:
export const createMessageTable = ` DROP TABLE IF EXISTS messages; CREATE TABLE IF NOT EXISTS messages ( id SERIAL PRIMARY KEY, name VARCHAR DEFAULT '', message VARCHAR NOT NULL ) `; export const insertMessages = ` INSERT INTO messages(name, message) VALUES ('chidimo', 'first message'), ('orji', 'second message') `; export const dropMessagesTable = 'DROP TABLE messages'; W tym pliku definiujemy trzy ciągi zapytań SQL. Pierwsze zapytanie usuwa i ponownie tworzy tabelę messages . Drugie zapytanie wstawia dwa wiersze do tabeli messages . Możesz dodać więcej elementów tutaj. Ostatnie zapytanie usuwa/usuwa tabelę messages .
Otwórz queryFunctions.js i wklej następujący kod:
import { pool } from '../models/pool'; import { insertMessages, dropMessagesTable, createMessageTable, } from './queries'; export const executeQueryArray = async arr => new Promise(resolve => { const stop = arr.length; arr.forEach(async (q, index) => { await pool.query(q); if (index + 1 === stop) resolve(); }); }); export const dropTables = () => executeQueryArray([ dropMessagesTable ]); export const createTables = () => executeQueryArray([ createMessageTable ]); export const insertIntoTables = () => executeQueryArray([ insertMessages ]); Tutaj tworzymy funkcje do wykonywania zapytań, które zdefiniowaliśmy wcześniej. Zauważ, że funkcja executeQueryArray wykonuje tablicę zapytań i czeka na zakończenie każdego z nich wewnątrz pętli. (Nie rób tego w kodzie produkcyjnym). Następnie rozwiązujemy obietnicę dopiero po wykonaniu ostatniego zapytania na liście. Powodem używania tablicy jest to, że liczba takich zapytań będzie rosła wraz ze wzrostem liczby tabel w naszej bazie danych.
Otwórz runQuery.js i wklej następujący kod:
import { createTables, insertIntoTables } from './queryFunctions'; (async () => { await createTables(); await insertIntoTables(); })(); W tym miejscu wykonujemy funkcje tworzenia tabeli i wstawiamy do niej komunikaty. Dodajmy polecenie w sekcji scripts naszego package.json , aby wykonać ten plik.
"runQuery": "babel-node ./src/utils/runQuery"Teraz uruchom:
yarn runQuery Jeśli sprawdzisz swoją bazę danych, zobaczysz, że tabela messages została utworzona i że wiadomości zostały wstawione do tabeli.
Jeśli używasz ElephantSQL, na stronie szczegółów bazy danych kliknij BROWSER w lewym menu nawigacyjnym. Wybierz tabelę messages i kliknij Execute . Powinieneś zobaczyć komunikaty z pliku query.js .
Stwórzmy kontroler i trasę do wyświetlania wiadomości z naszej bazy danych.
Utwórz nowy plik kontrolera src/controllers/messages.js i wklej następujący kod:
import Model from '../models/model'; const messagesModel = new Model('messages'); export const messagesPage = async (req, res) => { try { const data = await messagesModel.select('name, message'); res.status(200).json({ messages: data.rows }); } catch (err) { res.status(200).json({ messages: err.stack }); } }; Importujemy naszą klasę Model i tworzymy nową instancję tego modelu. To reprezentuje tabelę messages w naszej bazie danych. Następnie używamy metody select modelu do zapytania naszej bazy danych. Otrzymane dane ( name i message ) są wysyłane w odpowiedzi w formacie JSON.
Definiujemy kontroler messagesPage jako funkcję async . Ponieważ zapytania node-postgres zwracają obietnicę, await na wynik tego zapytania. Jeśli napotkamy błąd podczas zapytania, przechwytujemy go i wyświetlamy stos użytkownikowi. Powinieneś zdecydować, jak poradzić sobie z błędem.
Dodaj punkt końcowy pobierania komunikatów do src/routes/index.js i zaktualizuj wiersz importu.
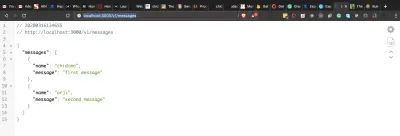
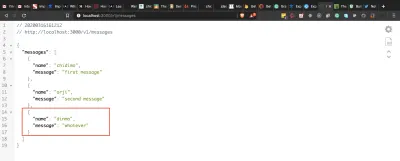
# update the import line import { indexPage, messagesPage } from '../controllers'; # add the get messages endpoint indexRouter.get('/messages', messagesPage)Odwiedź https://localhost:3000/v1/messages i powinieneś zobaczyć komunikaty wyświetlane, jak pokazano poniżej.
Teraz zaktualizujmy nasz plik testowy. Wykonując TDD, zwykle piszesz swoje testy przed implementacją kodu, który sprawia, że test przechodzi pomyślnie. Ja tutaj przyjmuję odwrotne podejście, ponieważ wciąż pracujemy nad konfiguracją bazy danych.
Utwórz nowy plik hooks.js w folderze test/ i wpisz poniższy kod:
import { dropTables, createTables, insertIntoTables, } from '../src/utils/queryFunctions'; before(async () => { await createTables(); await insertIntoTables(); }); after(async () => { await dropTables(); }); Po uruchomieniu naszego testu Mocha znajduje ten plik i wykonuje go przed uruchomieniem dowolnego pliku testowego. Wykonuje zaczep before , aby utworzyć bazę danych i wstawić do niej niektóre elementy. Pliki testowe są następnie uruchamiane. Po zakończeniu testu Mocha uruchamia hak after , w którym upuszczamy bazę danych. Dzięki temu za każdym razem, gdy uruchamiamy nasze testy, robimy to z czystymi i nowymi rekordami w naszej bazie danych.
Utwórz nowy plik testowy test/messages.test.js i dodaj poniższy kod:
import { expect, server, BASE_URL } from './setup'; describe('Messages', () => { it('get messages page', done => { server .get(`${BASE_URL}/messages`) .expect(200) .end((err, res) => { expect(res.status).to.equal(200); expect(res.body.messages).to.be.instanceOf(Array); res.body.messages.forEach(m => { expect(m).to.have.property('name'); expect(m).to.have.property('message'); }); done(); }); }); }); Twierdzimy, że wynikiem wywołania /messages jest tablica. Dla każdego obiektu komunikatu potwierdzamy, że ma on name i właściwość message .
Ostatnim krokiem w tej sekcji jest aktualizacja plików CI.
Dodaj następujące sekcje do pliku .travis.yml :
services: - postgresql addons: postgresql: "10" apt: packages: - postgresql-10 - postgresql-client-10 before_install: - sudo cp /etc/postgresql/{9.6,10}/main/pg_hba.conf - sudo /etc/init.d/postgresql restartTo instruuje Travisa, aby rozkręcił bazę danych PostgreSQL 10 przed uruchomieniem naszych testów.
Dodaj polecenie, aby utworzyć bazę danych jako pierwszy wpis w sekcji before_script :
# add this as the first line in the before_script section - psql -c 'create database testdb;' -U postgres Utwórz zmienną środowiskową CONNECTION_STRING w Travis i użyj poniższej wartości:
CONNECTION_STRING="postgresql://postgres:postgres@localhost:5432/testdb"Dodaj następujące sekcje do pliku .appveyor.yml :
before_test: - SET PGUSER=postgres - SET PGPASSWORD=Password12! - PATH=C:\Program Files\PostgreSQL\10\bin\;%PATH% - createdb testdb services: - postgresql101Dodaj zmienną środowiskową parametrów połączenia do appveyor. Użyj poniższej linii:
CONNECTION_STRING=postgresql://postgres:Password12!@localhost:5432/testdbTeraz zatwierdź swoje zmiany i wypchnij na GitHub. Twoje testy powinny przejść zarówno na Travis CI, jak i na AppVeyor.
- Odpowiednia gałąź w moim repozytorium to 07-connect-postgres.
Uwaga : mam nadzieję, że wszystko będzie dobrze u Ciebie, ale na wypadek, gdybyś miał z jakiegoś powodu problem, zawsze możesz sprawdzić mój kod w repozytorium!
Zobaczmy teraz, jak możemy dodać wiadomość do naszej bazy danych. Na tym etapie potrzebujemy sposobu na wysyłanie żądań POST na nasz adres URL. Będę używał Postmana do wysyłania żądań POST .
Pójdźmy drogą TDD i zaktualizujmy nasz test, aby odzwierciedlić to, czego oczekujemy.
Otwórz test/message.test.js i dodaj poniższy przypadek testowy:
it('posts messages', done => { const data = { name: 'some name', message: 'new message' }; server .post(`${BASE_URL}/messages`) .send(data) .expect(200) .end((err, res) => { expect(res.status).to.equal(200); expect(res.body.messages).to.be.instanceOf(Array); res.body.messages.forEach(m => { expect(m).to.have.property('id'); expect(m).to.have.property('name', data.name); expect(m).to.have.property('message', data.message); }); done(); }); }); Ten test wysyła żądanie POST do punktu końcowego /v1/messages i oczekujemy, że zostanie zwrócona tablica. Sprawdzamy również właściwości id , name i message w tablicy.
Uruchom testy, aby zobaczyć, że ta sprawa się nie powiedzie. Naprawmy to teraz.
Do wysyłania żądań pocztowych używamy metody pocztowej serwera. Wysyłamy również imię i wiadomość, którą chcemy wstawić. Oczekujemy, że odpowiedź będzie tablicą z id właściwości i innymi informacjami składającymi się na zapytanie. id jest dowodem, że rekord został wstawiony do bazy danych.
Otwórz src/models/model.js i dodaj metodę insert :
async insertWithReturn(columns, values) { const query = ` INSERT INTO ${this.table}(${columns}) VALUES (${values}) RETURNING id, ${columns} `; return this.pool.query(query); } Jest to metoda, która pozwala nam wstawiać wiadomości do bazy danych. Po wstawieniu elementu zwraca id , name i message .
Otwórz src/controllers/messages.js i dodaj poniższy kontroler:
export const addMessage = async (req, res) => { const { name, message } = req.body; const columns = 'name, message'; const values = `'${name}', '${message}'`; try { const data = await messagesModel.insertWithReturn(columns, values); res.status(200).json({ messages: data.rows }); } catch (err) { res.status(200).json({ messages: err.stack }); } }; Destrukturyzujemy treść żądania, aby uzyskać nazwę i wiadomość. Następnie używamy wartości do utworzenia ciągu zapytania SQL, który następnie wykonujemy za pomocą metody insertWithReturn naszego modelu.
Dodaj poniższy punkt końcowy POST do /src/routes/index.js i zaktualizuj wiersz importu.
import { indexPage, messagesPage, addMessage } from '../controllers'; indexRouter.post('/messages', addMessage);Uruchom testy, aby sprawdzić, czy zdają.
Otwórz Postman i wyślij żądanie POST do punktu końcowego messages . Jeśli właśnie uruchomiłeś test, pamiętaj, aby uruchomić yarn query , aby odtworzyć tabelę messages .
yarn query 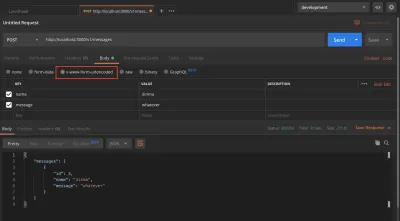
Zatwierdź zmiany i wypchnij na GitHub. Twoje testy powinny przejść zarówno na Travisa, jak i na AppVeyor. Twoje pokrycie testowe spadnie o kilka punktów, ale to jest w porządku.
- Odpowiednia gałąź w moim repozytorium to 08-post-to-db.
Oprogramowanie pośredniczące
Nasza dyskusja na temat Express nie będzie kompletna bez rozmowy o oprogramowaniu pośredniczącym. Dokumentacja Express opisuje oprogramowanie pośredniczące jako:
„[...] funkcje, które mają dostęp do obiektu żądania (req), obiektu odpowiedzi (res) i następnej funkcji oprogramowania pośredniego w cyklu żądanie-odpowiedź aplikacji. Następna funkcja oprogramowania pośredniego jest zwykle oznaczana przez zmienną o nazwienext”.
Oprogramowanie pośredniczące może wykonywać dowolną liczbę funkcji, takich jak uwierzytelnianie, modyfikowanie treści żądania i tak dalej. Zobacz dokumentację Express dotyczącą korzystania z oprogramowania pośredniczącego.
Napiszemy proste oprogramowanie pośredniczące, które modyfikuje treść żądania. Nasze oprogramowanie pośredniczące doda słowo SAYS: do przychodzącej wiadomości, zanim zostanie ona zapisana w bazie danych.
Zanim zaczniemy, zmodyfikujmy nasz test, aby odzwierciedlić to, co chcemy osiągnąć.
Otwórz test/messages.test.js i zmodyfikuj ostatnią linię oczekiwania w przypadku testowym posts message :
it('posts messages', done => { ... expect(m).to.have.property('message', `SAYS: ${data.message}`); # update this line ... }); Zapewniamy, że ciąg znaków SAYS: został dołączony do wiadomości. Uruchom testy, aby upewnić się, że ten przypadek testowy się nie powiedzie.
Teraz napiszmy kod, który sprawi, że test przejdzie.
Utwórz nowy folder middleware/ w folderze src/ . Utwórz dwa pliki w tym folderze:
- middleware.js
- index.js
Wpisz poniższy kod w middleware.js :
export const modifyMessage = (req, res, next) => { req.body.message = `SAYS: ${req.body.message}`; next(); }; Tutaj dołączamy ciąg SAYS: do wiadomości w treści żądania. Po wykonaniu tej czynności musimy wywołać funkcję next() , aby przekazać wykonanie następnej funkcji w łańcuchu żądanie-odpowiedź. Każde oprogramowanie pośredniczące musi wywołać next funkcję, aby przekazać wykonanie do następnego oprogramowania pośredniego w cyklu żądanie-odpowiedź.
Wpisz poniższy kod w index.js :
# export everything from the middleware file export * from './middleware'; Spowoduje to wyeksportowanie oprogramowania pośredniczącego, które mamy w pliku /middleware.js . Na razie mamy tylko oprogramowanie pośredniczące modifyMessage .
Otwórz src/routes/index.js i dodaj oprogramowanie pośredniczące do łańcucha żądanie-odpowiedź na wiadomość.
import { modifyMessage } from '../middleware'; indexRouter.post('/messages', modifyMessage, addMessage); Widzimy, że funkcja modifyMessage występuje przed funkcją addMessage . Wywołujemy funkcję addMessage , wywołując next w oprogramowaniu pośredniczącym modifyMessage . W ramach eksperymentu skomentuj wiersz next() w środkowej części modifyMessage i obserwuj, jak żądanie się zawiesza.
Otwórz Postman i utwórz nową wiadomość. Powinieneś zobaczyć dołączony ciąg.
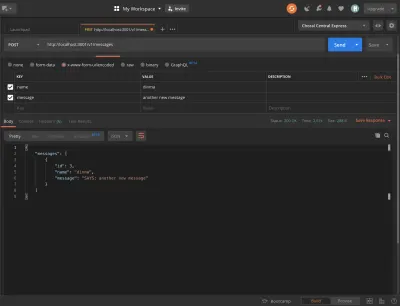
To dobry moment, aby zatwierdzić nasze zmiany.
- Odpowiednia gałąź w moim repozytorium to 09-middleware.
Obsługa błędów i asynchroniczne oprogramowanie pośredniczące
Błędy są nieuniknione w każdej aplikacji. Zadaniem dewelopera jest to, jak radzić sobie z błędami tak wdzięcznie, jak to tylko możliwe.
W ekspresowym:
Obsługa błędów odnosi się do tego, jak Express wychwytuje i przetwarza błędy, które występują zarówno synchronicznie, jak i asynchronicznie.
Gdybyśmy pisali tylko funkcje synchroniczne, moglibyśmy nie martwić się tak bardzo o obsługę błędów, ponieważ Express już radzi sobie z nimi znakomicie. Zgodnie z dokumentacją:
„Błędy występujące w kodzie synchronicznym wewnątrz programów obsługi tras i oprogramowania pośredniczącego nie wymagają dodatkowej pracy”.
Ale kiedy zaczniemy pisać programy obsługi routerów asynchronicznych i oprogramowanie pośredniczące, musimy zrobić trochę obsługi błędów.
Nasze oprogramowanie pośredniczące modifyMessage jest funkcją synchroniczną. Jeśli w tej funkcji wystąpi błąd, Express poradzi sobie z tym bez problemu. Zobaczmy, jak radzimy sobie z błędami w asynchronicznym oprogramowaniu pośredniczącym.
Załóżmy, że przed utworzeniem wiadomości chcemy uzyskać zdjęcie z interfejsu API Lorem Picsum, korzystając z tego adresu URL https://picsum.photos/id/0/info . Jest to operacja asynchroniczna, która może zakończyć się sukcesem lub niepowodzeniem, a to stanowi przypadek, z którym musimy sobie poradzić.
Zacznij od zainstalowania Axios.
# install axios yarn add axiosOtwórz src/middleware/middleware.js i dodaj poniższą funkcję:
export const performAsyncAction = async (req, res, next) => { try { await axios.get('https://picsum.photos/id/0/info'); next(); } catch (err) { next(err); } }; W tej funkcji async await na wywołanie API (w rzeczywistości nie potrzebujemy zwróconych danych), a następnie wywołujemy next funkcję w łańcuchu żądań. Jeśli żądanie się nie powiedzie, przechwytujemy błąd i przekazujemy go do next . Gdy Express zobaczy ten błąd, pomija wszystkie inne oprogramowanie pośredniczące w łańcuchu. Jeśli nie wywołaliśmy next(err) , żądanie zawiesi się. Jeśli wywołamy tylko next() bez err , żądanie będzie działać tak, jakby nic się nie stało, a błąd nie zostanie wyłapany.
Zaimportuj tę funkcję i dodaj ją do łańcucha oprogramowania pośredniego trasy wiadomości pocztowych:
import { modifyMessage, performAsyncAction } from '../middleware'; indexRouter.post('/messages', modifyMessage, performAsyncAction, addMessage); Otwórz src/app.js i dodaj poniższy kod tuż przed linią export default app .
app.use((err, req, res, next) => { res.status(400).json({ error: err.stack }); }); export default app;To jest nasz program obsługi błędów. Zgodnie z dokumentem obsługi błędów Express:
„[...] funkcje obsługi błędów mają cztery argumenty zamiast trzech: (err, req, res, next) .” Zauważ, że ta procedura obsługi błędów musi być ostatnia, po każdym app.use() . Gdy napotkamy błąd, zwracamy ślad stosu z kodem stanu 400 . Z błędem możesz zrobić, co chcesz. Możesz go zarejestrować lub gdzieś wysłać.
To dobre miejsce na zatwierdzenie zmian.
- Odpowiednia gałąź w moim repozytorium to 10-async-middleware.
Wdróż w Heroku
- Aby rozpocząć, przejdź do https://www.heroku.com/ i zaloguj się lub zarejestruj.
- Pobierz i zainstaluj Heroku CLI stąd.
- Otwórz terminal w folderze projektu, aby uruchomić polecenie.
# login to heroku on command line heroku loginSpowoduje to otwarcie okna przeglądarki i poproszenie o zalogowanie się na swoje konto Heroku.
Zaloguj się, aby przyznać terminalowi dostęp do konta Heroku i utwórz nową aplikację heroku, uruchamiając:
#app name is up to you heroku create app-nameSpowoduje to utworzenie aplikacji w Heroku i zwrócenie dwóch adresów URL.
# app production url and git url https://app-name.herokuapp.com/ | https://git.heroku.com/app-name.gitSkopiuj adres URL po prawej stronie i uruchom poniższe polecenie. Zauważ, że ten krok jest opcjonalny, ponieważ może się okazać, że Heroku dodał już zdalny adres URL.
# add heroku remote url git remote add heroku https://git.heroku.com/my-shiny-new-app.gitOtwórz boczny terminal i uruchom poniższe polecenie. To pokazuje log aplikacji w czasie rzeczywistym, jak pokazano na obrazku.
# see process logs heroku logs --tail 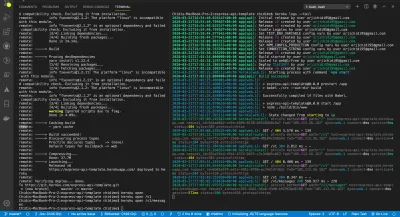
Uruchom następujące trzy polecenia, aby ustawić wymagane zmienne środowiskowe:
heroku config:set TEST_ENV_VARIABLE="Environment variable is coming across." heroku config:set CONNECTION_STRING=your-db-connection-string-here. heroku config:set NPM_CONFIG_PRODUCTION=falsePamiętaj w naszych skryptach ustawiamy:
"prestart": "babel ./src --out-dir build", "start": "node ./build/bin/www", Aby uruchomić aplikację, należy ją skompilować do ES5 przy użyciu babel w kroku prestart , ponieważ babel istnieje tylko w naszych zależnościach programistycznych. Musimy ustawić NPM_CONFIG_PRODUCTION na false , aby móc je również zainstalować.
Aby potwierdzić, że wszystko jest ustawione poprawnie, uruchom poniższe polecenie. Możesz także odwiedzić zakładkę settings na stronie aplikacji i kliknąć Reveal Config Vars konfiguracyjne .
# check configuration variables heroku config Teraz uruchom git push heroku .
Aby otworzyć aplikację, uruchom:
# open /v1 route heroku open /v1 # open /v1/messages route heroku open /v1/messagesJeśli tak jak ja używasz tej samej bazy danych PostgresSQL zarówno do celów deweloperskich, jak i produkcyjnych, może się okazać, że za każdym razem, gdy uruchamiasz testy, baza danych jest usuwana. Aby go odtworzyć, możesz uruchomić jedno z następujących poleceń:
# run script locally yarn runQuery # run script with heroku heroku run yarn runQueryCiągłe wdrażanie (CD) z Travis
Dodajmy teraz Ciągłe wdrażanie (CD), aby zakończyć przepływ CI/CD. Będziemy wdrażać z Travis po każdym pomyślnym uruchomieniu testowym.
Pierwszym krokiem jest zainstalowanie Travis CI. (Instrukcję instalacji znajdziesz tutaj.) Po pomyślnym zainstalowaniu Travis CI zaloguj się, uruchamiając poniższe polecenie. (Pamiętaj, że należy to zrobić w repozytorium projektu).
# login to travis travis login --pro # use this if you're using two factor authentication travis login --pro --github-token enter-github-token-here Jeśli Twój projekt jest hostowany na travis-ci.org, usuń flagę --pro . Aby uzyskać token GitHub, odwiedź stronę ustawień programisty swojego konta i wygeneruj go. Ma to zastosowanie tylko wtedy, gdy Twoje konto jest zabezpieczone 2FA.
Otwórz plik .travis.yml i dodaj sekcję wdrażania:
deploy: provider: heroku app: master: app-name Tutaj określamy, że chcemy wdrożyć w Heroku. Podsekcja app określa, że chcemy wdrożyć master gałąź naszego repozytorium w app-name na Heroku. Możliwe jest wdrażanie różnych gałęzi do różnych aplikacji. Więcej o dostępnych opcjach przeczytasz tutaj.
Uruchom poniższe polecenie, aby zaszyfrować klucz Heroku API i dodać go do sekcji wdrażania:
# encrypt heroku API key and add to .travis.yml travis encrypt $(heroku auth:token) --add deploy.api_key --proSpowoduje to dodanie poniższej podsekcji do sekcji wdrażania.
api_key: secure: very-long-encrypted-api-key-stringTeraz zatwierdź swoje zmiany i wypchnij na GitHub, jednocześnie monitorując swoje logi. Zobaczysz, że kompilacja zostanie uruchomiona, gdy tylko zakończy się test Travisa. W ten sposób, jeśli test zakończy się niepowodzeniem, zmiany nigdy nie zostaną wdrożone. Podobnie, jeśli kompilacja nie powiedzie się, cały przebieg testu zakończy się niepowodzeniem. To kończy przepływ CI/CD.
- Odpowiednia gałąź w moim repozytorium to 11-cd.
Wniosek
Jeśli dotarłeś tak daleko, mówię: „Kciuki w górę!” W tym samouczku pomyślnie skonfigurowaliśmy nowy projekt Express. Poszliśmy do przodu, aby skonfigurować zależności programistyczne, a także ciągłą integrację (CI). Następnie napisaliśmy funkcje asynchroniczne do obsługi żądań do naszych punktów końcowych API — uzupełnione testami. Następnie przyjrzeliśmy się krótko obsłudze błędów. Na koniec wdrożyliśmy nasz projekt w Heroku i skonfigurowaliśmy Continuous Deployment.
Masz teraz szablon dla swojego następnego projektu zaplecza. Zrobiliśmy tylko tyle, żebyś mógł zacząć, ale powinieneś uczyć się dalej. Koniecznie zapoznaj się również z dokumentacją Express.js. Jeśli wolisz używać MongoDB zamiast PostgreSQL , mam tutaj szablon, który robi dokładnie to. Możesz to sprawdzić w konfiguracji. Ma tylko kilka punktów różnicy.
Zasoby
- „Utwórz Backend Express API za pomocą MongoDB”, Orji Chidi Matthew, GitHub
- „Krótki przewodnik po połączeniu oprogramowania pośredniego”, Stephen Sugden
- „Szablon Express API”, GitHub
- „AppVeyor kontra Travis CI”, StackShare
- „Heroku CLI”, Centrum deweloperów Heroku
- „Wdrożenie Heroku”, Travis CI
- „Korzystanie z oprogramowania pośredniego”, Express.js
- „Obsługa błędów”, Express.js
- „Pierwsze kroki”, Mocha
-
nyc(GitHub) - ElephantSQL
- Listonosz
- Wyrazić
- Travis CI
- Kod Klimat
- PostgreSQL
- pgAdmin