
Eksploracyjna analiza danych w Pythonie: co musisz wiedzieć?
Opublikowany: 2021-03-12Eksploracyjna analiza danych (EDA) jest bardzo powszechną i ważną praktyką stosowaną przez wszystkich naukowców zajmujących się danymi. Jest to proces patrzenia na tabele i tabele danych pod różnymi kątami, aby je w pełni zrozumieć. Uzyskanie dobrego zrozumienia danych pomaga nam je uporządkować i podsumować, co następnie wydobywa spostrzeżenia i trendy, które w przeciwnym razie byłyby niejasne.
EDA nie ma sztywnych zasad, których należy przestrzegać, jak na przykład w „analizie danych”. Ludzie, którzy są nowicjuszami w tej dziedzinie, zawsze mają tendencję do mylenia tych dwóch terminów, które są w większości podobne, ale różnią się celem. W przeciwieństwie do EDA, analiza danych jest bardziej skłonna do wdrażania prawdopodobieństw i metod statystycznych w celu ujawnienia faktów i relacji między różnymi wariantami.
Wracając, nie ma dobrego ani złego sposobu wykonywania EDA. Różni się to w zależności od osoby, jednak istnieją pewne główne powszechnie stosowane wytyczne, które wymieniono poniżej.
- Obsługa brakujących wartości: wartości null można zobaczyć, gdy wszystkie dane mogły nie być dostępne lub zarejestrowane podczas zbierania.
- Usuwanie zduplikowanych danych: ważne jest, aby zapobiec nadmiernemu dopasowaniu lub uprzedzeniom powstałym podczas uczenia algorytmu uczenia maszynowego przy użyciu powtarzających się rekordów danych
- Postępowanie z wartościami odstającymi: wartości odstające to rekordy, które drastycznie różnią się od pozostałych danych i nie są zgodne z trendem. Może to wynikać z pewnych wyjątków lub niedokładności podczas zbierania danych
- Skalowanie i normalizowanie: Odbywa się to tylko dla liczbowych zmiennych danych. W większości przypadków zmienne znacznie różnią się zakresem i skalą, co utrudnia ich porównywanie i znajdowanie korelacji.
- Analiza jednowymiarowa i dwuwymiarowa: Analiza jednowymiarowa jest zwykle wykonywana poprzez sprawdzenie, jak jedna zmienna wpływa na zmienną docelową. Analiza dwuwymiarowa jest przeprowadzana między dowolnymi 2 zmiennymi, może być liczbowa, kategoryczna lub obie.
Przyjrzymy się, jak niektóre z nich są zaimplementowane przy użyciu bardzo znanego zestawu danych „Ryzyko niewypłacalności kredytu domowego” dostępnego na Kaggle tutaj . Dane zawierają informacje o osobie ubiegającej się o pożyczkę w momencie ubiegania się o pożyczkę. Zawiera dwa rodzaje scenariuszy:
- Klient z trudnościami w płatnościach : miał opóźnienia w płatnościach ponad X dni
na co najmniej jednej z pierwszych rat Y kredytu w naszej próbie,
- Wszystkie inne przypadki : Wszystkie inne przypadki, w których płatność jest uiszczona na czas.
Na potrzeby tego artykułu będziemy pracować tylko nad plikami danych aplikacji.
Powiązane: Pomysły i tematy projektów Pythona dla początkujących
Spis treści
Patrząc na dane
app_data = pd.read_csv( 'aplikacja_data.csv' )
app_data.info()
Po odczytaniu danych aplikacji używamy funkcji info(), aby uzyskać krótki przegląd danych, z którymi będziemy mieć do czynienia. Poniższe dane wyjściowe informują nas, że mamy około 300000 rekordów pożyczek ze 122 zmiennymi. Spośród nich jest 16 zmiennych kategorycznych, a reszta liczbowa.
<klasa 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 wpisów, od 0 do 307510
Kolumny: 122 wpisy, SK_ID_CURR do AMT_REQ_CREDIT_BUREAU_YEAR
dtypes: float64(65), int64(41), object(16)
wykorzystanie pamięci: 286,2+ MB
Dobrą praktyką jest zawsze oddzielne przetwarzanie i analizowanie danych liczbowych i kategorycznych.
categorical = app_data.select_dtypes(include = object).columns
app_data[categorical].apply(pd.Series.nunique, oś = 0)
Patrząc tylko na poniższe cechy kategorialne, widzimy, że większość z nich ma tylko kilka kategorii, co ułatwia ich analizę za pomocą prostych wykresów.
NAME_CONTRACT_TYPE 2
KOD_PŁEĆ 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
TYP ORGANIZACJI 58
FONDKAPREMONT_MODE 4
TYP DOMU_TRYB 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64
Teraz, jeśli chodzi o funkcje liczbowe, metoda description() daje nam statystyki naszych danych:
numer= dane_aplikacji.opis()
numeryczna= numer.kolumny
numer
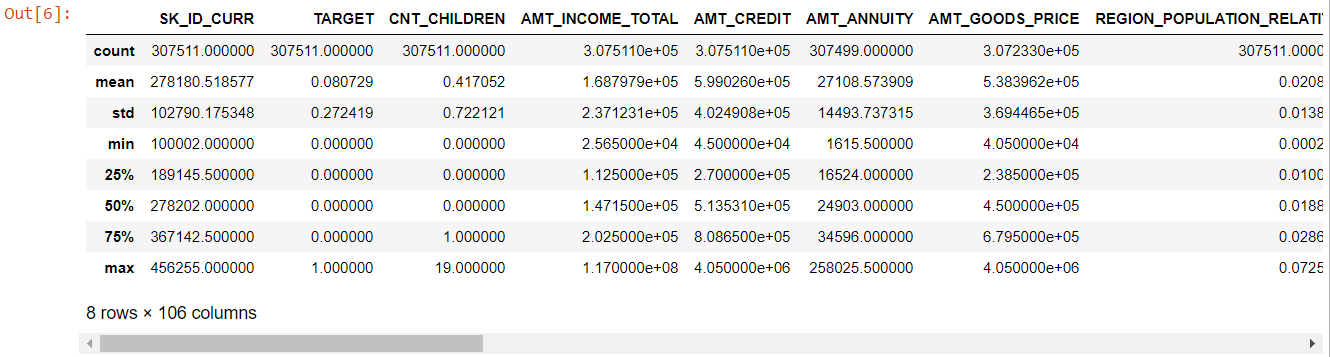
Patrząc na całą tabelę widać, że:
- liczba dni_urodzeń jest ujemna: wiek wnioskodawcy (w dniach) w stosunku do dnia złożenia wniosku
- dni_zatrudnienia ma wartości odstające (maksymalna wartość to około 100 lat) (635243)
- amt_annuity - średnia znacznie mniejsza niż wartość maksymalna
Więc teraz wiemy, które cechy będą musiały być dalej analizowane.
Brakujące dane
Możemy wykonać wykres punktowy wszystkich obiektów z brakującymi wartościami, wykreślając % brakujących danych wzdłuż osi Y.
brakujące = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))

ax = sns.pointplot('indeks', 0, dane = brak)
plt.xticks(obrót = 90, rozmiar czcionki = 7)
plt.title("Procent brakujących wartości")
plt.ylabel(„PROCENT”)
plt.pokaż()
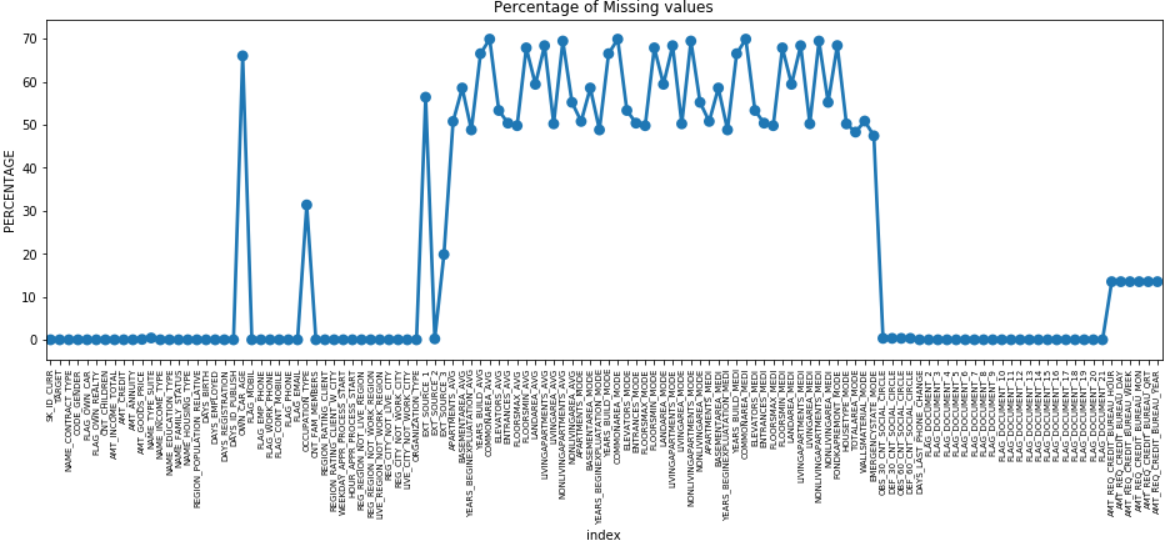
Wiele kolumn zawiera wiele brakujących danych (30-70%), niektóre mają niewiele brakujących danych (13-19%), a wiele kolumn również nie zawiera żadnych brakujących danych. Nie ma potrzeby modyfikowania zestawu danych, gdy wystarczy wykonać EDA. Jednak kontynuując wstępne przetwarzanie danych, powinniśmy wiedzieć, jak radzić sobie z brakującymi wartościami.
W przypadku obiektów z mniejszą liczbą braków danych możemy użyć regresji, aby przewidzieć brakujące wartości lub wypełnić średnią z obecnych wartości, w zależności od funkcji. W przypadku obiektów z bardzo dużą liczbą brakujących wartości lepiej jest usunąć te kolumny, ponieważ dają one bardzo mniejszy wgląd w analizę.
Brak równowagi danych
W tym zbiorze danych osoby niespłacające pożyczki są identyfikowane za pomocą zmiennej binarnej „TARGET”.
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91,927118
1 8.072882
Nazwa: TARGET, dtype: float64
Widzimy, że dane są bardzo niezrównoważone w stosunku 92:8. Większość pożyczek została spłacona terminowo (docelowo = 0). Tak więc, gdy występuje tak duża nierównowaga, lepiej jest wziąć cechy i porównać je ze zmienną docelową (analiza ukierunkowana), aby określić, które kategorie w tych cechach mają tendencję do niespłacania pożyczek bardziej niż inne.
Poniżej znajduje się tylko kilka przykładów wykresów, które można wykonać za pomocą biblioteki python Seaborn i prostych funkcji zdefiniowanych przez użytkownika.
Płeć
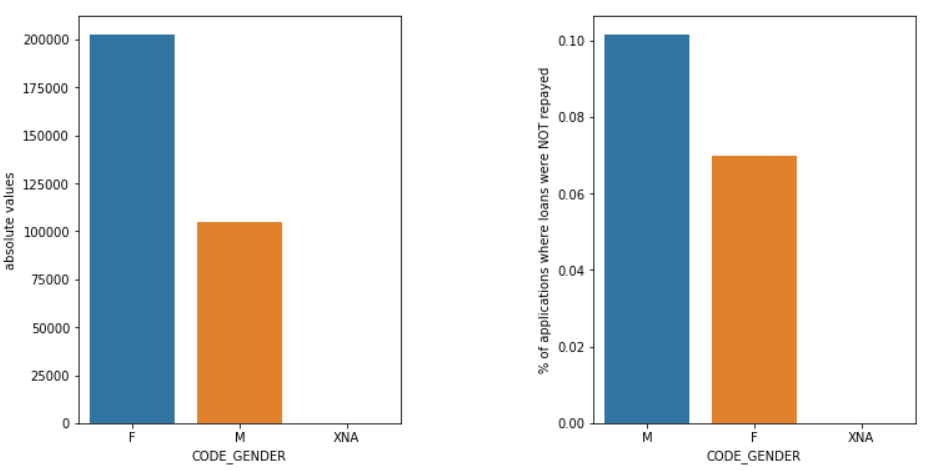
Mężczyźni (M) mają większą szansę na niewywiązanie się z płatności w porównaniu z kobietami (K), mimo że liczba kandydatek jest prawie dwa razy większa. Tak więc kobiety są bardziej niezawodne niż mężczyźni w spłacaniu pożyczek.
Rodzaj edukacji
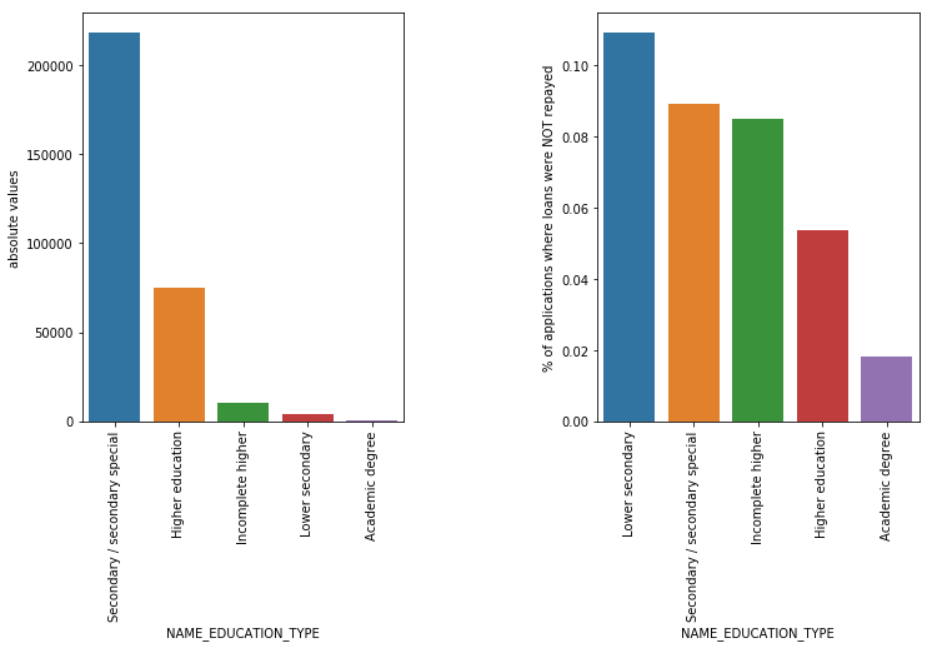
Mimo że większość pożyczek studenckich jest przeznaczona na ich wykształcenie średnie lub wyższe, to pożyczki na edukację na poziomie gimnazjum są najbardziej ryzykowne dla firmy, a następnie średnie.
Przeczytaj także: Kariera w nauce o danych
Wniosek
Taki rodzaj analizy, o której mowa powyżej, jest wykonywany w dużej mierze w analityce ryzyka w usługach bankowych i finansowych. W ten sposób można wykorzystać archiwa danych, aby zminimalizować ryzyko utraty pieniędzy podczas pożyczania klientom. Zakres EDA we wszystkich innych sektorach jest nieograniczony i powinien być szeroko stosowany.
Jeśli jesteś zainteresowany nauką o danych, sprawdź IIIT-B i upGrad Executive PG in Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami branżowymi, 1- on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Eksploracyjna analiza danych jest uważana za poziom początkowy na początku modelowania danych. Jest to dość wnikliwa technika analizy najlepszych praktyk modelowania danych. Będziesz mógł wyodrębnić wykresy wizualne, wykresy i raporty z danych, aby uzyskać ich pełne zrozumienie. Wartości odstające odnoszą się do anomalii lub niewielkich rozbieżności w Twoich danych. Może się to zdarzyć podczas zbierania danych. Istnieją 4 sposoby wykrywania wartości odstających w zbiorze danych. Metody te są następujące: W przeciwieństwie do analizy danych, EDA nie ma twardych i szybkich zasad i przepisów, których należy przestrzegać. Nie można powiedzieć, że jest to właściwa metoda lub zła metoda wykonywania EDA. Początkujący są często źle rozumiani i mylą się między EDA a analizą danych.Dlaczego potrzebna jest eksploracyjna analiza danych (EDA)?
EDA obejmuje pewne kroki w celu pełnej analizy danych, w tym wyprowadzenie wyników statystycznych, znalezienie brakujących wartości danych, obsługę błędnych wpisów danych i wreszcie wyprowadzenie różnych wykresów i wykresów.
Głównym celem tej analizy jest upewnienie się, że używany zestaw danych jest odpowiedni do rozpoczęcia stosowania algorytmów modelowania. Z tego powodu jest to pierwszy krok, który powinieneś wykonać na swoich danych przed przejściem do etapu modelowania. Czym są wartości odstające i jak sobie z nimi radzić?
1. Boxplot — Boxplot to metoda wykrywania wartości odstających, w której segregujemy dane według ich kwartyli.
2. Wykres punktowy — wykres punktowy wyświetla dane 2 zmiennych w postaci zbioru punktów zaznaczonych na płaszczyźnie kartezjańskiej. Wartość jednej zmiennej reprezentuje oś poziomą (x-ais), a wartość drugiej zmiennej reprezentuje oś pionową (oś y).
3. Z-score - Podczas obliczania Z-score szukamy punktów oddalonych od centrum i traktujemy je jako odstające.
4. Rozstęp międzykwartylowy (IQR) — Rozstęp międzykwartylowy lub IQR to różnica między górnym a dolnym kwartylem lub 75. i 25. kwartylem, często określana jako rozrzut statystyczny. Jakie są wytyczne dotyczące wykonywania EDA?
Istnieje jednak kilka wskazówek, które są powszechnie praktykowane:
1. Obsługa brakujących wartości
2. Usuwanie duplikatów danych
3. Postępowanie z wartościami odstającymi
4. Skalowanie i normalizacja
5. Analiza jednowymiarowa i dwuwymiarowa