
Co to jest eksploracyjna analiza danych w Pythonie? Ucz się od podstaw
Opublikowany: 2021-03-04Exploratory Data Analysis, w skrócie EDA, obejmuje prawie 70% projektu Data Science. EDA to proces eksploracji danych przy użyciu różnych narzędzi analitycznych, aby uzyskać z danych wnioskowane statystyki. Te eksploracje są wykonywane albo poprzez oglądanie zwykłych liczb, albo przez kreślenie wykresów i wykresów różnych typów.
Każdy wykres lub wykres przedstawia inną historię i kąt do tych samych danych. W przypadku większości części do analizy danych i czyszczenia najczęściej używanym narzędziem są Pandas. Do wizualizacji i kreślenia wykresów/wykresów wykorzystywane są biblioteki kreślenia, takie jak Matplotlib, Seaborn i Plotly.
Przeprowadzenie EDA jest niezwykle potrzebne, ponieważ powoduje, że dane się przyznają. Data Scientist, który wykonuje bardzo dobre EDA, dużo wie o danych, a zatem model, który zbudują, będzie automatycznie lepszy niż Data Scientist, który nie wykonuje dobrego EDA.
Pod koniec tego samouczka poznasz następujące rzeczy:
- Sprawdzenie podstawowego przeglądu danych
- Sprawdzanie opisowych statystyk danych
- Manipulowanie nazwami kolumn i typami danych
- Obsługa brakujących wartości i duplikatów wierszy
- Analiza dwuwymiarowa
Spis treści
Podstawowy przegląd danych
W tym samouczku użyjemy zestawu danych samochodów, który można pobrać z Kaggle. Pierwszym krokiem w przypadku prawie każdego zestawu danych jest zaimportowanie go i sprawdzenie jego podstawowego przeglądu – jego kształtu, kolumn, typów kolumn, 5 pierwszych wierszy itp. Ten krok zapewnia szybki przegląd danych, z którymi będziesz pracować. Zobaczmy, jak to zrobić w Pythonie.
| # Importowanie wymaganych bibliotek importuj pandy jako PD importuj numer jako np importuj seaborn jako sns #wizualizacja importuj matplotlib.pyplot jako plt #visualisation %matplotlib wbudowany sns.set(color_codes= True ) |
Głowica i ogon danych
| dane = pd.read_csv( “ścieżka/zbiór danych.csv” ) # Sprawdź 5 górnych wierszy ramki danych data.head() |
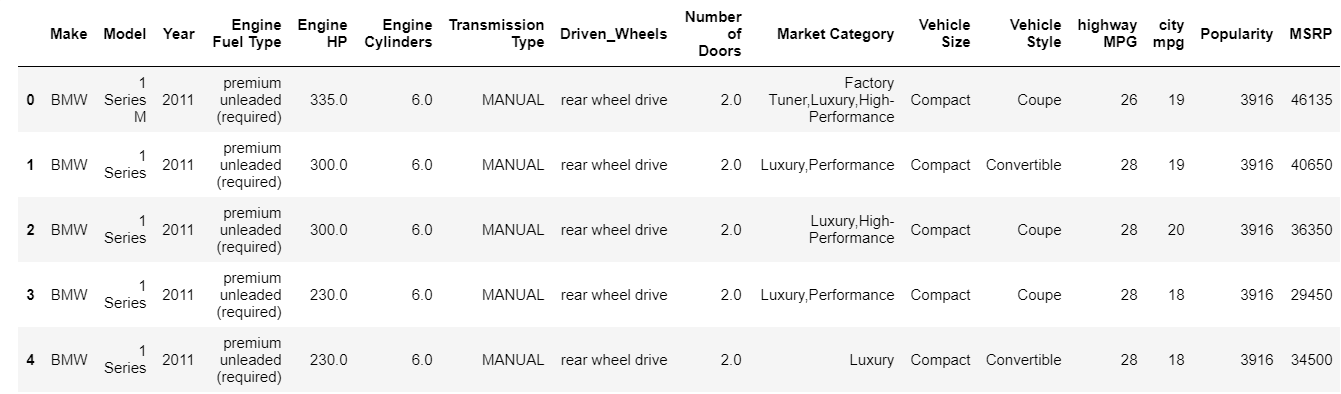
Funkcja head domyślnie drukuje 5 najwyższych indeksów ramki danych. Możesz również określić, ile najważniejszych indeksów musisz zobaczyć, pomijając tę wartość do nagłówka. Wydrukowanie głowicy natychmiast daje nam szybki wgląd w to, jakie dane posiadamy, jakie cechy są obecne i jakie wartości zawierają. Oczywiście nie opowiada to całej historii o danych, ale daje szybki wgląd w dane. W podobny sposób możesz wydrukować dolną część ramki danych za pomocą funkcji ogona.
| # Wydrukuj ostatnie 10 wierszy ramki danych dane.ogon( 10 ) |
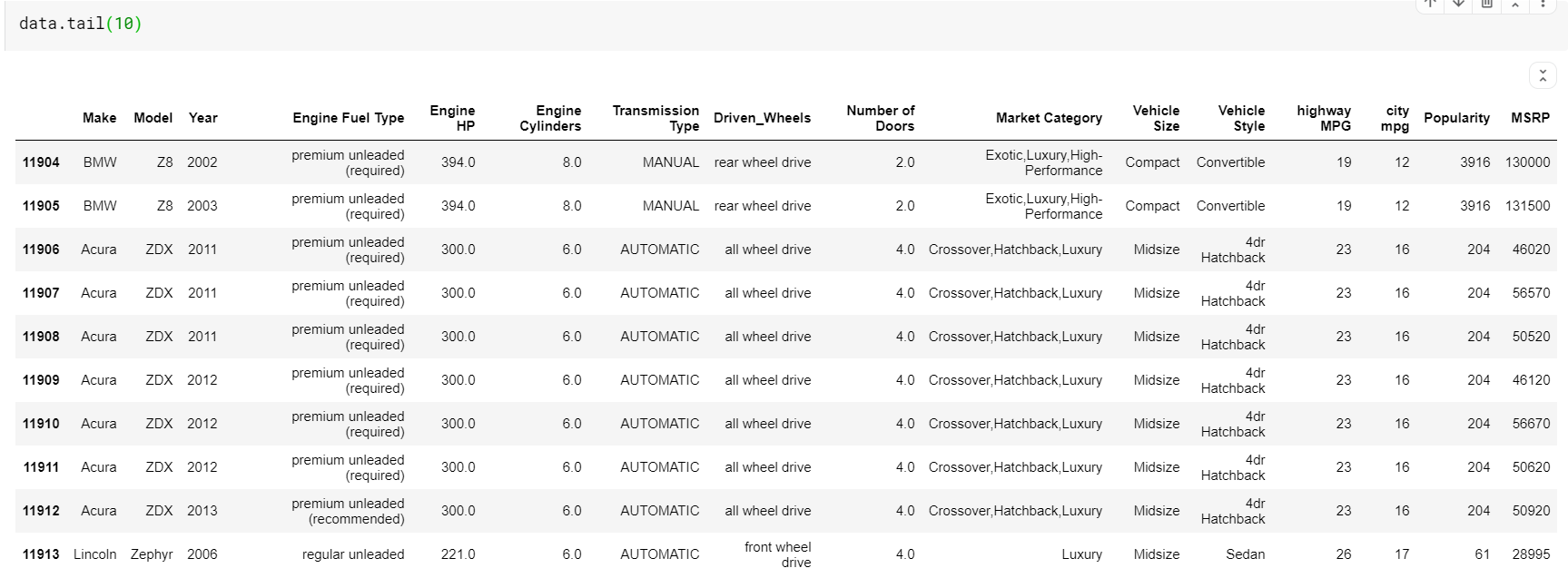
Należy zauważyć, że zarówno funkcje głowy, jak i ogona dają nam indeks górny lub dolny. Ale górne lub dolne wiersze nie zawsze dają dobry podgląd danych. Dzięki temu możesz również wydrukować dowolną liczbę wierszy losowo próbkowanych ze zbioru danych za pomocą funkcji sample().
| # Wydrukuj 5 losowych wierszy dane.przykład( 5 ) |
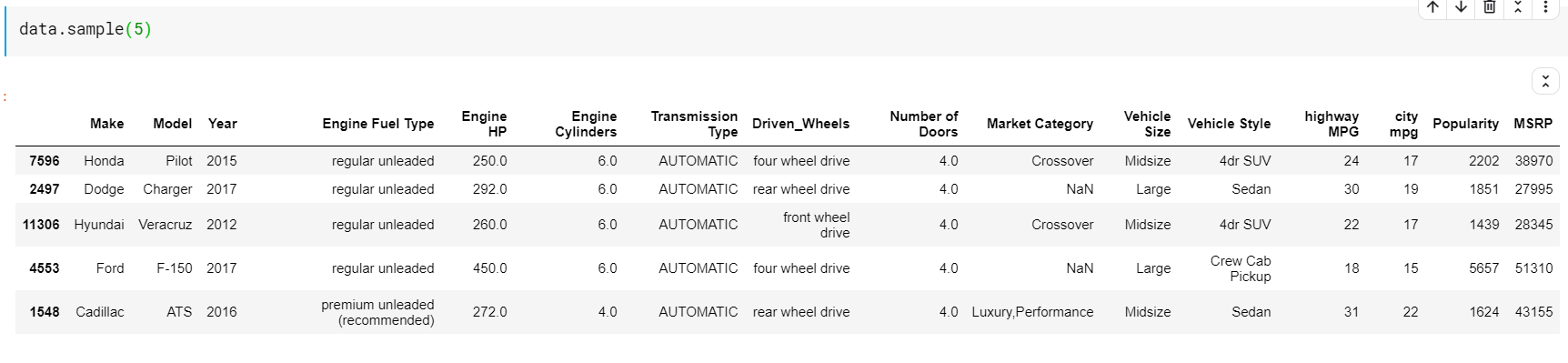
Opisowe statystyki
Następnie sprawdźmy statystyki opisowe zestawu danych. Statystyki opisowe składają się ze wszystkiego, co „opisuje” zbiór danych. Sprawdzamy kształt ramki danych, jakie są wszystkie kolumny, jakie są tam wszystkie cechy liczbowe i kategoryczne. Zobaczymy też, jak to wszystko zrobić w prostych funkcjach.
Kształt
| # Sprawdzanie kształtu ramki danych (mxn) # m=liczba rzędów # n=liczba kolumn dane.kształt |

Jak widzimy, ta ramka danych zawiera 11914 wierszy i 16 kolumn.
Kolumny
| # Wydrukuj nazwy kolumn dane.kolumny |
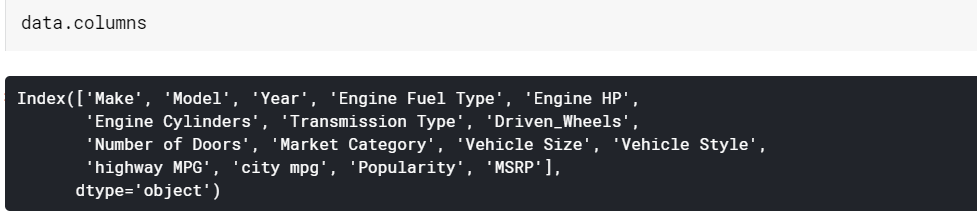
Informacje o ramce danych
| # Wydrukuj typy danych kolumn i liczbę niebrakujących wartości data.info() |
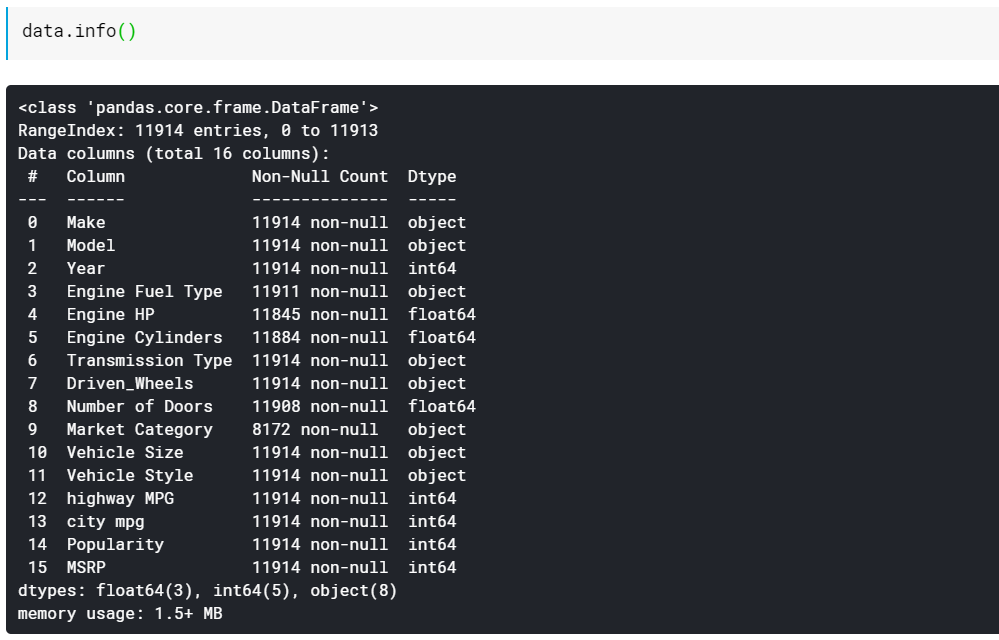
Jak widać, funkcja info() podaje nam wszystkie kolumny, ile wartości niepustych lub brakujących znajduje się w tych kolumnach i na koniec typ danych tych kolumn. Jest to dobry szybki sposób sprawdzenia, które funkcje są numeryczne, a jakie są kategorialne/tekstowe. Ponadto mamy teraz informacje o tym, które wszystkie kolumny mają brakujące wartości. Później przyjrzymy się, jak pracować z brakującymi wartościami.
Manipulowanie nazwami kolumn i typami danych
Dokładne sprawdzanie i manipulowanie każdą kolumną jest niezwykle ważne w EDA. Musimy zobaczyć, jakie wszystkie rodzaje treści zawiera kolumna/funkcja i jakie typy danych są odczytywane przez pandy. Numeryczne typy danych to głównie int64 lub float64. Cechom tekstowym lub kategorycznym przypisywany jest typ danych „obiekt”.
Przypisywane są funkcje oparte na dacie i czasie Są chwile, w których Pandy nie rozumieją typu danych funkcji. W takich przypadkach po prostu leniwie przypisuje mu typ danych „obiekt”. Możemy jawnie określić typy danych kolumn podczas odczytu danych za pomocą read_csv.
Wybieranie kolumn kategorialnych i numerycznych
| # Dodaj wszystkie kategorie i kolumny liczbowe do osobnych list categorical = data.select_dtypes( 'obiekt' ).kolumny numeryczna = data.select_dtypes( 'liczba' ).kolumny |

Tutaj typ, który przekazaliśmy jako „number”, wybiera wszystkie kolumny z typami danych, które mają dowolny rodzaj liczby - czy to int64, czy float64.

Zmiana nazwy kolumn
| # Zmiana nazw kolumn data = data.rename(columns={ “HP silnika” : “HP” , „Cylindry silnika” : „Cylindry” , „Typ transmisji” : „Transmisja” , „Driven_Wheels” : „Tryb jazdy” , „autostrada MPG” : „MPG-H” , „Sugerowana cena producenta” : „Cena” }) data.head( 5 ) |

Funkcja zmiany nazwy po prostu pobiera słownik z nazwami kolumn do zmiany i ich nowymi nazwami.
Obsługa brakujących wartości i zduplikowanych wierszy
Brakujące wartości to jeden z najczęstszych problemów/rozbieżności w każdym rzeczywistym zbiorze danych. Obsługa brakujących wartości jest sama w sobie obszernym tematem, ponieważ można to zrobić na wiele sposobów. Niektóre sposoby są bardziej ogólne, a niektóre są bardziej specyficzne dla zestawu danych, z którym można mieć do czynienia.
Sprawdzanie brakujących wartości
| # Sprawdzanie brakujących wartości data.isnull().sum() |
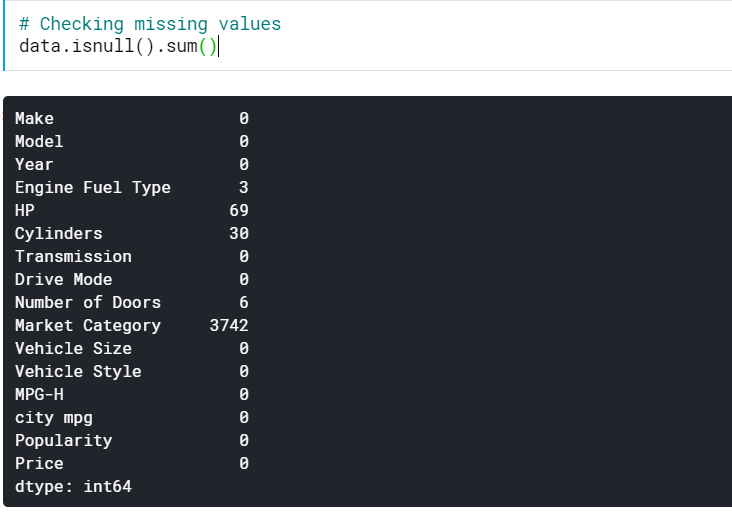
Daje nam to liczbę brakujących wartości we wszystkich kolumnach. Możemy również zobaczyć procent brakujących wartości.
| # Procent brakujących wartości data.isnull().mean()* 100 |
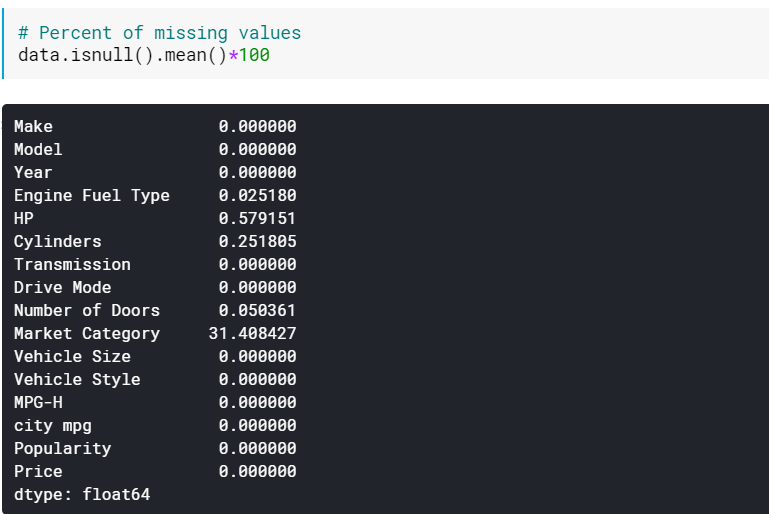
Sprawdzanie wartości procentowych może być przydatne, gdy istnieje wiele kolumn, w których brakuje wartości. W takich przypadkach kolumny z wieloma brakami danych (na przykład brak > 60%) można po prostu pominąć.
Wpisywanie brakujących wartości
| #Wprowadzanie braków danych w kolumnach liczbowych za pomocą średniej dane[liczbowe] = dane[liczbowe].fillna(dane[liczbowe].średnia().iloc[ 0 ]) #Wprowadzanie braków danych w kolumnach kategorii według trybu dane[kategoria] = dane[kategoria].fillna(dane[kategoria].mode().iloc[ 0 ]) |
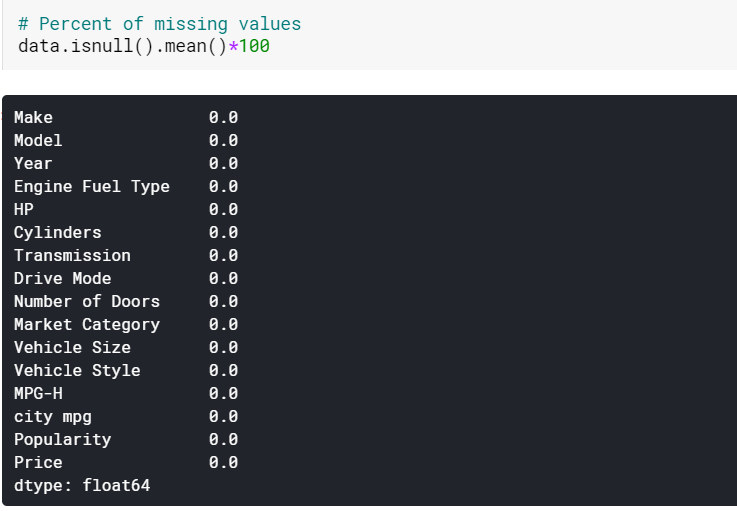
Tutaj po prostu przypisujemy brakujące wartości w kolumnach liczbowych według ich odpowiednich środków, a te w kolumnach kategorialnych według ich trybów. I jak widzimy, nie ma teraz brakujących wartości.
Należy pamiętać, że jest to najbardziej prymitywny sposób przypisywania wartości i nie działa w rzeczywistych przypadkach, w których opracowywane są bardziej wyrafinowane sposoby, na przykład interpolacja, KNN itp.
Obsługa zduplikowanych wierszy
| # Upuść zduplikowane wiersze data.drop_duplicates(inplace= Prawda ) |
To po prostu usuwa zduplikowane wiersze.
Zamówienie: pomysły i tematy projektów w Pythonie
Analiza dwuwymiarowa
Zobaczmy teraz, jak uzyskać więcej informacji, wykonując analizę dwuwymiarową. Dwuwymiarowa oznacza analizę, która składa się z 2 zmiennych lub cech. Dla różnych typów funkcji dostępne są różne rodzaje wykresów.
Dla liczbowe – liczbowe
- Wykres punktowy
- Działka liniowa
- Mapa cieplna dla korelacji
Dla kategoryczno-numerycznego
- Wykres słupkowy
- fabuła skrzypcowa
- Działka roju
Dla kategorycznej-kategorycznej
- Wykres słupkowy
- Działka punktowa
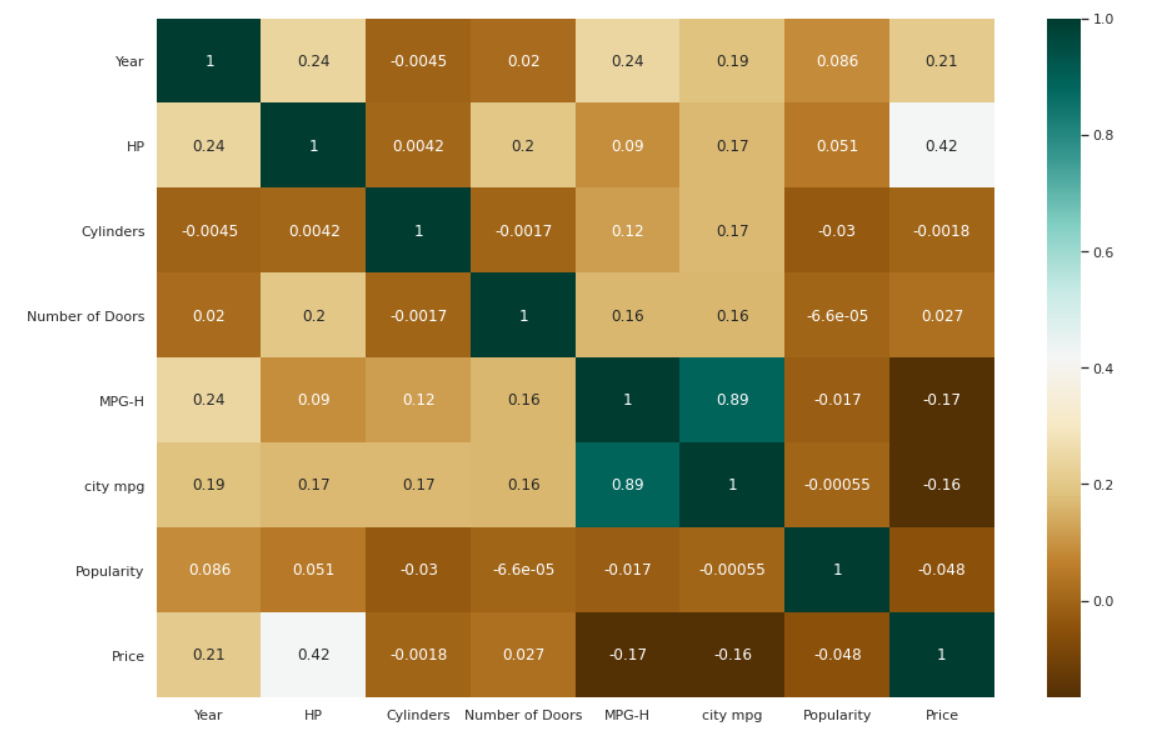
Mapa cieplna dla korelacji
| # Sprawdzenie korelacji między zmiennymi. plt.figure(figsize=( 15 , 10 )) c= dane.corr() sns.heatmap(c,cmap= “BrBG” ,annot= Prawda ) |
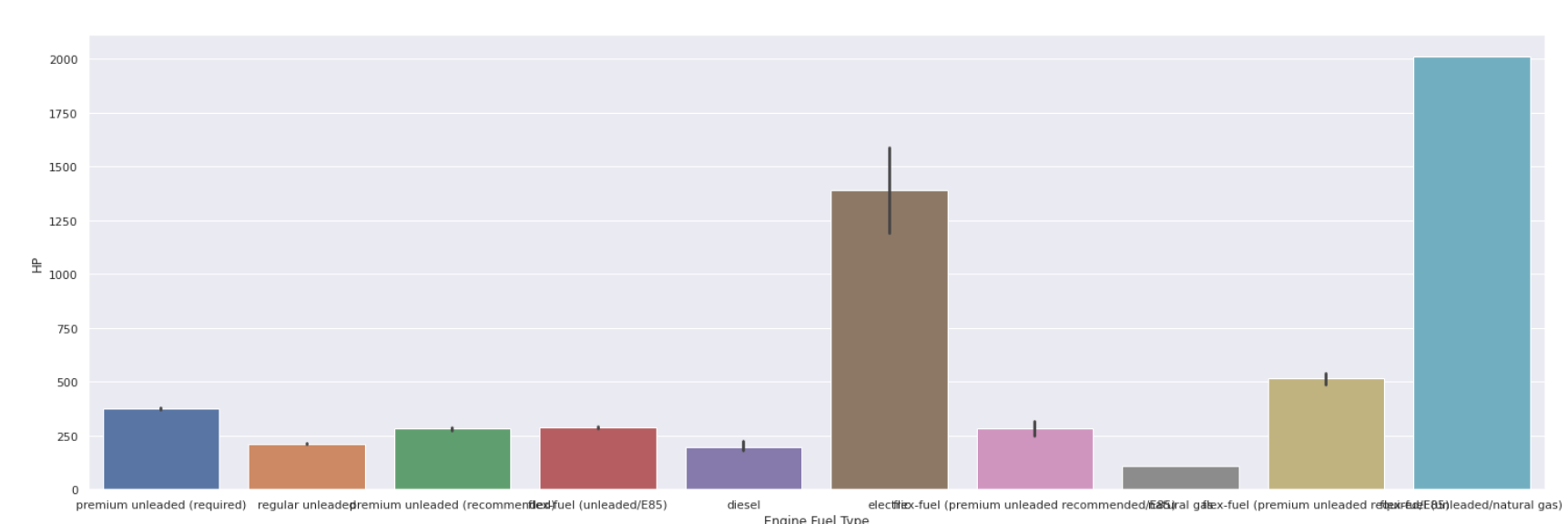
Wykres barowy
| sns.barplot(data[ 'Typ paliwa silnika' ], dane[ 'HP' ]) |
Uzyskaj certyfikat data science od najlepszych światowych uniwersytetów. Naucz się programów Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Wniosek
Jak widzieliśmy, podczas eksploracji zbioru danych należy wykonać wiele kroków. W tym samouczku omówiliśmy tylko kilka aspektów, ale da ci to więcej niż tylko podstawową wiedzę na temat dobrego EDA.
Jeśli chcesz dowiedzieć się czegoś o Pythonie, wszystkiego o nauce o danych, sprawdź IIIT-B i upGrad's PG Diploma in Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z przemysłem eksperci, indywidualni z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Jakie są etapy eksploracyjnej analizy danych?
Główne kroki, które należy wykonać, aby przeprowadzić eksploracyjną analizę danych to:
Należy zidentyfikować zmienne i typy danych.
Analiza podstawowych metryk
Jednowymiarowa analiza niegraficzna
Jednowymiarowa analiza graficzna
Analiza danych dwuwymiarowych
Transformacje, które są zmienne
Leczenie brakującej wartości
Leczenie wartości odstających
Analiza korelacji
Redukcja wymiarowości
Jaki jest cel eksploracyjnej analizy danych?
Podstawowym celem EDA jest pomoc w analizie danych przed przyjęciem jakichkolwiek założeń. Może pomóc w wykrywaniu ewidentnych błędów, a także w lepszym zrozumieniu wzorców danych, wykrywaniu wartości odstających lub nietypowych zdarzeń oraz odkrywaniu interesujących relacji między zmiennymi.
Analiza eksploracyjna może być wykorzystywana przez naukowców zajmujących się danymi, aby zagwarantować, że tworzone przez nich wyniki są dokładne i odpowiednie do wszelkich docelowych wyników i celów biznesowych. EDA pomaga również zainteresowanym stronom, zapewniając, że odpowiadają na odpowiednie pytania. Na odchylenia standardowe, dane kategoryczne i przedziały ufności można odpowiedzieć za pomocą EDA. Po zakończeniu EDA i wyodrębnieniu spostrzeżeń, jego funkcje można zastosować do bardziej zaawansowanej analizy danych lub modelowania, w tym uczenia maszynowego.
Jakie są rodzaje eksploracyjnej analizy danych?
Istnieją dwa rodzaje technik EDA: graficzna i ilościowa (niegraficzna). Z drugiej strony podejście ilościowe wymaga zestawienia statystyk podsumowujących, podczas gdy metody graficzne wymagają gromadzenia danych w sposób diagramowy lub wizualny. Podejścia jednowymiarowe i wielowymiarowe stanowią podzbiory tych dwóch rodzajów metodologii.
Aby zbadać relacje, podejścia jednowymiarowe przyglądają się jednej zmiennej (kolumnie danych) na raz, podczas gdy metody wielowymiarowe przyglądają się dwóm lub większej liczbie zmiennych jednocześnie. Jednowymiarowa i wielowymiarowa, graficzna i niegraficzna, to cztery formy EDA. Procedury ilościowe są bardziej obiektywne, natomiast metody obrazkowe są bardziej subiektywne.