
Przewodnik po etycznym usuwaniu dynamicznych stron internetowych z Node.js i Puppeteer
Opublikowany: 2022-03-10Zacznijmy od krótkiej sekcji o tym, co właściwie oznacza web scraping. Wszyscy używamy web scrapingu w naszym codziennym życiu. Opisuje jedynie proces wydobywania informacji ze strony internetowej. Dlatego, jeśli skopiujesz i wkleisz przepis na ulubione danie z makaronem z Internetu do swojego osobistego notatnika, wykonujesz skrobanie sieci .
Używając tego terminu w branży oprogramowania, zwykle odnosimy się do automatyzacji tego ręcznego zadania za pomocą oprogramowania. Trzymając się naszego poprzedniego przykładu „danie z makaronem”, ten proces zwykle obejmuje dwa etapy:
- Pobieranie strony
Najpierw musimy pobrać całą stronę. Ten krok przypomina otwieranie strony w przeglądarce internetowej podczas ręcznego scrapingu. - Analiza danych
Teraz musimy wyodrębnić przepis w kodzie HTML strony i przekonwertować go na format do odczytu maszynowego, taki jak JSON lub XML.
W przeszłości pracowałem dla wielu firm jako konsultant ds. danych. Byłem zdumiony, widząc, jak wiele zadań ekstrakcji danych, agregacji i wzbogacania jest nadal wykonywanych ręcznie, chociaż można je łatwo zautomatyzować za pomocą zaledwie kilku linijek kodu. Właśnie na tym polega dla mnie web scraping: wydobywanie i normalizowanie cennych informacji ze strony internetowej w celu napędzania kolejnego procesu biznesowego, który generuje wartość.
W tym czasie widziałem, jak firmy używają web scrapingu do wszelkiego rodzaju przypadków użycia. Firmy inwestycyjne skupiały się przede wszystkim na gromadzeniu alternatywnych danych, takich jak recenzje produktów , informacje o cenach lub posty w mediach społecznościowych, aby uzasadnić swoje inwestycje finansowe.
Oto jeden przykład. Klient zwrócił się do mnie, aby zebrać dane recenzji produktów dla obszernej listy produktów z kilku witryn e-commerce, w tym oceny, lokalizacji recenzenta i tekstu recenzji dla każdej przesłanej recenzji. Uzyskane dane pozwoliły klientowi zidentyfikować trendy dotyczące popularności produktu na różnych rynkach. To doskonały przykład na to, jak pozornie „bezużyteczna” pojedyncza informacja może stać się cenna w porównaniu z większą ilością.
Inne firmy przyspieszają proces sprzedaży poprzez wykorzystanie web scrapingu do generowania leadów . Ten proces zwykle obejmuje wyodrębnienie informacji kontaktowych, takich jak numer telefonu, adres e-mail i imię i nazwisko osoby kontaktowej dla danej listy witryn. Automatyzacja tego zadania daje zespołom sprzedażowym więcej czasu na dotarcie do potencjalnych klientów. Dzięki temu wzrasta efektywność procesu sprzedaży.
Trzymać się zasad
Ogólnie rzecz biorąc, publicznie dostępne dane z web scrapingu są legalne, co potwierdza jurysdykcja w sprawie Linkedin vs. HiQ. Jednak wyznaczyłem sobie etyczny zestaw zasad, których lubię się trzymać, rozpoczynając nowy projekt web scrapingu. To zawiera:
- Sprawdzam plik robots.txt.
Zwykle zawiera jasne informacje o tym, do których części witryny właściciel strony może mieć dostęp dla robotów i skrobaków, a także podkreśla sekcje, do których nie należy uzyskiwać dostępu. - Zapoznanie się z regulaminem.
W porównaniu z plikiem robots.txt ta informacja nie jest dostępna rzadziej, ale zwykle określa, w jaki sposób traktują one skrobaki danych. - Skrobanie z umiarkowaną prędkością.
Skrobanie powoduje obciążenie serwera infrastruktury witryny docelowej. W zależności od tego, co zgarniasz i na jakim poziomie współbieżności działa Twój scraper, ruch może powodować problemy w infrastrukturze serwera witryny docelowej. Oczywiście dużą rolę w tym równaniu odgrywa pojemność serwera. Dlatego szybkość mojego skrobaka jest zawsze równowagą między ilością danych, które zamierzam zeskrobać, a popularnością docelowej strony. Znalezienie tej równowagi można osiągnąć, odpowiadając na jedno pytanie: „Czy planowana prędkość znacząco zmieni ruch organiczny na stronie?”. W przypadkach, w których nie mam pewności co do ilości naturalnego ruchu na stronie, używam narzędzi takich jak ahrefs, aby uzyskać przybliżony pomysł.
Wybór odpowiedniej technologii
W rzeczywistości scraping za pomocą przeglądarki bezgłowej jest jedną z najmniej wydajnych technologii, których możesz użyć, ponieważ ma duży wpływ na twoją infrastrukturę. Jeden rdzeń procesora Twojej maszyny może w przybliżeniu obsłużyć jedną instancję Chrome.
Zróbmy szybkie przykładowe obliczenie , aby zobaczyć, co to oznacza dla projektu skrobania sieci w świecie rzeczywistym.
Scenariusz
- Chcesz zeskrobać 20 000 adresów URL.
- Średni czas odpowiedzi ze strony docelowej to 6 sekund.
- Twój serwer ma 2 rdzenie procesora.
Projekt zajmie 16 godzin .
Dlatego zawsze staram się unikać korzystania z przeglądarki podczas przeprowadzania testu wykonalności dla dynamicznej witryny internetowej.
Oto mała lista kontrolna, przez którą zawsze przechodzę:
- Czy mogę wymusić wymagany stan strony za pomocą parametrów GET w adresie URL? Jeśli tak, możemy po prostu uruchomić żądanie HTTP z dołączonymi parametrami.
- Czy informacje dynamiczne są częścią źródła strony i są dostępne przez obiekt JavaScript gdzieś w DOM? Jeśli tak, możemy ponownie użyć normalnego żądania HTTP i przeanalizować dane z obiektu z ciągiem znaków.
- Czy dane są pobierane przez żądanie XHR? Jeśli tak, czy mogę uzyskać bezpośredni dostęp do punktu końcowego za pomocą klienta HTTP? Jeśli tak, możemy wysłać żądanie HTTP bezpośrednio do punktu końcowego. Często odpowiedź jest nawet formatowana w formacie JSON, co znacznie ułatwia nam życie.
Jeśli na wszystkie pytania odpowiemy zdecydowanie „Nie”, oficjalnie skończą nam się możliwe opcje korzystania z klienta HTTP. Oczywiście może być więcej ulepszeń specyficznych dla witryny, które moglibyśmy wypróbować, ale zwykle wymagany czas na ich rozgryzienie jest zbyt długi w porównaniu z wolniejszą wydajnością przeglądarki bezgłowej. Piękno scrapingu w przeglądarce polega na tym, że możesz zeskrobać wszystko, co podlega następującej podstawowej zasadzie:
Jeśli możesz uzyskać do niego dostęp za pomocą przeglądarki, możesz go zeskrobać.
Weźmy następującą witrynę jako przykład dla naszego skrobaka: https://quotes.toscrape.com/search.aspx. Zawiera cytaty z listy podanych autorów na listę tematów. Wszystkie dane są pobierane przez XHR.
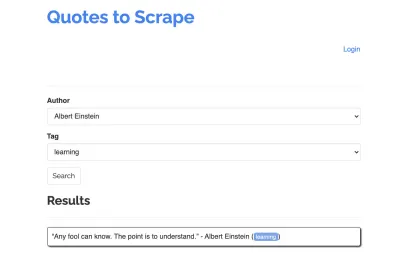
Ktokolwiek przyjrzał się bliżej funkcjonowaniu witryny i przeszedł przez powyższą listę kontrolną, prawdopodobnie zdał sobie sprawę, że cytaty można faktycznie zeskrobać za pomocą klienta HTTP, ponieważ można je pobrać, wysyłając żądanie POST bezpośrednio do punktu końcowego cytatów. Ale ponieważ ten samouczek ma omówić, jak skrobać witrynę za pomocą Puppeteer, będziemy udawać, że to niemożliwe.
Wymagania wstępne instalacji
Ponieważ zamierzamy zbudować wszystko za pomocą Node.js, najpierw utwórzmy i otwórzmy nowy folder, a następnie stwórzmy w nim nowy projekt Node, uruchamiając następujące polecenie:
mkdir js-webscraper cd js-webscraper npm initUpewnij się, że masz już zainstalowany npm. Instalator zada nam kilka pytań dotyczących meta-informacji o tym projekcie, które wszyscy możemy pominąć, naciskając Enter .
Instalowanie Lalkarza
Mówiliśmy już o skrobaniu za pomocą przeglądarki. Puppeteer to interfejs API Node.js, który pozwala nam programowo komunikować się z bezgłową instancją Chrome .
Zainstalujmy go za pomocą npm:
npm install puppeteerBudowanie naszego skrobaka
Teraz zacznijmy budować nasz scraper, tworząc nowy plik o nazwie scraper.js .
Najpierw importujemy wcześniej zainstalowaną bibliotekę Puppeteer:
const puppeteer = require('puppeteer');W następnym kroku mówimy Puppeteer, aby otworzył nową instancję przeglądarki wewnątrz asynchronicznej i samoczynnie wykonującej się funkcji:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();Uwaga : Domyślnie tryb bezgłowy jest wyłączony, ponieważ zwiększa to wydajność. Jednak budując nowy skrobak, lubię wyłączać tryb bezgłowy. Dzięki temu możemy śledzić proces, przez który przechodzi przeglądarka i zobaczyć całą renderowaną zawartość. Pomoże nam to później debugować nasz skrypt.
Wewnątrz naszej otwartej instancji przeglądarki otwieramy teraz nową stronę i kierujemy się do naszego docelowego adresu URL:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); W ramach funkcji asynchronicznej użyjemy instrukcji await , aby poczekać na wykonanie następującego polecenia przed przejściem do następnego wiersza kodu.
Teraz, gdy pomyślnie otworzyliśmy okno przeglądarki i przeszliśmy do strony, musimy utworzyć stan witryny , aby żądane informacje stały się widoczne do scrapingu.
Dostępne tematy są generowane dynamicznie dla wybranego autora. Dlatego najpierw wybierzemy „Albert Einstein” i czekamy na wygenerowaną listę tematów. Gdy lista zostanie w pełni wygenerowana, wybieramy „nauka” jako temat i wybieramy go jako drugi parametr formularza. Następnie klikamy „Prześlij” i wyodrębniamy pobrane cytaty z kontenera, w którym znajdują się wyniki.

Ponieważ teraz przekonwertujemy to na logikę JavaScript, zróbmy najpierw listę wszystkich selektorów elementów, o których mówiliśmy w poprzednim akapicie:
| Pole wyboru autora | #author |
| Pole wyboru tagu | #tag |
| Przycisk Prześlij | input[type="submit"] |
| Kontener ofert | .quote |
Zanim zaczniemy wchodzić w interakcję ze stroną, upewnimy się, że wszystkie elementy, do których uzyskamy dostęp są widoczne, dodając do naszego skryptu następujące wiersze:
await page.waitForSelector('#author'); await page.waitForSelector('#tag');Następnie wybierzemy wartości dla naszych dwóch wybranych pól:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');Jesteśmy teraz gotowi do przeprowadzenia wyszukiwania, naciskając przycisk „Szukaj” na stronie i poczekaj na pojawienie się cytatów:
await page.click('.btn'); await page.waitForSelector('.quote'); Ponieważ zamierzamy teraz uzyskać dostęp do struktury HTML DOM strony, wywołujemy podaną funkcję page.evaluate() , wybierając kontener, który przechowuje cudzysłowy (w tym przypadku jest to tylko jeden). Następnie budujemy obiekt i definiujemy null jako wartość zastępczą dla każdego parametru object :
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });Wszystkie wyniki możemy uwidocznić w naszej konsoli, logując je:
console.log(quotes);Na koniec zamknijmy naszą przeglądarkę i dodajmy oświadczenie catch:
await browser.close();Kompletny skrobak wygląda następująco:
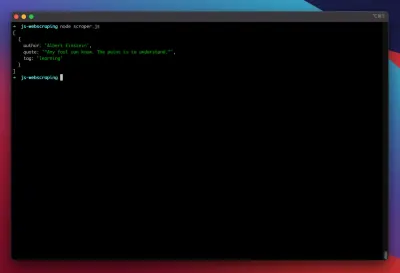
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();Spróbujmy uruchomić nasz skrobak za pomocą:
node scraper.jsI gotowe! Skrobak zwraca nasz obiekt cytatu zgodnie z oczekiwaniami:
Zaawansowane optymalizacje
Nasz podstawowy skrobak teraz działa. Dodajmy kilka ulepszeń, aby przygotować go do poważniejszych zadań związanych ze skrobaniem.
Ustawianie agenta użytkownika
Domyślnie Puppeteer używa klienta użytkownika zawierającego ciąg HeadlessChrome . Sporo stron internetowych szuka tego rodzaju podpisu i blokuje przychodzące żądania za pomocą takiego podpisu. Aby uniknąć potencjalnej przyczyny niepowodzenia scrapera, zawsze ustawiam niestandardowego klienta użytkownika, dodając następujący wiersz do naszego kodu:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');Można to jeszcze bardziej poprawić, wybierając losowego klienta użytkownika przy każdym żądaniu z tablicy pięciu najpopularniejszych klientów użytkownika. Listę najczęstszych klientów użytkownika można znaleźć w artykule na temat Most Common User-Agent.
Wdrażanie proxy
Puppeteer sprawia, że łączenie się z serwerem proxy jest bardzo łatwe, ponieważ adres proxy można przekazać do Puppeteer podczas uruchamiania, w następujący sposób:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxy udostępnia dużą listę bezpłatnych serwerów proxy, których możesz użyć. Alternatywnie można korzystać z usług rotacyjnego proxy. Ponieważ serwery proxy są zwykle dzielone między wielu klientów (lub w tym przypadku użytkowników bezpłatnych), połączenie staje się znacznie bardziej zawodne niż w normalnych okolicznościach. To idealny moment, aby porozmawiać o obsłudze błędów i zarządzaniu ponownymi próbami.
Zarządzanie błędami i ponawianiem prób
Wiele czynników może spowodować awarię skrobaka. Dlatego ważne jest, aby radzić sobie z błędami i decydować, co powinno się stać w przypadku awarii. Ponieważ podłączyliśmy nasz skrobak do serwera proxy i spodziewamy się, że połączenie będzie niestabilne (zwłaszcza dlatego, że używamy bezpłatnych serwerów proxy), chcemy spróbować cztery razy, zanim się poddamy.
Ponadto nie ma sensu ponawiać żądania z tym samym adresem IP, jeśli wcześniej się nie powiodło. Dlatego zamierzamy zbudować mały system proxy rotacji .
Przede wszystkim tworzymy dwie nowe zmienne:
let retry = 0; let maxRetries = 5; Za każdym razem, gdy uruchamiamy naszą funkcję scrape() , zwiększamy naszą zmienną retry o 1. Następnie otaczamy całą logikę scrapingu instrukcją try and catch, aby móc obsłużyć błędy. Zarządzanie ponawianiem odbywa się w naszej funkcji catch :
Poprzednia instancja przeglądarki zostanie zamknięta, a jeśli nasza zmienna ponawiania jest mniejsza niż zmienna maxRetries , funkcja scrape jest wywoływana rekursywnie.
Nasz skrobak będzie teraz wyglądał tak:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };Teraz dodajmy wspomniany wcześniej rotator proxy.
Stwórzmy najpierw tablicę zawierającą listę serwerów proxy:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];Teraz wybierz losową wartość z tablicy:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];Możemy teraz uruchomić dynamicznie generowane proxy razem z naszą instancją Puppeteer:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });Oczywiście ten rotator proxy można dalej zoptymalizować, aby oznaczać martwe serwery proxy i tak dalej, ale zdecydowanie wykraczałoby to poza zakres tego samouczka.
Oto kod naszego skrobaka (wraz ze wszystkimi ulepszeniami):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();Voila! Uruchomienie naszego skrobaka w naszym terminalu zwróci cytaty.
Dramaturg jako alternatywa dla lalkarza
Lalkarz został opracowany przez Google. Na początku 2020 roku Microsoft wypuścił alternatywę o nazwie Playwright. Microsoft headhuntował wielu inżynierów z Zespołu Lalkarzy. Dlatego Playwright został opracowany przez wielu inżynierów, którzy już mieli swoje ręce pracując nad Puppeteer. Oprócz bycia nowym dzieckiem na blogu, największym wyróżnikiem Playwrighta jest obsługa wielu przeglądarek, ponieważ obsługuje Chromium, Firefox i WebKit (Safari).
Testy wydajności (takie jak ten przeprowadzony przez Checkly) pokazują, że Puppeteer generalnie zapewnia około 30% lepszą wydajność w porównaniu do Playwrighta, co odpowiada moim własnym doświadczeniom — przynajmniej w momencie pisania.
Inne różnice, takie jak możliwość uruchamiania wielu urządzeń za pomocą jednej instancji przeglądarki, nie są tak naprawdę cenne w kontekście web scrapingu.
Zasoby i dodatkowe linki
- Dokumentacja lalkarza
- Nauka lalkarza i dramaturga
- Web Scrape za pomocą Javascript przez Zenscrape
- Najczęstsze klienty użytkownika
- Lalkarz kontra dramaturg