
Dodawanie funkcji dynamicznych i asynchronicznych do witryn JAMstack
Opublikowany: 2022-03-10Czy to oznacza, że witryny JAMstack nie obsługują interakcji dynamicznych? Absolutnie nie!
Witryny JAMstack doskonale nadają się do tworzenia bardzo dynamicznych, asynchronicznych interakcji. Dzięki niewielkim zmianom w sposobie myślenia o naszym kodzie możemy tworzyć zabawne, wciągające interakcje, używając tylko statycznych zasobów!
Coraz częściej spotyka się witryny internetowe zbudowane przy użyciu JAMstack — czyli witryny, które mogą być obsługiwane jako statyczne pliki HTML zbudowane z JavaScript, znaczników i interfejsów API. Firmy uwielbiają JAMstack, ponieważ zmniejsza on koszty infrastruktury, przyspiesza dostarczanie i obniża bariery dla poprawy wydajności i bezpieczeństwa, ponieważ wysyłanie zasobów statycznych eliminuje potrzebę skalowania serwerów lub utrzymywania wysokiej dostępności baz danych (co oznacza również, że nie ma serwerów ani baz danych, które mogą zostać zhakowany). Deweloperzy lubią JAMstack, ponieważ zmniejsza złożoność uruchamiania witryny w Internecie: nie ma serwerów do zarządzania ani wdrażania; możemy napisać kod front-endowy i po prostu się uruchomi , jak magia .
(„Magia” w tym przypadku to automatyczne statyczne wdrożenia, które są dostępne bezpłatnie w wielu firmach, w tym Netlify, w której pracuję.)
Ale jeśli spędzisz dużo czasu rozmawiając z programistami o JAMstack, pojawi się pytanie, czy JAMstack poradzi sobie z poważnymi aplikacjami internetowymi. W końcu witryny JAMstack są witrynami statycznymi, prawda? I czy statyczne witryny nie są bardzo ograniczone w swoich możliwościach?
Jest to naprawdę powszechne nieporozumienie i w tym artykule zagłębimy się w jego źródło, przyjrzymy się możliwościom JAMstack i omówimy kilka przykładów wykorzystania JAMstack do tworzenia poważnych aplikacji internetowych.
Podstawy JAMstack
Phil Hawksworth wyjaśnia, co tak naprawdę oznacza JAMStack i kiedy ma sens wykorzystanie go w swoich projektach, a także jak wpływa na oprzyrządowanie i architekturę front-endu. Przeczytaj powiązany artykuł →
Co sprawia, że witryna JAMstack jest „statyczna”?
Dzisiejsze przeglądarki internetowe ładują pliki HTML, CSS i JavaScript, tak jak w latach 90.
Witryna JAMstack, w swej istocie, to folder pełen plików HTML, CSS i JavaScript.
Są to „zasoby statyczne”, co oznacza, że nie potrzebujemy pośredniego kroku, aby je wygenerować (na przykład projekty PHP, takie jak WordPress, potrzebują serwera do generowania kodu HTML przy każdym żądaniu).
To jest prawdziwa moc JAMstack: do działania nie wymaga żadnej specjalistycznej infrastruktury. Możesz uruchomić witrynę JAMstack na komputerze lokalnym, umieszczając ją w preferowanej sieci dostarczania treści (CDN), udostępniając ją z usługami takimi jak GitHub Pages — możesz nawet przeciągnąć i upuścić folder do swojego ulubionego klienta FTP, aby go przesłać do hostingu współdzielonego.
Zasoby statyczne nie muszą koniecznie oznaczać statycznych doświadczeń
Ponieważ witryny JAMstack składają się z plików statycznych, łatwo jest założyć, że ich działanie jest, wiesz, statyczne . Ale tak nie jest!
JavaScript jest w stanie robić wiele dynamicznych rzeczy. W końcu nowoczesne frameworki JavaScript są plikami statycznymi po przejściu przez etap budowania — i są setki przykładów niesamowicie dynamicznych środowisk internetowych, które są na nich oparte.
Istnieje powszechne błędne przekonanie, że „statyczny” oznacza nieelastyczny lub stały. Ale wszystko to, co „statyczne” tak naprawdę oznacza w kontekście „witryny statycznej”, to to, że przeglądarki nie potrzebują żadnej pomocy w dostarczaniu ich treści — są w stanie używać ich natywnie bez serwera obsługującego najpierw etap przetwarzania.
Lub w inny sposób:
„Zasoby statyczne” nie oznaczają aplikacji statycznych; oznacza to, że serwer nie jest wymagany.
“
Czy JAMstack może to zrobić?
Jeśli ktoś pyta o tworzenie nowej aplikacji, często pojawiają się sugestie dotyczące metod JAMstack, takich jak Gatsby, Eleveny, Nuxt i innych podobnych narzędzi. Równie często pojawiają się zastrzeżenia: „statyczne generatory witryn nie potrafią _______”, gdzie _______ to coś dynamicznego.
Ale — jak wspomnieliśmy w poprzedniej sekcji — witryny JAMstack mogą obsługiwać dynamiczną zawartość i interakcje!
Oto niepełna lista rzeczy, o których wielokrotnie słyszałem, jak ludzie twierdzą, że JAMstack nie poradzi sobie z tym, a zdecydowanie może:
- Załaduj dane asynchronicznie
- Obsługuj przetwarzanie plików, takie jak manipulowanie obrazami
- Odczytuj i zapisuj w bazie danych
- Obsługuj uwierzytelnianie użytkowników i chroń zawartość za logowaniem
W kolejnych sekcjach przyjrzymy się, jak zaimplementować każdy z tych przepływów pracy w witrynie JAMstack.
Jeśli nie możesz się doczekać, aby zobaczyć dynamiczny JAMstack w akcji, możesz najpierw sprawdzić wersje demonstracyjne, a następnie wrócić i dowiedzieć się, jak działają.
Uwaga na temat dem :
Te dema są napisane bez żadnych frameworków. Są to tylko HTML, CSS i standardowy JavaScript. Zostały zbudowane z myślą o nowoczesnych przeglądarkach (np. Chrome, Firefox, Safari, Edge) i wykorzystują nowsze funkcje, takie jak moduły JavaScript, szablony HTML i Fetch API. Nie dodano żadnych wypełniaczy, więc jeśli używasz nieobsługiwanej przeglądarki, demo prawdopodobnie się nie powiedzie.
Asynchroniczne ładowanie danych z zewnętrznego interfejsu API
„A co, jeśli po zbudowaniu plików statycznych potrzebuję uzyskać nowe dane?”
W JAMstack możemy skorzystać z wielu bibliotek asynchronicznych żądań, w tym wbudowanego Fetch API, aby w dowolnym momencie załadować dane za pomocą JavaScript.
Demo: Wyszukaj interfejs API innej firmy w witrynie JAMstack
Typowym scenariuszem, który wymaga asynchronicznego ładowania, jest sytuacja, w której potrzebna zawartość zależy od danych wejściowych użytkownika. Na przykład, jeśli tworzymy stronę wyszukiwania dla interfejsu API Rick & Morty , nie wiemy, jaką treść wyświetlić, dopóki ktoś nie wprowadzi wyszukiwanego hasła.
Aby sobie z tym poradzić, musimy:
- Utwórz formularz, w którym ludzie będą mogli wpisywać wyszukiwane hasło,
- Posłuchaj na przesłanie formularza,
- Pobierz wyszukiwane hasło z przesłanego formularza,
- Wyślij asynchroniczne żądanie do API Rick & Morty przy użyciu wyszukiwanego hasła,
- Wyświetl wyniki żądania na stronie.
Najpierw musimy stworzyć formularz i pusty element, który będzie zawierał nasze wyniki wyszukiwania, który wygląda tak:
<form> <label for="name">Find characters by name</label> <input type="text" name="name" required /> <button type="submit">Search</button> </form> <ul></ul>Następnie musimy napisać funkcję, która obsługuje przesyłanie formularzy. Ta funkcja:
- Zapobiegaj domyślnemu zachowaniu przesyłania formularzy
- Pobierz wyszukiwane hasło z danych wejściowych formularza
- Użyj interfejsu API Fetch, aby wysłać żądanie do interfejsu API Rick & Morty przy użyciu wyszukiwanego hasła
- Wywołaj funkcję pomocniczą, która wyświetla wyniki wyszukiwania na stronie
Musimy również dodać detektor zdarzeń w formularzu dla zdarzenia submit, które wywołują naszą funkcję obsługi.
Oto jak ten kod wygląda w całości:
<script type="module"> import showResults from './show-results.js'; const form = document.querySelector('form'); const handleSubmit = async event => { event.preventDefault(); // get the search term from the form input const name = form.elements['name'].value; // send a request to the Rick & Morty API based on the user input const characters = await fetch( `https://rickandmortyapi.com/api/character/?name=${name}`, ) .then(response => response.json()) .catch(error => console.error(error)); // add the search results to the DOM showResults(characters.results); }; form.addEventListener('submit', handleSubmit); </script>Uwaga: aby skupić się na dynamicznych zachowaniach JAMstack, nie będziemy omawiać sposobu pisania funkcji narzędziowych, takich jak showResults. Kod jest jednak dokładnie skomentowany, więc sprawdź źródło, aby dowiedzieć się, jak to działa!
Mając ten kod na miejscu, możemy załadować naszą witrynę w przeglądarce i zobaczymy pusty formularz bez żadnych wyników pokazujących:
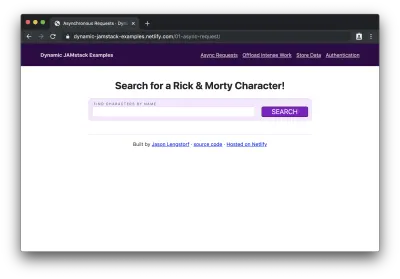
Jeśli wpiszemy nazwę postaci (np. „rick”) i klikniemy „szukaj”, zobaczymy listę postaci, których nazwy zawierają „rick”:
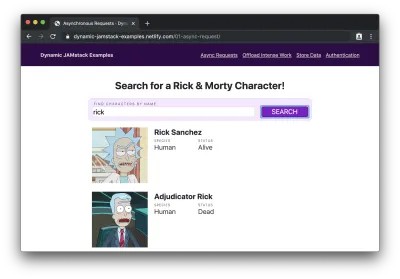
Hej! Czy ta statyczna witryna właśnie dynamicznie ładowała dane? Święte wiadra!
Możesz wypróbować to sam na demo na żywo lub zapoznać się z pełnym kodem źródłowym, aby uzyskać więcej informacji.
Obsługa kosztownych zadań obliczeniowych poza urządzeniem użytkownika
W wielu aplikacjach musimy robić rzeczy, które wymagają dużej ilości zasobów, takie jak przetwarzanie obrazu. Chociaż niektóre z tego rodzaju operacji są możliwe tylko przy użyciu JavaScript po stronie klienta, niekoniecznie jest dobrym pomysłem, aby urządzenia użytkowników wykonywały całą tę pracę. Jeśli korzystają z urządzenia o niskim poborze mocy lub próbują wydłużyć ostatnie 5% czasu pracy na baterii, zmuszanie ich do wykonywania mnóstwa pracy prawdopodobnie będzie dla nich frustrującym doświadczeniem.
Czy to oznacza, że aplikacje JAMstack nie mają szczęścia? Zupełnie nie!
Litera „A” w JAMstack oznacza API. Oznacza to, że możemy wysłać tę pracę do interfejsu API i uniknąć podkręcania fanów komputerów naszych użytkowników do ustawienia „najechania”.
„Ale poczekaj”, możesz powiedzieć. „Jeśli nasza aplikacja musi wykonać niestandardową pracę, a ta praca wymaga interfejsu API, czy nie oznacza to po prostu, że budujemy serwer?”
Dzięki potędze funkcji serverless nie musimy!
Funkcje bezserwerowe (nazywane również „funkcjami lambda”) są rodzajem interfejsu API, który nie wymaga żadnego szablonu serwera. Możemy napisać zwykłą starą funkcję JavaScript, a cała praca związana z wdrażaniem, skalowaniem, routingiem i tak dalej jest odkładana na naszego wybranego dostawcę bezserwerowego.
Korzystanie z funkcji bezserwerowych nie oznacza, że nie ma serwera; oznacza to po prostu, że nie musimy myśleć o serwerze.
“
Funkcje bezserwerowe są masłem orzechowym dla naszego JAMstack: odblokowują cały świat zaawansowanych, dynamicznych funkcji, nie prosząc nas o zajęcie się kodem serwera lub Devops.
Demo: Konwertuj obraz na skalę szarości
Załóżmy, że mamy aplikację, która musi:
- Pobierz obraz z adresu URL
- Konwertuj ten obraz na skalę szarości
- Prześlij przekonwertowany obraz do repozytorium GitHub
O ile mi wiadomo, nie ma możliwości przeprowadzenia takiej konwersji obrazów w całości w przeglądarce — a nawet gdyby tak było, jest to dość zasobochłonna czynność, więc prawdopodobnie nie chcemy obciążać naszych użytkowników ' urządzenia.
Zamiast tego możemy przesłać adres URL do przekonwertowania na funkcję bezserwerową, która wykona za nas ciężką pracę i odeśle adres URL do przekonwertowanego obrazu.
W przypadku naszej funkcji bezserwerowej będziemy używać funkcji Netlify. W kodzie naszej witryny dodajemy folder na poziomie głównym o nazwie „functions” i tworzymy w nim nowy plik o nazwie „convert-image.js”. Następnie piszemy coś, co nazywamy handler, czyli to, co odbiera i — jak można się domyślić — obsługuje żądania do naszej funkcji bezserwerowej.
Aby przekonwertować obraz, wygląda to tak:
exports.handler = async event => { // only try to handle POST requests if (event.httpMethod !== 'POST') { return { statusCode: 404, body: '404 Not Found' }; } try { // get the image URL from the POST submission const { imageURL } = JSON.parse(event.body); // use a temporary directory to avoid intermediate file cruft // see https://www.npmjs.com/package/tmp const tmpDir = tmp.dirSync(); const convertedPath = await convertToGrayscale(imageURL, tmpDir); // upload the processed image to GitHub const response = await uploadToGitHub(convertedPath, tmpDir.name); return { statusCode: 200, body: JSON.stringify({ url: response.data.content.download_url, }), }; } catch (error) { return { statusCode: 500, body: JSON.stringify(error.message), }; } };Ta funkcja wykonuje następujące czynności:
- Sprawdza, czy żądanie zostało wysłane przy użyciu metody HTTP POST
- Pobiera adres URL obrazu z treści POST
- Tworzy tymczasowy katalog do przechowywania plików, które zostaną wyczyszczone po wykonaniu funkcji
- Wywołuje funkcję pomocniczą, która konwertuje obraz do skali szarości
- Wywołuje funkcję pomocniczą, która przesyła przekonwertowany obraz do GitHub
- Zwraca obiekt odpowiedzi z kodem stanu HTTP 200 i adresem URL nowo przesłanego obrazu
Uwaga : nie będziemy omawiać, jak działa pomocnik do konwersji obrazów lub przesyłania do GitHub, ale kod źródłowy jest dobrze skomentowany, dzięki czemu można zobaczyć, jak to działa.
Następnie musimy dodać formularz, który będzie służył do zgłaszania adresów URL do przetworzenia oraz miejsce do pokazania przed i po:
<form action="/.netlify/functions/convert-image" method="POST" > <label for="imageURL">URL of an image to convert</label> <input type="url" name="imageURL" required /> <button type="submit">Convert</button> </form> <div></div>Na koniec musimy dodać do formularza detektor zdarzeń, abyśmy mogli wysłać adresy URL do naszej funkcji bezserwerowej w celu przetworzenia:
<script type="module"> import showResults from './show-results.js'; const form = document.querySelector('form'); form.addEventListener('submit', event => { event.preventDefault(); // get the image URL from the form const imageURL = form.elements['imageURL'].value; // send the image off for processing const promise = fetch('/.netlify/functions/convert-image', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ imageURL }), }) .then(result => result.json()) .catch(error => console.error(error)); // do the work to show the result on the page showResults(imageURL, promise); }); </script>Po wdrożeniu strony (wraz z jej nowym folderem „functions”) do Netlify i/lub uruchomieniu Netlify Dev w naszym CLI, w naszej przeglądarce możemy zobaczyć formularz:
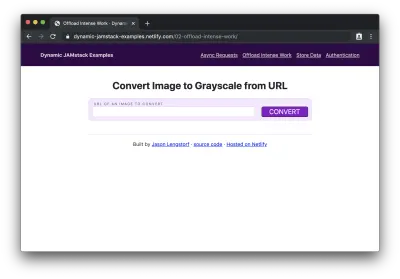
Jeśli dodamy adres URL obrazu do formularza i klikniemy „konwertuj”, zobaczymy przez chwilę „przetwarzanie…” podczas konwersji, a następnie zobaczymy oryginalny obraz i jego nowo utworzony odpowiednik w skali szarości:

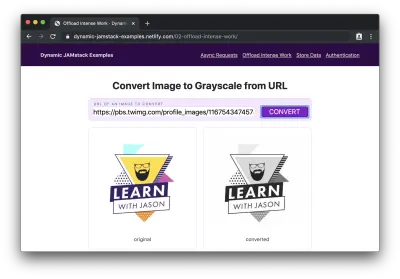
O cholera! Nasza strona JAMstack właśnie obsługiwała całkiem poważną sprawę i nie musieliśmy ani razu myśleć o serwerach ani rozładowywać baterii naszych użytkowników!
Użyj bazy danych do przechowywania i pobierania wpisów
W wielu aplikacjach nieuchronnie będziemy potrzebować możliwości zapisywania danych wprowadzanych przez użytkownika. A to oznacza, że potrzebujemy bazy danych.
Możesz myśleć: „Więc to jest to, prawda? Jig jest gotowy? Z pewnością witryna JAMstack — o której powiedziałeś nam, że jest tylko zbiorem plików w folderze — nie może być połączona z bazą danych!”
Przeciwnie.
Jak widzieliśmy w poprzedniej sekcji, funkcje bezserwerowe dają nam możliwość robienia wszelkiego rodzaju potężnych rzeczy bez konieczności tworzenia własnych serwerów.
Podobnie możemy użyć narzędzi bazy danych jako usługi (DBaaS) (takich jak Fauna) do odczytu i zapisu w bazie danych bez konieczności jej samodzielnego konfigurowania lub hostowania.
Narzędzia DBaaS znacznie upraszczają proces konfigurowania baz danych dla stron internetowych: tworzenie nowej bazy danych jest tak proste, jak zdefiniowanie typów danych, które chcemy przechowywać. Narzędzia automatycznie generują cały kod do zarządzania operacjami tworzenia, odczytu, aktualizacji i usuwania (CRUD) i udostępniają go do użycia za pośrednictwem interfejsu API, dzięki czemu nie musimy faktycznie zarządzać bazą danych; po prostu z niego korzystamy .
Demo: Utwórz stronę z petycją
Jeśli chcemy stworzyć małą aplikację do zbierania podpisów cyfrowych dla petycji, musimy skonfigurować bazę danych do przechowywania tych podpisów i umożliwienia stronie odczytania ich w celu wyświetlenia.
W tym demo użyjemy Fauny jako naszego dostawcy DBaaS. Nie będziemy zagłębiać się w sposób działania Fauny, ale w celu zademonstrowania niewielkiego wysiłku wymaganego do utworzenia bazy danych, wypiszmy każdy krok i kliknijmy, aby uzyskać gotową do użycia bazę danych:
- Załóż konto Fauna na https://fauna.com
- Kliknij „utwórz nową bazę danych”
- Nadaj bazie danych nazwę (np. „dynamic-jamstack-demos”)
- Kliknij „Utwórz”
- Kliknij „bezpieczeństwo” w menu po lewej stronie na następnej stronie
- Kliknij „nowy klucz”
- Zmień listę rozwijaną roli na „Serwer”
- Dodaj nazwę klucza (np. „Dynamic JAMstack Demos”)
- Przechowuj klucz w bezpiecznym miejscu do użytku z aplikacją
- Kliknij „zapisz”
- Kliknij „GraphQL” w menu po lewej stronie
- Kliknij „importuj schemat”
- Prześlij plik o nazwie
db-schema.gql, który zawiera następujący kod:
type Signature { name: String! } type Query { signatures: [Signature!]! }Po przesłaniu schematu nasza baza danych jest gotowa do użycia. (Na serio.)
Trzynaście kroków to dużo, ale dzięki tym trzynastu krokom otrzymaliśmy właśnie bazę danych, interfejs API GraphQL, automatyczne zarządzanie pojemnością, skalowanie, wdrażanie, zabezpieczenia i nie tylko — a wszystko to jest obsługiwane przez ekspertów od baz danych. Za darmo. Cóż za czas na życie!
Aby to wypróbować, opcja „GraphQL” w menu po lewej stronie daje nam eksplorator GraphQL z dokumentacją na temat dostępnych zapytań i mutacji, które pozwalają nam wykonywać operacje CRUD.
Uwaga : nie będziemy wchodzić w szczegóły dotyczące zapytań i mutacji GraphQL w tym poście, ale Eve Porcello napisała doskonałe wprowadzenie do wysyłania zapytań i mutacji GraphQL, jeśli chcesz dowiedzieć się, jak to działa.
Gdy baza danych jest gotowa do pracy, możemy stworzyć funkcję bezserwerową, która przechowuje nowe sygnatury w bazie danych:
const qs = require('querystring'); const graphql = require('./util/graphql'); exports.handler = async event => { try { // get the signature from the POST data const { signature } = qs.parse(event.body); const ADD_SIGNATURE = ` mutation($signature: String!) { createSignature(data: { name: $signature }) { _id } } `; // store the signature in the database await graphql(ADD_SIGNATURE, { signature }); // send people back to the petition page return { statusCode: 302, headers: { Location: '/03-store-data/', }, // body is unused in 3xx codes, but required in all function responses body: 'redirecting...', }; } catch (error) { return { statusCode: 500, body: JSON.stringify(error.message), }; } };Ta funkcja wykonuje następujące czynności:
- Pobiera wartość podpisu z formularza
POSTdata - Wywołuje funkcję pomocniczą, która przechowuje podpis w bazie danych
- Definiuje mutację GraphQL do zapisania w bazie danych
- Wysyła mutację za pomocą funkcji pomocniczej GraphQL
- Przekierowuje z powrotem do strony, która przesłała dane
Następnie potrzebujemy funkcji bezserwerowej, aby odczytać wszystkie podpisy z bazy danych, abyśmy mogli pokazać, ile osób popiera naszą petycję:
const graphql = require('./util/graphql'); exports.handler = async () => { const { signatures } = await graphql(` query { signatures { data { name } } } `); return { statusCode: 200, body: JSON.stringify(signatures.data), }; };Ta funkcja wysyła zapytanie i zwraca je.
Ważna uwaga na temat wrażliwych klawiszy i aplikacji JAMstack :
Należy zwrócić uwagę na to, że do wykonywania tych połączeń używamy funkcji bezserwerowych, ponieważ musimy przekazać Faunie prywatny klucz serwera, który dowodzi, że mamy dostęp do tej bazy danych w trybie odczytu i zapisu. Nie możemy umieścić tego klucza w kodzie po stronie klienta, ponieważ oznaczałoby to, że każdy mógłby go znaleźć w kodzie źródłowym i użyć go do wykonania operacji CRUD na naszej bazie danych. Funkcje bezserwerowe mają kluczowe znaczenie dla zachowania prywatności kluczy prywatnych w aplikacjach JAMstack.
Po skonfigurowaniu naszych funkcji bezserwerowych możemy dodać formularz, który przesyła do funkcji w celu dodania podpisu, element do pokazania istniejących podpisów i trochę JS do wywołania funkcji w celu pobrania podpisów i umieszczenia ich na naszym ekranie element:
<form action="/.netlify/functions/add-signature" method="POST"> <label for="signature">Your name</label> <input type="text" name="signature" required /> <button type="submit">Sign</button> </form> <ul class="signatures"></ul> <script> fetch('/.netlify/functions/get-signatures') .then(res => res.json()) .then(names => { const signatures = document.querySelector('.signatures'); names.forEach(({ name }) => { const li = document.createElement('li'); li.innerText = name; signatures.appendChild(li); }); }); </script>Jeśli załadujemy to w przeglądarce, zobaczymy nasz formularz petycji z podpisami pod nim:
Następnie, jeśli dodamy nasz podpis…
…i prześlij go, zobaczymy nasze imię i nazwisko na dole listy:
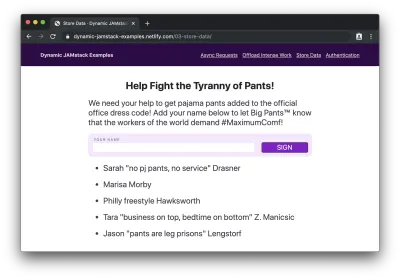
Gorący piesek! Właśnie napisaliśmy w pełni opartą na bazie danych aplikację JAMstack z około 75 wierszami kodu i 7 wierszami schematu bazy danych!
Chroń zawartość za pomocą uwierzytelniania użytkownika
„W porządku, tym razem na pewno utknąłeś” — możesz pomyśleć. „Nie ma możliwości , aby witryna JAMstack obsługiwała uwierzytelnianie użytkowników. Jak u diabła by to zadziałało, nawet?!”
Opowiem ci , jak to działa, przyjacielu: dzięki naszym zaufanym funkcjom bezserwerowym i OAuth.
OAuth to powszechnie przyjęty standard umożliwiający użytkownikom udzielanie aplikacjom ograniczonego dostępu do informacji o koncie zamiast udostępniania haseł. Jeśli kiedykolwiek logowałeś się do usługi przy użyciu innej usługi (na przykład „zaloguj się na swoje konto Google”), to już wcześniej używałeś OAuth.
Uwaga: nie będziemy zagłębiać się w sposób działania OAuth, ale Aaron Parecki napisał solidny przegląd OAuth, który obejmuje szczegóły i przepływ pracy.
W aplikacjach JAMstack możemy korzystać z OAuth i tokenów JSON Web Tokens (JWT), które zapewnia nam do identyfikacji użytkowników, ochrony treści i zezwalania na jej przeglądanie tylko zalogowanym użytkownikom.
Demo: Wymagaj logowania, aby wyświetlić chronioną zawartość
Jeśli potrzebujemy zbudować witrynę, która wyświetla treści tylko zalogowanym użytkownikom, potrzebujemy kilku rzeczy:
- Dostawca tożsamości, który zarządza użytkownikami i przepływem logowania
- Elementy interfejsu użytkownika do zarządzania logowaniem i wylogowaniem
- Funkcja bezserwerowa, która sprawdza zalogowanego użytkownika za pomocą tokenów JWT i zwraca chronioną zawartość, jeśli jest dostępna
W tym przykładzie użyjemy Netlify Identity, co zapewni nam naprawdę przyjemne wrażenia programistyczne do dodawania uwierzytelniania i zapewnia widżet drop-in do zarządzania działaniami logowania i wylogowania.
Aby to włączyć:
- Odwiedź swój pulpit nawigacyjny Netlify
- Wybierz witrynę, która wymaga uwierzytelnienia, z listy witryn
- Kliknij „tożsamość” w górnym panelu nawigacyjnym
- Kliknij przycisk „Włącz tożsamość”
Możemy dodać Netlify Identity do naszej strony poprzez dodanie znacznika, który pokazuje wylogowaną treść oraz dodaje element do pokazywania treści chronionych po zalogowaniu:
<div class="content logged-out"> <h1>Super Secret Stuff!</h1> <p> only my bestest friends can see this content</p> <button class="login">log in / sign up to be my best friend</button> </div> <div class="content logged-in"> <div class="secret-stuff"></div> <button class="logout">log out</button> </div>Ten znacznik opiera się na CSS, aby wyświetlać zawartość w zależności od tego, czy użytkownik jest zalogowany, czy nie. Jednak nie możemy na tym polegać, aby faktycznie chronić zawartość — każdy może wyświetlić kod źródłowy i ukraść nasze sekrety!
Zamiast tego utworzyliśmy pusty element div, który będzie zawierał naszą chronioną zawartość, ale musimy wysłać żądanie do funkcji bezserwerowej, aby faktycznie pobrać tę zawartość. Wkrótce zastanowimy się, jak to działa.
Następnie musimy dodać kod, aby nasz przycisk logowania działał, załadować chronioną zawartość i pokazać ją na ekranie:
<script src="https://identity.netlify.com/v1/netlify-identity-widget.js"></script> <script> const login = document.querySelector('.login'); login.addEventListener('click', () => { netlifyIdentity.open(); }); const logout = document.querySelector('.logout'); logout.addEventListener('click', () => { netlifyIdentity.logout(); }); netlifyIdentity.on('logout', () => { document.querySelector('body').classList.remove('authenticated'); }); netlifyIdentity.on('login', async () => { document.querySelector('body').classList.add('authenticated'); const token = await netlifyIdentity.currentUser().jwt(); const response = await fetch('/.netlify/functions/get-secret-content', { headers: { Authorization: `Bearer ${token}`, }, }).then(res => res.text()); document.querySelector('.secret-stuff').innerHTML = response; }); </script>Oto, co robi ten kod:
- Ładuje widżet Netlify Identity, który jest biblioteką pomocniczą, która tworzy modalne logowanie, obsługuje przepływ pracy OAuth za pomocą Netlify Identity i daje naszej aplikacji dostęp do informacji zalogowanego użytkownika
- Dodaje detektor zdarzeń do przycisku logowania, który uruchamia modalne logowanie Netlify Identity do otwarcia
- Dodaje detektor zdarzeń do przycisku wylogowania, który wywołuje metodę wylogowania Netlify Identity
- Dodaje procedurę obsługi zdarzeń do wylogowania, aby usunąć uwierzytelnioną klasę po wylogowaniu, która ukrywa zawartość zalogowanego użytkownika i pokazuje zawartość wylogowanego
- Dodaje procedurę obsługi zdarzeń do logowania, która:
- Dodaje uwierzytelnioną klasę, aby pokazać zawartość po zalogowaniu i ukryć zawartość po wylogowaniu
- Pobiera JWT zalogowanego użytkownika
- Wywołuje funkcję bezserwerową w celu załadowania chronionej zawartości, wysyłając token JWT w nagłówku autoryzacji
- Umieszcza tajną zawartość w div z tajnymi rzeczami, aby zalogowani użytkownicy mogli ją zobaczyć
W tej chwili funkcja bezserwerowa, którą wywołujemy w tym kodzie, nie istnieje. Stwórzmy go następującym kodem:
exports.handler = async (_event, context) => { try { const { user } = context.clientContext; if (!user) throw new Error('Not Authorized'); return { statusCode: 200, headers: { 'Content-Type': 'text/html', }, body: `Masz zaproszenie, ${user.user_metadata.full_name}!
Jeśli możesz to przeczytać, oznacza to, że jesteśmy najlepszymi przyjaciółmi.
Oto sekretne szczegóły mojego przyjęcia urodzinowego:
`, }; } złapać (błąd) { powrót { kod statusu: 401, treść: 'Brak Autoryzacji', }; } };
jason.af/party
Ta funkcja wykonuje następujące czynności:
- Sprawdza użytkownika w argumencie kontekstu funkcji bezserwerowej
- Zgłasza błąd, jeśli nie znaleziono użytkownika
- Zwraca tajną zawartość po upewnieniu się, że zalogowany użytkownik o to poprosił
Netlify Functions wykryje tokeny JWT Netlify Identity w nagłówkach autoryzacji i automatycznie umieści te informacje w kontekście — oznacza to, że możemy sprawdzić prawidłowe tokeny JWT bez konieczności pisania kodu w celu walidacji tokenów JWT!
Gdy załadujemy tę stronę w naszej przeglądarce, najpierw zobaczymy stronę wylogowania:
Jeśli klikniemy przycisk, aby się zalogować, zobaczymy widżet Netlify Identity:
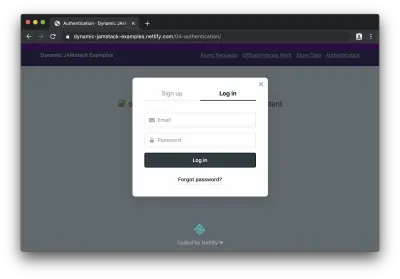
Po zalogowaniu (lub zarejestrowaniu się) widzimy chronioną treść:
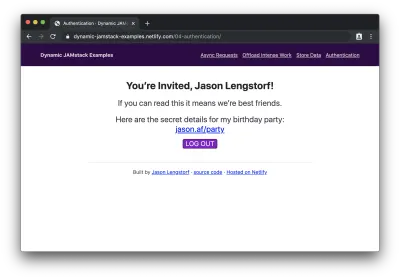
Oooo! Właśnie dodaliśmy login użytkownika i chronione treści do aplikacji JAMstack!
Co zrobic nastepnie
JAMstack to znacznie więcej niż „tylko statyczne witryny” — możemy reagować na interakcje użytkowników, przechowywać dane, obsługiwać uwierzytelnianie użytkowników i prawie wszystko, co chcemy robić na nowoczesnej stronie internetowej. A wszystko to bez potrzeby udostępniania, konfigurowania lub wdrażania serwera!
Co chcesz zbudować za pomocą JAMstack? Czy jest coś, z czym nadal nie jesteś przekonany, że JAMstack poradzi sobie? Bardzo chciałbym o tym usłyszeć — napisz do mnie na Twitterze lub w komentarzach!