
Programowanie dla sieci semantycznej
Opublikowany: 2022-03-10W lipcu Fundacja Wikimedia ogłosiła Abstract Wikipedia, próbę oznaczenia wiedzy niezależnej od języka. Pod wieloma względami jest to kulminacja dziesięcioleci budowania, podczas których marzenie o sieci semantycznej nigdy nie wystartowało, ale też nigdy nie zniknęło.
W rzeczywistości sieć semantyczna rozwija się, a ponieważ odnawia swoją misję, wszyscy możemy zyskać na wprowadzaniu znaczników semantycznych do naszych stron internetowych, czy to osobistych blogów, czy gigantów mediów społecznościowych. Niezależnie od tego, czy zależy Ci na wyrafinowanych doświadczeniach internetowych, SEO, czy odpieraniu tyranii monopoli internetowych, Sieć Semantyczna zasługuje na naszą uwagę.
Korzyści płynące z tworzenia sieci semantycznej nie zawsze są natychmiastowe lub widoczne, ale każda witryna, która to robi, wzmacnia fundamenty otwartego, przejrzystego i zdecentralizowanego internetu.
Sieć semantyczna
Czym dokładnie jest sieć semantyczna? Jest to sieć do odczytu maszynowego, zapewniająca za pośrednictwem metadanych „wspólną strukturę, która umożliwia udostępnianie i ponowne wykorzystywanie danych w aplikacjach, przedsiębiorstwach i społecznościach”.
Pomysł jest tak stary, jak sama sieć WWW. W rzeczywistości starszy. Był to centralny punkt propozycji Tima Bernersa-Lee z 1989 roku. Jak podkreślił, nie tylko dokumenty powinny tworzyć sieci, ale także dane w nich zawarte powinny:
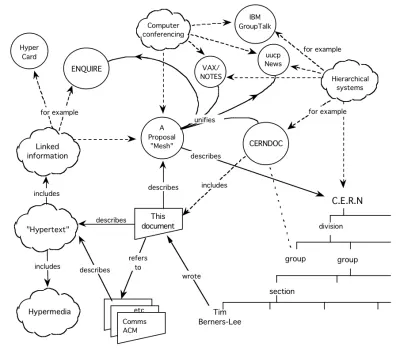
Sieć semantyczna kroczyła wyboistą drogą w ostatnich dziesięcioleciach. Od przełomu tysiącleci przekształcił się w wiele koncepcji — otwarte dane, wykresy wiedzy — wszystkie w praktyce oznaczają to samo: sieci danych.
Jak podsumowuje W3C, jest to „rozszerzenie obecnej sieci, w której informacje mają dobrze zdefiniowane znaczenie, lepiej umożliwiające komputerom i ludziom współpracę”.

Pomysł zyskał uczciwy udział zwolenników. Haktywista internetowy, Aaron Swartz, napisał rękopis książki o sieci semantycznej zatytułowany A Programmable Web . Napisał w nim:
„Dokumentów tak naprawdę nie można łączyć, integrować i przeszukiwać; służą głównie jako pojedyncze przypadki, które należy przeglądać i recenzować. Ale dane są proste i mogą przybrać dowolny kształt, który najlepiej odpowiada Twoim potrzebom”.
Z różnych powodów sieć semantyczna nie wystartowała w taki sam sposób, jak sieć, chociaż nadrabia zaległości. Przez lata kilka znaczników próbowało przejąć kontrolę — RDFa, OWL i Schema, żeby wymienić tylko kilka — chociaż żaden nie stał się standardem w taki sposób, jak, powiedzmy, HTML czy CSS. Bariera wejścia była zbyt wysoka.
Jednak marzenie o sieci semantycznej przetrwało, a ponieważ coraz więcej witryn włącza ją do swoich projektów, jest jeszcze więcej powodów, aby dołączyć do imprezy. Im więcej witryn wchodzi na pokład, tym silniejsza staje się sieć semantyczna.
Dalsza lektura
- Analiza danych
- The Semantic Web, artykuł Tima Bernersa-Lee, Jamesa Hensleya i Ory Lassili z 2001 roku
- Wiarygodna grupa społeczności internetowej w W3C
Wiedza bez granic
Zanim przejdziemy do chwastów projektowania dla sieci semantycznej, warto zagłębić się w przyczynę . Jakie to ma znaczenie, czy dane są połączone? Czy połączone dokumenty nie są wystarczające?
Istnieje kilka powodów, dla których Sieć Semantyczna jest nadal forsowana przez tych, którym zależy na wolnym i otwartym Internecie. Zrozumienie tych powodów jest niezbędne w procesie wdrażania. Nie powinien to być przypadek „jedz warzywa, używaj znaczników semantycznych”. Sieć semantyczna to coś, w co można wierzyć i być częścią.
Korzyści z sieci semantycznej obejmują:
- Bogatsze, bardziej wyrafinowane doświadczenia internetowe
- Omijanie silosów treści i monopoli internetowych
- Poprawiona czytelność i rankingi wyszukiwarek
- Demokratyzacja informacji
Większość z nich można wywieść z podstawowej zasady sieci semantycznej: uniwersalnego języka danych. Chociaż internet zdziałał już cuda w komunikacji międzynarodowej, nie da się uniknąć faktu, że niektóre kraje mają go znacznie lepiej niż inne. Weźmy na przykład języki używane w Internecie i języki używane w świecie rzeczywistym. Sokoleoki wśród was może dostrzec niewielką nierównowagę w danych poniżej…
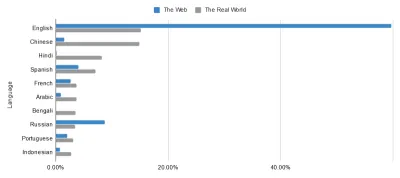
Bezgraniczna utopia sieci nie jest tak bliska, jak mogłoby się wydawać tym z nas wewnątrz anglojęzycznej bańki. Czy to jest coś, za co można kogoś karać? Niekoniecznie, ale trzeba się z tym zmierzyć. Takie postępowanie podkreśla znaczenie znaczników, które wypełniają te luki. Wzbogacając dane w sieci, odciążamy jej języki.
To jest sedno niedawno ogłoszonej Wikipedii Abstract, która będzie próbowała oddzielić artykuły od języka, w jakim zostały napisane. Dyrektor Wykonawcza Wikimedia, Katherine Maher, pisze: „Korzystając z kodu, wolontariusze będą mogli przetłumaczyć te abstrakcyjne 'artykuły' na własnymi językami. Jeśli się powiedzie, może to w końcu umożliwić wszystkim czytanie na dowolny temat w Wikidanych w swoim własnym języku”.
Streszczenie Twórca Wikipedii, Denny Vrandecic, od lat jest zwolennikiem sieci semantycznej, dostrzegając jej potencjał do uwolnienia niewykorzystanego potencjału online. W tym procesie zasadnicze znaczenie ma przełamanie barier krajowych.
„Bez względu na to, w jakim języku publikujesz swoje treści, przegapisz włączenie ogromnej większości ludzi na świecie. Sieć dała nam wspaniałą okazję do osiągnięcia globalnego zasięgu — ale opierając się na jednym języku lub małym zestawie języków, marnujemy tę szansę. Chociaż najważniejszym celem jest przede wszystkim tworzenie dobrych treści, zachęcasz więcej osób do udziału w tworzeniu lepszych treści poprzez bycie niezależnym od języka. Pomaga obniżyć bariery dla wkładu i konsumpcji, a także pozwala znacznie większej liczbie osób czerpać korzyści z tego wysiłku”.
— Denny Vrandecic, twórca abstrakcyjnej Wikipedii
Przykładem na to jest wizualizacja danych podczas pandemii COVID-19. Wirus wywołał niewyobrażalne spustoszenie na całym świecie, ale był także świetnym momentem dla otwartych sieci danych, umożliwiając udostępnianie doskonałych aplikacji internetowych, raportów i innych w całej sieci.
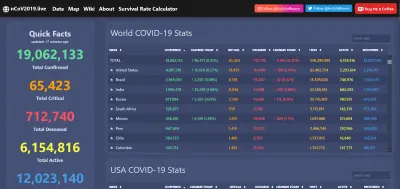
Oczywiście, gdy dane są przejrzyste i łatwo dostępne, łatwiej jest zidentyfikować anomalie… lub po prostu oszustwo. Powszechny publiczny dostęp do powyższych informacji byłby nie do pomyślenia nawet 20 lat temu. Teraz tego oczekujemy i czujemy szczura, kiedy nam go odmówiono. Dane są potężne i jeśli chcemy, można nimi zawładnąć na dobre.
Podobnie, sprawdzanie się z silosów treści — cecha charakterystyczna współczesnego korzystania z Internetu — odbiera władzę monopolistom internetowym, takim jak Google, Facebook i Twitter. Jesteśmy tak przyzwyczajeni do odszyfrowywania i prezentowania informacji przez zewnętrzne platformy, że zapominamy, że nie są one bezwzględnie konieczne.
„Gdybyśmy mieli współdzielone formaty, współdzielone protokoły, nadal moglibyśmy skończyć z niektórymi dostawcami odgrywającymi dużą rolę na niektórych rynkach – pomyśl o Gmailu dla poczty e-mail – ale każdy może przejść do innego dostawcy, a rynek pozostaje konkurencyjny”.
— Denny Vrandecic, twórca abstrakcyjnej Wikipedii
Sieć semantyczna jest pozbawiona silosów; jest bezpłatny, otwarty i abstrakcyjny, umożliwiając komunikację między różnymi językami i platformami, która w innym przypadku byłaby o wiele trudniejsza.
Treści internetowe do przetwarzania danych
Projektowanie dla sieci semantycznej sprowadza się do przetwarzania danych online — patrzenia na treść i sprawdzania, co można (i należy) wyabstrahować. Co to oznacza w praktyce, poza niejasną zgodą, że warto to zrobić? To zależy:
- Jeśli zaczynasz projekt od zera, uwzględnij w tym, co robisz, kwestie związane z siecią semantyczną. Gdy witryna nabiera kształtu, wpleć znaczniki semantyczne w jej DNA.
- Jeśli aktualizujesz lub przebudowujesz projekt, oceń, co można by wpleść w sieć semantyczną, a czego obecnie nie ma, a następnie zaimplementuj.
Oba przypadki w zasadzie sprowadzają się do treści zawierających dane. W tej sekcji omówimy kilka przykładów abstrakcji danych i tego, jak może ona sprawić, że treść będzie lepsza, inteligentniejsza i szerzej dostępna.
Abstrakcyjne informacje
Projektowanie i rozwijanie dla sieci semantycznej oznacza przeglądanie treści online pod kątem danych. Większość z nas postrzega sieć jako serię łączących się dokumentów lub stron; to, co chcesz zrobić z siecią semantyczną, to informacje o połączeniu. Oznacza to ocenę treści pod kątem punktów danych, a następnie dostosowanie projektu na podstawie znalezionych informacji.
Adwokat sieci semantycznej, James Hendler, szczególnie dobrze opisuje ten proces, przedstawiając swój etos DIVE. ( ZANURZ SIĘ w danych, co? Ech?). Rozkłada się w następujący sposób:
- Odkryć
Znajdź zbiory danych i/lub treści (w tym poza własną organizacją). - Zintegrować
Połącz relacje za pomocą znaczących etykiet. - Uprawomocnić
Dostarczanie danych wejściowych do systemów modelowania i symulacji. - Badać
Opracuj metody przekształcania danych w praktyczną wiedzę.
Programowanie dla sieci semantycznej polega w dużej mierze na tym, aby mieć widok z lotu ptaka na to, co robisz, i to, w jaki sposób potencjalnie wpływa to na nieskończenie bogatsze doświadczenia internetowe. Jak mówi Hendler, celem jest wiedza, którą można wykorzystać.
To naprawdę można zastosować do prawie każdego rodzaju treści internetowych, ale zacznijmy od typowego przykładu: przepisów . Załóżmy, że prowadzisz bloga kulinarnego, na którym w każdy czwartek znajdziesz nowe przepisy. Jeśli jesteś Francuzem i opublikujesz na swoim osobistym blogu wspaniały przepis na suflet, przyda się on tylko tym, którzy potrafią czytać po francusku.
Jednak dzięki wdrożeniu znaczników semantycznych blog może zostać przekształcony w zestaw danych receptury do odczytu maszynowego. Istnieje składnia do abstrahowania terminów gotowania. Na przykład schemat, który może współpracować z Microdata, RDFa lub JSON-LD, ma znaczniki, w tym:
- czas przygotowania
- czas gotowania
- przepisWydajność
- przepisSkładnik
- Szacowany koszt
- odżywianie, rozkładanie na kalorie i tłuszczZawartość
- odpowiedni dla diety.
Mogę iść dalej. Pełną gamę opcji wraz z przykładami można znaleźć na Schema.org. Dodając je do formatu posta, format przepisu wcale nie musi się zmieniać — po prostu umieszczasz informacje w terminach zrozumiałych dla komputerów.

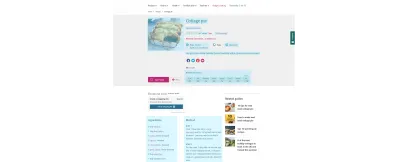
Na przykład wszystko, co zostało zaznaczone na niebiesko w powyższym przepisie BBC, otrzymało również znaczniki semantyczne — od czasu gotowania po wartości odżywcze. Możesz zobaczyć, co dzieje się pod maską, wprowadzając adres URL przepisu do testu wyników rozszerzonych Google. Zwróć uwagę na funkcjonalność „Dodaj do listy zakupów”, przykład połączenia możliwego dzięki implementacji Semantic Web. Dobra treść staje się użytecznymi danymi.
Większość z nas skrzyżowała ścieżki z tego rodzaju wyrafinowaniem poprzez wyniki wyszukiwania, ale aplikacje są znacznie szersze. Znaczniki semantyczne przepisów ułatwiają znajdowanie stron internetowych i korzystanie z nich przez pomoc domową. Wymienione składniki można zamówić w lokalnym supermarkecie. Przepisy można filtrować na różne sposoby — pod kątem diety, alergii, religii, kosztów, co tylko chcesz. Albo powiedzmy, że masz w domu ograniczoną liczbę składników. Dzięki bazie danych możesz wprowadzić te składniki i zobaczyć, jakie przepisy pasują do rachunku.
Wachlarz możliwości naprawdę graniczy z nieograniczonym. Jak powiedział Swartz, dane są protean. Kiedy już go masz, możesz go używać na różne dziwne i cudowne sposoby. W tym artykule nie chodzi o te dziwne i cudowne sposoby, ale o umożliwienie ich. Projektowanie dla sieci semantycznej sprawia, że późniejsze projektowanie staje się nieskończenie bogatsze.
Oto bardziej osobisty przykład, aby pokazać, o co mi chodzi. Jako hobby prowadzę z parą przyjaciół mały muzyczny webzine. Chociaż publikujemy dziwny artykuł lub wywiad, „głównym wydarzeniem” są nasze cotygodniowe recenzje albumów, w których każda z nas troje przypisuje ocenę, wybiera ulubione utwory i pisze streszczenia. Działamy już od ponad pięciu lat, co oznacza, że mamy blisko 250 recenzji, co oznacza strasznie dużo potencjalnych danych. Nie zdawaliśmy sobie sprawy z tego, dopóki nie zaczęliśmy przebudowywać strony.
Dotknąłem tego w artykule o wpalaniu uporządkowanych danych w procesie projektowania. Analizując nasze recenzje, zdaliśmy sobie sprawę, że są one pełne informacji, którym można nadać semantyczne znaczniki. Wykonawcy, nazwy albumów, okładka, data wydania, indywidualne wyniki, ogólne wyniki, typ wydania i inne. Co więcej — i tutaj robi się naprawdę ekscytująco — zdaliśmy sobie sprawę, że możemy połączyć się z istniejącą bazą danych: MusicBrainz.
To dwukierunkowe podejście jest sednem sieci semantycznej. Po ponownym uruchomieniu naszej muzycznej witryny internetowej będzie ona własnym otwartym źródłem danych z tysiącami unikalnych punktów danych. Połączenie z istniejącą muzyczną bazą danych zapewni naszym własnym danym więcej kontekstu — i potencjał. Tysiące punktów danych staje się dziesiątkami tysięcy punktów danych, może więcej.
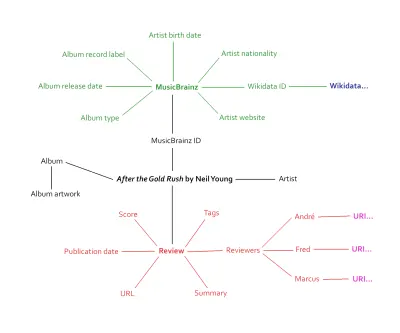
Powyższa grafika tylko zarysowuje powierzchnię tego, ile informacji będzie połączonych ze stronami z recenzjami. Treść jest taka sama jak wcześniej, tylko teraz jest podłączona do ekosystemu metadanych — Giant Global Graph, jak kiedyś nazwał go Berners-Lee.
Programowanie dla sieci semantycznej oznacza identyfikowanie własnych danych, oznaczanie ich, a następnie sprawdzanie, w jaki sposób łączą się z innymi danymi. Ponieważ tak. Zawsze tak jest. I ten proces polega na tym, że…
… z czasem staje się to…
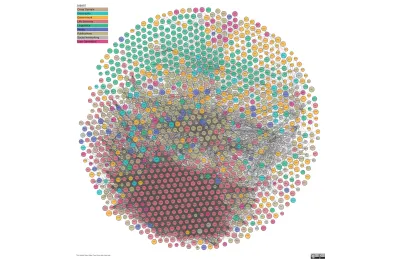
Drugi obraz to The Linked Open Data Cloud, stale aktualizowana wizualizacja połączonych danych w sieci. Ten czerwony ul połączeń to nauki; reszta ma jeszcze do zrobienia. I tu wchodzimy.
Przydatne zasoby sieci semantycznej
- RDF na w3schools.com
- Walidator RDF W3C
- „Sieć semantyczna stała się łatwa” autorstwa W3C
- „Co się stało z siecią semantyczną?” przez historię dwubitową
- Generator JSON-LD
- Pomocnik Google do oznaczania danych strukturalnych
Podłączanie
Ideałem Sieci Semantycznej jest połączenie. Twórz dane, udostępniaj dane, żądaj danych. Bądź częścią ekosystemu informacyjnego. Świetnie, gdy tworzysz oryginalne dane. Udostępnij to. Gdy dane już istnieją i chcesz ich użyć, pobierz je.
Oto tylko garść dostępnych zasobów danych:
- DPpedia
- MusicBrainz
- ŚwiatKot
- ISBNdb
Rzeczywiście, tam, gdzie istnieją takie bazy danych, posunąłbym się do stwierdzenia, że właściwą rzeczą byłoby zaktualizowanie ich tam, gdzie brakuje im informacji. Po co trzymać to dla siebie? Zostań współtwórcą, adwokatem Semantic Web.
Realizacja
Jeśli chodzi o budowanie sieci semantycznej w twoich witrynach, z pewnością nie popieram ręcznego oznaczania dokument po dokumencie. Kto ma na to czas? Najczęściej rozwiązaniem jest standaryzacja formatu i tworzenie dla niego szablonów.
Tworzenie szablonów to tutaj wielka szansa. Ile osób naprawdę ma czas na ręczne oznaczenie wszystkich tych informacji? Jeśli jednak masz niestandardowe dane wejściowe, uzyskasz to, co najlepsze z obu światów. Treść może być wypełniona informacjami przyjaznymi dla ludzi, a informacje istnieją jako dane gotowe do wykorzystania w dowolnym celu, który przyjdzie do głowy.
Weźmy na przykład statyczny generator witryn, taki jak Eleveny, który ostatnio cieszy się trochę miłością społeczności programistów. Piszesz post, przepuszczasz go przez szablon i jesteś złoty. Dlaczego więc nie włączyć znaczników semantycznych do samego szablonu?
Podobnie jak Eleveny, nowa wersja naszego muzycznego webzine'u wykorzystuje Markdown do swoich postów. Chociaż mamy te same stare posty tekstowe, które zawsze tworzyliśmy, każda recenzja zawiera teraz również następujące dane wejściowe metadanych, które są następnie wciągane do szablonu:
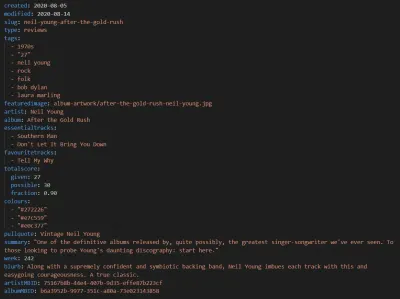
Wraz ze szczegółami autora w treści posta i pewnymi ogólnymi informacjami o witrynie internetowej przekłada się to na następujący znacznik semantyczny:
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "One of the definitive albums released by, quite possibly, the greatest singer-songwriter we've ever seen. To those looking to probe Young's daunting discography: start here.", "datePublished": "2020-08-14", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "name": "After the Gold Rush", "@id": "https://musicbrainz.org/release-group/b6a3952b-9977-351c-a80a-73e023143858", "image": "https://audioxide.com/images/album-artwork/after-the-gold-rush-neil-young.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "byArtist": { "@type": "MusicGroup", "name": "Neil Young", "@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf" } }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 }, "publisher": { "@type": "Organization", "name": "Audioxide", "description": "Independent music webzine founded in 2015. Publishes reviews, articles, interviews, and other oddities.", "url": "https://audioxide.com", "logo": "https://audioxide.com/logo-location.jpg", "sameAs" : [ "https://facebook.com/audioxide", "https://twitter.com/audioxide", "https://instagram.com/audioxidecom" ] } } </script>Tam, gdzie wcześniej był tylko tekst, na każdej stronie z recenzjami będą teraz również dostępne do odczytu maszynowego wersje tego, co widzą czytelnicy odwiedzający witrynę. Wszystkie słowa wciąż tam są, treść prawie się nie zmieniła — po prostu została oparta na danych. Od rozbudowanych wyników wyszukiwania po interaktywne strony ze statystykami recenzji, znacznie zwiększa to, co jest możliwe. Droga przed nami jest szeroka i otwarta. Daje nam również udział w przyszłości MusicBrainz. Łącząc ich dane z naszymi własnymi, chcemy z kolei zobaczyć, jak działa dobrze i zrobimy wszystko, aby to zapewnić.
Odpowiednie znaczniki semantyczne zależą od charakteru witryny, ale są szanse, że istnieje. Zacznij od oczywistych danych wejściowych (data, autor, typ treści itp.) i przejdź przez chwasty treści. Pierwszy krok może być tak prosty, jak hCard (rodzaj cyfrowej karty identyfikacyjnej) dla Twojej osobistej strony internetowej. Wydrukuj zrzuty ekranu stron i zacznij dodawać adnotacje. Zdziwisz się, ile treści można wprowadzić do danych.
Poza wyobraźnią
Projektowanie i rozwijanie dla sieci semantycznej to praktyka wywodząca się z ideałów założycielskich Internetu. Niezależnie od tego, czy cenisz sobie piękną, pouczającą wizualizację danych, potrzebujesz bardziej wyrafinowanych wyników wyszukiwania, chcesz usunąć władzę z monopoli internetowych, czy po prostu wierzysz w darmowe i otwarte informacje, Sieć Semantyczna jest Twoim sprzymierzeńcem.
Aaron Swartz zamknął swój rękopis wezwaniem do nadziei:
„Sieć semantyczna opiera się na zakładzie, założeniu, że udostępnienie światu narzędzi do łatwej współpracy i komunikacji doprowadzi do tak wspaniałych możliwości, że ledwo możemy je sobie teraz wyobrazić”.
Streszczenie Wikipedia Denny Vrandecic podziela te odczucia dzisiaj, mówiąc:
„Istnieje potrzeba infrastruktury sieciowej, która ułatwi interoperacyjność między usługami, co wymaga wspólnego zestawu standardów reprezentacji danych i wspólnych protokołów u dostawców”.
Sieć semantyczna utykała na tyle długo, aby było jasne, że język srebrnego punktu jest mało prawdopodobny, ale jest ich już wystarczająco dużo, by pokojowo współistnieć, by marzenie Bernersa-Lee mogło stać się rzeczywistością dla większości sieci. Każdy z nas może być adwokatem w swoim sąsiedztwie.
Bądź lepszy, żądaj lepszego
Jak powiedział Tim Berners-Lee, sieć semantyczna jest zarówno kulturą, jak i przeszkodą techniczną. W 2009 TED Talk podsumował to ładnie: twórz połączone dane, żądaj powiązanych danych . Teraz jest to prawdziwsze niż kiedykolwiek. Sieć WWW jest tak otwarta, połączona i dobra, jak my do tego zmuszamy. Za każdym razem, gdy tworzysz coś online, zadaj sobie pytanie: „Jak można to podłączyć do sieci semantycznej?” Odpowiedzi nadadzą nowy wymiar tworzonym przez nas rzeczom i stworzą niewyobrażalnie wspaniałe nowe możliwości na nadchodzące lata.