
Wizualizacja danych w Pythonie: podstawowe wykresy wyjaśnione [z ilustracją graficzną]
Opublikowany: 2021-02-08Spis treści
Podstawowe zasady projektowania
Dla każdego aspirującego lub odnoszącego sukcesy naukowca danych umiejętność wyjaśnienia swoich badań i analiz jest bardzo ważną i przydatną umiejętnością. W tym miejscu pojawia się wizualizacja danych. Uczciwe korzystanie z tego narzędzia jest bardzo ważne, ponieważ odbiorca może łatwo zostać wprowadzony w błąd lub zwiedziony przez złe wybory projektowe.
Jako badacze danych wszyscy mamy pewne obowiązki w kwestii zachowania prawdy.
Po pierwsze, podczas czyszczenia i podsumowywania danych powinniśmy być całkowicie szczerzy wobec siebie. Wstępne przetwarzanie danych jest bardzo ważnym etapem działania każdego algorytmu uczenia maszynowego, więc każda nieuczciwość w danych doprowadzi do drastycznie odmiennych wyników.
Kolejny obowiązek dotyczy naszej grupy docelowej. Istnieją różne techniki wizualizacji danych, które służą do wyróżnienia określonych sekcji danych i zmniejszenia widoczności innych fragmentów danych. Jeśli więc nie będziemy wystarczająco ostrożni, czytelnik nie będzie w stanie właściwie zbadać i ocenić analizy, co może prowadzić do wątpliwości i braku zaufania.
Ciągłe zadawanie sobie pytań jest dobrą cechą dla naukowców zajmujących się danymi. I zawsze powinniśmy pomyśleć o tym, jak w zrozumiały i estetyczny sposób pokazać to, co naprawdę jest ważne, pamiętając jednocześnie, że ważny jest kontekst.
To jest dokładnie to, co Alberto Cairo stara się przedstawić w swoich naukach. Wspomina o pięciu cechach wspaniałych wizualizacji: pięknych, pouczających, funkcjonalnych, wnikliwych i prawdziwych , o których warto pamiętać.
Niektóre podstawowe wątki
Teraz, gdy mamy podstawową wiedzę na temat zasad projektowania, zagłębmy się w kilka podstawowych technik wizualizacji przy użyciu biblioteki matplotlib w pythonie.
Cały poniższy kod można wykonać w notatniku Jupyter.
%notplotlib notatnik
# to zapewnia interaktywne środowisko i ustawia zaplecze. ( %matplotlib inline może być również użyty, ale nie jest interaktywny. Oznacza to, że dalsze wywołania funkcji kreślenia nie będą automatycznie aktualizować naszej oryginalnej wizualizacji.)
import matplotlib.pyplot jako plt # importowanie wymaganego modułu biblioteki
Wykresy punktowe
Najprostszą funkcją matplotlib do wykreślania punktu jest plot() . Argumenty reprezentują współrzędne X i Y, a następnie wartość ciągu opisującą sposób wyświetlania danych wyjściowych.
pl.figura()
plt.plot( 5, 6, '+' ) # znak + działa jak znacznik
Wykresy punktowe
Wykres rozrzutu to wykres dwuwymiarowy. Funkcja scatter() również przyjmuje wartość X jako pierwszy argument i wartość Y jako drugi. Poniższy wykres jest linią ukośną, a matplotlib automatycznie dostosowuje rozmiar obu osi. Tutaj wykres punktowy nie traktuje pozycji jako serii. Możemy więc podać również listę pożądanych kolorów odpowiadających każdemu z punktów.
importuj numer jako np
x = np. tablica( [1, 2, 3, 4, 5, 6, 7, 8] )
y = x
pl.figura()
plt.scatter( x, y )
Działki liniowe
Wykres liniowy jest tworzony za pomocą funkcji plot() i wykreśla szereg różnych serii punktów danych, takich jak wykres punktowy, ale łączy każdą serię punktów za pomocą linii.
importuj numer jako np
dane_liniowe = np. tablica( [1, 2, 3, 4, 5, 6, 7, 8] )
dane_kwadratowe = dane_liniowe**2
pl.figura()
plt.plot( dane_liniowe, '-o', dane_kwadratowe, '-o')
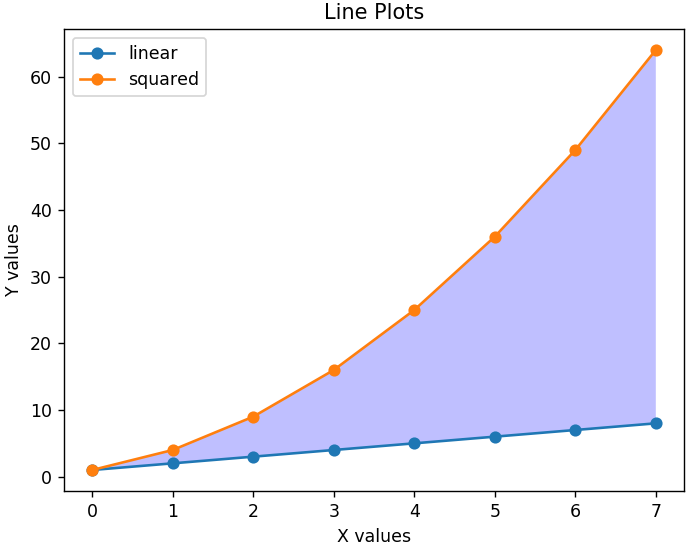
Aby wykres był bardziej czytelny, możemy również dodać legendę, która powie nam, co reprezentuje każda linia. Ważny jest odpowiedni tytuł wykresu i obu osi. Również każdą sekcję wykresu można zacienić za pomocą funkcji fill_between() , aby podświetlić odpowiednie regiony.
plt.xlabel('Wartości X')
plt.ylabel('Wartości Y')
plt.title('Wykresy liniowe')

plt.legend( ['liniowe', 'kwadratowe'] )
plt.gca().fill_between( range ( len ( linear_data ) ), linear_data, squared_data, facecolor = 'blue', alpha = 0.25)
Tak wygląda zmodyfikowany wykres-
Wykresy słupkowe
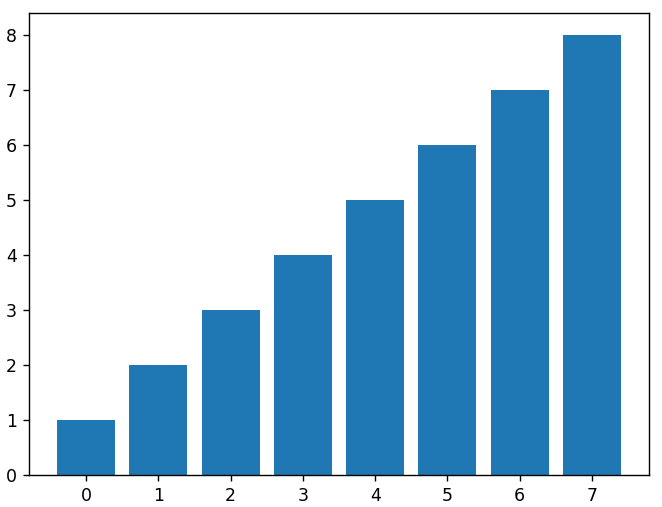
Możemy wykreślić wykres słupkowy, wysyłając argumenty dla wartości X i wysokości każdego słupka do funkcji bar() . Poniżej znajduje się wykres słupkowy tej samej liniowej tablicy danych, której użyliśmy powyżej.
pl.figura()
x = zakres( dł ( dane_liniowe ))
plt.bar( x, dane_liniowe )
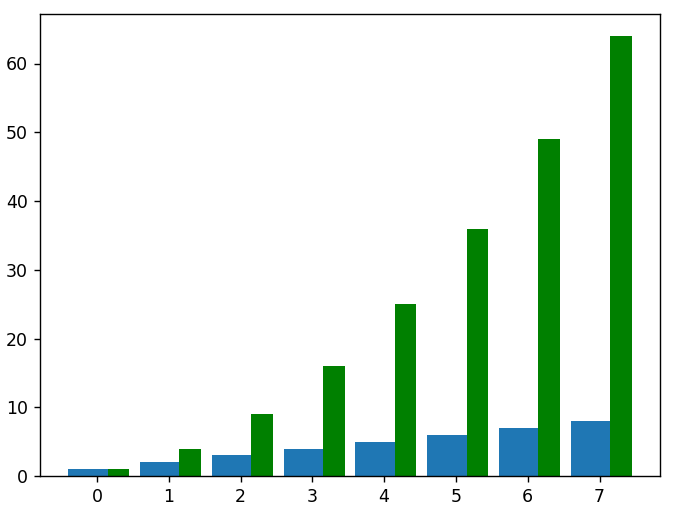
# aby wykreślić dane do kwadratu jako kolejny zestaw słupków na tym samym wykresie, musimy dostosować nowe wartości x, aby uzupełnić pierwszy zestaw słupków
nowy_x = []
dla danych w x:
nowy_x.append(dane+0.3)
plt.bar(nowy_x, dane_kwadratowe, szerokość = 0,3, kolor = 'zielony')
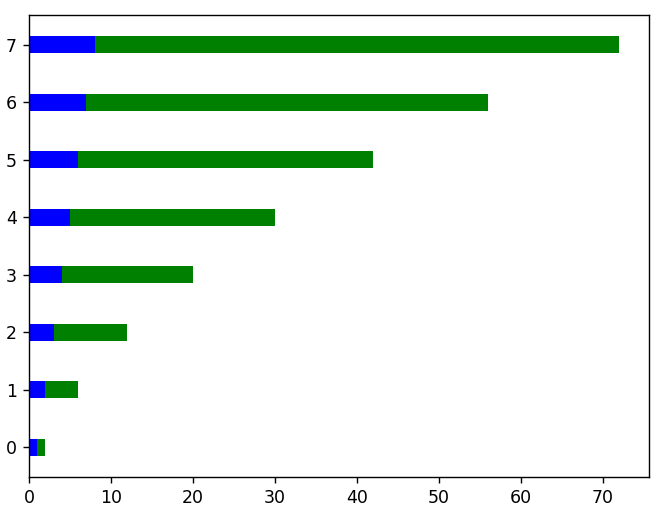
# Dla wykresów z orientacją poziomą używamy funkcji barh ()
pl.figura()
x = zakres( len( dane_liniowe ))
plt.barh( x, dane_liniowe, wysokość = 0,3, kolor = 'b')
plt.barh( x, dane_kwadratowe, wysokość = 0,3, lewa = dane_liniowe, kolor = 'g')
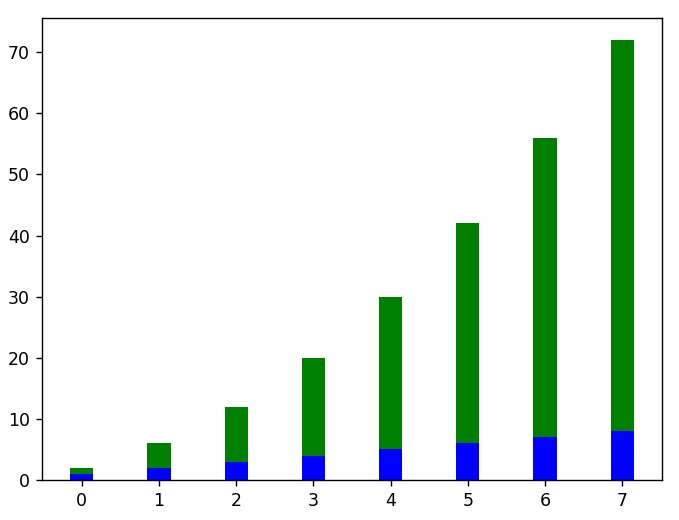
#tutaj jest przykład pionowego układania wykresów słupków
pl.figura()
x = zakres( len( dane_liniowe ))
plt.bar( x, linear_data, width = 0.3, color = 'b')
plt.bar( x, dane_kwadratowe, szerokość = 0,3, dół = dane_liniowe, kolor = 'g')
Ucz się kursów nauki o danych z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Wniosek
Rodzaje wizualizacji nie kończą się tutaj. Python ma również świetną bibliotekę o nazwie seaborn , którą zdecydowanie warto poznać. Właściwa wizualizacja informacji znacznie pomaga zwiększyć wartość naszych danych. Wizualizacja danych zawsze będzie lepszą opcją do uzyskiwania wglądu i identyfikowania różnych trendów i wzorców, zamiast przeglądania nudnych tabel z milionami rekordów.
Jeśli jesteś zainteresowany nauką o danych, sprawdź IIIT-B i upGrad's PG Diploma in Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, 1- on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Jakie są przydatne pakiety Pythona do wizualizacji danych?
Python ma kilka niesamowitych i użytecznych pakietów do wizualizacji danych. Niektóre z tych pakietów są wymienione poniżej:
1. Matplotlib — Matplotlib to popularna biblioteka Pythona używana do wizualizacji danych w różnych formach, takich jak wykresy rozrzutu, wykresy słupkowe, wykresy kołowe i wykresy liniowe. Używa Numpy do swoich operacji matematycznych.
2. Seaborn — Biblioteka Seaborn jest używana do reprezentacji statystycznych w Pythonie. Jest rozwijany na bazie Matplotlib i jest zintegrowany ze strukturami danych Pandas.
3. Altair — Altair to kolejna popularna biblioteka Pythona do wizualizacji danych. Jest to deklaratywna biblioteka statystyczna, która pozwala tworzyć wizualizacje przy minimalnym możliwym kodowaniu.
4. Plotly — Plotly to interaktywna biblioteka do wizualizacji danych o otwartym kodzie źródłowym w Pythonie. Wizualizacje tworzone przez tę bibliotekę opartą na przeglądarce są obsługiwane przez wiele platform, takich jak Jupyter Notebook i samodzielne pliki HTML.
Co wiesz o wykresach punktowych i wykresach punktowych?
Wykresy punktowe to najbardziej podstawowe i najprostsze wykresy do wizualizacji danych. Wykres punktowy wyświetla dane w postaci punktów na płaszczyźnie kartezjańskiej. „+” pokazuje wzrost wartości, a „-” oznacza spadek wartości w czasie.
Z drugiej strony wykres punktowy to zoptymalizowany wykres, w którym dane są wizualizowane na płaszczyźnie 2D. Jest ona definiowana za pomocą funkcji scatter(), która przyjmuje wartość z osi x jako pierwszy parametr, a wartość z osi y jako drugi parametr.
Jakie są zalety wizualizacji danych?
Poniższe zalety pokazują, jak wizualizacje danych mogą stać się prawdziwym bohaterem rozwoju organizacji:
1. Wizualizacja danych ułatwia interpretację surowych danych i zrozumienie ich do dalszej analizy.
2. Po zbadaniu i przeanalizowaniu danych wyniki można wyświetlić za pomocą znaczących wizualizacji. Ułatwia to nawiązanie kontaktu z publicznością i wyjaśnienie wyników.
3. Jednym z najważniejszych zastosowań tej techniki jest analiza wzorców i trendów w celu wywnioskowania przewidywań i potencjalnych obszarów wzrostu.
4. Pozwala również na segregowanie danych według preferencji klienta. Możesz także określić obszary, które wymagają większej uwagi.