
Struktury danych w Pythonie – kompletny przewodnik
Opublikowany: 2021-06-14Spis treści
Co to jest struktura danych?
Struktura danych odnosi się do obliczeniowego przechowywania danych w celu efektywnego wykorzystania. Przechowuje dane w sposób, który można łatwo modyfikować i uzyskiwać do nich dostęp. Odnosi się zbiorczo do wartości danych, relacji między nimi oraz operacji, które można wykonać na danych. Znaczenie struktury danych polega na jej zastosowaniu do tworzenia programów komputerowych. Ponieważ programy komputerowe w dużym stopniu opierają się na danych, właściwe ułożenie danych w celu łatwego dostępu ma ogromne znaczenie dla każdego programu lub oprogramowania.
Cztery główne funkcje struktury danych to
- Aby wprowadzić informacje
- Aby przetworzyć informacje
- Aby zachować informacje
- Aby uzyskać informacje
Rodzaje struktur danych w Pythonie
Kilka struktur danych jest obsługiwanych przez Python w celu łatwego dostępu i przechowywania danych. Typy struktur danych Pythona można sklasyfikować jako pierwotne i nieprymitywne typy danych. Pierwszy typ danych to Integers, Float, Strings i Boolean, podczas gdy drugi to tablica, lista, krotki, słowniki, zestawy i pliki. Dlatego struktury danych w Pythonie są zarówno wbudowanymi strukturami danych, jak i strukturami danych zdefiniowanymi przez użytkownika. Wbudowana struktura danych jest nazywana strukturą danych nieprymitywnych.
Wbudowane struktury danych
Python ma kilka struktur danych, które działają jak kontenery do przechowywania innych danych. Te struktury danych Pythona to listy, słowniki, krotki i zestawy.
Struktury danych zdefiniowane przez użytkownika
Te struktury danych można zaprogramować tak samo, jak wbudowane struktury danych w Pythonie . Zdefiniowane przez użytkownika struktury danych to: Lista połączona, Stos, Kolejka, Drzewo, Wykres i Hashmap.
Lista wbudowanych struktur danych i objaśnienia
1. Lista
Dane przechowywane na liście są uporządkowane sekwencyjnie i należą do różnych typów danych. Do każdej danej przypisywany jest adres i jest on nazywany indeksem. Wartość indeksu zaczyna się od 0 i ciągnie się do ostatniego elementu. Nazywa się to indeksem dodatnim. Ujemny indeks istnieje również w przypadku odwrotnego dostępu do elementów. Nazywa się to indeksowaniem ujemnym.
Tworzenie listy
Lista jest tworzona w nawiasach kwadratowych. Elementy mogą być następnie odpowiednio dodawane. Można go dodać w nawiasach kwadratowych, aby utworzyć listę. Jeśli nie zostaną dodane żadne elementy, zostanie utworzona pusta lista. W przeciwnym razie zostaną utworzone elementy na liście.
| Wejście moja_lista = [] #utwórz pustą listę drukuj(moja_lista) moja_lista = [1, 2, 3, 'przykład', 3.132] #tworzenie listy z danymi drukuj(moja_lista) | Wyjście [] [1, 2, 3, 'przykład', 3.132] |
Dodawanie elementów w ramach listy
Do dodawania elementów na liście służą trzy funkcje. Te funkcje to append(), extend() i insert().
- Wszystkie elementy są dodawane jako pojedynczy element za pomocą funkcji append().
- Do dodawania elementów jeden po drugim na liście używana jest funkcja extend().
- Do dodawania elementów według ich wartości indeksu używana jest funkcja insert().
| Wejście moja_lista = [1, 2, 3] drukuj(moja_lista) moja_lista.append([555, 12]) #dodaj jako pojedynczy element drukuj(moja_lista) moja_lista.extend([234, 'more_example']) #dodaj jako różne elementy drukuj(moja_lista) moja_lista.insert(1, 'wstaw_przyklad') #dodaj element i drukuj(moja_lista) | Wyjście: [1, 2, 3] [1, 2, 3, [555, 12]] [1, 2, 3, [555, 12], 234, 'więcej_przykładu'] [1, 'wstaw_przykład', 2, 3, [555, 12], 234, 'więcej_przykładu'] |
Usuwanie elementów z listy
Wbudowane słowo kluczowe „del” w Pythonie służy do usuwania elementu z listy. Jednak ta funkcja nie zwraca usuniętego elementu.
- Do zwrócenia usuniętego elementu używana jest funkcja pop(). Wykorzystuje wartość indeksu elementu, który ma zostać usunięty.
- Funkcja remove() służy do usuwania elementu według jego wartości.
Wyjście:
[1, 2, 3, 'przykład', 3.132, 30]
[1, 2, 3, 3.132, 30]
Popped Element: 2 Pozostała lista: [1, 3, 3.132, 30]
[]
Ocena elementów na liście
- Ocena elementu na liście jest prosta. Wydrukowanie listy spowoduje bezpośrednie wyświetlenie elementów.
- Określone elementy można ocenić, przekazując wartość indeksu.
Wyjście:
1
2
3
przykład
3.132
10
30
[1, 2, 3, 'przykład', 3.132, 10, 30]
Przykład
[1, 2]
[30, 10, 3.132, 'przykład', 3, 2, 1]
Oprócz wyżej wymienionych operacji, w pythonie dostępnych jest kilka innych wbudowanych funkcji do pracy z listami.
- len(): funkcja służy do zwracania długości listy.
- index(): ta funkcja pozwala użytkownikowi poznać wartość indeksu przekazanej wartości.
- Funkcja count() służy do znalezienia licznika przekazanej do niej wartości.
- sort() sortuje wartość na liście i modyfikuje listę.
- sorted() sortuje wartość na liście i zwraca listę.
Wyjście
6
3
2
[1, 2, 3, 10, 10, 30]
[30, 10, 10, 3, 2, 1]
2. Słownik
Słownik to rodzaj struktury danych, w której przechowywane są pary klucz-wartość, a nie pojedyncze elementy. Można to wyjaśnić na przykładzie książki telefonicznej, która zawiera wszystkie numery osób wraz z ich numerami telefonów. Nazwisko i numer telefonu definiują tutaj stałe wartości, które są „kluczem”, a liczby i nazwiska wszystkich osób jako wartości tego klucza. Ocena klucza da dostęp do wszystkich wartości przechowywanych w tym kluczu. Ta zdefiniowana struktura klucz-wartość w Pythonie jest znana jako słownik.
Tworzenie słownika
- Nawiasy kwiatowe bezczynne przy funkcji dict() mogą być używane do tworzenia słownika.
- Pary klucz-wartość należy dodać podczas tworzenia słownika.
Modyfikacja w parach klucz-wartość
Wszelkie modyfikacje w słowniku można wykonać tylko za pomocą klucza. Dlatego najpierw należy uzyskać dostęp do kluczy, a następnie dokonać modyfikacji.
| Wejście my_dict = {'Pierwszy': 'Python', 'Drugi': 'Java'} print(my_dict) my_dict['Drugi'] = 'C++' #zmiana elementu print(my_dict) my_dict['Third'] = 'Ruby' #adding pary klucz-wartość print(my_dict) | Wyjście: {'Pierwszy': 'Python', 'Drugi': 'Java'} {'Pierwszy': 'Python', 'Drugi': 'C++'} {'Pierwszy': 'Python', 'Drugi': 'C++', 'Trzeci': 'Rubin'} |
Usunięcie słownika
Do usunięcia całego słownika służy funkcja clear (). Słownik można ocenić za pomocą kluczy, używając funkcji get() lub przekazując wartości kluczy.
| Wejście dict = {'Miesiąc': 'Styczeń', 'Sezon': 'zima'} print(dict['Pierwszy']) print(dict.get('Drugi') | Wyjście Styczeń Zima |
Inne funkcje związane ze słownikiem to keys(), values() i items().
3. Krotka
Podobnie jak lista, krotki są listami przechowywania danych, ale jedyną różnicą jest to, że danych przechowywanych w krotce nie można modyfikować. Jeśli dane w krotce są zmienne, tylko wtedy można je zmienić.
- Krotki można tworzyć za pomocą funkcji tuple().
Wejście
nowa_krotka = (10, 20, 30, 40)
drukuj(nowa_krotka)
Wyjście
(10, 20, 30, 40)
- Elementy w krotce można oceniać w taki sam sposób, jak ocenianie elementów na liście.
Wejście
nowa_tuple2 = (10, 20, 30, 'wiek')
dla x w new_tuple2:
drukuj(x)
drukuj(nowa_krotka2)
drukuj(new_tuple2[0])
Wyjście
10
20
30
Wiek
(10, 20, 30, „wiek”)
10
- Operator „+” służy do dołączania kolejnej krotki
Wejście
krotka = (1, 2, 3)
krotka = krotka + (4, 5, 6
drukuj (krotka)
Wyjście
(1, 2, 3, 4, 5, 6)
4. Ustaw
Struktura danych zbioru jest podobna do zbiorów arytmetycznych. Jest to w zasadzie zbiór niepowtarzalnych elementów. Jeśli dane się powtarzają, to zestawy rozważają dodanie tego elementu tylko raz.
- Zestaw można utworzyć po prostu przekazując mu wartości w nawiasach kwiatowych.
Wejście
zbiór = {10, 20, 30, 40, 40, 40}
drukuj(zestaw)
Wyjście
{10, 20, 30, 40}
- Funkcja add() może służyć do dodawania elementów do zestawu.
- Aby połączyć dane z dwóch zestawów, można użyć funkcji union().
- Do identyfikacji danych, które są obecne w obu zestawach, używana jest funkcja intersection().
- Funkcja różnicy() wyprowadza tylko dane, które są unikalne dla zestawu, usuwając wspólne dane.
- Funkcja symmetric_difference() wyprowadza dane unikalne dla obu zestawów.
Lista zdefiniowanych przez użytkownika struktur danych i wyjaśnienia
1. Stosy
Stos jest strukturą liniową, która jest strukturą Last in First out (LIFO) lub strukturą First in Last Out (FIFO). W stosie istnieją dwie główne operacje, tj. push i pop. Push oznacza dołączenie elementu na górze listy, podczas gdy pop oznacza usunięcie elementu z dołu stosu. Proces jest dobrze opisany na rysunku 1.

Przydatność stosu
- Poprzednie elementy można ocenić za pomocą śledzenia wstecznego.
- Dopasowywanie elementów rekurencyjnych.
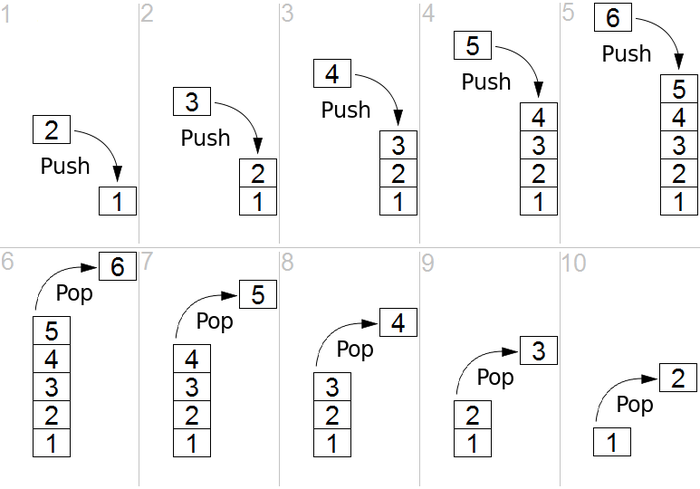
Źródło
Rysunek 1: Graficzna reprezentacja stosu
Przykład

Wyjście
['pierwszy drugi trzeci']
['pierwszy', 'drugi', 'trzeci', 'czwarty', 'piąty']
piąty
['pierwszy drugi trzeci czwarty']
2. Kolejka
Podobnie jak stosy, kolejka jest strukturą liniową, która umożliwia wstawianie elementu na jednym końcu i usuwanie z drugiego końca. Te dwie operacje są znane jako kolejkowanie i usuwanie z kolejki. Ostatnio dodany element jest usuwany jako pierwszy, podobnie jak stosy. Graficzna reprezentacja kolejki jest pokazana na rysunku 2. Jednym z głównych zastosowań kolejki jest przetwarzanie rzeczy zaraz po ich wejściu.
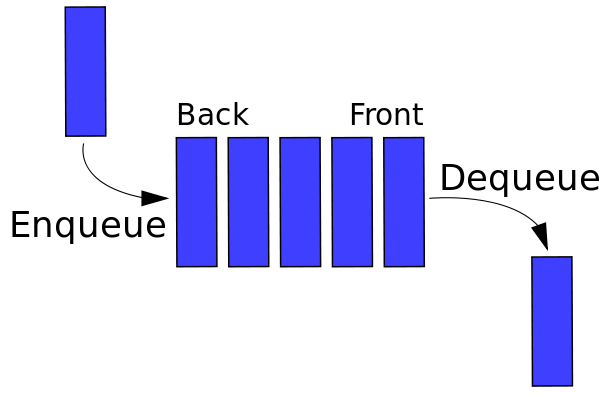
Źródło
Rysunek 2 : Graficzna reprezentacja kolejek
Przykład

Wyjście
['pierwszy drugi trzeci']
['pierwszy', 'drugi', 'trzeci', 'czwarty', 'piąty']
pierwszy
piąty
['drugi', 'trzeci', 'czwarty', 'piąty']
3. Drzewo
Drzewa to nieliniowe i hierarchiczne struktury danych składające się z węzłów połączonych krawędziami. Struktura danych drzewa Pythona ma węzeł główny, węzeł nadrzędny i węzeł podrzędny. Korzeń jest najwyższym elementem struktury danych. Drzewo binarne to struktura, w której elementy mają nie więcej niż dwa węzły podrzędne.
Przydatność drzewa
- Wyświetla strukturalne relacje elementów danych.
- Efektywne przechodzenie przez każdy węzeł
- Użytkownicy mogą wstawiać, wyszukiwać, pobierać i usuwać dane.
- Elastyczne struktury danych
Rysunek 3: Graficzna reprezentacja drzewa
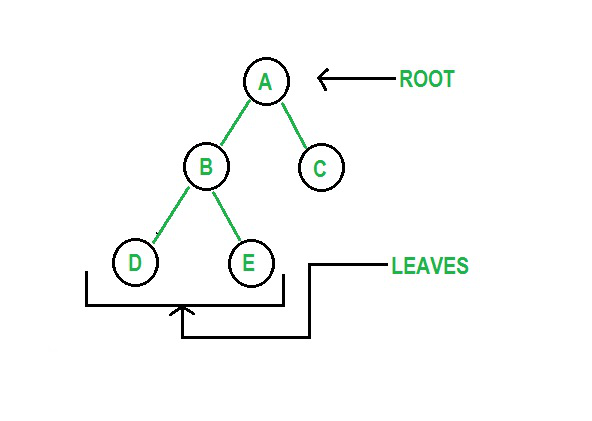
Źródło
Przykład:

Wyjście
Pierwszy
druga
Trzeci
4. Wykres
Inną nieliniową strukturą danych w Pythonie jest graf składający się z węzłów i krawędzi. Graficznie wyświetla zestaw obiektów, z niektórymi obiektami połączonymi łączami. Wierzchołki są połączonymi ze sobą obiektami, podczas gdy połączenia nazywane są krawędziami. Reprezentację wykresu można wykonać za pomocą słownikowej struktury danych Pythona, gdzie klucz reprezentuje wierzchołki, a wartości reprezentują krawędzie.
Podstawowe operacje, które można wykonać na wykresach
- Wyświetlaj wierzchołki i krawędzie wykresu.
- Dodanie wierzchołka.
- Dodanie krawędzi.
- Tworzenie wykresu
Przydatność wykresu
- Przedstawienie wykresu jest łatwe do zrozumienia i śledzenia.
- Jest to świetna struktura do reprezentowania powiązanych relacji, np. znajomych z Facebooka.
Rysunek 4: Graficzna reprezentacja wykresu
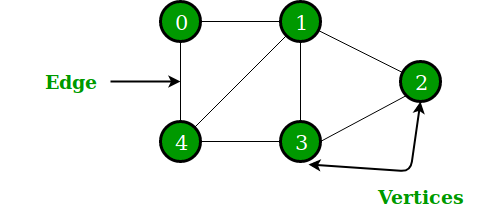
Źródło
Przykład

g = wykres(4)
g.krawędź(0, 2)
g.krawędź (1, 3)
g.krawędź(3, 2)
g.krawędź(0, 3)
g.__repr__()
Wyjście
Lista sąsiedztwa wierzchołków 0
głowa -> 3 -> 2
Lista sąsiedztwa wierzchołka 1
głowa -> 3
Lista sąsiedztwa wierzchołka 2
głowa -> 3 -> 0
Lista sąsiedztwa wierzchołków 3
głowa -> 0 -> 2 -> 1
5. Hashmapa
Hashmapy to indeksowane struktury danych Pythona przydatne do przechowywania par klucz-wartość. Dane przechowywane w hashmapach są pobierane za pomocą kluczy, które są obliczane za pomocą funkcji skrótu. Tego typu struktury danych są przydatne do przechowywania danych uczniów, danych klientów itp. Słowniki w pythonie są przykładem hashmap.
Przykład

Wyjście
0 -> pierwszy
1 -> sekunda
2 -> trzeci
0 -> pierwszy
1 -> sekunda
2 -> trzeci
3 -> czwarta
0 -> pierwszy
1 -> sekunda
2 -> trzeci
Przydatność
- Jest to najbardziej elastyczna i niezawodna metoda wyszukiwania informacji niż inne struktury danych.
6. Połączona lista
Jest to rodzaj liniowej struktury danych. Zasadniczo jest to seria elementów danych połączonych ze sobą za pomocą łączy w pythonie. Elementy na połączonej liście są połączone wskaźnikami. Pierwszy węzeł tej struktury danych jest nazywany nagłówkiem, a ostatni węzeł jest określany jako ogon. Dlatego połączona lista składa się z węzłów posiadających wartości, a każdy węzeł składa się ze wskaźnika połączonego z innym węzłem.
Przydatność list połączonych
- W porównaniu z tablicą, która jest stała, połączona lista jest dynamiczną formą wprowadzania danych. Pamięć jest zapisywana, ponieważ przydziela pamięć węzłów. W tablicy rozmiar musi być wstępnie zdefiniowany, co prowadzi do marnowania pamięci.
- Lista połączona może być przechowywana w dowolnym miejscu pamięci. Połączony węzeł listy można zaktualizować i przenieść w inne miejsce.
Rysunek 6: Graficzna reprezentacja połączonej listy
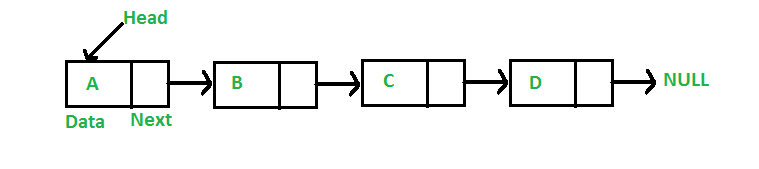
Źródło
Przykład

Wyjście:
['pierwszy drugi trzeci']
['pierwszy', 'drugi', 'trzeci', 'szósty', 'czwarty', 'piąty']
['pierwszy', 'trzeci', 'szósty', 'czwarty', 'piąty']
Wniosek
Zbadano różne typy struktur danych w Pythonie . Niezależnie od tego, czy jesteś nowicjuszem, czy ekspertem, struktury danych i algorytmy nie mogą być ignorowane. Przy wykonywaniu dowolnej formy operacji na danych istotną rolę odgrywają koncepcje struktur danych. Struktury danych pomagają w przechowywaniu informacji w sposób zorganizowany, podczas gdy algorytmy pomagają w prowadzeniu całej analizy danych. Dlatego zarówno struktury danych, jak i algorytmy Pythona pomagają informatykowi lub dowolnym użytkownikom w przetwarzaniu ich danych.
Jeśli chcesz dowiedzieć się więcej o strukturach danych, sprawdź IIIT-B i upGrad's Executive PG Program in Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, 1 -on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Która struktura danych jest szybsza w Pythonie?
W słownikach wyszukiwania są szybsze, ponieważ Python używa do ich implementacji tablic mieszających. Jeśli użyjemy koncepcji Big O do zilustrowania tego rozróżnienia, słowniki mają stałą złożoność czasową O(1), podczas gdy listy mają liniową złożoność czasową O(n).
W Pythonie słowniki to najszybszy sposób na częste wyszukiwanie danych z tysiącami wpisów. Słowniki są wysoce zoptymalizowane, ponieważ są wbudowanym typem mapowania w Pythonie. Jednak w słownikach i listach istnieje wspólny kompromis czasoprzestrzenny. Oznacza to, że chociaż możemy skrócić czas potrzebny na nasze podejście, będziemy musieli wykorzystać więcej miejsca w pamięci.
Na listach, aby uzyskać to, czego chcesz, musisz przejrzeć pełną listę. Z drugiej strony słownik zwróci wartość, której szukasz, bez przeszukiwania wszystkich kluczy.
Co jest szybsze w liście lub tablicy w Pythonie?
Ogólnie rzecz biorąc, listy Pythona są niewiarygodnie elastyczne i mogą zawierać całkowicie heterogeniczne, losowe dane, a także są dołączane szybko i w przybliżonym stałym czasie. Są dobrym rozwiązaniem, jeśli chcesz szybko i bezboleśnie zmniejszyć i rozszerzyć swoją listę. Zajmują jednak znacznie więcej miejsca niż tablice, częściowo dlatego, że każdy element listy wymaga utworzenia osobnego obiektu Pythona.
Z drugiej strony typ array.array jest zasadniczo cienkim opakowaniem wokół tablic C. Może przenosić tylko jednorodne dane (to znaczy dane tego samego typu), stąd pamięć jest ograniczona do sizeof(jednego obiektu) * długości bajtów.
Jaka jest różnica między tablicą NumPy a listą?
Numpy to podstawowy pakiet obliczeniowy Pythona. Wykorzystuje duży wielowymiarowy obiekt tablicy, a także narzędzia do manipulowania nimi. Tablica numpy to siatka wartości identycznego typu, indeksowana przez krotkę nieujemnych liczb całkowitych.
Listy zostały zawarte w podstawowej bibliotece Pythona. Lista jest podobna do tablicy w Pythonie, ale można ją zmieniać i zawierać elementy różnych typów. Jaka jest tutaj prawdziwa różnica? Odpowiedzią jest wydajność. Struktury danych Numpy są bardziej wydajne pod względem rozmiaru, wydajności i funkcjonalności.