
Czym są struktury danych w C i jak z nich korzystać?
Opublikowany: 2021-02-26Spis treści
Wstęp
Po pierwsze, struktura danych to zbiór elementów danych, które są utrzymywane razem pod jedną nazwą lub nagłówkiem i jest specyficznym sposobem przechowywania i gromadzenia danych, aby można było z nich efektywnie korzystać.
Rodzaje
Struktury danych są powszechne i używane w prawie każdym systemie oprogramowania. Niektóre z najczęstszych przykładów struktur danych to tablice, kolejki, stosy, listy połączone i drzewa.
Aplikacje
W projektowaniu kompilatorów, systemów operacyjnych, tworzeniu baz danych, aplikacji sztucznej inteligencji i wielu innych.
Klasyfikacja
Struktury danych są podzielone na dwie kategorie: pierwotne struktury danych i inne niż pierwotne struktury danych.
1. Prymitywne: Są to podstawowe typy danych obsługiwane przez język programowania. Typowym przykładem tej klasyfikacji są liczby całkowite, znaki i wartości logiczne.
2. Nieprymitywny: Te kategorie struktur danych są tworzone przy użyciu pierwotnych struktur danych. Przykłady obejmują połączone stosy, połączone listy, wykresy i drzewa.

Tablice
Tablica to prosty zbiór elementów danych, które mają ten sam typ danych. Oznacza to, że tablica liczb całkowitych typu może przechowywać tylko wartości całkowite. Tablica typu zmiennoprzecinkowego może przechowywać wartości odpowiadające typowi danych zmiennoprzecinkowe i nic więcej.
Elementy przechowywane w tablicy są dostępne liniowo i znajdują się w ciągłych blokach pamięci, do których można się odwoływać za pomocą indeksu.
Deklarowanie tablicy
W C tablicę można zadeklarować jako:
nazwa_typu danych[długość];
Na przykład,
zamówienia międzynarodowe[10];
Powyższy wiersz kodu tworzy tablicę 10 bloków pamięci, w której można przechowywać wartość całkowitą. W C, wartość indeksu tablicy zaczyna się od 0. Zatem wartości indeksu będą mieścić się w zakresie od 0 do 9. Jeśli chcemy uzyskać dostęp do określonej wartości w tej tablicy, wystarczy wpisać:
printf(zamówienie[numer_indeksu]);
Inny sposób zadeklarowania tablicy jest następujący:
data_type array_name[size]={lista wartości};
Na przykład,
znaki int[5]={9, 8, 7, 9, 8};
Powyższy wiersz polecenia tworzy tablicę zawierającą 5 bloków pamięci ze stałymi wartościami w każdym z bloków. W 32-bitowym kompilatorze 32-bitowa pamięć zajmowana przez typ danych int ma 4 bajty. Tak więc 5 bloków pamięci zajęłoby 20 bajtów pamięci.
Innym prawidłowym sposobem inicjowania tablic jest:
znaki int [5] = {9 , 45};
To polecenie utworzy tablicę 5 bloków, przy czym ostatnie 3 bloki mają wartość 0.
Innym legalnym sposobem jest:
znaki int [] = {9 , 5, 2, 1, 3,4};
Kompilator C rozumie, że do dopasowania tych danych do tablicy potrzeba tylko 5 bloków. Dlatego zainicjuje tablicę znaczników nazw o rozmiarze 5.
Podobnie tablicę 2-D można zainicjować w następujący sposób
znaki int[2] [3]={{9,7,7},{6, 2, 1}};
Powyższe polecenie utworzy tablicę 2D zawierającą 2 wiersze i 3 kolumny.
Przeczytaj: Pomysły i tematy projektów dotyczących struktury danych
Operacje
Istnieje kilka operacji, które można wykonać na tablicach. Na przykład:
- przechodzenie przez tablicę
- Wstawianie elementu do tablicy
- Wyszukiwanie określonego elementu w tablicy
- Usuwanie konkretnego elementu z tablicy
- Scalanie dwóch tablic i,
- Sortowanie tablicy — w kolejności rosnącej lub malejącej.
Niedogodności
Pamięć przydzielona do macierzy jest stała. To właściwie jest problem. Powiedzmy, że stworzyliśmy tablicę o rozmiarze 50 i uzyskaliśmy dostęp tylko do 30 bloków pamięci. Pozostałe 20 bloków zajmuje pamięć bez żadnego użycia. Dlatego, aby rozwiązać ten problem, mamy połączoną listę.
Połączona lista
Lista połączona, podobnie jak tablice, przechowuje dane szeregowo. Główna różnica polega na tym, że nie przechowuje wszystkiego na raz. Zamiast tego przechowuje dane lub udostępnia blok pamięci w razie potrzeby. Na połączonej liście bloki są podzielone na dwie części. Pierwsza część zawiera aktualne dane.
Druga część to wskaźnik, który wskazuje następny blok na połączonej liście. Wskaźnik przechowuje adres następnego bloku, który przechowuje dane. Jest jeszcze jeden wskaźnik zwany wskaźnikiem głowy. head wskazuje pierwszy blok pamięci na połączonej liście. Poniżej znajduje się reprezentacja połączonej listy. Bloki te są również nazywane „węzłami”.
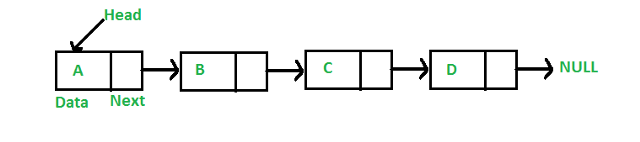
źródło
Inicjowanie połączonych list
Aby zainicjować listę linków, tworzymy węzeł nazw struktur. Struktura ma dwie rzeczy. 1. Dane, które przechowuje i 2. Wskaźnik wskazujący na następny węzeł. Typem danych wskaźnika będzie typ struktury, ponieważ wskazuje na węzeł struktury.

węzeł struktury
{
dane wewn.;
węzeł struktury *następny;
};
W połączonej liście wskaźnik ostatniego węzła nie będzie wskazywał niczego lub po prostu będzie wskazywał na null.
Przeczytaj także: Wykresy w strukturze danych
Przechodzenie przez połączone listy
W połączonej liście wskaźnik ostatniego węzła nie będzie wskazywał niczego lub po prostu będzie wskazywał na null. Tak więc, aby przemierzyć całą połączoną listę, tworzymy fikcyjny wskaźnik, który początkowo wskazuje na głowę. A dla długości połączonej listy wskaźnik kontynuuje przesuwanie się do przodu, aż wskaże wartość null lub osiągnie ostatni węzeł połączonej listy.
Dodawanie węzła
Algorytm dodawania węzła przed określonym węzłem byłby następujący:
- ustaw dwa atrapy wskaźników (ptr i preptr), które początkowo wskazują na głowę
- przenieś ptr, aż ptr.data będzie równe danym, zanim zamierzamy wstawić węzeł. preptr będzie 1 węzeł za ptr.
- Utwórz węzeł
- Węzeł, na który wskazywał dummy preptr, następny ten węzeł będzie wskazywał na ten nowy węzeł
- Następny nowy węzeł będzie wskazywał na ptr.
W podobny sposób zostałby wykonany algorytm dodawania węzła po określonych danych.
Zalety połączonej listy
- Rozmiar dynamiczny w przeciwieństwie do tablicy
- Wstawianie i usuwanie jest łatwiejsze na połączonej liście niż w tablicy.
Kolejka
Kolejka podąża za systemem typu „pierwsze weszło, pierwsze wyszło” lub FIFO. W implementacji tablicowej będziemy mieli dwa wskaźniki do zademonstrowania przypadku użycia Queue.
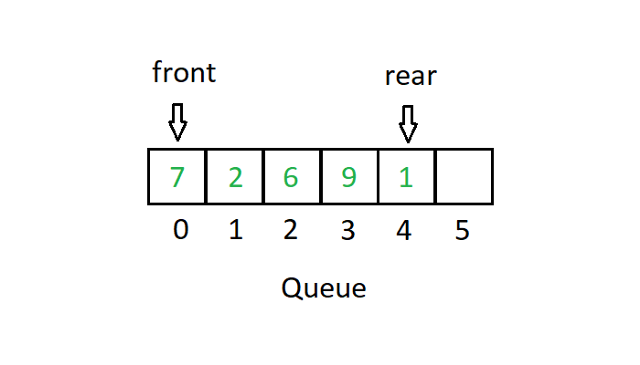
Źródło
FIFO zasadniczo oznacza, że wartość, która jako pierwsza wchodzi na stos, jako pierwsza opuszcza tablicę. Na powyższym schemacie kolejki, front wskaźnika wskazuje na wartość 7. Jeśli usuniemy pierwszy blok (usuwanie z kolejki), to front będzie teraz wskazywał na wartość 2. Podobnie, jeśli wprowadzimy liczbę (w kolejce), powiedzmy 3 w pozycja 5. Następnie tylny wskaźnik wskaże pozycję 5.
Warunki przepełnienia i niedopełnienia
Niemniej jednak przed wprowadzeniem wartości danych do kolejki musimy sprawdzić warunki przepełnienia. Przepełnienie nastąpi, gdy nastąpi próba wstawienia elementu do kolejki, która jest już pełna. Kolejka zapełni się, gdy tył = max_size–1.
Podobnie przed usunięciem danych z kolejki powinniśmy sprawdzić stan niedopełnienia. Niedopełnienie wystąpi, gdy nastąpi próba usunięcia elementu z kolejki, która jest już pusta, tzn. jeśli front = null i rear = null, to kolejka jest pusta.
Stos
Stos to struktura danych, w której wstawiamy i usuwamy elementy tylko na jednym końcu, zwanym również wierzchołkiem stosu. Implementacja stosu jest zatem określana jako implementacja LIFO (ostatnie weszło, pierwsze wyszło). W przeciwieństwie do kolejki, dla stosu potrzebujemy tylko jednego górnego wskaźnika.
Jeśli chcemy wprowadzić (przesunąć) elementy do tablicy, górny wskaźnik przesuwa się w górę lub zwiększa się o 1. Jeśli chcemy usunąć (wyskakiwać) element, górny wskaźnik zmniejsza się o 1 lub obniża się o 1 jednostkę. Stos obsługuje trzy podstawowe operacje: push, pop i peep. Operacja Peep to po prostu wyświetlenie najwyższego elementu w stosie.
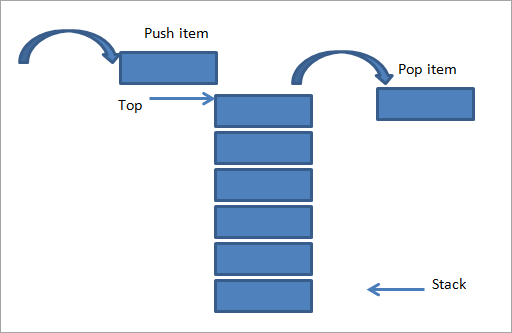
Źródło
Ucz się kursów oprogramowania online z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Wniosek
W tym artykule omówiliśmy 4 rodzaje struktur danych, a mianowicie tablice, listy połączone, kolejki i stosy. Mam nadzieję, że spodobał Ci się ten artykuł i czekaj na więcej interesujących lektur. Do następnego razu.
Jeśli chcesz dowiedzieć się więcej o JavaScript, programowaniu pełnego stosu, sprawdź program Executive PG UpGrad i IIIT-B w zakresie programowania pełnego stosu, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 500 godzin rygorystycznych szkoleń, ponad 9 projektów i zadania, status absolwentów IIIT-B, praktyczne praktyczne projekty zwieńczenia i pomoc w pracy z najlepszymi firmami.
Jakie są struktury danych w programowaniu?
Struktury danych to sposób, w jaki organizujemy dane w programie. Dwie najważniejsze struktury danych to tablice i listy połączone. Tablice to najbardziej znana i najłatwiejsza do zrozumienia struktura danych. Tablice to w zasadzie ponumerowane listy powiązanych elementów. Są łatwe do zrozumienia i użycia, ale nie są zbyt wydajne podczas pracy z dużymi ilościami danych. Listy połączone są bardziej złożone, ale mogą być bardzo wydajne, jeśli są odpowiednio używane. Są dobrym wyborem, gdy będziesz musiał dodać lub usunąć elementy w środku dużej listy lub gdy musisz wyszukać elementy na dużej liście.
Jakie są różnice między listą połączoną a tablicami?
W tablicach indeks jest używany do uzyskania dostępu do elementu. Elementy w tablicy są zorganizowane w kolejności sekwencyjnej, co ułatwia dostęp do elementów i ich modyfikowanie, jeśli używany jest indeks. Tablica ma również stały rozmiar. Elementy są przydzielane w momencie ich powstania. Na połączonej liście wskaźnik jest używany do uzyskania dostępu do elementu. Elementy połączonej listy niekoniecznie są przechowywane w kolejności sekwencyjnej. Połączona lista ma nieznany rozmiar, ponieważ może zawierać węzły w momencie jej tworzenia. Wskaźnik służy do dostępu do elementu, dzięki czemu alokacja pamięci jest łatwiejsza.
Czym jest wskaźnik w C?
Wskaźnik to typ danych w C, który przechowuje adres dowolnej zmiennej lub funkcji. Jest zwykle używany jako odniesienie do innej lokalizacji w pamięci. Wskaźnik może przechowywać adres pamięci tablicy, struktury, funkcji lub dowolnego innego typu. C używa wskaźników do przekazywania wartości i odbierania wartości z funkcji. Wskaźniki służą do dynamicznego przydzielania miejsca w pamięci.