
Kompletna ściągawka do nauki o danych, którą każdy badacz danych powinien mieć
Opublikowany: 2021-01-29Dla wszystkich początkujących profesjonalistów i początkujących, którzy myślą o zanurzeniu się w dynamicznie rozwijającym się świecie nauki o danych, przygotowaliśmy krótką ściągawkę, aby odświeżyć podstawy i metodologie, które podkreślają tę dziedzinę.
Spis treści
Nauka o danych — podstawy
Dane, które są generowane w naszym świecie, mają surową formę, tj. liczby, kody, słowa, zdania itp. Nauka o danych wykorzystuje te bardzo surowe dane do przetwarzania ich za pomocą metod naukowych, aby przekształcić je w znaczące formy w celu uzyskania wiedzy i wglądu .
Dane
Zanim zagłębimy się w założenia nauki o danych, porozmawiajmy trochę o danych, ich typach i przetwarzaniu danych.
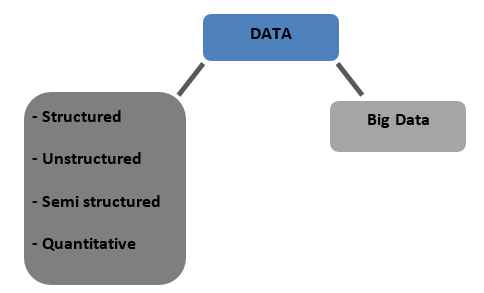
Rodzaje danych
Strukturalny — dane przechowywane w bazach danych w formacie tabelarycznym. Może to być numeryczna lub tekstowa
Nieustrukturyzowane — dane, których nie można zestawić z żadną ostateczną strukturą, o której można mówić, są nazywane danymi nieustrukturyzowanymi
Częściowo ustrukturyzowane — mieszane dane o cechach danych ustrukturyzowanych i nieustrukturyzowanych
Ilościowa — dane o określonych wartościach liczbowych, które można określić ilościowo
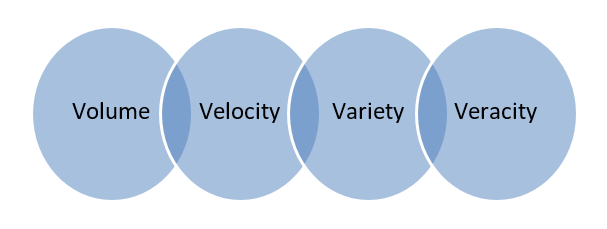
Big Data – Dane przechowywane w ogromnych bazach danych obejmujących wiele komputerów lub farm serwerów nazywane są Big Data. Dane biometryczne, dane z mediów społecznościowych itp. są uważane za Big Data. Big data charakteryzuje się 4 V
Wstępne przetwarzanie danych
Klasyfikacja danych — jest to proces kategoryzowania lub oznaczania danych w klasach, takich jak numeryczne, tekstowe lub graficzne, tekstowe, wideo itp.
Oczyszczanie danych – polega na usunięciu brakujących/niespójnych/niekompatybilnych danych lub zastąpieniu danych za pomocą jednej z poniższych metod.
- Interpolacja
- Heurystyczny
- Przypisanie losowe
- Najbliższy sąsiad
Maskowanie danych — ukrywanie lub maskowanie poufnych danych w celu zachowania prywatności poufnych informacji przy jednoczesnym zachowaniu możliwości ich przetwarzania.
Z czego składa się analiza danych?
Koncepcje statystyki
Regresja
Regresja liniowa
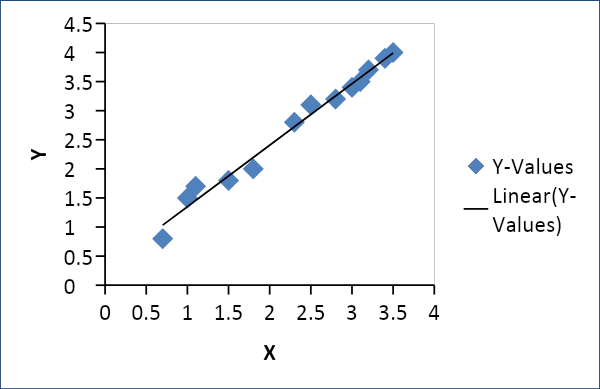
Regresja liniowa służy do ustalenia związku między dwiema zmiennymi, takimi jak podaż i popyt, cena i konsumpcja itp. Odnosi się do jednej zmiennej x jako funkcji liniowej innej zmiennej y w następujący sposób
Y = f(x) lub Y =mx + c, gdzie m = współczynnik
Regresja logistyczna
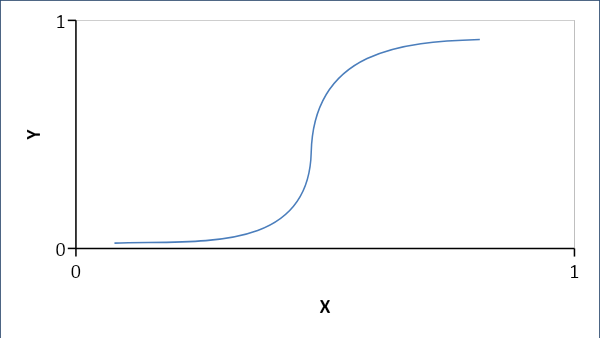
Regresja logistyczna ustanawia raczej zależność probabilistyczną niż liniową między zmiennymi. Otrzymana odpowiedź to 0 lub 1 i szukamy prawdopodobieństw, a krzywa ma kształt litery S.
Jeśli p < 0,5, to jego 0 inaczej 1
Formuła:
Y = e^ (b0 + b1x) / (1 + e^ (b0 +b1x))
gdzie b0 = odchylenie, a b1 = współczynnik
Prawdopodobieństwo
Prawdopodobieństwo pomaga przewidzieć prawdopodobieństwo wystąpienia zdarzenia. Niektóre terminologie:
Próbka: zbiór prawdopodobnych wyników
Zdarzenie: Jest to podzbiór przestrzeni próbki
Zmienna losowa: zmienne losowe pomagają mapować lub określać ilościowo prawdopodobne wyniki na liczby lub linię w przestrzeni próbki
Rozkłady prawdopodobieństwa
Dystrybucje dyskretne: podaje prawdopodobieństwo jako zbiór wartości dyskretnych (liczba całkowita)
P[X=x] = p(x)
 Źródło obrazu
Źródło obrazu
Rozkłady ciągłe: podaje prawdopodobieństwo w wielu ciągłych punktach lub przedziałach zamiast wartości dyskretnych. Formuła:
P[a ≤ x ≤ b] = a∫bf(x) dx, gdzie a, b są punktami
Źródło obrazu
Korelacja i kowariancja
Odchylenie standardowe: zmienność lub odchylenie danego zbioru danych od jego średniej wartości
σ = √ {(Σi=1N ( xi – x )) / (N -1)}
Kowariancja
Określa zakres odchylenia zmiennych losowych X i Y ze średnią zbioru danych.
Cov(X,Y) = σ2XY = E[(X−μX)(Y−μY)] = E[XY]−μXμY
Korelacja
Korelacja określa zakres liniowej zależności między zmiennymi wraz z ich kierunkiem, +ve lub -ve
ρXY= σ2XY/ σX * *σY
Sztuczna inteligencja
Zdolność maszyn do zdobywania wiedzy i podejmowania decyzji na podstawie danych wejściowych nazywana jest sztuczną inteligencją lub po prostu sztuczną inteligencją.
Rodzaje
- Reaktywne maszyny: Reaktywna sztuczna inteligencja maszyn działa, ucząc się reagowania na predefiniowane scenariusze, zawężając się do najszybszych i najlepszych opcji. Brakuje im pamięci i najlepiej nadają się do zadań o określonym zestawie parametrów. Wysoce niezawodne i spójne.
- Ograniczona pamięć: ta sztuczna inteligencja ma wgrane do niej pewne dane obserwacyjne i starsze. Potrafi uczyć się i podejmować decyzje na podstawie podanych danych, ale nie może zdobywać nowych doświadczeń.
- Teoria umysłu: Jest to interaktywna sztuczna inteligencja, która może podejmować decyzje w oparciu o zachowanie otaczających jednostek.
- Samoświadomość: ta sztuczna inteligencja jest świadoma swojego istnienia i funkcjonowania poza otoczeniem. Może rozwijać zdolności poznawcze oraz rozumieć i oceniać wpływ własnych działań na otoczenie.
Warunki AI
Sieci neuronowe
Sieci neuronowe to grupa lub sieć połączonych ze sobą węzłów, które przekazują dane i informacje w systemie. Modele NN naśladują neurony w naszych mózgach i mogą podejmować decyzje poprzez uczenie się i przewidywanie.
Heurystyka
Heurystyka to zdolność do szybkiego przewidywania na podstawie przybliżeń i szacunków z wykorzystaniem wcześniejszych doświadczeń w sytuacjach, gdy dostępne informacje są niejednolite. Jest szybki, ale nie dokładny ani precyzyjny.
Uzasadnienie w oparciu o przypadki
Umiejętność wyciągania wniosków z poprzednich przypadków rozwiązywania problemów i stosowania ich w bieżących sytuacjach w celu uzyskania akceptowalnego rozwiązania
Przetwarzanie języka naturalnego
To po prostu zdolność maszyny do rozumienia i interakcji bezpośrednio z ludzką mową lub tekstem. Na przykład polecenia głosowe w samochodzie
Nauczanie maszynowe
Uczenie maszynowe to po prostu zastosowanie sztucznej inteligencji wykorzystującej różne modele i algorytmy do przewidywania i rozwiązywania problemów.

Rodzaje
Nadzorowane
Ta metoda opiera się na danych wejściowych, które są skojarzone z danymi wyjściowymi. Maszyna jest wyposażona w zestaw zmiennych docelowych Y i musi dojść do zmiennej docelowej poprzez zestaw zmiennych wejściowych X pod nadzorem algorytmu optymalizacji. Przykładami nadzorowanego uczenia się są sieci neuronowe, losowy las, głębokie uczenie, maszyny wektorów nośnych itp.
Bez nadzoru
W tej metodzie zmienne wejściowe nie mają etykiet ani powiązań, a algorytmy pracują w celu znalezienia wzorców i klastrów, co skutkuje nową wiedzą i spostrzeżeniami.
Wzmocniony
Wzmocnione uczenie się koncentruje się na technikach improwizacji w celu wyostrzenia lub doszlifowania zachowań związanych z uczeniem się. Jest to metoda oparta na nagrodzie, w której maszyna stopniowo poprawia swoje techniki, aby wygrać docelową nagrodę.
Metody modelowania
Regresja
Modele regresji zawsze podają liczby jako dane wyjściowe poprzez interpolację lub ekstrapolację danych ciągłych.
Klasyfikacja
Modele klasyfikacji zawierają dane wyjściowe jako klasę lub etykietę i są lepsze w przewidywaniu dyskretnych wyników, takich jak „jaki rodzaj”
Zarówno regresja, jak i klasyfikacja są modelami nadzorowanymi.
Grupowanie
Klastrowanie to nienadzorowany model, który identyfikuje klastry na podstawie cech, atrybutów, cech itp.
Algorytmy ML
Drzewa decyzyjne
Drzewa decyzyjne wykorzystują podejście binarne, aby uzyskać rozwiązanie oparte na kolejnych pytaniach na każdym etapie, tak aby wynik był jednym z dwóch możliwych, takich jak „Tak” lub „Nie”. Drzewa decyzyjne są proste w implementacji i interpretacji.
Losowy Las lub Bagging
Random Forest to zaawansowany algorytm drzew decyzyjnych. Wykorzystuje dużą liczbę drzew decyzyjnych, co sprawia, że struktura jest gęsta i złożona jak las. Generuje wiele wyników, a tym samym prowadzi do dokładniejszych wyników i wydajności.
K — najbliższy sąsiad (KNN)
kNN wykorzystuje bliskość najbliższych punktów danych na wykresie względem nowego punktu danych, aby przewidzieć, do której kategorii należy. Nowy punkt danych zostaje przypisany do kategorii o większej liczbie sąsiadów.
k = liczba najbliższych sąsiadów
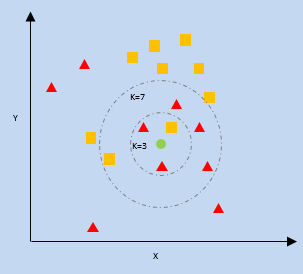
Naiwny Bayes
Naive Bayes pracuje na dwóch filarach, po pierwsze, że każda cecha punktów danych jest niezależna, niepowiązana ze sobą, tj. niepowtarzalna, a po drugie na twierdzeniu Bayesa, które przewiduje wyniki na podstawie warunku lub hipotezy.
Twierdzenie Bayesa:
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
Gdzie P(X|Y) = Warunkowe prawdopodobieństwo X przy danym wystąpieniu Y
P(Y|X) = Warunkowe prawdopodobieństwo Y przy wystąpieniu X
P(X), P(Y) = Prawdopodobieństwo wystąpienia X i Y indywidualnie
Wsparcie maszyn wektorowych
Algorytm ten próbuje segregować dane w przestrzeni na podstawie granic, którymi może być linia lub płaszczyzna. Granica ta nazywana jest „hiperpłaszczyzną” i jest definiowana przez najbliższe punkty danych każdej klasy, które z kolei nazywane są „wektorami nośnymi”. Maksymalna odległość między wektorami nośnymi po obu stronach nazywana jest marginesem.
Sieci neuronowe
Perceptron
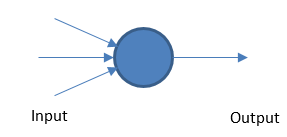
Podstawowa sieć neuronowa działa na podstawie ważonych danych wejściowych i wyjściowych na podstawie wartości progowej.
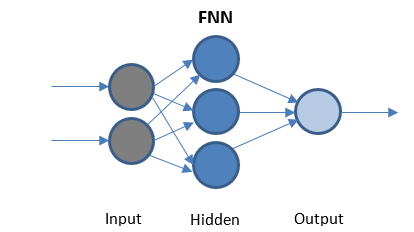
Feed Forward Sieć neuronowa
FFN to najprostsza sieć, która przesyła dane tylko w jednym kierunku. Może mieć ukryte warstwy lub nie.
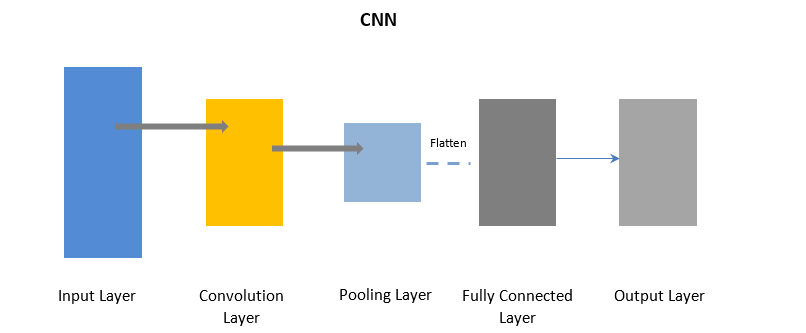
Konwolucyjne sieci neuronowe
CNN używa warstwy konwolucji do przetwarzania niektórych części danych wejściowych w partiach, a następnie warstwy puli w celu ukończenia danych wyjściowych.
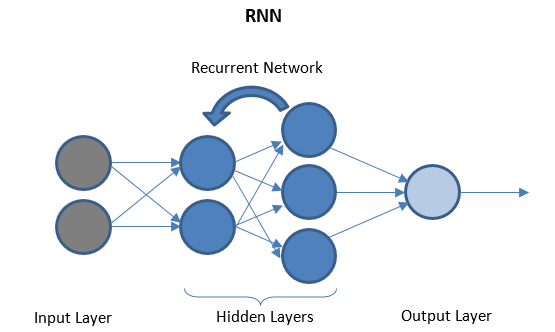
Rekurencyjne sieci neuronowe
RNN składa się z kilku powtarzających się warstw pomiędzy warstwami we/wy, które mogą przechowywać „historyczne” dane. Przepływ danych jest dwukierunkowy i jest podawany do warstw cyklicznych w celu poprawy prognoz.
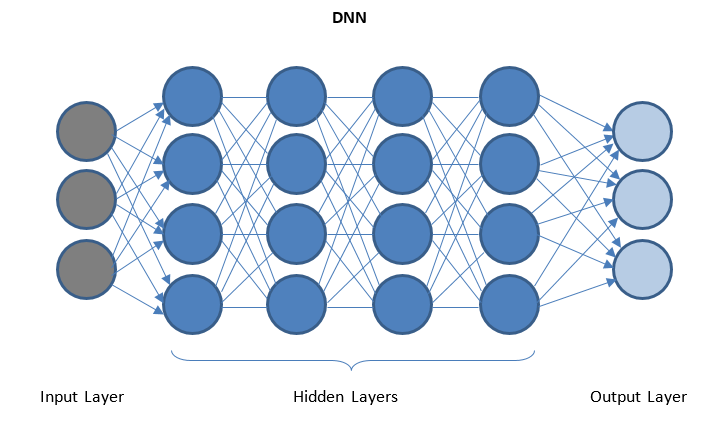
Głębokie sieci neuronowe i głębokie uczenie
DNN to sieć z wieloma ukrytymi warstwami między warstwami we/wy. Ukryte warstwy stosują kolejne przekształcenia danych przed wysłaniem ich do warstwy wyjściowej.
„Głębokie uczenie” jest ułatwione dzięki DNN i może obsługiwać ogromne ilości złożonych danych i osiągnąć wysoką dokładność dzięki wielu ukrytym warstwom
Uzyskaj certyfikat nauk o danych od najlepszych uniwersytetów na świecie. Naucz się programów Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Wniosek
Data science to rozległa dziedzina, która biegnie przez różne strumienie, ale jest dla nas rewolucją i objawieniem. Nauka o danych kwitnie i zmieni sposób, w jaki nasze systemy działają i działają w przyszłości.
Jeśli jesteś zainteresowany nauką o danych, sprawdź IIIT-B i upGrad's PG Diploma in Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, 1- on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Który język programowania najlepiej nadaje się do nauki o danych i dlaczego?
Istnieją dziesiątki języków programowania dla nauki o danych, ale większość społeczności zajmującej się nauką o danych uważa, że jeśli chcesz osiągnąć sukces w nauce o danych, Python jest właściwym wyborem. Poniżej znajdują się niektóre powody, które wspierają to przekonanie:
1. Python ma szeroką gamę modułów i bibliotek, takich jak TensorFlow i PyTorch, które ułatwiają radzenie sobie z koncepcjami data science.
2. Ogromna społeczność programistów Pythona stale pomaga nowicjuszom przejść do następnej fazy ich podróży do nauki o danych.
3. Ten język jest zdecydowanie jednym z najwygodniejszych i najłatwiejszych do pisania języków z przejrzystą składnią, która poprawia jego czytelność.
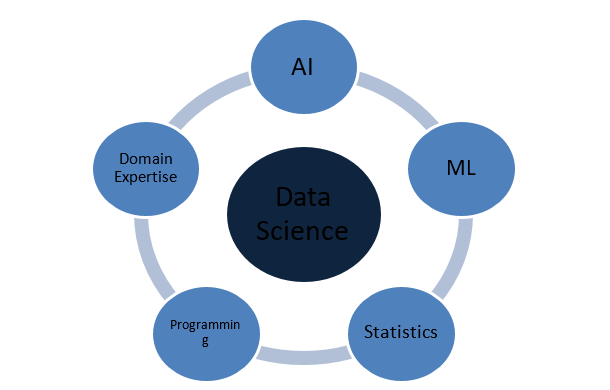
Jakie koncepcje sprawiają, że nauka o danych jest kompletna?
Data Science to rozległa dziedzina, która działa jak parasol dla różnych innych kluczowych dziedzin. Oto najważniejsze koncepcje składające się na naukę o danych:
Statystyka
Statystyka to ważna koncepcja, w której musisz się wyróżniać, aby iść naprzód w nauce o danych. Ponadto zawiera kilka tematów podrzędnych:
1. Regresja liniowa
2. Prawdopodobieństwo
3. Rozkład prawdopodobieństwa
Sztuczna inteligencja
Nauka zapewniająca maszynom mózg i pozwalająca im podejmować własne decyzje na podstawie danych wejściowych jest znana jako sztuczna inteligencja. Maszyny reaktywne, ograniczona pamięć, teoria umysłu i samoświadomość to tylko niektóre rodzaje sztucznej inteligencji.
Nauczanie maszynowe
Uczenie maszynowe to kolejny kluczowy element nauki o danych, który zajmuje się uczeniem maszyn w celu przewidywania przyszłych wyników na podstawie dostarczonych danych. Uczenie maszynowe ma trzy główne metody modelowania — klastrowanie, regresję i klasyfikację.
Opisać rodzaje uczenia maszynowego?
Uczenie maszynowe lub prosta ML ma trzy główne typy w oparciu o ich metody pracy. Są to następujące typy:
1. Uczenie się nadzorowane
Jest to najbardziej prymitywny typ ML, w którym dane wejściowe są oznakowane. Maszyna otrzymuje mniejszy zestaw danych, który daje jej wgląd w problem i jest w tym zakresie przeszkolony.
2. Nauka nienadzorowana
Największą zaletą tego typu jest to, że dane są tutaj nieoznaczone, a praca ludzka jest prawie znikoma. To otwiera bramę dla znacznie większych zestawów danych, które mają zostać wprowadzone do modelu.
3. Wzmocnione uczenie się Jest to najbardziej zaawansowany rodzaj uczenia się, który czerpie inspirację z życia ludzi. Pożądane wyjścia są wzmacniane, podczas gdy bezużyteczne wyjścia są zniechęcane.