
Wstępne przetwarzanie danych w uczeniu maszynowym: 7 łatwych kroków do wykonania
Opublikowany: 2021-07-15Wstępne przetwarzanie danych w uczeniu maszynowym to kluczowy krok, który pomaga poprawić jakość danych, aby promować wydobywanie znaczących spostrzeżeń z danych. Wstępne przetwarzanie danych w uczeniu maszynowym odnosi się do techniki przygotowywania (czyszczenia i organizowania) nieprzetworzonych danych, aby nadawały się do budowania i trenowania modeli uczenia maszynowego. Krótko mówiąc, wstępne przetwarzanie danych w uczeniu maszynowym to technika eksploracji danych, która przekształca surowe dane w zrozumiały i czytelny format.
Spis treści
Dlaczego wstępne przetwarzanie danych w uczeniu maszynowym?
Jeśli chodzi o tworzenie modelu uczenia maszynowego, wstępne przetwarzanie danych jest pierwszym krokiem oznaczającym rozpoczęcie procesu. Zazwyczaj dane ze świata rzeczywistego są niekompletne, niespójne, niedokładne (zawierają błędy lub wartości odstające) i często nie zawierają określonych wartości/trendów atrybutów. W tym miejscu do scenariusza wchodzi wstępne przetwarzanie danych — pomaga ono wyczyścić, sformatować i uporządkować nieprzetworzone dane, dzięki czemu są gotowe do użycia w modelach uczenia maszynowego. Przyjrzyjmy się różnym etapom wstępnego przetwarzania danych w uczeniu maszynowym.
Dołącz do kursu Sztucznej Inteligencji online z najlepszych światowych uniwersytetów — studiów magisterskich, programów podyplomowych dla kadry kierowniczej oraz zaawansowanego programu certyfikacji w zakresie uczenia maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
Etapy wstępnego przetwarzania danych w uczeniu maszynowym
Istnieje siedem ważnych etapów wstępnego przetwarzania danych w uczeniu maszynowym:
1. Zdobądź zbiór danych
Pozyskanie zestawu danych to pierwszy krok w procesie wstępnego przetwarzania danych w uczeniu maszynowym. Aby budować i rozwijać modele uczenia maszynowego, musisz najpierw uzyskać odpowiedni zestaw danych. Ten zbiór danych będzie składał się z danych zebranych z wielu różnych źródeł, które następnie zostaną połączone w odpowiednim formacie w celu utworzenia zbioru danych. Formaty zbiorów danych różnią się w zależności od przypadków użycia. Na przykład zbiór danych biznesowych będzie zupełnie inny niż zbiór danych medycznych. Podczas gdy zbiór danych biznesowych będzie zawierał odpowiednie dane branżowe i biznesowe, zbiór danych medycznych będzie zawierał dane związane z opieką zdrowotną.
Istnieje kilka źródeł online, z których można pobrać zestawy danych, takie jak https://www.kaggle.com/uciml/datasets i https://archive.ics.uci.edu/ml/index.php . Możesz również utworzyć zestaw danych, zbierając dane za pomocą różnych interfejsów API Pythona. Gdy zestaw danych jest gotowy, musisz umieścić go w formacie pliku CSV, HTML lub XLSX.

2. Importuj wszystkie kluczowe biblioteki
Ponieważ Python jest najszerzej używaną, a także najbardziej preferowaną biblioteką przez naukowców zajmujących się danymi na całym świecie, pokażemy Ci, jak importować biblioteki Pythona do wstępnego przetwarzania danych w uczeniu maszynowym. Przeczytaj więcej o bibliotekach Pythona dla Data Science tutaj. Predefiniowane biblioteki Pythona mogą wykonywać określone zadania wstępnego przetwarzania danych. Importowanie wszystkich kluczowych bibliotek to drugi etap wstępnego przetwarzania danych w uczeniu maszynowym. Trzy podstawowe biblioteki Pythona używane do tego wstępnego przetwarzania danych w uczeniu maszynowym to:
- NumPy — NumPy to podstawowy pakiet do obliczeń naukowych w Pythonie. Dlatego służy do wstawiania do kodu dowolnego rodzaju operacji matematycznej. Używając NumPy, możesz również dodawać do swojego kodu duże wielowymiarowe tablice i macierze.
- Pandas – Pandas to doskonała biblioteka Pythona typu open source do manipulacji i analizy danych. Jest szeroko stosowany do importowania i zarządzania zestawami danych. Zawiera wydajne, łatwe w użyciu struktury danych i narzędzia do analizy danych dla Pythona.
- Matplotlib – Matplotlib to biblioteka do kreślenia 2D Pythona, która służy do kreślenia dowolnego typu wykresów w Pythonie. Może dostarczać dane o jakości publikacji w wielu formatach papierowych i interaktywnych środowiskach na różnych platformach (powłoki IPython, notebooki Jupyter, serwery aplikacji internetowych itp.).
Przeczytaj : Pomysły na projekty uczenia maszynowego dla początkujących
3. Zaimportuj zbiór danych
W tym kroku musisz zaimportować zestawy danych, które zebrałeś dla danego projektu ML. Importowanie zestawu danych jest jednym z ważnych etapów wstępnego przetwarzania danych w uczeniu maszynowym. Jednak zanim będzie można zaimportować zestawy danych, należy ustawić bieżący katalog jako katalog roboczy. Możesz ustawić katalog roboczy w Spyder IDE w trzech prostych krokach:
- Zapisz plik Pythona w katalogu zawierającym zestaw danych.
- Przejdź do opcji Eksplorator plików w Spyder IDE i wybierz żądany katalog.
- Teraz kliknij przycisk F5 lub opcję Uruchom, aby uruchomić plik.
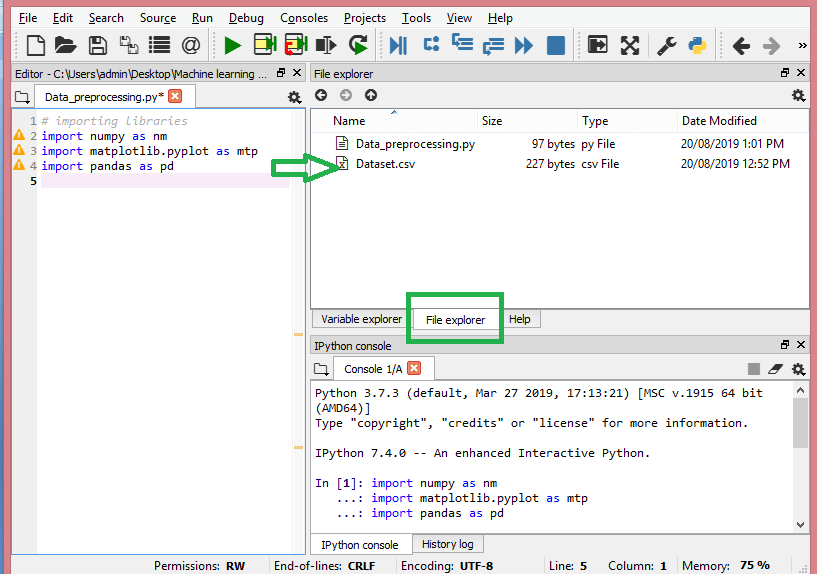
Źródło
Tak powinien wyglądać katalog roboczy.
Po ustawieniu katalogu roboczego zawierającego odpowiedni zestaw danych, możesz zaimportować zestaw danych za pomocą funkcji „read_csv()” biblioteki Pandas. Ta funkcja może odczytywać plik CSV (lokalnie lub przez adres URL), a także wykonywać na nim różne operacje. Read_csv() jest napisane jako:
data_set= pd.read_csv('Zbiór danych.csv')
W tym wierszu kodu „data_set” oznacza nazwę zmiennej, w której przechowywałeś zestaw danych. Funkcja zawiera również nazwę zbioru danych. Po wykonaniu tego kodu zestaw danych zostanie pomyślnie zaimportowany.
Podczas procesu importowania zestawu danych jest jeszcze jedna ważna rzecz, którą musisz zrobić – wyodrębnienie zmiennych zależnych i niezależnych. Dla każdego modelu uczenia maszynowego konieczne jest oddzielenie zmiennych niezależnych (macierz cech) i zmiennych zależnych w zestawie danych.
Rozważ ten zbiór danych:
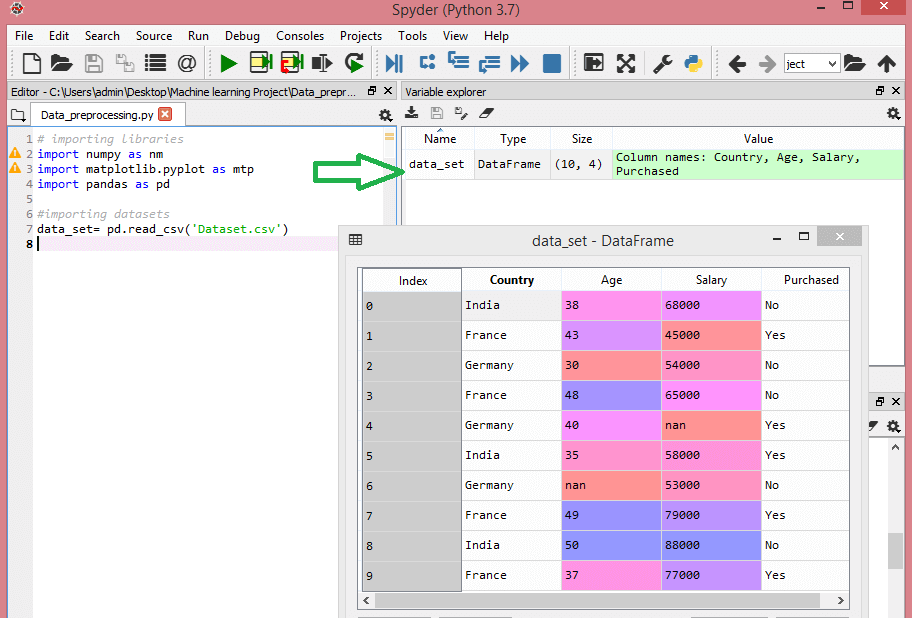
Źródło
Ten zbiór danych zawiera trzy zmienne niezależne – kraj, wiek i wynagrodzenie oraz jedną zmienną zależną – zakupioną.
Jak wyodrębnić zmienne niezależne?
Aby wyodrębnić zmienne niezależne, możesz użyć funkcji „iloc[ ]” z biblioteki Pandas. Ta funkcja może wyodrębnić wybrane wiersze i kolumny z zestawu danych.
x= zbiór_danych.iloc[:,:-1].wartości
W powyższym wierszu kodu pierwszy dwukropek(:) uwzględnia wszystkie wiersze, a drugi dwukropek(:) uwzględnia wszystkie kolumny. Kod zawiera „:-1”, ponieważ musisz pominąć ostatnią kolumnę zawierającą zmienną zależną. Wykonując ten kod uzyskasz matrycę funkcji, taką jak ta –
[['Indie' 38,0 68000,0]
[„Francja” 43,0 45000,0]
['Niemcy' 30,0 54000,0]
[„Francja” 48,0 65000,0]
['Niemcy' 40,0 nan]
['Indie' 35,0 58000,0]
[„Niemcy” na 53000.0]
[„Francja” 49,0 79000,0]
['Indie' 50,0 88000,0]
[„Francja” 37,0 77000,0]]
Jak wyodrębnić zmienną zależną?
Możesz również użyć funkcji „iloc[ ]”, aby wyodrębnić zmienną zależną. Oto jak to piszesz:
y= zbiór_danych.iloc[:,3].wartości
Ten wiersz kodu uwzględnia tylko wszystkie wiersze z ostatnią kolumną. Wykonując powyższy kod, otrzymasz tablicę zmiennych zależnych, jak na przykład –
array(['Nie', 'Tak', 'Nie', 'Nie', 'Tak', 'Tak', 'Nie', 'Tak', 'Nie', 'Tak'],
dtype=obiekt)
4. Identyfikacja i obsługa brakujących wartości
We wstępnym przetwarzaniu danych kluczowe znaczenie ma identyfikacja i poprawna obsługa brakujących wartości, w przeciwnym razie możesz wyciągnąć niedokładne i błędne wnioski i wnioski z danych. Nie trzeba dodawać, że utrudni to Twój projekt ML.
Zasadniczo istnieją dwa sposoby obsługi brakujących danych:
- Usuwanie określonego wiersza — w tej metodzie usuwasz określony wiersz, który ma wartość null dla funkcji lub określonej kolumny, w której brakuje ponad 75% wartości. Jednak ta metoda nie jest w 100% wydajna i zaleca się jej używanie tylko wtedy, gdy zbiór danych zawiera odpowiednie próbki. Musisz upewnić się, że po usunięciu danych nie pozostanie żadne dodanie stronniczości.
- Obliczanie średniej — ta metoda jest przydatna w przypadku obiektów posiadających dane liczbowe, takie jak wiek, wynagrodzenie, rok itp. W tym miejscu można obliczyć średnią, medianę lub tryb określonej funkcji lub kolumny lub wiersza, które zawierają brakującą wartość, i zastąpić wynik dla brakującej wartości. Ta metoda może zwiększyć wariancję zestawu danych, a każdą utratę danych można skutecznie zanegować. Daje więc lepsze wyniki w porównaniu z pierwszą metodą (pominięcie wierszy/kolumn). Innym sposobem przybliżenia jest odchylenie sąsiednich wartości. Jednak działa to najlepiej w przypadku danych liniowych.
Przeczytaj: Zastosowania aplikacji uczenia maszynowego za pomocą chmury
5. Kodowanie danych kategorycznych
Dane kategoryczne odnoszą się do informacji, które mają określone kategorie w zbiorze danych. W cytowanym powyżej zbiorze danych występują dwie zmienne kategoryczne – kraj i zakup.
Modele uczenia maszynowego opierają się głównie na równaniach matematycznych. W ten sposób możesz intuicyjnie zrozumieć, że utrzymywanie danych kategorycznych w równaniu spowoduje pewne problemy, ponieważ w równaniach będą potrzebne tylko liczby.
Jak zakodować zmienną country?
Jak widać w naszym przykładzie zestawu danych, kolumna country spowoduje problemy, więc musisz przekonwertować ją na wartości liczbowe. Aby to zrobić, możesz użyć klasy LabelEncoder() z biblioteki sci-kit Learn. Kod będzie wyglądał następująco –
#Dane kategoryczne
#dla zmiennej kraju
ze sklearn.preprocessing import LabelEncoder
label_encoder_x= Koder Etykiet()
x[:, 0]= koder_etykiety_x.fit_transform(x[:, 0])
A wynik będzie –
Out[15]:
tablica([[2, 38,0, 68000,0],
[0, 43,0, 45000,0],
[1, 30,0, 54000,0],
[0, 48,0, 65000,0],
[1, 40,0, 65222.222222222222],
[2, 35,0, 58000,0],
[1, 41.1111111111111114, 53000.0],
[0, 49,0, 79000,0],
[2, 50,0, 88000,0],
[0, 37,0, 77000,0]], dtype=obiekt)
Tutaj widzimy, że klasa LabelEncoder pomyślnie zakodowała zmienne na cyfry. Istnieją jednak zmienne kraju, które są zakodowane jako 0, 1 i 2 w danych wyjściowych pokazanych powyżej. Tak więc model ML może zakładać, że istnieje pewna korelacja między trzema zmiennymi, co skutkuje błędnymi wynikami. Aby wyeliminować ten problem, użyjemy teraz kodowania fikcyjnego.
Zmienne fikcyjne to takie, które przyjmują wartości 0 lub 1, wskazujące na brak lub obecność określonego kategorycznego efektu, który może przesunąć wynik. W tym przypadku wartość 1 wskazuje na obecność tej zmiennej w określonej kolumnie, podczas gdy pozostałe zmienne mają wartość 0. W kodowaniu fikcyjnym liczba kolumn jest równa liczbie kategorii.
Ponieważ nasz zestaw danych ma trzy kategorie, wygeneruje trzy kolumny o wartościach 0 i 1. W przypadku kodowania dummy użyjemy klasy OneHotEncoder z biblioteki scikit-learn. Kod wejściowy będzie następujący –
#dla zmiennej kraju
ze sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= Koder Etykiet()
x[:, 0]= koder_etykiety_x.fit_transform(x[:, 0])
#Kodowanie dla zmiennych fikcyjnych

onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
Po wykonaniu tego kodu otrzymasz następujące dane wyjściowe:
tablica([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.5000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.4000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.111111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
W przedstawionym powyżej wyniku wszystkie zmienne są podzielone na trzy kolumny i zakodowane w wartościach 0 i 1.
Jak zakodować zakupioną zmienną?
Dla drugiej zmiennej kategorialnej, czyli zakupionej, można użyć obiektu „labelencoder” klasy LabelEncoder. Nie używamy klasy OneHotEncoder, ponieważ zakupiona zmienna ma tylko dwie kategorie tak lub nie, z których obie są zakodowane jako 0 i 1.
Kod wejściowy dla tej zmiennej to –
labelencoder_y= koder etykiet()
y= koder_etykiet_y.fit_transform(y)
Wyjście będzie –
Out[17]: array([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
6. Dzielenie zbioru danych
Podział zbioru danych to kolejny krok we wstępnym przetwarzaniu danych w uczeniu maszynowym. Każdy zestaw danych dla modelu uczenia maszynowego musi być podzielony na dwa oddzielne zestawy — zestaw uczący i zestaw testowy.
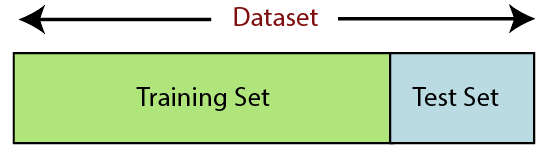
Źródło
Zestaw uczący oznacza podzbiór zestawu danych, który jest używany do uczenia modelu uczenia maszynowego. Tutaj jesteś już świadomy wyjścia. Z drugiej strony zestaw testowy jest podzbiorem zestawu danych używanym do testowania modelu uczenia maszynowego. Model ML używa zestawu testowego do przewidywania wyników.
Zazwyczaj zbiór danych jest podzielony na proporcje 70:30 lub 80:20. Oznacza to, że bierzesz 70% lub 80% danych do trenowania modelu, pomijając pozostałe 30% lub 20%. Proces podziału różni się w zależności od kształtu i rozmiaru danego zestawu danych.
Aby podzielić zbiór danych, musisz napisać następujący wiersz kodu –
ze sklearn.model_selection importuj train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
Tutaj pierwszy wiersz dzieli tablice zestawu danych na losowe podzbiory pociągów i testów. Druga linia kodu zawiera cztery zmienne:
- x_train – funkcje dla danych treningowych
- x_test – funkcje dla danych testowych
- y_train – zmienne zależne dla danych treningowych
- y_test – zmienna niezależna do testowania danych
Tak więc funkcja train_test_split() zawiera cztery parametry, z których pierwsze dwa dotyczą tablic danych. Funkcja test_size określa rozmiar zestawu testowego. Test_size może być .5, .3 lub .2 – to określa stosunek podziału między zbiorem uczącym i testowym. Ostatni parametr, „random_state” ustawia ziarno generatora losowego, dzięki czemu wyjście jest zawsze takie samo.
7. Skalowanie funkcji
Skalowanie funkcji oznacza koniec wstępnego przetwarzania danych w uczeniu maszynowym. Jest to metoda standaryzacji niezależnych zmiennych zbioru danych w określonym zakresie. Innymi słowy, skalowanie cech ogranicza zakres zmiennych, dzięki czemu można je porównać na wspólnych podstawach.
Rozważmy na przykład ten zbiór danych –
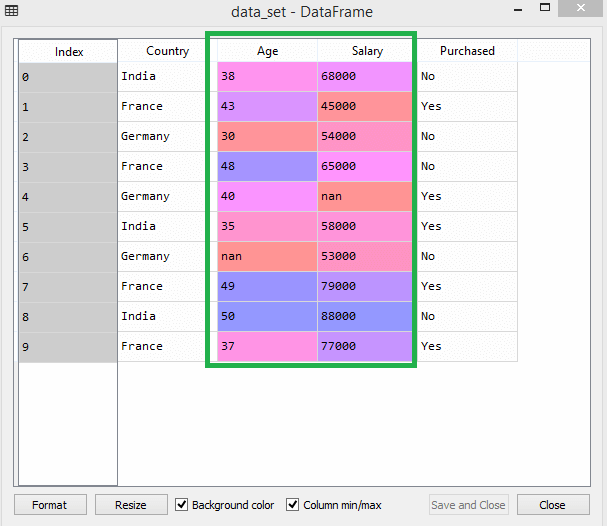
Źródło
W zestawie danych można zauważyć, że kolumny wieku i wynagrodzeń nie mają tej samej skali. W takim scenariuszu, jeśli obliczysz dowolne dwie wartości z kolumn wieku i wynagrodzenia, wartości wynagrodzenia zdominują wartości wieku i dadzą nieprawidłowe wyniki. W związku z tym należy usunąć ten problem, wykonując skalowanie funkcji dla uczenia maszynowego.
Większość modeli ML opiera się na odległości euklidesowej, która jest reprezentowana jako:
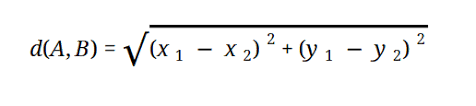
Źródło
Skalowanie funkcji w uczeniu maszynowym można przeprowadzić na dwa sposoby:
Normalizacja
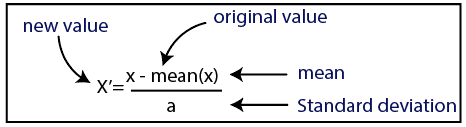
Źródło
Normalizacja
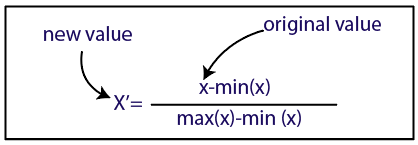
Źródło
Dla naszego zbioru danych użyjemy metody standaryzacji. W tym celu zaimportujemy klasę StandardScaler z biblioteki sci-kit-learn, używając następującego wiersza kodu:
ze sklearn.preprocessing import StandardScaler
Kolejnym krokiem będzie utworzenie obiektu klasy StandardScaler dla zmiennych niezależnych. Następnie możesz dopasować i przekształcić treningowy zestaw danych za pomocą następującego kodu:
st_x= Standardowy skaler()
x_train= st_x.fit_transform(x_train)
W przypadku testowego zestawu danych możesz bezpośrednio zastosować funkcję transform() (nie musisz używać funkcji fit_transform(), ponieważ jest to już zrobione w zestawie uczącym). Kod będzie wyglądał następująco –
x_test= st_x.transform(x_test)
Dane wyjściowe dla testowego zestawu danych pokażą przeskalowane wartości dla x_train i x_test jako:
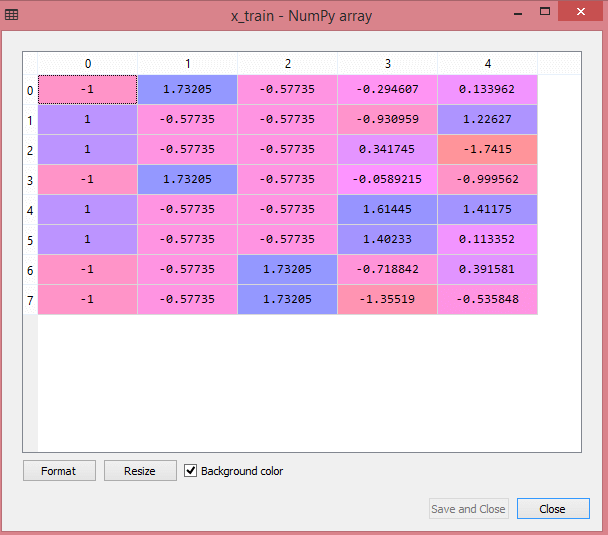
Źródło
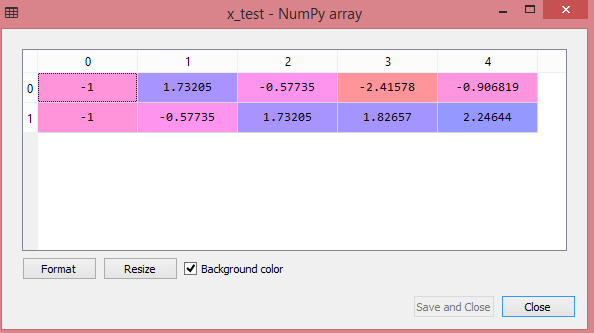
Źródło
Wszystkie zmienne na wyjściu są skalowane między wartościami -1 i 1.
Teraz, aby połączyć wszystkie kroki, które wykonaliśmy do tej pory, otrzymujesz:
# importowanie bibliotek
importuj numpy jako nm
importuj matplotlib.pyplot jako mtp
importuj pandy jako PD
#importowanie zbiorów danych
data_set= pd.read_csv('Zbiór danych.csv')
#Ekstrakcja zmiennej niezależnej
x= zbiór_danych.iloc[:, :-1].wartości
#Wyodrębnianie zmiennej zależnej
y= zbiór_danych.iloc[:, 3].wartości
#handling brakujących danych(Zastępowanie brakujących danych wartością średnią)
ze sklearn.preprocessing import Imputer
imputer= Imputer(brakujące_wartości ='NaN', strategy='średnia', oś = 0)
#Dopasowanie obiektu imputerowego do zmiennych niezależnych x.
imputerimputer= imputer.fit(x[:, 1:3])
#Zastępowanie brakujących danych obliczoną wartością średnią
x[:, 1:3]= imputer.transform(x[:, 1:3])
#dla zmiennej kraju
ze sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= Koder Etykiet()
x[:, 0]= koder_etykiety_x.fit_transform(x[:, 0])
#Kodowanie dla zmiennych fikcyjnych
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
#kodowanie dla zakupionej zmiennej
labelencoder_y= koder etykiet()
y= koder_etykiet_y.fit_transform(y)
# Podział zbioru danych na zbiór treningowy i testowy.
ze sklearn.model_selection importuj train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#Skalowanie funkcji zbiorów danych
ze sklearn.preprocessing import StandardScaler
st_x= Standardowy skaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
Tak w skrócie wygląda przetwarzanie danych w uczeniu maszynowym!
Możesz sprawdzić program Executive PG w IIT Delhi w zakresie uczenia maszynowego i sztucznej inteligencji we współpracy z upGrad . IIT Delhi to jedna z najbardziej prestiżowych instytucji w Indiach. Z większą liczbą ponad 500 wewnętrznych członków wydziału, którzy są najlepsi w tej dziedzinie.
Jakie znaczenie ma wstępne przetwarzanie danych?
Ponieważ błędy, nadmiarowość, brakujące wartości i niespójności zagrażają integralności zestawu danych, należy zająć się nimi wszystkimi, aby uzyskać dokładniejszy wynik. Załóżmy, że używasz wadliwego zestawu danych do trenowania systemu uczenia maszynowego do obsługi zakupów klientów. System prawdopodobnie będzie generował błędy i odchylenia, powodując złe wrażenia użytkownika. W rezultacie, zanim wykorzystasz te dane do zamierzonego celu, muszą one być tak zorganizowane i „czyste” jak to tylko możliwe. W zależności od rodzaju trudności, z jakim masz do czynienia, istnieje wiele opcji.
Co to jest czyszczenie danych?
Prawie na pewno w Twoich zbiorach danych będą brakujące i zaszumione dane. Ponieważ procedura zbierania danych nie jest idealna, będziesz mieć wiele bezużytecznych i brakujących informacji. Czyszczenie danych to sposób, w jaki powinieneś poradzić sobie z tym problemem. Można to podzielić na dwie kategorie. Pierwsza z nich omawia, jak radzić sobie z brakującymi danymi. Możesz zignorować brakujące wartości w tej sekcji zbierania danych (nazywanej krotką). Druga metoda czyszczenia danych dotyczy danych, które są zaszumione. Bardzo ważne jest pozbycie się bezużytecznych danych, których systemy nie mogą odczytać, jeśli chcesz, aby cały proces przebiegał płynnie.
Co rozumiesz przez transformację i redukcję danych?
Wstępne przetwarzanie danych przechodzi do etapu transformacji po rozwiązaniu problemów. Używasz go do konwersji danych na odpowiednie konformacje do analizy. Normalizacja, wybór atrybutów, dyskretyzacja i generowanie hierarchii koncepcji to tylko niektóre z podejść, które można zastosować, aby to osiągnąć. Nawet w przypadku metod zautomatyzowanych przeszukiwanie dużych zbiorów danych może zająć dużo czasu. Dlatego etap redukcji danych jest tak ważny: zmniejsza rozmiar zbiorów danych, ograniczając je do najważniejszych informacji, zwiększając wydajność przechowywania przy jednoczesnym obniżeniu kosztów finansowych i czasowych pracy z nimi.