
Ramki danych w Pythonie: szczegółowy samouczek Pythona 2022
Opublikowany: 2021-01-09Jeśli jesteś programistą lub programistą pracującym w języku programowania Python, musisz znać jedną z najbardziej niesamowitych bibliotek do zarządzania danymi – Pandas, jedną z najlepszych dostępnych bibliotek Pythona. Z biegiem lat Pandas stała się standardowym narzędziem do analizy i zarządzania danymi za pomocą Pythona. Przeczytaj o innych ważnych narzędziach Pythona.
Pandas to bez wątpienia najbardziej wszechstronny pakiet Pythona do nauki o danych i słusznie. Zapewnia potężne, ekspresyjne i elastyczne struktury danych do łatwej manipulacji i analizy danych, a ramki danych w Pythonie są jedną z tych struktur.
To jest dokładnie nasz temat do dyskusji w tym poście – przedstawimy Wam podstawowy format danych dla Pand, czyli Pandy Data Frame.
Spis treści
Co to jest ramka danych?
Zgodnie z dokumentacją biblioteki Pandas , Data Frame jest „dwuwymiarową, zmienną rozmiarem, potencjalnie heterogeniczną tabelaryczną strukturą danych z oznaczonymi osiami (wierszami i kolumnami)”. Mówiąc prościej, Data Frame to struktura danych, w której dane są wyrównane w sposób tabelaryczny, to znaczy w wierszach i kolumnach.
Ramka danych ma zwykle następujące cechy:
- Może mieć wiele wierszy i kolumn.
- Chociaż każdy wiersz reprezentuje próbkę danych, każda kolumna zawiera inną zmienną opisującą próbki (wiersze).
- Dane w każdej kolumnie to zazwyczaj dane tego samego typu (na przykład liczby, ciągi, daty itp.).
- W przeciwieństwie do zestawów danych programu Excel unika brakujących wartości, dzięki czemu między wierszami lub kolumnami nie ma przerw ani pustych wartości.
W ramce danych Pandy możesz również określić nazwy indeksów i kolumn dla ramki danych. Podczas gdy indeks wskazuje różnicę w wierszach, nazwy kolumn pokazują różnicę w kolumnach.
Jak utworzyć ramkę danych w Pythonie (przy użyciu Pand)
Stworzenie ramki danych jest pierwszym krokiem do przeładowania danych w Pythonie. Możesz utworzyć ramkę danych Pandy, używając danych wejściowych, takich jak:
- dykt
- Listy
- Seria
- Numpy „ndarray”
- Kolejna ramka danych
- Pliki zewnętrzne, takie jak CS
- Tworzenie pustej ramki danych
Bardzo łatwo jest stworzyć podstawową ramkę danych, czyli pustą ramkę danych. Oto przykład:
Wejście -

Wyjście -

- Tworzenie ramki danych z list
Ramkę danych można utworzyć przy użyciu jednej lub wielu list.
Wejście -

Wyjście -

- Tworzenie ramki danych z dyktatu „ndarrays” lub list
Aby utworzyć ramkę danych z dyktatu ndarray, wszystkie ndarray muszą mieć tę samą długość. Ponadto, jeśli jest indeksowany, długość indeksu powinna być równa długości tablic. Jeśli jednak nie jest indeksowany, domyślnie indeks będzie miał postać range(n), gdzie 'n' oznacza długość tablicy.
Wejście -

Wyjście -

Tutaj wartości 0,1,2,3 są domyślnym indeksem przypisanym do każdego wiersza za pomocą funkcji range(n).
Jakie są podstawowe operacje na ramkach danych?
Teraz, gdy poznaliśmy już trzy sposoby tworzenia ramek danych w Pythonie, nadszedł czas, aby poznać różne operacje na ramkach danych.
- Wybieranie indeksu lub kolumny z ramki danych Pandy
Ważne jest, aby wiedzieć, jak wybrać indeks lub kolumnę, zanim zaczniesz dodawać, usuwać i zmieniać nazwy składników w DataFrame. Załóżmy, że to jest Twoja ramka danych:

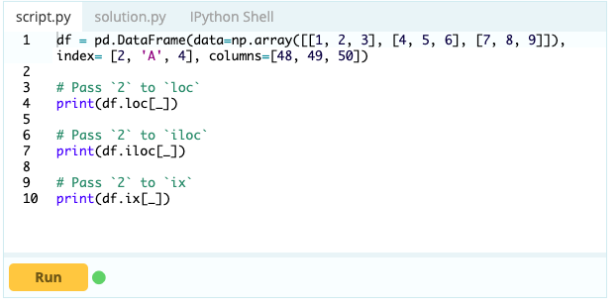
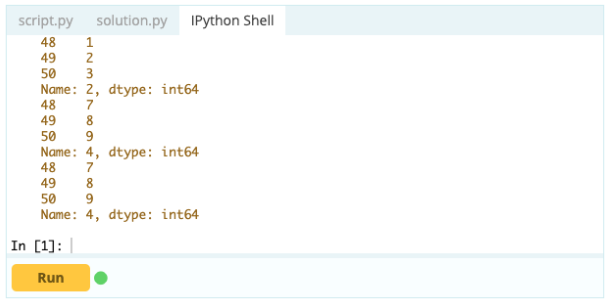
Chcesz uzyskać dostęp do wartości pod indeksem 0 w kolumnie 'A' – wartość wynosi 1. Jest wiele sposobów uzyskania dostępu do tej wartości, ale dwa z najważniejszych to – .loc[] i .iloc[].
Wejście -
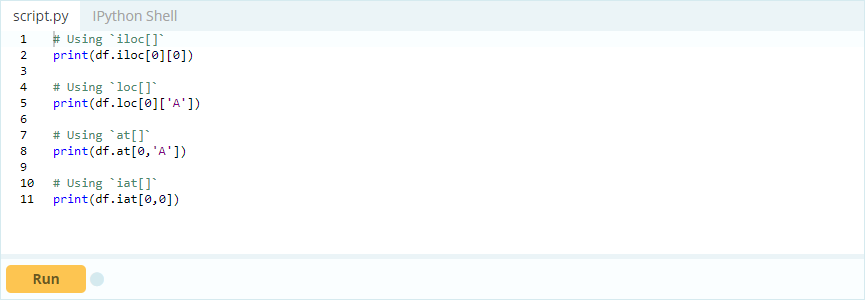
Wyjście -
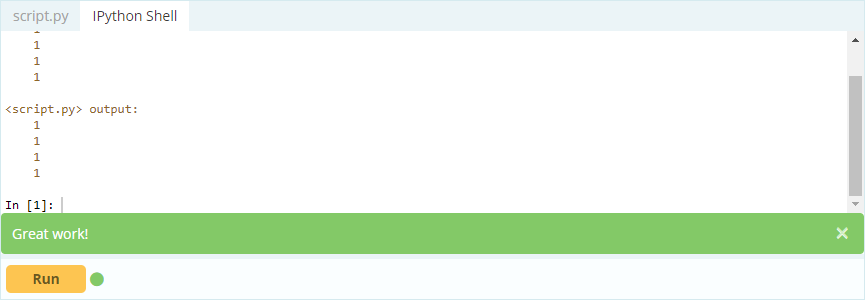
Tak więc, jak widać, możesz uzyskać dostęp do wartości, wywołując je według ich etykiety lub deklarując ich pozycję w indeksie lub kolumnie. Chociaż było to wybieranie wartości z ramki danych, jak możesz wybrać wiersze i kolumny z tego samego?
Oto jak:
Wejście -
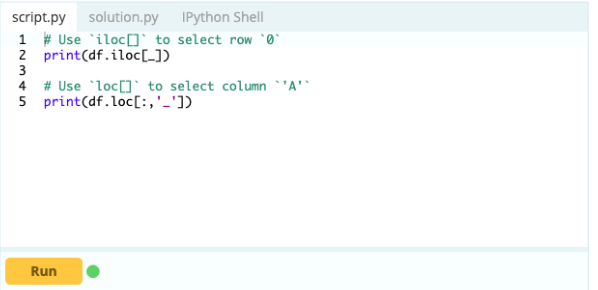
Wyjście-
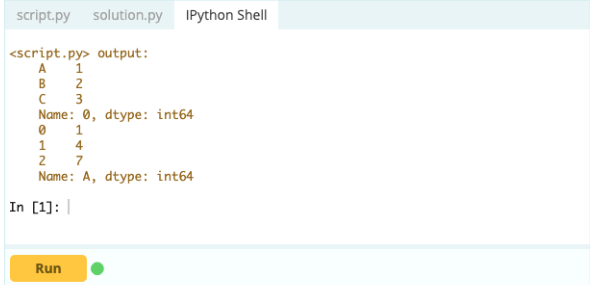
- Jak dodać indeks, wiersz lub kolumnę do ramki danych Pandas
Gdy nauczysz się, jak uzyskać dostęp do wartości i wybrać kolumny z ramki danych, możesz nauczyć się dodawać indeks, wiersz lub kolumnę w ramce danych Pandy.
Dodawanie indeksu:
Podczas tworzenia ramki danych możesz dodać dane wejściowe do argumentu „indeks”. Zapewnia to łatwy dostęp do żądanego indeksu. Jeśli nie określisz indeksu, domyślnie zostanie do niego dodany indeks o wartościach liczbowych, który zaczyna się od 0 i jest kontynuowany do ostatniego wiersza DataFrame. Chociaż nawet po domyślnym określeniu indeksu można użyć kolumny i przekonwertować ją na indeks, wywołując funkcję set_index() w ramce danych.

Dodawanie wiersza:
Możesz dodać wiersze do DataFrame za pomocą funkcji append.
Wejście -

Wyjście -

Możesz także użyć .loc, aby wstawić wiersze do ramki DataFrame w następujący sposób:
Wejście -
Wyjście -
Dodawanie kolumny
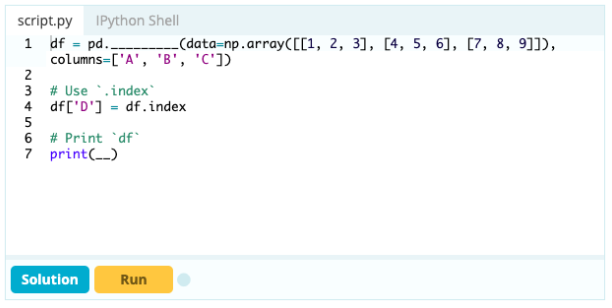
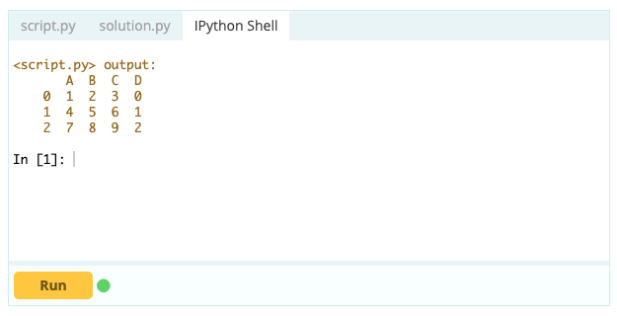
Jeśli chcesz, aby indeks był częścią ramki danych, możesz pobrać kolumnę z ramki danych lub odwołać się do kolumny, która nie została jeszcze utworzona, i przypisać ją do właściwości .index w następujący sposób:
Wejście -
Wyjście -
W przypadku dodawania kolumn do ramki danych można również użyć tego samego podejścia, którego używa się do dodawania indeksu do ramki danych, czyli można użyć funkcji .loc[ ] lub .iloc[ ]. Na przykład:
Wejście -
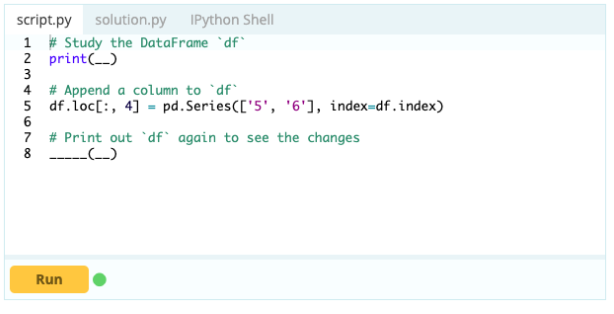
Wyjście
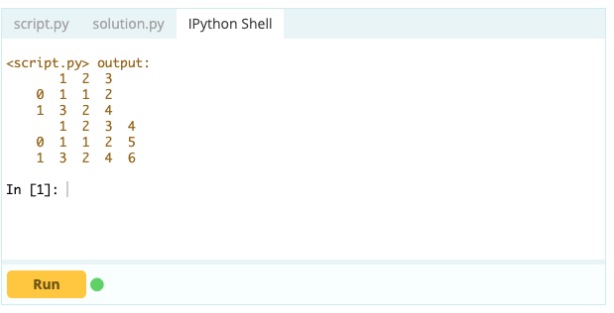
Za pomocą .loc[] możesz dodać serię do istniejącej ramki DataFrame. Ponieważ obiekt serii jest dość podobny do kolumny ramki danych, bardzo łatwo jest dodać serię do istniejącej ramki danych.
- Jak zresetować indeks ramki danych?
Możesz zresetować indeks ramki danych, jeśli nie wygląda zgodnie z oczekiwaniami. W tym celu możesz użyć funkcji .reset_index().
Wejście -
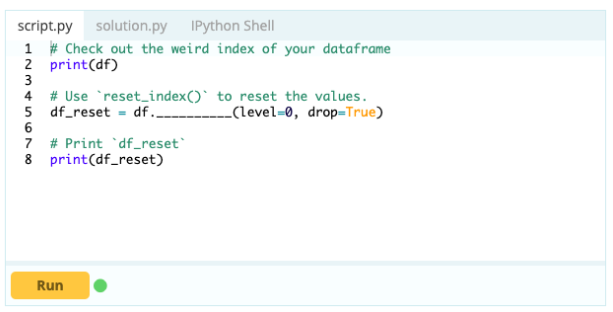
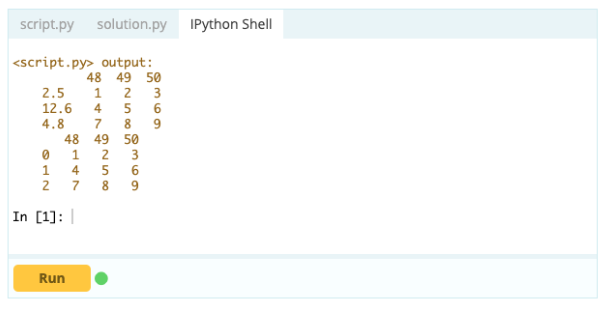
Wyjście -
- Jak usunąć indeks, wiersz lub kolumnę do ramki danych Pandas
Usuwanie indeksu
- Resetowanie indeksu ramki danych.
- Usuń nazwę indeksu (jeśli istnieje) za pomocą funkcji del df.index.name.
- Usuń indeks wraz z wierszem.
- Usuń wszystkie zduplikowane wartości indeksu, resetując indeks, upuszczając duplikaty kolumny indeksu, która została dodana do ramki danych, i ponownie przywracając nową kolumnę (pozbawioną zduplikowanego indeksu) jako indeks.
Usuwanie kolumny
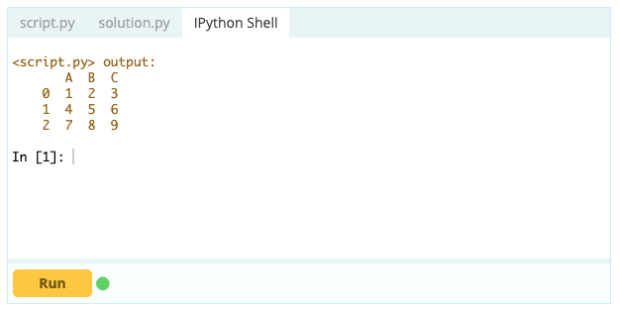
Aby usunąć kolumny z ramki danych, możesz użyć funkcji drop().
Wejście -
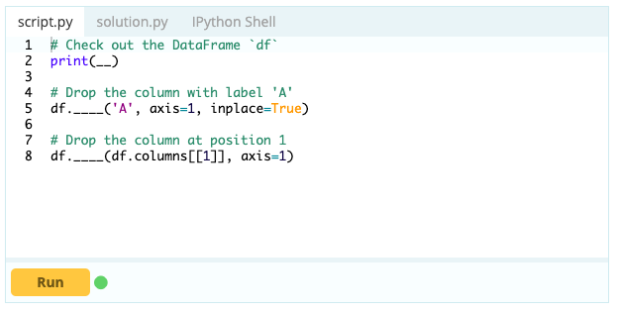
Wyjście -
Usuwanie wiersza
Aby usunąć wiersz z ramki danych, możesz użyć funkcji drop(), używając właściwości index do określenia indeksu wierszy, które chcesz usunąć z ramki DataFrame.
Wejście -
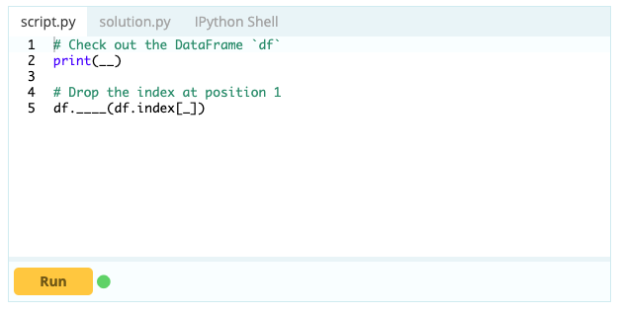
Wyjście -
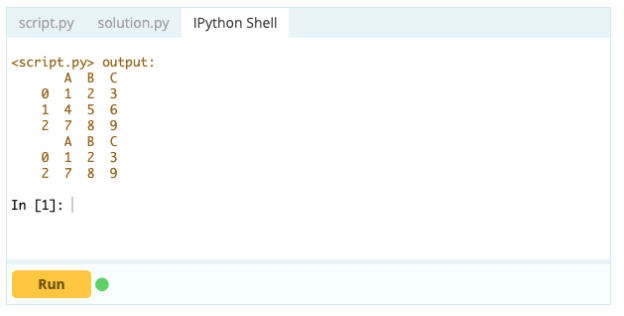
Aby jednak usunąć zduplikowane wiersze, możesz użyć funkcji df.drop_duplicates().
Wejście -
Wyjście -
Źródła: Tutorialspoint Datacamp
Wniosek
Oto twój podstawowy samouczek dotyczący ramki danych w Pythonie za pomocą Pand.
Jeśli jesteś zainteresowany nauką Pythona, data science, sprawdź IIIT-B i upGrad's PG Diploma in Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, Indywidualnie z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Dlaczego Pandas jest jedną z najbardziej preferowanych bibliotek do tworzenia ramek danych w Pythonie?
Biblioteka Pandas jest uważana za najlepiej nadającą się do tworzenia ramek danych, ponieważ zapewnia różne funkcje, które sprawiają, że tworzenie ramek danych jest wydajne. Niektóre z tych cech są następujące: Pandy dostarczają nam różnych ramek danych, które nie tylko pozwalają na wydajną reprezentację danych, ale także umożliwiają nam manipulowanie nimi. Zapewnia wydajne funkcje wyrównywania i indeksowania, które zapewniają inteligentne sposoby etykietowania i organizowania danych. Niektóre cechy Pand sprawiają, że kod jest czysty i zwiększa jego czytelność, dzięki czemu jest bardziej wydajny. Może również czytać wiele formatów plików. JSON, CSV, HDF5 i Excel to tylko niektóre z formatów plików obsługiwanych przez Pandy. Łączenie wielu zestawów danych było prawdziwym wyzwaniem dla wielu programistów. Pandy również to przezwyciężają i bardzo skutecznie łączą wiele zestawów danych.
Jakie są inne biblioteki i narzędzia, które uzupełniają bibliotekę Pandy?
Pandas działa nie tylko jako centralna biblioteka do tworzenia ramek danych, ale współpracuje również z innymi bibliotekami i narzędziami Pythona, aby być bardziej wydajnym. Pandas jest zbudowany na pakiecie NumPy Python, co wskazuje, że większość struktury biblioteki Pandas jest replikowana z pakietu NumPy. Analiza statystyczna danych w bibliotece Pandas jest obsługiwana przez SciPy, wykreślanie funkcji w Matplotlib, a algorytmy uczenia maszynowego w Scikit-learn. Jupyter Notebook to interaktywne środowisko internetowe, które działa jako środowisko IDE i oferuje dobre środowisko dla Pand.
Jakie są podstawowe operacje na ramkach danych?
Wybór indeksu lub kolumny przed rozpoczęciem jakiejkolwiek operacji, takiej jak dodawanie lub usuwanie, jest ważne. Gdy nauczysz się, jak uzyskać dostęp do wartości i wybrać kolumny z ramki danych, możesz nauczyć się dodawać indeks, wiersz lub kolumnę w ramce danych Pandas. Jeśli indeks w ramce danych nie jest zgodny z oczekiwaniami, możesz go zresetować. Aby zresetować indeks, możesz użyć funkcji „reset_index()”.