
„Twórz raz, publikuj wszędzie” z WordPress
Opublikowany: 2022-03-10COPE to strategia zmniejszenia ilości pracy potrzebnej do publikowania naszych treści na różnych nośnikach, takich jak strona internetowa, poczta e-mail, aplikacje i inne. Po raz pierwszy zapoczątkowany przez NPR, osiąga swój cel, ustanawiając jedno źródło prawdy dla treści, które można wykorzystać we wszystkich różnych mediach.
Posiadanie treści, które działają wszędzie, nie jest trywialnym zadaniem, ponieważ każde medium ma swoje własne wymagania. Na przykład, podczas gdy HTML jest odpowiedni do drukowania treści w Internecie, ten język nie jest odpowiedni dla aplikacji na iOS/Android. Podobnie możemy dodać klasy do naszego HTML dla sieci, ale muszą one zostać przekonwertowane na style dla wiadomości e-mail.
Rozwiązaniem tej zagadki jest oddzielenie formy od treści: prezentacja i znaczenie treści muszą być oddzielone, a tylko znaczenie jest używane jako jedyne źródło prawdy. Prezentację można następnie dodać na innej warstwie (specyficznej dla wybranego medium).
Na przykład, biorąc pod uwagę następujący fragment kodu HTML, <p> jest znacznikiem HTML, który ma zastosowanie głównie w Internecie, a atrybut class="align-center" to prezentacja (umieszczenie elementu „na środku” ma sens w przypadku medium oparte na ekranie, ale nie na nośniku dźwiękowym, takim jak Amazon Alexa):
<p class="align-center">Hello world!</p>Dlatego ten fragment treści nie może być używany jako pojedyncze źródło prawdy i musi zostać przekonwertowany na format oddzielający znaczenie od prezentacji, taki jak następujący fragment kodu JSON:
{ content: "Hello world!", placement: "center", type: "paragraph" }Ten fragment kodu może być wykorzystany jako jedyne źródło prawdy dla treści, ponieważ z niego możemy ponownie odtworzyć kod HTML do wykorzystania w sieci i uzyskać odpowiedni format dla innych mediów.
Dlaczego WordPress
WordPress idealnie nadaje się do realizacji strategii COPE z kilku powodów:
- Jest wszechstronny.
Model bazy danych WordPress nie definiuje stałego, sztywnego modelu treści; wręcz przeciwnie, został stworzony z myślą o wszechstronności, umożliwiając tworzenie zróżnicowanych modeli treści za pomocą metapola, które pozwalają na przechowywanie dodatkowych danych dla czterech różnych podmiotów: postów i niestandardowych typów postów, użytkowników, komentarzy i taksonomii ( tagi i kategorie). - Jest potężny.
WordPress błyszczy jak CMS (Content Management System), a jego ekosystem wtyczek umożliwia łatwe dodawanie nowych funkcjonalności. - Jest szeroko rozpowszechniony.
Szacuje się, że 1/3 stron internetowych działa na WordPressie. Wtedy spora liczba osób pracujących w sieci wie o WordPressie i potrafi z niego korzystać. Nie tylko programiści, ale także blogerzy, sprzedawcy, personel marketingowy i tak dalej. Wtedy wielu różnych interesariuszy, bez względu na ich zaplecze techniczne, będzie mogło tworzyć treści, które będą stanowić jedyne źródło prawdy. - Jest bezgłowy.
Headlessness to zdolność do oddzielenia treści od warstwy prezentacji i jest to podstawowa cecha wdrażania COPE (aby móc przesyłać dane do różnych mediów).
Od czasu włączenia WP REST API do rdzenia, począwszy od wersji 4.7, a jeszcze wyraźniej od uruchomienia Gutenberga w wersji 5.0 (dla którego trzeba było zaimplementować wiele punktów końcowych API REST), WordPress można uznać za bezgłowy CMS, ponieważ większość treści WordPress można uzyskać dostęp za pośrednictwem interfejsu API REST przez dowolną aplikację zbudowaną na dowolnym stosie.
Ponadto niedawno utworzony WPGraphQL integruje WordPress i GraphQL, umożliwiając przesyłanie treści z WordPressa do dowolnej aplikacji za pomocą tego coraz popularniejszego interfejsu API. Wreszcie, mój własny projekt PoP dodał niedawno implementację API dla WordPressa, która pozwala na eksport danych WordPressa w natywnych formatach REST, GraphQL lub PoP. - Zawiera Gutenberg , edytor blokowy, który znacznie pomaga w implementacji COPE, ponieważ opiera się na koncepcji bloków (jak wyjaśniono w poniższych sekcjach).
Obiekty Blob kontra bloki do reprezentowania informacji
Blob to pojedyncza jednostka informacji przechowywana razem w bazie danych. Na przykład pisanie poniższego posta na blogu w systemie CMS, który opiera się na obiektach blob do przechowywania informacji, spowoduje przechowywanie treści posta na blogu w jednym wpisie w bazie danych — zawierającym tę samą treść:
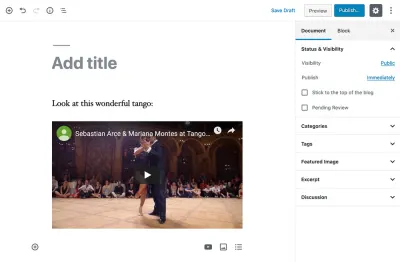
<p>Look at this wonderful tango:</p> <figure> <iframe width="951" height="535" src="https://www.youtube.com/embed/sxm3Xyutc1s" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> <figcaption>An exquisite tango performance</figcaption> </figure>Jak można docenić, ważne fragmenty informacji z tego posta na blogu (takie jak treść w akapicie i adres URL, wymiary i atrybuty filmu z YouTube) nie są łatwo dostępne: Jeśli chcemy odzyskać którąkolwiek z nich sami musimy przeanalizować kod HTML, aby je wyodrębnić — co jest dalekie od idealnego rozwiązania.
Bloki działają inaczej. Reprezentując informacje jako listę bloków, możemy przechowywać zawartość w bardziej semantyczny i przystępny sposób. Każdy blok zawiera własną treść i własne właściwości, które mogą zależeć od jego typu (np. czy jest to akapit czy wideo?).
Na przykład powyższy kod HTML może być reprezentowany jako lista bloków w następujący sposób:
{ [ type: "paragraph", content: "Look at this wonderful tango:" ], [ type: "embed", provider: "Youtube", url: "https://www.youtube.com/embed/sxm3Xyutc1s", width: 951, height: 535, frameborder: 0, allowfullscreen: true, allow: "accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture", caption: "An exquisite tango performance" ] } Dzięki takiemu sposobowi przedstawiania informacji możemy z łatwością wykorzystać każdy fragment danych samodzielnie i dostosować go do konkretnego nośnika, na którym ma być wyświetlany. Na przykład, jeśli chcemy wyodrębnić wszystkie filmy z wpisu na blogu, aby wyświetlić je w samochodowym systemie rozrywki, możemy po prostu iterować wszystkie bloki informacji, wybrać te z type="embed" i provider="Youtube" i wyodrębnić URL z nich. Podobnie, jeśli chcemy pokazać wideo na Apple Watch, nie musimy dbać o wymiary wideo, więc możemy w prosty sposób zignorować atrybuty width i height .
Jak Gutenberg wdraża bloki
Przed wersją 5.0 WordPressa WordPress używał obiektów blob do przechowywania treści postów w bazie danych. Począwszy od wersji 5.0, WordPress jest dostarczany z Gutenbergiem, edytorem blokowym, umożliwiającym ulepszony sposób przetwarzania wspomnianych wyżej treści, co stanowi przełom w kierunku wdrożenia COPE. Niestety, Gutenberg nie został zaprojektowany dla tego konkretnego przypadku użycia, a jego reprezentacja informacji różni się od tej opisanej dla bloków, co skutkuje kilkoma niedogodnościami, z którymi będziemy musieli sobie poradzić.
Przyjrzyjmy się najpierw, jak opisany powyżej post na blogu jest zapisywany przez Gutenberga:
<!-- wp:paragraph --> <p>Look at this wonderful tango:</p> <!-- /wp:paragraph --> <!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} --> <figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio"> <div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div> <figcaption>An exquisite tango performance</figcaption> </figure> <!-- /wp:core-embed/youtube -->Z tego fragmentu kodu możemy poczynić następujące obserwacje:
Bloki są zapisywane razem w tym samym wpisie bazy danych
W powyższym kodzie znajdują się dwa bloki:
<!-- wp:paragraph --> <p>Look at this wonderful tango:</p> <!-- /wp:paragraph --> <!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} --> <figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio"> <div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div> <figcaption>An exquisite tango performance</figcaption> </figure> <!-- /wp:core-embed/youtube --> Z wyjątkiem bloków globalnych (zwanych również „wielokrotnego użytku”), które mają własny wpis w bazie danych i można się do nich odwoływać bezpośrednio poprzez ich identyfikatory, wszystkie bloki są zapisywane razem we wpisie wpisu na blogu w tabeli wp_posts .
W związku z tym, aby pobrać informacje dla konkretnego bloku, najpierw musimy przeanalizować zawartość i odizolować wszystkie bloki od siebie. Dogodnie WordPress udostępnia funkcję parse_blocks($content) , która właśnie to robi. Ta funkcja odbiera ciąg znaków zawierający treść wpisu na blogu (w formacie HTML) i zwraca obiekt JSON zawierający dane dla wszystkich zawartych bloków.
Typ bloku i atrybuty są przekazywane za pomocą komentarzy HTML
Każdy blok jest ograniczony znacznikiem początkowym <!-- wp:{block-type} {block-attributes-encoded-as-JSON} --> i znacznikiem końcowym <!-- /wp:{block-type} --> które (jako komentarze HTML) zapewniają, że informacje te nie będą widoczne podczas wyświetlania ich na stronie internetowej. Nie możemy jednak wyświetlić posta na blogu bezpośrednio na innym nośniku, ponieważ komentarz HTML może być widoczny i wyglądać jak zniekształcona treść. Nie jest to jednak wielka sprawa, ponieważ po przeanalizowaniu treści za pomocą funkcji parse_blocks($content) komentarze HTML są usuwane i możemy operować bezpośrednio z danymi bloku jako obiektem JSON.
Bloki zawierają HTML
Blok akapitowy zawiera w treści "<p>Look at this wonderful tango:</p>" , zamiast "Look at this wonderful tango:" . W związku z tym zawiera kod HTML (tagi <p> i </p> ), który nie jest przydatny dla innych mediów i jako taki musi zostać usunięty, na przykład za pomocą funkcji PHP strip_tags($content) .
Podczas usuwania znaczników możemy zachować te znaczniki HTML, które wyraźnie przekazują informacje semantyczne, takie jak znaczniki <strong> i <em> (zamiast ich odpowiedników <b> i <i> , które mają zastosowanie tylko do nośnika ekranowego) oraz usuń wszystkie inne tagi. Dzieje się tak, ponieważ istnieje duża szansa, że znaczniki semantyczne mogą być poprawnie zinterpretowane również dla innych mediów (np. Amazon Alexa potrafi rozpoznawać znaczniki <strong> i <em> i odpowiednio zmieniać ich głos i intonację podczas czytania fragmentu tekstu). Aby to zrobić, wywołujemy funkcję strip_tags z drugim parametrem zawierającym dozwolone tagi i umieszczamy ją w funkcji zawijania dla wygody:
function strip_html_tags($content) { return strip_tags($content, '<strong><em>'); }Podpis filmu jest zapisywany w kodzie HTML, a nie jako atrybut
Jak widać w bloku wideo YouTube, podpis "An exquisite tango performance" jest przechowywany w kodzie HTML (zawartym w tagu <figcaption /> ), ale nie w obiekcie atrybutów zakodowanym w formacie JSON. W konsekwencji, aby wyodrębnić podpis, będziemy musieli przeanalizować zawartość bloku, na przykład za pomocą wyrażenia regularnego:
function extract_caption($content) { $matches = []; preg_match('/<figcaption>(.*?)<\/figcaption>/', $content, $matches); if ($caption = $matches[1]) { return strip_html_tags($caption); } return null; }Jest to przeszkoda, którą musimy pokonać, aby wyodrębnić wszystkie metadane z bloku Gutenberga. Dzieje się to na kilku blokach; ponieważ nie wszystkie fragmenty metadanych są zapisywane jako atrybuty, musimy najpierw zidentyfikować te fragmenty metadanych, a następnie przeanalizować zawartość HTML, aby wyodrębnić je blok po bloku i kawałek po kawałku.
W przypadku COPE oznacza to zmarnowaną szansę na uzyskanie naprawdę optymalnego rozwiązania. Można argumentować, że opcja alternatywna również nie jest idealna, ponieważ powielałaby informacje, przechowując je zarówno w kodzie HTML, jak i jako atrybut, co narusza zasadę DRY (nie powtarzaj siebie). Jednak to naruszenie już ma miejsce: na przykład atrybut className zawiera wartość "wp-embed-aspect-16-9 wp-has-aspect-ratio" , która jest również drukowana wewnątrz treści, pod atrybutem HTML class .
Wdrażanie COPE
Uwaga: udostępniłem tę funkcję, w tym cały kod opisany poniżej, jako wtyczkę do WordPressa Block Metadata. Możesz go zainstalować i bawić się nim, abyś mógł posmakować mocy COPE. Kod źródłowy jest dostępny w tym repozytorium GitHub.
Teraz, gdy wiemy już, jak wygląda wewnętrzna reprezentacja bloku, przejdźmy do implementacji COPE poprzez Gutenberga. Procedura będzie obejmować następujące kroki:
- Ponieważ funkcja
parse_blocks($content)zwraca obiekt JSON z zagnieżdżonymi poziomami, musimy najpierw uprościć tę strukturę. - Iterujemy wszystkie bloki i dla każdego identyfikujemy ich fragmenty metadanych i wyodrębniamy je, przekształcając je w procesie do formatu niezależnego od medium. Atrybuty dodawane do odpowiedzi mogą się różnić w zależności od typu bloku.
- W końcu udostępniamy dane poprzez API (REST/GraphQL/PoP).
Zaimplementujmy te kroki jeden po drugim.
1. Uproszczenie struktury obiektu JSON
Zwrócony obiekt JSON z funkcji parse_blocks($content) ma architekturę zagnieżdżoną, w której dane dla normalnych bloków pojawiają się na pierwszym poziomie, ale brakuje danych dla przywoływanego bloku wielokrotnego użytku (dodawane są tylko dane dla bloku odniesienia), a dane dla bloków zagnieżdżonych (które są dodawane w ramach innych bloków) oraz dla bloków zgrupowanych (gdzie kilka bloków może być zgrupowanych razem) pojawiają się na 1 lub więcej podpoziomach. Taka architektura utrudnia przetwarzanie danych blokowych ze wszystkich bloków w treści posta, ponieważ z jednej strony brakuje niektórych danych, az drugiej nie wiemy a priori, na ilu poziomach znajdują się dane. Dodatkowo w każdej parze bloków umieszczony jest dzielnik bloków, który nie zawiera żadnej treści, którą można spokojnie zignorować.
Na przykład odpowiedź uzyskana z postu zawierającego prosty blok, globalny blok, zagnieżdżony blok zawierający prosty blok i grupę prostych bloków, w tej kolejności, jest następująca:
[ // Simple block { "blockName": "core/image", "attrs": { "id": 70, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n" ] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Reference to reusable block { "blockName": "core/block", "attrs": { "ref": 218 }, "innerBlocks": [], "innerHTML": "", "innerContent": [] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Nested block { "blockName": "core/columns", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/column", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/image", "attrs": { "id": 69, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/column", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/paragraph", "attrs": [], "innerBlocks": [], "innerHTML": "\n<p>This is how I wake up every morning</p>\n", "innerContent": [ "\n<p>This is how I wake up every morning</p>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n", "innerContent": [ "\n<div class=\"wp-block-columns\">", null, "\n\n", null, "</div>\n" ] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Block group { "blockName": "core/group", "attrs": [], // Contained grouped blocks "innerBlocks": [ { "blockName": "core/image", "attrs": { "id": 71, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerBlocks": [], "innerHTML": "\n<p>Second element of the group</p>\n", "innerContent": [ "\n<p>Second element of the group</p>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n", "innerContent": [ "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">", null, "\n\n", null, "</div></div>\n" ] } ]Lepszym rozwiązaniem jest posiadanie wszystkich danych na pierwszym poziomie, dzięki czemu logika iteracji wszystkich danych bloku jest znacznie uproszczona. Dlatego musimy pobrać dane dla tych bloków wielokrotnego użytku / zagnieżdżonych / zgrupowanych i dodać je również na pierwszym poziomie. Jak widać w powyższym kodzie JSON:
- Pusty blok rozdzielający ma atrybut
"blockName"o wartościNULL - Odniesienie do bloku wielokrotnego użytku jest zdefiniowane przez
$block["attrs"]["ref"] - Bloki zagnieżdżone i grupowe definiują swoje bloki zawarte w
$block["innerBlocks"]
Dlatego poniższy kod PHP usuwa puste bloki rozdzielające, identyfikuje bloki wielokrotnego użytku/zagnieżdżone/grupowane i dodaje ich dane do pierwszego poziomu oraz usuwa wszystkie dane ze wszystkich podpoziomów:
/** * Export all (Gutenberg) blocks' data from a WordPress post */ function get_block_data($content, $remove_divider_block = true) { // Parse the blocks, and convert them into a single-level array $ret = []; $blocks = parse_blocks($content); recursively_add_blocks($ret, $blocks); // Maybe remove blocks without name if ($remove_divider_block) { $ret = remove_blocks_without_name($ret); } // Remove 'innerBlocks' property if it exists (since that code was copied to the first level, it is currently duplicated) foreach ($ret as &$block) { unset($block['innerBlocks']); } return $ret; } /** * Remove the blocks without name, such as the empty block divider */ function remove_blocks_without_name($blocks) { return array_values(array_filter( $blocks, function($block) { return $block['blockName']; } )); } /** * Add block data (including global and nested blocks) into the first level of the array */ function recursively_add_blocks(&$ret, $blocks) { foreach ($blocks as $block) { // Global block: add the referenced block instead of this one if ($block['attrs']['ref']) { $ret = array_merge( $ret, recursively_render_block_core_block($block['attrs']) ); } // Normal block: add it directly else { $ret[] = $block; } // If it contains nested or grouped blocks, add them too if ($block['innerBlocks']) { recursively_add_blocks($ret, $block['innerBlocks']); } } } /** * Function based on `render_block_core_block` */ function recursively_render_block_core_block($attributes) { if (empty($attributes['ref'])) { return []; } $reusable_block = get_post($attributes['ref']); if (!$reusable_block || 'wp_block' !== $reusable_block->post_type) { return []; } if ('publish' !== $reusable_block->post_status || ! empty($reusable_block->post_password)) { return []; } return get_block_data($reusable_block->post_content); } Wywołując funkcję get_block_data($content) przekazującą treść posta ( $post->post_content ) jako parametr, otrzymujemy teraz następującą odpowiedź:
[[ { "blockName": "core/image", "attrs": { "id": 70, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n", "innerContent": [ "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n" ] }, { "blockName": "core/columns", "attrs": [], "innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n", "innerContent": [ "\n<div class=\"wp-block-columns\">", null, "\n\n", null, "</div>\n" ] }, { "blockName": "core/column", "attrs": [], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/image", "attrs": { "id": 69, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n" ] }, { "blockName": "core/column", "attrs": [], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>This is how I wake up every morning</p>\n", "innerContent": [ "\n<p>This is how I wake up every morning</p>\n" ] }, { "blockName": "core/group", "attrs": [], "innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n", "innerContent": [ "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">", null, "\n\n", null, "</div></div>\n" ] }, { "blockName": "core/image", "attrs": { "id": 71, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>Second element of the group</p>\n", "innerContent": [ "\n<p>Second element of the group</p>\n" ] } ] Chociaż nie jest to bezwzględnie konieczne, bardzo pomocne jest utworzenie punktu końcowego interfejsu API REST w celu wyświetlenia wyniku naszej nowej funkcji get_block_data($content) , która pozwoli nam łatwo zrozumieć, jakie bloki są zawarte w konkretnym poście i w jaki sposób zbudowany. Poniższy kod dodaje taki punkt końcowy w /wp-json/block-metadata/v1/data/{POST_ID} :

/** * Define REST endpoint to visualize a post's block data */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'data/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_blocks' ]); }); function get_post_blocks($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $response = new WP_REST_Response($block_data); $response->set_status(200); return $response; }/** * Define REST endpoint to visualize a post's block data */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'data/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_blocks' ]); }); function get_post_blocks($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $response = new WP_REST_Response($block_data); $response->set_status(200); return $response; }
Aby zobaczyć to w akcji, sprawdź ten link, który eksportuje dane dla tego posta.
2. Wyodrębnienie wszystkich metadanych bloku do formatu średnio niezależnego
Na tym etapie mamy dane blokowe zawierające kod HTML, który nie jest odpowiedni dla COPE. Dlatego musimy usunąć niesemantyczne znaczniki HTML dla każdego bloku, aby przekonwertować go na format średnio niezależny.
Możemy zdecydować, które atrybuty muszą być wyodrębnione na podstawie typu bloku według typu bloku (na przykład wyodrębnij właściwość wyrównania tekstu dla bloków "paragraph" , właściwość adresu URL wideo dla bloku "youtube embed" itd.) .
Jak widzieliśmy wcześniej, nie wszystkie atrybuty są faktycznie zapisywane jako atrybuty bloku, ale w wewnętrznej treści bloku, dlatego w takich sytuacjach będziemy musieli przeanalizować zawartość HTML za pomocą wyrażeń regularnych, aby wyodrębnić te fragmenty metadanych.
Po sprawdzeniu wszystkich bloków dostarczonych przez rdzeń WordPressa postanowiłem nie wyodrębniać metadanych dla następujących:
"core/columns""core/column""core/cover" | Odnoszą się one tylko do mediów opartych na ekranie i (będąc blokami zagnieżdżonymi) są trudne do pokonania. |
"core/html" | Ten ma sens tylko w sieci. |
"core/table""core/button""core/media-text" | Nie miałem pojęcia, jak przedstawić ich dane w sposób średnio-agnostyczny, a nawet czy ma to sens. |
Pozostaje mi to z następującymi blokami, dla których przejdę do wyodrębnienia ich metadanych:
-
'core/paragraph' -
'core/image' -
'core-embed/youtube'(jako przedstawiciel wszystkich bloków'core-embed') -
'core/heading' -
'core/gallery' -
'core/list' -
'core/audio' -
'core/file' -
'core/video' -
'core/code' -
'core/preformatted' -
'core/quote'i'core/pullquote' -
'core/verse'
Aby wyodrębnić metadane, tworzymy funkcję get_block_metadata($block_data) , która otrzymuje tablicę z danymi bloku dla każdego bloku (tj. wyjście z naszej wcześniej zaimplementowanej funkcji get_block_data ) oraz, w zależności od typu bloku (podanej we właściwości "blockName" ), decyduje o tym, jakie atrybuty są wymagane i jak je wyodrębnić:
/** * Process all (Gutenberg) blocks' metadata into a medium-agnostic format from a WordPress post */ function get_block_metadata($block_data) { $ret = []; foreach ($block_data as $block) { $blockMeta = null; switch ($block['blockName']) { case ...: $blockMeta = ... break; case ...: $blockMeta = ... break; ... } if ($blockMeta) { $ret[] = [ 'blockName' => $block['blockName'], 'meta' => $blockMeta, ]; } } return $ret; }Przejdźmy do wyodrębniania metadanych dla każdego typu bloku, jeden po drugim:
“core/paragraph”
Po prostu usuń tagi HTML z treści i usuń końcowe linie nieciągłości.
case 'core/paragraph': $blockMeta = [ 'content' => trim(strip_html_tags($block['innerHTML'])), ]; break; 'core/image'
Blok ma identyfikator odnoszący się do przesłanego pliku multimedialnego lub, jeśli nie, źródło obrazu musi zostać wyodrębnione z <img src="..."> . Kilka atrybutów (podpis, linkDestination, link, wyrównanie) jest opcjonalnych.
case 'core/image': $blockMeta = []; // If inserting the image from the Media Manager, it has an ID if ($block['attrs']['id'] && $img = wp_get_attachment_image_src($block['attrs']['id'], $block['attrs']['sizeSlug'])) { $blockMeta['img'] = [ 'src' => $img[0], 'width' => $img[1], 'height' => $img[2], ]; } elseif ($src = extract_image_src($block['innerHTML'])) { $blockMeta['src'] = $src; } if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } if ($linkDestination = $block['attrs']['linkDestination']) { $blockMeta['linkDestination'] = $linkDestination; if ($link = extract_link($block['innerHTML'])) { $blockMeta['link'] = $link; } } if ($align = $block['attrs']['align']) { $blockMeta['align'] = $align; } break; Sensowne jest tworzenie funkcji extract_image_src , extract_caption i extract_link , ponieważ ich wyrażenia regularne będą używane wielokrotnie dla kilku bloków. Zwróć uwagę, że podpis w języku Gutenberg może zawierać linki ( <a href="..."> ), jednak podczas wywoływania strip_html_tags są one usuwane z podpisu.
Chociaż godne ubolewania, uważam tę praktykę za nieuniknioną, ponieważ nie możemy zagwarantować linku do pracy na platformach innych niż web. Co za tym idzie, chociaż treści zyskują na uniwersalności, ponieważ mogą być wykorzystywane na różnych nośnikach, to jednocześnie tracą na specyficzności, przez co ich jakość jest gorsza w porównaniu z treścią, która została stworzona i dostosowana do konkretnej platformy.
function extract_caption($innerHTML) { $matches = []; preg_match('/<figcaption>(.*?)<\/figcaption>/', $innerHTML, $matches); if ($caption = $matches[1]) { return strip_html_tags($caption); } return null; } function extract_link($innerHTML) { $matches = []; preg_match('/<a href="(.*?)">(.*?)<\/a>>', $innerHTML, $matches); if ($link = $matches[1]) { return $link; } return null; } function extract_image_src($innerHTML) { $matches = []; preg_match('/<img src="(.*?)"/', $innerHTML, $matches); if ($src = $matches[1]) { return $src; } return null; } 'core-embed/youtube'
Po prostu pobierz adres URL wideo z atrybutów bloku i wyodrębnij jego podpis z treści HTML, jeśli istnieje.
case 'core-embed/youtube': $blockMeta = [ 'url' => $block['attrs']['url'], ]; if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } break; 'core/heading'
Zarówno rozmiar nagłówka (h1, h2, …, h6), jak i tekst nagłówka nie są atrybutami, więc muszą być uzyskane z treści HTML. Zwróć uwagę, że zamiast zwracać tag HTML dla nagłówka, atrybut size jest po prostu równoważną reprezentacją, która jest bardziej agnostyczna i ma większy sens w przypadku platform innych niż internetowe.
case 'core/heading': $matches = []; preg_match('/<h[1-6])>(.*?)<\/h([1-6])>/', $block['innerHTML'], $matches); $sizes = [ null, 'xxl', 'xl', 'l', 'm', 'sm', 'xs', ]; $blockMeta = [ 'size' => $sizes[$matches[1]], 'heading' => $matches[2], ]; break; 'core/gallery'
Niestety w przypadku galerii obrazów nie udało mi się wyodrębnić podpisów z każdego obrazu, ponieważ nie są to atrybuty, a wyodrębnienie ich za pomocą prostego wyrażenia regularnego może się nie powieść: Jeśli istnieje podpis dla pierwszego i trzeciego elementu, ale żaden dla drugi, wtedy nie wiedziałbym, który podpis odpowiada jakiemu obrazowi (a nie poświęciłem czasu na stworzenie złożonego wyrażenia regularnego). Podobnie w poniższej logice zawsze pobieram "full" rozmiar obrazu, jednak nie musi tak być i nie jestem świadomy, jak można wywnioskować bardziej odpowiedni rozmiar.
case 'core/gallery': $imgs = []; foreach ($block['attrs']['ids'] as $img_id) { $img = wp_get_attachment_image_src($img_id, 'full'); $imgs[] = [ 'src' => $img[0], 'width' => $img[1], 'height' => $img[2], ]; } $blockMeta = [ 'imgs' => $imgs, ]; break; 'core/list'
Po prostu przekształć elementy <li> w tablicę elementów.
case 'core/list': $matches = []; preg_match_all('/<li>(.*?)<\/li>/', $block['innerHTML'], $matches); if ($items = $matches[1]) { $blockMeta = [ 'items' => array_map('strip_html_tags', $items), ]; } break; 'core/audio'
Uzyskaj adres URL odpowiedniego przesłanego pliku multimedialnego.
case 'core/audio': $blockMeta = [ 'src' => wp_get_attachment_url($block['attrs']['id']), ]; break; 'core/file'
Podczas gdy adres URL pliku jest atrybutem, jego tekst musi zostać wyodrębniony z wewnętrznej treści.
case 'core/file': $href = $block['attrs']['href']; $matches = []; preg_match('/<a href="'.str_replace('/', '\/', $href).'">(.*?)<\/a>/', $block['innerHTML'], $matches); $blockMeta = [ 'href' => $href, 'text' => strip_html_tags($matches[1]), ]; break; 'core/video'
Uzyskaj adres URL filmu i wszystkie właściwości, aby skonfigurować sposób odtwarzania filmu za pomocą wyrażenia regularnego. Jeśli Gutenberg kiedykolwiek zmieni kolejność, w jakiej te właściwości są drukowane w kodzie, to wyrażenie regularne przestanie działać, co świadczy o jednym z problemów związanych z niedodawaniem metadanych bezpośrednio przez atrybuty bloku.
case 'core/video': $matches = []; preg_match('/ 'core/code'
Simply extract the code from within <code /> .
case 'core/code': $matches = []; preg_match('/<code>(.*?)<\/code>/is', $block['innerHTML'], $matches); $blockMeta = [ 'code' => $matches[1], ]; break; 'core/preformatted'
Similar to <code /> , but we must watch out that Gutenberg hardcodes a class too.
case 'core/preformatted': $matches = []; preg_match('/<pre class="wp-block-preformatted">(.*?)<\/pre>/is', $block['innerHTML'], $matches); $blockMeta = [ 'text' => strip_html_tags($matches[1]), ]; break; 'core/quote' and 'core/pullquote'
We must convert all inner <p /> tags to their equivalent generic "\n" character.
case 'core/quote': case 'core/pullquote': $matches = []; $regexes = [ 'core/quote' => '/<blockquote class=\"wp-block-quote\">(.*?)<\/blockquote>/', 'core/pullquote' => '/<figure class=\"wp-block-pullquote\"><blockquote>(.*?)<\/blockquote><\/figure>/', ]; preg_match($regexes[$block['blockName']], $block['innerHTML'], $matches); if ($quoteHTML = $matches[1]) { preg_match_all('/<p>(.*?)<\/p>/', $quoteHTML, $matches); $blockMeta = [ 'quote' => strip_html_tags(implode('\n', $matches[1])), ]; preg_match('/<cite>(.*?)<\/cite>/', $quoteHTML, $matches); if ($cite = $matches[1]) { $blockMeta['cite'] = strip_html_tags($cite); } } break; 'core/verse'
Similar situation to <pre /> .
case 'core/verse': $matches = []; preg_match('/<pre class="wp-block-verse">(.*?)<\/pre>/is', $block['innerHTML'], $matches); $blockMeta = [ 'text' => strip_html_tags($matches[1]), ]; break;3. Exporting Data Through An API
Now that we have extracted all block metadata, we need to make it available to our different mediums, through an API. WordPress has access to the following APIs:
- REST, through the WP REST API (integrated in WordPress core)
- GraphQL, through WPGraphQL
- PoP, through its implementation for WordPress
Let's see how to export the data through each of them.
ODPOCZYNEK
The following code creates endpoint /wp-json/block-metadata/v1/metadata/{POST_ID} which exports all block metadata for a specific post:
/** * Define REST endpoints to export the blocks' metadata for a specific post */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'metadata/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_block_meta' ]); }); function get_post_block_meta($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); $response = new WP_REST_Response($block_metadata); $response->set_status(200); return $response; }/** * Define REST endpoints to export the blocks' metadata for a specific post */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'metadata/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_block_meta' ]); }); function get_post_block_meta($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); $response = new WP_REST_Response($block_metadata); $response->set_status(200); return $response; }
To see it working, this link (corresponding to this blog post) displays the metadata for blocks of all the types analyzed earlier on.
GraphQL (Through WPGraphQL)
GraphQL works by setting-up schemas and types which define the structure of the content, from which arises this API's power to fetch exactly the required data and nothing else. Setting-up schemas works very well when the structure of the object has a unique representation.
In our case, however, the metadata returned by a new field "block_metadata" (which calls our newly-created function get_block_metadata ) depends on the specific block type, so the structure of the response can vary wildly; GraphQL provides a solution to this issue through a Union type, allowing to return one among a set of different types. However, its implementation for all different variations of the metadata structure has proved to be a lot of work, and I quit along the way .
As an alternative (not ideal) solution, I decided to provide the response by simply encoding the JSON object through a new field "jsonencoded_block_metadata" :
/** * Define WPGraphQL field "jsonencoded_block_metadata" */ add_action('graphql_register_types', function() { register_graphql_field( 'Post', 'jsonencoded_block_metadata', [ 'type' => 'String', 'description' => __('Post blocks encoded as JSON', 'wp-graphql'), 'resolve' => function($post) { $post = get_post($post->ID); $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); return json_encode($block_metadata); } ] ); });PoP
Note: This functionality is available on its own GitHub repo.
The final API is called PoP, which is a little-known project I've been working on for several years now. I have recently converted it into a full-fledged API, with the capacity to produce a response compatible with both REST and GraphQL, and which even benefits from the advantages from these 2 APIs, at the same time: no under/over-fetching of data, like in GraphQL, while being cacheable on the server-side and not susceptible to DoS attacks, like REST. It offers a mix between the two of them: REST-like endpoints with GraphQL-like queries.
The block metadata is made available through the API through the following code:
class PostFieldValueResolver extends AbstractDBDataFieldValueResolver { public static function getClassesToAttachTo(): array { return array(\PoP\Posts\FieldResolver::class); } public function resolveValue(FieldResolverInterface $fieldResolver, $resultItem, string $fieldName, array $fieldArgs = []) { $post = $resultItem; switch ($fieldName) { case 'block-metadata': $block_data = \Leoloso\BlockMetadata\Data::get_block_data($post->post_content); $block_metadata = \Leoloso\BlockMetadata\Metadata::get_block_metadata($block_data); // Filter by blockName if ($blockName = $fieldArgs['blockname']) { $block_metadata = array_filter( $block_metadata, function($block) use($blockName) { return $block['blockName'] == $blockName; } ); } return $block_metadata; } return parent::resolveValue($fieldResolver, $resultItem, $fieldName, $fieldArgs); } }To see it in action, this link displays the block metadata (+ ID, title and URL of the post, and the ID and name of its author, a la GraphQL) for a list of posts.
Dodatkowo, podobnie jak w przypadku argumentów GraphQL, nasze zapytanie można dostosować za pomocą argumentów pola, dzięki czemu można uzyskać tylko te dane, które mają sens dla konkretnej platformy. Na przykład, jeśli chcemy wyodrębnić wszystkie filmy z YouTube dodane do wszystkich postów, możemy dodać modyfikator (blockname:core-embed/youtube) do pola block-metadata w adresie URL punktu końcowego, tak jak w tym łączu. Lub jeśli chcemy wyodrębnić wszystkie obrazy z określonego postu, możemy dodać modyfikator (blockname:core/image) , jak w tym innym linku|id|tytule).
Wniosek
Strategia COPE („Utwórz raz, opublikuj wszędzie”) pomaga nam zmniejszyć ilość pracy potrzebnej do stworzenia kilku aplikacji, które muszą działać na różnych nośnikach (sieci, poczta e-mail, aplikacje, asystenci domowi, rzeczywistość wirtualna itp.) poprzez stworzenie jednego źródła prawdy dla naszej treści. W przypadku WordPressa, mimo że zawsze błyszczał jako system zarządzania treścią, wdrożenie strategii COPE w przeszłości okazało się wyzwaniem.
Jednak kilka ostatnich wydarzeń sprawiło, że wdrożenie tej strategii dla WordPressa stało się coraz bardziej wykonalne. Z jednej strony, od czasu integracji z rdzeniem WP REST API, a zwłaszcza od uruchomienia Gutenberga, większość treści WordPress jest dostępna za pośrednictwem interfejsów API, dzięki czemu jest to prawdziwy system bezgłowy. Z drugiej strony Gutenberg (który jest nowym domyślnym edytorem treści) jest oparty na blokach, dzięki czemu wszystkie metadane w poście na blogu są łatwo dostępne dla interfejsów API.
W konsekwencji wdrożenie COPE dla WordPressa jest proste. W tym artykule zobaczyliśmy, jak to zrobić, a cały odpowiedni kod został udostępniony za pośrednictwem kilku repozytoriów. Mimo że rozwiązanie nie jest optymalne (ponieważ wymaga dużej ilości parsowania kodu HTML), nadal działa całkiem dobrze, co powoduje, że wysiłek potrzebny do wydania naszych aplikacji na wiele platform może zostać znacznie zmniejszony. Uznanie za to!