
Tworzenie przepływu pracy testu ciągłej integracji za pomocą akcji GitHub
Opublikowany: 2022-03-10Przy współudziale w projektach na platformach kontroli wersji, takich jak GitHub i Bitbucket, konwencja jest taka, że istnieje główna gałąź zawierająca funkcjonalną bazę kodu. Są też inne gałęzie, w których kilku programistów może pracować na kopiach głównej, aby dodać nową funkcję, naprawić błąd i tak dalej. Ma to sens, ponieważ łatwiej jest monitorować wpływ, jaki nadchodzące zmiany będą miały na istniejący kod. Jeśli wystąpi jakikolwiek błąd, można go łatwo prześledzić i naprawić przed włączeniem zmian do głównej gałęzi. Ręczne przeszukiwanie każdego wiersza kodu w poszukiwaniu błędów lub błędów może być czasochłonne — nawet w przypadku małego projektu. Tu właśnie pojawia się ciągła integracja.
Co to jest ciągła integracja (CI)?
„Ciągła integracja (CI) to praktyka automatyzacji integracji zmian kodu od wielu współtwórców w jeden projekt oprogramowania”.
— Atlassian.com
Ogólną ideą stojącą za ciągłą integracją (CI) jest zapewnienie, że zmiany wprowadzone w projekcie nie „uszkodzą kompilacji”, czyli zrujnują istniejącą bazę kodu. Wdrażanie ciągłej integracji w projekcie, w zależności od konfiguracji przepływu pracy, spowoduje utworzenie kompilacji za każdym razem, gdy ktoś dokona zmian w repozytorium.
Więc co to jest kompilacja?
Kompilacja — w tym kontekście — to kompilacja kodu źródłowego do formatu wykonywalnego. Jeśli się powiedzie, oznacza to, że nadchodzące zmiany nie wpłyną negatywnie na bazę kodu i są gotowe. Jeśli jednak kompilacja się nie powiedzie, zmiany będą musiały zostać ponownie ocenione. Dlatego wskazane jest dokonywanie zmian w projekcie poprzez pracę na kopii projektu w innej gałęzi przed włączeniem jej do głównej bazy kodu. W ten sposób, jeśli kompilacja się zepsuje, łatwiej będzie ustalić, skąd pochodzi błąd, a także nie wpłynie to na główny kod źródłowy.
„Im wcześniej wykryjesz defekty, tym taniej będzie je naprawić”.
— David Farley, Continuous Delivery: niezawodne wydania oprogramowania dzięki automatyzacji kompilacji, testowania i wdrażania
Dostępnych jest kilka narzędzi, które pomogą w tworzeniu ciągłej integracji dla Twojego projektu. Należą do nich Jenkins, TravisCI, CircleCI, GitLab CI, GitHub Actions itp. W tym samouczku będę korzystać z akcji GitHub.
Akcje GitHub dla ciągłej integracji
CI Actions to dość nowa funkcja w serwisie GitHub, która umożliwia tworzenie przepływów pracy, które automatycznie uruchamiają kompilację i testy projektu. Przepływ pracy zawiera co najmniej jedno zadanie, które można aktywować po wystąpieniu zdarzenia. To zdarzenie może być wypchnięciem do dowolnej gałęzi w repozytorium lub utworzeniem żądania ściągnięcia. W dalszej części wyjaśnię te warunki szczegółowo.
Zacznijmy!
Warunki wstępne
To jest samouczek dla początkujących, więc będę głównie mówił o GitHub Actions CI na poziomie powierzchni. Czytelnicy powinni już być zaznajomieni z tworzeniem interfejsu Node JS REST API przy użyciu bazy danych PostgreSQL, Sequelize ORM i pisania testów z Mocha i Chai.
Powinieneś również mieć zainstalowane na swoim komputerze następujące elementy:
- Węzeł JS,
- PostgreSQL,
- NPM,
- VSCode (lub dowolny edytor i terminal do wyboru).
Skorzystam z RESTowego API, które już stworzyłem o nazwie countries-info-api . Jest to proste API bez autoryzacji opartych na rolach (jak w momencie pisania tego samouczka). Oznacza to, że każdy może dodawać, usuwać i/lub aktualizować dane kraju. Każdy kraj będzie miał identyfikator (automatycznie wygenerowany UUID), nazwę, stolicę i populację. Aby to osiągnąć, wykorzystałem Node js, express js framework oraz Postgresql dla bazy danych.
Pokrótce wyjaśnię, jak skonfigurowałem serwer, bazę danych, zanim zacznę pisać testy na pokrycie testów i plik workflow do ciągłej integracji.
Możesz sklonować repozytorium countries-info-api aby śledzić lub tworzyć własne API.
Zastosowane technologie : Node Js, NPM (menedżer pakietów dla Javascript), baza danych Postgresql, sequelize ORM, Babel.
Konfiguracja serwera
Przed skonfigurowaniem serwera zainstalowałem kilka zależności z npm.
npm install express dotenv cors npm install --save-dev @babel/core @babel/cli @babel/preset-env nodemonUżywam Express Framework i piszę w formacie ES6, więc będę potrzebował Babeljs do skompilowania mojego kodu. Możesz przeczytać oficjalną dokumentację, aby dowiedzieć się więcej o tym, jak to działa i jak skonfigurować go dla swojego projektu. Nodemon wykryje wszelkie zmiany wprowadzone w kodzie i automatycznie zrestartuje serwer.
Uwaga : pakiety Npm zainstalowane przy użyciu flagi --save-dev są wymagane tylko na etapie rozwoju i są widoczne w sekcji devDependencies w pliku package.json .
Do mojego index.js dodałem:
import express from "express"; import bodyParser from "body-parser"; import cors from "cors"; import "dotenv/config"; const app = express(); const port = process.env.PORT; app.use(bodyParser.json()); app.use(bodyParser.urlencoded({ extended: true })); app.use(cors()); app.get("/", (req, res) => { res.send({message: "Welcome to the homepage!"}) }) app.listen(port, () => { console.log(`Server is running on ${port}...`) }) Spowoduje to skonfigurowanie naszego interfejsu API do działania na tym, co jest przypisane do zmiennej PORT w pliku .env . W tym miejscu będziemy również deklarować zmienne, do których nie chcemy, aby inni mieli łatwy dostęp. Pakiet dotenv npm ładuje nasze zmienne środowiskowe z .env .
Teraz, gdy uruchamiam npm run start w moim terminalu, otrzymuję to:
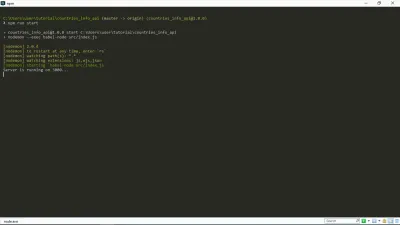
Jak widać, nasz serwer działa. Tak!
Ten link https://127.0.0.1:your_port_number/ w przeglądarce internetowej powinien zwrócić wiadomość powitalną. To znaczy tak długo, jak działa serwer.
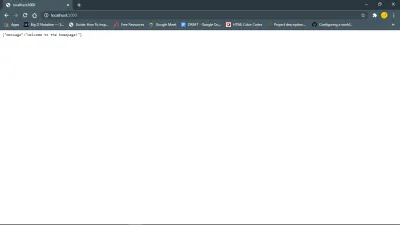
Dalej, baza danych i modele.
Stworzyłem model kraju za pomocą Sequelize i połączyłem się z moją bazą danych Postgres. Sequelize to ORM dla Nodejs. Dużą zaletą jest to, że oszczędza nam czas na pisanie surowych zapytań SQL.
Ponieważ używamy Postgresql, bazę danych można utworzyć za pomocą wiersza poleceń psql za pomocą CREATE DATABASE database_name . Można to również zrobić na swoim terminalu, ale wolę powłokę PSQL.
W pliku env skonfigurujemy parametry połączenia naszej bazy danych, zgodnie z poniższym formatem.
TEST_DATABASE_URL = postgres://<db_username>:<db_password>@127.0.0.1:5432/<database_name>W przypadku mojego modelu skorzystałem z tego samouczka sequelize. Jest łatwy do naśladowania i wyjaśnia wszystko na temat konfigurowania Sequelize.
Następnie napiszę testy dla właśnie utworzonego modelu i skonfiguruję pokrycie w kombinezonie.
Pisanie testów i raportowanie
Po co pisać testy? Osobiście uważam, że pisanie testów pomaga programiście lepiej zrozumieć, jak oprogramowanie powinno działać w rękach użytkownika, ponieważ jest to proces burzy mózgów. Pomaga także wykrywać błędy na czas.
Testy:
Istnieją jednak różne metody testowania oprogramowania. W tym samouczku wykorzystałem testy jednostkowe i kompleksowe.
Napisałem swoje testy przy użyciu frameworka testowego Mocha i biblioteki asercji Chai. Zainstalowałem również sequelize-test-helpers aby pomóc przetestować model, który stworzyłem za pomocą sequelize.define .
Pokrycie testowe:
Wskazane jest sprawdzenie pokrycia testami, ponieważ wynik pokazuje, czy nasze przypadki testowe faktycznie obejmują kod, a także ile kodu jest używane podczas uruchamiania naszych przypadków testowych.

Użyłem Istanbul (narzędzia do pokrycia testów), nyc (klienta CLI Instabul) i kombinezonów.
Zgodnie z dokumentacją, Istanbul wyposaża Twój kod JavaScript ES5 i ES2015+ za pomocą liczników wierszy, dzięki czemu możesz śledzić, jak dobrze Twoje testy jednostkowe wykorzystują bazę kodu.
W moim pliku package.json skrypt testowy uruchamia testy i generuje raport.
{ "scripts": { "test": "nyc --reporter=lcov --reporter=text mocha -r @babel/register ./src/test/index.js" } } W trakcie tego procesu utworzy folder .nyc_output zawierający surowe informacje o pokryciu oraz folder coverage zawierający pliki raportów o pokryciu. Oba pliki nie są potrzebne w moim repozytorium, więc umieściłem je w pliku .gitignore .
Teraz, gdy wygenerowaliśmy raport, musimy wysłać go do kombinezonu. Jedną fajną rzeczą dotyczącą kombinezonów (i innych narzędzi pokrycia, jak zakładam), jest sposób, w jaki raportuje pokrycie twojego testu. Pokrycie jest podzielone na plik po pliku i można zobaczyć odpowiednie pokrycie, zakryte i pominięte linie oraz zmiany w pokryciu kompilacji.
Aby rozpocząć, zainstaluj pakiet npm kombinezony. Musisz także zalogować się do kombinezonu i dodać do niego repozytorium.
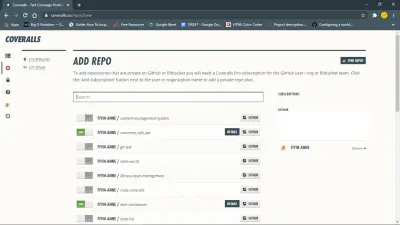
Następnie skonfiguruj kombinezon dla swojego projektu javascript, tworząc plik coveralls.yml w katalogu głównym. W tym pliku będzie przechowywany Twój repo-token uzyskany z sekcji ustawień dla Twojego repozytorium na kombinezonach.
Kolejnym skryptem potrzebnym w pliku package.json są skrypty pokrycia. Ten skrypt przyda się, gdy tworzymy kompilację za pomocą akcji.
{ "scripts": { "coverage": "nyc npm run test && nyc report --reporter=text-lcov --reporter=lcov | node ./node_modules/coveralls/bin/coveralls.js --verbose" } }Zasadniczo przeprowadzi testy, pobierze raport i wyśle go do kombinezonu w celu analizy.
Przejdźmy teraz do głównego punktu tego samouczka.
Utwórz plik przepływu pracy węzła JS
W tym momencie skonfigurowaliśmy niezbędne zadania, które będziemy uruchamiać w naszej akcji GitHub. (Zastanawiasz się, co oznacza „praca”? Czytaj dalej.)
GitHub ułatwił tworzenie pliku przepływu pracy, udostępniając szablon startowy. Jak widać na stronie Akcje, istnieje kilka szablonów przepływu pracy służących różnym celom. W tym samouczku użyjemy przepływu pracy Node.js (który już uprzejmie zasugerował GitHub).
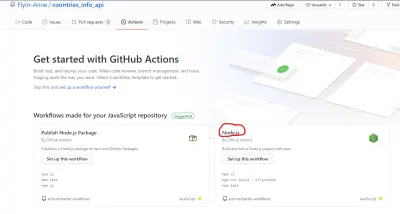
Możesz edytować plik bezpośrednio na GitHub, ale ręcznie utworzę plik w moim lokalnym repozytorium. Folder .github/workflows zawierający plik node.js.yml będzie znajdował się w katalogu głównym.
Ten plik zawiera już kilka podstawowych poleceń, a pierwszy komentarz wyjaśnia, co one robią.
# This workflow will do a clean install of node dependencies, build the source code and run tests across different versions of nodeWprowadzę w nim kilka zmian, aby oprócz powyższego komentarza prowadziła również relację.
Mój plik .node.js.yml :
name: NodeJS CI on: ["push"] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run coverage - name: Coveralls uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} COVERALLS_GIT_BRANCH: ${{ github.ref }} with: github-token: ${{ secrets.GITHUB_TOKEN }}Co to znaczy?
Rozbijmy to.
-
name
Będzie to nazwa twojego przepływu pracy (NodeJS CI) lub zadania (kompilacja), a GitHub wyświetli ją na stronie akcji twojego repozytorium. -
on
To jest zdarzenie, które wyzwala przepływ pracy. Ten wiersz w moim pliku w zasadzie mówi GitHubowi, aby wyzwolił przepływ pracy za każdym razem, gdy zostanie wykonane push do mojego repozytorium. -
jobs
Przepływ pracy może zawierać co najmniej jedno lub więcej zadań, a każde zadanie jest uruchamiane w środowisku określonym przezruns-on. W powyższym przykładzie pliku jest tylko jedno zadanie, które uruchamia kompilację, a także obsługuje pokrycie, i działa w środowisku Windows. Mogę również podzielić to na dwie różne prace, takie jak:
Zaktualizowany plik Node.yml
name: NodeJS CI on: [push] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run test coverage: name: Coveralls runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} with: github-token: ${{ secrets.GITHUB_TOKEN }}-
env
Zawiera zmienne środowiskowe, które są dostępne dla wszystkich lub określonych zadań i kroków w przepływie pracy. W zadaniu pokrycia możesz zobaczyć, że zmienne środowiskowe zostały „ukryte”. Można je znaleźć na stronie sekretów twojego repozytorium w ustawieniach. -
steps
Zasadniczo jest to lista kroków, które należy wykonać podczas uruchamiania tego zadania. - Praca
buildma wiele funkcji:- Używa akcji checkout (v2 oznacza wersję), która dosłownie pobiera twoje repozytorium, aby było dostępne dla twojego przepływu pracy;
- Używa akcji setup-node, która konfiguruje środowisko węzła, które ma być używane;
- Uruchamia skrypty instalacji, budowania i testowania znajdujące się w naszym pliku package.json.
-
coverage
Wykorzystuje to działanie coverallsapp, które publikuje dane dotyczące pokrycia LCOV twojego zestawu testów na coveralls.io w celu analizy.
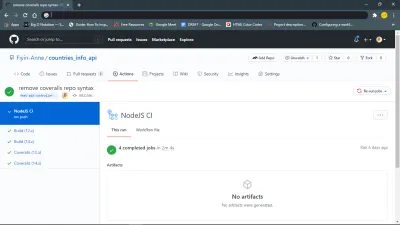
Początkowo popchnąłem moją gałąź feat-add-controllers-and-route i zapomniałem dodać repo_token z Coveralls do mojego pliku .coveralls.yml , więc otrzymałem błąd, który można zobaczyć w wierszu 132.
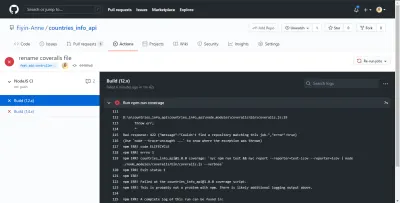
Bad response: 422 {"message":"Couldn't find a repository matching this job.","error":true} Po dodaniu repo_token moja kompilacja mogła działać pomyślnie. Bez tego tokena kombinezony nie byłyby w stanie poprawnie zgłosić mojej analizy pokrycia testowego. Dobrze, że nasz CI GitHub Actions wskazał błąd, zanim został wypchnięty do głównej gałęzi.
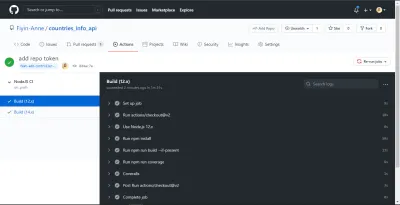
NB: Zostały one zrobione, zanim podzieliłem pracę na dwie prace. Ponadto mogłem zobaczyć podsumowanie zasięgu i komunikat o błędzie na moim terminalu, ponieważ dodałem flagę --verbose na końcu mojego skryptu zasięgu
Wniosek
Możemy zobaczyć, jak skonfigurować ciągłą integrację dla naszych projektów, a także zintegrować pokrycie testami za pomocą akcji udostępnianych przez GitHub. Jest tak wiele innych sposobów, aby dostosować je do potrzeb Twojego projektu. Chociaż przykładowe repozytorium użyte w tym samouczku jest naprawdę niewielkim projektem, możesz zobaczyć, jak ważna jest ciągła integracja nawet w większym projekcie. Teraz, gdy moje prace przebiegały pomyślnie, jestem pewny, że połączę oddział z moim głównym oddziałem. Nadal radzę, abyś przeczytał również wyniki kroków po każdym biegu, aby zobaczyć, że jest to całkowity sukces.