
Dodawanie funkcji dzielenia kodu do witryny WordPress za pośrednictwem PoP
Opublikowany: 2022-03-10Szybkość jest obecnie jednym z najwyższych priorytetów dla każdej witryny internetowej. Jednym ze sposobów przyspieszenia ładowania strony internetowej jest dzielenie kodu: podzielenie aplikacji na porcje, które można załadować na żądanie — ładowanie tylko wymaganego kodu JavaScript, który jest potrzebny i nic więcej. Strony internetowe oparte na frameworkach JavaScript mogą od razu zaimplementować dzielenie kodu poprzez Webpack, popularny pakiet JavaScript. Jednak w przypadku witryn WordPress nie jest to takie proste. Po pierwsze, Webpack nie został celowo stworzony do pracy z WordPressem, więc skonfigurowanie go będzie wymagało pewnego obejścia; po drugie, wydaje się, że nie są dostępne żadne narzędzia, które zapewniają natywne możliwości ładowania zasobów na żądanie dla WordPressa.
Biorąc pod uwagę brak odpowiedniego rozwiązania dla WordPressa, zdecydowałem się zaimplementować własną wersję code-splittingu dla PoP, frameworka open-source do budowania stron WordPress, które stworzyłem. Witryna WordPress z zainstalowanym PoP będzie miała natywnie funkcje dzielenia kodu, więc nie będzie musiała zależeć od Webpacka ani żadnego innego pakietu. W tym artykule pokażę, jak to się robi, wyjaśniając, jakie decyzje zostały podjęte na podstawie aspektów architektury frameworka. Na koniec przeanalizuję wydajność witryny z dzieleniem kodu i bez niego, a także zalety i wady korzystania z niestandardowej implementacji w porównaniu z zewnętrznym pakietem. Mam nadzieję, że spodoba ci się jazda!
Definiowanie strategii
Dzielenie kodu można ogólnie podzielić na te dwa kroki:
- Obliczanie jakie aktywa muszą być wczytane dla każdej trasy,
- Dynamiczne ładowanie tych zasobów na żądanie.
Aby poradzić sobie z pierwszym krokiem, będziemy musieli stworzyć mapę zależności zasobów, zawierającą wszystkie zasoby w naszej aplikacji. Zasoby muszą być dodawane rekursywnie do tej mapy — należy również dodawać zależności zależności, dopóki nie będą potrzebne żadne dalsze zasoby. Następnie możemy obliczyć wszystkie zależności wymagane dla określonej trasy, przemierzając mapę zależności zasobów, zaczynając od punktu wejścia trasy (tj. pliku lub fragmentu kodu, od którego rozpoczyna się wykonywanie) aż do ostatniego poziomu.
Aby poradzić sobie z drugim krokiem, moglibyśmy obliczyć, które zasoby są potrzebne dla żądanego adresu URL po stronie serwera, a następnie albo wysłać listę potrzebnych zasobów w odpowiedzi, po której aplikacja będzie musiała je załadować, albo bezpośrednio HTTP/ 2 popchnij zasoby wraz z odpowiedzią.
Rozwiązania te nie są jednak optymalne. W pierwszym przypadku aplikacja musi zażądać wszystkich zasobów po zwróceniu odpowiedzi, więc pojawiłaby się dodatkowa seria żądań w obie strony w celu pobrania zasobów, a widok nie mógł zostać wygenerowany przed załadowaniem wszystkich, co skutkuje użytkownik musi czekać (ten problem jest łagodzony przez wstępne buforowanie wszystkich zasobów przez procesy robocze, dzięki czemu czas oczekiwania jest skrócony, ale nie możemy uniknąć parsowania zasobów, które ma miejsce dopiero po zwróceniu odpowiedzi). W drugim przypadku możemy wielokrotnie przesyłać te same zasoby (chyba że dodamy dodatkową logikę, na przykład wskazanie, które zasoby już załadowaliśmy za pomocą plików cookie, ale to rzeczywiście zwiększa niepożądaną złożoność i blokuje buforowanie odpowiedzi) i my nie może obsługiwać zasobów z sieci CDN.
Z tego powodu zdecydowałem się na obsługę tej logiki po stronie klienta. Lista zasobów potrzebnych dla każdej trasy jest udostępniana aplikacji na kliencie, aby już wiedziała, które zasoby są potrzebne dla żądanego adresu URL. To rozwiązuje problemy wymienione powyżej:
- Zasoby można wczytać natychmiast, bez konieczności czekania na odpowiedź serwera. (Kiedy połączymy to z pracownikami usług, możemy być prawie pewni, że do czasu otrzymania odpowiedzi wszystkie zasoby zostaną załadowane i przeanalizowane, więc nie ma dodatkowego czasu oczekiwania).
- Aplikacja wie, które zasoby zostały już załadowane; w związku z tym nie zażąda wszystkich zasobów wymaganych dla tej trasy, ale tylko te, które jeszcze się nie załadowały.
Negatywnym aspektem dostarczania tej listy do frontendu jest to, że może ona stać się ciężka, w zależności od rozmiaru witryny (takiej jak liczba dostępnych tras). Musimy znaleźć sposób, aby go załadować bez zwiększania postrzeganego czasu ładowania aplikacji. Więcej o tym później.
Po podjęciu tych decyzji możemy przystąpić do projektowania, a następnie implementacji dzielenia kodu w aplikacji. Aby ułatwić zrozumienie, proces został podzielony na następujące kroki:
- Zrozumienie architektury aplikacji,
- Mapowanie zależności aktywów,
- Lista wszystkich tras aplikacji,
- Generowanie listy definiującej, jakie zasoby są wymagane dla każdej trasy,
- Dynamicznie ładowane aktywa,
- Stosowanie optymalizacji.
Przejdźmy od razu!
0. Zrozumienie architektury aplikacji
Będziemy musieli zmapować wzajemne relacje wszystkich zasobów. Przyjrzyjmy się szczegółom architektury PoP, aby zaprojektować najbardziej odpowiednie rozwiązanie do osiągnięcia tego celu.
PoP to warstwa, która otacza WordPressa, umożliwiając nam używanie WordPressa jako systemu CMS, który napędza aplikację, a jednocześnie zapewnia niestandardową strukturę JavaScript do renderowania treści po stronie klienta w celu tworzenia dynamicznych stron internetowych. Na nowo definiuje elementy konstrukcyjne strony internetowej: podczas gdy WordPress opiera się obecnie na koncepcji hierarchicznych szablonów, które tworzą HTML (takich jak single.php , home.php i archive.php ), PoP opiera się na koncepcji „modułów, ”, które są albo atomową funkcjonalnością, albo kompozycją innych modułów. Budowanie aplikacji PoP jest podobne do zabawy z LEGO — układania modułów jeden na drugim lub owijania się nawzajem, ostatecznie tworząc bardziej złożoną strukturę. Można to również traktować jako implementację atomowego projektu Brada Frosta i wygląda to tak:
Moduły można pogrupować w encje wyższego rzędu, a mianowicie: bloki, grupy blokowe, pageSections i topLevels. Te jednostki są również modułami, tylko z dodatkowymi właściwościami i obowiązkami, i zawierają się nawzajem zgodnie z architekturą ściśle odgórną, w której każdy moduł może zobaczyć i zmienić właściwości wszystkich swoich modułów wewnętrznych. Relacja między modułami wygląda tak:
- 1 topLevel zawiera N pageSections,
- 1 pageSection zawiera N bloków lub grup bloków,
- 1 grupa bloków zawiera N bloków lub grup bloków,
- 1 blok zawiera N modułów,
- 1 moduł zawiera N modułów, ad infinitum.
Wykonywanie kodu JavaScript w PoP
PoP dynamicznie tworzy HTML, zaczynając od poziomu pageSection, iterując przez wszystkie moduły w dół wiersza, renderując każdy z nich za pomocą predefiniowanego szablonu Handlebars modułu i na koniec dodając odpowiadające nowo utworzone elementy modułu do DOM. Po wykonaniu tej czynności wykonuje na nich funkcje JavaScript, które są predefiniowane dla poszczególnych modułów.
PoP różni się od frameworków JavaScript (takich jak React i AngularJS) tym, że przepływ aplikacji nie pochodzi od klienta, ale nadal jest konfigurowany na zapleczu, wewnątrz konfiguracji modułu (która jest zakodowana w obiekcie PHP). Pod wpływem haków akcji WordPress, PoP implementuje wzorzec publikuj-subskrybuj:
- Każdy moduł definiuje, które funkcje JavaScript muszą być wykonane na odpowiadających mu nowo utworzonych elementach DOM, niekoniecznie wiedząc z góry, co wykona ten kod lub skąd będzie pochodził.
- Obiekty JavaScript muszą zarejestrować, które funkcje JavaScript implementują.
- Na koniec, w czasie wykonywania, PoP oblicza, które obiekty JavaScript muszą wykonywać określone funkcje JavaScript, i odpowiednio je wywołuje.
Na przykład, poprzez odpowiedni obiekt PHP, moduł kalendarza wskazuje, że potrzebuje funkcji calendar do wykonania na swoich elementach DOM w następujący sposób:
class CalendarModule { function get_jsmethods() { $methods = parent::get_jsmethods(); $this->add_jsmethod($methods, 'calendar'); return $methods; } ... } Następnie obiekt JavaScript — w tym przypadku popFullCalendar — informuje, że zaimplementowano funkcję calendar . Odbywa się to poprzez wywołanie popJSLibraryManager.register :
window.popFullCalendar = { calendar : function(elements) { ... } }; popJSLibraryManager.register(popFullCalendar, ['calendar', ...]); Wreszcie, popJSLibraryManager dopasowuje to, co wykonuje dany kod. Pozwala obiektom JavaScript rejestrować, które funkcje implementują, i zapewnia metodę wykonania określonej funkcji ze wszystkich subskrybowanych obiektów JavaScript:
window.popJSLibraryManager = { libraries: [], methods: {}, register : function(library, methods) { this.libraries.push(library); for (var i = 0; i < methods.length; i++) { var method = methods[i]; this.methods[method] = this.methods[method] || []; this.methods[method].push(library); } }, execute : function(method, elements) { var libraries = this.methods[method] || []; for (var i = 0; i < libraries.length; i++) { var library = libraries[i]; library[method](elements); } } } Po dodaniu nowego elementu kalendarza do DOM, który ma identyfikator calendar-293 , PoP po prostu wykona następującą funkcję:
popJSLibraryManager.execute("calendar", document.getElementById("calendar-293"));Punkt wejścia
W przypadku PoP punktem wejścia do wykonania kodu JavaScript jest ten wiersz na końcu wyniku HTML:
<script type="text/javascript">popManager.init();</script> popManager.init() najpierw inicjuje framework front-end, a następnie wykonuje funkcje JavaScript zdefiniowane przez wszystkie renderowane moduły, jak wyjaśniono powyżej. Poniżej znajduje się bardzo uproszczona forma tej funkcji (oryginalny kod znajduje się na GitHub). Po wywołaniu popJSLibraryManager.execute('pageSectionInitialized', pageSection) i popJSLibraryManager.execute('documentInitialized') wszystkie obiekty JavaScript, które implementują te funkcje ( pageSectionInitialized i documentInitialized ) wykonają je.
(function($){ window.popManager = { // The configuration for all the modules (including pageSections and blocks) in the application configuration : {...}, init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { // Obtain the pageSection element in the DOM from the ID var pageSection = $('#'+pageSectionId); // Run all required JavaScript methods on it this.runJSMethods(pageSection, configuration); // Trigger an event marking the block as initialized popJSLibraryManager.execute('pageSectionInitialized', pageSection); }); // Trigger an event marking the document as initialized popJSLibraryManager.execute('documentInitialized'); }, ... }; })(jQuery); Funkcja runJSMethods wykonuje metody JavaScript zdefiniowane dla każdego modułu, zaczynając od pageSection, który jest najwyższym modułem, a następnie w dół dla wszystkich jego wewnętrznych bloków i ich wewnętrznych modułów:
(function($){ window.popManager = { ... runJSMethods : function(pageSection, configuration) { // Initialize the heap with "modules", starting from the top one, and recursively iterate over its inner modules var heap = [pageSection.data('module')], i; while (heap.length > 0) { // Get the first element of the heap var module = heap.pop(); // The configuration for that module contains which JavaScript methods to execute, and which are the module's inner modules var moduleConfiguration = configuration[module]; // The list of all JavaScript functions that must be executed on the module's newly created DOM elements var jsMethods = moduleConfiguration['js-methods']; // Get all of the elements added to the DOM for that module, which have been stored in JavaScript object `popJSRuntimeManager` upon creation var elements = popJSRuntimeManager.getDOMElements(module); // Iterate through all of the JavaScript methods and execute them, passing the elements as argument for (i = 0; i < jsMethods.length; i++) { popJSLibraryManager.execute(jsMethods[i], elements); } // Finally, add the inner-modules to the heap heap = heap.concat(moduleConfiguration['inner-modules']); } }, }; })(jQuery);Podsumowując, wykonywanie JavaScriptu w PoP jest luźno powiązane: Zamiast mieć ustalone zależności, wykonujemy funkcje JavaScript poprzez punkty zaczepienia, do których może subskrybować każdy obiekt JavaScript.
Strony internetowe i interfejsy API
Witryna PoP jest samoczynnym interfejsem API. W PoP nie ma rozróżnienia między stroną internetową a interfejsem API: każdy adres URL domyślnie zwraca stronę internetową, a po dodaniu parametru output=json zamiast tego zwraca swój interfejs API (na przykład getpop.org/en/ jest stronę internetową, a jej API to getpop.org/en/?output=json). API służy do dynamicznego renderowania treści w PoP; więc po kliknięciu w link do innej strony, żądane jest API, ponieważ do tego czasu zostanie załadowana ramka witryny (taka jak górna i boczna nawigacja) — wtedy zestaw zasobów potrzebnych do trybu API być podzbiorem tego ze strony internetowej. Będziemy musieli wziąć to pod uwagę podczas obliczania zależności dla trasy: Wczytywanie trasy podczas pierwszego ładowania witryny lub dynamiczne wczytywanie przez kliknięcie jakiegoś linku wygeneruje różne zestawy wymaganych zasobów.
To są najważniejsze aspekty PoP, które zdefiniują projektowanie i implementację dzielenia kodu. Przejdźmy do następnego kroku.
1. Mapowanie zależności aktywów
Moglibyśmy dodać plik konfiguracyjny dla każdego pliku JavaScript, wyszczególniając ich jawne zależności. To jednak powielałoby kod i byłoby trudne do zachowania spójności. Czystszym rozwiązaniem byłoby zachowanie plików JavaScript jako jedynego źródła prawdy, wyodrębnienie z nich kodu, a następnie przeanalizowanie tego kodu w celu odtworzenia zależności.
Metadane, których szukamy w plikach źródłowych JavaScript, aby móc odtworzyć mapowanie, są następujące:
- wywołania metod wewnętrznych, takie jak
this.runJSMethods(...); - wywołania metod zewnętrznych, takich jak
popJSRuntimeManager.getDOMElements(...); - wszystkie wystąpienia
popJSLibraryManager.execute(...), które wykonują funkcję JavaScript we wszystkich tych obiektach, które ją implementują; - wszystkie wystąpienia
popJSLibraryManager.register(...), aby uzyskać informacje, które obiekty JavaScript implementują które metody JavaScript.
Użyjemy jParser i jTokenizer do tokenizacji naszych plików źródłowych JavaScript w PHP i wyodrębnienia metadanych w następujący sposób:
- Wywołania metod wewnętrznych (takich jak
this.runJSMethods) są dedukowane po znalezieniu następującej sekwencji: tokenthislubthat+.+ jakiś inny token, który jest nazwą metody wewnętrznej (runJSMethods). - Wywołania metod zewnętrznych (takich jak
popJSRuntimeManager.getDOMElements) są dedukowane po znalezieniu następującej sekwencji: token zawarty na liście wszystkich obiektów JavaScript w naszej aplikacji (będziemy potrzebować tej listy z góry; w tym przypadku będzie ona zawierać obiektpopJSRuntimeManager) +.+ jakiś inny token, który jest nazwą metody zewnętrznej (getDOMElements). - Za każdym razem, gdy znajdujemy
popJSLibraryManager.execute("someFunctionName"), dedukujemy metodę JavaScript jakosomeFunctionNamefunkcji. - Za każdym razem, gdy znajdujemy
popJSLibraryManager.register(someJSObject, ["someFunctionName1", "someFunctionName2"])dedukujemy obiekt JavaScriptsomeJSObjectw celu zaimplementowania metodsomeFunctionName1,someFunctionName2.
Zaimplementowałem skrypt, ale nie będę go tutaj opisywał. (Jest zbyt długi, nie dodaje wiele wartości, ale można go znaleźć w repozytorium PoP). Skrypt, który uruchamia się na żądanie strony wewnętrznej na serwerze deweloperskim serwisu (o której metodologii pisałem w poprzednim artykule o service workerach), wygeneruje plik mapowania i zapisze go na serwerze. Przygotowałem przykład wygenerowanego pliku mapowania. Jest to prosty plik JSON zawierający następujące atrybuty:
-
internalMethodCalls
Dla każdego obiektu JavaScript wypisz między sobą zależności z funkcji wewnętrznych. -
externalMethodCalls
Dla każdego obiektu JavaScript wypisz zależności między funkcjami wewnętrznymi a funkcjami z innych obiektów JavaScript. -
publicMethods
Wypisz wszystkie zarejestrowane metody i dla każdej metody, które obiekty JavaScript ją implementują. -
methodExecutions
Dla każdego obiektu JavaScript i każdej funkcji wewnętrznej wypisz wszystkie metody wykonywane przezpopJSLibraryManager.execute('someMethodName').
Należy pamiętać, że wynikiem nie jest jeszcze mapa zależności zasobów, ale mapa zależności obiektów JavaScript. Z tej mapy możemy ustalić, kiedy wykonywana jest funkcja z jakiegoś obiektu, jakie inne obiekty będą również wymagane. Nadal musimy skonfigurować, które obiekty JavaScript są zawarte w każdym zasobie, dla wszystkich zasobów (w skrypcie jTokenizer obiekty JavaScript są tokenami, których szukamy do identyfikacji wywołań metod zewnętrznych, więc ta informacja jest danymi wejściowymi do skryptu i może nie można uzyskać z samych plików źródłowych). Odbywa się to za pomocą obiektów PHP ResourceLoaderProcessor , takich jak resourceloader-processor.php.
Wreszcie, łącząc mapę i konfigurację, będziemy mogli obliczyć wszystkie wymagane zasoby dla każdej trasy w aplikacji.
2. Lista wszystkich tras aplikacji
Musimy zidentyfikować wszystkie trasy dostępne w naszej aplikacji. W przypadku witryny WordPress ta lista rozpocznie się od adresu URL z każdej z hierarchii szablonów. Te zaimplementowane dla PoP to:
- strona główna: https://getpop.org/en/
- autor: https://getpop.org/en/u/leo/
- singiel: https://getpop.org/en/blog/nowa-funkcja-podział-kodu/
- tag: https://getpop.org/en/tags/internet/
- strona: https://getpop.org/en/filozofia/
- kategoria: https://getpop.org/en/blog/ (kategoria jest faktycznie zaimplementowana jako strona, aby usunąć
category/ze ścieżki adresu URL) - 404: https://getpop.org/en/ta-strona-nie-istnieje/
Dla każdej z tych hierarchii musimy uzyskać wszystkie trasy, które tworzą unikalną konfigurację (tj. która będzie wymagała unikalnego zestawu zasobów). W przypadku PoP mamy do czynienia z:
- strona główna i 404 są unikalne.
- Strony tagów mają zawsze taką samą konfigurację dla każdego tagu. Dlatego wystarczy jeden adres URL dla dowolnego tagu.
- Pojedynczy post zależy od kombinacji typu posta (np. „wydarzenie” lub „post”) oraz głównej kategorii posta (np. „blog” lub „artykuł”). Następnie potrzebujemy adresu URL dla każdej z tych kombinacji.
- Konfiguracja strony kategorii zależy od kategorii. Potrzebujemy więc adresu URL każdej kategorii postów.
- Strona autora zależy od roli autora („osoba”, „organizacja” lub „społeczność”). Potrzebujemy więc adresów URL trzech autorów, z których każdy ma jedną z tych ról.
- Każda strona może mieć własną konfigurację („zaloguj się”, „skontaktuj się z nami”, „nasza misja” itp.). Dlatego wszystkie adresy URL stron muszą zostać dodane do listy.
Jak widać, lista jest już dość długa. Ponadto nasza aplikacja może dodawać parametry do adresu URL, które zmieniają konfigurację, potencjalnie również zmieniając wymagane zasoby. Na przykład PoP oferuje dodanie następujących parametrów adresu URL:
- tab (
?tab=…), aby wyświetlić powiązane informacje: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors; - format (
?format=…), aby zmienić sposób wyświetlania danych: https://getpop.org/en/blog/?format=list; - target (
?target=…), aby otworzyć stronę w innej sekcji strony: https://getpop.org/en/add-post/?target=addons.
Niektóre z początkowych tras mogą mieć jeden, dwa lub nawet trzy z powyższych parametrów, tworząc szeroką gamę kombinacji:
- pojedynczy post: https://getpop.org/en/blog/new-feature-code-splitting/
- autorzy pojedynczego posta: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors
- autorzy pojedynczego posta w postaci listy: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list
- autorzy pojedynczego posta jako lista w oknie modalnym: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list&target=modals
Podsumowując, w przypadku PoP wszystkie możliwe trasy są kombinacją następujących elementów:
- wszystkie początkowe trasy hierarchii szablonów;
- wszystkie różne wartości, dla których hierarchia stworzy inną konfigurację;
- wszystkie możliwe zakładki dla każdej hierarchii (różne hierarchie mogą mieć różne wartości zakładek: pojedynczy post może mieć zakładki „autorzy” i „odpowiedzi”, podczas gdy autor może mieć zakładki „posty” i „obserwatorzy”);
- wszystkie możliwe formaty dla każdej zakładki (różne zakładki mogą być stosowane różne formaty: zakładka „autorzy” może mieć format „mapa”, ale zakładka „odpowiedzi” może nie);
- wszystkie możliwe cele wskazujące sekcje strony, w których może być wyświetlana każda trasa (podczas gdy post można utworzyć w sekcji głównej lub w ruchomym oknie, strona „Udostępnij znajomym” może być ustawiona tak, aby otwierała się w oknie modalnym).
Dlatego w przypadku nieco złożonej aplikacji tworzenie listy zawierającej wszystkie trasy nie może być wykonane ręcznie. Następnie musimy stworzyć skrypt, aby wyodrębnić te informacje z bazy danych, manipulować nimi i na koniec wyprowadzić je w wymaganym formacie. Ten skrypt pobierze wszystkie kategorie postów, z których możemy utworzyć listę wszystkich różnych adresów URL stron kategorii, a następnie, dla każdej kategorii, przeszuka bazę danych dla dowolnego posta pod tym samym, co wygeneruje adres URL dla jednego post w każdej kategorii i tak dalej. Dostępny jest pełny skrypt, zaczynając od function get_resources() , która ujawnia zaczepy do zaimplementowania przez każdy przypadek hierarchii.
3. Generowanie listy definiującej, które zasoby są wymagane dla każdej trasy
Do tej pory mamy mapę zależności aktywów i listę wszystkich tras w aplikacji. Teraz nadszedł czas, aby połączyć te dwa elementy i stworzyć listę wskazującą dla każdej trasy, jakie zasoby są wymagane.
Aby utworzyć tę listę, stosujemy następującą procedurę:
- Utwórz listę zawierającą wszystkie metody JavaScript do wykonania dla każdej trasy:
Oblicz moduły trasy, a następnie uzyskaj konfigurację dla każdego modułu, a następnie wyodrębnij z konfiguracji funkcje JavaScript, które moduł musi wykonać, i dodaj je wszystkie razem. - Następnie przejrzyj mapę zależności zasobów dla każdej funkcji JavaScript, zbierz listę wszystkich wymaganych zależności i dodaj je wszystkie razem.
- Na koniec dodaj szablony Handlebars potrzebne do renderowania każdego modułu wewnątrz tej trasy.
Ponadto, jak wspomniano wcześniej, każdy adres URL ma tryby strony internetowej i API, więc musimy uruchomić powyższą procedurę dwa razy, raz dla każdego trybu (tj. raz dodając parametr output=json do adresu URL, reprezentujący trasę dla trybu API, i po pozostawieniu niezmienionego adresu URL w trybie strony internetowej). Następnie stworzymy dwie listy, które będą miały różne zastosowania:

- Lista trybów stron internetowych zostanie użyta podczas początkowego ładowania witryny, dzięki czemu odpowiednie skrypty dla tej trasy zostaną uwzględnione w początkowej odpowiedzi HTML. Ta lista będzie przechowywana na serwerze.
- Lista trybów API będzie używana podczas dynamicznego ładowania strony w serwisie. Ta lista zostanie załadowana do klienta, aby umożliwić aplikacji obliczenie, jakie dodatkowe zasoby muszą zostać załadowane na żądanie po kliknięciu łącza.
Większość logiki została zaimplementowana począwszy od function add_resources_from_settingsprocessors($fetching_json, ...) , (można ją znaleźć w repozytorium). Parametr $fetching_json rozróżnia tryby strony internetowej ( false ) i API ( true ).
Po uruchomieniu skryptu trybu strony internetowej wygeneruje on plik resourceloader-bundle-mapping.json, który jest obiektem JSON o następujących właściwościach:
-
bundle-ids
Jest to zbiór maksymalnie czterech zasobów (ich nazwy zostały zniekształcone dla środowiska produkcyjnego:eq=>handlebars,er=>handlebars-helpers, itp.), zgrupowanych pod identyfikatorem pakietu. -
bundlegroup-ids
To jest zbiórbundle-ids. Każda grupa bundleGroup reprezentuje unikalny zestaw zasobów. -
key-ids
Jest to mapowanie między trasami (reprezentowanymi przez ich hash, który identyfikuje zestaw wszystkich atrybutów, które czynią trasę unikatową) i odpowiadającą im grupą pakietów.
Jak można zauważyć, odwzorowanie trasy na jej zasoby nie jest proste. Zamiast mapować key-ids na listę zasobów, mapuje je do unikalnej grupy bundleGroup, która sama w sobie jest listą bundles , a tylko każdy pakiet jest listą resources (do czterech elementów w każdym pakiecie). Dlaczego tak się stało? Służy to dwóm celom:
- Umożliwia nam identyfikację wszystkich zasobów w ramach unikalnej grupy bundleGroup. W ten sposób zamiast uwzględniać wszystkie zasoby w odpowiedzi HTML, możemy dołączyć unikalny zasób JavaScript, który jest zamiast tego odpowiednim plikiem bundleGroup, który obejmuje wszystkie odpowiednie zasoby. Jest to przydatne w przypadku obsługi urządzeń, które nadal nie obsługują protokołu HTTP/2, a także skróci czas ładowania, ponieważ skompresowanie pojedynczego pliku w pakiecie Gzip jest bardziej efektywne niż samodzielne kompresowanie jego plików składowych, a następnie dodawanie ich do siebie. Alternatywnie moglibyśmy również załadować serię pakietów zamiast unikalnej grupy bundleGroup, co jest kompromisem między zasobami a grupami bundleGroup (ładowanie pakietów jest wolniejsze niż bundleGroups z powodu Gzip'ing, ale jest bardziej wydajne, jeśli unieważnienie zdarza się często, więc możemy pobierze tylko zaktualizowany pakiet, a nie całą grupę bundleGroup). Skrypty do łączenia wszystkich zasobów w pakiety i grupy bundles znajdują się w plikach filegenerator-bundles.php i filegenerator-bundlegroups.php.
- Dzielenie zbiorów zasobów na paczki pozwala nam identyfikować wspólne wzorce (na przykład identyfikować zestawy czterech zasobów, które są współdzielone przez wiele tras), w konsekwencji umożliwiając różnym trasom łączenie się z tym samym pakietem. W rezultacie wygenerowana lista będzie miała mniejszy rozmiar. Może to nie być zbyt przydatne dla listy stron internetowych, która znajduje się na serwerze, ale jest świetna dla listy API, która zostanie załadowana na klienta, jak zobaczymy później.
Po uruchomieniu skryptu trybu API wygeneruje plik resources.js z następującymi właściwościami:
-
bundlesibundle-groupssłużą temu samemu celowi, co określone dla trybu strony internetowej -
keyssłużą również temu samemu celowi, cokey-idsw trybie strony internetowej. Jednak zamiast mieć hash jako klucz do reprezentowania trasy, jest to połączenie wszystkich tych atrybutów, które czynią trasę unikalną — w naszym przypadku format (f), tab (t) i target (r). -
sourcesto plik źródłowy każdego zasobu. -
typesto CSS lub JavaScript dla każdego zasobu (chociaż dla uproszczenia nie omówiliśmy w tym artykule, że zasoby JavaScript mogą również ustawiać zasoby CSS jako zależności, a moduły mogą ładować własne zasoby CSS, wdrażając strategię progresywnego ładowania CSS ). -
resourcesprzechwytują, które grupy bundleGroups muszą być załadowane dla każdej hierarchii. -
ordered-load-resourceszawiera informacje o tym, które zasoby należy załadować w odpowiedniej kolejności, aby uniemożliwić ładowanie skryptów przed ich zależnymi skryptami (domyślnie są one asynchroniczne).
W następnej sekcji omówimy, jak korzystać z tego pliku.
4. Dynamiczne ładowanie aktywów
Jak wspomniano, lista API zostanie załadowana do klienta, abyśmy mogli rozpocząć ładowanie wymaganych zasobów dla trasy natychmiast po kliknięciu przez użytkownika w link.
Ładowanie skryptu mapowania
Wygenerowany plik JavaScript z listą zasobów dla wszystkich tras w aplikacji nie jest lekki — w tym przypadku wyszedł do 85 KB (co samo w sobie jest zoptymalizowane, po zniekształceniu nazw zasobów i wyprodukowaniu paczek w celu zidentyfikowania wspólnych wzorców na trasach) . Czas parsowania nie powinien być dużym wąskim gardłem, ponieważ parsowanie JSON jest 10 razy szybsze niż parsowanie JavaScript dla tych samych danych. Jednak rozmiar jest problemem związanym z transferem sieciowym, więc musimy załadować ten skrypt w sposób, który nie wpływa na postrzegany czas ładowania aplikacji ani nie zmusza użytkownika do czekania.
Zaimplementowanym przeze mnie rozwiązaniem jest wstępne buforowanie tego pliku za pomocą serviceworkerów, wczytanie go za pomocą defer , aby nie blokował głównego wątku podczas wykonywania krytycznych metod JavaScript, a następnie wyświetlenie komunikatu awaryjnego, jeśli użytkownik kliknie łącze przed załadowaniem skryptu: „Witryna nadal się ładuje, poczekaj kilka chwil, aby kliknąć linki”. Osiąga się to poprzez dodanie stałego div z klasą loadingscreen ładowania umieszczoną nad wszystkim podczas ładowania skryptów, a następnie dodanie powiadomienia z klasą notificationmsg , wewnątrz div i tych kilku linijek CSS:
.loadingscreen > .notificationmsg { display: none; } .loadingscreen:focus > .notificationmsg, .loadingscreen:active > .notificationmsg { display: block; }Innym rozwiązaniem jest podzielenie tego pliku na kilka części i ładowanie ich stopniowo w razie potrzeby (strategia, którą już zakodowałem). Co więcej, plik o wielkości 85 KB zawiera wszystkie możliwe trasy w aplikacji, w tym takie, jak „ogłoszenia autora, pokazane w miniaturach, wyświetlane w oknie modalnym”, do których można uzyskać dostęp raz na niebieskim księżycu, jeśli w ogóle. Tras, do których najczęściej uzyskuje się dostęp, to zaledwie kilka (strona główna, strona pojedyncza, autor, znacznik i wszystkie strony, wszystkie bez dodatkowych atrybutów), co powinno dać znacznie mniejszy plik, około 30 KB.
Uzyskiwanie trasy z żądanego adresu URL
Musimy być w stanie zidentyfikować trasę z żądanego adresu URL. Na przykład:
-
https://getpop.org/en/u/leo/mapuje trasę „autor”, -
https://getpop.org/en/u/leo/?tab=followersmapuje trasę „obserwatorzy autora”, -
https://getpop.org/en/tags/internet/mapuje trasę „tag”, -
https://getpop.org/en/tags/mapuje trasę „page/tags/”, - i tak dalej.
Aby to osiągnąć, będziemy musieli ocenić adres URL i wydedukować z niego elementy, które czynią trasę unikalną: hierarchię i wszystkie atrybuty (format, tabulator i cel). Identyfikacja atrybutów nie stanowi problemu, ponieważ są to parametry w adresie URL. Jedynym wyzwaniem jest wywnioskowanie hierarchii (strona główna, autor, pojedynczy, strona lub tag) z adresu URL, dopasowując adres URL do kilku wzorców. Na przykład,
- Wszystko, co zaczyna się od
https://getpop.org/en/u/, jest autorem. - Wszystko, co zaczyna się od, ale nie jest dokładnie
https://getpop.org/en/tags/, jest tagiem. Jeśli jest to dokładniehttps://getpop.org/en/tags/, to jest to strona. - I tak dalej.
Poniższa funkcja, zaimplementowana od wiersza 321 pliku resourceloader.js, musi być zasilana konfiguracją z wzorcami dla wszystkich tych hierarchii. Najpierw sprawdza, czy w adresie URL nie ma podścieżki — w takim przypadku jest to „dom”. Następnie sprawdza jeden po drugim, aby dopasować hierarchie „autor”, „tag” i „pojedynczy”. Jeśli nie powiedzie się z żadnym z nich, to jest to domyślny przypadek, czyli „strona”:
window.popResourceLoader = { // The config will be populated externally, using a config.js file, generated by a script config : {}, getPath : function(url) { var parser = document.createElement('a'); parser.href = url; return parser.pathname; }, getHierarchy : function(url) { var path = this.getPath(url); if (!path) { return 'home'; } var config = this.config; if (path.startsWith(config.paths.author) && path != config.paths.author) { return 'author'; } if (path.startsWith(config.paths.tag) && path != config.paths.tag) { return 'tag'; } // We must also check that this path is, itself, not a potential page (https://getpop.org/en/posts/articles/ is "page", but https://getpop.org/en/posts/this-is-a-post/ is "single") if (config.paths.single.indexOf(path) === -1 && config.paths.single.some(function(single_path) { return path.startsWith(single_path) && path != single_path;})) { return 'single'; } return 'page'; }, ... };Ponieważ wszystkie wymagane dane znajdują się już w bazie danych (wszystkie kategorie, wszystkie slugi strony itp.), wykonamy skrypt, aby automatycznie utworzyć ten plik konfiguracyjny w środowisku programistycznym lub pomostowym. The implemented script is resourceloader-config.php, which produces config.js with the URL patterns for the hierarchies “author”, “tag” and “single”, under the key “paths”:
popResourceLoader.config = { "paths": { "author": "u/", "tag": "tags/", "single": ["posts/articles/", "posts/announcements/", ...] }, ... };Loading Resources for the Route
Once we have identified the route, we can obtain the required assets from the generated JavaScript file under the key “resources”, which looks like this:
config.resources = { "home": { "1": [1, 110, ...], "2": [2, 111, ...], ... }, "author": { "7": [6, 114, ...], "8": [7, 114, ...], ... }, "tag": { "119": [66, 127, ...], "120": [66, 127, ...], ... }, "single": { "posts/": { "7": [190, 142, ...], "3": [190, 142, ...], ... }, "events/": { "7": [213, 389, ...], "3": [213, 389, ...], ... }, ... }, "page": { "log-in/": { "3": [233, 115, ...] }, "log-out/": { "3": [234, 115, ...] }, "add-post/": { "3": [239, 398, ...] }, "posts/": { "120": [268, 127, ...], "122": [268, 127, ...], ... }, ... } };At the first level, we have the hierarchy (home, author, tag, single or page). Hierarchies are divided into two groups: those that have only one set of resources (home, author and tag), and those that have a specific subpath (page permalink for the pages, custom post type or category for the single). Finally, at the last level, for each key ID (which represents a unique combination of the possible values of “format”, “tab” and “target”, stored under “keys”), we have an array of two elements: [JS bundleGroup ID, CSS bundleGroup ID], plus additional bundleGroup IDs if executing progressive booting (JS bundleGroups to be loaded as "async" or "defer" are bundled separately; this will be explained in the optimizations section below).
Please note: For the single hierarchy, we have different configurations depending on the custom post type. This can be reflected in the subpath indicated above (for example, events and posts ) because this information is in the URL (for example, https://getpop.org/en/posts/the-winners-of-climate-change-techno-fixes/ and https://getpop.org/en/events/debate-post-fork/ ), so that, when clicking on a link, we will know the corresponding post type and can thus infer the corresponding route. However, this is not the case with the author hierarchy. As indicated earlier, an author may have three different configurations, depending on the user role ( individual , organization or community ); however, in this file, we've defined only one configuration for the author hierarchy, not three. That is because we are not able to tell from the URL what is the role of the author: user leo (under https://getpop.org/en/u/leo/ ) is an individual, whereas user pop (under https://getpop.org/en/u/pop/ ) is a community; however, their URLs have the same pattern. If we could instead have the URLs https://getpop.org/en/u/individuals/leo/ and https://getpop.org/en/u/communities/pop/ , then we could add a configuration for each user role. However, I've found no way to achieve this in WordPress. As a consequence, only for the API mode, we must merge the three routes (individuals, organizations and communities) into one, which will have all of the resources for the three cases; and clicking on the link for user leo will also load the resources for organizations and communities, even if we don't need them.
Finally, when a URL is requested, we obtain its route, from which we obtain the bundleGroup IDs (for both JavaScript and CSS assets). From each bundleGroup, we find the corresponding bundles under bundlegroups . Then, for each bundle, we obtain all resources under the key bundles . Finally, we identify which assets have not yet been loaded, and we load them by getting their source, which is stored under the key sources . The whole logic is coded starting from line 472 in resourceloader.js.
And with that, we have implemented code-splitting for our application! From now on, we can get better loading times by applying optimizations. Let's tackle that next.
5. Applying Optimizations
The objective is to load as little code as possible, as delayed as possible, and to cache as much of it as possible. Let's explore how to do this.
Splitting Up the Code Into Smaller Units
A single JavaScript asset may implement several functions (by calling popJSLibraryManager.register ), yet maybe only one of those functions is actually needed by the route. Thus, it makes sense to split up the asset into several subassets, implementing a single function on each of them, and extracting all common code from all of the functions into yet another asset, depended upon by all of them.
For instance, in the past, there was a unique file, waypoints.js , that implemented the functions waypointsFetchMore , waypointsTheater and a few more. However, in most cases, only the function waypointsFetchMore was needed, so I was loading the code for the function waypointsTheater unnecessarily. Then, I split up waypoints.js into the following assets:
- waypoints.js, with all common code and implementing no public functions;
- waypoints-fetchmore.js, which implements just the public function
waypointsFetchMore; - waypoints-theater.js, which implements just the public function
waypointsTheater.
Evaluating how to split the files is a manual job. Luckily, there is a tool that greatly eases the task: Chrome Developer Tools' “Coverage” tab, which displays in red those portions of JavaScript code that have not been invoked:
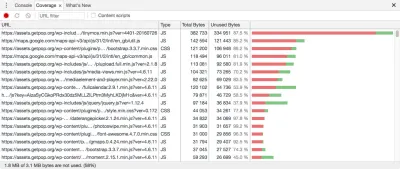
By using this tool, we can better understand how to split our JavaScript files into more granular units, thus reducing the amount of unneeded code that is loaded.
Integration With Service Workers
By precaching all of the resources using service workers, we can be pretty sure that, by the time the response is back from the server, all of the required assets will have been loaded and parsed. I wrote an article on Smashing Magazine on how to accomplish this.
Progressive Booting
PoP's architecture plays very nice with the concept of loading assets in different stages. When defining the JavaScript methods to execute on each module (by doing $this->add_jsmethod($methods, 'calendar') ), these can be set as either critical or non-critical . By default, all methods are set as non-critical, and critical methods must be explicitly defined by the developer, by adding an extra parameter: $this->add_jsmethod($methods, 'calendar', 'critical') . Then, we will be able to load scripts immediately for critical functions, and wait until the page is loaded to load non-critical functions, the JavaScript files of which are loaded using defer .
(function($){ window.popManager = { init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'critical'); ... }); window.addEventListener('load', function() { $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'non-critical'); ... }); }); ... }, ... }; })(jQuery);The gains from progressive booting are major: The JavaScript engine needs not spend time parsing non-critical JavaScript initially, when a quick response to the user is most important, and overall reduces the time to interactive.
Testing And Analizying Performance Gains
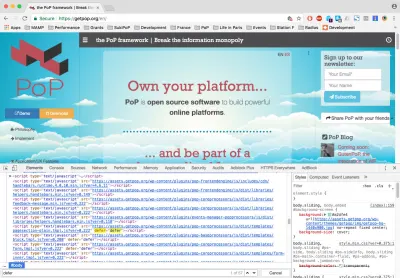
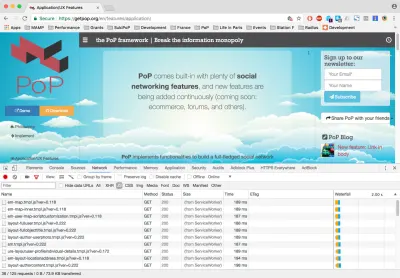
We can use https://getpop.org/en/, a PoP website, for testing purposes. When loading the home page, opening Chrome Developer Tools' “Elements” tab and searching for “defer”, it shows 4 occurrences. Thanks to progressive booting, that is 4 bundleGroup JavaScript files containing the contents of 57 Javascript files with non-critical methods that could wait until the website finished loading to be loaded:
If we now switch to the “Network” tab and click on a link, we can see which assets get loaded. For instance, click on the link “Application/UX Features” on the left side. Filtering by JavaScript, we see it loaded 38 files, including JavaScript libraries and Handlebars templates. Filtering by CSS, we see it loaded 9 files. These 47 files have all been loaded on demand:
Let's check whether the loading time got boosted. We can use WebPagetest to measure the application with and without code-splitting, and calculate the difference.
- Without code-splitting: testing URL, WebPagetest results

- With code-splitting, loading resources: testing URL, WebPagetest Results

- With code-splitting, loading a bundleGroup: testing URL, WebPagetest Results

We can see that when loading the app bundle with all resources or when doing code-splitting and loading resources, there is not so much gain. However, when doing code-splitting and loading a bundleGroup, the gains are significant: 1.7 seconds in loading time, 500 milliseconds to the first meaningful paint, and 1 second to interactive.
Conclusion: Is It Worth It?
You might be thinking, Is it worth it all this trouble? Let's analyze the advantages and disadvantages of implementing our own code-splitting features.
Niedogodności
- Musimy to utrzymać.
Gdybyśmy po prostu korzystali z Webpack, moglibyśmy polegać na jego społeczności, aby aktualizować oprogramowanie i czerpać korzyści z ekosystemu wtyczek. - Uruchomienie skryptów zajmuje trochę czasu.
Witryna PoP Agenda Urbana ma 304 różne trasy, z których produkuje 422 zestawy unikalnych zasobów. W przypadku tej witryny uruchomienie skryptu generującego mapę zależności zasobów przy użyciu MacBooka Pro z 2012 roku zajmuje około 8 minut, a uruchomienie skryptu generującego listy ze wszystkimi zasobami oraz tworzącego pliki bundle i bundleGroup zajmuje 15 minut . To więcej niż wystarczająco dużo czasu, aby wybrać się na kawę! - Wymaga środowiska inscenizacyjnego.
Jeśli musimy poczekać około 25 minut na uruchomienie skryptów, nie możemy ich uruchomić w środowisku produkcyjnym. Musielibyśmy mieć środowisko pomostowe z dokładnie taką samą konfiguracją jak system produkcyjny. - Do strony dodawany jest dodatkowy kod, tylko do zarządzania.
85 KB kodu nie działa sam w sobie, ale po prostu kod do zarządzania innym kodem. - Dodano złożoność.
Jest to nieuniknione w każdym przypadku, jeśli chcemy podzielić nasze aktywa na mniejsze jednostki. Webpack zwiększyłby również złożoność aplikacji.
Zalety
- Działa z WordPressem.
Webpack nie działa z WordPress po wyjęciu z pudełka i aby działał, wymaga pewnego obejścia. To rozwiązanie działa po wyjęciu z pudełka dla WordPressa (pod warunkiem, że zainstalowany jest PoP). - Jest skalowalny i rozszerzalny.
Rozmiar i złożoność aplikacji może rosnąć bez ograniczeń, ponieważ pliki JavaScript są ładowane na żądanie. - Obsługuje Gutenberga (czyli WordPressa jutra).
Ponieważ pozwala nam ładować frameworki JavaScript na żądanie, będzie obsługiwać bloki Gutenberga (zwane Gutenblocks), które mają być kodowane we frameworku wybranym przez programistę, co może skutkować tym, że dla tej samej aplikacji będą potrzebne różne frameworki. - To wygodne.
Narzędzie do budowania zajmuje się generowaniem plików konfiguracyjnych. Oprócz czekania, nie jest potrzebny żaden dodatkowy wysiłek z naszej strony. - Ułatwia optymalizację.
Obecnie, jeśli wtyczka WordPress chce selektywnie ładować zasoby JavaScript, użyje wielu warunków, aby sprawdzić, czy identyfikator strony jest właściwy. Dzięki temu narzędziu nie ma takiej potrzeby; proces jest automatyczny. - Aplikacja załaduje się szybciej.
To był cały powód, dla którego zakodowaliśmy to narzędzie. - Wymaga środowiska inscenizacyjnego.
Pozytywnym efektem ubocznym jest zwiększona niezawodność: nie będziemy uruchamiać skryptów na produkcji, więc niczego tam nie zepsujemy; proces wdrażania nie zawiedzie z powodu nieoczekiwanego zachowania; a programista będzie zmuszony przetestować aplikację przy użyciu tej samej konfiguracji, co w środowisku produkcyjnym. - Jest dostosowany do naszej aplikacji.
Nie ma narzutu ani obejść. Otrzymujemy dokładnie to, czego potrzebujemy, w oparciu o architekturę, z którą pracujemy.
Podsumowując: tak, warto, ponieważ teraz jesteśmy w stanie zastosować aktywa ładowania na żądanie na naszej stronie WordPress i przyspieszyć jej ładowanie.
Dalsze zasoby
- Pakiet internetowy, w tym przewodnik „”Podział kodu”
- „Better Webpack Builds” (wideo), K. Adam White
Integracja Webpacka z WordPress - „Gutenberg i WordPress jutra”, Morten Rand-Hendriksen, WP Tavern
- „WordPress bada podejście JavaScript Framework-Agnostic do budowania bloków Gutenberga”, Sarah Gooding, WP Tavern