
CNN vs RNN: różnica między CNN a RNN
Opublikowany: 2021-02-25Spis treści
Wstęp
W dziedzinie sztucznej inteligencji sieci neuronowe inspirowane ludzkim mózgiem są szeroko stosowane w wydobywaniu i przetwarzaniu złożonych informacji z różnych danych oraz wykorzystywaniu w takich zastosowaniach zarówno splotowych sieci neuronowych (CNN), jak i rekurencyjnych sieci neuronowych (RNN). okazują się przydatne.
W tym artykule zrozumiemy koncepcje zarówno splotowych sieci neuronowych, jak i rekurencyjnych sieci neuronowych, zobaczymy ich zastosowania i rozróżnimy różnice między obydwoma popularnymi rodzajami sieci neuronowych.
Ucz się szkoleń z zakresu uczenia maszynowego na najlepszych światowych uniwersytetach. Zdobywaj programy Masters, Executive PGP lub Advanced Certificate Programy, aby przyspieszyć swoją karierę.
Sieci neuronowe i głębokie uczenie
Zanim przejdziemy do koncepcji zarówno splotowych sieci neuronowych, jak i rekurencyjnych sieci neuronowych, zrozummy koncepcje sieci neuronowych i ich powiązanie z głębokim uczeniem.
W ostatnim czasie Deep Learning jest kiedyś pojęciem szeroko stosowanym w wielu dziedzinach i dlatego jest obecnie gorącym tematem. Ale jaki jest powód, dla którego tak szeroko się o tym mówi? Aby odpowiedzieć na to pytanie, poznamy koncepcję sieci neuronowych.
Krótko mówiąc, sieci neuronowe są podstawą uczenia głębokiego. Są to zbiór warstw składających się z wysoce powiązanych ze sobą elementów, znanych jako neurony, które wykonują serię transformacji na danych, które generują własne zrozumienie tych danych, które nazywamy terminem cechy.

Co to są sieci neuronowe?
Pierwszą koncepcją, z którą musimy się uporać, są sieci neuronowe. Wiemy, że ludzki mózg jest jedną ze złożonych struktur, jakie kiedykolwiek badano. Ze względu na jego złożoność pojawiły się ogromne trudności w rozwikłaniu jego wewnętrznych mechanizmów, ale obecnie podejmuje się kilka rodzajów badań w celu ujawnienia jego tajemnic. Ten ludzki mózg służy jako inspiracja modeli sieci neuronowych.
Z definicji sieci neuronowe są funkcjonalnymi jednostkami głębokiego uczenia, które wykorzystują te sieci neuronowe do naśladowania aktywności mózgu i rozwiązywania złożonych problemów. Kiedy dane wejściowe są przesyłane do sieci neuronowej, są one przetwarzane przez warstwy perceptronu i ostatecznie dają wynik.
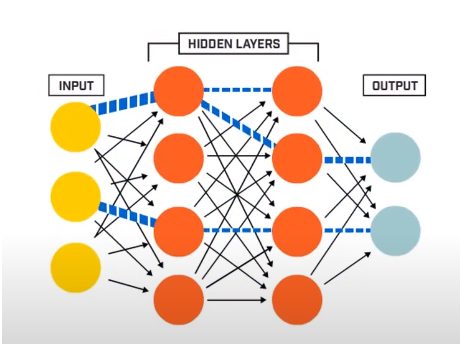
Sieć neuronowa składa się w zasadzie z 3 warstw –
- Warstwa wejściowa
- Ukryte warstwy
- Warstwa wyjściowa
Warstwa wejściowa odczytuje dane wejściowe, które są wprowadzane do systemu sieci neuronowej w celu dalszego wstępnego przetwarzania przez kolejne warstwy sztucznych neuronów. Wszystkie warstwy istniejące między warstwą wejściową a wyjściową są określane jako warstwy ukryte.
To właśnie w tych ukrytych warstwach obecne w nich neurony wykorzystują ważone dane wejściowe i uprzedzenia i wytwarzają dane wyjściowe wykorzystując funkcje aktywacji. Warstwa wyjściowa to ostatnia warstwa neuronów, która daje nam wyjście dla danego programu.
Źródło
Jak działają sieci neuronowe?
Teraz, gdy mamy już pojęcie o podstawowej strukturze sieci neuronowych, pójdziemy dalej i zrozumiemy, jak one działają. Aby zrozumieć jego działanie, musimy najpierw poznać jedną z podstawowych struktur sieci neuronowych, znaną jako perceptron.
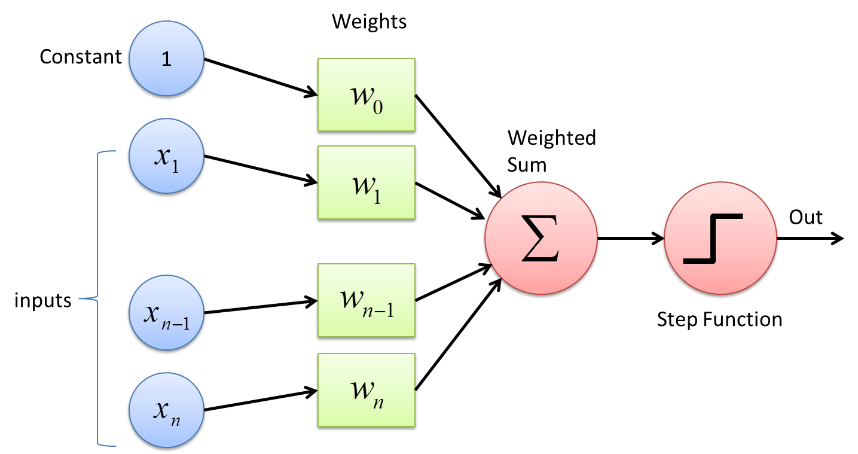
Perceptron to rodzaj sieci neuronowej, która ma najbardziej podstawową formę. Jest to prosta sztuczna sieć neuronowa ze sprzężeniem do przodu z tylko jedną ukrytą warstwą. W sieci Perceptron każdy neuron jest połączony z każdym innym neuronem w kierunku do przodu.
Połączenia między tymi neuronami są ważone, dzięki czemu informacja przekazywana między dwoma neuronami jest wzmacniana lub osłabiana przez te wagi. W procesie uczenia sieci neuronowych to właśnie te wagi są dostosowywane, aby uzyskać prawidłową wartość.
Perceptron korzysta z funkcji klasyfikatora binarnego, w którym mapuje wektor zmiennych o charakterze binarnym na pojedyncze wyjście binarne. Można to również wykorzystać w uczeniu nadzorowanym. Kroki w algorytmie uczenia perceptronu to:
- Pomnóż wszystkie dane wejściowe przez ich wagi w, gdzie w są liczbami rzeczywistymi, które mogą być początkowo ustalone lub losowane.
- Dodać iloczyn razem, aby otrzymać sumę ważoną, ∑ wj xj
- Po uzyskaniu ważonej sumy wejść, funkcja aktywacji jest stosowana w celu określenia, czy suma ważona jest większa niż konkretna wartość progowa, czy nie, w zależności od zastosowanej funkcji aktywacji. Wyjście jest przypisane jako 1 lub 0 w zależności od warunku progu. Tutaj wartość „-próg” odnosi się również do terminu bias, b.
W ten sposób algorytm uczenia perceptronu może zostać wykorzystany do uruchomienia (wartość =1) neuronów obecnych w sieciach neuronowych, które są obecnie projektowane i rozwijane. Inną reprezentacją algorytmu uczenia perceptronu jest:
f(x) = 1, jeśli ∑ wj xj + b ≥ 0
0, jeśli ∑ wj xj + b < 0
Chociaż perceptrony nie są obecnie szeroko stosowane, nadal pozostają jednym z podstawowych pojęć w sieciach neuronowych. Podczas dalszych badań zrozumiano, że niewielkie zmiany wag lub odchylenia nawet w jednym perceptronie mogą znacznie zmienić wynik z 1 na 0 lub odwrotnie. To była jedna z głównych wad Perceptrona. W związku z tym opracowano bardziej złożone funkcje aktywacji, takie jak ReLU, funkcje sigmoidalne, które wprowadzają jedynie umiarkowane zmiany wag i odchyleń sztucznych neuronów.
Źródło
Konwolucyjne sieci neuronowe
Splotowa sieć neuronowa to algorytm głębokiego uczenia się, który przyjmuje obraz jako dane wejściowe, przypisuje różne wagi i odchylenia do różnych części obrazu, tak aby można je było odróżnić od siebie. Gdy staną się one rozróżnialne, przy użyciu różnych funkcji aktywacji, Konwolucyjny model sieci neuronowej może wykonywać kilka zadań w domenie przetwarzania obrazu, w tym rozpoznawanie obrazu, klasyfikację obrazu, wykrywanie obiektów i twarzy itp.
Podstawą modelu splotowej sieci neuronowej jest to, że otrzymuje on obraz wejściowy. Obraz wejściowy może być oznaczony etykietą (np. kot, pies, lew itp.) lub bez etykiety. W zależności od tego algorytmy Deep Learning są podzielone na dwa typy, a mianowicie nadzorowane algorytmy, w których obrazy są oznaczone etykietami, i nienadzorowane algorytmy, w których obrazom nie przypisano żadnej szczególnej etykiety.
Dla maszyny komputerowej obraz wejściowy jest postrzegany jako tablica pikseli, częściej w postaci matrycy. Obrazy mają przeważnie postać hxwxd (gdzie h = wysokość, w = szerokość, d = wymiar). Na przykład obraz o rozmiarze matrycy 16 x 16 x 3 oznacza obraz RGB (3 oznacza wartości RGB). Z drugiej strony obraz matrycy 14 x 14 x 1 reprezentuje obraz w skali szarości.
Źródło
Warstwy splotowej sieci neuronowej
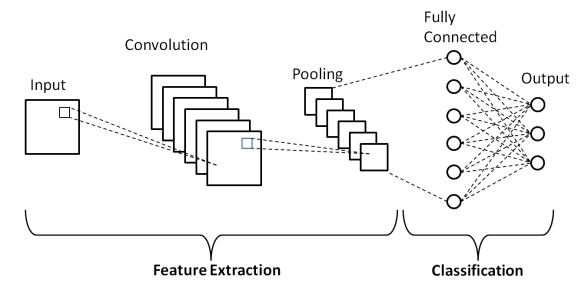
Jak pokazano w powyższej podstawowej architekturze splotowej sieci neuronowej, model CNN składa się z kilku warstw, przez które obrazy wejściowe przechodzą wstępne przetwarzanie w celu uzyskania danych wyjściowych. Zasadniczo warstwy te są podzielone na dwie części –
- Pierwsze trzy warstwy, w tym warstwa wejściowa, warstwa splotu i warstwa pulowania, która działa jako narzędzie do wyodrębniania cech w celu uzyskania cech na poziomie podstawowym z obrazów wprowadzonych do modelu.
- Ostatnia warstwa w pełni połączona i warstwa wyjściowa wykorzystują dane wyjściowe warstw wyodrębniania elementów i przewidują klasę obrazu w zależności od wyodrębnionych elementów.
Pierwsza warstwa to warstwa wejściowa , w której obraz jest podawany do modelu Convolutional Neural Network Model w postaci tablicy macierzy tj. 32 x 32 x 3, gdzie 3 oznacza, że obraz jest obrazem RGB o równej wysokości i szerokości 32 piksele. Następnie te obrazy wejściowe przechodzą przez warstwę splotową , w której wykonywana jest matematyczna operacja Splotu.

Obraz wejściowy jest splatany z inną macierzą kwadratową znaną jako jądro lub filtr. Przesuwając jądro jeden po drugim nad pikselami obrazu wejściowego, uzyskujemy obraz wyjściowy znany jako mapa cech, który dostarcza informacji o podstawowych cechach obrazu, takich jak krawędzie i linie.
Po warstwie splotowej następuje warstwa Pooling, której celem jest zmniejszenie rozmiaru mapy obiektów w celu zmniejszenia kosztów obliczeniowych. Odbywa się to za pomocą kilku rodzajów puli, takich jak pule maksymalne, pule średnie i pule sum.
Warstwa w pełni połączona (FC) jest przedostatnią warstwą modelu splotowej sieci neuronowej, w której warstwy są spłaszczane i podawane do warstwy FC. Tutaj, przy użyciu funkcji aktywacji, takich jak funkcje Sigmoid, ReLU i tanH, przewidywanie etykiety odbywa się i jest podawane w końcowej warstwie wyjściowej .
Gdzie CNN zawodzą
Przy tak wielu użytecznych zastosowaniach Convolutional Neural Network w wizualnych danych obrazowych, CNN mają niewielką wadę, ponieważ nie działają dobrze z sekwencją obrazów (wideo) i nie potrafią interpretować informacji czasowych i bloków tekstu.
Aby poradzić sobie z danymi czasowymi lub sekwencyjnymi, takimi jak zdania, potrzebujemy algorytmów, które uczą się na podstawie danych z przeszłości, a także danych przyszłych w sekwencji. Na szczęście rekurencyjne sieci neuronowe właśnie to robią.
Rekurencyjne sieci neuronowe
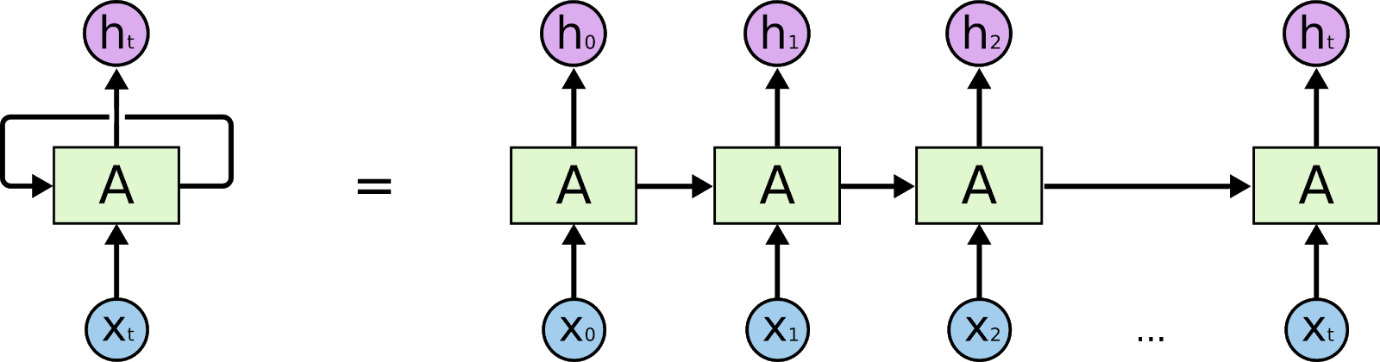
Rekurencyjne sieci neuronowe to sieci zaprojektowane do interpretacji informacji czasowych lub sekwencyjnych. RNN używają innych punktów danych w sekwencji, aby lepiej przewidywać. Robią to, przyjmując dane wejściowe i ponownie wykorzystując aktywacje poprzednich lub późniejszych węzłów w sekwencji, aby wpłynąć na dane wyjściowe.
Źródło
Dzięki pamięci wewnętrznej sieci neuronowe rekurencyjne mogą zapamiętywać istotne szczegóły, takie jak otrzymane dane wejściowe, dzięki czemu są bardzo precyzyjne w przewidywaniu, co będzie dalej. Dlatego są najbardziej preferowanym algorytmem dla danych sekwencyjnych, takich jak szeregi czasowe, mowa, tekst, audio, wideo i wiele innych. Rekurencyjne sieci neuronowe mogą zapewnić znacznie głębsze zrozumienie sekwencji i jej kontekstu w porównaniu z innymi algorytmami.
Jak działają powtarzalne sieci neuronowe?
Podstawy zrozumienia pracy nad Recurrent Neural Networks są takie same jak w przypadku Convolutional Neural Networks, prostych sieci neuronowych typu feed-forward, znanych również jako Perceptron. Dodatkowo, w sieciach Recurrent Neural, dane wyjściowe z poprzedniego kroku są podawane jako dane wejściowe do bieżącego kroku. W większości sieci neuronowych wyjście jest zwykle niezależne od wejść i odwrotnie, jest to podstawowa różnica między RNN a innymi sieciami neuronowymi.
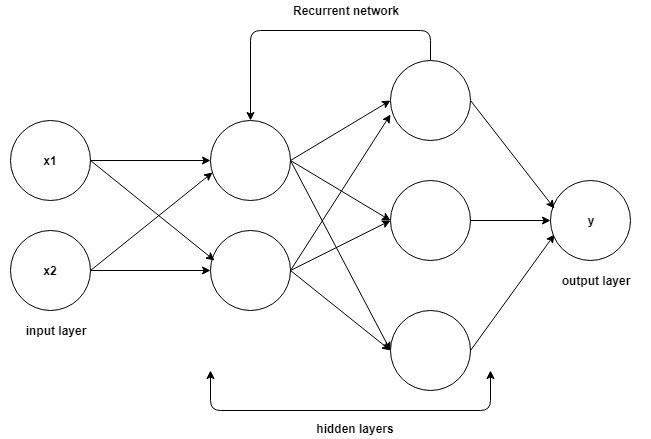
Źródło
Dlatego RNN ma dwa wejścia: teraźniejszość i niedawną przeszłość. Jest to ważne, ponieważ sekwencja danych zawiera kluczowe informacje o tym, co będzie dalej, i dlatego RNN może robić rzeczy, których nie potrafią inne algorytmy. Główną i najważniejszą cechą Recurrent Neural Networks jest stan Ukryty, który zapamiętuje pewne informacje o sekwencji.
Rekurencyjne sieci neuronowe posiadają pamięć, która przechowuje wszystkie informacje o tym, co zostało obliczone. Używając tych samych parametrów dla każdego wejścia i wykonując to samo zadanie na wszystkich wejściach lub warstwach ukrytych, zmniejsza się złożoność parametrów.
Różnica między CNN a RNN
| Konwolucyjne sieci neuronowe | Rekurencyjne sieci neuronowe |
| W głębokim uczeniu, splotowa sieć neuronowa (CNN lub ConvNet) to klasa głębokich sieci neuronowych, najczęściej stosowana do analizy obrazów wizualnych. | Rekurencyjna sieć neuronowa (RNN) to klasa sztucznych sieci neuronowych, w których połączenia między węzłami tworzą skierowany graf wzdłuż sekwencji czasowej. |
| Nadaje się do danych przestrzennych, takich jak obrazy. | RNN jest używany do danych czasowych, zwanych również danymi sekwencyjnymi. |
| CNN jest rodzajem sztucznej sieci neuronowej ze sprzężeniem do przodu z odmianami wielowarstwowych perceptronów zaprojektowanych do wykorzystywania minimalnych ilości przetwarzania wstępnego. | RNN, w przeciwieństwie do sieci neuronowych ze sprzężeniem do przodu, może wykorzystywać swoją pamięć wewnętrzną do przetwarzania dowolnych sekwencji danych wejściowych. |
| CNN jest uważany za silniejszy niż RNN. | RNN zawiera mniejszą kompatybilność funkcji w porównaniu z CNN. |
| Ta CNN pobiera dane wejściowe o stałych rozmiarach i generuje dane wyjściowe o stałych rozmiarach. | RNN może obsługiwać dowolne długości wejścia/wyjścia. |
| CNN są idealne do przetwarzania obrazów i wideo. | RNN są idealne do analizy tekstu i mowy. |
| Zastosowania obejmują rozpoznawanie obrazu, klasyfikację obrazu, analizę obrazu medycznego, wykrywanie twarzy i widzenie komputerowe. | Zastosowania obejmują tłumaczenie tekstu, przetwarzanie języka naturalnego, tłumaczenie języka, analizę nastrojów i analizę mowy. |
Wniosek
Dlatego w tym artykule o różnicach między dwoma najpopularniejszymi typami sieci neuronowych, splotowymi sieciami neuronowymi i rekurencyjnymi sieciami neuronowymi, poznaliśmy podstawową strukturę sieci neuronowej, wraz z podstawami zarówno CNN, jak i RNN, a na koniec podsumowaliśmy krótkie porównanie obu z ich zastosowaniami w świecie rzeczywistym.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, zapoznaj się z programem IIIT-B i upGrad Executive PG w zakresie uczenia maszynowego i sztucznej inteligencji , który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadań, IIIT Status -B Alumni, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Dlaczego CNN jest szybsze niż RNN?
Sieci CNN są szybsze niż sieci RNN, ponieważ są zaprojektowane do obsługi obrazów, podczas gdy sieci RNN są przeznaczone do obsługi tekstu. Chociaż RNN można wytrenować do obsługi obrazów, nadal trudno jest im oddzielić kontrastujące ze sobą elementy, które są bliżej siebie. Na przykład, jeśli masz zdjęcie twarzy z oczami, nosem i ustami, RNN mają trudności z ustaleniem, którą funkcję wyświetlić jako pierwszą. Sieci CNN wykorzystują siatkę punktów, a za pomocą algorytmu można je nauczyć rozpoznawania kształtów i wzorów. CNN są lepsze niż RNN w sortowaniu obrazów; są szybsze niż RNN, ponieważ są łatwe do obliczenia i lepiej sortują obrazy.
Do czego służy RNN?
Rekurencyjne sieci neuronowe (RNN) to klasa sztucznych sieci neuronowych, w których połączenia między jednostkami tworzą ukierunkowany cykl. Wyjście jednej jednostki staje się wejściem innej jednostki i tak dalej, podobnie jak wyjście jednego neuronu staje się wejściem innego. Sieci RNN są z powodzeniem wykorzystywane do wykonywania złożonych zadań, takich jak rozpoznawanie mowy i tłumaczenie maszynowe, które są trudne do wykonania standardowymi metodami.
Co to jest RNN i czym różni się od Feedforward Neural Networks?
Rekurencyjne sieci neuronowe (RNN) to rodzaj sieci neuronowych, które służą do przetwarzania danych sekwencyjnych. Rekurencyjna sieć neuronowa składa się z warstwy wejściowej, co najmniej jednej warstwy ukrytej i warstwy wyjściowej. Ukryte warstwy są przeznaczone do uczenia się wewnętrznych reprezentacji danych wejściowych, które są następnie prezentowane warstwie wyjściowej jako reprezentacja zewnętrzna. RNN jest szkolony za pomocą wstecznej propagacji. Sieci RNN są często porównywane z sieciami neuronowymi ze sprzężeniem do przodu (FNN). Podczas gdy zarówno RNN, jak i FNN mogą uczyć się wewnętrznych reprezentacji danych, RNN są w stanie nauczyć się długoterminowych zależności, do których FNN nie są zdolne.