
Zrozumienie GraphQl po stronie klienta z klientem Apollo w aplikacjach React
Opublikowany: 2022-03-10Według State of JavaScript 2019 38,7% programistów chciałoby korzystać z GraphQL, podczas gdy 50,8% programistów chciałoby uczyć się GraphQL.
Będąc językiem zapytań, GraphQL upraszcza przepływ pracy przy tworzeniu aplikacji klienckiej. Eliminuje złożoność zarządzania punktami końcowymi interfejsu API w aplikacjach po stronie klienta, ponieważ udostępnia pojedynczy punkt końcowy HTTP do pobierania wymaganych danych. Tym samym eliminuje overfetching i underfetching danych, jak w przypadku REST.
Ale GraphQL to tylko język zapytań. Aby z niego łatwo korzystać, potrzebujemy platformy, która wykona za nas ciężkie podnoszenie. Jedną z takich platform jest Apollo.
Platforma Apollo to implementacja GraphQL, która przesyła dane między chmurą (serwerem) do interfejsu użytkownika aplikacji. Gdy używasz klienta Apollo, cała logika pobierania danych, śledzenia, ładowania i aktualizacji interfejsu użytkownika jest zamknięta w haczyku useQuery (tak jak w przypadku Reacta). Dlatego pobieranie danych jest deklaratywne. Ma również pamięć podręczną o zerowej konfiguracji. Po prostu konfigurując Apollo Client w swojej aplikacji, otrzymujesz inteligentną pamięć podręczną po wyjęciu z pudełka, bez dodatkowej konfiguracji.
Apollo Client jest również interoperacyjny z innymi frameworkami, takimi jak Angular, Vue.js i React.
Uwaga : ten samouczek przyda się tym, którzy w przeszłości pracowali z RESTful lub innymi formami API po stronie klienta i chcą sprawdzić, czy warto spróbować GraphQL. Oznacza to, że powinieneś już wcześniej pracować z API; tylko wtedy będziesz w stanie zrozumieć, jak korzystny może być dla Ciebie GraphQL. Podczas gdy będziemy omawiać kilka podstaw GraphQL i Apollo Client, przyda się dobra znajomość JavaScript i React Hooks.
Podstawy GraphQL
Ten artykuł nie jest kompletnym wprowadzeniem do GraphQL, ale przed kontynuacją zdefiniujemy kilka konwencji.
Co to jest GraphQL?
GraphQL to specyfikacja opisująca deklaratywny język zapytań, którego klienci mogą używać do zapytania API o dokładnie takie dane, jakich potrzebują. Osiąga się to poprzez utworzenie silnego schematu typów dla Twojego interfejsu API, z najwyższą elastycznością. Zapewnia również, że interfejs API rozwiązuje dane i sprawdza poprawność zapytań klientów względem schematu. Ta definicja oznacza, że GraphQL zawiera pewne specyfikacje, które czynią go deklaratywnym językiem zapytań, z interfejsem API, który jest statycznie typowany (zbudowany na bazie Typescript) i umożliwia klientowi wykorzystanie tych systemów typów do zapytania API o dokładne dane, których potrzebuje .
Tak więc, jeśli utworzyliśmy niektóre typy z pewnymi polami, to po stronie klienta moglibyśmy powiedzieć: „Daj nam te dane z dokładnie tymi polami”. Wtedy API odpowie dokładnie tym kształtem, tak jakbyśmy używali systemu typów w silnie typizowanym języku. Możesz dowiedzieć się więcej w moim artykule maszynopisu.
Przyjrzyjmy się niektórym konwencjom GraphQl, które pomogą nam w dalszej pracy.
Podstawy
- Operacje
W GraphQL każda wykonana akcja nazywana jest operacją. Jest kilka operacji, a mianowicie:- Zapytanie
Ta operacja dotyczy pobierania danych z serwera. Możesz też nazwać to pobieraniem tylko do odczytu. - Mutacja
Ta operacja obejmuje tworzenie, aktualizowanie i usuwanie danych z serwera. Jest to popularnie nazywane operacją CUD (tworzenie, aktualizowanie i usuwanie). - Subskrypcje
Ta operacja w GraphQL polega na wysyłaniu danych z serwera do jego klientów, gdy mają miejsce określone zdarzenia. Są one zwykle implementowane za pomocą WebSockets.
- Zapytanie
W tym artykule zajmiemy się tylko operacjami zapytań i mutacji.
- Nazwy operacji
Istnieją unikalne nazwy zapytań po stronie klienta i operacji mutacji. - Zmienne i argumenty
Operacje mogą definiować argumenty, podobnie jak funkcje w większości języków programowania. Zmienne te można następnie przekazać do wywołań zapytań lub mutacji wewnątrz operacji jako argumenty. Oczekuje się, że zmienne zostaną podane w czasie wykonywania podczas wykonywania operacji z klienta. - Aliasy
Jest to konwencja w GraphQL po stronie klienta, która obejmuje zmianę nazw pełnych lub niejasnych nazw pól na proste i czytelne nazwy pól dla interfejsu użytkownika. Aliasowanie jest konieczne w przypadkach użycia, w których nie chcesz mieć sprzecznych nazw pól.
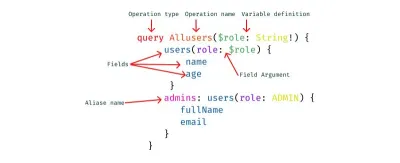
Co to jest GraphQL po stronie klienta?
Kiedy inżynier frontonu buduje komponenty interfejsu użytkownika przy użyciu dowolnego frameworka, takiego jak Vue.js lub (w naszym przypadku) React, te komponenty są modelowane i projektowane na podstawie określonego wzorca na kliencie, aby pasowały do danych, które zostaną pobrane z serwera.
Jednym z najczęstszych problemów z interfejsami API RESTful jest nadmierne pobieranie i niedostateczne pobieranie. Dzieje się tak, ponieważ jedynym sposobem, w jaki klient może pobrać dane, jest trafienie do punktów końcowych, które zwracają stałe struktury danych. Overfetching w tym kontekście oznacza, że klient pobiera więcej informacji, niż jest to wymagane przez aplikację.
Z drugiej strony w GraphQL wystarczy wysłać pojedyncze zapytanie do serwera GraphQL, które zawiera wymagane dane. Serwer odpowiedziałby wówczas obiektem JSON zawierającym dokładnie te dane, których żądałeś — stąd bez nadmiernego pobierania. Sebastian Eschweiler wyjaśnia różnice między RESTful API a GraphQL.
GraphQL po stronie klienta to infrastruktura po stronie klienta, która łączy się z danymi z serwera GraphQL w celu wykonywania następujących funkcji:
- Zarządza danymi, wysyłając zapytania i mutując dane bez konieczności samodzielnego konstruowania żądań HTTP. Możesz poświęcić mniej czasu na hydraulikę danych, a więcej na tworzenie rzeczywistej aplikacji.
- Zarządza dla Ciebie złożonością pamięci podręcznej. Dzięki temu możesz przechowywać i pobierać dane pobrane z serwera bez ingerencji osób trzecich i łatwo uniknąć ponownego pobierania zduplikowanych zasobów. W ten sposób identyfikuje, kiedy dwa zasoby są takie same, co jest świetne w przypadku złożonej aplikacji.
- Dzięki temu Twój interfejs użytkownika jest zgodny z Optymistycznym interfejsem użytkownika, konwencją, która symuluje wyniki mutacji (tj. utworzone dane) i aktualizuje interfejs użytkownika nawet przed otrzymaniem odpowiedzi z serwera. Po otrzymaniu odpowiedzi z serwera optymistyczny wynik jest odrzucany i zastępowany rzeczywistym wynikiem.
Aby uzyskać więcej informacji na temat GraphQL po stronie klienta, poświęć godzinę na współtwórcę GraphQL i innych fajnych ludzi w GraphQL Radio.
Co to jest klient Apollo?
Apollo Client to interoperacyjny, bardzo elastyczny, oparty na społeczności klient GraphQL dla JavaScript i platform natywnych. Jego imponujące funkcje obejmują solidne narzędzie do zarządzania stanem (Apollo Link), system buforowania z zerową konfiguracją, deklaratywne podejście do pobierania danych, łatwą do zaimplementowania paginację i Optymistyczny interfejs użytkownika dla aplikacji po stronie klienta.
Apollo Client przechowuje nie tylko stan z danych pobranych z serwera, ale także stan, który utworzył lokalnie na twoim kliencie; w związku z tym zarządza stanem zarówno danych API, jak i danych lokalnych.
Należy również zauważyć, że możesz używać klienta Apollo razem z innymi narzędziami do zarządzania stanem, takimi jak Redux, bez konfliktów. Ponadto istnieje możliwość migracji zarządzania stanem, powiedzmy, z Redux do klienta Apollo (co wykracza poza zakres tego artykułu). Ostatecznie głównym celem Apollo Client jest umożliwienie inżynierom bezproblemowego wysyłania zapytań do danych w interfejsie API.
Funkcje klienta Apollo
Apollo Client zdobył uznanie tak wielu inżynierów i firm dzięki swoim niezwykle pomocnym funkcjom, które sprawiają, że tworzenie nowoczesnych, solidnych aplikacji jest dziecinnie proste. Następujące funkcje są zapiekane w:
- Buforowanie
Apollo Client obsługuje buforowanie w locie. - Optymistyczny interfejs użytkownika
Apollo Client ma świetne wsparcie dla Optimistic UI. Polega na chwilowym wyświetlaniu końcowego stanu operacji (mutacji) w trakcie trwania operacji. Po zakończeniu operacji rzeczywiste dane zastępują dane optymistyczne. - Paginacja
Apollo Client posiada wbudowaną funkcjonalność, która ułatwia zaimplementowanie stronicowania w Twojej aplikacji. Załatwia większość technicznych problemów związanych z pobieraniem listy danych, zarówno w postaci poprawek, jak i na raz, za pomocą funkcjifetchMore, która jest dostarczana z hakiemuseQuery.
W tym artykule przyjrzymy się wybranym z tych funkcji.
Dość teorii. Zapnij pasy i weź filiżankę kawy do swoich naleśników, ponieważ ubrudzimy sobie ręce.
Tworzenie naszej aplikacji internetowej
Ten projekt jest inspirowany Scottem Mossem.
Zbudujemy prostą aplikację internetową sklepu zoologicznego, której funkcje obejmują:
- ściąganie naszych zwierzaków z serwera;
- tworzenie zwierzaka (co obejmuje stworzenie imienia, typu zwierzaka i wizerunku);
- za pomocą Optymistycznego interfejsu użytkownika;
- używanie paginacji do segmentacji naszych danych.
Aby rozpocząć, sklonuj repozytorium, upewniając się, że gałąź starter jest tym, co sklonowałeś.
Pierwsze kroki
- Zainstaluj rozszerzenie Apollo Client Developer Tools dla przeglądarki Chrome.
- Korzystając z interfejsu wiersza poleceń (CLI), przejdź do katalogu sklonowanego repozytorium i uruchom polecenie, aby uzyskać wszystkie zależności:
npm install. - Uruchom polecenie
npm run app, aby uruchomić aplikację. - Pozostając w folderze głównym, uruchom polecenie
npm run server. Uruchomi to dla nas nasz serwer zaplecza, z którego będziemy korzystać w miarę postępów.
Aplikacja powinna otworzyć się w skonfigurowanym porcie. Mój to https://localhost:1234/ ; twój jest prawdopodobnie czymś innym.
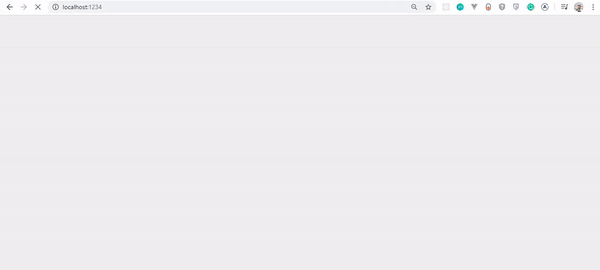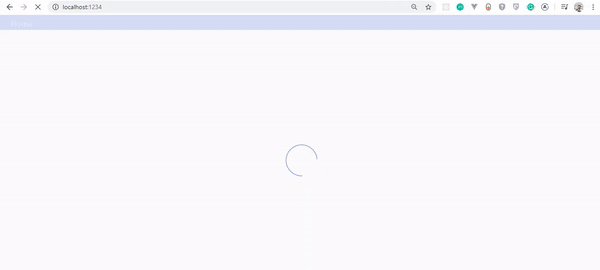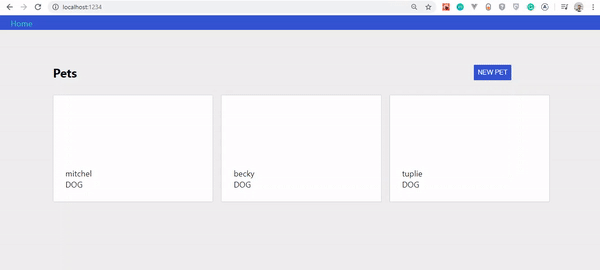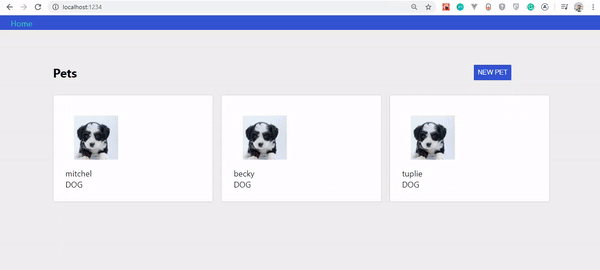
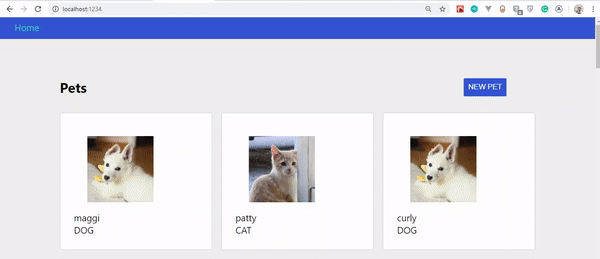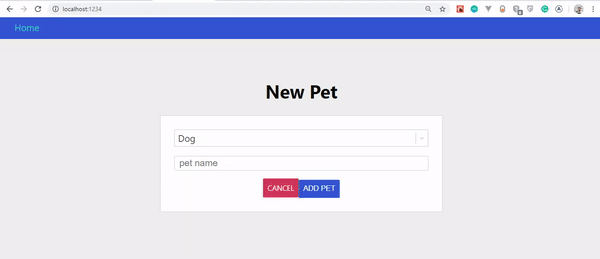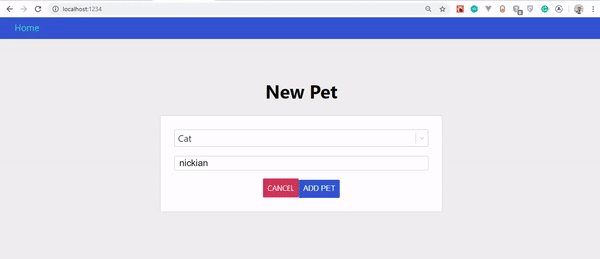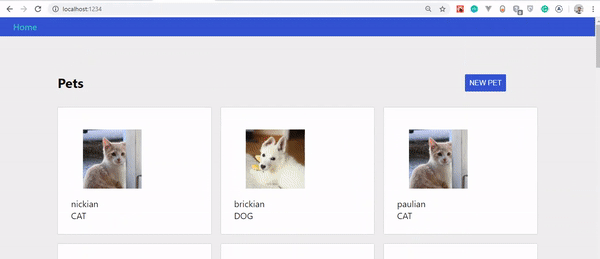
Jeśli wszystko działało dobrze, Twoja aplikacja powinna wyglądać tak:
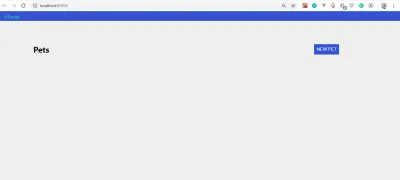
Zauważysz, że nie mamy zwierząt do pokazania. To dlatego, że takiej funkcjonalności jeszcze nie stworzyliśmy.
Jeśli poprawnie zainstalowałeś Apollo Client Developer Tools, otwórz narzędzia programistyczne i kliknij ikonę w zasobniku. Zobaczysz „Apollo” i coś takiego:
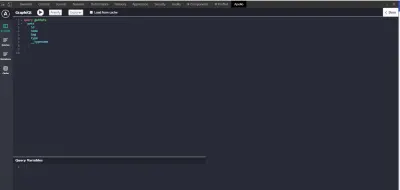
Podobnie jak narzędzia programistyczne Redux i React, będziemy używać narzędzi programistycznych Apollo Client do pisania i testowania naszych zapytań i mutacji. Rozszerzenie jest dostarczane z GraphQL Playground.
Pobieranie zwierząt
Dodajmy funkcję, która pobiera zwierzęta. Przejdź do client/src/client.js . Napiszemy klienta Apollo, połączymy go z API, wyeksportujemy jako klienta domyślnego i napiszemy nowe zapytanie.
Skopiuj następujący kod i wklej go w client.js :
import { ApolloClient } from 'apollo-client' import { InMemoryCache } from 'apollo-cache-inmemory' import { HttpLink } from 'apollo-link-http' const link = new HttpLink({ uri: 'https://localhost:4000/' }) const cache = new InMemoryCache() const client = new ApolloClient({ link, cache }) export default clientOto wyjaśnienie tego, co dzieje się powyżej:
-
ApolloClient
Będzie to funkcja, która opakowuje naszą aplikację, a tym samym łączy się z HTTP, buforuje dane i aktualizuje interfejs użytkownika. -
InMemoryCache
Jest to znormalizowany magazyn danych w kliencie Apollo, który pomaga w manipulowaniu pamięcią podręczną w naszej aplikacji. -
HttpLink
Jest to standardowy interfejs sieciowy do modyfikowania przepływu sterowania żądaniami GraphQL i pobierania wyników GraphQL. Działa jako oprogramowanie pośredniczące, pobierając wyniki z serwera GraphQL przy każdym uruchomieniu łącza. Ponadto jest dobrym zamiennikiem innych opcji, takich jakAxiosiwindow.fetch. - Deklarujemy zmienną link, która jest przypisana do instancji
HttpLink. Pobiera właściwośćurii wartość do naszego serwera, czylihttps://localhost:4000/. - Następna jest zmienna pamięci podręcznej, która przechowuje nowe wystąpienie
InMemoryCache. - Zmienna client pobiera również instancję
ApolloClienti otaczalinkorazcache. - Na koniec eksportujemy
client, aby móc z niego korzystać w całej aplikacji.
Zanim zobaczymy to w akcji, musimy się upewnić, że cała nasza aplikacja jest wystawiona na działanie Apollo i że nasza aplikacja może odbierać dane pobrane z serwera i może je mutować.
Aby to osiągnąć, przejdźmy do client/src/index.js :
import React from 'react' import ReactDOM from 'react-dom' import { BrowserRouter } from 'react-router-dom' import { ApolloProvider } from '@apollo/react-hooks' import App from './components/App' import client from './client' import './index.css' const Root = () => ( <BrowserRouter><ApolloProvider client={client}> <App /> </ApolloProvider></BrowserRouter> ); ReactDOM.render(<Root />, document.getElementById('app')) if (module.hot) { module.hot.accept() }
Jak zauważysz w wyróżnionym kodzie, opakowaliśmy komponent App w ApolloProvider i przekazaliśmy klienta jako podpowiedź do client . ApolloProvider jest podobny do Context.Provider . Otacza twoją aplikację React i umieszcza klienta w kontekście, co pozwala na dostęp do niego z dowolnego miejsca w drzewie komponentów.
Aby pobrać nasze zwierzaki z serwera, musimy napisać zapytania, które żądają dokładnie tych pól , które chcemy. Udaj się do client/src/pages/Pets.js i skopiuj i wklej do niego następujący kod:
import React, {useState} from 'react' import gql from 'graphql-tag' import { useQuery, useMutation } from '@apollo/react-hooks' import PetsList from '../components/PetsList' import NewPetModal from '../components/NewPetModal' import Loader from '../components/Loader'const GET_PETS = gql` query getPets { pets { id name type img } } `;export default function Pets () { const [modal, setModal] = useState(false)const { loading, error, data } = useQuery(GET_PETS); if (loading) return <Loader />; if (error) return <p>An error occured!</p>;const onSubmit = input => { setModal(false) } if (modal) { return <NewPetModal onSubmit={onSubmit} onCancel={() => setModal(false)} /> } return ( <div className="page pets-page"> <section> <div className="row betwee-xs middle-xs"> <div className="col-xs-10"> <h1>Pets</h1> </div> <div className="col-xs-2"> <button onClick={() => setModal(true)}>new pet</button> </div> </div> </section> <section><PetsList pets={data.pets}/></section> </div> ) }
Za pomocą kilku bitów kodu jesteśmy w stanie pobrać zwierzaki z serwera.

Co to jest gql?
Należy zauważyć, że operacje w GraphQL są generalnie obiektami JSON pisanymi za pomocą graphql-tag i backtickami.
Tagi gql są tagami literału szablonu JavaScript, które analizują ciągi zapytań GraphQL do GraphQL AST (drzewa abstrakcyjnego składni).
- Operacje zapytań
Aby pobrać nasze zwierzaki z serwera, musimy wykonać operację zapytania.- Ponieważ tworzymy operację
query, przed nazwaniem jej musieliśmy określićtypeoperacji. - Nazwa naszego zapytania to
GET_PETS. Jest to konwencja nazewnictwa GraphQL do używania camelCase dla nazw pól. - Nazwa naszych pól to
pets. W związku z tym podajemy dokładne pola, których potrzebujemy z serwera(id, name, type, img). -
useQueryto hook React, który jest podstawą do wykonywania zapytań w aplikacji Apollo. Aby wykonać operację zapytania w naszym komponencie React, wywołujemy hookuseQuery, który został pierwotnie zaimportowany z@apollo/react-hooks. Następnie przekazujemy mu łańcuch zapytania GraphQL, którym w naszym przypadku jestGET_PETS.
- Ponieważ tworzymy operację
- Kiedy nasz komponent się renderuje,
useQueryzwraca odpowiedź obiektu z klienta Apollo, która zawiera właściwości ładowania, błędu i danych. W związku z tym są one zdestrukturyzowane, dzięki czemu możemy ich użyć do renderowania interfejsu użytkownika. -
useQueryjest niesamowite. Nie musimy uwzględniaćasync-await. Zadbano już o to w tle. Całkiem fajnie, prawda?-
loading
Ta właściwość pomaga nam obsłużyć stan ładowania aplikacji. W naszym przypadku zwracamy składnikLoaderpodczas ładowania aplikacji. Domyślnie wczytywanie tofalse. -
error
Na wszelki wypadek używamy tej właściwości do obsługi wszelkich błędów, które mogą wystąpić. -
data
Zawiera nasze aktualne dane z serwera. - Na koniec, w naszym komponencie
PetsList, przekazujemy rekwizytypets, zdata.petsjako wartością obiektu.
-
W tym momencie pomyślnie przeszukaliśmy nasz serwer.
Aby uruchomić naszą aplikację, uruchommy następujące polecenie:
- Uruchom aplikację kliencką. Uruchom polecenie
npm run appw swoim CLI. - Uruchom serwer. Uruchom polecenie
npm run serverw innym CLI.
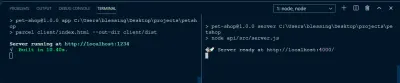
Jeśli wszystko poszło dobrze, powinieneś zobaczyć to:
Mutowanie danych
Mutowanie danych lub tworzenie danych w kliencie Apollo to prawie to samo, co zapytanie o dane, z bardzo niewielkimi zmianami.
Nadal w client/src/pages/Pets.js podświetlony kod:
.... const GET_PETS = gql` query getPets { pets { id name type img } } `;const NEW_PETS = gql` mutation CreateAPet($newPet: NewPetInput!) { addPet(input: $newPet) { id name type img } } `;const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS);const [createPet, newPet] = useMutation(NEW_PETS);const onSubmit = input => { setModal(false)createPet({ variables: { newPet: input } }); } if (loading || newPet.loading) return <Loader />; if (error || newPet.error) return <p>An error occured</p>;if (modal) { return <NewPetModal onSubmit={onSubmit} onCancel={() => setModal(false)} /> } return ( <div className="page pets-page"> <section> <div className="row betwee-xs middle-xs"> <div className="col-xs-10"> <h1>Pets</h1> </div> <div className="col-xs-2"> <button onClick={() => setModal(true)}>new pet</button> </div> </div> </section> <section> <PetsList pets={data.pets}/> </section> </div> ) } export default Pets
Aby stworzyć mutację, zrobilibyśmy następujące kroki.
1. mutation
Aby utworzyć, zaktualizować lub usunąć, musimy wykonać operację mutation . Operacja mutation ma nazwę CreateAPet z jednym argumentem. Ten argument ma zmienną $newPet typu NewPetInput . ! oznacza, że operacja jest wymagana; w ten sposób GraphQL nie wykona operacji, chyba że przekażemy zmienną newPet , której typem jest NewPetInput .
2. addPet
Funkcja addPet , która znajduje się wewnątrz operacji mutation , pobiera argument input i jest ustawiona na naszą zmienną $newPet . Zestawy pól określone w naszej funkcji addPet muszą być równe zestawom pól w naszym zapytaniu. Zestawy terenowe w naszej działalności to:
-
id -
name -
type -
img
3. useMutation
Hak useMutation React jest głównym interfejsem API do wykonywania mutacji w aplikacji Apollo. Kiedy potrzebujemy zmutować dane, wywołujemy useMutation w komponencie React i przekazujemy mu łańcuch GraphQL (w naszym przypadku NEW_PETS ).
Kiedy nasz komponent renderuje useMutation , zwraca krotkę (czyli uporządkowany zestaw danych tworzących rekord) w tablicy, która zawiera:
- funkcję
mutate, którą możemy wywołać w dowolnym momencie, aby wykonać mutację; - obiekt z polami reprezentującymi aktualny stan wykonania mutacji.
Hak useMutation jest przekazywany ciągiem mutacji GraphQL (w naszym przypadku jest to NEW_PETS ). Zdestrukturyzowaliśmy krotkę, czyli funkcję ( createPet ), która zmutuje dane i pole obiektu ( newPets ).
4. createPet
W naszej funkcji onSubmit , krótko po stanie setModal , zdefiniowaliśmy naszego createPet . Ta funkcja pobiera variable z właściwością obiektu o wartości { newPet: input } . Dane input reprezentują różne pola wejściowe w naszym formularzu (takie jak nazwa, typ itp.).
Po wykonaniu tych czynności wynik powinien wyglądać tak:
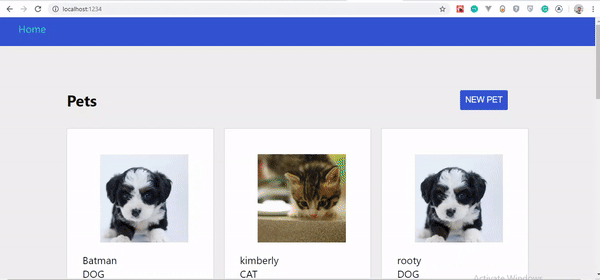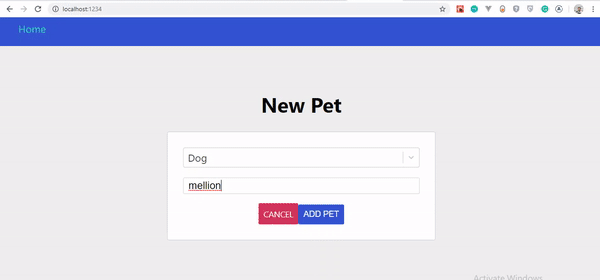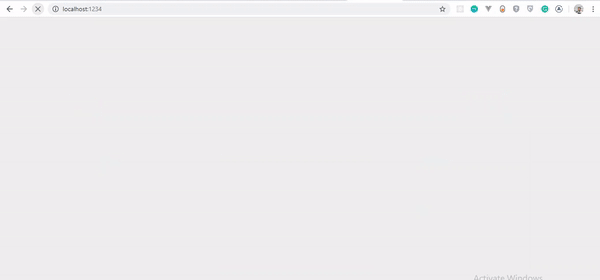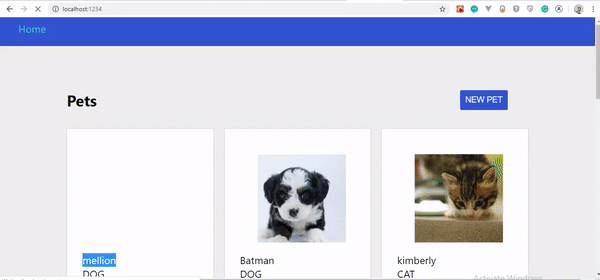
Jeśli przyjrzysz się uważnie GIF-owi, zauważysz, że stworzony przez nas zwierzak nie pojawia się od razu, tylko po odświeżeniu strony. Został jednak zaktualizowany na serwerze.
Najważniejsze pytanie brzmi, dlaczego nasz zwierzak nie aktualizuje się natychmiast? Dowiedzmy się w następnej sekcji.
Buforowanie w kliencie Apollo
Powodem, dla którego nasza aplikacja nie aktualizuje się automatycznie, jest to, że nasze nowo utworzone dane nie pasują do danych z pamięci podręcznej w kliencie Apollo. Tak więc istnieje konflikt dotyczący tego, co dokładnie należy zaktualizować z pamięci podręcznej.
Mówiąc najprościej, jeśli wykonamy mutację, która aktualizuje lub usuwa wiele wpisów (węzeł), to jesteśmy odpowiedzialni za aktualizację wszelkich zapytań odwołujących się do tego węzła, tak aby modyfikuje nasze dane w pamięci podręcznej , aby pasowały do modyfikacji, które mutacja wprowadza na naszych plecach- dane końcowe .
Synchronizacja pamięci podręcznej
Istnieje kilka sposobów na synchronizację naszej pamięci podręcznej za każdym razem, gdy wykonujemy operację mutacji.
Pierwszy polega na ponownym pobieraniu pasujących zapytań po mutacji przy użyciu właściwości obiektu refetchQueries (najprostszy sposób).
Uwaga: Gdybyśmy mieli użyć tej metody, w naszej funkcji createPet zajęłaby ona właściwość obiektu o nazwie refetchQueries , która zawierałaby tablicę obiektów z wartością zapytania: refetchQueries: [{ query: GET_PETS }] .
Ponieważ w tej sekcji nie skupiamy się tylko na aktualizowaniu stworzonych przez nas zwierzaków w interfejsie użytkownika, ale także na manipulowaniu pamięcią podręczną, nie będziemy używać tej metody.
Drugim podejściem jest użycie funkcji update . W kliencie Apollo znajduje się funkcja pomocnicza update , która pomaga modyfikować dane w pamięci podręcznej, tak aby synchronizowały się z modyfikacjami, które mutacja wprowadza w naszych danych zaplecza. Za pomocą tej funkcji możemy odczytywać i zapisywać do pamięci podręcznej.
Aktualizacja pamięci podręcznej
Skopiuj następujący podświetlony kod i wklej go w client/src/pages/Pets.js :
...... const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS);const [createPet, newPet] = useMutation(NEW_PETS, { update(cache, { data: { addPet } }) { const data = cache.readQuery({ query: GET_PETS }); cache.writeQuery({ query: GET_PETS, data: { pets: [addPet, ...data.pets] }, }); }, } );.....
Funkcja update otrzymuje dwa argumenty:
- Pierwszym argumentem jest pamięć podręczna klienta Apollo.
- Drugi to dokładna odpowiedź mutacji z serwera. Destrukturyzujemy właściwość
datai ustawiamy ją na naszą mutację (addPet).
Następnie, aby zaktualizować funkcję, musimy sprawdzić, jakie zapytanie należy zaktualizować (w naszym przypadku zapytanie GET_PETS ) i odczytać pamięć podręczną.
Po drugie, musimy napisać do query , które zostało odczytane, aby wiedziało, że zamierzamy je zaktualizować. Robimy to, przekazując obiekt, który zawiera właściwość obiektu query , z wartością ustawioną na naszą operację query ( GET_PETS ) oraz właściwość data , której wartość jest obiektem pet i ma tablicę mutacji addPet oraz kopię dane zwierzęcia.
Jeśli dokładnie wykonałeś te kroki, powinieneś zobaczyć, jak twoje zwierzaki aktualizują się automatycznie podczas ich tworzenia. Przyjrzyjmy się zmianom:
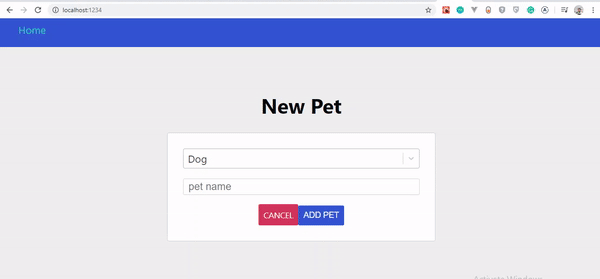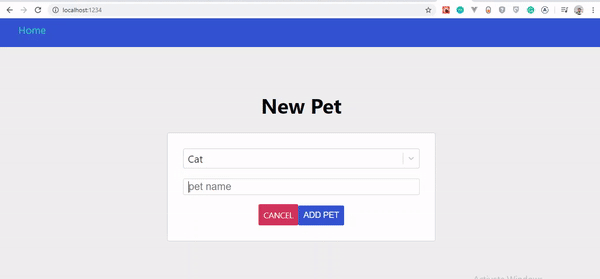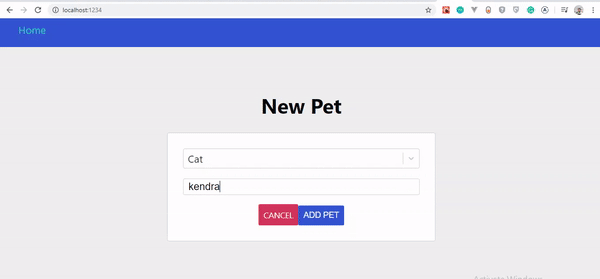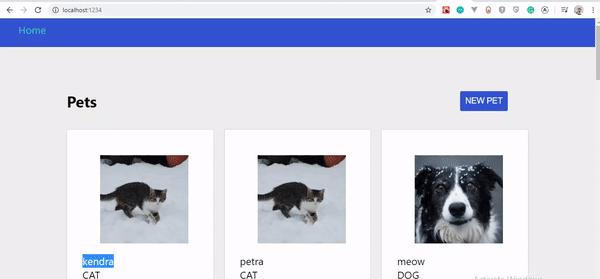
Optymistyczny interfejs użytkownika
Wiele osób jest wielkimi fanami ładowarek i błystek. Nie ma nic złego w używaniu programu ładującego; istnieją idealne przypadki użycia, w których ładowarka jest najlepszą opcją. Pisałem o ładowarkach kontra błystki i ich najlepszych przypadkach.
Ładowarki i spinnery rzeczywiście odgrywają ważną rolę w projektowaniu interfejsu użytkownika i UX, ale pojawienie się Optymistycznego interfejsu użytkownika skradło reflektory.
Co to jest optymistyczny interfejs użytkownika?
Optymistyczny interfejs użytkownika to konwencja, która symuluje wyniki mutacji (utworzonych danych) i aktualizuje interfejs użytkownika przed otrzymaniem odpowiedzi z serwera. Po otrzymaniu odpowiedzi z serwera optymistyczny wynik jest odrzucany i zastępowany rzeczywistym wynikiem.
Ostatecznie optymistyczny interfejs użytkownika to nic innego jak sposób zarządzania postrzeganą wydajnością i unikania stanów ładowania.
Apollo Client ma bardzo ciekawy sposób integracji Optymistycznego UI. Daje nam prosty hook, który pozwala nam pisać do lokalnej pamięci podręcznej po mutacji. Zobaczmy, jak to działa!
Krok 1
Przejdź do client/src/client.js i dodaj tylko podświetlony kod.
import { ApolloClient } from 'apollo-client' import { InMemoryCache } from 'apollo-cache-inmemory' import { HttpLink } from 'apollo-link-http'import { setContext } from 'apollo-link-context' import { ApolloLink } from 'apollo-link' const http = new HttpLink({ uri: "https://localhost:4000/" }); const delay = setContext( request => new Promise((success, fail) => { setTimeout(() => { success() }, 800) }) ) const link = ApolloLink.from([ delay, http ])const cache = new InMemoryCache() const client = new ApolloClient({ link, cache }) export default client
Pierwszy krok obejmuje:
- Importujemy
setContextzapollo-link-context. FunkcjasetContextprzyjmuje funkcję zwrotną i zwraca obietnicę, którejsetTimeoutjest ustawiony na800ms, aby utworzyć opóźnienie podczas wykonywania operacji mutacji. - Metoda
ApolloLink.fromzapewnia, że aktywność sieciowa reprezentująca łącze (nasze API) zHTTPjest opóźniona.
Krok 2
Następnym krokiem jest użycie zaczepu Optimistic UI. Wróć do client/src/pages/Pets.js i dodaj tylko podświetlony poniżej kod.
..... const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS); const [createPet, newPet] = useMutation(NEW_PETS, { update(cache, { data: { addPet } }) { const data = cache.readQuery({ query: GET_PETS }); cache.writeQuery({ query: GET_PETS, data: { pets: [addPet, ...data.pets] }, }); }, } ); const onSubmit = input => { setModal(false) createPet({ variables: { newPet: input },optimisticResponse: { __typename: 'Mutation', addPet: { __typename: 'Pet', id: Math.floor(Math.random() * 10000 + ''), name: input.name, type: input.type, img: 'https://via.placeholder.com/200' } }}); } .....
Obiekt optimisticResponse jest używany, jeśli chcemy, aby interfejs użytkownika aktualizował się natychmiast po utworzeniu zwierzaka, zamiast czekać na odpowiedź serwera.
Powyższe fragmenty kodu zawierają następujące elementy:
-
__typenamejest wstrzykiwany przez Apollo do zapytania w celu pobraniatypeodpytywanych jednostek. Te typy są używane przez klienta Apollo do budowania właściwościid(która jest symbolem) do celów buforowania wapollo-cache. Tak więc__typenamejest prawidłową właściwością odpowiedzi na zapytanie. - Mutacja jest ustawiona jako
__typenameoptimisticResponse. - Tak jak wcześniej zdefiniowano, nazwa naszej mutacji to
addPet, a__typenametoPet. - Dalej są pola naszej mutacji, które chcemy zaktualizować w optymistycznej odpowiedzi:
-
id
Ponieważ nie wiemy, jaki będzie identyfikator z serwera, wymyśliliśmy go za pomocąMath.floor. -
name
Ta wartość jest ustawiona nainput.name. -
type
Wartość typu toinput.type. -
img
Teraz, ponieważ nasz serwer generuje dla nas obrazy, użyliśmy symbolu zastępczego, aby naśladować nasz obraz z serwera.
-
To była rzeczywiście długa jazda. Jeśli dotarłeś do końca, nie wahaj się oderwać od krzesła przy filiżance kawy.
Przyjrzyjmy się naszemu wynikowi. Repozytorium wspierające dla tego projektu znajduje się na GitHub. Klonuj i eksperymentuj z nim.
Wniosek
Niesamowite funkcje klienta Apollo, takie jak Optymistyczny interfejs użytkownika i podział na strony, sprawiają, że tworzenie aplikacji po stronie klienta staje się rzeczywistością.
Podczas gdy Apollo Client działa bardzo dobrze z innymi frameworkami, takimi jak Vue.js i Angular, programiści React mają Apollo Client Hooks, więc nie mogą nie cieszyć się tworzeniem świetnej aplikacji.
W tym artykule tylko zarysowaliśmy powierzchnię. Opanowanie klienta Apollo wymaga stałej praktyki. Więc śmiało sklonuj repozytorium, dodaj paginację i baw się innymi funkcjami, które oferuje.
Podziel się swoją opinią i doświadczeniem w sekcji komentarzy poniżej. Możemy również omówić Twoje postępy na Twitterze. Dzięki!
Bibliografia
- „GraphQL po stronie klienta w reakcji”, Scott Moss, Frontend Master
- „Dokumentacja”, Klient Apollo
- „Optymistyczny interfejs użytkownika z reakcją”, Patryk Andrzejewski
- „Prawdziwe kłamstwa optymistycznych interfejsów użytkownika”, Smashing Magazine