
Wybór nowej technologii bezserwerowej bazy danych w agencji (studium przypadku)
Opublikowany: 2022-03-10Ten artykuł został życzliwie poparty przez naszych drogich przyjaciół z Fauna, którzy sprawiają, że praca z danymi operacyjnymi jest wydajna, skalowalna i bezpieczna dla każdego zespołu programistów. Dziękuję Ci!

Przyjęcie nowej technologii to jedna z najtrudniejszych decyzji dla technologa na stanowisku kierowniczym. Często jest to duży i niewygodny obszar ryzyka, niezależnie od tego, czy tworzysz oprogramowanie dla innej organizacji, czy we własnej.
Przez ostatnie dwanaście lat jako inżynier oprogramowania znalazłem się w sytuacji, w której muszę oceniać nową technologię z coraz większą częstotliwością. Może to być kolejny framework frontendowy, nowy język, a nawet zupełnie nowe architektury, takie jak bezserwerowe.
Faza eksperymentowania jest często zabawna i ekscytująca. To tam inżynierowie oprogramowania czują się najbardziej w domu, korzystając z nowości i euforii momentów „aha”, jednocześnie grokując nowe koncepcje. Jako inżynierowie lubimy myśleć i majstrować, ale mając wystarczające doświadczenie, każdy inżynier dowiaduje się, że nawet najbardziej niesamowita technologia ma swoje wady. Po prostu jeszcze ich nie znalazłeś.
Teraz, jako współzałożyciel agencji kreatywnej, mój zespół i ja często mamy wyjątkową możliwość wykorzystania nowych technologii. Widzimy wiele projektów greenfield, które stają się doskonałą okazją do wprowadzenia czegoś nowego. Projekty te charakteryzują się również pewnym poziomem izolacji technicznej od większej organizacji i często są mniej obciążone wcześniejszymi decyzjami.
Biorąc to pod uwagę, dobremu leadowi powierza się opiekę nad cudzym pomysłem i dostarczenie go światu. Musimy podchodzić do tego z jeszcze większą uwagą niż do własnych projektów. Ilekroć mam zamiar dokonać ostatecznego połączenia z nową technologią, często zastanawiam się nad mądrością współzałożyciela Stack Overflow Joela Spolskiego:
„Musisz się pocić i krwawić przez rok lub dwa, zanim naprawdę będziesz wiedział, że jest wystarczająco dobry lub zdasz sobie sprawę, że bez względu na to, jak bardzo się starasz, nie możesz…”
To jest strach, to jest miejsce, w którym żaden lider technologiczny nie chce się znaleźć. Wybór nowej technologii do projektu w świecie rzeczywistym jest wystarczająco trudny, ale jako agencja musisz podejmować te decyzje z czyimś projektem, kimś czyjeś marzenie, cudze pieniądze. W agencji ostatnią rzeczą, jakiej chcesz, jest znalezienie jednej z tych skaz w pobliżu terminu realizacji projektu. Napięte ramy czasowe i budżety sprawiają, że zmiana kursu po przekroczeniu pewnego progu jest prawie niemożliwa , więc stwierdzenie, że technologia nie może zrobić czegoś krytycznego lub jest zawodna zbyt późno w projekcie, może być katastrofalne.
Przez całą swoją karierę jako inżynier oprogramowania pracowałem w firmach SaaS i agencjach kreatywnych. Jeśli chodzi o adaptację nowej technologii do projektu, te dwa środowiska mają bardzo różne kryteria. Kryteria nakładają się na siebie, ale ogólnie rzecz biorąc, środowisko agencji musi pracować ze sztywnymi budżetami i rygorystycznymi ograniczeniami czasowymi . Chociaż chcemy, aby tworzone przez nas produkty dobrze się starzały, często trudniej jest zainwestować w coś mniej sprawdzonego lub zastosować technologię o bardziej stromych krzywych uczenia się i ostrych krawędziach.
Biorąc to pod uwagę, agencje mają również pewne unikalne ograniczenia, których może nie mieć pojedyncza organizacja. Musimy nastawić na wydajność i stabilność. Rozliczana godzina jest często ostateczną jednostką miary po zakończeniu projektu. Byłem w firmach SaaS, gdzie spędzenie dnia lub dwóch na konfiguracji lub kompilacji nie jest niczym wielkim.
W agencji tego rodzaju koszt czasu obciąża relacje, ponieważ zespoły finansowe widzą zawężanie marż przy mało widocznych rezultatach. Musimy również wziąć pod uwagę długoterminowe utrzymanie projektu i odwrotnie, co się stanie, jeśli projekt musi zostać zwrócony klientowi. Dlatego musimy skłaniać się ku wydajności, krzywej uczenia się i stabilności w wybranej przez nas technologii.
Oceniając nowy element technologii, patrzę na trzy nadrzędne obszary:
- Technologia
- Doświadczenie programisty
- Biznes
Każdy z tych obszarów ma zestaw kryteriów, które lubię spełnić, zanim zacznę naprawdę zagłębiać się w kod i eksperymentować. W tym artykule przyjrzymy się tym kryteriom i użyjemy przykładu rozważania nowej bazy danych dla projektu i przeglądu jej na wysokim poziomie pod każdym obiektywem. Podjęcie takiej namacalnej decyzji pomoże zademonstrować, jak możemy zastosować te ramy w prawdziwym świecie.
Technologia
Pierwszą rzeczą, na którą należy zwrócić uwagę podczas oceny nowej technologii, jest to, czy rozwiązanie to może rozwiązać problemy, które twierdzi, że ma rozwiązać. Zanim zagłębimy się w to, w jaki sposób technologia może wspomóc nasze procesy i operacje biznesowe, ważne jest, aby najpierw ustalić, czy spełnia ona nasze wymagania funkcjonalne . W tym miejscu lubię też przyjrzeć się, z jakich istniejących rozwiązań korzystamy i jak wypada na nie ten nowy.
Zadam sobie pytania typu:
- Czy to przynajmniej rozwiązuje problem, który rozwiązuje moje obecne rozwiązanie?
- W jaki sposób to rozwiązanie jest lepsze?
- W jaki sposób jest gorzej?
- W przypadku obszarów, w których jest gorzej, co trzeba zrobić, aby przezwyciężyć te niedociągnięcia?
- Czy zastąpi wiele narzędzi?
- Jak stabilna jest technologia?
Nasze Dlaczego?
W tym miejscu chciałbym również omówić, dlaczego szukamy innego rozwiązania. Prostą odpowiedzią jest to, że napotykamy problem, którego nie rozwiązują istniejące rozwiązania . Jednak często zdarza się to rzadko. Na przestrzeni lat rozwiązaliśmy wiele problemów związanych z oprogramowaniem za pomocą całej technologii, którą mamy dzisiaj. Zwykle dzieje się tak, że zostajemy zwróceni na nową technologię, która sprawia, że coś, co obecnie robimy, staje się łatwiejsze, stabilniejsze, szybsze lub tańsze.
Weźmy jako przykład React. Dlaczego zdecydowaliśmy się na Reacta, kiedy wykonywało to zadanie jQuery lub Vanilla JavaScript? W tym przypadku użycie frameworka pokazało, że jest to znacznie lepszy sposób obsługi interfejsów stanowych. Dzięki pracy ze strukturami danych, zamiast bezpośredniej manipulacji DOM, przyspieszyliśmy tworzenie takich rzeczy, jak funkcje filtrowania i sortowania . Była to oszczędność czasu i zwiększona stabilność naszych rozwiązań.
Typescript to kolejny przykład, w którym zdecydowaliśmy się go zastosować, ponieważ stwierdziliśmy wzrost stabilności naszego kodu i łatwości konserwacji. Przyjmując nowe technologie, często nie ma jasnego problemu, który chcemy rozwiązać, ale raczej staramy się być na bieżąco, a następnie odkrywać bardziej wydajne i stabilne rozwiązania, niż obecnie używamy.
W przypadku bazy danych szczególnie rozważaliśmy przejście na opcję bezserwerową . Odnieśliśmy wiele sukcesów związanych z aplikacjami i wdrożeniami bezserwerowymi, które zmniejszały nasze ogólne koszty jako organizacji. Jednym z obszarów, w których naszym zdaniem tego brakowało, była nasza warstwa danych. Widzieliśmy usługi takie jak Amazon Aurora, Fauna, Cosmos i Firebase, które stosowały zasady bezserwerowe do baz danych i chcieliśmy sprawdzić, czy nadszedł czas, aby sami wykonać ten skok. W tym przypadku chcieliśmy obniżyć koszty operacyjne i zwiększyć szybkość i wydajność rozwoju.
Na tym poziomie ważne jest, aby zrozumieć, dlaczego , zanim zaczniesz zagłębiać się w nowe oferty. Może to być spowodowane tym, że rozwiązujesz nowy problem, ale znacznie częściej chcesz poprawić swoją zdolność do rozwiązania problemu, który już rozwiązujesz. W takim przypadku musisz sporządzić spis miejsc, w których byłeś, aby dowiedzieć się, co zapewniłoby znaczącą poprawę przepływu pracy. Opierając się na naszym przykładzie patrzenia na bezserwerowe bazy danych, musimy przyjrzeć się, jak obecnie rozwiązujemy problemy i gdzie te rozwiązania są niewystarczające.
Gdzie byliśmy…
Jako agencja korzystaliśmy wcześniej z szerokiej gamy baz danych, w tym między innymi MySQL, PostgreSQL, MongoDB, DynamoDB, BigQuery i Firebase Cloud Storage. Zdecydowana większość naszej pracy koncentrowała się jednak na trzech podstawowych bazach danych: PostgreSQL, MongoDB i Firebase Realtime Database. Każda z nich ma w rzeczywistości oferty bezserwerowe, ale niektóre kluczowe cechy nowszych ofert skłoniły nas do ponownej oceny naszych poprzednich założeń. Przyjrzyjmy się naszym historycznym doświadczeniom z każdym z nich na początku i dlaczego w pierwszej kolejności rozważamy alternatywy.
Zazwyczaj wybieramy PostgreSQL do większych, długoterminowych projektów, ponieważ jest to sprawdzony w boju złoty standard dla prawie wszystkiego. Obsługuje klasyczne transakcje, znormalizowane dane i jest zgodny z ACID. Istnieje wiele narzędzi i ORM dostępnych w prawie każdym języku i może być nawet używana jako baza danych ad-hoc NoSQL z obsługą kolumn JSON. Dobrze integruje się z wieloma istniejącymi frameworkami, bibliotekami i językami programowania, dzięki czemu jest prawdziwym narzędziem do pracy w dowolnym miejscu. Jest to również oprogramowanie typu open source i dlatego nie ogranicza nas do jednego dostawcy. Jak mówią, nikt nigdy nie został zwolniony za wybranie Postgresa.
Biorąc to pod uwagę, stopniowo coraz rzadziej używaliśmy PostgreSQL, ponieważ staliśmy się sklepem zorientowanym na Node. Odkryliśmy, że ORM dla Node są słabe i wymagają więcej niestandardowych zapytań (choć teraz stało się to mniej problematyczne), a NoSQL wydaje się być bardziej naturalnym dopasowaniem podczas pracy w środowisku wykonawczym JavaScript lub TypeScript. Biorąc to pod uwagę, często mieliśmy projekty, które można było wykonać dość szybko za pomocą klasycznego modelowania relacyjnego, takiego jak przepływy pracy w e-commerce. Jednak radzenie sobie z lokalną konfiguracją bazy danych, ujednolicenie przepływu testów w zespołach i radzenie sobie z lokalnymi migracjami to rzeczy, których nie lubiliśmy i z przyjemnością porzuciliśmy, ponieważ bazy danych oparte na chmurze NoSQL stały się bardziej popularne.
MongoDB był coraz częściej naszą bazą danych, ponieważ przyjęliśmy Node.js jako preferowany backend. Współpraca z MongoDB Atlas ułatwiła szybkie tworzenie i testowanie baz danych, z których nasz zespół może korzystać. Przez pewien czas MongoDB nie był zgodny z ACID, nie obsługiwał transakcji i zniechęcał do zbyt wielu operacji typu sprzężenie wewnętrzne, dlatego w przypadku aplikacji e-commerce nadal najczęściej korzystaliśmy z Postgresa. Biorąc to pod uwagę, istnieje wiele bibliotek, które są z nim powiązane, a język zapytań Mongo i pierwszorzędna obsługa JSON zapewniły nam szybkość i wydajność, których nie doświadczyliśmy w przypadku relacyjnych baz danych. MongoDB dodał niedawno obsługę transakcji ACID, ale przez długi czas był to główny powód, dla którego zdecydowaliśmy się zamiast tego na Postgres.
MongoDB wprowadził nas również na nowy poziom elastyczności. W środku projektu agencyjnego wymagania muszą się zmienić. Bez względu na to, jak mocno się przed nim bronisz, zawsze istnieje wymóg dotyczący danych z ostatniej chwili . Ogólnie rzecz biorąc, w przypadku baz danych NoSQL elastyczność struktury danych sprawiała, że tego typu zmiany były mniej dotkliwe. Nie skończyliśmy z folderem pełnym plików migracji, aby zarządzać tymi dodanymi, usuniętymi i ponownie dodanymi kolumnami, zanim projekt ujrzał światło dzienne.
Jako usługa, Mongo Atlas był również bardzo zbliżony do tego, czego oczekiwaliśmy od usługi w chmurze bazy danych. Lubię myśleć o Atlasie jako o ofercie częściowo bezserwerowej, ponieważ zarządzanie nią nadal wiąże się z pewnymi kosztami operacyjnymi. Musisz aprowizować bazę danych o określonym rozmiarze i wybrać ilość pamięci z góry. Te rzeczy nie skalują się automatycznie, więc będziesz musiał je monitorować, gdy nadejdzie czas, aby zapewnić więcej miejsca lub pamięci. W prawdziwie bezserwerowej bazie danych wszystko to odbywałoby się automatycznie i na żądanie.
W kilku projektach korzystaliśmy również z Bazy danych czasu rzeczywistego Firebase. W rzeczywistości była to oferta bezserwerowa, w której baza danych skaluje się w górę iw dół na żądanie, a dzięki opłatom zgodnie z rzeczywistym użyciem ma to sens w przypadku aplikacji, w których skala nie była znana z góry, a budżet był ograniczony. Użyliśmy tego zamiast MongoDB w przypadku krótkotrwałych projektów, które miały proste wymagania dotyczące danych.
Jedną z rzeczy, które nie podobały nam się w Firebase, było to, że odeszliśmy od typowego modelu relacyjnego opartego na znormalizowanych danych, do których byliśmy przyzwyczajeni. Utrzymywanie płaskich struktur danych oznaczało, że często mieliśmy więcej duplikacji, co mogło stać się nieco brzydsze w miarę rozwoju projektu. Koniecznie musisz zaktualizować te same dane w wielu miejscach lub spróbować połączyć różne referencje, co skutkuje wieloma zapytaniami, które mogą być trudne do uzasadnienia w kodzie. Chociaż lubiliśmy Firebase, nigdy tak naprawdę nie zakochaliśmy się w języku zapytań i czasami dokumentacja była słaba.
Ogólnie zarówno MongoDB, jak i Firebase w podobny sposób koncentrowały się na zdenormalizowanych danych , a bez dostępu do wydajnych transakcji często znajdowaliśmy wiele przepływów pracy, które można było łatwo zamodelować w relacyjnych bazach danych, co prowadziło do bardziej złożonego kodu w warstwie aplikacji z ich odpowiedniki NoSQL. Gdybyśmy mogli uzyskać elastyczność i łatwość tych ofert NoSQL z solidnością i modelowaniem relacyjnym tradycyjnej bazy danych SQL, naprawdę znaleźlibyśmy świetne dopasowanie. Czuliśmy, że MongoDB ma lepszy interfejs API i możliwości, ale Firebase ma operacyjnie model bezserwerowy.
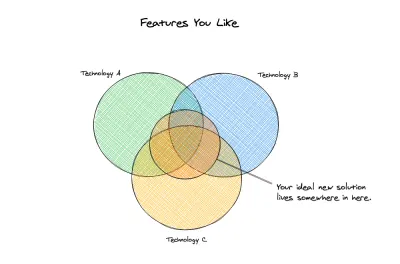
Nasz ideał
W tym momencie możemy zacząć zastanawiać się, jakie nowe opcje rozważymy. Jasno zdefiniowaliśmy nasze poprzednie rozwiązania i zidentyfikowaliśmy rzeczy, które są dla nas ważne, abyśmy mieli co najmniej w naszym nowym rozwiązaniu. Mamy nie tylko podstawowy lub minimalny zestaw wymagań, ale także zestaw problemów, które chcielibyśmy, aby nowe rozwiązanie załagodziło dla nas. Oto wymagania techniczne, które mamy:
- Bezserwerowe operacyjne ze skalą na żądanie
- Elastyczne modelowanie (bez schematu)
- Brak zależności od migracji lub ORM
- Transakcje zgodne z ACID
- Obsługuje relacje i znormalizowane dane
- Działa zarówno z backendami bezserwerowymi, jak i tradycyjnymi
Więc teraz, gdy mamy listę niezbędnych rzeczy, możemy właściwie ocenić niektóre opcje. To może nie być ważne, aby nowe rozwiązanie przyszło tutaj do każdego celu. Może po prostu trafić w odpowiednią kombinację funkcji, w której istniejące rozwiązania nie nakładają się. Na przykład, jeśli potrzebujesz elastyczności bez schematu , musisz zrezygnować z transakcji ACID. (Tak było przez długi czas z bazami danych.)
Przykładem z innej domeny jest to, że jeśli chcesz mieć walidację maszynopisu w renderowaniu szablonu, musisz używać TSX i React. Jeśli wybierzesz opcje takie jak Svelte lub Vue, możesz mieć to — częściowo, ale nie całkowicie — poprzez renderowanie szablonu . Tak więc rozwiązanie, które zapewniło ci niewielki rozmiar i szybkość Svelte ze sprawdzaniem typu szablonu React i TypeScript, może wystarczyć do przyjęcia, nawet jeśli brakowało innej funkcji. Równowaga pragnień i potrzeb będzie się zmieniać z projektu na projekt. Od Ciebie zależy, gdzie będzie ta wartość, i zdecydujesz, jak zaznaczyć najważniejsze punkty w swojej analizie.
Możemy teraz przyjrzeć się rozwiązaniu i zobaczyć, jak wypada ono w porównaniu z naszym pożądanym rozwiązaniem. Fauna to bezserwerowe rozwiązanie bazodanowe, które oferuje skalę na żądanie z globalną dystrybucją. Jest to nieschematyczna baza danych, która zapewnia transakcje zgodne z ACID i obsługuje zapytania relacyjne oraz znormalizowane dane jako funkcję. Fauna może być używana zarówno w aplikacjach bezserwerowych, jak i bardziej tradycyjnych backendach i udostępnia biblioteki do pracy z najpopularniejszymi językami. Fauna dodatkowo zapewnia przepływy pracy dla uwierzytelniania, a także łatwą i wydajną obsługę wielu najemców. Obie te cechy są solidnymi dodatkowymi cechami, na które należy zwrócić uwagę, ponieważ mogą one być czynnikami wpływającymi, gdy w naszej ocenie dwie technologie są nos w nos.
Teraz, po przyjrzeniu się wszystkim tym mocnym stronom, musimy ocenić słabości . Jednym z nich jest Fauna, która nie jest open source. Oznacza to, że istnieje ryzyko zablokowania dostawcy lub zmian biznesowych i cenowych, na które nie masz wpływu. Open source może być fajny, ponieważ często możesz przenieść technologię do innego dostawcy, jeśli zechcesz lub potencjalnie wniesiesz swój wkład z powrotem do projektu.
W świecie agencji musimy bacznie przyglądać się uzależnieniu od dostawcy , nie tyle ze względu na cenę, ale na opłacalność podstawowej działalności. Konieczność zmiany baz danych w projekcie, który jest w trakcie rozwoju lub ma kilka lat, są katastrofalne dla agencji. Często klient będzie musiał za to zapłacić rachunek, co nie jest przyjemną rozmową.
Inną słabością, którą się martwiliśmy, jest skupienie się na JAMstack . Chociaż uwielbiamy JAMstack, częściej tworzymy szeroką gamę tradycyjnych aplikacji internetowych. Chcemy mieć pewność, że Fauna nadal wspiera te przypadki użycia. W przeszłości mieliśmy złe doświadczenia z dostawcą usług hostingowych, który wszedł all-in na JAMstack i ostatecznie musieliśmy przeprowadzić migrację dość dużej części witryn z usługi, więc chcemy mieć pewność, że wszystkie przypadki użycia będą nadal widoczne solidne wsparcie. W tej chwili wydaje się, że tak jest, a przepływy pracy bezserwerowe dostarczane przez Fauna faktycznie mogą całkiem ładnie uzupełnić bardziej tradycyjną aplikację.

W tym momencie przeprowadziliśmy badania funkcjonalne i jedynym sposobem, aby dowiedzieć się, czy to rozwiązanie jest opłacalne, jest zejście i napisanie kodu. W środowisku agencji nie możemy po prostu wydłużyć harmonogramu o kilka tygodni, aby ludzie mogli ocenić wiele rozwiązań. Taka jest natura pracy w agencji vs w środowisku SaaS . W tym drugim przypadku możesz zbudować kilka prototypów, aby spróbować znaleźć właściwe rozwiązanie. W agencji dostaniesz kilka dni na eksperymenty, a może możliwość zrobienia pobocznego projektu, ale w zasadzie na tym etapie naprawdę musimy zawęzić to do jednej lub dwóch technologii, a następnie przyłożyć palce do klawiatury.
Doświadczenie programisty
Ocena doświadczenia nowej technologii jest prawdopodobnie najtrudniejszym z trzech obszarów, ponieważ jest z natury subiektywna. Będzie również zmienny w zależności od zespołu. Na przykład, jeśli zapytasz programistę Rubiego, programistę Pythona i programistę Rusta o ich opinie na temat różnych funkcji językowych, otrzymasz całkiem sporo odpowiedzi. Tak więc, zanim zaczniesz oceniać doświadczenie, musisz najpierw zdecydować, jakie cechy są najważniejsze dla Twojego zespołu.

Myślę, że w przypadku agencji istnieją dwa główne wąskie gardła , które pojawiają się w odniesieniu do doświadczenia programistów:
- Czas instalacji i konfiguracja
- Umiejętność uczenia się
Oba te czynniki w różny sposób wpływają na długoterminową żywotność nowej technologii. Synchronizowanie przejściowych zespołów programistów w agencji może być bólem głowy. Narzędzia, które mają wiele początkowych kosztów instalacji i konfiguracji, są notorycznie trudne do pracy dla agencji. Drugi to umiejętność uczenia się i łatwość rozwijania nowej technologii przez programistów. Omówimy je bardziej szczegółowo i dlaczego są one moją podstawą, kiedy zaczynam oceniać doświadczenie programistów.
Konfiguracja czasu i konfiguracji
Agencje mają zwykle mało cierpliwości i czasu na konfigurację. Dla mnie uwielbiam ostre narzędzia, o ergonomicznej konstrukcji, które pozwalają mi szybko zająć się problemem biznesowym. Kilka lat temu pracowałem dla firmy SaaS, która miała złożoną konfigurację lokalną, która obejmowała wiele konfiguracji i często kończyła się niepowodzeniem w losowych punktach procesu konfiguracji. Po skonfigurowaniu konwencjonalna mądrość polegała na tym, aby niczego nie dotykać i mieć nadzieję, że nie byłeś w firmie wystarczająco długo, aby trzeba było ją ponownie skonfigurować na innej maszynie. Spotkałem programistów, którzy bardzo lubili konfigurować każdy najmniejszy element ich konfiguracji emacs i nie myśleli o utracie kilku godzin na zepsutym środowisku lokalnym.
Ogólnie rzecz biorąc, zauważyłem , że inżynierowie agencji mają pogardę dla tego typu rzeczy w swojej codziennej pracy. W domu mogą majstrować przy tego typu narzędziach, ale w terminie nie ma nic lepszego niż narzędzia, które po prostu działają. W agencjach zazwyczaj wolelibyśmy nauczyć się kilku nowych rzeczy, które działają dobrze, konsekwentnie, niż móc konfigurować każdy element technologii zgodnie z osobistym gustem każdej osoby.
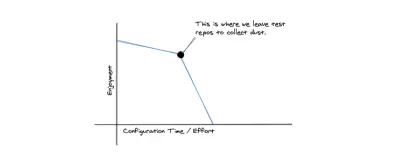
Jedną z dobrych rzeczy w pracy z platformą chmurową, która nie jest open source, jest to, że są całkowicie właścicielami konfiguracji i konfiguracji. Chociaż wadą tego jest uzależnienie od dostawcy, zaletą jest to, że tego typu narzędzia często robią to, do czego zostały skonfigurowane dobrze. Nie ma konieczności majstrowania przy środowiskach, lokalnych konfiguracji ani potoków wdrożeniowych. Mamy też mniej decyzji do podjęcia.
Jest to z natury atrakcyjność serwera bezserwerowego . Ogólnie rzecz biorąc, bezserwerowy w większym stopniu polega na usługach i narzędziach zastrzeżonych. Handlujemy elastycznością hostingu i kodu źródłowego, dzięki czemu możemy uzyskać większą stabilność i skupić się na problemach domeny biznesowej, którą staramy się rozwiązać. Zauważę również, że kiedy oceniam technologię i mam wrażenie, że migracja z platformy może być potrzebna, często jest to zły znak na początku.
W przypadku baz danych konfiguracja „ustaw i zapomnij” jest idealna podczas pracy z klientami, w których potrzeby bazy danych mogą być niejednoznaczne. Mieliśmy klientów, którzy nie byli pewni, jak popularny będzie program lub aplikacja. Mieliśmy klientów, z którymi technicznie nie byliśmy zakontraktowani do obsługi w ten sposób, ale mimo to zadzwonili do nas w panice, gdy potrzebowali nas do skalowania ich bazy danych lub aplikacji.
W przeszłości, tworząc nasze SOW, zawsze musieliśmy brać pod uwagę takie rzeczy, jak nadmiarowość, replikacja danych i sharding w celu skalowania. Próba omówienia każdego scenariusza, a jednocześnie przygotowanie do przeniesienia pełnej księgi biznesowej w przypadku, gdyby baza danych nie była skalowana, jest sytuacją niemożliwą do przygotowania. W końcu bezserwerowa baza danych ułatwia te rzeczy.
Nigdy nie tracisz danych , nie musisz się martwić o replikację danych w sieci ani udostępnianie większej bazy danych i komputera do ich uruchamiania — to wszystko po prostu działa. Skupiamy się tylko na bieżącym problemie biznesowym, architektura techniczna i skala będą zawsze zarządzane. Dla naszego zespołu programistów jest to ogromna wygrana; mamy mniej ćwiczeń przeciwpożarowych, monitorowania i przełączania kontekstu.
Umiejętność uczenia się
Istnieje klasyczna miara doświadczenia użytkownika, która moim zdaniem ma zastosowanie do doświadczenia programisty, a mianowicie umiejętność uczenia się . Projektując dla określonego doświadczenia użytkownika, nie patrzymy tylko na to, czy coś jest oczywiste lub łatwe za pierwszym razem. Technologia jest po prostu bardziej złożona niż przez większość czasu. Ważne jest to, jak łatwo nowy użytkownik może nauczyć się i opanować system.
Jeśli chodzi o narzędzia techniczne, zwłaszcza te o dużej mocy, byłoby dużo prosić o zerową krzywą uczenia się . Zwykle szukamy dobrej dokumentacji dla najczęstszych przypadków użycia i łatwego i szybkiego budowania tej wiedzy w projekcie. Tracenie trochę czasu na naukę przy pierwszym projekcie z technologią jest w porządku. Po tym powinniśmy widzieć poprawę efektywności z każdym kolejnym projektem.
To, czego szukam tutaj, to to, jak możemy wykorzystać wiedzę i wzorce, które już znamy, aby skrócić krzywą uczenia się. Na przykład w przypadku baz danych bezserwerowych nie będzie praktycznie żadnej krzywej uczenia się, aby je skonfigurować w chmurze i wdrożyć. Jeśli chodzi o korzystanie z bazy danych, jedną z rzeczy, które lubię, jest to, że wciąż możemy wykorzystać wszystkie lata doskonalenia relacyjnych baz danych i zastosować zdobytą wiedzę w naszej nowej konfiguracji. W tym przypadku uczymy się korzystać z nowego narzędzia, ale nie zmusza nas to do ponownego przemyślenia modelowania danych od podstaw.

Jako przykład tego, podczas korzystania z Firebase, MongoDB i DynamoDB stwierdziliśmy, że zachęca to do denormalizacji danych zamiast prób łączenia różnych dokumentów. Stworzyło to wiele problemów poznawczych podczas modelowania naszych danych, ponieważ musieliśmy myśleć w kategoriach wzorców dostępu, a nie podmiotów biznesowych. Z drugiej strony ta fauna pozwoliła nam wykorzystać naszą wieloletnią relacyjną wiedzę, a także nasze preferencje dla znormalizowanych danych, jeśli chodzi o modelowanie danych.
Część, do której musieliśmy się przyzwyczaić, to używanie indeksów i nowego języka zapytań, aby połączyć te elementy. Ogólnie rzecz biorąc, odkryłem, że zachowanie koncepcji, które są częścią większych paradygmatów projektowania oprogramowania, ułatwia zespołowi programistów pod względem uczenia się i adaptacji.
Skąd wiemy, że zespół przyjmuje i kocha nową technologię? Myślę, że najlepszym znakiem jest pytanie, czy to narzędzie integruje się ze wspomnianą nową technologią? Kiedy nowa technologia osiąga poziom atrakcyjności i radości, że zespół szuka sposobów na włączenie jej do większej liczby projektów, jest to dobry znak, że masz zwycięzcę.
Biznes
W tej sekcji musimy przyjrzeć się, jak nowa technologia spełnia nasze potrzeby biznesowe . Należą do nich pytania takie jak:
- Jak łatwo można go wycenić i zintegrować z naszymi planami wsparcia?
- Czy możemy łatwo przenieść go do klientów?
- Czy klienci mogą być dołączani do tego narzędzia, jeśli zajdzie taka potrzeba?
- Ile czasu faktycznie oszczędza to narzędzie, jeśli w ogóle?
Pojawienie się modelu serverless jako paradygmatu dobrze pasuje do agencji. Kiedy mówimy o bazach danych i DevOps, zapotrzebowanie na specjalistów w tych dziedzinach w agencjach jest ograniczone. Często przekazujemy projekt po jego zakończeniu lub wspieramy go w ograniczonym zakresie długoterminowo. Mamy tendencję do skłaniania się ku inżynierom zajmującym się pełnymi stosami, ponieważ te potrzeby znacznie przewyższają potrzeby DevOps. Gdybyśmy zatrudnili inżyniera DevOps, prawdopodobnie spędziliby kilka godzin na wdrażaniu projektu i wiele więcej godzin czekając na pożar.
W związku z tym zawsze mamy gotowych wykonawców DevOps , ale nie zatrudniamy pracowników na te stanowiska w pełnym wymiarze godzin. Oznacza to, że nie możemy polegać na inżynierze DevOps, który będzie gotowy do skoku w przypadku nieoczekiwanego problemu. Dla nas wiemy, że możemy uzyskać lepsze stawki za hosting, przechodząc bezpośrednio do AWS, ale wiemy również, że korzystając z Heroku, możemy polegać na naszym obecnym personelu, aby debugować większość problemów. O ile nie mamy klienta, który musi wspierać długoterminowe z określonymi potrzebami zaplecza, lubimy domyślnie korzystać z zarządzanych platform jako usługi.
Bazy danych nie są wyjątkiem. Uwielbiamy opierać się na usługach takich jak Mongo Atlas czy Heroku Postgres, aby maksymalnie uprościć ten proces. Gdy zaczęliśmy widzieć, jak coraz więcej z naszego stosu przechodzi w narzędzia bezserwerowe, takie jak Vercel, Netlify lub AWS Lambda – nasze potrzeby w zakresie baz danych musiały ewoluować wraz z tym. Bezserwerowe bazy danych , takie jak Firebase, DynamoDB i Fauna, są świetne, ponieważ dobrze integrują się z aplikacjami bezserwerowymi, ale także całkowicie uwalniają naszą firmę od aprowizacji i skalowania.
Rozwiązania te sprawdzają się również dobrze w przypadku bardziej tradycyjnych aplikacji, w których nie mamy aplikacji bezserwerowej, ale nadal możemy wykorzystać wydajność bezserwerową na poziomie bazy danych. Jako firma bardziej produktywne jest dla nas poznanie jednej bazy danych, która może mieć zastosowanie do obu światów, niż do przełączania kontekstu. Jest to podobne do naszej decyzji o przyjęciu Node i izomorficznego JavaScript (i TypeScript).
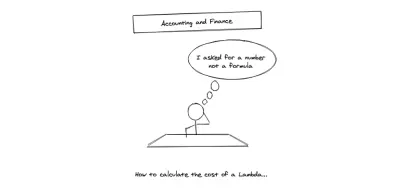
Jedną z wad, jakie znaleźliśmy w przypadku bezserwerowego, było wymyślanie cen dla klientów , dla których zarządzamy tymi usługami. W bardziej tradycyjnej architekturze poziomy stawki ryczałtowej bardzo ułatwiają przełożenie ich na stawkę dla klientów z przewidywalnymi okolicznościami ponoszenia podwyżek i nadwyżek. Jeśli chodzi o serverless, może to być niejednoznaczne. Finansiści zazwyczaj nie lubią słuchać takich rzeczy, jak pobieramy 1/10 pensa za każdy odczyt powyżej 1 miliona i tak dalej i tak dalej.
Trudno to przełożyć na ustaloną liczbę nawet dla inżynierów, ponieważ często budujemy aplikacje, których nie jesteśmy pewni, jakie będą ich zastosowania . Często musimy sami tworzyć poziomy, ale wiele zmiennych, które biorą udział w kalkulacji kosztów lambdy, może być trudne do zrozumienia. Ostatecznie, w przypadku produktu SaaS te modele opłat zgodnie z rzeczywistym użyciem są świetne, ale w przypadku agencji księgowi lubią bardziej konkretne i przewidywalne liczby.
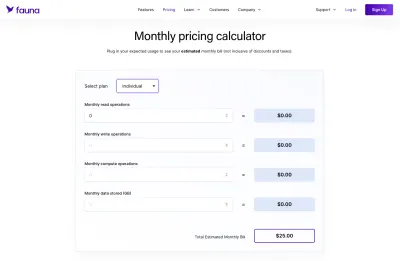
Jeśli chodzi o Faunę, zdecydowanie bardziej niejednoznaczne było ustalenie, niż powiedzmy, standardowa baza danych MySQL, która miała hosting za stałą stawkę za określoną ilość miejsca. Plusem było to, że Fauna zapewnia ładny kalkulator, którego mogliśmy użyć do stworzenia własnych schematów cenowych.
Innym trudnym aspektem bezserwerowego może być to, że wielu z tych dostawców nie pozwala na łatwy podział każdej hostowanej aplikacji. Na przykład platforma Heroku ułatwia to, tworząc nowe potoki i zespoły. Możemy nawet wprowadzić dla nich kartę kredytową klienta, jeśli nie chcą korzystać z naszych planów hostingowych. Wszystko to można zrobić w tym samym panelu, więc nie musieliśmy tworzyć wielu loginów.
W przypadku innych narzędzi bezserwerowych było to znacznie trudniejsze. Przy ocenie bezserwerowych baz danych Firebase obsługuje podział płatności według projektu . W przypadku Fauny czy DynamoDB nie jest to możliwe, więc musimy trochę popracować, aby monitorować wykorzystanie w ich desce rozdzielczej, a jeśli klient chce zrezygnować z naszego serwisu, musielibyśmy przenieść bazę danych na własne konto.
Ostatecznie narzędzia bezserwerowe zapewniają wspaniałe możliwości biznesowe pod względem oszczędności kosztów, zarządzania i wydajności procesów. Jednak często stanowią one wyzwanie dla agencji , jeśli chodzi o ustalanie cen i zarządzanie kontem. Jest to jeden obszar, w którym musieliśmy wykorzystać kalkulatory kosztów, aby stworzyć własne przewidywalne poziomy cenowe lub skonfigurować klientów z własnymi kontami, aby mogli dokonywać płatności bezpośrednio.
Wniosek
Przyjęcie nowej technologii jako agencji może być trudnym zadaniem. Chociaż jesteśmy w wyjątkowej sytuacji, aby pracować nad nowymi projektami typu greenfield, które mają możliwości dla nowych technologii, musimy również wziąć pod uwagę ich długoterminowe inwestycje. Jak sobie poradzą? Czy nasi ludzie będą produktywni i będą czerpać przyjemność z ich używania? Can we incorporate them into our business offering?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
Dalsza lektura
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience