
Budowanie wykrywacza pomieszczeń dla urządzeń IoT w systemie Mac OS
Opublikowany: 2022-03-10Wiedza, w którym pomieszczeniu się znajdujesz, umożliwia korzystanie z różnych aplikacji IoT — od włączania światła po zmianę kanałów telewizyjnych. Jak więc możemy wykryć moment, w którym Ty i Twój telefon jesteście w kuchni, sypialni lub salonie? Przy dzisiejszym sprzęcie towarowym istnieje niezliczona ilość możliwości:
Jednym z rozwiązań jest wyposażenie każdego pokoju w urządzenie bluetooth . Gdy telefon znajdzie się w zasięgu urządzenia Bluetooth, telefon będzie wiedział, które to pomieszczenie, na podstawie urządzenia Bluetooth. Jednak utrzymanie szeregu urządzeń Bluetooth wiąże się ze znacznym obciążeniem — od wymiany baterii po wymianę dysfunkcyjnych urządzeń. Ponadto bliskość urządzenia Bluetooth nie zawsze jest odpowiedzią: jeśli jesteś w salonie, przy ścianie dzielonej z kuchnią, Twoje urządzenia kuchenne nie powinny zacząć produkować jedzenia.
Innym, choć niepraktycznym rozwiązaniem jest użycie GPS . Należy jednak pamiętać, że GPS działa słabo w pomieszczeniach, w których mnogość ścian, inne sygnały i inne przeszkody sieją spustoszenie w precyzji GPS.
Zamiast tego nasze podejście polega na wykorzystaniu wszystkich sieci Wi-Fi w zasięgu — nawet tych, do których nie jest podłączony Twój telefon. Oto jak: rozważ siłę WiFi A w kuchni; powiedzmy, że jest to 5. Ponieważ między kuchnią a sypialnią jest ściana, możemy rozsądnie oczekiwać, że siła Wi-Fi A w sypialni będzie różna; powiedzmy, że to 2. Możemy wykorzystać tę różnicę do przewidzenia, w którym pomieszczeniu się znajdujemy. Co więcej: Sieć WiFi B od naszego sąsiada można wykryć tylko z salonu, ale jest skutecznie niewidoczna z kuchni. To sprawia, że przewidywanie jest jeszcze łatwiejsze. Podsumowując, lista wszystkich WiFi w zasięgu daje nam mnóstwo informacji.
Ta metoda ma wyraźne zalety:
- nie wymaga więcej sprzętu;
- poleganie na bardziej stabilnych sygnałach, takich jak WiFi;
- działa dobrze tam, gdzie inne techniki, takie jak GPS, są słabe.
Im więcej ścian, tym lepiej, im bardziej zróżnicowane są moce sieci Wi-Fi, tym łatwiej klasyfikować pomieszczenia. Zbudujesz prostą aplikację komputerową, która zbiera dane, uczy się na ich podstawie i przewiduje, w którym pokoju jesteś w danym momencie.
Dalsze czytanie na SmashingMag:
- Powstanie inteligentnego interfejsu konwersacyjnego
- Zastosowania uczenia maszynowego dla projektantów
- Jak prototypować doświadczenia IoT: budowanie sprzętu
- Projektowanie dla Internetu rzeczy emocjonalnych
Warunki wstępne
Do tego samouczka będziesz potrzebować systemu Mac OSX. Podczas gdy kod może dotyczyć dowolnej platformy, udostępnimy tylko instrukcje dotyczące instalacji zależności dla komputerów Mac.
- Mac OS X
- Homebrew, menedżer pakietów dla Mac OSX. Aby zainstalować, skopiuj i wklej polecenie w brew.sh
- Instalacja NodeJS 10.8.0+ i npm
- Instalacja Pythona 3.6+ i pip. Zobacz pierwsze 3 sekcje „Jak zainstalować virtualenv, instalowanie za pomocą pip i zarządzanie pakietami”
Krok 0: Skonfiguruj środowisko pracy
Twoja aplikacja komputerowa zostanie napisana w NodeJS. Jednak, aby wykorzystać bardziej wydajne biblioteki obliczeniowe, takie jak numpy , kod uczenia i przewidywania zostanie napisany w Pythonie. Na początek skonfigurujemy Twoje środowiska i zainstalujemy zależności. Utwórz nowy katalog do przechowywania swojego projektu.
mkdir ~/riotPrzejdź do katalogu.
cd ~/riotUżyj pip, aby zainstalować domyślny menedżer środowiska wirtualnego Pythona.
sudo pip install virtualenv Utwórz wirtualne środowisko Python3.6 o nazwie riot .
virtualenv riot --python=python3.6Aktywuj środowisko wirtualne.
source riot/bin/activate Twój monit jest teraz poprzedzony (riot) . Oznacza to, że pomyślnie weszliśmy do środowiska wirtualnego. Zainstaluj następujące pakiety za pomocą pip :
-
numpy: wydajna, liniowa biblioteka algebry -
scipy: naukowa biblioteka obliczeniowa, która implementuje popularne modele uczenia maszynowego
pip install numpy==1.14.3 scipy ==1.1.0Po skonfigurowaniu katalogu roboczego zaczniemy od aplikacji komputerowej, która rejestruje wszystkie sieci Wi-Fi w zasięgu. Te nagrania będą stanowić dane szkoleniowe dla Twojego modelu uczenia maszynowego. Gdy będziemy mieć dane pod ręką, napiszesz klasyfikator metodą najmniejszych kwadratów, wyszkolony na zebranych wcześniej sygnałach WiFi. Na koniec użyjemy modelu najmniejszych kwadratów, aby przewidzieć pokój, w którym się znajdujesz, na podstawie sieci Wi-Fi w zasięgu.
Krok 1: Początkowa aplikacja komputerowa
W tym kroku stworzymy nową aplikację desktopową przy użyciu Electron JS. Na początek zamiast tego użyjemy menedżera pakietów Node npm i narzędzie do pobierania wget .
brew install npm wgetNa początek stworzymy nowy projekt Node.
npm init To monituje o nazwę pakietu, a następnie numer wersji. Naciśnij ENTER , aby zaakceptować domyślną nazwę riot i domyślną wersję 1.0.0 .
package name: (riot) version: (1.0.0) To monituje o opis projektu. Dodaj dowolny niepusty opis, który chcesz. Poniżej opis to room detector
description: room detector Zostanie wyświetlony monit o podanie punktu wejścia lub głównego pliku, z którego ma być uruchamiany projekt. Wpisz app.js .
entry point: (index.js) app.js To monituje o test command i git repository . Naciśnij ENTER , aby na razie pominąć te pola.
test command: git repository: To monituje o keywords i author . Wpisz dowolne wartości. Poniżej używamy iot , wifi dla słów kluczowych i używamy John Doe dla autora.
keywords: iot,wifi author: John Doe To monituje o licencję. Naciśnij ENTER , aby zaakceptować domyślną wartość ISC .
license: (ISC) W tym momencie npm wyświetli podsumowanie dotychczasowych informacji. Twój wynik powinien być podobny do poniższego.
{ "name": "riot", "version": "1.0.0", "description": "room detector", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "iot", "wifi" ], "author": "John Doe", "license": "ISC" } Naciśnij ENTER , aby zaakceptować. npm następnie tworzy package.json . Wymień wszystkie pliki do ponownego sprawdzenia.
lsSpowoduje to wyświetlenie jedynego pliku w tym katalogu wraz z folderem środowiska wirtualnego.
package.json riotZainstaluj zależności NodeJS dla naszego projektu.
npm install electron --global # makes electron binary accessible globally npm install node-wifi --save Zacznij od main.js z Electron Quick Start, pobierając plik, korzystając z poniższego. Poniższy argument -O zmienia nazwę main.js na app.js .
wget https://raw.githubusercontent.com/electron/electron-quick-start/master/main.js -O app.js Otwórz app.js w nano lub w swoim ulubionym edytorze tekstu.
nano app.js W linii 12. zmień index.html na static/index.html , ponieważ utworzymy katalog static , który będzie zawierał wszystkie szablony HTML.
function createWindow () { // Create the browser window. win = new BrowserWindow({width: 1200, height: 800}) // and load the index.html of the app. win.loadFile('static/index.html') // Open the DevTools. Zapisz zmiany i wyjdź z edytora. Twój plik powinien być zgodny z kodem źródłowym pliku app.js Teraz utwórz nowy katalog do przechowywania naszych szablonów HTML.
mkdir staticPobierz arkusz stylów utworzony dla tego projektu.
wget https://raw.githubusercontent.com/alvinwan/riot/master/static/style.css?token=AB-ObfDtD46ANlqrObDanckTQJ2Q1Pyuks5bf79PwA%3D%3D -O static/style.css Otwórz static/index.html w nano lub w swoim ulubionym edytorze tekstu. Zacznij od standardowej struktury HTML.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> </head> <body> <main> </main> </body> </html>Zaraz po tytule połącz czcionkę Montserrat połączoną z czcionkami Google i arkuszem stylów.
<title>Riot | Room Detector</title> <!-- start new code --> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> <!-- end new code --> </head> Pomiędzy main tagami dodaj miejsce na przewidywaną nazwę pokoju.
<main> <!-- start new code --> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> <!-- end new code --> </main>Twój skrypt powinien teraz dokładnie odpowiadać następującym. Wyjdź z edytora.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> </main> </body> </html>Teraz zmień plik pakietu, aby zawierał polecenie start.
nano package.json Zaraz po wierszu 7 dodaj polecenie start , które jest aliasem do electron . . Pamiętaj, aby dodać przecinek na końcu poprzedniego wiersza.
"scripts": { "test": "echo \"Error: no test specified\" && exit 1", "start": "electron ." }, Zapisz i wyjdź. Jesteś teraz gotowy do uruchomienia swojej aplikacji komputerowej w Electron JS. Użyj npm , aby uruchomić aplikację.
npm startTwoja aplikacja komputerowa powinna odpowiadać następującym.

To kończy twoją początkową aplikację komputerową. Aby wyjść, wróć do terminala i CTRL + C. W następnym kroku nagramy sieci Wi-Fi i udostępnimy narzędzie do nagrywania za pośrednictwem interfejsu użytkownika aplikacji komputerowej.
Krok 2: Nagrywaj sieci Wi-Fi
W tym kroku napiszesz skrypt NodeJS, który rejestruje siłę i częstotliwość wszystkich sieci Wi-Fi w zasięgu. Utwórz katalog dla swoich skryptów.
mkdir scripts Otwórz scripts/observe.js w nano lub swoim ulubionym edytorze tekstu.
nano scripts/observe.jsZaimportuj narzędzie Wi-Fi NodeJS i obiekt systemu plików.
var wifi = require('node-wifi'); var fs = require('fs'); Zdefiniuj funkcję record , która akceptuje procedurę obsługi uzupełniania.
/** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { } Wewnątrz nowej funkcji zainicjuj narzędzie Wi-Fi. Ustaw iface na null, aby zainicjować losowy interfejs Wi-Fi, ponieważ ta wartość jest obecnie nieistotna.
function record(n, completion, hook) { wifi.init({ iface : null }); }Zdefiniuj tablicę zawierającą próbki. Próbki to dane szkoleniowe, których użyjemy w naszym modelu. Próbki w tym konkretnym samouczku to listy sieci Wi-Fi w zasięgu i powiązane z nimi mocne strony, częstotliwości, nazwy itp.
function record(n, completion, hook) { ... samples = [] } Zdefiniuj funkcję rekurencyjną startScan , która asynchronicznie zainicjuje skanowanie Wi-Fi. Po zakończeniu asynchroniczne skanowanie Wi-Fi będzie rekurencyjnie wywołać startScan .
function record(n, completion, hook) { ... function startScan(i) { wifi.scan(function(err, networks) { }); } startScan(n); } W wywołaniu zwrotnym wifi.scan sprawdź błędy lub puste listy sieci i ponownie uruchom skanowanie, jeśli tak.
wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } });Dodaj podstawowy przypadek funkcji rekurencyjnej, który wywołuje procedurę obsługi uzupełniania.
wifi.scan(function(err, networks) { ... if (i <= 0) { return completion({samples: samples}); } });Wyprowadź aktualizację postępu, dołącz do listy próbek i wykonaj wywołanie cykliczne.
wifi.scan(function(err, networks) { ... hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); Na końcu pliku wywołaj funkcję record z wywołaniem zwrotnym, które zapisuje próbki w pliku na dysku.
function record(completion) { ... } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + (21-i) + " with " + networks.length + " networks"); }) } cli();Dokładnie sprawdź, czy Twój plik pasuje do następujących elementów:
var wifi = require('node-wifi'); var fs = require('fs'); /** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { wifi.init({ iface : null // network interface, choose a random wifi interface if set to null }); samples = [] function startScan(i) { wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } if (i <= 0) { return completion({samples: samples}); } hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); } startScan(n); } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks"); }) } cli();Zapisz i wyjdź. Uruchom skrypt.
node scripts/observe.jsTwoje dane wyjściowe będą pasować do następujących, ze zmienną liczbą sieci.
* [INFO] Collected sample 1 with 39 networks Zbadaj próbki, które właśnie zostały zebrane. Pipe to json_pp , aby ładnie wydrukować JSON i pipe do head, aby wyświetlić pierwsze 16 wierszy.
cat samples.json | json_pp | head -16Poniżej znajduje się przykładowe wyjście dla sieci 2,4 GHz.
{ "samples": [ [ { "mac": "64:0f:28:79:9a:29", "bssid": "64:0f:28:79:9a:29", "ssid": "SMASHINGMAGAZINEROCKS", "channel": 4, "frequency": 2427, "signal_level": "-91", "security": "WPA WPA2", "security_flags": [ "(PSK/AES,TKIP/TKIP)", "(PSK/AES,TKIP/TKIP)" ] },Na tym kończy się skrypt skanowania Wi-Fi NodeJS. To pozwala nam przeglądać wszystkie sieci Wi-Fi w zasięgu. W następnym kroku udostępnisz ten skrypt z aplikacji komputerowej.
Krok 3: Połącz skrypt skanowania z aplikacją komputerową
W tym kroku najpierw dodasz przycisk do aplikacji komputerowej, aby uruchomić skrypt. Następnie zaktualizujesz interfejs aplikacji komputerowej zgodnie z postępem skryptu.
Otwórz static/index.html .
nano static/index.htmlWstaw przycisk „Dodaj”, jak pokazano poniżej.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <div class="buttons"> <a href="add.html" class="button">Add new room</a> </div> <!-- end new code --> </main> Zapisz i wyjdź. Otwórz static/add.html .
nano static/add.htmlWklej następującą treść.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Add New Room</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <h1 class="title">0</h1> <p class="subtitle">of <span>20</span> samples needed. Feel free to move around the room.</p> <input type="text" class="text-field" placeholder="(room name)"> <div class="buttons"> <a href="#" class="button">Start recording</a> <a href="index.html" class="button light">Cancel</a> </div> <p class="text"></p> </main> <script> require('../scripts/observe.js') </script> </body> </html> Zapisz i wyjdź. Otwórz ponownie scripts/observe.js .
nano scripts/observe.js Pod funkcją cli zdefiniuj nową funkcję ui .
function cli() { ... } // start new code function ui() { } // end new code cli();Zaktualizuj stan aplikacji komputerowej, aby wskazać, że funkcja została uruchomiona.
function ui() { var room_name = document.querySelector('#add-room-name').value; var status = document.querySelector('#add-status'); var number = document.querySelector('#add-title'); status.style.display = "block" status.innerHTML = "Listening for wifi..." }Podziel dane na zestawy danych uczących i walidacyjnych.
function ui() { ... function completion(data) { train_data = {samples: data['samples'].slice(0, 15)} test_data = {samples: data['samples'].slice(15)} var train_json = JSON.stringify(train_data); var test_json = JSON.stringify(test_data); } } Nadal w wywołaniu zwrotnym completion zapisz oba zestawy danych na dysku.
function ui() { ... function completion(data) { ... fs.writeFile('data/' + room_name + '_train.json', train_json, 'utf8', function() {}); fs.writeFile('data/' + room_name + '_test.json', test_json, 'utf8', function() {}); console.log(" * [INFO] Done") status.innerHTML = "Done." } } Wywołaj record z odpowiednimi wywołaniami zwrotnymi, aby nagrać 20 próbek i zapisać próbki na dysku.
function ui() { ... function completion(data) { ... } record(20, completion, function(i, networks) { number.innerHTML = i console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks") }) } Na koniec w razie potrzeby wywołaj funkcje cli i ui . Zacznij od usunięcia cli(); zadzwoń na dole pliku.
function ui() { ... } cli(); // remove me Sprawdź, czy obiekt dokumentu jest dostępny globalnie. Jeśli nie, skrypt jest uruchamiany z wiersza poleceń. W takim przypadku wywołaj funkcję cli . Jeśli tak, skrypt jest ładowany z aplikacji komputerowej. W takim przypadku powiąż odbiornik kliknięć z funkcją ui .
if (typeof document == 'undefined') { cli(); } else { document.querySelector('#start-recording').addEventListener('click', ui) }Zapisz i wyjdź. Utwórz katalog do przechowywania naszych danych.
mkdir dataUruchom aplikację komputerową.
npm startZobaczysz następującą stronę główną. Kliknij „Dodaj pokój”.
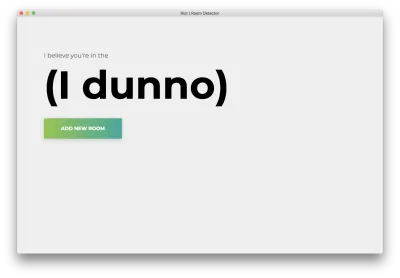
Zobaczysz następujący formularz. Wpisz nazwę pokoju. Zapamiętaj tę nazwę, ponieważ użyjemy jej później. Naszym przykładem będzie bedroom .
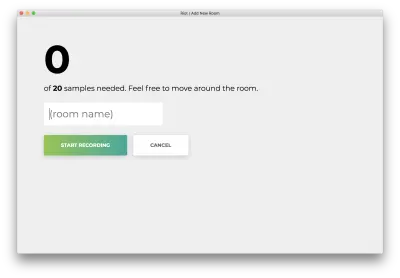
Kliknij „Rozpocznij nagrywanie”, a zobaczysz następujący status „Słuchanie Wi-Fi…”.
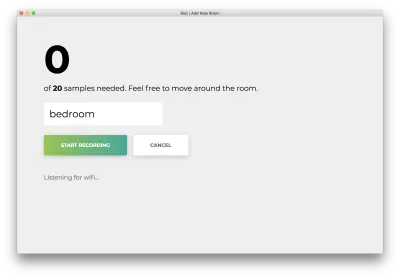
Po zarejestrowaniu wszystkich 20 próbek Twoja aplikacja będzie pasować do następujących elementów. Status będzie brzmieć „Gotowe”.

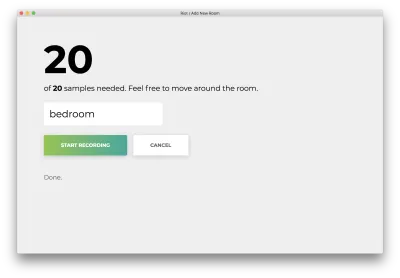
Kliknij błędnie nazwaną „Anuluj”, aby powrócić do strony głównej, która odpowiada następującym.
Możemy teraz skanować sieci Wi-Fi z pulpitu, co zapisze wszystkie nagrane próbki do plików na dysku. Następnie przeszkolimy gotowy algorytm uczenia maszynowego – najmniejszy kwadrat na zebranych danych.
Krok 4: Napisz skrypt szkoleniowy Pythona
W tym kroku napiszemy skrypt szkoleniowy w Pythonie. Utwórz katalog dla narzędzi szkoleniowych.
mkdir model Otwórz model/train.py
nano model/train.py U góry pliku zaimportuj bibliotekę obliczeniową numpy i scipy dla jej modelu najmniejszych kwadratów.
import numpy as np from scipy.linalg import lstsq import json import sysKolejne trzy narzędzia zajmą się ładowaniem i konfiguracją danych z plików na dysku. Zacznij od dodania funkcji narzędziowej, która spłaszcza zagnieżdżone listy. Użyjesz tego do spłaszczenia listy próbek.
import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) Dodaj drugie narzędzie, które ładuje próbki z określonych plików. Ta metoda eliminuje fakt, że próbki są rozłożone na wiele plików, zwracając tylko jeden generator dla wszystkich próbek. Dla każdej próbki etykieta jest indeksem pliku. np. jeśli wywołasz get_all_samples('a.json', 'b.json') , wszystkie próbki w a.json będą miały etykietę 0, a wszystkie próbki w b.json będą miały etykietę 1.
def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, labelNastępnie dodaj narzędzie, które koduje próbki przy użyciu modelu bag-of-words-esque. Oto przykład: Załóżmy, że pobieramy dwie próbki.
- sieć Wi-Fi A o sile 10 i sieć Wi-Fi B o sile 15
- sieć Wi-Fi B o sile 20 i sieć Wi-Fi C o sile 25.
Ta funkcja wygeneruje listę trzech liczb dla każdej próbki: pierwsza wartość to siła sieci Wi-Fi A, druga dla sieci B, a trzecia dla C. W efekcie format to [A, B, C ].
- [10, 15, 0]
- [0, 20, 25]
def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [strengths[networks.index(network)] if network in networks else 0 for network in ordering] Używając wszystkich trzech powyższych narzędzi, syntetyzujemy kolekcję próbek i ich etykiet. Zbierz wszystkie próbki i etykiety za pomocą get_all_samples . Zdefiniuj spójną ordering formatu, aby kodować wszystkie próbki w trybie one_hot, a następnie zastosuj kodowanie one_hot do próbek. Na koniec skonstruuj odpowiednio macierze danych i etykiet X i Y
def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, orderingTe funkcje uzupełniają potok danych. Następnie abstrahujemy przewidywanie i ocenę modelu. Zacznij od zdefiniowania metody przewidywania. Pierwsza funkcja normalizuje dane wyjściowe naszego modelu, tak że suma wszystkich wartości wynosi 1 i wszystkie wartości są nieujemne; zapewnia to, że wynik jest prawidłowym rozkładem prawdopodobieństwa. Drugi ocenia model.
def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1)Następnie oceń dokładność modelu. W pierwszym wierszu przeprowadzana jest predykcja przy użyciu modelu. Drugi zlicza, ile razy obie wartości przewidywane i prawdziwe zgadzają się, a następnie normalizuje się o całkowitą liczbę próbek.
def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy To kończy nasze narzędzia do przewidywania i oceny. Po tych narzędziach zdefiniuj main funkcję, która będzie gromadzić zestaw danych, trenować i oceniać. Zacznij od przeczytania listy argumentów z wiersza poleceń sys.argv ; są to pomieszczenia, które należy uwzględnić w szkoleniu. Następnie utwórz duży zestaw danych ze wszystkich określonych pomieszczeń.
def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering)Zastosuj kodowanie one-hot do etykiet. Kodowanie jednorazowe jest podobne do powyższego modelu bag-of-words; używamy tego kodowania do obsługi zmiennych kategorialnych. Powiedzmy, że mamy 3 możliwe etykiety. Zamiast oznaczać 1, 2 lub 3, oznaczamy dane za pomocą [1, 0, 0], [0, 1, 0] lub [0, 0, 1]. W tym samouczku oszczędzimy wyjaśnienia, dlaczego kodowanie jednokrotne jest ważne. Trenuj model i oceniaj zarówno w zbiorach trenowania, jak i walidacji.
def main(): ... X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) test_accuracy = evaluate(X_test, Y_test, w)Wydrukuj obie dokładności i zapisz model na dysku.
def main(): ... print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, test_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() Na końcu pliku uruchom funkcję main .
if __name__ == '__main__': main()Zapisz i wyjdź. Dokładnie sprawdź, czy Twój plik pasuje do następujących elementów:
import numpy as np from scipy.linalg import lstsq import json import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [int(strengths[networks.index(network)]) if network in networks else 0 for network in ordering] def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1) def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) validation_accuracy = evaluate(X_test, Y_test, w) print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, validation_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() if __name__ == '__main__': main() Zapisz i wyjdź. Przypomnij sobie nazwę pokoju użytą powyżej podczas nagrywania 20 sampli. Użyj tej nazwy zamiast bedroom poniżej. Naszym przykładem jest bedroom . Używamy -W ignore , aby zignorować ostrzeżenia z błędu LAPACK.
python -W ignore model/train.py bedroomPonieważ zebraliśmy próbki szkoleniowe tylko dla jednego pokoju, powinieneś zobaczyć 100% dokładności szkolenia i walidacji.
Train accuracy (100.0%), Validation accuracy (100.0%)Następnie połączymy ten skrypt szkoleniowy z aplikacją komputerową.
Krok 5: Połącz skrypt pociągu
Na tym etapie automatycznie przeszkolimy model za każdym razem, gdy użytkownik pobierze nową partię próbek. Otwórz scripts/observe.js .
nano scripts/observe.js Zaraz po imporcie fs zaimportuj spawner procesów potomnych i narzędzia.
var fs = require('fs'); // start new code const spawn = require("child_process").spawn; var utils = require('./utils.js'); W funkcji ui użytkownika dodaj następujące wywołanie, aby ponownie retrain się na końcu procedury obsługi zakończenia.
function ui() { ... function completion() { ... retrain((data) => { var status = document.querySelector('#add-status'); accuracies = data.toString().split('\n')[0]; status.innerHTML = "Retraining succeeded: " + accuracies }); } ... } Po funkcji ui dodaj następującą funkcję retrain . Spowoduje to pojawienie się procesu potomnego, który uruchomi skrypt Pythona. Po zakończeniu proces wywołuje procedurę obsługi zakończenia. W przypadku niepowodzenia zarejestruje komunikat o błędzie.
function ui() { .. } function retrain(completion) { var filenames = utils.get_filenames() const pythonProcess = spawn('python', ["./model/train.py"].concat(filenames)); pythonProcess.stdout.on('data', completion); pythonProcess.stderr.on('data', (data) => { console.log(" * [ERROR] " + data.toString()) }) } Zapisz i wyjdź. Otwórz scripts/utils.js .
nano scripts/utils.js Dodaj następujące narzędzie do pobierania wszystkich zestawów danych w data/ .
var fs = require('fs'); module.exports = { get_filenames: get_filenames } function get_filenames() { filenames = new Set([]); fs.readdirSync("data/").forEach(function(filename) { filenames.add(filename.replace('_train', '').replace('_test', '').replace('.json', '' )) }); filenames = Array.from(filenames.values()) filenames.sort(); filenames.splice(filenames.indexOf('.DS_Store'), 1) return filenames }Zapisz i wyjdź. Aby zakończyć ten krok, przenieś się fizycznie do nowej lokalizacji. W idealnym przypadku pomiędzy pierwotną lokalizacją a nową lokalizacją powinna znajdować się ściana. Im więcej barier, tym lepiej będzie działać Twoja aplikacja komputerowa.
Ponownie uruchom aplikację komputerową.
npm startTak jak poprzednio, uruchom skrypt szkoleniowy. Kliknij „Dodaj pokój”.
Wpisz nazwę pokoju, która różni się od nazwy Twojego pierwszego pokoju. Wykorzystamy living room .
Kliknij „Rozpocznij nagrywanie”, a zobaczysz następujący status „Słuchanie Wi-Fi…”.
Po zarejestrowaniu wszystkich 20 próbek Twoja aplikacja będzie pasować do następujących elementów. Status będzie brzmieć „Gotowe. Model przekwalifikowania…”
W następnym kroku użyjemy tego przeszkolonego modelu do przewidywania pokoju, w którym się znajdujesz, w locie.
Krok 6: Napisz skrypt ewaluacyjny Pythona
W tym kroku załadujemy wstępnie wytrenowane parametry modelu, przeskanujemy w poszukiwaniu sieci Wi-Fi i przewidzimy pomieszczenie na podstawie skanowania.
Otwórz model/eval.py .
nano model/eval.pyImportuj biblioteki używane i zdefiniowane w naszym ostatnim skrypcie.
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate Zdefiniuj narzędzie do wyodrębniania nazw wszystkich zestawów danych. Ta funkcja zakłada, że wszystkie zestawy danych są przechowywane w data/ jako <dataset>_train.json i <dataset>_test.json .
from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) Zdefiniuj main funkcję i zacznij od załadowania parametrów zapisanych ze skryptu szkoleniowego.
def get_datasets(): ... def main(): w = np.load('w.npy') ordering = np.load('ordering.npy')Utwórz zbiór danych i przewiduj.
def main(): ... classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w))Oblicz wynik ufności na podstawie różnicy między dwoma najwyższymi prawdopodobieństwami.
def main(): ... sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) Na koniec wyodrębnij kategorię i wydrukuj wynik. Aby zakończyć skrypt, wywołaj funkcję main .
def main() ... category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Zapisz i wyjdź. Dokładnie sprawdź, czy kod pasuje do następującego (kod źródłowy):
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) def main(): w = np.load('w.npy') ordering = np.load('ordering.npy') classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w)) sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Następnie połączymy ten skrypt oceny z aplikacją komputerową. Aplikacja komputerowa będzie stale skanować Wi-Fi i aktualizować interfejs użytkownika o przewidywany pokój.
Krok 7: Połącz ocenę z aplikacją komputerową
W tym kroku zaktualizujemy interfejs użytkownika, wyświetlając „zaufanie”. Następnie powiązany skrypt NodeJS będzie stale uruchamiał skanowanie i przewidywanie, odpowiednio aktualizując interfejs użytkownika.
Otwórz static/index.html .
nano static/index.htmlDodaj linię dla pewności tuż po tytule i przed przyciskami.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <p class="subtitle">with <span>0%</span> confidence</p> <!-- end new code --> <div class="buttons"> Zaraz po main , ale przed końcem body , dodaj nowy skrypt predict.js .
</main> <!-- start new code --> <script> require('../scripts/predict.js') </script> <!-- end new code --> </body> Zapisz i wyjdź. Otwórz scripts/predict.js .
nano scripts/predict.jsZaimportuj potrzebne narzędzia NodeJS dla systemu plików, narzędzi i generatora procesów potomnych.
var fs = require('fs'); var utils = require('./utils'); const spawn = require("child_process").spawn; Zdefiniuj funkcję predict , która wywołuje oddzielny proces węzła do wykrywania sieci Wi-Fi i oddzielny proces Pythona do przewidywania pomieszczenia.
function predict(completion) { const nodeProcess = spawn('node', ["scripts/observe.js"]); const pythonProcess = spawn('python', ["-W", "ignore", "./model/eval.py", "samples.json"]); }Po pojawieniu się obu procesów dodaj wywołania zwrotne do procesu Pythona, aby uzyskać zarówno sukcesy, jak i błędy. Funkcja wywołania zwrotnego sukcesu rejestruje informacje, wywołuje wywołanie zwrotne dotyczące zakończenia i aktualizuje interfejs użytkownika o przewidywanie i pewność. Wywołanie zwrotne błędu rejestruje błąd.
function predict(completion) { ... pythonProcess.stdout.on('data', (data) => { information = JSON.parse(data.toString()); console.log(" * [INFO] Room '" + information.category + "' with confidence '" + information.confidence + "'") completion() if (typeof document != "undefined") { document.querySelector('#predicted-room-name').innerHTML = information.category document.querySelector('#predicted-confidence').innerHTML = information.confidence } }); pythonProcess.stderr.on('data', (data) => { console.log(data.toString()); }) } Zdefiniuj główną funkcję, aby wywoływać funkcję predict rekurencyjnie, na zawsze.
function main() { f = function() { predict(f) } predict(f) } main();Po raz ostatni otwórz aplikację komputerową, aby zobaczyć prognozę na żywo.
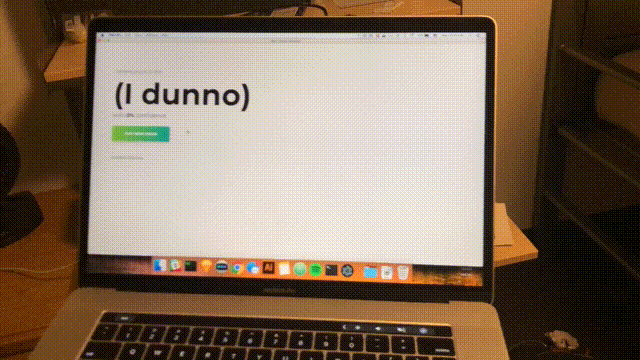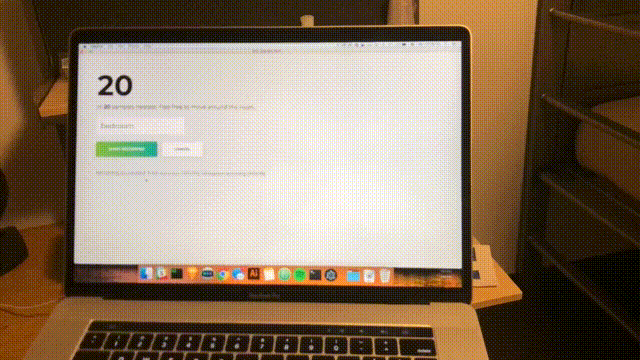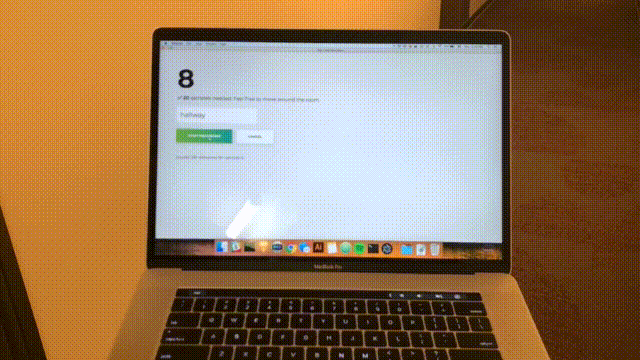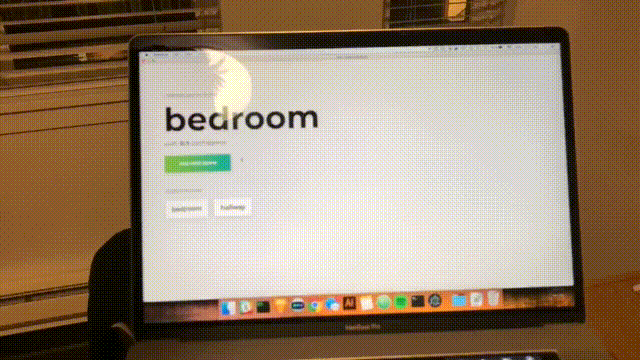
npm startMniej więcej co sekundę skanowanie zostanie zakończone, a interfejs zostanie zaktualizowany o najnowsze zaufanie i przewidywany pokój. Gratulacje; ukończyłeś prosty czujnik pokojowy oparty na wszystkich sieciach Wi-Fi w zasięgu.
Wniosek
W tym samouczku stworzyliśmy rozwiązanie wykorzystujące tylko Twój pulpit do wykrywania Twojej lokalizacji w budynku. Zbudowaliśmy prostą aplikację komputerową przy użyciu Electron JS i zastosowaliśmy prostą metodę uczenia maszynowego we wszystkich sieciach Wi-Fi w zasięgu. To toruje drogę aplikacjom Internetu rzeczy bez potrzeby korzystania z tablicy urządzeń, których utrzymanie jest kosztowne (koszt nie pod względem pieniędzy, ale pod względem czasu i rozwoju).
Uwaga : możesz zobaczyć kod źródłowy w całości na Github.
Z czasem może się okazać, że ta najmniejsza liczba kwadratów w rzeczywistości nie działa spektakularnie. Spróbuj znaleźć dwie lokalizacje w jednym pomieszczeniu lub stań w drzwiach. Najmniejsze kwadraty będą duże, niezdolne do rozróżnienia przypadków brzegowych. Czy możemy zrobić lepiej? Okazuje się, że możemy, a w przyszłych lekcjach wykorzystamy inne techniki i podstawy uczenia maszynowego, aby uzyskać lepszą wydajność. Ten samouczek służy jako szybkie stanowisko testowe dla przyszłych eksperymentów.