
Budowanie centralnej usługi rejestrowania we własnym zakresie
Opublikowany: 2022-03-10Wszyscy wiemy, jak ważne jest debugowanie dla poprawy wydajności i funkcji aplikacji. BrowserStack uruchamia milion sesji dziennie na wysoce rozproszonym stosie aplikacji! Każda obejmuje kilka ruchomych części, ponieważ pojedyncza sesja klienta może obejmować wiele komponentów w kilku regionach geograficznych.
Bez odpowiednich ram i narzędzi proces debugowania może być koszmarem. W naszym przypadku potrzebowaliśmy sposobu na zebranie zdarzeń zachodzących na różnych etapach każdego procesu, aby uzyskać dogłębne zrozumienie wszystkiego, co dzieje się podczas sesji. Dzięki naszej infrastrukturze rozwiązanie tego problemu stało się skomplikowane, ponieważ każdy komponent może mieć wiele zdarzeń z cyklu życia przetwarzania żądania.
Dlatego opracowaliśmy własne, wewnętrzne narzędzie Central Logging Service (CLS), które rejestruje wszystkie ważne zdarzenia zarejestrowane podczas sesji. Te zdarzenia pomagają naszym programistom zidentyfikować warunki, w których coś pójdzie nie tak w sesji, oraz śledzić niektóre kluczowe wskaźniki produktu.
Debugowanie danych obejmuje zarówno proste rzeczy, jak opóźnienie odpowiedzi interfejsu API, jak i monitorowanie kondycji sieci użytkownika. W tym artykule dzielimy się naszą historią budowania naszego narzędzia CLS, które zbiera 70G odpowiednich danych chronologicznych dziennie z ponad 100 komponentów niezawodnie, na dużą skalę i z dwoma instancjami M3.large EC2.
Decyzja o budowie we własnym zakresie
Najpierw zastanówmy się, dlaczego zbudowaliśmy nasze narzędzie CLS we własnym zakresie, zamiast korzystać z istniejącego rozwiązania. Każda z naszych sesji wysyła średnio 15 zdarzeń z wielu komponentów do usługi - co przekłada się na około 15 milionów zdarzeń dziennie.
Nasza usługa potrzebowała możliwości przechowywania wszystkich tych danych. Poszukiwaliśmy kompletnego rozwiązania do obsługi przechowywania, wysyłania i wysyłania zapytań dotyczących wydarzeń. Ponieważ rozważaliśmy rozwiązania innych firm, takie jak Amplitude i Keen, nasze wskaźniki oceny obejmowały koszt, wydajność w obsłudze wielu równoległych żądań i łatwość przyjęcia. Niestety, nie mogliśmy znaleźć dopasowania, które spełniałoby wszystkie nasze wymagania w ramach budżetu – chociaż korzyści obejmowałyby oszczędność czasu i minimalizację alertów. Chociaż wymagałoby to dodatkowego wysiłku, postanowiliśmy sami opracować własne rozwiązanie.

Szczegóły techniczne
Jeśli chodzi o architekturę naszego komponentu, określiliśmy następujące podstawowe wymagania:
- Wydajność klienta
Nie wpływa na wydajność klienta/komponentu wysyłającego zdarzenia. - Skala
Możliwość równoległej obsługi dużej liczby żądań. - Wydajność obsługi
Szybkie przetwarzanie wszystkich wysyłanych do niego zdarzeń. - Wgląd w dane
Każde zarejestrowane zdarzenie musi zawierać pewne metainformacje, aby móc jednoznacznie zidentyfikować składnik lub użytkownika, konto lub wiadomość i podać więcej informacji, aby pomóc programistom w szybszym debugowaniu. - Przeszukiwalny interfejs
Deweloperzy mogą wysyłać zapytania do wszystkich zdarzeń dla określonej sesji, pomagając w debugowaniu określonej sesji, tworzeniu raportów o kondycji komponentów lub generowaniu znaczących statystyk wydajności naszych systemów. - Szybsza i łatwiejsza adopcja
Łatwa integracja z istniejącym lub nowym komponentem bez obciążania zespołów i zajmowania ich zasobów. - Niskie koszty utrzymania
Jesteśmy małym zespołem inżynierskim, więc szukaliśmy rozwiązania, które pozwoli zminimalizować alerty!
Budowanie naszego rozwiązania CLS
Decyzja 1: Wybór interfejsu do ujawnienia
Tworząc CLS, oczywiście nie chcieliśmy stracić żadnych danych, ale nie chcieliśmy też, aby wydajność komponentów spadła. Nie wspominając o dodatkowym czynniku, który sprawia, że istniejące komponenty nie stają się bardziej skomplikowane, ponieważ opóźniłoby to ogólne przyjęcie i wydanie. Przy określaniu naszego interfejsu wzięliśmy pod uwagę następujące wybory:
- Przechowywanie zdarzeń w lokalnym Redis w każdym komponencie, ponieważ procesor w tle wypycha je do CLS. Wymaga to jednak zmiany we wszystkich komponentach, wraz z wprowadzeniem Redisa dla komponentów, które jeszcze go nie zawierały.
- Model wydawca - subskrybent, w którym Redis jest bliższy CLS. Ponieważ wszyscy publikują wydarzenia, ponownie mamy do czynienia z komponentami działającymi na całym świecie. W czasie dużego ruchu opóźniłoby to komponenty. Co więcej, ten zapis może sporadycznie skakać do pięciu sekund (z powodu samego Internetu).
- Wysyłanie zdarzeń przez UDP, co ma mniejszy wpływ na wydajność aplikacji. W takim przypadku dane zostałyby wysłane i zapomniane, jednak wadą byłaby tutaj utrata danych.
Co ciekawe, nasza utrata danych przez UDP wyniosła mniej niż 0,1 proc., co było akceptowalną wartością, abyśmy mogli rozważyć zbudowanie takiej usługi. Udało nam się przekonać wszystkie zespoły, że tak duża strata była warta wykonania, i skorzystaliśmy z interfejsu UDP, który nasłuchuje wszystkich wysyłanych zdarzeń.
Chociaż jednym z wyników był mniejszy wpływ na wydajność aplikacji, napotkaliśmy problem, ponieważ ruch UDP nie był dozwolony ze wszystkich sieci, głównie od naszych użytkowników, co w niektórych przypadkach powodowało, że nie odbieraliśmy w ogóle danych. Jako obejście obsługiwaliśmy rejestrowanie zdarzeń przy użyciu żądań HTTP. Wszystkie zdarzenia pochodzące od użytkownika byłyby przesyłane przez HTTP, natomiast wszystkie zdarzenia rejestrowane z naszych komponentów odbywałyby się przez UDP.
Decyzja 2: stos technologiczny (język, struktura i pamięć masowa)
Jesteśmy sklepem Ruby. Jednak nie byliśmy pewni, czy Ruby byłby lepszym wyborem dla naszego konkretnego problemu. Nasz serwis musiałby obsłużyć wiele przychodzących żądań, a także przetworzyć wiele zapisów. Z blokadą Global Interpreter osiągnięcie wielowątkowości lub współbieżności byłoby trudne w Ruby (proszę nie obrażać się - kochamy Rubiego!). Potrzebowaliśmy więc rozwiązania, które pomogłoby nam osiągnąć tego rodzaju współbieżność.
Chcieliśmy również ocenić nowy język w naszym stosie technologicznym, a ten projekt wydawał się idealny do eksperymentowania z nowymi rzeczami. Wtedy postanowiliśmy dać szansę Golangowi, ponieważ oferował wbudowaną obsługę współbieżności oraz lekkich wątków i rutyn. Każdy zarejestrowany punkt danych przypomina parę klucz-wartość, gdzie „klucz” to zdarzenie, a „wartość” służy jako skojarzona z nim wartość.
Jednak posiadanie prostego klucza i wartości nie wystarczy do pobrania danych związanych z sesją — jest w nich więcej metadanych. Aby temu zaradzić, zdecydowaliśmy, że każde zdarzenie wymagające rejestracji będzie miało identyfikator sesji wraz z kluczem i wartością. Dodaliśmy również dodatkowe pola, takie jak znacznik czasu, identyfikator użytkownika i komponent rejestrujący dane, aby łatwiej było pobierać i analizować dane.

Teraz, kiedy zdecydowaliśmy się na naszą strukturę ładunku, musieliśmy wybrać nasz magazyn danych. Rozważaliśmy Elastic Search, ale chcieliśmy również obsługiwać żądania aktualizacji kluczy. Spowodowałoby to ponowne zindeksowanie całego dokumentu, co mogłoby wpłynąć na wydajność naszych zapisów. MongoDB miał więcej sensu jako magazyn danych, ponieważ łatwiej byłoby przeszukiwać wszystkie zdarzenia na podstawie dowolnego z dodanych pól danych. To było łatwe!
Decyzja 3: Rozmiar bazy danych jest ogromny, a zapytania i archiwizacja są do niczego!
Aby ograniczyć konserwację, nasz serwis musiałby obsłużyć jak najwięcej zdarzeń. Biorąc pod uwagę szybkość, z jaką BrowserStack wydaje funkcje i produkty, byliśmy pewni, że liczba naszych zdarzeń będzie z czasem wzrastać w szybszym tempie, co oznacza, że nasza usługa będzie musiała nadal dobrze funkcjonować. Wraz ze wzrostem przestrzeni odczyty i zapisy zabierają więcej czasu – co może mieć ogromny wpływ na wydajność usługi.
Pierwszym zbadanym przez nas rozwiązaniem było przeniesienie logów z pewnego okresu poza bazę danych (w naszym przypadku zdecydowaliśmy się na 15 dni). W tym celu na każdy dzień utworzyliśmy inną bazę danych, dzięki czemu możemy znaleźć logi starsze niż określony okres bez konieczności skanowania wszystkich pisemnych dokumentów. Teraz nieustannie usuwamy z Mongo bazy danych starsze niż 15 dni, oczywiście zachowując kopie zapasowe na wszelki wypadek.
Jedynym elementem, który pozostał, był interfejs programisty do wyszukiwania danych związanych z sesją. Szczerze mówiąc, to był najłatwiejszy do rozwiązania problem. Zapewniamy interfejs HTTP, za pomocą którego ludzie mogą wysyłać zapytania o zdarzenia związane z sesją w odpowiedniej bazie danych w MongoDB, o dowolne dane mające określony identyfikator sesji.
Architektura
Porozmawiajmy o wewnętrznych komponentach usługi, biorąc pod uwagę następujące punkty:
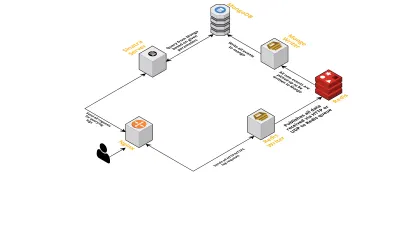
- Jak wspomniano wcześniej, potrzebowaliśmy dwóch interfejsów — jednego nasłuchującego przez UDP i drugiego nasłuchującego przez HTTP. Zbudowaliśmy więc dwa serwery, ponownie po jednym dla każdego interfejsu, aby nasłuchiwać zdarzeń. Gdy tylko nadejdzie zdarzenie, analizujemy je, aby sprawdzić, czy ma wymagane pola - są to identyfikator sesji, klucz i wartość. Jeśli tak się nie stanie, dane są usuwane. W przeciwnym razie dane są przekazywane przez kanał Go do innej gorutyny, której jedynym obowiązkiem jest zapisywanie do MongoDB.
- Możliwym problemem jest tutaj pisanie do MongoDB. Jeśli zapisy do MongoDB są wolniejsze niż szybkość odbierania danych, tworzy to wąskie gardło. To z kolei pozbawia inne przychodzące wydarzenia i oznacza utratę danych. Dlatego serwer powinien szybko przetwarzać przychodzące logi i być gotowym na przetwarzanie nadchodzących. Aby rozwiązać ten problem, podzieliliśmy serwer na dwie części: pierwsza odbiera wszystkie zdarzenia i umieszcza je w kolejce, a druga przetwarza je i zapisuje w MongoDB.
- Do kolejki wybraliśmy Redis. Dzieląc cały komponent na te dwie części, zmniejszyliśmy obciążenie serwera, dając mu miejsce na obsługę większej liczby logów.
- Napisaliśmy mały serwis wykorzystujący serwer Sinatra do obsługi całej pracy związanej z odpytywaniem MongoDB z podanymi parametrami. Zwraca odpowiedź HTML/JSON do programistów, gdy potrzebują informacji o określonej sesji.
Wszystkie te procesy szczęśliwie działają na jednej instancji m3.large .
Prośby o funkcje
Ponieważ z czasem nasze narzędzie CLS było coraz częściej używane, potrzebowało więcej funkcji. Poniżej omawiamy te i sposób ich dodania.
Brakujące metadane
Stopniowo wraz ze wzrostem liczby komponentów w BrowserStack wymagaliśmy od CLS więcej. Na przykład potrzebowaliśmy możliwości rejestrowania zdarzeń z komponentów bez identyfikatora sesji. W przeciwnym razie jego pozyskanie obciążyłoby naszą infrastrukturę, wpływając na wydajność aplikacji i pociągając ruch na naszych głównych serwerach.
Rozwiązaliśmy ten problem, włączając rejestrowanie zdarzeń przy użyciu innych kluczy, takich jak identyfikatory terminala i użytkowników. Teraz za każdym razem, gdy sesja jest tworzona lub aktualizowana, CLS jest informowany o identyfikatorze sesji, a także o odpowiednich identyfikatorach użytkownika i terminala. Przechowuje mapę, którą można pobrać w procesie zapisu do MongoDB. Za każdym razem, gdy pobierane jest zdarzenie zawierające identyfikator użytkownika lub terminala, dodawany jest identyfikator sesji.
Obsługa spamu (problemy z kodem w innych komponentach)
CLS napotkał również zwykłe trudności z obsługą zdarzeń spamowych. Często znajdowaliśmy wdrożenia w komponentach, które generowały ogromną liczbę żądań wysyłanych do CLS. Inne logi ucierpiałyby w tym procesie, ponieważ serwer stał się zbyt zajęty, aby je przetworzyć, a ważne logi zostały usunięte.
W większości rejestrowane dane pochodziły z żądań HTTP. Aby je kontrolować, włączamy ograniczanie szybkości w nginx (za pomocą modułu limit_req_zone), który blokuje żądania z dowolnego adresu IP, który trafia na żądania przekraczające określoną liczbę w krótkim czasie. Oczywiście wykorzystujemy raporty o stanie wszystkich zablokowanych adresów IP i informujemy odpowiedzialne zespoły.
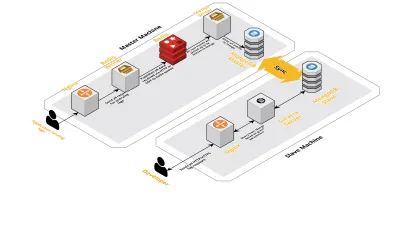
Skaluj v2
Wraz ze wzrostem liczby naszych sesji dziennie rosły również dane rejestrowane w CLS. Wpłynęło to na zapytania, które nasi programiści uruchamiali codziennie, i wkrótce nasze wąskie gardło dotyczyło samej maszyny. Nasza konfiguracja składała się z dwóch podstawowych maszyn, na których działały wszystkie powyższe komponenty, wraz z kilkoma skryptami do wysyłania zapytań do Mongo i śledzenia kluczowych wskaźników dla każdego produktu. Z biegiem czasu dane na maszynie znacznie wzrosły, a skrypty zaczęły zajmować dużo czasu procesora. Nawet po próbie optymalizacji zapytań Mongo zawsze wracaliśmy do tych samych problemów.
Aby rozwiązać ten problem, dodaliśmy kolejną maszynę do uruchamiania skryptów raportujących o kondycji oraz interfejs do wysyłania zapytań o te sesje. Proces obejmował uruchomienie nowej maszyny i skonfigurowanie niewolnika Mongo działającego na głównej maszynie. Pomogło to zredukować skoki procesora, które obserwowaliśmy każdego dnia, spowodowane przez te skrypty.
Wniosek
Tworzenie usługi dla zadania tak prostego, jak rejestrowanie danych, może się komplikować w miarę wzrostu ilości danych. W tym artykule omówiono rozwiązania, które zbadaliśmy, a także wyzwania stojące przed rozwiązaniem tego problemu. Eksperymentowaliśmy z Golangiem, aby zobaczyć, jak dobrze pasuje do naszego ekosystemu i jak dotąd byliśmy zadowoleni. Nasz wybór stworzenia usługi wewnętrznej zamiast płacenia za usługę zewnętrzną był cudownie opłacalny. Nie musieliśmy również skalować naszej konfiguracji na inną maszynę, aż do znacznie później - kiedy ilość naszych sesji wzrosła. Oczywiście nasze wybory dotyczące rozwoju CLS były całkowicie oparte na naszych wymaganiach i priorytetach.
Dziś CLS obsługuje do 15 milionów zdarzeń dziennie, co stanowi do 70 GB danych. Dane te są wykorzystywane do rozwiązywania wszelkich problemów, z którymi borykają się nasi klienci podczas dowolnej sesji. Wykorzystujemy te dane również do innych celów. Biorąc pod uwagę wgląd w dane każdej sesji na temat różnych produktów i komponentów wewnętrznych, zaczęliśmy wykorzystywać te dane do śledzenia każdego produktu. Osiąga się to poprzez wyodrębnienie kluczowych metryk dla wszystkich ważnych komponentów.
Podsumowując, odnieśliśmy wielki sukces w budowaniu naszego własnego narzędzia CLS. Jeśli ma to dla Ciebie sens, radzę rozważyć zrobienie tego samego!