
Jak zbudować skrobaczkę produktu Amazon za pomocą Node.js
Opublikowany: 2022-03-10Czy kiedykolwiek byłeś w sytuacji, w której musisz dokładnie poznać rynek konkretnego produktu? Może uruchamiasz jakieś oprogramowanie i chcesz wiedzieć, jak je wycenić. A może masz już własny produkt na rynku i chcesz zobaczyć, jakie funkcje dodać, aby zyskać przewagę nad konkurencją. A może po prostu chcesz kupić coś dla siebie i upewnić się, że otrzymasz najlepszy zwrot z każdej zainwestowanej złotówki.
Wszystkie te sytuacje mają jedną wspólną cechę: do podjęcia właściwej decyzji potrzebne są dokładne dane . Właściwie jest jeszcze jedna rzecz, którą dzielą. Wszystkie scenariusze mogą skorzystać na zastosowaniu skrobaka sieci.
Web scraping to praktyka wydobywania dużych ilości danych internetowych za pomocą oprogramowania. Zasadniczo jest to więc sposób na zautomatyzowanie żmudnego procesu 200-krotnego naciskania „kopiuj”, a następnie „wklej”. Oczywiście bot może to zrobić w czasie, który zajęło ci przeczytanie tego zdania, więc jest to nie tylko mniej nudne, ale też dużo szybsze.
Ale palące pytanie brzmi: po co ktoś miałby chcieć skrobać strony Amazona?
Zaraz się dowiesz! Ale przede wszystkim chciałbym teraz coś wyjaśnić — podczas gdy czynność zbierania publicznie dostępnych danych jest legalna, Amazon ma pewne środki, aby temu zapobiec na swoich stronach. W związku z tym zachęcam, aby zawsze zwracać uwagę na stronę internetową podczas skrobania, uważać, aby jej nie uszkodzić i postępować zgodnie z wytycznymi etycznymi.
Polecana lektura : „Przewodnik po etycznym zdrapywaniu dynamicznych stron internetowych z Node.js i Puppeteer” autorstwa Andreasa Altheimera
Dlaczego powinieneś wyodrębnić dane produktów Amazon
Będąc największym sprzedawcą internetowym na świecie, można śmiało powiedzieć, że jeśli chcesz coś kupić, prawdopodobnie możesz to kupić na Amazon. Nie trzeba więc mówić, jak wielką skarbnicą danych jest ta strona internetowa.
Podczas skrobania sieci głównym pytaniem powinno być, co zrobić z tymi wszystkimi danymi. Chociaż istnieje wiele indywidualnych powodów, sprowadza się to do dwóch głównych przypadków użycia: optymalizacji produktów i znalezienia najlepszych ofert.
“
Zacznijmy od pierwszego scenariusza. Jeśli nie zaprojektowałeś naprawdę innowacyjnego nowego produktu, istnieje szansa, że na Amazon znajdziesz już coś co najmniej podobnego. Scrapanie tych stron produktów może dostarczyć bezcennych danych, takich jak:
- Strategia cenowa konkurencji
Abyś mógł dostosować swoje ceny, aby były konkurencyjne i zrozumieć, jak inni radzą sobie z ofertami promocyjnymi; - Opinie klientów
Aby zobaczyć, na czym najbardziej zależy Twojej przyszłej bazie klientów i jak poprawić ich doświadczenie; - Najczęstsze cechy
Aby zobaczyć, co oferuje Twoja konkurencja, wiedzieć, które funkcjonalności są kluczowe, a które można zostawić na później.
Zasadniczo Amazon ma wszystko, czego potrzebujesz do głębokiej analizy rynku i produktu. Dzięki tym danym będziesz lepiej przygotowany do projektowania, uruchamiania i rozszerzania oferty produktów.
Drugi scenariusz może dotyczyć zarówno firm, jak i zwykłych ludzi. Pomysł jest bardzo podobny do tego, o czym wspomniałem wcześniej. Możesz zeskrobać ceny, funkcje i recenzje wszystkich produktów, które możesz wybrać, dzięki czemu będziesz mógł wybrać ten, który oferuje najwięcej korzyści za najniższą cenę. W końcu kto nie lubi dobrej okazji?
Nie wszystkie produkty zasługują na taki poziom dbałości o szczegóły, ale może to mieć ogromne znaczenie w przypadku drogich zakupów. Niestety, choć korzyści są oczywiste, ze zdrapywaniem Amazona wiąże się wiele trudności.
Wyzwania związane ze złomowaniem danych produktów Amazon
Nie wszystkie strony internetowe są takie same. Z reguły im bardziej złożona i rozpowszechniona jest strona internetowa, tym trudniej ją zeskrobać. Pamiętasz, jak powiedziałem, że Amazon jest najbardziej znaną witryną e-commerce? Cóż, to czyni go zarówno niezwykle popularnym, jak i dość złożonym.
Po pierwsze, Amazon wie, jak działają boty zgarniające, więc w witrynie zastosowano środki zaradcze. Mianowicie, jeśli skrobak podąża za przewidywalnym wzorcem, wysyłając żądania w stałych odstępach czasu, szybciej niż człowiek lub z niemal identycznymi parametrami, Amazon zauważy i zablokuje adres IP. Proxy mogą rozwiązać ten problem, ale nie potrzebowałem ich, ponieważ w przykładzie nie będziemy skrobać zbyt wielu stron.
Następnie Amazon celowo wykorzystuje różne struktury stron dla swoich produktów. To znaczy, że jeśli przejrzysz strony pod kątem różnych produktów, jest duża szansa, że znajdziesz znaczące różnice w ich strukturze i atrybutach. Powód tego jest dość prosty. Musisz dostosować kod scrapera do konkretnego systemu , a jeśli użyjesz tego samego skryptu na nowej stronie, będziesz musiał przepisać jego części. Tak więc zasadniczo sprawiają, że pracujesz więcej na danych.
Wreszcie Amazon to ogromna strona internetowa. Jeśli chcesz zebrać duże ilości danych, uruchomienie oprogramowania do scrapingu na twoim komputerze może zająć zbyt dużo czasu. Ten problem jest dodatkowo wzmacniany przez fakt, że zbyt szybka jazda spowoduje zablokowanie skrobaka. Jeśli więc potrzebujesz szybko dużej ilości danych, potrzebujesz naprawdę potężnego skrobaka.
Cóż, wystarczy mówić o problemach, skupmy się na rozwiązaniach!
Jak zbudować skrobak sieciowy dla Amazon
Aby wszystko było proste, zajmiemy się pisaniem kodu krok po kroku. Zapraszam do pracy równolegle z przewodnikiem.
Poszukaj danych, których potrzebujemy
Oto scenariusz: za kilka miesięcy przeprowadzam się w nowe miejsce i potrzebuję kilku nowych półek na książki i czasopisma. Chcę poznać wszystkie moje opcje i uzyskać jak najlepszą ofertę. Przejdźmy więc na rynek Amazon, wyszukajmy „półki” i zobaczmy, co dostaniemy.
Adres URL tego wyszukiwania i strony, którą będziemy przeszukiwać, znajduje się tutaj.
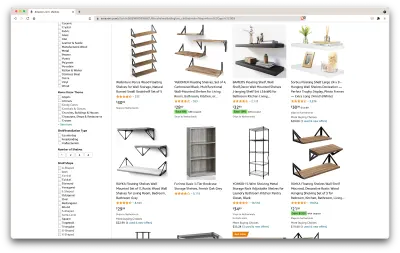
Ok, zróbmy bilans tego, co tu mamy. Wystarczy spojrzeć na stronę, aby uzyskać dobre zdjęcie na temat:
- jak wyglądają półki;
- co zawiera pakiet;
- jak oceniają je klienci;
- ich cena;
- link do produktu;
- sugestia tańszej alternatywy dla niektórych pozycji.
To więcej niż moglibyśmy prosić!
Uzyskaj wymagane narzędzia
Upewnijmy się, że mamy zainstalowane i skonfigurowane wszystkie poniższe narzędzia, zanim przejdziemy do następnego kroku.
- Chrom
Możemy go pobrać stąd. - Kod VS
Postępuj zgodnie z instrukcjami na tej stronie, aby zainstalować go na swoim urządzeniu. - Node.js
Zanim zaczniemy używać Axios lub Cheerio, musimy zainstalować Node.js i Node Package Manager. Najłatwiejszym sposobem zainstalowania Node.js i NPM jest pobranie jednego z instalatorów z oficjalnego źródła Node.Js i uruchomienie go.
Teraz utwórzmy nowy projekt NPM. Utwórz nowy folder dla projektu i uruchom następujące polecenie:
npm init -yAby stworzyć web scraper, musimy zainstalować w naszym projekcie kilka zależności:
- Cheerio
Biblioteka o otwartym kodzie źródłowym, która pomaga nam wydobywać przydatne informacje poprzez analizowanie znaczników i udostępnianie interfejsu API do manipulowania danymi wynikowymi. Cheerio pozwala nam wybierać znaczniki dokumentu HTML za pomocą selektorów:$("div"). Ten konkretny selektor pomaga nam wybrać wszystkie elementy<div>na stronie. Aby zainstalować Cheerio, uruchom następujące polecenie w folderze projektów:
npm install cheerio- Aksjos
Biblioteka JavaScript używana do wysyłania żądań HTTP z Node.js.
npm install axiosSprawdź źródło strony
W kolejnych krokach dowiemy się więcej o organizacji informacji na stronie. Chodzi o to, aby lepiej zrozumieć, co możemy wydobyć z naszego źródła.
Narzędzia programistyczne pomagają nam interaktywnie badać obiektowy model dokumentu (DOM) witryny. Będziemy korzystać z narzędzi programistycznych w Chrome, ale możesz korzystać z dowolnej przeglądarki internetowej, z którą masz do czynienia.
Otwórzmy go, klikając prawym przyciskiem myszy w dowolnym miejscu na stronie i wybierając opcję „Sprawdź”:
Otworzy się nowe okno zawierające kod źródłowy strony. Jak powiedzieliśmy wcześniej, staramy się zdrapywać informacje z każdej półki.
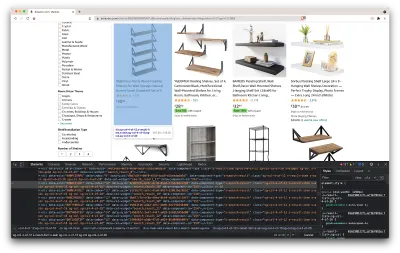
Jak widać na powyższym zrzucie ekranu, kontenery, w których znajdują się wszystkie dane, mają następujące klasy:
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20W kolejnym kroku za pomocą Cheerio wybierzemy wszystkie elementy zawierające potrzebne nam dane.

Pobierz dane
Po zainstalowaniu wszystkich przedstawionych powyżej zależności, utwórzmy nowy plik index.js i wpiszmy następujące wiersze kodu:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); Jak widać, importujemy potrzebne nam zależności w pierwszych dwóch wierszach, a następnie tworzymy funkcję fetchShelves() , która za pomocą Cheerio pobiera ze strony wszystkie elementy zawierające informacje o naszych produktach.
Iteruje nad każdym z nich i umieszcza go w pustej tablicy, aby uzyskać lepiej sformatowany wynik.
Funkcja fetchShelves() w danym momencie zwróci tylko tytuł produktu, więc zdobądźmy resztę potrzebnych nam informacji. Proszę dodać następujące wiersze kodu po wierszu, w którym zdefiniowaliśmy title zmiennej.
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } I zamień shelves.push(title) na shelves.push(element) .
Wybieramy teraz wszystkie potrzebne nam informacje i dodajemy je do nowego obiektu o nazwie element . Każdy element jest następnie umieszczany w tablicy shelves , aby uzyskać listę obiektów zawierających tylko te dane, których szukamy.
Tak powinien wyglądać przedmiot na shelf , zanim zostanie dodany do naszej listy:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }Sformatuj dane
Teraz, gdy udało nam się pobrać potrzebne nam dane, warto zapisać je jako plik .CSV , aby poprawić czytelność. Po zebraniu wszystkich danych użyjemy modułu fs dostarczonego przez Node.js i zapiszemy nowy plik o nazwie saved-shelves.csv w folderze projektu. Zaimportuj moduł fs na górze pliku i skopiuj lub napisz w następujących wierszach kodu:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) Jak widać, w pierwszych trzech wierszach formatujemy dane, które wcześniej zebraliśmy, łącząc wszystkie wartości obiektu półki za pomocą przecinka. Następnie za pomocą modułu fs tworzymy plik o nazwie saved-shelves.csv , dodajemy nowy wiersz zawierający nagłówki kolumn, dodajemy dane, które właśnie sformatowaliśmy i tworzymy funkcję zwrotną obsługującą błędy.
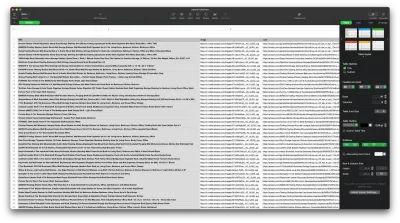
Wynik powinien wyglądać mniej więcej tak:
Dodatkowe wskazówki!
Skrobanie aplikacji jednostronicowych
Treści dynamiczne stają się obecnie standardem, ponieważ strony internetowe są bardziej złożone niż kiedykolwiek wcześniej. Aby zapewnić użytkownikom jak najlepsze wrażenia, programiści muszą stosować różne mechanizmy ładowania zawartości dynamicznej , co nieco komplikuje naszą pracę. Jeśli nie wiesz, co to oznacza, wyobraź sobie przeglądarkę bez graficznego interfejsu użytkownika. Na szczęście istnieje Puppeteer — magiczna biblioteka Node, która zapewnia interfejs API wysokiego poziomu do kontrolowania instancji Chrome za pomocą protokołu DevTools. Mimo to oferuje taką samą funkcjonalność jak przeglądarka, ale musi być kontrolowana programowo, wpisując kilka wierszy kodu. Zobaczmy, jak to działa.
We wcześniej utworzonym projekcie zainstaluj bibliotekę Puppeteer, uruchamiając npm install puppeteer , utwórz nowy plik puppeteer.js i skopiuj lub napisz wzdłuż następujących wierszy kodu:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() W powyższym przykładzie tworzymy instancję Chrome i otwieramy nową stronę przeglądarki, która jest wymagana, aby przejść do tego linku. W kolejnym wierszu mówimy przeglądarce bezgłowej, aby poczekała, aż na stronie pojawi się element z klasą rpBJOHq2PR60pnwJlUyP0 . Określiliśmy również, jak długo przeglądarka powinna czekać na załadowanie strony (2000 milisekund).
Korzystając z metody evaluate zmiennej page , poinstruowaliśmy Puppeteer, aby wykonał fragmenty kodu JavaScript w kontekście strony tuż po ostatecznym załadowaniu elementu. Umożliwi nam to dostęp do treści HTML strony i zwrócenie treści strony jako danych wyjściowych. Następnie zamykamy instancję Chrome, wywołując metodę close na zmiennej chrome . Wynikowa praca powinna składać się z całego dynamicznie generowanego kodu HTML. W ten sposób Puppeteer może pomóc nam załadować dynamiczną zawartość HTML .
Jeśli nie czujesz się komfortowo podczas korzystania z Puppeteer, pamiętaj, że istnieje kilka alternatyw, takich jak NightwatchJS, NightmareJS lub CasperJS. Są nieco inne, ale ostatecznie proces jest dość podobny.
Ustawianie nagłówków klienta user-agent
user-agent to nagłówek żądania, który informuje odwiedzaną witrynę o Tobie, a mianowicie o Twojej przeglądarce i systemie operacyjnym. Służy do optymalizacji treści pod kątem Twojej konfiguracji, ale strony internetowe używają go również do identyfikacji botów wysyłających mnóstwo żądań — nawet jeśli zmieniają IPS.
Oto jak wygląda nagłówek klienta user-agent :
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36Aby nie zostać wykrytym i zablokowanym, powinieneś regularnie zmieniać ten nagłówek. Zachowaj szczególną ostrożność, aby nie wysłać pustego lub nieaktualnego nagłówka, ponieważ nigdy nie powinno to się zdarzyć w przypadku użytkownika, który działa na bieżąco, a będziesz się wyróżniać.
Ograniczenie szybkości
Skrobaki internetowe mogą gromadzić treści niezwykle szybko, ale należy unikać korzystania z najwyższych prędkości. Są ku temu dwa powody:
- Zbyt wiele żądań w krótkim czasie może spowolnić serwer witryny, a nawet go wyłączyć, powodując problemy dla właściciela i innych odwiedzających. Zasadniczo może stać się atakiem DoS.
- Bez rotujących serwerów proxy przypomina to głośne ogłaszanie, że używasz bota, ponieważ żaden człowiek nie wysłałby setek lub tysięcy żądań na sekundę.
Rozwiązaniem jest wprowadzenie opóźnień między żądaniami, praktyki zwanej „ograniczeniem szybkości”. ( Zaimplementowanie też jest całkiem proste! )
W powyższym przykładzie Puppeteer, przed utworzeniem zmiennej body , możemy użyć metody waitForTimeout dostarczonej przez Puppeteer, aby poczekać kilka sekund przed wysłaniem kolejnego żądania:
await page.waitForTimeout(3000); Gdzie ms to liczba sekund, przez które chcesz poczekać.
Ponadto, jeśli chcielibyśmy zrobić to samo dla przykładu axios, możemy utworzyć obietnicę, która wywołuje metodę setTimeout() , aby pomóc nam czekać na pożądaną liczbę milisekund:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))W ten sposób możesz uniknąć wywierania zbyt dużej presji na docelowym serwerze, a także wprowadzić bardziej ludzkie podejście do skrobania sieci.
Myśli zamykające
I oto masz, przewodnik krok po kroku, jak stworzyć własny skrobak sieciowy dla danych produktów Amazon! Ale pamiętaj, to była tylko jedna sytuacja. Jeśli chcesz zeskrobać inną witrynę, musisz wprowadzić kilka poprawek, aby uzyskać sensowne wyniki.
Powiązane czytanie
Jeśli nadal chcesz zobaczyć więcej web scrapingu w akcji, oto kilka przydatnych materiałów do czytania:
- „Ostateczny przewodnik po drapaniu stron internetowych za pomocą JavaScript i Node.Js”, Robert Sfichi
- „Zaawansowane drapanie stron internetowych Node.JS za pomocą Puppeteer”, Gabriel Cioci
- „Python Web Scraping: najlepszy przewodnik po budowaniu skrobaka”, Raluca Penciuc