
Utwórz aplikację do tworzenia zakładek za pomocą FaunaDB, Netlify i 11ty
Opublikowany: 2022-03-10Rewolucja JAMstack (JavaScript, API i Markup) trwa w najlepsze. Witryny statyczne są bezpieczne, szybkie, niezawodne i przyjemne w pracy. Sercem JAMstack są statyczne generatory witryn (SSG), które przechowują Twoje dane w postaci zwykłych plików: Markdown, YAML, JSON, HTML i tak dalej. Czasami zarządzanie danymi w ten sposób może być zbyt skomplikowane. Czasami nadal potrzebujemy bazy danych.
Mając to na uwadze, Netlify — statyczny host witryny i FaunaDB — bezserwerowa baza danych w chmurze — nawiązały współpracę, aby ułatwić łączenie obu systemów.
Dlaczego witryna z zakładkami?
JAMstack doskonale nadaje się do wielu profesjonalnych zastosowań, ale jednym z moich ulubionych aspektów tego zestawu technologii jest niska bariera wejścia dla osobistych narzędzi i projektów.
Na rynku jest mnóstwo dobrych produktów do większości zastosowań, które mógłbym wymyślić, ale żaden nie byłby dla mnie dokładnie skonfigurowany. Żaden nie dałby mi pełnej kontroli nad moją zawartością. Żadne nie byłoby bez kosztów (pieniężnych lub informacyjnych).
Mając to na uwadze, możemy tworzyć własne mini-serwisy za pomocą metod JAMstack. W tym przypadku stworzymy witrynę do przechowywania i publikowania wszystkich interesujących artykułów, na które natrafię podczas codziennej lektury technologii.
Spędzam dużo czasu czytając artykuły, które zostały udostępnione na Twitterze. Kiedy mi się podoba, uderzam w ikonę „serca”. Potem, w ciągu kilku dni, znalezienie nowych faworytów jest prawie niemożliwe. Chcę zbudować coś tak bliskiego wygodzie „serca”, ale to, co posiadam i kontroluję.
Jak zamierzamy to zrobić? Cieszę się, że zapytałeś.
Chcesz otrzymać kod? Możesz pobrać go na Github lub po prostu wdrożyć bezpośrednio do Netlify z tego repozytorium! Zobacz gotowy produkt tutaj.
Nasze technologie
Funkcje hostingowe i bezserwerowe: Netlify
Do hostingu i funkcji bezserwerowych będziemy używać Netlify. Jako dodatkowy bonus, dzięki nowej współpracy, o której mowa powyżej, CLI Netlify — „Netlify Dev” — automatycznie połączy się z FaunaDB i będzie przechowywać nasze klucze API jako zmienne środowiskowe.
Baza danych: FaunaDB
FaunaDB to „bezserwerowa” baza danych NoSQL. Będziemy go używać do przechowywania danych naszych zakładek.
Generator stron statycznych: 11 tys
Jestem wielkim zwolennikiem HTML. Z tego powodu samouczek nie będzie wykorzystywał frontonu JavaScript do renderowania naszych zakładek. Zamiast tego użyjemy 11ty jako statycznego generatora witryn. 11ty ma wbudowaną funkcjonalność danych, która sprawia, że pobieranie danych z API jest tak proste, jak napisanie kilku krótkich funkcji JavaScript.
Skróty iOS
Potrzebujemy łatwego sposobu na publikowanie danych w naszej bazie danych. W tym przypadku użyjemy aplikacji Skróty na iOS. Można to również przekonwertować na skryptozakładkę JavaScript na Androida lub pulpit.
Konfiguracja FaunaDB przez Netlify Dev
Niezależnie od tego, czy już zarejestrowałeś się w FaunaDB, czy chcesz utworzyć nowe konto, najłatwiejszym sposobem skonfigurowania połączenia między FaunaDB i Netlify jest użycie CLI Netlify: Netlify Dev. Pełne instrukcje FaunaDB można znaleźć tutaj lub postępować zgodnie z poniższymi instrukcjami.
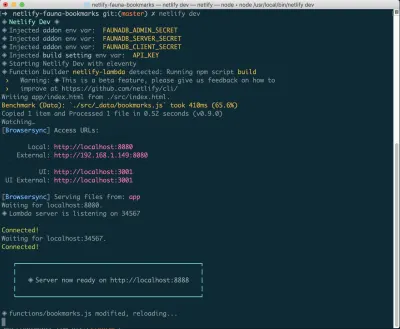
Jeśli nie masz jeszcze tego zainstalowanego, możesz uruchomić następujące polecenie w Terminalu:
npm install netlify-cli -gW katalogu projektu uruchom następujące polecenia:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account Gdy to wszystko jest połączone, możesz uruchomić netlify dev w swoim projekcie. Spowoduje to uruchomienie wszystkich skonfigurowanych przez nas skryptów kompilacji, ale także połączy się z usługami Netlify i FaunaDB i pobierze wszelkie niezbędne zmienne środowiskowe. Poręczny!
Tworzenie naszych pierwszych danych
Stąd zalogujemy się do FaunaDB i utworzymy nasz pierwszy zestaw danych. Zaczniemy od utworzenia nowej bazy danych o nazwie „zakładki”. Wewnątrz bazy danych mamy zbiory, dokumenty i indeksy.
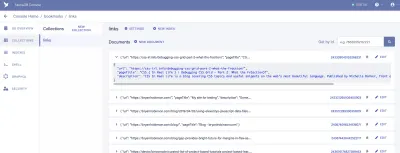
Kolekcja to skategoryzowana grupa danych. Każda część danych ma formę Dokumentu. Dokument to „pojedynczy, zmienny zapis w bazie danych FaunaDB”, zgodnie z dokumentacją Fauny. Możesz myśleć o Kolekcji jak o tradycyjnej tabeli bazy danych, ao dokumencie jako o wierszu.
Do naszej aplikacji potrzebujemy jednej kolekcji, którą nazwiemy „linkami”. Każdy dokument w kolekcji „links” będzie prostym obiektem JSON z trzema właściwościami. Na początek dodamy nowy dokument, którego użyjemy do zbudowania naszego pierwszego pobierania danych.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }Stwarza to podstawę dla informacji, które będziemy musieli pobrać z naszych zakładek, a także zapewnia nam pierwszy zestaw danych do pobrania do naszego szablonu.
Jeśli jesteś podobny do mnie, chcesz od razu zobaczyć owoce swojej pracy. Zróbmy coś na stronie!
Instalowanie 11ty i pobieranie danych do szablonu
Ponieważ chcemy, aby zakładki były renderowane w HTML, a nie pobierane przez przeglądarkę, będziemy potrzebować czegoś do renderowania. Jest wiele świetnych sposobów na zrobienie tego, ale dla łatwości i mocy uwielbiam używać generatora statycznych witryn 11ty.
Ponieważ 11ty jest generatorem stron statycznych JavaScript, możemy go zainstalować za pomocą NPM.
npm install --save @11ty/eleventy Z tej instalacji możemy uruchomić eleventy lub eleventy --serve w naszym projekcie, aby zacząć działać.
Netlify Dev często wykrywa 11ty jako wymaganie i uruchamia polecenie za nas. Aby to zadziałało — i upewnić się, że jesteśmy gotowi do wdrożenia, możemy również utworzyć polecenia „serve” i „build” w naszym package.json .
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }Pliki danych 11ty
Większość generatorów statycznych witryn ma wbudowany pomysł na „plik danych”. Zazwyczaj są to pliki JSON lub YAML, które umożliwiają dodawanie dodatkowych informacji do witryny.
W 11ty możesz używać plików danych JSON lub plików danych JavaScript. Korzystając z pliku JavaScript, możemy faktycznie wywołać nasze API i zwrócić dane bezpośrednio do szablonu.
Domyślnie 11ty chce przechowywać pliki danych w katalogu _data . Następnie możesz uzyskać dostęp do danych, używając nazwy pliku jako zmiennej w szablonach. W naszym przypadku utworzymy plik w _data/bookmarks.js i uzyskamy do niego dostęp poprzez nazwę zmiennej {{ bookmarks }} .
Jeśli chcesz zagłębić się w konfigurację plików danych, możesz zapoznać się z przykładami w dokumentacji 11ty lub zapoznać się z tym samouczkiem dotyczącym korzystania z plików danych 11ty w interfejsie Meetup API.
Plik będzie modułem JavaScript. Aby więc cokolwiek działało, musimy wyeksportować nasze dane lub funkcję. W naszym przypadku wyeksportujemy funkcję.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } Rozłóżmy to. Mamy tutaj dwie funkcje wykonujące naszą główną pracę: mapBookmarks() i getBookmarks() .
Funkcja getBookmarks() pobierze nasze dane z naszej bazy danych FaunaDB, a mapBookmarks() pobierze tablicę zakładek i zrestrukturyzuje ją, aby działała lepiej dla naszego szablonu.
Przyjrzyjmy się getBookmarks() .
getBookmarks()
Najpierw musimy zainstalować i zainicjować instancję sterownika FaunaDB JavaScript.
npm install --save faunadbTeraz, gdy już go zainstalowaliśmy, dodajmy go na początku naszego pliku danych. Ten kod pochodzi prosto z dokumentacji Fauny.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); Następnie możemy stworzyć naszą funkcję. Zaczniemy od zbudowania naszego pierwszego zapytania przy użyciu wbudowanych metod sterownika. Ten pierwszy fragment kodu zwróci odniesienia do bazy danych, których możemy użyć, aby uzyskać pełne dane dla wszystkich naszych linków oznaczonych zakładkami. Używamy metody Paginate , jako pomocnika w zarządzaniu stanem kursora, jeśli zdecydujemy się na paginację danych przed przekazaniem ich do 11ty. W naszym przypadku po prostu zwrócimy wszystkie referencje.
W tym przykładzie zakładam, że zainstalowałeś i połączyłeś FaunaDB za pomocą Netlify Dev CLI. Korzystając z tego procesu, otrzymujesz lokalne zmienne środowiskowe sekretów FaunaDB. Jeśli nie zainstalowałeś go w ten sposób lub nie używasz netlify dev w swoim projekcie, będziesz potrzebować pakietu takiego jak dotenv , aby utworzyć zmienne środowiskowe. Będziesz także musiał dodać zmienne środowiskowe do konfiguracji witryny Netlify, aby wdrożenia działały później.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })Ten kod zwróci tablicę wszystkich naszych linków w formie referencyjnej. Możemy teraz zbudować listę zapytań do wysłania do naszej bazy danych.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) Stąd wystarczy wyczyścić zwrócone dane. mapBookmarks() !
mapBookmarks()
W tej funkcji zajmujemy się dwoma aspektami danych.
Najpierw dostajemy darmową dateTime w FaunaDB. Dla wszelkich utworzonych danych istnieje właściwość sygnatury czasowej ( ts ). Nie jest sformatowany w sposób, który sprawia, że domyślny filtr daty Liquid jest szczęśliwy, więc naprawmy to.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } Pomijając to, możemy zbudować nowy obiekt dla naszych danych. W tym przypadku będzie miał właściwość time i użyjemy operatora Spread, aby zdestrukturyzować nasz obiekt data , aby wszystkie były aktywne na jednym poziomie.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }Oto nasze dane przed naszą funkcją:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }Oto nasze dane po naszej funkcji:

{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }Teraz mamy dobrze sformatowane dane, które są gotowe dla naszego szablonu!
Napiszmy prosty szablon. Przejrzymy nasze zakładki i sprawdzimy, czy każda ma tytuł pageTitle i url , więc nie wyglądamy głupio.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>Pozyskujemy i wyświetlamy teraz dane z FaunaDB. Poświęćmy chwilę i zastanówmy się, jakie to miłe, że renderuje to czysty HTML i nie ma potrzeby pobierania danych po stronie klienta!
Ale to naprawdę nie wystarczy, aby ta aplikacja była dla nas użyteczna. Wymyślmy lepszy sposób niż dodanie zakładki w konsoli FaunaDB.
Wejdź do funkcji Netlify
Dodatek Netlify Functions jest jednym z prostszych sposobów wdrażania funkcji lambda AWS. Ponieważ nie ma kroku konfiguracyjnego, jest idealny do projektów DIY, w których chcesz po prostu napisać kod.
Ta funkcja będzie znajdować się pod adresem URL w Twoim projekcie, który wygląda tak: https://myproject.com/.netlify/functions/bookmarks przy założeniu, że plik, który utworzymy w naszym folderze funkcji to bookmarks.js .
Podstawowy przepływ
- Przekaż adres URL jako parametr zapytania do adresu URL naszej funkcji.
- Użyj funkcji, aby załadować adres URL i pobrać tytuł i opis strony, jeśli są dostępne.
- Sformatuj szczegóły FaunaDB.
- Prześlij szczegóły do naszej kolekcji FaunaDB.
- Przebuduj witrynę.
Wymagania
Mamy kilka pakietów, których będziemy potrzebować podczas tworzenia tego. Użyjemy netlify-lambda CLI, aby zbudować nasze funkcje lokalnie. request-promise to pakiet, którego będziemy używać do składania żądań. Cheerio.js to pakiet, którego użyjemy do zdrapania określonych elementów z żądanej strony (pomyśl o jQuery dla węzła). I na koniec będziemy potrzebować FaunaDb (która powinna już być zainstalowana.
npm install --save netlify-lambda request-promise cheerioPo zainstalowaniu skonfigurujmy nasz projekt tak, aby budował i obsługiwał funkcje lokalnie.
Zmodyfikujemy nasze skrypty „build” i „serve” w naszym package.json , aby wyglądały tak:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } Ostrzeżenie: Wystąpił błąd ze sterownikiem Fauna's NodeJS podczas kompilacji z pakietem Webpack, którego funkcje Netlify używają do budowy. Aby obejść ten problem, musimy zdefiniować plik konfiguracyjny dla Webpacka. Możesz zapisać następujący kod w nowym — lub istniejącym — webpack.config.js .
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; Gdy plik już istnieje, kiedy użyjemy polecenia netlify-lambda , będziemy musieli powiedzieć mu, aby działał z tej konfiguracji. Dlatego nasze skrypty „serwuj” i „buduj” używają wartości --config dla tego polecenia.
Funkcja sprzątania
Aby utrzymać nasz główny plik funkcji tak czysty, jak to tylko możliwe, utworzymy nasze funkcje w osobnym katalogu bookmarks i zaimportujemy je do naszego głównego pliku funkcji.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
Funkcja getDetails() przyjmie adres URL przekazany z naszego wyeksportowanego modułu obsługi. Stamtąd przejdziemy do witryny pod tym adresem URL i pobierzemy odpowiednie części strony, aby zapisać je jako dane do naszej zakładki.
Zaczynamy od wymagania pakietów NPM, których potrzebujemy:
const rp = require('request-promise'); const cheerio = require('cheerio'); Następnie użyjemy modułu request-promise , aby zwrócić ciąg HTML dla żądanej strony i przekazać go do cheerio , aby uzyskać interfejs bardzo jQuery.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }Stąd musimy uzyskać tytuł strony i metaopis. W tym celu użyjemy selektorów, tak jak w jQuery.
Uwaga: w tym kodzie używamy 'head > title' jako selektora, aby uzyskać tytuł strony. Jeśli tego nie określisz, możesz otrzymać tagi <title> wewnątrz wszystkich plików SVG na stronie, co nie jest idealne.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }Mając dane w ręku, czas wysłać naszą zakładkę do naszej Kolekcji w FaunaDB!
saveBookmark(details)
W przypadku naszej funkcji zapisu będziemy chcieli przekazać szczegóły, które uzyskaliśmy z getDetails , a także adres URL jako pojedynczy obiekt. Operator Spread uderza ponownie!
const savedResponse = await saveBookmark({url, ...details}); W naszym pliku create.js musimy również wymagać i skonfigurować nasz sterownik FaunaDB. Powinno to wyglądać bardzo znajomo z naszego pliku danych 11ty.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });Kiedy już to usuniemy, będziemy mogli kodować.
Najpierw musimy sformatować nasze dane w strukturę danych, której Fauna oczekuje dla naszego zapytania. Fauna oczekuje obiektu z właściwością data zawierającą dane, które chcemy przechowywać.
const saveBookmark = async function(details) { const data = { data: details }; ... }Następnie otworzymy nowe zapytanie, aby dodać je do naszej Kolekcji. W tym przypadku użyjemy naszego pomocnika zapytań i użyjemy metody Create. Create() przyjmuje dwa argumenty. Pierwsza to Kolekcja, w której chcemy przechowywać nasze dane, a druga to same dane.
Po uratowaniu zwracamy naszemu przewodnikowi sukces lub porażkę.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }Przyjrzyjmy się całemu plikowi Function.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
Wnikliwe oko zauważy, że mamy jeszcze jedną funkcję zaimportowaną do naszego handlera: rebuildSite() . Ta funkcja użyje funkcji Deploy Hook Netlify, aby odbudować naszą witrynę z nowych danych za każdym razem, gdy prześlemy nową — pomyślną — zapisaną zakładkę.
W ustawieniach witryny w Netlify możesz uzyskać dostęp do ustawień Build & Deploy i utworzyć nowy „Build Hook”. Hooki mają nazwę, która pojawia się w sekcji Deploy, oraz opcję wdrożenia gałęzi innej niż master, jeśli sobie tego życzysz. W naszym przypadku nazwiemy go „new_link” i wdrożymy naszą główną gałąź.
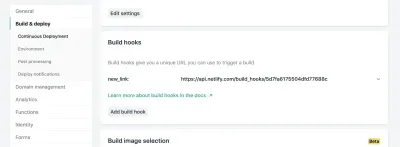
Stamtąd wystarczy wysłać żądanie POST na podany adres URL.
Potrzebujemy sposobu na składanie żądań, a ponieważ już zainstalowaliśmy request-promise , będziemy nadal używać tego pakietu, wymagając go na początku naszego pliku.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } Konfigurowanie skrótu iOS
Mamy więc bazę danych, sposób wyświetlania danych i funkcję dodawania danych, ale nadal nie jesteśmy zbyt przyjazni dla użytkownika.
Netlify udostępnia adresy URL dla naszych funkcji Lambda, ale ich wpisywanie na urządzeniu mobilnym nie jest zabawne. Musielibyśmy również przekazać do niego adres URL jako parametr zapytania. To DUŻO wysiłku. Jak możemy zrobić to jak najmniej wysiłku?
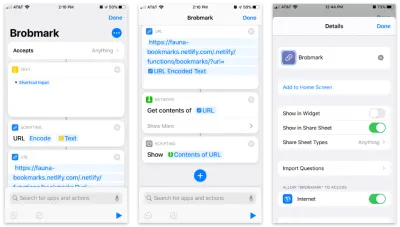
Aplikacja Skróty firmy Apple umożliwia tworzenie niestandardowych elementów, które trafiają do arkusza udostępniania. Wewnątrz tych skrótów możemy wysyłać różnego rodzaju żądania danych zebranych w procesie udostępniania.
Oto skrót krok po kroku:
- Zaakceptuj wszystkie elementy i przechowuj je w bloku „tekst”.
- Przekaż ten tekst do bloku „Skrypty” do kodowania adresu URL (na wszelki wypadek).
- Przekaż ten ciąg do bloku adresu URL z adresem URL naszej funkcji Netlify i parametrem zapytania
url. - Z „Sieci” użyj bloku „Pobierz zawartość”, aby POST do JSON na nasz adres URL.
- Opcjonalnie: Od „Skryptowania” „Pokaż” zawartość ostatniego kroku (aby potwierdzić dane, które wysyłamy).
Aby uzyskać do tego dostęp z menu udostępniania, otwieramy ustawienia tego skrótu i włączamy opcję „Pokaż w arkuszu udostępniania”.
Od iOS13 te akcje „Akcje” można dodawać do ulubionych i przenosić na wysoką pozycję w oknie dialogowym.
Mamy teraz działającą „aplikację” do udostępniania zakładek na wielu platformach!
Idź o krok dalej!
Jeśli jesteś zainspirowany do samodzielnego wypróbowania, istnieje wiele innych możliwości dodania funkcjonalności. Radość z sieci DIY polega na tym, że możesz sprawić, by tego rodzaju aplikacje działały dla Ciebie. Oto kilka pomysłów:
- Użyj fałszywego „klucza API” do szybkiego uwierzytelnienia, aby inni użytkownicy nie publikowali na Twojej stronie (moja używa klucza API, więc nie próbuj do niego publikować!).
- Dodaj funkcję tagów, aby uporządkować zakładki.
- Dodaj kanał RSS do swojej witryny, aby inni mogli subskrybować.
- Programowo wysyłaj cotygodniowe wiadomości e-mail z podsumowaniem dodanych linków.
Naprawdę, niebo jest granicą, więc zacznij eksperymentować!