
Rozkład dwumianowy w Pythonie z przykładami ze świata rzeczywistego [2022]
Opublikowany: 2021-01-09Wartość prawdopodobieństwa i statystyki w dziedzinie nauki o danych była ogromna, a sztuczna inteligencja i uczenie maszynowe w dużej mierze na nich polegały. Używamy modeli procesowych rozkładu normalnego za każdym razem, gdy przeprowadzamy testy A/B i modelowanie inwestycji.
Jednak rozkład dwumianowy w Pythonie jest stosowany na wiele sposobów w celu przeprowadzenia kilku procesów. Ale zanim zaczniesz pracę z dystrybucją dwumianową w Pythonie , musisz wiedzieć ogólnie o dystrybucji dwumianowej i jej zastosowaniu w życiu codziennym. Jeśli jesteś początkującym i chcesz dowiedzieć się więcej na temat nauki o danych, zapoznaj się z naszym szkoleniem z nauki o danych prowadzonym przez najlepsze uniwersytety.
Spis treści
Co to jest rozkład dwumianowy ?
Czy kiedykolwiek rzuciłeś monetą? Jeśli tak, to musisz wiedzieć, że prawdopodobieństwo trafienia orła lub reszki jest równe. Ale co z prawdopodobieństwem uzyskania siedmiu reszek w sumie dziesięciu rzutów monetą? W tym miejscu rozkład dwumianowy może pomóc w obliczeniu wyników każdego rzutu, a tym samym w ustaleniu prawdopodobieństwa uzyskania siedmiu reszek za dziesięć rzutów monetą.
Sedno rozkładu prawdopodobieństwa pochodzi z wariancji dowolnego zdarzenia. Na każde 10 rzutów monetą prawdopodobieństwo trafienia orłem może wynosić od jednego do dziesięciu razy, jednakowo i prawdopodobnie. Niepewność wyniku (znana również jako wariancja) pomaga w wygenerowaniu rozkładu otrzymanych wyników.
Innymi słowy, rozkład dwumianowy to proces, w którym są tylko dwa możliwe wyniki: prawda lub fałsz. Dlatego ma równe prawdopodobieństwo obu wyników we wszystkich zdarzeniach, ponieważ za każdym razem wykonywane są te same czynności. Jest tylko jeden warunek… Kroki muszą być całkowicie niezależne od siebie, a wyniki mogą, ale nie muszą być równie prawdopodobne.
Dlatego funkcją prawdopodobieństwa rozkładu dwumianowego jest:
f f( k k , n n, p p) = P r Pr( k k; n n, p p) = P r Pr ( X X= k k) =
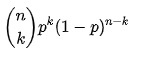
Źródło
Gdzie,
![]() = n n! k k ! ( n n! - k k!)
= n n! k k ! ( n n! - k k!)
Tutaj n = całkowita liczba prób
p = prawdopodobieństwo sukcesu
k = docelowa liczba sukcesów
Rozkład dwumianowy w Pythonie
W przypadku rozkładu dwumianowego za pośrednictwem Pythona można utworzyć odrębną zmienną losową z funkcji binom.rvs(), gdzie „n” jest zdefiniowane jako całkowita częstotliwość prób, a „p” jest równe prawdopodobieństwu sukcesu.
Możesz także przesunąć rozkład za pomocą funkcji loc, a rozmiar określa częstotliwość akcji, która jest powtarzana w serii. Dodanie random_state może pomóc w utrzymaniu odtwarzalności.
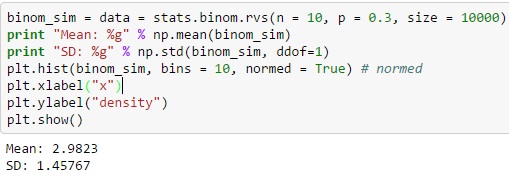
Źródło
Rzeczywiste przykłady rozkładu dwumianowego w Pythonie
Istnieje wiele innych zdarzeń (większych niż rzuty monetą), które można rozwiązać za pomocą rozkładu dwumianowego w Pythonie. Niektóre przypadki użycia mogą pomóc w śledzeniu i poprawie ROI (zwrotu z inwestycji) dla dużych i małych firm. Oto jak:

- Pomyśl o call center, w którym każdy pracownik otrzymuje średnio 50 połączeń dziennie.
- Prawdopodobieństwo konwersji podczas każdego połączenia wynosi 4%.
- Średnia generacja przychodów dla firmy na podstawie każdej takiej konwersji wynosi 20 USD.
- Jeśli przeanalizujesz 100 takich pracowników, którzy każdego dnia zarabiają 200 USD, to
n = 50
p = 4%
Kod może generować dane wyjściowe w następujący sposób:
- Średni współczynnik konwersji dla każdego pracownika = 2,13
- Odchylenie standardowe konwersji dla każdego personelu call center = 1,48
- Konwersja brutto = 213
- Generowanie przychodów brutto = 21 300 USD
- Koszt brutto = 20 000 USD
- Zysk brutto = 1300 USD
Modele rozkładu dwumianowego i inne rozkłady prawdopodobieństwa mogą przewidywać tylko przybliżenie, które może zbliżyć się do świata rzeczywistego pod względem parametrów działania, „n” i „p”. Pomaga nam zrozumieć i zidentyfikować nasze obszary zainteresowania oraz zwiększyć ogólne szanse na lepszą wydajność i skuteczność.
Przeczytaj także: 13 ciekawych pomysłów na projekt struktury danych i tematów dla początkujących
Co następne?
Jeśli jesteś zainteresowany nauką o danych, sprawdź program IIIT-B i upGrad Executive PG w dziedzinie Data Science , który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, 1 -on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Jaka jest różnica między dyskretnym rozkładem prawdopodobieństwa a ciągłym rozkładem prawdopodobieństwa?
Dyskretny rozkład prawdopodobieństwa lub po prostu dyskretny rozkład oblicza prawdopodobieństwa zmiennej losowej, która może być dyskretna. Na przykład, jeśli rzucimy monetą dwa razy, prawdopodobne wartości zmiennej losowej X, która oznacza całkowitą liczbę orłów, wyniosą {0, 1, 2}, a nie dowolna wartość losowa. Bernoulli, dwumianowy, hipergeometryczny to tylko niektóre przykłady dyskretnego rozkładu prawdopodobieństwa. Z drugiej strony ciągły rozkład prawdopodobieństwa dostarcza prawdopodobieństwa wartości losowej, która może być dowolną liczbą losową. Na przykład wartość zmiennej losowej X oznaczającej wzrost mieszkańców miasta może być dowolną liczbą, taką jak 161,2, 150,9 itd. Normalny, T Studenta, Chi-kwadrat to tylko niektóre przykłady rozkładu ciągłego.
Jakie znaczenie ma prawdopodobieństwo w nauce o danych?
Ponieważ nauka o danych polega na badaniu danych, prawdopodobieństwo odgrywa tutaj kluczową rolę. Poniższe powody opisują, jak prawdopodobieństwo jest nieodzowną częścią nauki o danych: Pomaga analitykom i badaczom w przewidywaniu na podstawie zbiorów danych. Tego rodzaju szacunkowe wyniki są podstawą do dalszej analizy danych. Prawdopodobieństwo jest również wykorzystywane przy opracowywaniu algorytmów wykorzystywanych w modelach uczenia maszynowego. Pomaga w analizie zestawów danych używanych do uczenia modeli. Pozwala na kwantyfikację danych i uzyskanie wyników, takich jak pochodne, średnia i dystrybucja. Wszystkie wyniki uzyskane za pomocą prawdopodobieństwa ostatecznie podsumowują dane. Podsumowanie to pomaga również w identyfikacji istniejących wartości odstających w zbiorach danych.
Wyjaśnij rozkład hipergeometryczny. W jakim przypadku jest to rozkład dwumianowy?
sukcesy w liczbie prób bez wymiany. Powiedzmy, że mamy worek pełen czerwonych i zielonych piłek i musimy obliczyć prawdopodobieństwo wybicia zielonej piłki w 5 próbach, ale za każdym razem, gdy wybieramy piłkę, nie zwracamy jej z powrotem do worka. To trafny przykład rozkładu hipergeometrycznego.
Dla większego N bardzo trudno jest obliczyć rozkład hipergeometryczny, ale gdy N jest małe, w tym przypadku dąży do rozkładu dwumianowego.